 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ZeroGen: Zero-shot Multimodal Controllable Text Generation with Multiple Oracles
Jun 29, 2023

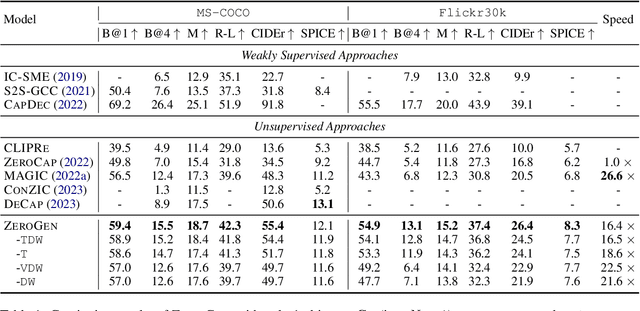
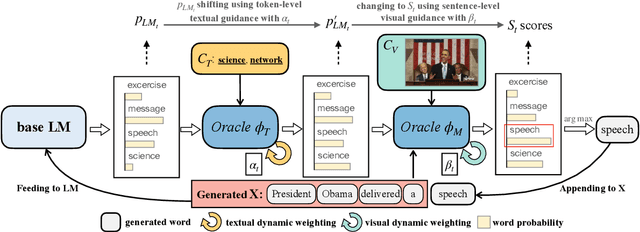
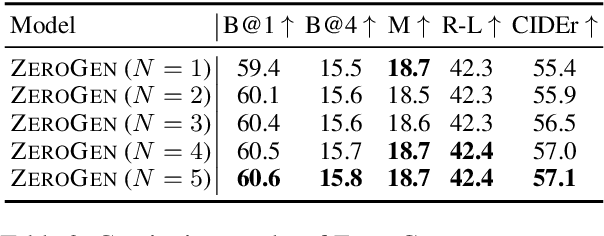
Automatically generating textual content with desired attributes is an ambitious task that people have pursued long. Existing works have made a series of progress in incorporating unimodal controls into language models (LMs), whereas how to generate controllable sentences with multimodal signals and high efficiency remains an open question. To tackle the puzzle, we propose a new paradigm of zero-shot controllable text generation with multimodal signals (\textsc{ZeroGen}). Specifically, \textsc{ZeroGen} leverages controls of text and image successively from token-level to sentence-level and maps them into a unified probability space at decoding, which customizes the LM outputs by weighted addition without extra training. To achieve better inter-modal trade-offs, we further introduce an effective dynamic weighting mechanism to regulate all control weights. Moreover, we conduct substantial experiments to probe the relationship of being in-depth or in-width between signals from distinct modalities. Encouraging empirical results on three downstream tasks show that \textsc{ZeroGen} not only outperforms its counterparts on captioning tasks by a large margin but also shows great potential in multimodal news generation with a higher degree of control. Our code will be released at https://github.com/ImKeTT/ZeroGen.
KBNet: Kernel Basis Network for Image Restoration
Mar 06, 2023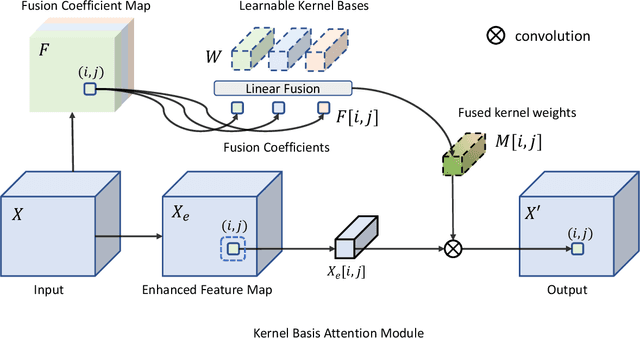
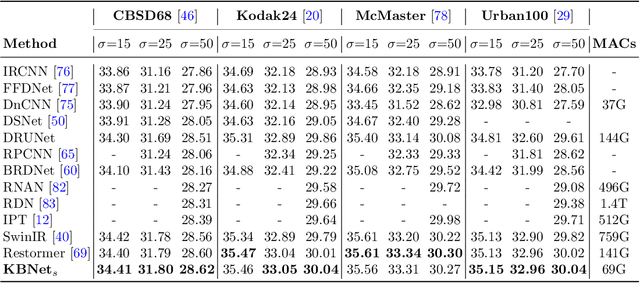
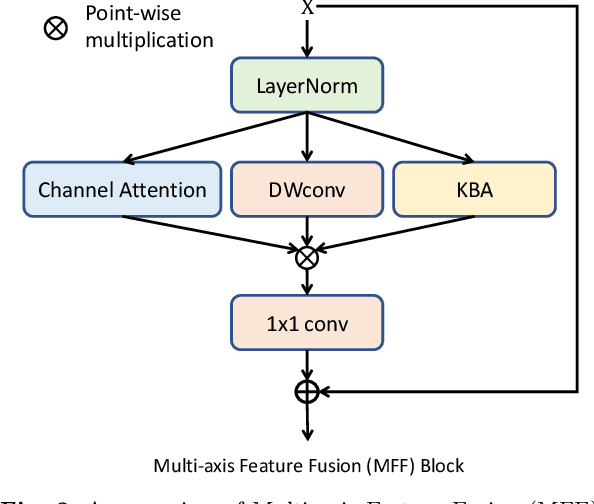
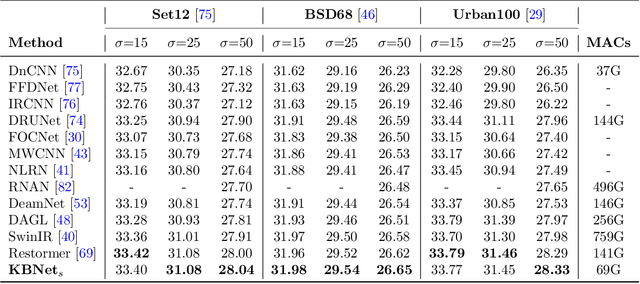
How to aggregate spatial information plays an essential role in learning-based image restoration. Most existing CNN-based networks adopt static convolutional kernels to encode spatial information, which cannot aggregate spatial information adaptively. Recent transformer-based architectures achieve adaptive spatial aggregation. But they lack desirable inductive biases of convolutions and require heavy computational costs. In this paper, we propose a kernel basis attention (KBA) module, which introduces learnable kernel bases to model representative image patterns for spatial information aggregation. Different kernel bases are trained to model different local structures. At each spatial location, they are linearly and adaptively fused by predicted pixel-wise coefficients to obtain aggregation weights. Based on the KBA module, we further design a multi-axis feature fusion (MFF) block to encode and fuse channel-wise, spatial-invariant, and pixel-adaptive features for image restoration. Our model, named kernel basis network (KBNet), achieves state-of-the-art performances on more than ten benchmarks over image denoising, deraining, and deblurring tasks while requiring less computational cost than previous SOTA methods.
LightGlue: Local Feature Matching at Light Speed
Jun 23, 2023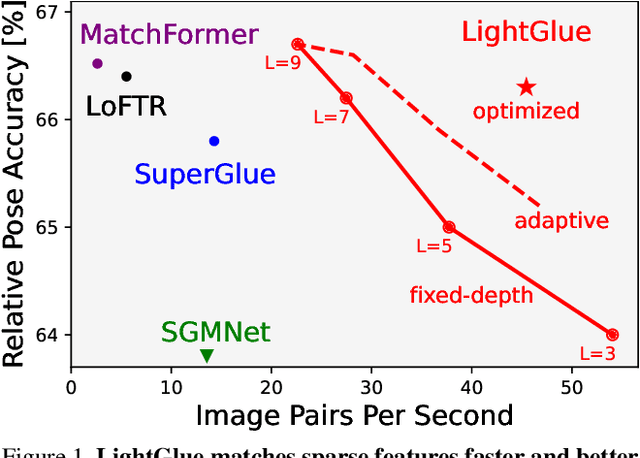
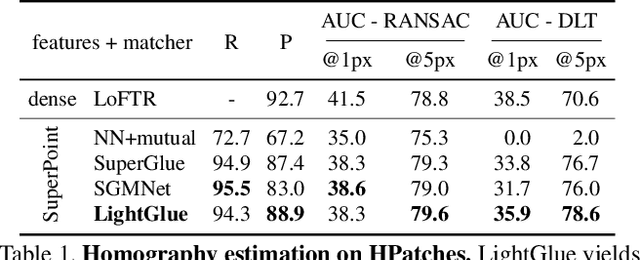

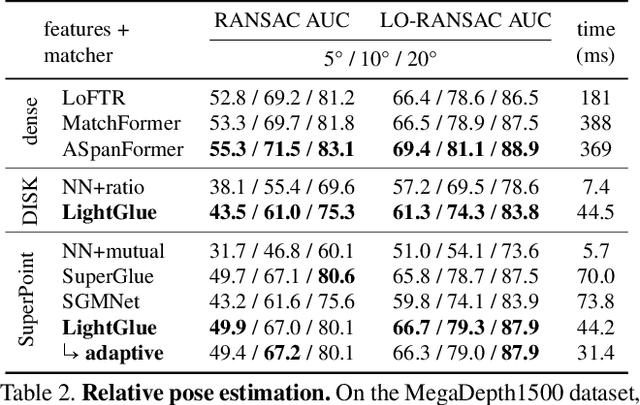
We introduce LightGlue, a deep neural network that learns to match local features across images. We revisit multiple design decisions of SuperGlue, the state of the art in sparse matching, and derive simple but effective improvements. Cumulatively, they make LightGlue more efficient - in terms of both memory and computation, more accurate, and much easier to train. One key property is that LightGlue is adaptive to the difficulty of the problem: the inference is much faster on image pairs that are intuitively easy to match, for example because of a larger visual overlap or limited appearance change. This opens up exciting prospects for deploying deep matchers in latency-sensitive applications like 3D reconstruction. The code and trained models are publicly available at https://github.com/cvg/LightGlue.
SMC-UDA: Structure-Modal Constraint for Unsupervised Cross-Domain Renal Segmentation
Jun 14, 2023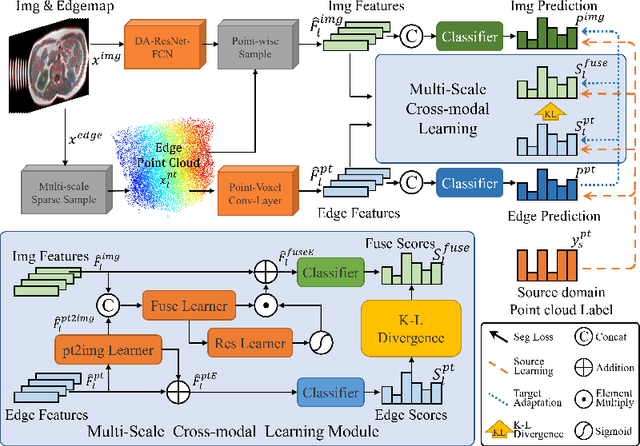
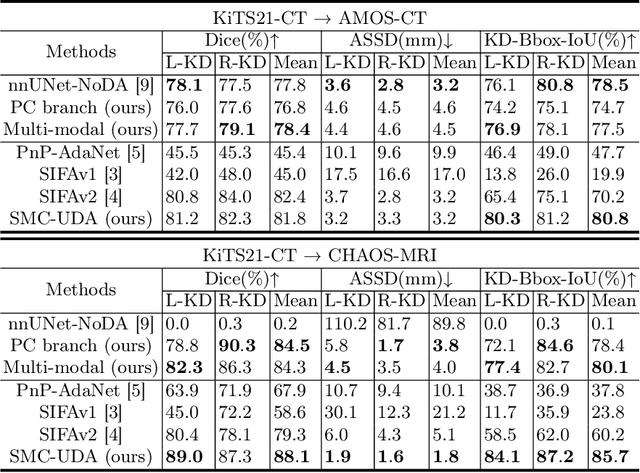

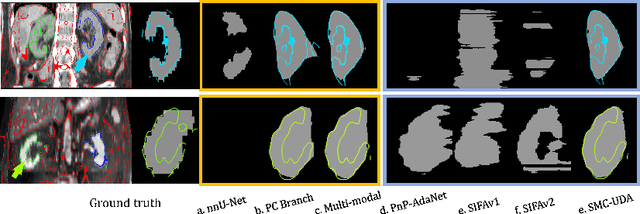
Medical image segmentation based on deep learning often fails when deployed on images from a different domain. The domain adaptation methods aim to solve domain-shift challenges, but still face some problems. The transfer learning methods require annotation on the target domain, and the generative unsupervised domain adaptation (UDA) models ignore domain-specific representations, whose generated quality highly restricts segmentation performance. In this study, we propose a novel Structure-Modal Constrained (SMC) UDA framework based on a discriminative paradigm and introduce edge structure as a bridge between domains. The proposed multi-modal learning backbone distills structure information from image texture to distinguish domain-invariant edge structure. With the structure-constrained self-learning and progressive ROI, our methods segment the kidney by locating the 3D spatial structure of the edge. We evaluated SMC-UDA on public renal segmentation datasets, adapting from the labeled source domain (CT) to the unlabeled target domain (CT/MRI). The experiments show that our proposed SMC-UDA has a strong generalization and outperforms generative UDA methods.
Anomaly Detection with Conditioned Denoising Diffusion Models
May 25, 2023
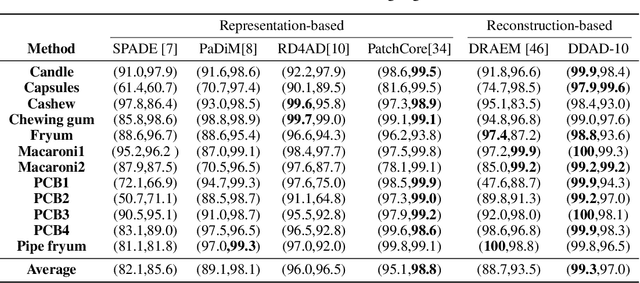
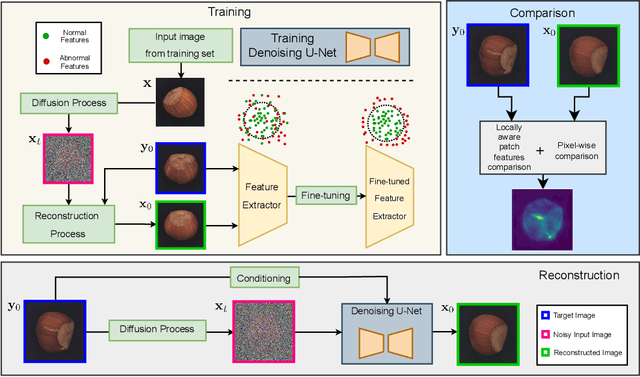
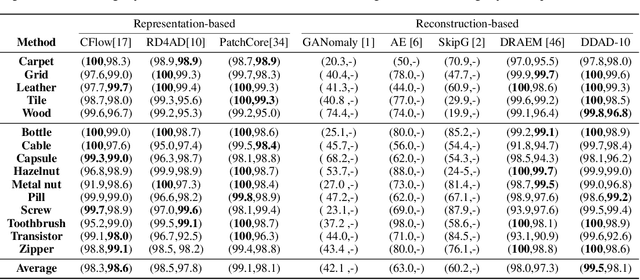
Reconstruction-based methods have struggled to achieve competitive performance on anomaly detection. In this paper, we introduce Denoising Diffusion Anomaly Detection (DDAD). We propose a novel denoising process for image reconstruction conditioned on a target image. This results in a coherent restoration that closely resembles the target image. Subsequently, our anomaly detection framework leverages this conditioning where the target image is set as the input image to guide the denoising process, leading to defectless reconstruction while maintaining nominal patterns. We localise anomalies via a pixel-wise and feature-wise comparison of the input and reconstructed image. Finally, to enhance the effectiveness of feature comparison, we introduce a domain adaptation method that utilises generated examples from our conditioned denoising process to fine-tune the feature extractor. The veracity of the approach is demonstrated on various datasets including MVTec and VisA benchmarks, achieving state-of-the-art results of 99.5% and 99.3% image-level AUROC respectively.
SMRVIS: Point cloud extraction from 3-D ultrasound for non-destructive testing
Jun 07, 2023
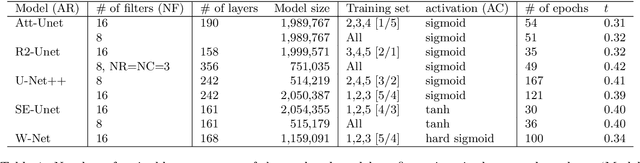
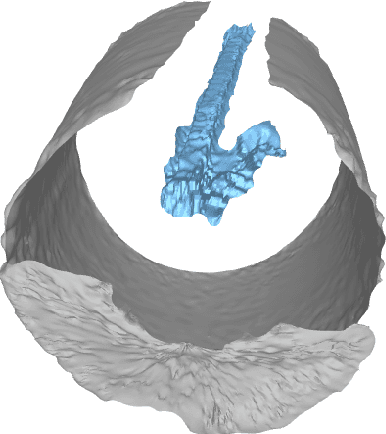

We propose to formulate point cloud extraction from ultrasound volumes as an image segmentation problem. Through this convenient formulation, a quick prototype exploring various variants of the U-Net architecture was developed and evaluated. This report documents the experimental results compiled using a training dataset of 5 labelled ultrasound volumes and 84 unlabelled volumes that got completed in a two-week period as part of a challenge submission to an open challenge entitled ``Deep Learning in Ultrasound Image Analysis''. Source code is shared with the research community at this GitHub URL \url{https://github.com/lisatwyw/smrvis}.
AutoML Systems For Medical Imaging
Jun 07, 2023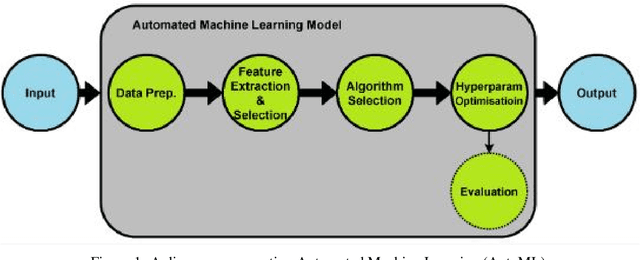
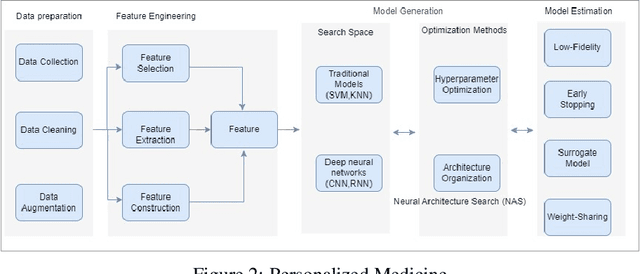
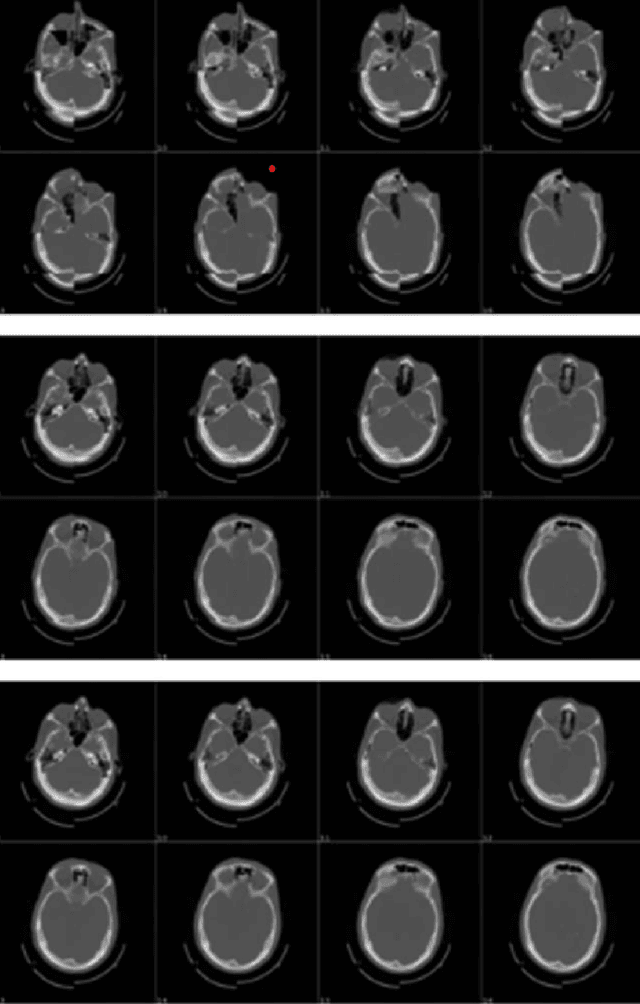
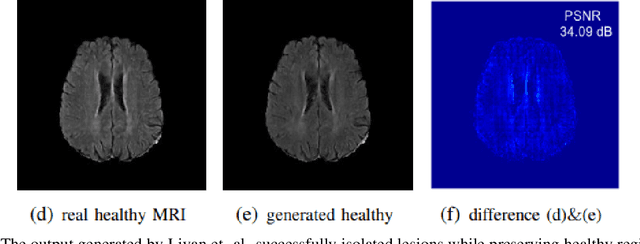
The integration of machine learning in medical image analysis can greatly enhance the quality of healthcare provided by physicians. The combination of human expertise and computerized systems can result in improved diagnostic accuracy. An automated machine learning approach simplifies the creation of custom image recognition models by utilizing neural architecture search and transfer learning techniques. Medical imaging techniques are used to non-invasively create images of internal organs and body parts for diagnostic and procedural purposes. This article aims to highlight the potential applications, strategies, and techniques of AutoML in medical imaging through theoretical and empirical evidence.
Using super-resolution for enhancing visual perception and segmentation performance in veterinary cytology
Jun 20, 2023
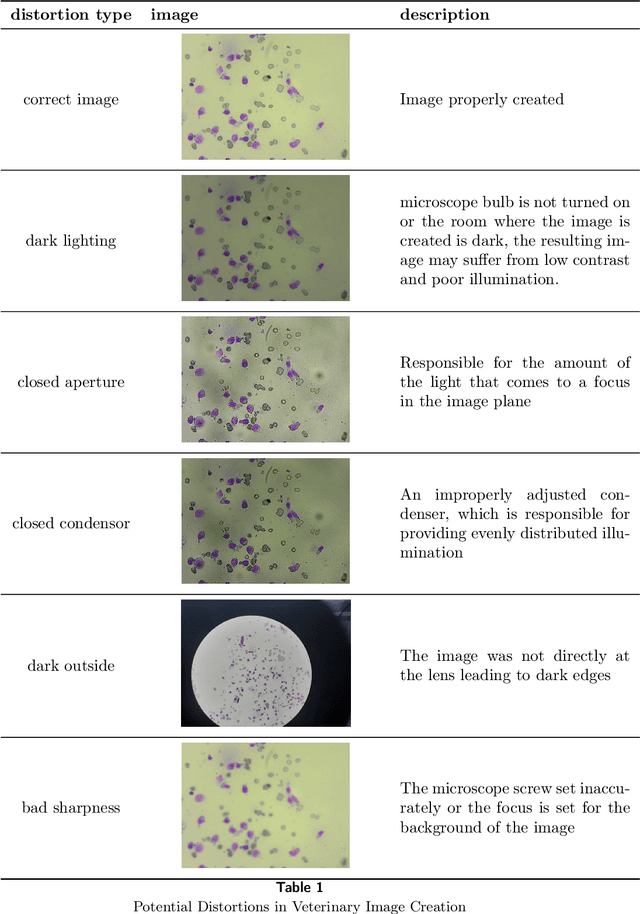
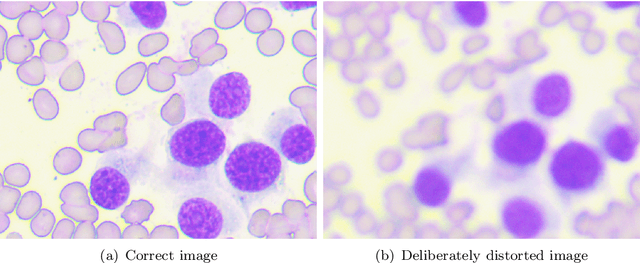
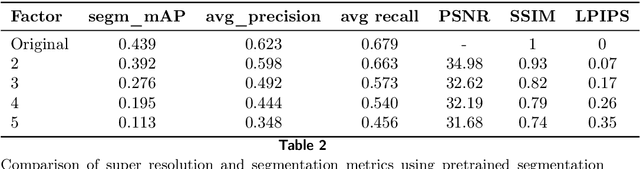
The primary objective of this research was to enhance the quality of semantic segmentation in cytology images by incorporating super-resolution (SR) architectures. An additional contribution was the development of a novel dataset aimed at improving imaging quality in the presence of inaccurate focus. Our experimental results demonstrate that the integration of SR techniques into the segmentation pipeline can lead to a significant improvement of up to 25% in the mean average precision (mAP) segmentation metric. These findings suggest that leveraging SR architectures holds great promise for advancing the state of the art in cytology image analysis.
DUBLIN -- Document Understanding By Language-Image Network
May 24, 2023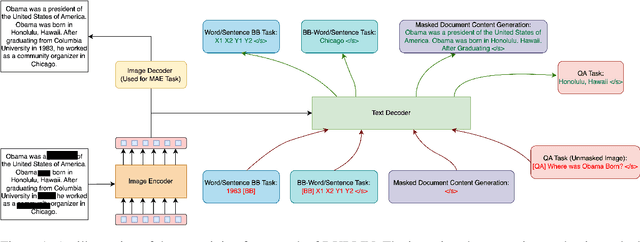


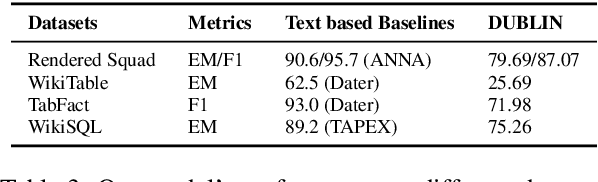
Visual document understanding is a complex task that involves analyzing both the text and the visual elements in document images. Existing models often rely on manual feature engineering or domain-specific pipelines, which limit their generalization ability across different document types and languages. In this paper, we propose DUBLIN, which is pretrained on web pages using three novel objectives: Masked Document Content Generation Task, Bounding Box Task, and Rendered Question Answering Task, that leverage both the spatial and semantic information in the document images. Our model achieves competitive or state-of-the-art results on several benchmarks, such as Web-Based Structural Reading Comprehension, Document Visual Question Answering, Key Information Extraction, Diagram Understanding, and Table Question Answering. In particular, we show that DUBLIN is the first pixel-based model to achieve an EM of 77.75 and F1 of 84.25 on the WebSRC dataset. We also show that our model outperforms the current pixel-based SoTA models on DocVQA and AI2D datasets by 2% and 21%, respectively. Also, DUBLIN is the first ever pixel-based model which achieves comparable performance to text-based SoTA methods on XFUND dataset for Semantic Entity Recognition showcasing its multilingual capability. Moreover, we create new baselines for text-based datasets by rendering them as document images to promote research in this direction.
You are here! Finding position and orientation on a 2D map from a single image: The Flatlandia localization problem and dataset
Apr 17, 2023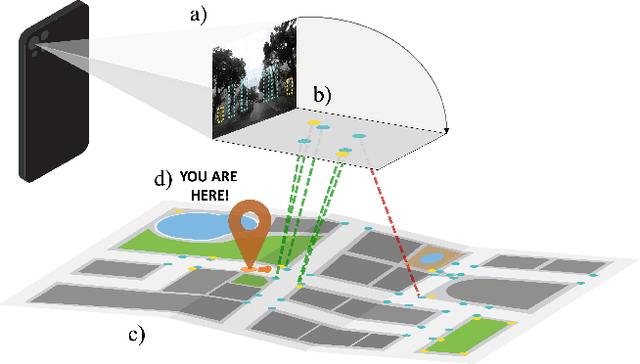
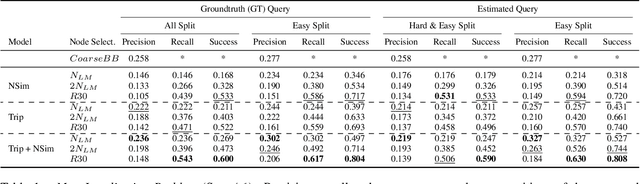
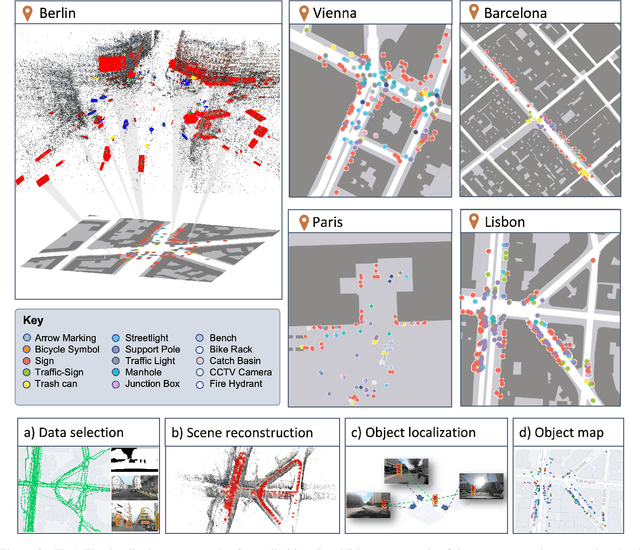
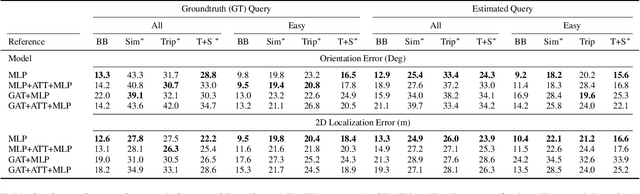
We introduce Flatlandia, a novel problem for visual localization of an image from object detections composed of two specific tasks: i) Coarse Map Localization: localizing a single image observing a set of objects in respect to a 2D map of object landmarks; ii) Fine-grained 3DoF Localization: estimating latitude, longitude, and orientation of the image within a 2D map. Solutions for these new tasks exploit the wide availability of open urban maps annotated with GPS locations of common objects (\eg via surveying or crowd-sourced). Such maps are also more storage-friendly than standard large-scale 3D models often used in visual localization while additionally being privacy-preserving. As existing datasets are unsuited for the proposed problem, we provide the Flatlandia dataset, designed for 3DoF visual localization in multiple urban settings and based on crowd-sourced data from five European cities. We use the Flatlandia dataset to validate the complexity of the proposed tasks.