 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DGC-GNN: Descriptor-free Geometric-Color Graph Neural Network for 2D-3D Matching
Jun 21, 2023

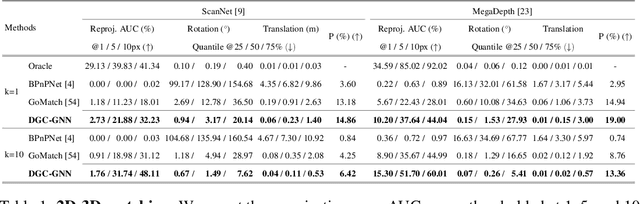


Direct matching of 2D keypoints in an input image to a 3D point cloud of the scene without requiring visual descriptors has garnered increased interest due to its lower memory requirements, inherent privacy preservation, and reduced need for expensive 3D model maintenance compared to visual descriptor-based methods. However, existing algorithms often compromise on performance, resulting in a significant deterioration compared to their descriptor-based counterparts. In this paper, we introduce DGC-GNN, a novel algorithm that employs a global-to-local Graph Neural Network (GNN) that progressively exploits geometric and color cues to represent keypoints, thereby improving matching robustness. Our global-to-local procedure encodes both Euclidean and angular relations at a coarse level, forming the geometric embedding to guide the local point matching. We evaluate DGC-GNN on both indoor and outdoor datasets, demonstrating that it not only doubles the accuracy of the state-of-the-art descriptor-free algorithm but, also, substantially narrows the performance gap between descriptor-based and descriptor-free methods. The code and trained models will be made publicly available.
Polygon Detection for Room Layout Estimation using Heterogeneous Graphs and Wireframes
Jun 21, 2023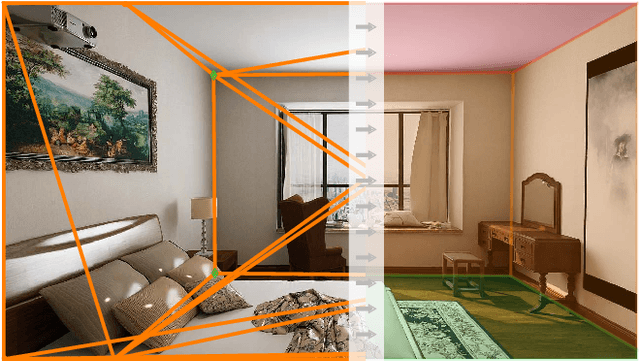
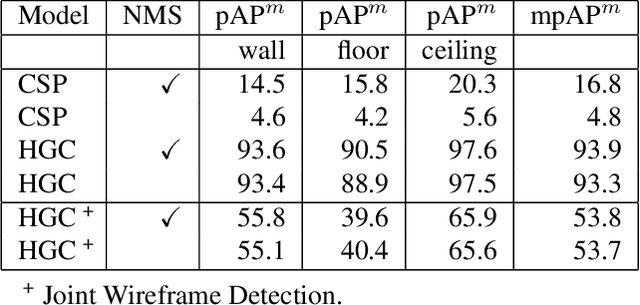
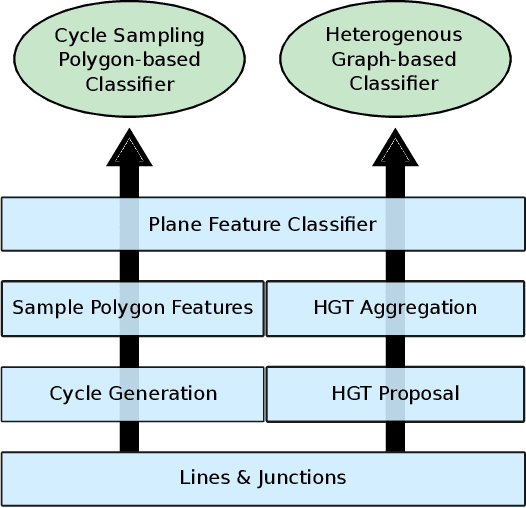

This paper presents a neural network based semantic plane detection method utilizing polygon representations. The method can for example be used to solve room layout estimations tasks. The method is built on, combines and further develops several different modules from previous research. The network takes an RGB image and estimates a wireframe as well as a feature space using an hourglass backbone. From these, line and junction features are sampled. The lines and junctions are then represented as an undirected graph, from which polygon representations of the sought planes are obtained. Two different methods for this last step are investigated, where the most promising method is built on a heterogeneous graph transformer. The final output is in all cases a projection of the semantic planes in 2D. The methods are evaluated on the Structured 3D dataset and we investigate the performance both using sampled and estimated wireframes. The experiments show the potential of the graph-based method by outperforming state of the art methods in Room Layout estimation in the 2D metrics using synthetic wireframe detections.
Training Transformers with 4-bit Integers
Jun 21, 2023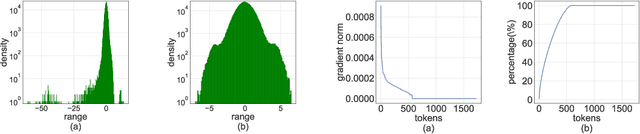
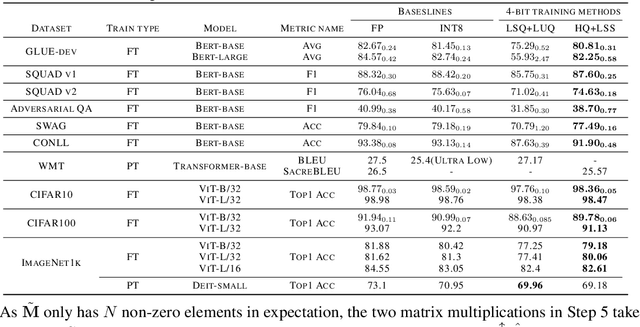
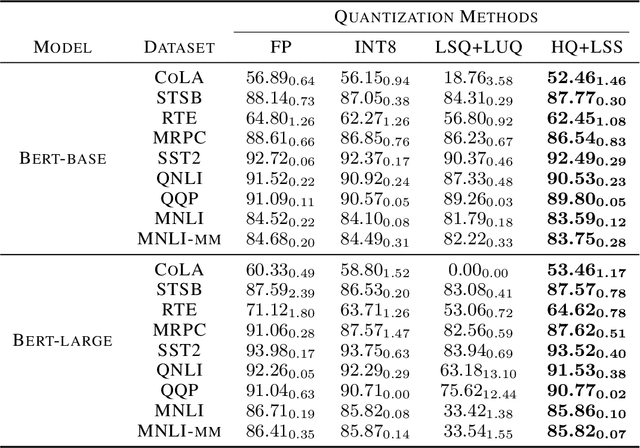
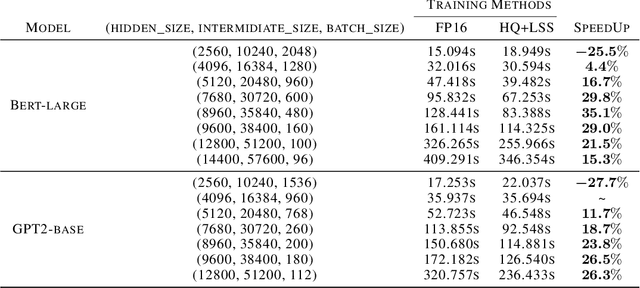
Quantizing the activation, weight, and gradient to 4-bit is promising to accelerate neural network training. However, existing 4-bit training methods require custom numerical formats which are not supported by contemporary hardware. In this work, we propose a training method for transformers with all matrix multiplications implemented with the INT4 arithmetic. Training with an ultra-low INT4 precision is challenging. To achieve this, we carefully analyze the specific structures of activation and gradients in transformers to propose dedicated quantizers for them. For forward propagation, we identify the challenge of outliers and propose a Hadamard quantizer to suppress the outliers. For backpropagation, we leverage the structural sparsity of gradients by proposing bit splitting and leverage score sampling techniques to quantize gradients accurately. Our algorithm achieves competitive accuracy on a wide range of tasks including natural language understanding, machine translation, and image classification. Unlike previous 4-bit training methods, our algorithm can be implemented on the current generation of GPUs. Our prototypical linear operator implementation is up to 2.2 times faster than the FP16 counterparts and speeds up the training by up to 35.1%.
Off-By-One Implementation Error in J-UNIWARD
May 31, 2023J-UNIWARD is a popular steganography method for hiding secret messages in JPEG cover images. As a content-adaptive method, J-UNIWARD aims to embed into textured image regions where changes are difficult to detect. To this end, J-UNIWARD first assigns to each DCT coefficient an embedding cost calculated based on the image's Wavelet residual, and then uses a coding method that minimizes the cost while embedding the desired payload. Changing one DCT coefficient affects a 23x23 window of Wavelet coefficients. To speed up the costmap computation, the original implementation pre-computes the Wavelet residual and then considers per changed DCT coefficient a 23x23 window of the Wavelet residual. However, the implementation accesses a window accidentally shifted by one pixel to the bottom right. In this report, we evaluate the effect of this off-by-one error on the resulting costmaps. Some image blocks are over-priced while other image blocks are under-priced, but the difference is relatively small. The off-by-one error seems to make little difference for learning-based steganalysis.
PanFlowNet: A Flow-Based Deep Network for Pan-sharpening
May 16, 2023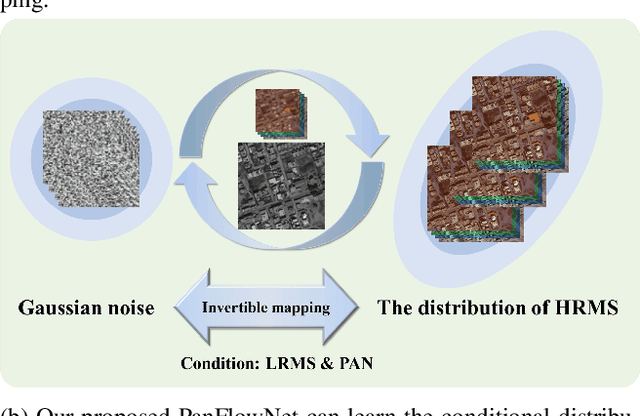
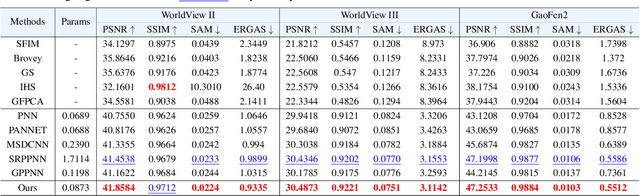
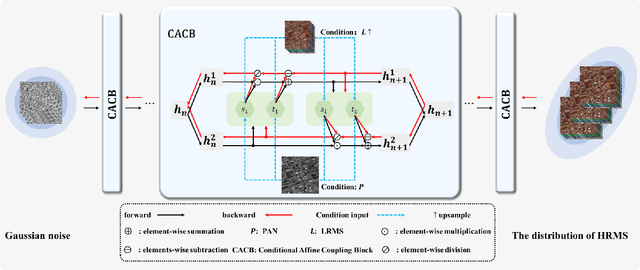
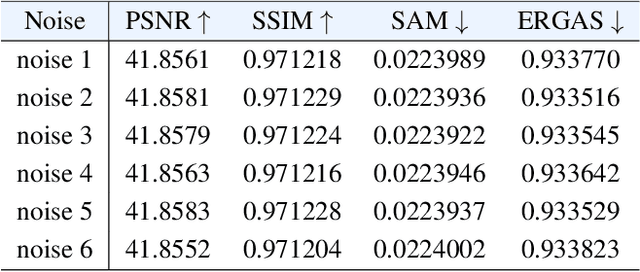
Pan-sharpening aims to generate a high-resolution multispectral (HRMS) image by integrating the spectral information of a low-resolution multispectral (LRMS) image with the texture details of a high-resolution panchromatic (PAN) image. It essentially inherits the ill-posed nature of the super-resolution (SR) task that diverse HRMS images can degrade into an LRMS image. However, existing deep learning-based methods recover only one HRMS image from the LRMS image and PAN image using a deterministic mapping, thus ignoring the diversity of the HRMS image. In this paper, to alleviate this ill-posed issue, we propose a flow-based pan-sharpening network (PanFlowNet) to directly learn the conditional distribution of HRMS image given LRMS image and PAN image instead of learning a deterministic mapping. Specifically, we first transform this unknown conditional distribution into a given Gaussian distribution by an invertible network, and the conditional distribution can thus be explicitly defined. Then, we design an invertible Conditional Affine Coupling Block (CACB) and further build the architecture of PanFlowNet by stacking a series of CACBs. Finally, the PanFlowNet is trained by maximizing the log-likelihood of the conditional distribution given a training set and can then be used to predict diverse HRMS images. The experimental results verify that the proposed PanFlowNet can generate various HRMS images given an LRMS image and a PAN image. Additionally, the experimental results on different kinds of satellite datasets also demonstrate the superiority of our PanFlowNet compared with other state-of-the-art methods both visually and quantitatively.
3D-aware Conditional Image Synthesis
Feb 16, 2023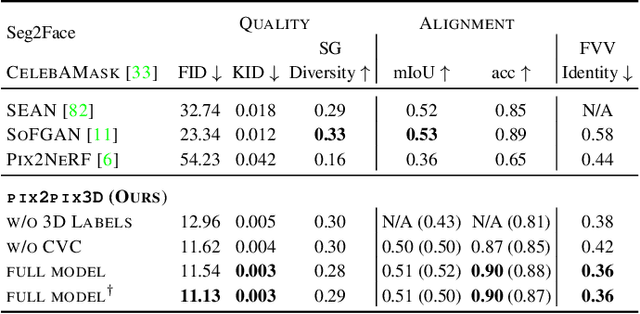
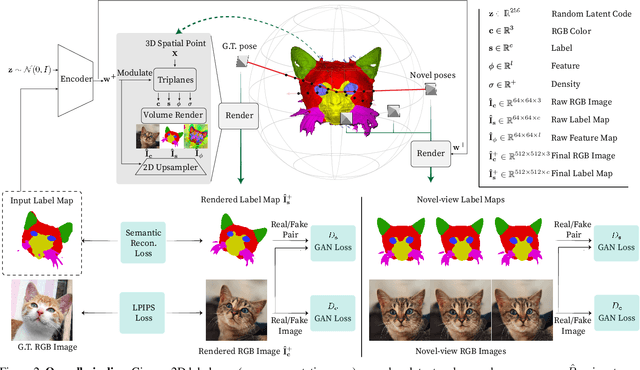
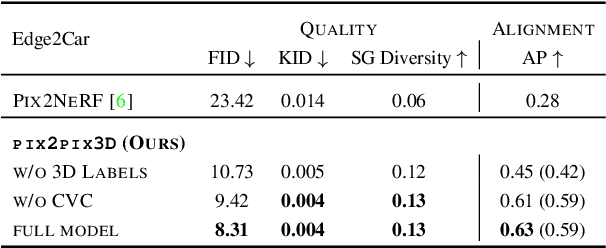
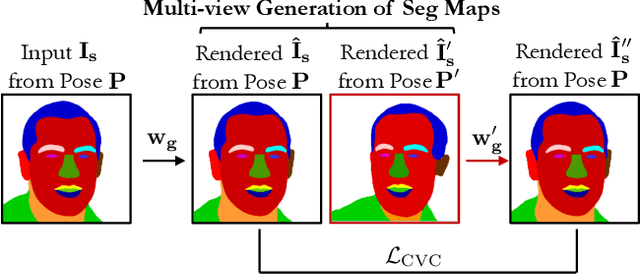
We propose pix2pix3D, a 3D-aware conditional generative model for controllable photorealistic image synthesis. Given a 2D label map, such as a segmentation or edge map, our model learns to synthesize a corresponding image from different viewpoints. To enable explicit 3D user control, we extend conditional generative models with neural radiance fields. Given widely-available monocular images and label map pairs, our model learns to assign a label to every 3D point in addition to color and density, which enables it to render the image and pixel-aligned label map simultaneously. Finally, we build an interactive system that allows users to edit the label map from any viewpoint and generate outputs accordingly.
Multi-view Cross-Modality MR Image Translation for Vestibular Schwannoma and Cochlea Segmentation
Mar 27, 2023In this work, we propose a multi-view image translation framework, which can translate contrast-enhanced T1 (ceT1) MR imaging to high-resolution T2 (hrT2) MR imaging for unsupervised vestibular schwannoma and cochlea segmentation. We adopt two image translation models in parallel that use a pixel-level consistent constraint and a patch-level contrastive constraint, respectively. Thereby, we can augment pseudo-hrT2 images reflecting different perspectives, which eventually lead to a high-performing segmentation model. Our experimental results on the CrossMoDA challenge show that the proposed method achieved enhanced performance on the vestibular schwannoma and cochlea segmentation.
TransMRSR: Transformer-based Self-Distilled Generative Prior for Brain MRI Super-Resolution
Jun 11, 2023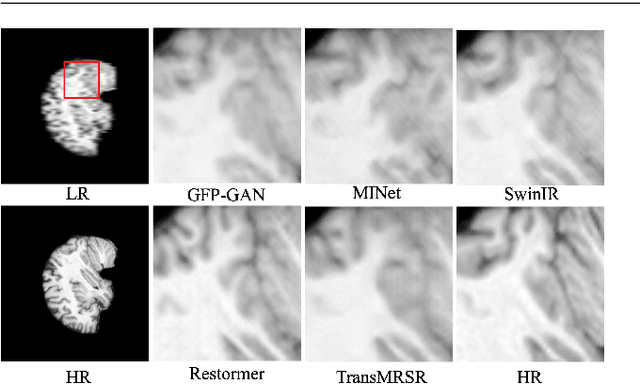
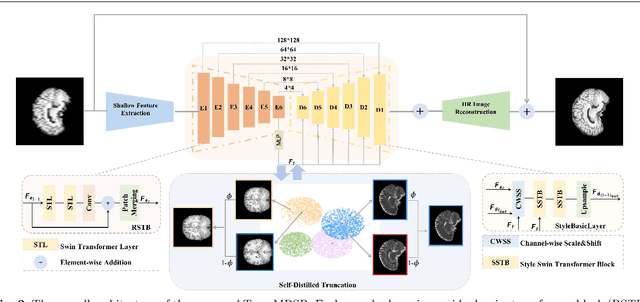
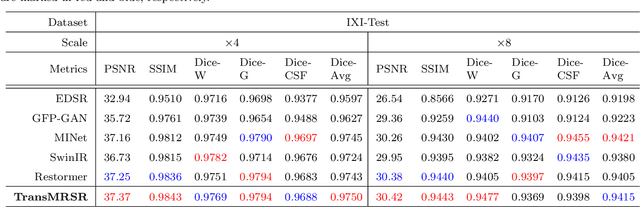
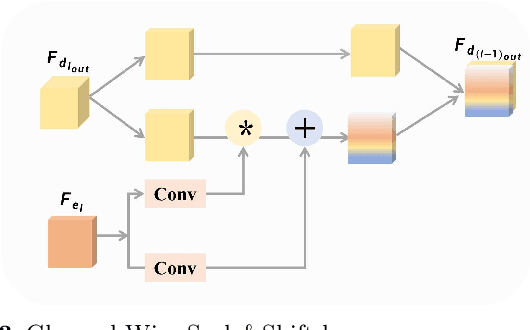
Magnetic resonance images (MRI) acquired with low through-plane resolution compromise time and cost. The poor resolution in one orientation is insufficient to meet the requirement of high resolution for early diagnosis of brain disease and morphometric study. The common Single image super-resolution (SISR) solutions face two main challenges: (1) local detailed and global anatomical structural information combination; and (2) large-scale restoration when applied for reconstructing thick-slice MRI into high-resolution (HR) iso-tropic data. To address these problems, we propose a novel two-stage network for brain MRI SR named TransMRSR based on the convolutional blocks to extract local information and transformer blocks to capture long-range dependencies. TransMRSR consists of three modules: the shallow local feature extraction, the deep non-local feature capture, and the HR image reconstruction. We perform a generative task to encapsulate diverse priors into a generative network (GAN), which is the decoder sub-module of the deep non-local feature capture part, in the first stage. The pre-trained GAN is used for the second stage of SR task. We further eliminate the potential latent space shift caused by the two-stage training strategy through the self-distilled truncation trick. The extensive experiments show that our method achieves superior performance to other SSIR methods on both public and private datasets. Code is released at https://github.com/goddesshs/TransMRSR.git .
GlueGen: Plug and Play Multi-modal Encoders for X-to-image Generation
Mar 17, 2023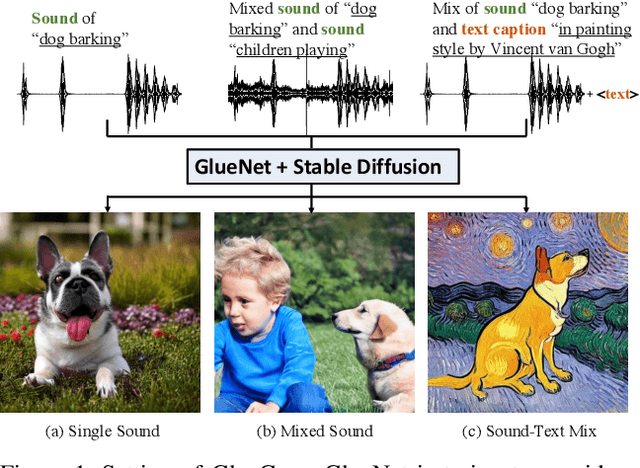
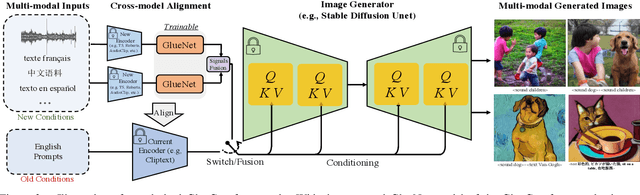

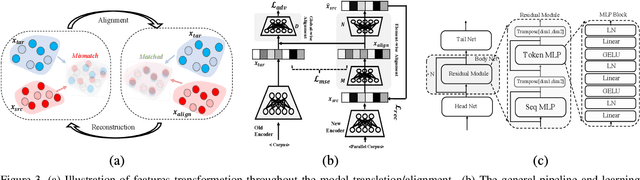
Text-to-image (T2I) models based on diffusion processes have achieved remarkable success in controllable image generation using user-provided captions. However, the tight coupling between the current text encoder and image decoder in T2I models makes it challenging to replace or upgrade. Such changes often require massive fine-tuning or even training from scratch with the prohibitive expense. To address this problem, we propose GlueGen, which applies a newly proposed GlueNet model to align features from single-modal or multi-modal encoders with the latent space of an existing T2I model. The approach introduces a new training objective that leverages parallel corpora to align the representation spaces of different encoders. Empirical results show that GlueNet can be trained efficiently and enables various capabilities beyond previous state-of-the-art models: 1) multilingual language models such as XLM-Roberta can be aligned with existing T2I models, allowing for the generation of high-quality images from captions beyond English; 2) GlueNet can align multi-modal encoders such as AudioCLIP with the Stable Diffusion model, enabling sound-to-image generation; 3) it can also upgrade the current text encoder of the latent diffusion model for challenging case generation. By the alignment of various feature representations, the GlueNet allows for flexible and efficient integration of new functionality into existing T2I models and sheds light on X-to-image (X2I) generation.
Automatically Predict Material Properties with Microscopic Image Example Polymer Compatibility
Mar 22, 2023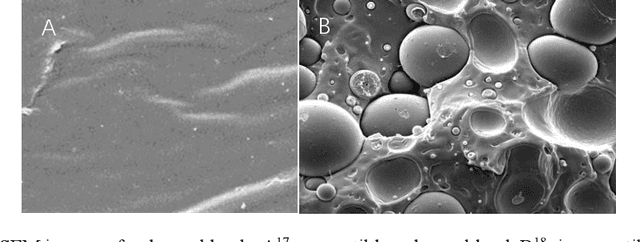
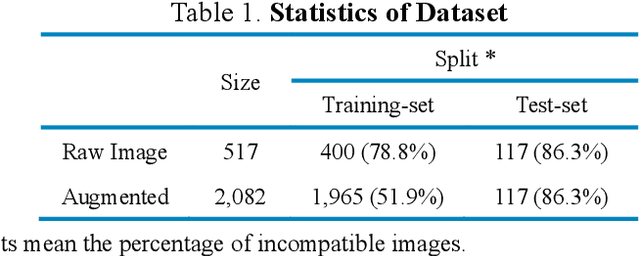
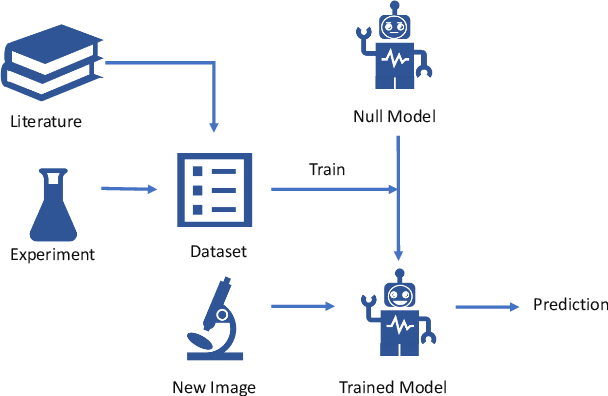
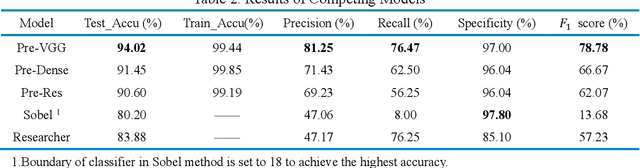
Many material properties are manifested in the morphological appearance and characterized with microscopic image, such as scanning electron microscopy (SEM). Polymer compatibility is a key physical quantity of polymer material and commonly and intuitively judged by SEM images. However, human observation and judgement for the images is time-consuming, labor-intensive and hard to be quantified. Computer image recognition with machine learning method can make up the defects of artificial judging, giving accurate and quantitative judgement. We achieve automatic compatibility recognition utilizing convolution neural network and transfer learning method, and the model obtains up to 94% accuracy. We also put forward a quantitative criterion for polymer compatibility with this model. The proposed method can be widely applied to the quantitative characterization of the microstructure and properties of various materials.