 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive Semantic-Enhanced Denoising Diffusion Probabilistic Model for Remote Sensing Image Super-Resolution
Mar 17, 2024
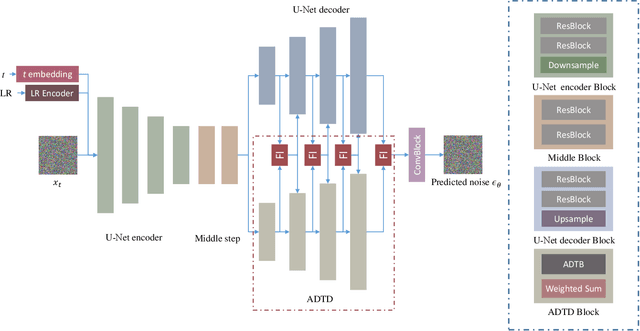
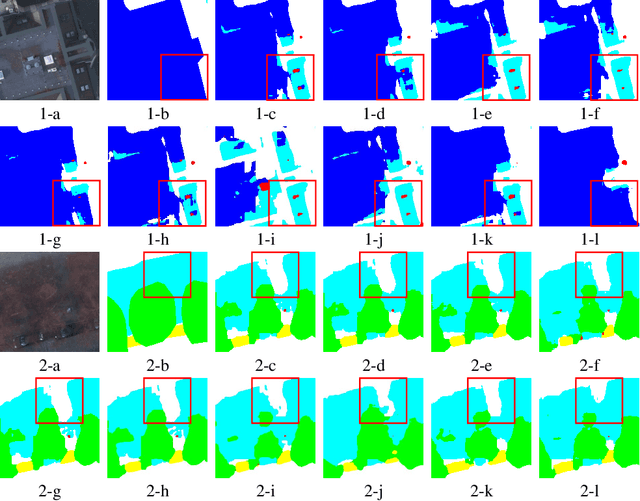
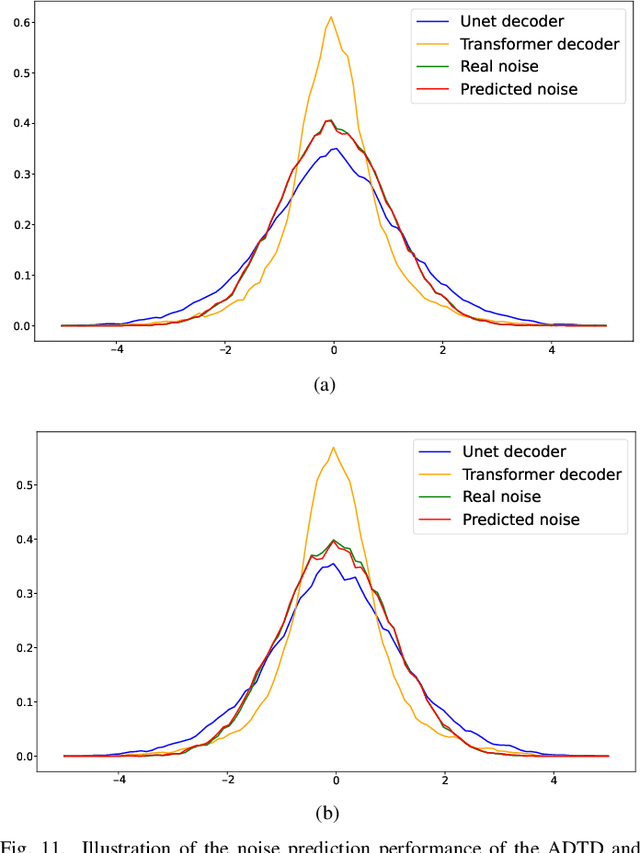
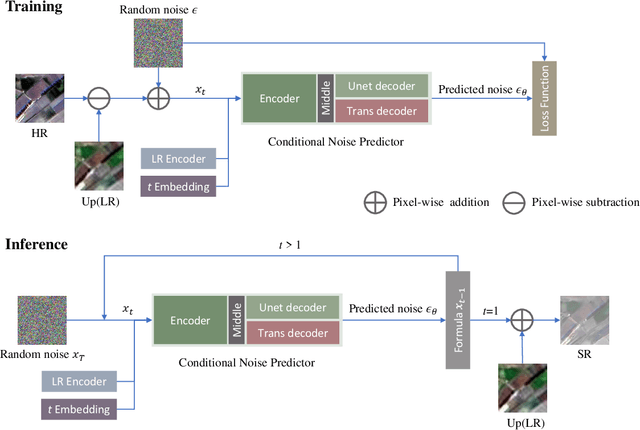
Remote sensing image super-resolution (SR) is a crucial task to restore high-resolution (HR) images from low-resolution (LR) observations. Recently, the Denoising Diffusion Probabilistic Model (DDPM) has shown promising performance in image reconstructions by overcoming problems inherent in generative models, such as over-smoothing and mode collapse. However, the high-frequency details generated by DDPM often suffer from misalignment with HR images due to the model's tendency to overlook long-range semantic contexts. This is attributed to the widely used U-Net decoder in the conditional noise predictor, which tends to overemphasize local information, leading to the generation of noises with significant variances during the prediction process. To address these issues, an adaptive semantic-enhanced DDPM (ASDDPM) is proposed to enhance the detail-preserving capability of the DDPM by incorporating low-frequency semantic information provided by the Transformer. Specifically, a novel adaptive diffusion Transformer decoder (ADTD) is developed to bridge the semantic gap between the encoder and decoder through regulating the noise prediction with the global contextual relationships and long-range dependencies in the diffusion process. Additionally, a residual feature fusion strategy establishes information exchange between the two decoders at multiple levels. As a result, the predicted noise generated by our approach closely approximates that of the real noise distribution.Extensive experiments on two SR and two semantic segmentation datasets confirm the superior performance of the proposed ASDDPM in both SR and the subsequent downstream applications. The source code will be available at https://github.com/littlebeen/ASDDPM-Adaptive-Semantic-Enhanced-DDPM.
Scalable Non-Cartesian Magnetic Resonance Imaging with R2D2
Mar 27, 2024We propose a new approach for non-Cartesian magnetic resonance image reconstruction. While unrolled architectures provide robustness via data-consistency layers, embedding measurement operators in Deep Neural Network (DNN) can become impractical at large scale. Alternative Plug-and-Play (PnP) approaches, where the denoising DNNs are blind to the measurement setting, are not affected by this limitation and have also proven effective, but their highly iterative nature also affects scalability. To address this scalability challenge, we leverage the "Residual-to-Residual DNN series for high-Dynamic range imaging (R2D2)" approach recently introduced in astronomical imaging. R2D2's reconstruction is formed as a series of residual images, iteratively estimated as outputs of DNNs taking the previous iteration's image estimate and associated data residual as inputs. The method can be interpreted as a learned version of the Matching Pursuit algorithm. We demonstrate R2D2 in simulation, considering radial k-space sampling acquisition sequences. Our preliminary results suggest that R2D2 achieves: (i) suboptimal performance compared to its unrolled incarnation R2D2-Net, which is however non-scalable due to the necessary embedding of NUFFT-based data-consistency layers; (ii) superior reconstruction quality to a scalable version of R2D2-Net embedding an FFT-based approximation for data consistency; (iii) superior reconstruction quality to PnP, while only requiring few iterations.
LUWA Dataset: Learning Lithic Use-Wear Analysis on Microscopic Images
Mar 27, 2024
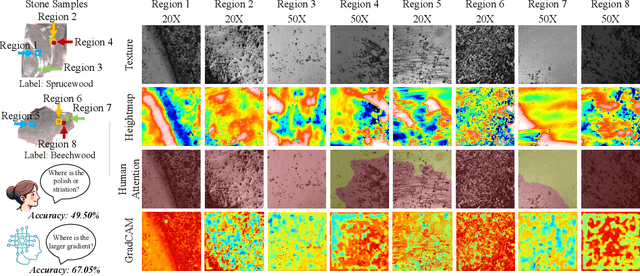
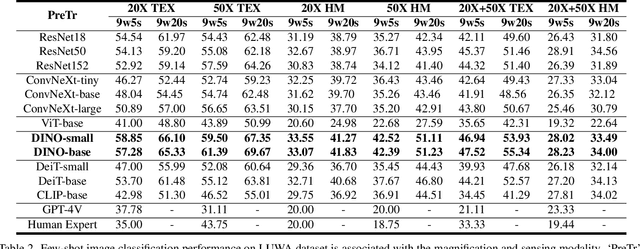
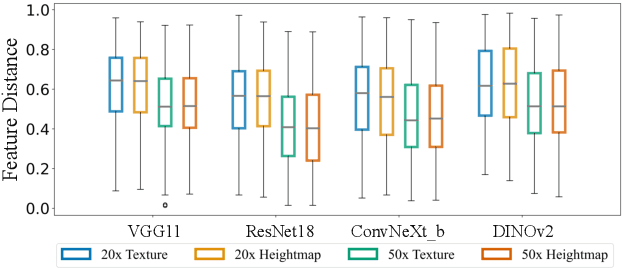
Lithic Use-Wear Analysis (LUWA) using microscopic images is an underexplored vision-for-science research area. It seeks to distinguish the worked material, which is critical for understanding archaeological artifacts, material interactions, tool functionalities, and dental records. However, this challenging task goes beyond the well-studied image classification problem for common objects. It is affected by many confounders owing to the complex wear mechanism and microscopic imaging, which makes it difficult even for human experts to identify the worked material successfully. In this paper, we investigate the following three questions on this unique vision task for the first time:(i) How well can state-of-the-art pre-trained models (like DINOv2) generalize to the rarely seen domain? (ii) How can few-shot learning be exploited for scarce microscopic images? (iii) How do the ambiguous magnification and sensing modality influence the classification accuracy? To study these, we collaborated with archaeologists and built the first open-source and the largest LUWA dataset containing 23,130 microscopic images with different magnifications and sensing modalities. Extensive experiments show that existing pre-trained models notably outperform human experts but still leave a large gap for improvements. Most importantly, the LUWA dataset provides an underexplored opportunity for vision and learning communities and complements existing image classification problems on common objects.
TGGLinesPlus: A robust topological graph-guided computer vision algorithm for line detection from images
Mar 26, 2024Line detection is a classic and essential problem in image processing, computer vision and machine intelligence. Line detection has many important applications, including image vectorization (e.g., document recognition and art design), indoor mapping, and important societal challenges (e.g., sea ice fracture line extraction from satellite imagery). Many line detection algorithms and methods have been developed, but robust and intuitive methods are still lacking. In this paper, we proposed and implemented a topological graph-guided algorithm, named TGGLinesPlus, for line detection. Our experiments on images from a wide range of domains have demonstrated the flexibility of our TGGLinesPlus algorithm. We also benchmarked our algorithm with five classic and state-of-the-art line detection methods and the results demonstrate the robustness of TGGLinesPlus. We hope our open-source implementation of TGGLinesPlus will inspire and pave the way for many applications where spatial science matters.
Semantically-Shifted Incremental Adapter-Tuning is A Continual ViTransformer
Mar 29, 2024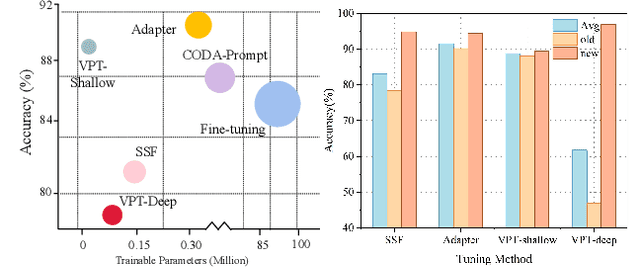
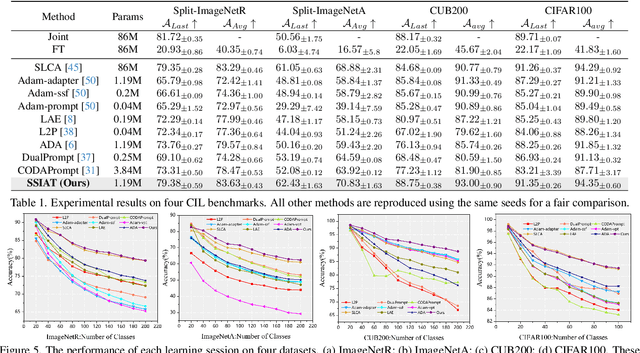
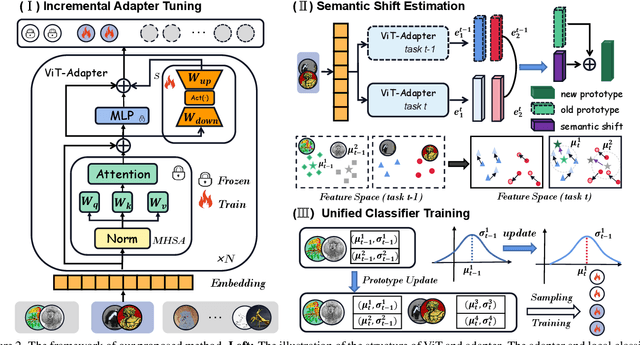
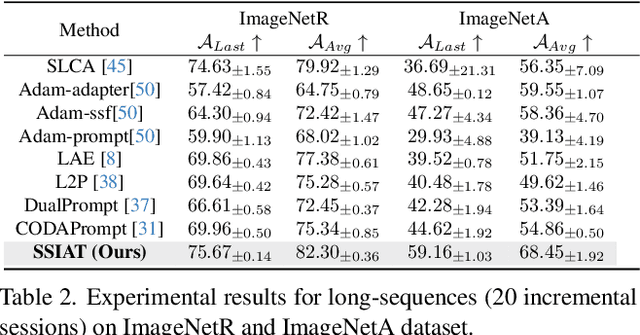
Class-incremental learning (CIL) aims to enable models to continuously learn new classes while overcoming catastrophic forgetting. The introduction of pre-trained models has brought new tuning paradigms to CIL. In this paper, we revisit different parameter-efficient tuning (PET) methods within the context of continual learning. We observe that adapter tuning demonstrates superiority over prompt-based methods, even without parameter expansion in each learning session. Motivated by this, we propose incrementally tuning the shared adapter without imposing parameter update constraints, enhancing the learning capacity of the backbone. Additionally, we employ feature sampling from stored prototypes to retrain a unified classifier, further improving its performance. We estimate the semantic shift of old prototypes without access to past samples and update stored prototypes session by session. Our proposed method eliminates model expansion and avoids retaining any image samples. It surpasses previous pre-trained model-based CIL methods and demonstrates remarkable continual learning capabilities. Experimental results on five CIL benchmarks validate the effectiveness of our approach, achieving state-of-the-art (SOTA) performance.
Gamba: Marry Gaussian Splatting with Mamba for single view 3D reconstruction
Mar 29, 2024We tackle the challenge of efficiently reconstructing a 3D asset from a single image with growing demands for automated 3D content creation pipelines. Previous methods primarily rely on Score Distillation Sampling (SDS) and Neural Radiance Fields (NeRF). Despite their significant success, these approaches encounter practical limitations due to lengthy optimization and considerable memory usage. In this report, we introduce Gamba, an end-to-end amortized 3D reconstruction model from single-view images, emphasizing two main insights: (1) 3D representation: leveraging a large number of 3D Gaussians for an efficient 3D Gaussian splatting process; (2) Backbone design: introducing a Mamba-based sequential network that facilitates context-dependent reasoning and linear scalability with the sequence (token) length, accommodating a substantial number of Gaussians. Gamba incorporates significant advancements in data preprocessing, regularization design, and training methodologies. We assessed Gamba against existing optimization-based and feed-forward 3D generation approaches using the real-world scanned OmniObject3D dataset. Here, Gamba demonstrates competitive generation capabilities, both qualitatively and quantitatively, while achieving remarkable speed, approximately 0.6 second on a single NVIDIA A100 GPU.
Heterogeneous Image-based Classification Using Distributional Data Analysis
Mar 11, 2024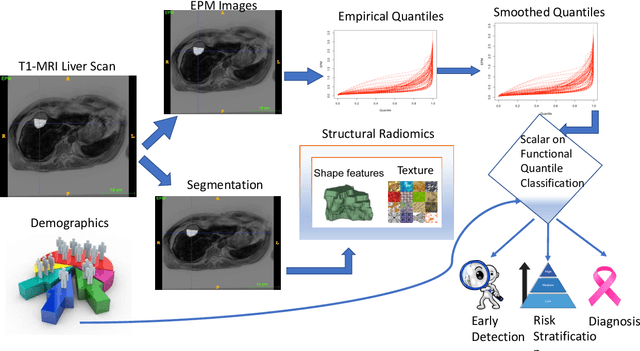
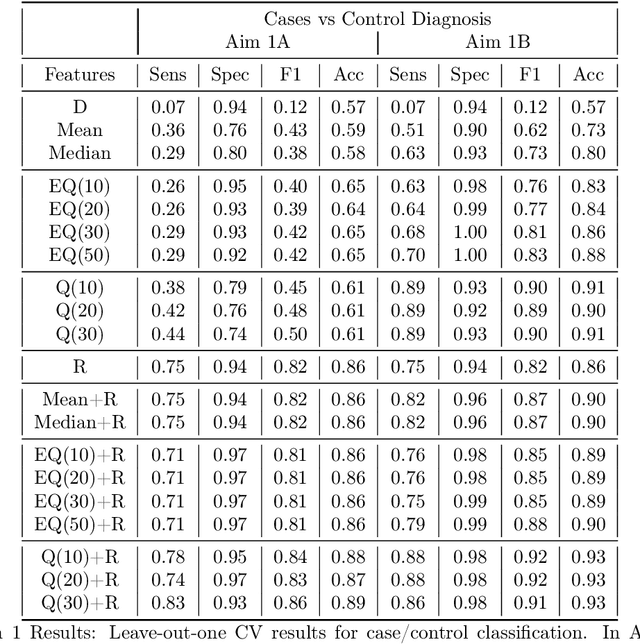
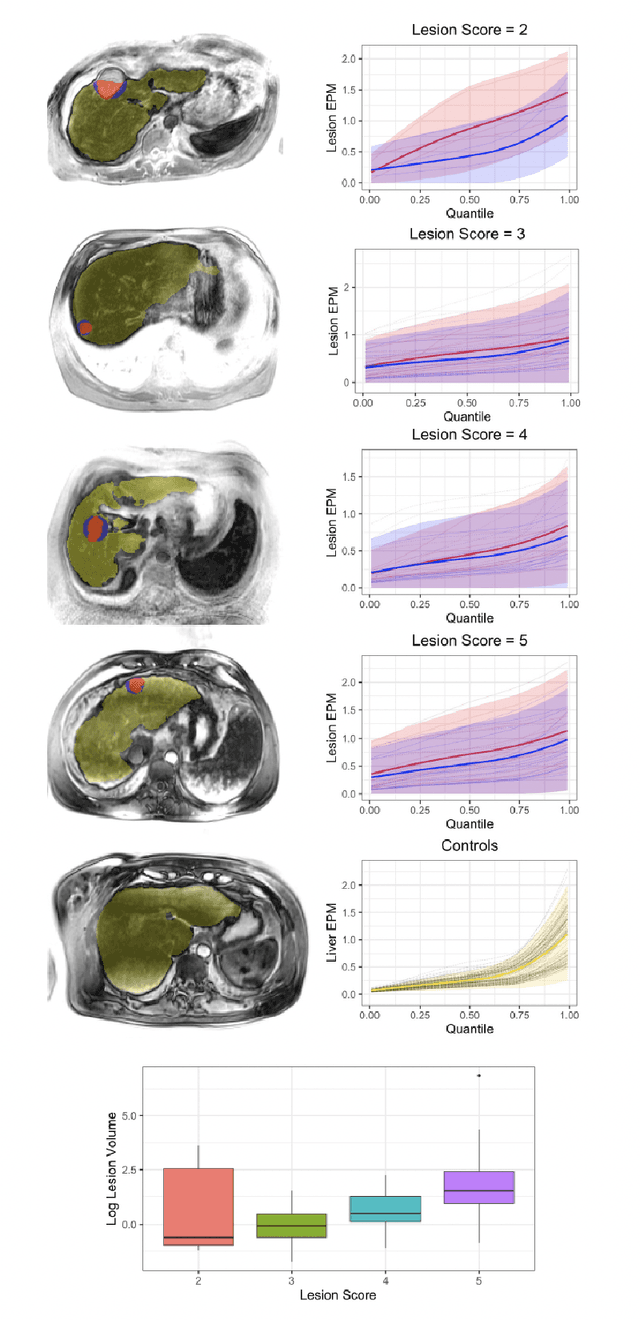
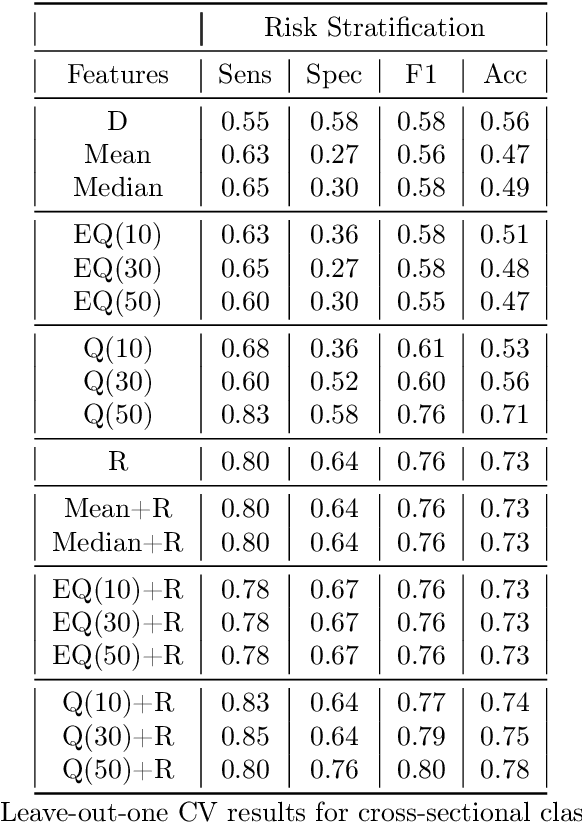
Diagnostic imaging has gained prominence as potential biomarkers for early detection and diagnosis in a diverse array of disorders including cancer. However, existing methods routinely face challenges arising from various factors such as image heterogeneity. We develop a novel imaging-based distributional data analysis (DDA) approach that incorporates the probability (quantile) distribution of the pixel-level features as covariates. The proposed approach uses a smoothed quantile distribution (via a suitable basis representation) as functional predictors in a scalar-on-functional quantile regression model. Some distinctive features of the proposed approach include the ability to: (i) account for heterogeneity within the image; (ii) incorporate granular information spanning the entire distribution; and (iii) tackle variability in image sizes for unregistered images in cancer applications. Our primary goal is risk prediction in Hepatocellular carcinoma that is achieved via predicting the change in tumor grades at post-diagnostic visits using pre-diagnostic enhancement pattern mapping (EPM) images of the liver. Along the way, the proposed DDA approach is also used for case versus control diagnosis and risk stratification objectives. Our analysis reveals that when coupled with global structural radiomics features derived from the corresponding T1-MRI scans, the proposed smoothed quantile distributions derived from EPM images showed considerable improvements in sensitivity and comparable specificity in contrast to classification based on routinely used summary measures that do not account for image heterogeneity. Given that there are limited predictive modeling approaches based on heterogeneous images in cancer, the proposed method is expected to provide considerable advantages in image-based early detection and risk prediction.
EAGLE: An Edge-Aware Gradient Localization Enhanced Loss for CT Image Reconstruction
Mar 15, 2024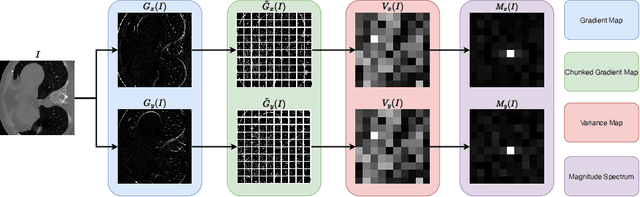
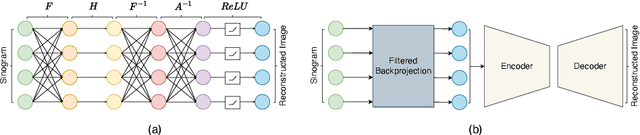
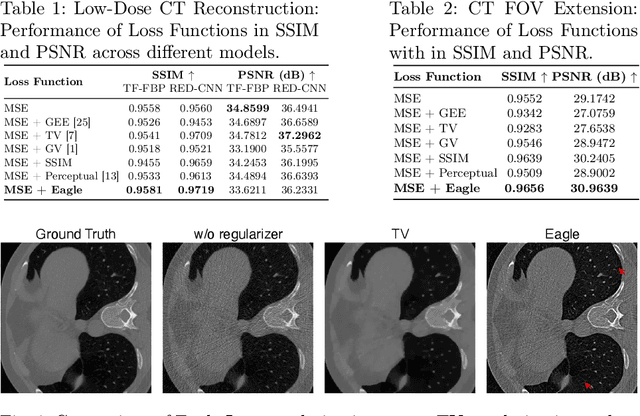

Computed Tomography (CT) image reconstruction is crucial for accurate diagnosis and deep learning approaches have demonstrated significant potential in improving reconstruction quality. However, the choice of loss function profoundly affects the reconstructed images. Traditional mean squared error loss often produces blurry images lacking fine details, while alternatives designed to improve may introduce structural artifacts or other undesirable effects. To address these limitations, we propose Eagle-Loss, a novel loss function designed to enhance the visual quality of CT image reconstructions. Eagle-Loss applies spectral analysis of localized features within gradient changes to enhance sharpness and well-defined edges. We evaluated Eagle-Loss on two public datasets across low-dose CT reconstruction and CT field-of-view extension tasks. Our results show that Eagle-Loss consistently improves the visual quality of reconstructed images, surpassing state-of-the-art methods across various network architectures. Code and data are available at \url{https://github.com/sypsyp97/Eagle_Loss}.
Frozen Feature Augmentation for Few-Shot Image Classification
Mar 15, 2024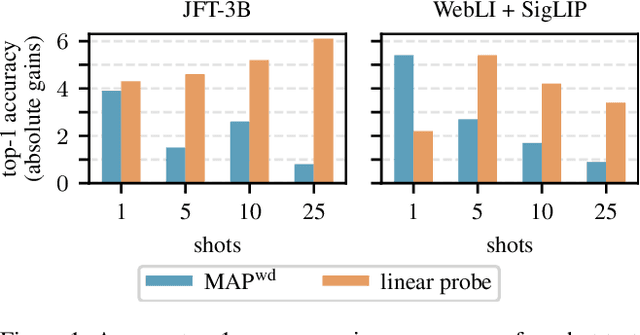
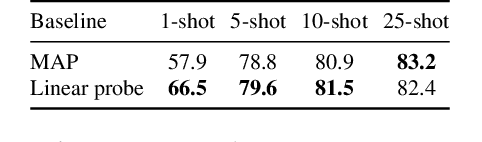
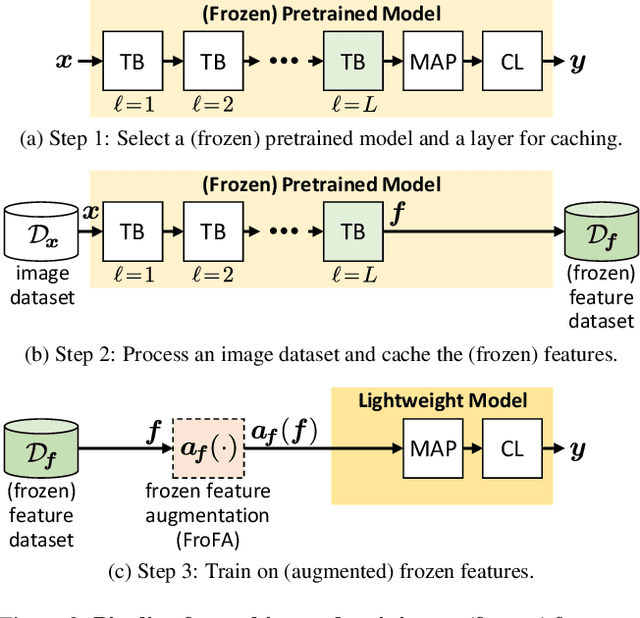
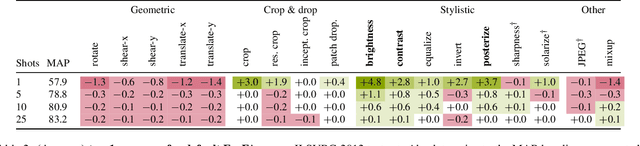
Training a linear classifier or lightweight model on top of pretrained vision model outputs, so-called 'frozen features', leads to impressive performance on a number of downstream few-shot tasks. Currently, frozen features are not modified during training. On the other hand, when networks are trained directly on images, data augmentation is a standard recipe that improves performance with no substantial overhead. In this paper, we conduct an extensive pilot study on few-shot image classification that explores applying data augmentations in the frozen feature space, dubbed 'frozen feature augmentation (FroFA)', covering twenty augmentations in total. Our study demonstrates that adopting a deceptively simple pointwise FroFA, such as brightness, can improve few-shot performance consistently across three network architectures, three large pretraining datasets, and eight transfer datasets.
Iterative Online Image Synthesis via Diffusion Model for Imbalanced Classification
Mar 13, 2024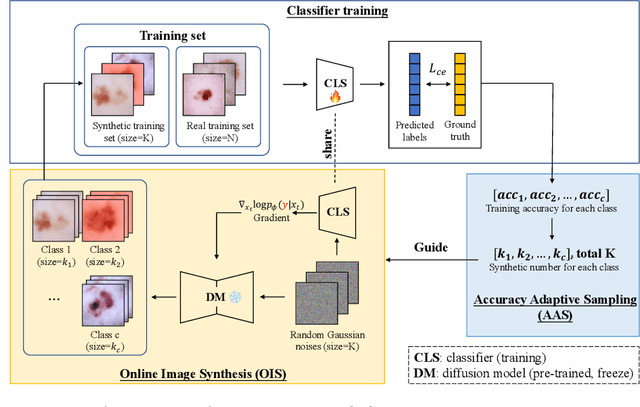
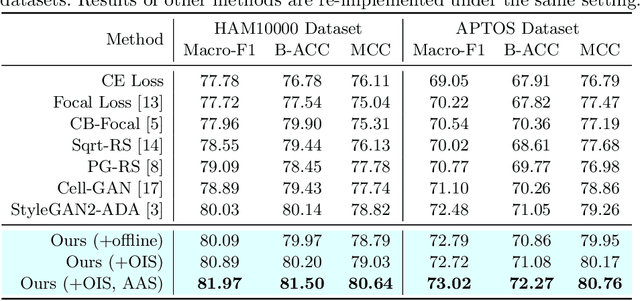
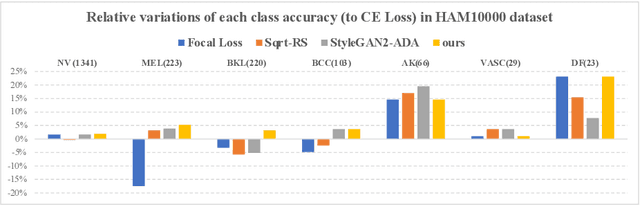

Accurate and robust classification of diseases is important for proper diagnosis and treatment. However, medical datasets often face challenges related to limited sample sizes and inherent imbalanced distributions, due to difficulties in data collection and variations in disease prevalence across different types. In this paper, we introduce an Iterative Online Image Synthesis (IOIS) framework to address the class imbalance problem in medical image classification. Our framework incorporates two key modules, namely Online Image Synthesis (OIS) and Accuracy Adaptive Sampling (AAS), which collectively target the imbalance classification issue at both the instance level and the class level. The OIS module alleviates the data insufficiency problem by generating representative samples tailored for online training of the classifier. On the other hand, the AAS module dynamically balances the synthesized samples among various classes, targeting those with low training accuracy. To evaluate the effectiveness of our proposed method in addressing imbalanced classification, we conduct experiments on the HAM10000 and APTOS datasets. The results obtained demonstrate the superiority of our approach over state-of-the-art methods as well as the effectiveness of each component. The source code will be released upon acceptance.