 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DreamSparse: Escaping from Plato's Cave with 2D Diffusion Model Given Sparse Views
Jun 08, 2023

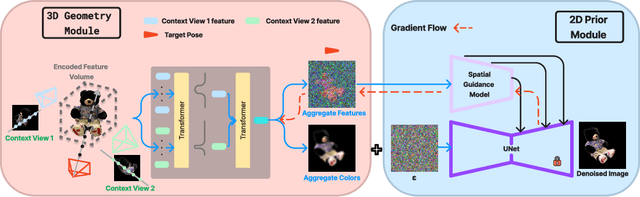


Synthesizing novel view images from a few views is a challenging but practical problem. Existing methods often struggle with producing high-quality results or necessitate per-object optimization in such few-view settings due to the insufficient information provided. In this work, we explore leveraging the strong 2D priors in pre-trained diffusion models for synthesizing novel view images. 2D diffusion models, nevertheless, lack 3D awareness, leading to distorted image synthesis and compromising the identity. To address these problems, we propose DreamSparse, a framework that enables the frozen pre-trained diffusion model to generate geometry and identity-consistent novel view image. Specifically, DreamSparse incorporates a geometry module designed to capture 3D features from sparse views as a 3D prior. Subsequently, a spatial guidance model is introduced to convert these 3D feature maps into spatial information for the generative process. This information is then used to guide the pre-trained diffusion model, enabling it to generate geometrically consistent images without tuning it. Leveraging the strong image priors in the pre-trained diffusion models, DreamSparse is capable of synthesizing high-quality novel views for both object and scene-level images and generalising to open-set images. Experimental results demonstrate that our framework can effectively synthesize novel view images from sparse views and outperforms baselines in both trained and open-set category images. More results can be found on our project page: https://sites.google.com/view/dreamsparse-webpage.
Device Image-IV Mapping using Variational Autoencoder for Inverse Design and Forward Prediction
Apr 03, 2023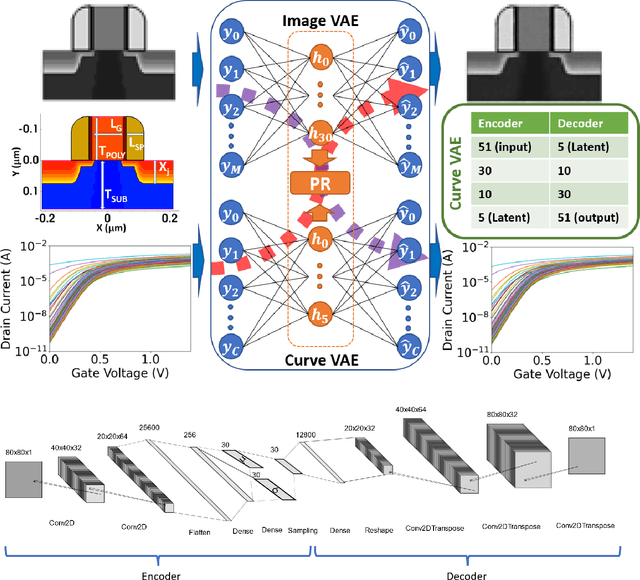
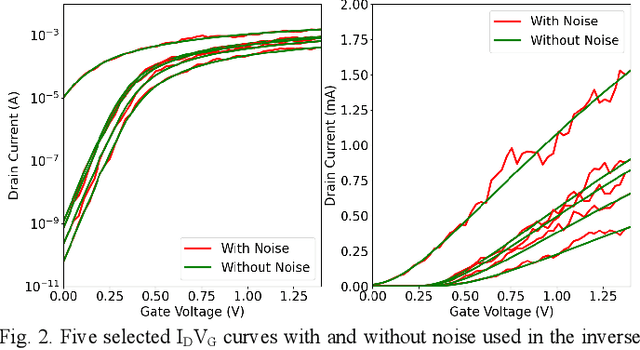
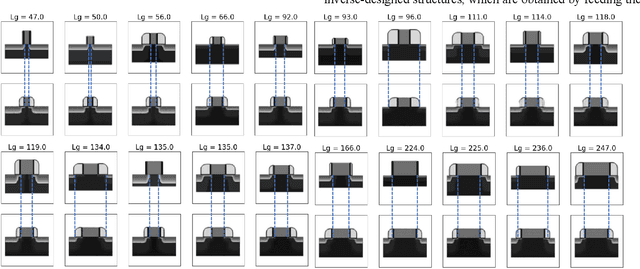
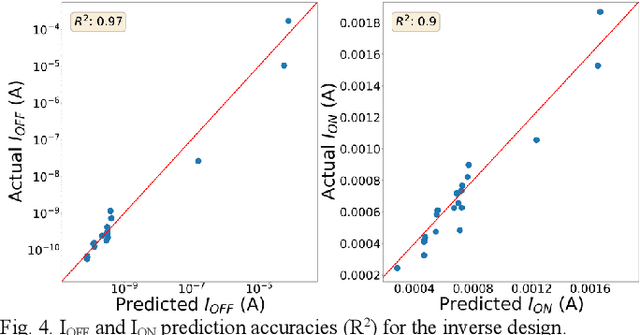
This paper demonstrates the learning of the underlying device physics by mapping device structure images to their corresponding Current-Voltage (IV) characteristics using a novel framework based on variational autoencoders (VAE). Since VAE is used, domain expertise is not required and the framework can be quickly deployed on any new device and measurement. This is expected to be useful in the compact modeling of novel devices when only device cross-sectional images and electrical characteristics are available (e.g. novel emerging memory). Technology Computer-Aided Design (TCAD) generated and hand-drawn Metal-Oxide-Semiconductor (MOS) device images and noisy drain-current-gate-voltage curves (IDVG) are used for the demonstration. The framework is formed by stacking two VAEs (one for image manifold learning and one for IDVG manifold learning) which communicate with each other through the latent variables. Five independent variables with different strengths are used. It is shown that it can perform inverse design (generate a design structure for a given IDVG) and forward prediction (predict IDVG for a given structure image, which can be used for compact modeling if the image is treated as device parameters) successfully. Since manifold learning is used, the machine is shown to be robust against noise in the inputs (i.e. using hand-drawn images and noisy IDVG curves) and not confused by weak and irrelevant independent variables.
Self-Supervised Image Denoising for Real-World Images with Context-aware Transformer
Apr 04, 2023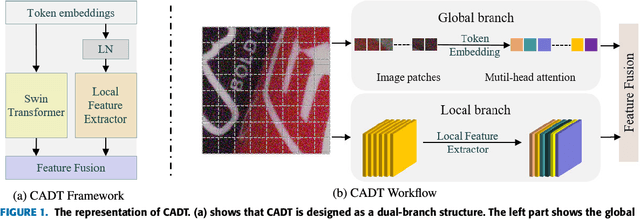

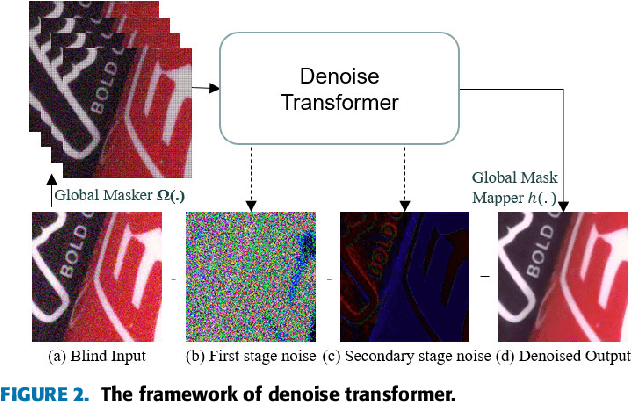
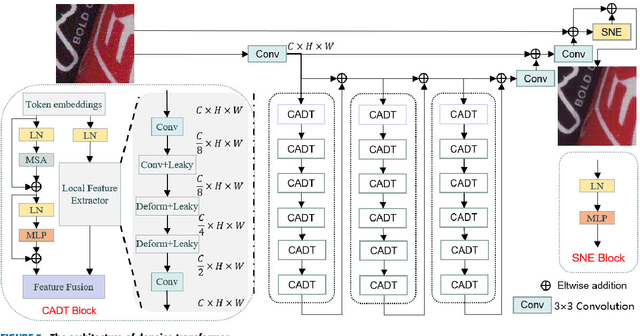
In recent years, the development of deep learning has been pushing image denoising to a new level. Among them, self-supervised denoising is increasingly popular because it does not require any prior knowledge. Most of the existing self-supervised methods are based on convolutional neural networks (CNN), which are restricted by the locality of the receptive field and would cause color shifts or textures loss. In this paper, we propose a novel Denoise Transformer for real-world image denoising, which is mainly constructed with Context-aware Denoise Transformer (CADT) units and Secondary Noise Extractor (SNE) block. CADT is designed as a dual-branch structure, where the global branch uses a window-based Transformer encoder to extract the global information, while the local branch focuses on the extraction of local features with small receptive field. By incorporating CADT as basic components, we build a hierarchical network to directly learn the noise distribution information through residual learning and obtain the first stage denoised output. Then, we design SNE in low computation for secondary global noise extraction. Finally the blind spots are collected from the Denoise Transformer output and reconstructed, forming the final denoised image. Extensive experiments on the real-world SIDD benchmark achieve 50.62/0.990 for PSNR/SSIM, which is competitive with the current state-of-the-art method and only 0.17/0.001 lower. Visual comparisons on public sRGB, Raw-RGB and greyscale datasets prove that our proposed Denoise Transformer has a competitive performance, especially on blurred textures and low-light images, without using additional knowledge, e.g., noise level or noise type, regarding the underlying unknown noise.
* 10 pages, 9 figures
Contrastive Semi-supervised Learning for Underwater Image Restoration via Reliable Bank
Apr 04, 2023
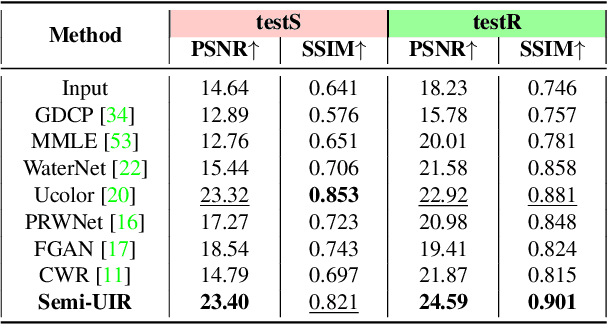
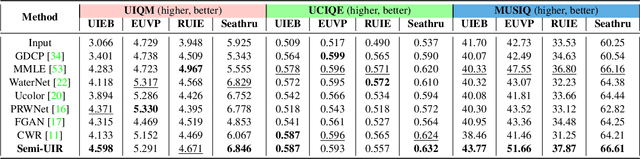
Despite the remarkable achievement of recent underwater image restoration techniques, the lack of labeled data has become a major hurdle for further progress. In this work, we propose a mean-teacher based Semi-supervised Underwater Image Restoration (Semi-UIR) framework to incorporate the unlabeled data into network training. However, the naive mean-teacher method suffers from two main problems: (1) The consistency loss used in training might become ineffective when the teacher's prediction is wrong. (2) Using L1 distance may cause the network to overfit wrong labels, resulting in confirmation bias. To address the above problems, we first introduce a reliable bank to store the "best-ever" outputs as pseudo ground truth. To assess the quality of outputs, we conduct an empirical analysis based on the monotonicity property to select the most trustworthy NR-IQA method. Besides, in view of the confirmation bias problem, we incorporate contrastive regularization to prevent the overfitting on wrong labels. Experimental results on both full-reference and non-reference underwater benchmarks demonstrate that our algorithm has obvious improvement over SOTA methods quantitatively and qualitatively. Code has been released at https://github.com/Huang-ShiRui/Semi-UIR.
CLIMAX: An exploration of Classifier-Based Contrastive Explanations
Jul 02, 2023
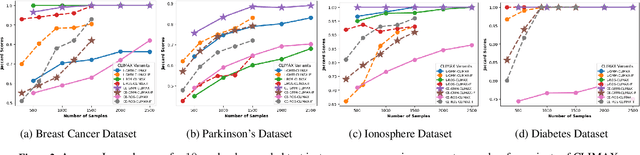
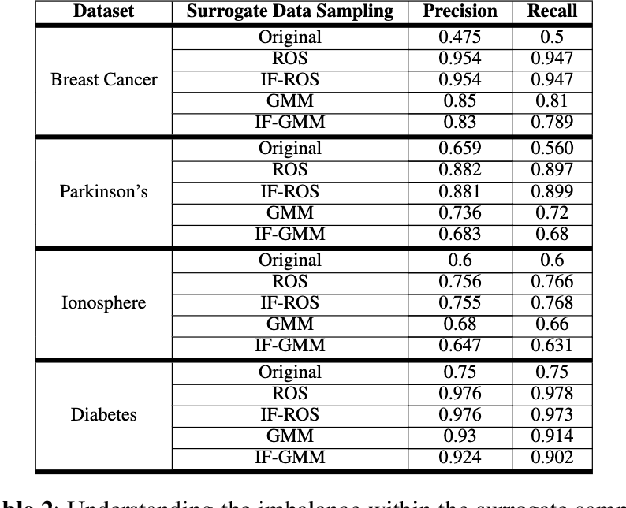
Explainable AI is an evolving area that deals with understanding the decision making of machine learning models so that these models are more transparent, accountable, and understandable for humans. In particular, post-hoc model-agnostic interpretable AI techniques explain the decisions of a black-box ML model for a single instance locally, without the knowledge of the intrinsic nature of the ML model. Despite their simplicity and capability in providing valuable insights, existing approaches fail to deliver consistent and reliable explanations. Moreover, in the context of black-box classifiers, existing approaches justify the predicted class, but these methods do not ensure that the explanation scores strongly differ as compared to those of another class. In this work we propose a novel post-hoc model agnostic XAI technique that provides contrastive explanations justifying the classification of a black box classifier along with a reasoning as to why another class was not predicted. Our method, which we refer to as CLIMAX which is short for Contrastive Label-aware Influence-based Model Agnostic XAI, is based on local classifiers . In order to ensure model fidelity of the explainer, we require the perturbations to be such that it leads to a class-balanced surrogate dataset. Towards this, we employ a label-aware surrogate data generation method based on random oversampling and Gaussian Mixture Model sampling. Further, we propose influence subsampling in order to retaining effective samples and hence ensure sample complexity. We show that we achieve better consistency as compared to baselines such as LIME, BayLIME, and SLIME. We also depict results on textual and image based datasets, where we generate contrastive explanations for any black-box classification model where one is able to only query the class probabilities for an instance of interest.
MindDiffuser: Controlled Image Reconstruction from Human Brain Activity with Semantic and Structural Diffusion
Mar 24, 2023

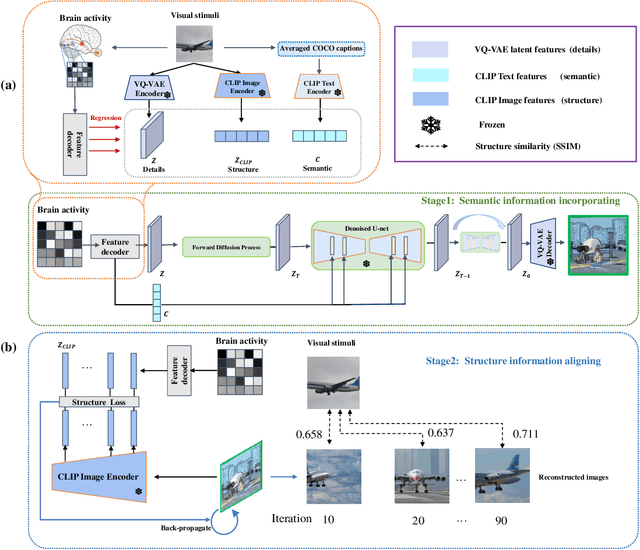
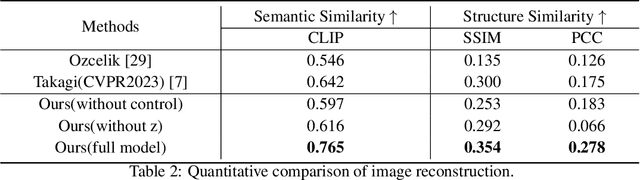
Reconstructing visual stimuli from measured functional magnetic resonance imaging (fMRI) has been a meaningful and challenging task. Previous studies have successfully achieved reconstructions with structures similar to the original images, such as the outlines and size of some natural images. However, these reconstructions lack explicit semantic information and are difficult to discern. In recent years, many studies have utilized multi-modal pre-trained models with stronger generative capabilities to reconstruct images that are semantically similar to the original ones. However, these images have uncontrollable structural information such as position and orientation. To address both of the aforementioned issues simultaneously, we propose a two-stage image reconstruction model called MindDiffuser, utilizing Stable Diffusion. In Stage 1, the VQ-VAE latent representations and the CLIP text embeddings decoded from fMRI are put into the image-to-image process of Stable Diffusion, which yields a preliminary image that contains semantic and structural information. In Stage 2, we utilize the low-level CLIP visual features decoded from fMRI as supervisory information, and continually adjust the two features in Stage 1 through backpropagation to align the structural information. The results of both qualitative and quantitative analyses demonstrate that our proposed model has surpassed the current state-of-the-art models in terms of reconstruction results on Natural Scenes Dataset (NSD). Furthermore, the results of ablation experiments indicate that each component of our model is effective for image reconstruction.
Approximated Prompt Tuning for Vision-Language Pre-trained Models
Jun 27, 2023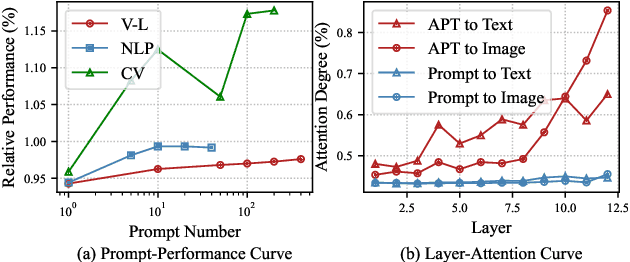
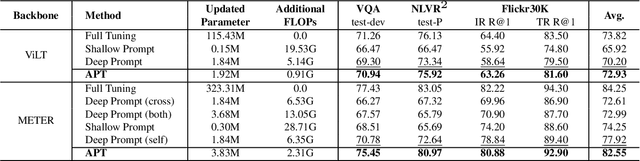
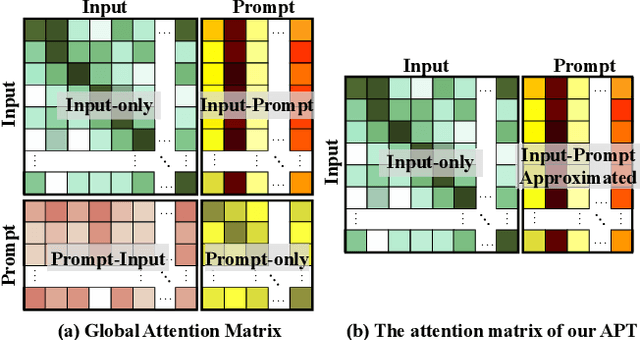
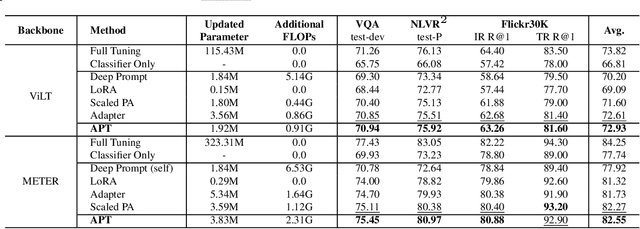
Prompt tuning is a parameter-efficient way to deploy large-scale pre-trained models to downstream tasks by adding task-specific tokens. In terms of vision-language pre-trained (VLP) models, prompt tuning often requires a large number of learnable tokens to bridge the gap between the pre-training and downstream tasks, which greatly exacerbates the already high computational overhead. In this paper, we revisit the principle of prompt tuning for Transformer-based VLP models and reveal that the impact of soft prompt tokens can be actually approximated via independent information diffusion steps, thereby avoiding the expensive global attention modeling and reducing the computational complexity to a large extent. Based on this finding, we propose a novel Approximated Prompt Tuning (APT) approach towards efficient VL transfer learning. To validate APT, we apply it to two representative VLP models, namely ViLT and METER, and conduct extensive experiments on a bunch of downstream tasks. Meanwhile, the generalization of APT is also validated on CLIP for image classification. The experimental results not only show the superior performance gains and computation efficiency of APT against the conventional prompt tuning methods, e.g., +6.6% accuracy and -64.62% additional computation overhead on METER, but also confirm its merits over other parameter-efficient transfer learning approaches.
CellViT: Vision Transformers for Precise Cell Segmentation and Classification
Jun 27, 2023Nuclei detection and segmentation in hematoxylin and eosin-stained (H&E) tissue images are important clinical tasks and crucial for a wide range of applications. However, it is a challenging task due to nuclei variances in staining and size, overlapping boundaries, and nuclei clustering. While convolutional neural networks have been extensively used for this task, we explore the potential of Transformer-based networks in this domain. Therefore, we introduce a new method for automated instance segmentation of cell nuclei in digitized tissue samples using a deep learning architecture based on Vision Transformer called CellViT. CellViT is trained and evaluated on the PanNuke dataset, which is one of the most challenging nuclei instance segmentation datasets, consisting of nearly 200,000 annotated Nuclei into 5 clinically important classes in 19 tissue types. We demonstrate the superiority of large-scale in-domain and out-of-domain pre-trained Vision Transformers by leveraging the recently published Segment Anything Model and a ViT-encoder pre-trained on 104 million histological image patches - achieving state-of-the-art nuclei detection and instance segmentation performance on the PanNuke dataset with a mean panoptic quality of 0.51 and an F1-detection score of 0.83. The code is publicly available at https://github.com/TIO-IKIM/CellViT
OTRE: Where Optimal Transport Guided Unpaired Image-to-Image Translation Meets Regularization by Enhancing
Feb 09, 2023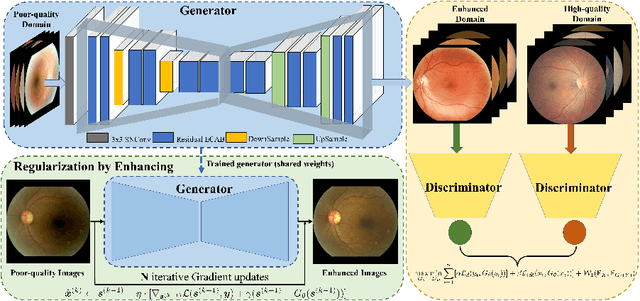
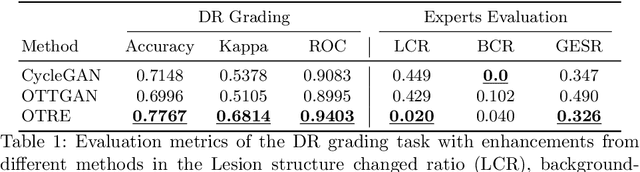
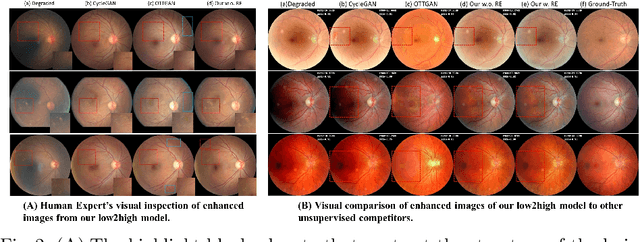
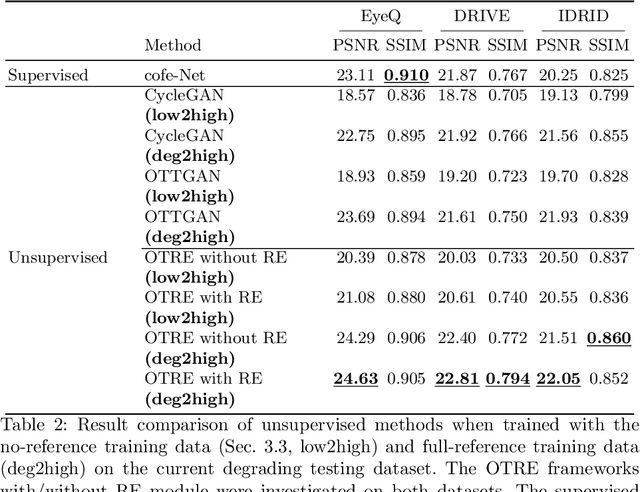
Non-mydriatic retinal color fundus photography (CFP) is widely available due to the advantage of not requiring pupillary dilation, however, is prone to poor quality due to operators, systemic imperfections, or patient-related causes. Optimal retinal image quality is mandated for accurate medical diagnoses and automated analyses. Herein, we leveraged the Optimal Transport (OT) theory to propose an unpaired image-to-image translation scheme for mapping low-quality retinal CFPs to high-quality counterparts. Furthermore, to improve the flexibility, robustness, and applicability of our image enhancement pipeline in the clinical practice, we generalized a state-of-the-art model-based image reconstruction method, regularization by denoising, by plugging in priors learned by our OT-guided image-to-image translation network. We named it as regularization by enhancing (RE). We validated the integrated framework, OTRE, on three publicly available retinal image datasets by assessing the quality after enhancement and their performance on various downstream tasks, including diabetic retinopathy grading, vessel segmentation, and diabetic lesion segmentation. The experimental results demonstrated the superiority of our proposed framework over some state-of-the-art unsupervised competitors and a state-of-the-art supervised method.
DreamEditor: Text-Driven 3D Scene Editing with Neural Fields
Jun 23, 2023
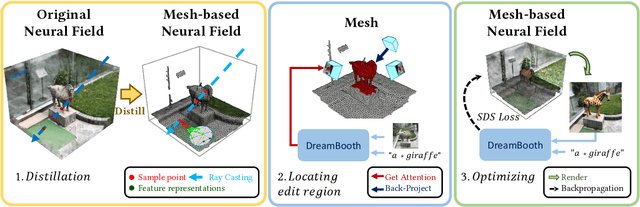

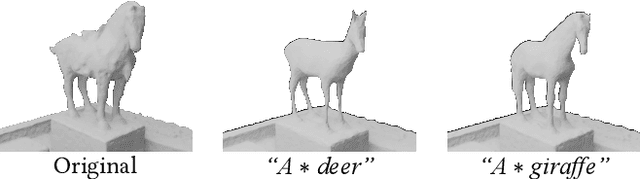
Neural fields have achieved impressive advancements in view synthesis and scene reconstruction. However, editing these neural fields remains challenging due to the implicit encoding of geometry and texture information. In this paper, we propose DreamEditor, a novel framework that enables users to perform controlled editing of neural fields using text prompts. By representing scenes as mesh-based neural fields, DreamEditor allows localized editing within specific regions. DreamEditor utilizes the text encoder of a pretrained text-to-Image diffusion model to automatically identify the regions to be edited based on the semantics of the text prompts. Subsequently, DreamEditor optimizes the editing region and aligns its geometry and texture with the text prompts through score distillation sampling [29]. Extensive experiments have demonstrated that DreamEditor can accurately edit neural fields of real-world scenes according to the given text prompts while ensuring consistency in irrelevant areas. DreamEditor generates highly realistic textures and geometry, significantly surpassing previous works in both quantitative and qualitative evaluations.