 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RADiff: Controllable Diffusion Models for Radio Astronomical Maps Generation
Jul 05, 2023
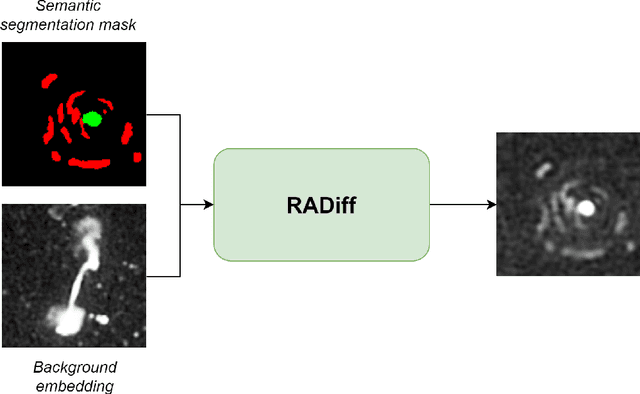
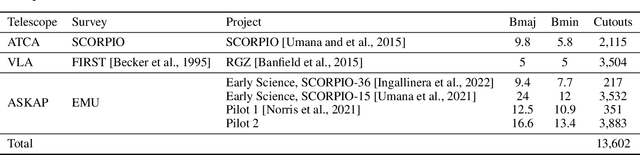
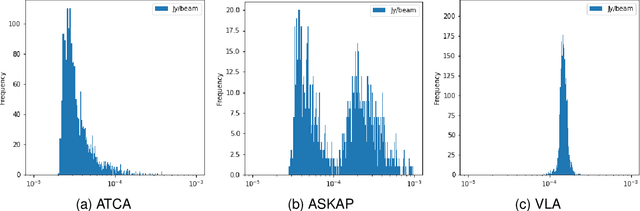
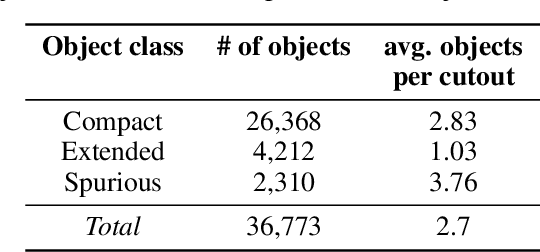
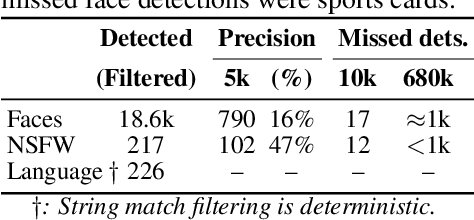
Along with the nearing completion of the Square Kilometre Array (SKA), comes an increasing demand for accurate and reliable automated solutions to extract valuable information from the vast amount of data it will allow acquiring. Automated source finding is a particularly important task in this context, as it enables the detection and classification of astronomical objects. Deep-learning-based object detection and semantic segmentation models have proven to be suitable for this purpose. However, training such deep networks requires a high volume of labeled data, which is not trivial to obtain in the context of radio astronomy. Since data needs to be manually labeled by experts, this process is not scalable to large dataset sizes, limiting the possibilities of leveraging deep networks to address several tasks. In this work, we propose RADiff, a generative approach based on conditional diffusion models trained over an annotated radio dataset to generate synthetic images, containing radio sources of different morphologies, to augment existing datasets and reduce the problems caused by class imbalances. We also show that it is possible to generate fully-synthetic image-annotation pairs to automatically augment any annotated dataset. We evaluate the effectiveness of this approach by training a semantic segmentation model on a real dataset augmented in two ways: 1) using synthetic images obtained from real masks, and 2) generating images from synthetic semantic masks. We show an improvement in performance when applying augmentation, gaining up to 18% in performance when using real masks and 4% when augmenting with synthetic masks. Finally, we employ this model to generate large-scale radio maps with the objective of simulating Data Challenges.
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Jun 12, 2023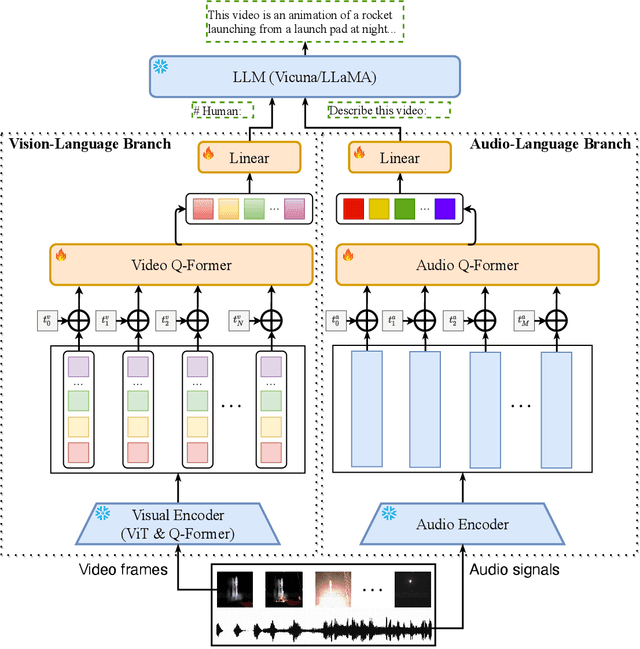
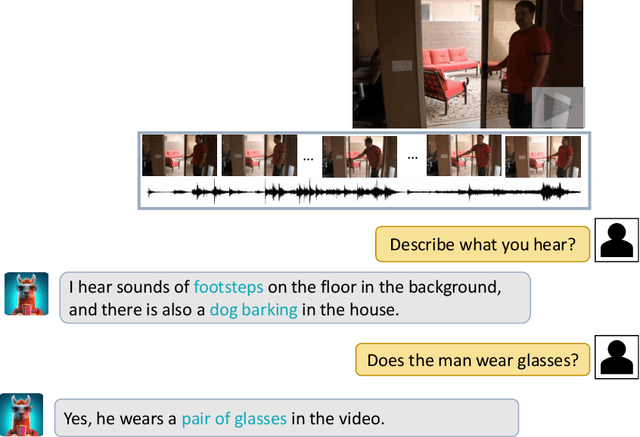
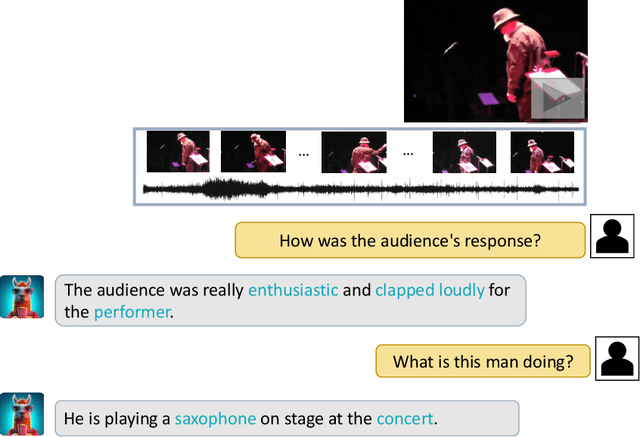
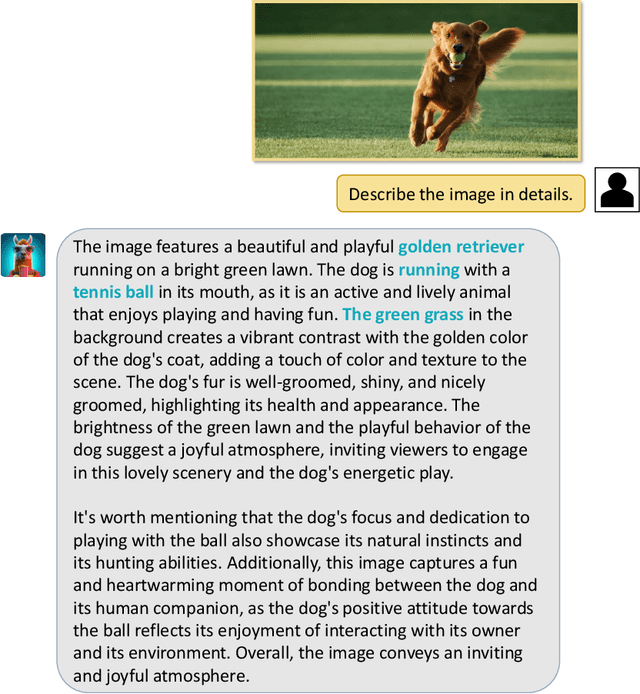
We present Video-LLaMA, a multi-modal framework that empowers Large Language Models (LLMs) with the capability of understanding both visual and auditory content in the video. Video-LLaMA bootstraps cross-modal training from the frozen pre-trained visual & audio encoders and the frozen LLMs. Unlike previous vision-LLMs that focus on static image comprehensions such as MiniGPT-4 and LLaVA, Video-LLaMA mainly tackles two challenges in video understanding: (1) capturing the temporal changes in visual scenes, (2) integrating audio-visual signals. To counter the first challenge, we propose a Video Q-former to assemble the pre-trained image encoder into our video encoder and introduce a video-to-text generation task to learn video-language correspondence. For the second challenge, we leverage ImageBind, a universal embedding model aligning multiple modalities as the pre-trained audio encoder, and introduce an Audio Q-former on top of ImageBind to learn reasonable auditory query embeddings for the LLM module. To align the output of both visual & audio encoders with LLM's embedding space, we train Video-LLaMA on massive video/image-caption pairs as well as visual-instruction-tuning datasets of moderate amount but higher quality. We found Video-LLaMA showcases the ability to perceive and comprehend video content, generating meaningful responses that are grounded in the visual and auditory information presented in the videos. This highlights the potential of Video-LLaMA as a promising prototype for audio-visual AI assistants.
Scalable 3D Captioning with Pretrained Models
Jun 12, 2023

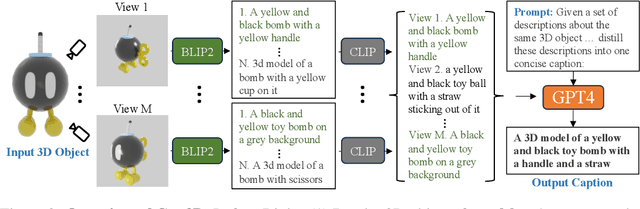
We introduce Cap3D, an automatic approach for generating descriptive text for 3D objects. This approach utilizes pretrained models from image captioning, image-text alignment, and LLM to consolidate captions from multiple views of a 3D asset, completely side-stepping the time-consuming and costly process of manual annotation. We apply Cap3D to the recently introduced large-scale 3D dataset, Objaverse, resulting in 660k 3D-text pairs. Our evaluation, conducted using 41k human annotations from the same dataset, demonstrates that Cap3D surpasses human-authored descriptions in terms of quality, cost, and speed. Through effective prompt engineering, Cap3D rivals human performance in generating geometric descriptions on 17k collected annotations from the ABO dataset. Finally, we finetune Text-to-3D models on Cap3D and human captions, and show Cap3D outperforms; and benchmark the SOTA including Point-E, Shape-E, and DreamFusion.
Discovering Novel Biological Traits From Images Using Phylogeny-Guided Neural Networks
Jun 05, 2023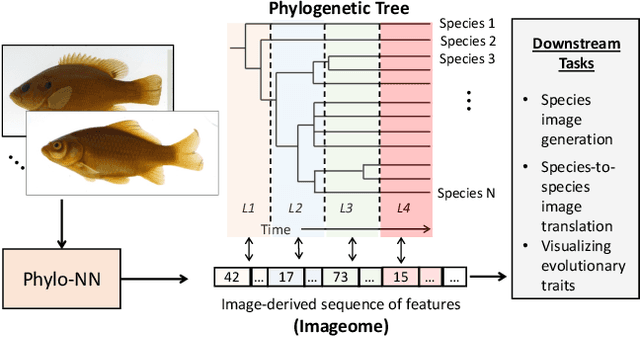
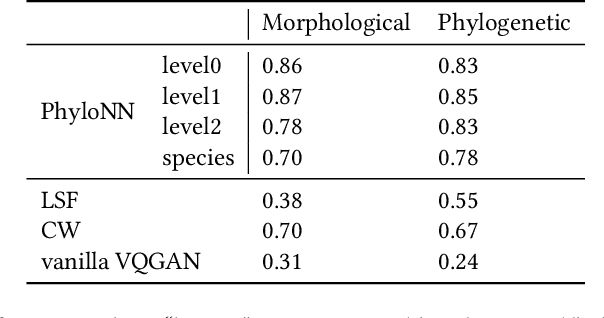
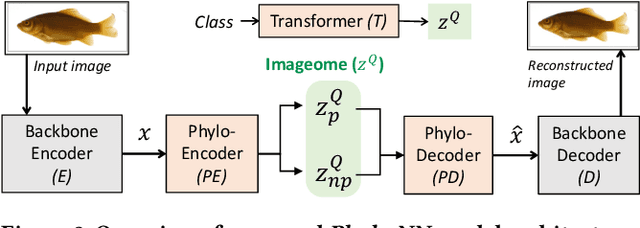
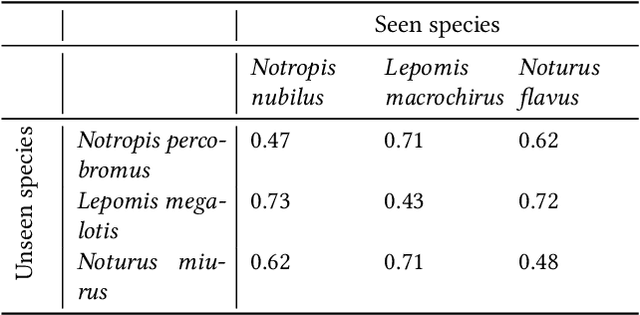
Discovering evolutionary traits that are heritable across species on the tree of life (also referred to as a phylogenetic tree) is of great interest to biologists to understand how organisms diversify and evolve. However, the measurement of traits is often a subjective and labor-intensive process, making trait discovery a highly label-scarce problem. We present a novel approach for discovering evolutionary traits directly from images without relying on trait labels. Our proposed approach, Phylo-NN, encodes the image of an organism into a sequence of quantized feature vectors -- or codes -- where different segments of the sequence capture evolutionary signals at varying ancestry levels in the phylogeny. We demonstrate the effectiveness of our approach in producing biologically meaningful results in a number of downstream tasks including species image generation and species-to-species image translation, using fish species as a target example.
Multi-domain learning CNN model for microscopy image classification
Apr 20, 2023
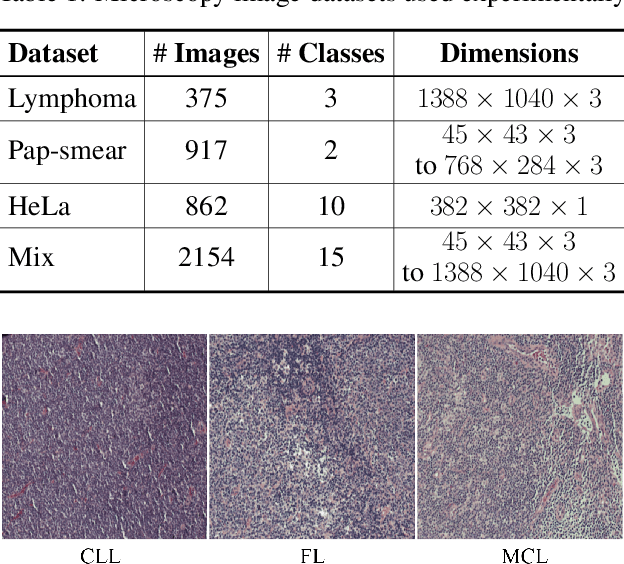
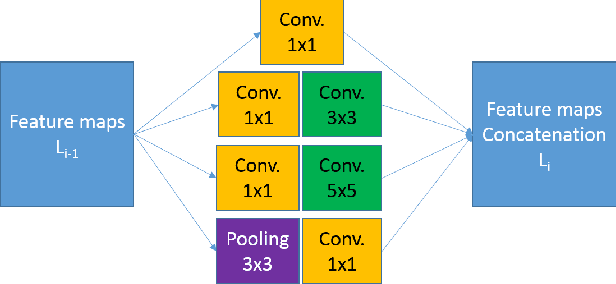
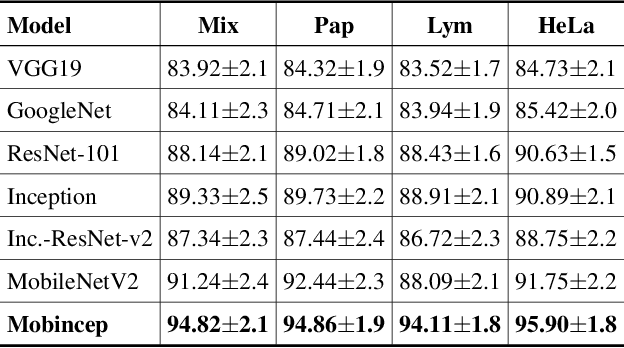
For any type of microscopy image, getting a deep learning model to work well requires considerable effort to select a suitable architecture and time to train it. As there is a wide range of microscopes and experimental setups, designing a single model that can apply to multiple imaging domains, instead of having multiple per-domain models, becomes more essential. This task is challenging and somehow overlooked in the literature. In this paper, we present a multi-domain learning architecture for the classification of microscopy images that differ significantly in types and contents. Unlike previous methods that are computationally intensive, we have developed a compact model, called Mobincep, by combining the simple but effective techniques of depth-wise separable convolution and the inception module. We also introduce a new optimization technique to regulate the latent feature space during training to improve the network's performance. We evaluated our model on three different public datasets and compared its performance in single-domain and multiple-domain learning modes. The proposed classifier surpasses state-of-the-art results and is robust for limited labeled data. Moreover, it helps to eliminate the burden of designing a new network when switching to new experiments.
Human-to-Human Interaction Detection
Jul 02, 2023
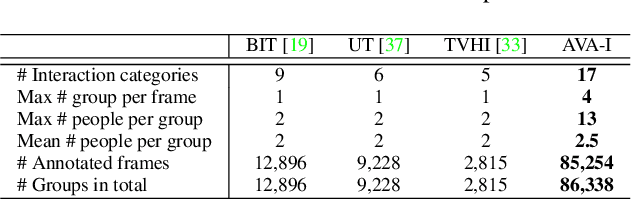
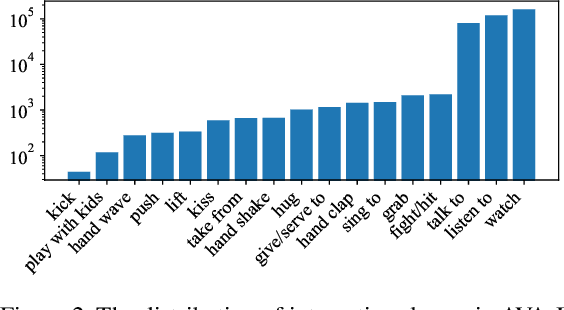
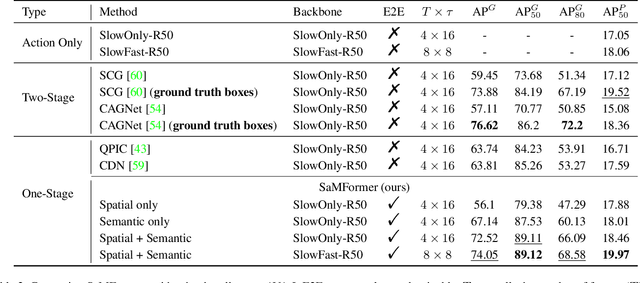
A comprehensive understanding of interested human-to-human interactions in video streams, such as queuing, handshaking, fighting and chasing, is of immense importance to the surveillance of public security in regions like campuses, squares and parks. Different from conventional human interaction recognition, which uses choreographed videos as inputs, neglects concurrent interactive groups, and performs detection and recognition in separate stages, we introduce a new task named human-to-human interaction detection (HID). HID devotes to detecting subjects, recognizing person-wise actions, and grouping people according to their interactive relations, in one model. First, based on the popular AVA dataset created for action detection, we establish a new HID benchmark, termed AVA-Interaction (AVA-I), by adding annotations on interactive relations in a frame-by-frame manner. AVA-I consists of 85,254 frames and 86,338 interactive groups, and each image includes up to 4 concurrent interactive groups. Second, we present a novel baseline approach SaMFormer for HID, containing a visual feature extractor, a split stage which leverages a Transformer-based model to decode action instances and interactive groups, and a merging stage which reconstructs the relationship between instances and groups. All SaMFormer components are jointly trained in an end-to-end manner. Extensive experiments on AVA-I validate the superiority of SaMFormer over representative methods. The dataset and code will be made public to encourage more follow-up studies.
Static Background Removal in Vehicular Radar: Filtering in Azimuth-Elevation-Doppler Domain
Jul 04, 2023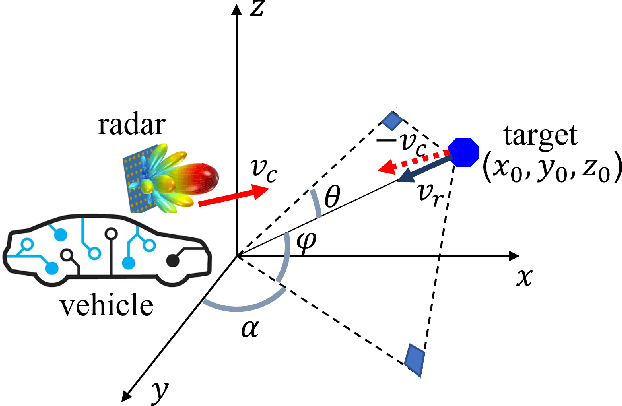
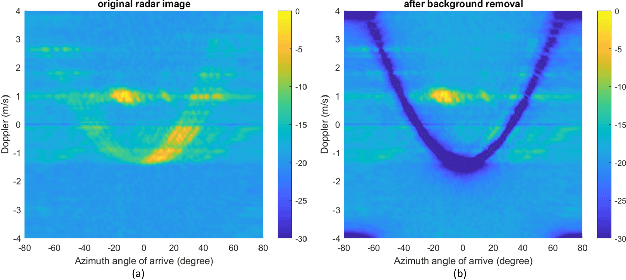
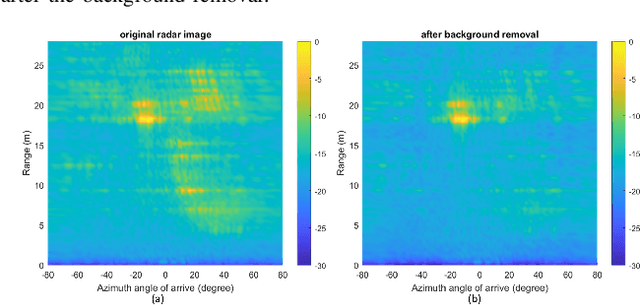
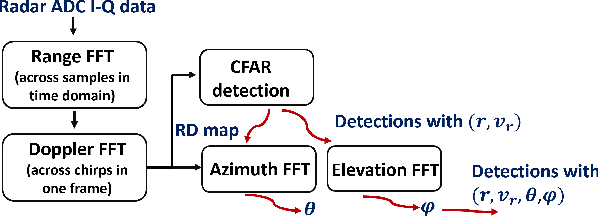
A significant challenge in autonomous driving systems lies in image understanding within complex environments, particularly dense traffic scenarios. An effective solution to this challenge involves removing the background or static objects from the scene, so as to enhance the detection of moving targets as key component of improving overall system performance. In this paper, we present an efficient algorithm for background removal in automotive radar applications, specifically utilizing a frequency-modulated continuous wave (FMCW) radar. Our proposed algorithm follows a three-step approach, encompassing radar signal preprocessing, three-dimensional (3D) ego-motion estimation, and notch filter-based background removal in the azimuth-elevation-Doppler domain. To begin, we model the received signal of the FMCW multiple-input multiple-output (MIMO) radar and develop a signal processing framework for extracting four-dimensional (4D) point clouds. Subsequently, we introduce a robust 3D ego-motion estimation algorithm that accurately estimates radar ego-motion speed, accounting for Doppler ambiguity, by processing the point clouds. Additionally, our algorithm leverages the relationship between Doppler velocity, azimuth angle, elevation angle, and radar ego-motion speed to identify the spectrum belonging to background clutter. Subsequently, we employ notch filters to effectively filter out the background clutter. The performance of our algorithm is evaluated using both simulated data and extensive experiments with real-world data. The results demonstrate its effectiveness in efficiently removing background clutter and enhacing perception within complex environments. By offering a fast and computationally efficient solution, our approach effectively addresses challenges posed by non-homogeneous environments and real-time processing requirements.
Convolutional Transformer for Autonomous Recognition and Grading of Tomatoes Under Various Lighting, Occlusion, and Ripeness Conditions
Jul 04, 2023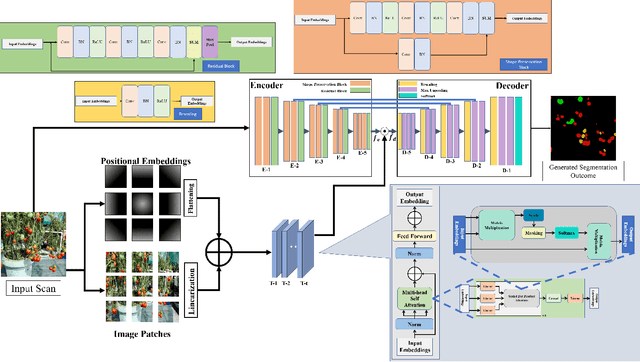


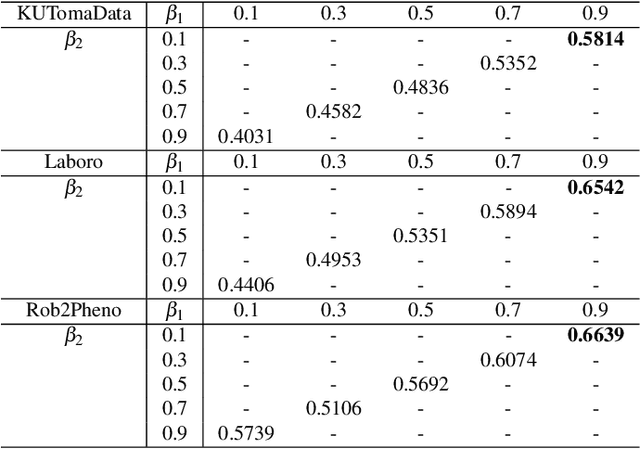
Harvesting fully ripe tomatoes with mobile robots presents significant challenges in real-world scenarios. These challenges arise from factors such as occlusion caused by leaves and branches, as well as the color similarity between tomatoes and the surrounding foliage during the fruit development stage. The natural environment further compounds these issues with varying light conditions, viewing angles, occlusion factors, and different maturity levels. To overcome these obstacles, this research introduces a novel framework that leverages a convolutional transformer architecture to autonomously recognize and grade tomatoes, irrespective of their occlusion level, lighting conditions, and ripeness. The proposed model is trained and tested using carefully annotated images curated specifically for this purpose. The dataset is prepared under various lighting conditions, viewing perspectives, and employs different mobile camera sensors, distinguishing it from existing datasets such as Laboro Tomato and Rob2Pheno Annotated Tomato. The effectiveness of the proposed framework in handling cluttered and occluded tomato instances was evaluated using two additional public datasets, Laboro Tomato and Rob2Pheno Annotated Tomato, as benchmarks. The evaluation results across these three datasets demonstrate the exceptional performance of our proposed framework, surpassing the state-of-the-art by 58.14%, 65.42%, and 66.39% in terms of mean average precision scores for KUTomaData, Laboro Tomato, and Rob2Pheno Annotated Tomato, respectively. The results underscore the superiority of the proposed model in accurately detecting and delineating tomatoes compared to baseline methods and previous approaches. Specifically, the model achieves an F1-score of 80.14%, a Dice coefficient of 73.26%, and a mean IoU of 66.41% on the KUTomaData image dataset.
RRCNN: A novel signal decomposition approach based on recurrent residue convolutional neural network
Jul 04, 2023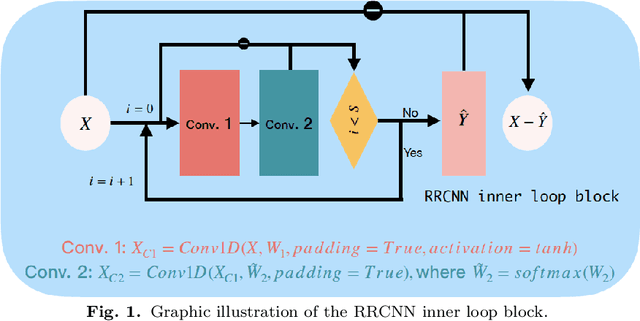
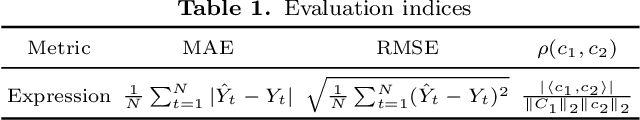
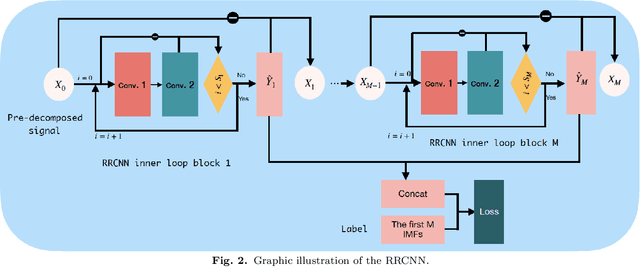

The decomposition of non-stationary signals is an important and challenging task in the field of signal time-frequency analysis. In the recent two decades, many signal decomposition methods led by the empirical mode decomposition, which was pioneered by Huang et al. in 1998, have been proposed by different research groups. However, they still have some limitations. For example, they are generally prone to boundary and mode mixing effects and are not very robust to noise. Inspired by the successful applications of deep learning in fields like image processing and natural language processing, and given the lack in the literature of works in which deep learning techniques are used directly to decompose non-stationary signals into simple oscillatory components, we use the convolutional neural network, residual structure and nonlinear activation function to compute in an innovative way the local average of the signal, and study a new non-stationary signal decomposition method under the framework of deep learning. We discuss the training process of the proposed model and study the convergence analysis of the learning algorithm. In the experiments, we evaluate the performance of the proposed model from two points of view: the calculation of the local average and the signal decomposition. Furthermore, we study the mode mixing, noise interference, and orthogonality properties of the decomposed components produced by the proposed method. All results show that the proposed model allows for better handling boundary effect, mode mixing effect, robustness, and the orthogonality of the decomposed components than existing methods.
Learning Feature Matching via Matchable Keypoint-Assisted Graph Neural Network
Jul 04, 2023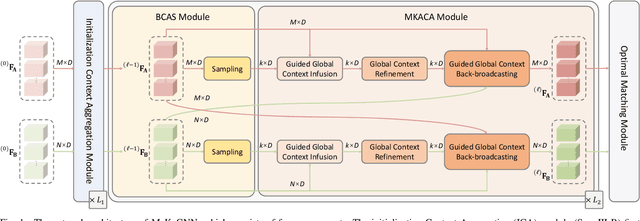
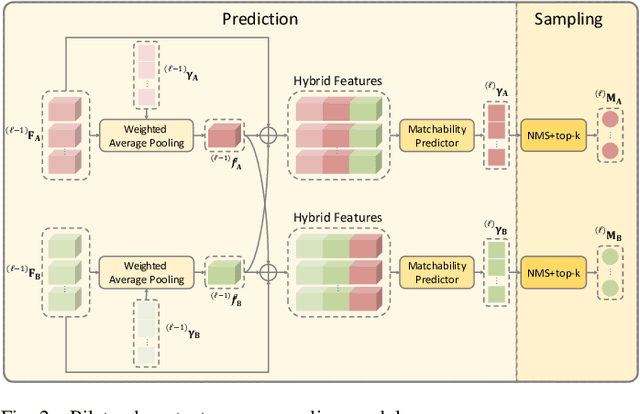
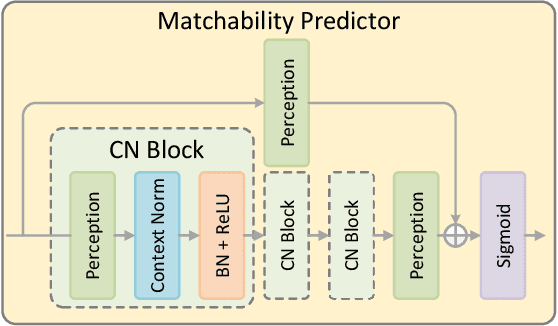
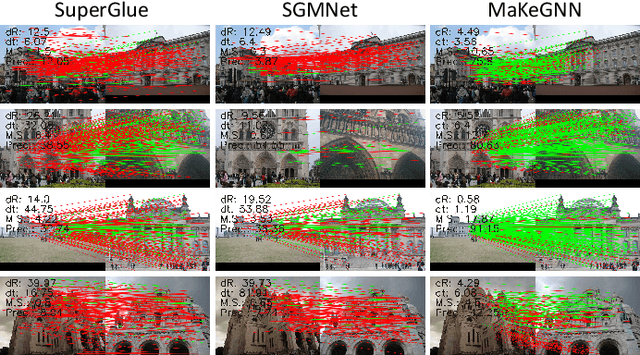
Accurately matching local features between a pair of images is a challenging computer vision task. Previous studies typically use attention based graph neural networks (GNNs) with fully-connected graphs over keypoints within/across images for visual and geometric information reasoning. However, in the context of feature matching, considerable keypoints are non-repeatable due to occlusion and failure of the detector, and thus irrelevant for message passing. The connectivity with non-repeatable keypoints not only introduces redundancy, resulting in limited efficiency, but also interferes with the representation aggregation process, leading to limited accuracy. Targeting towards high accuracy and efficiency, we propose MaKeGNN, a sparse attention-based GNN architecture which bypasses non-repeatable keypoints and leverages matchable ones to guide compact and meaningful message passing. More specifically, our Bilateral Context-Aware Sampling Module first dynamically samples two small sets of well-distributed keypoints with high matchability scores from the image pair. Then, our Matchable Keypoint-Assisted Context Aggregation Module regards sampled informative keypoints as message bottlenecks and thus constrains each keypoint only to retrieve favorable contextual information from intra- and inter- matchable keypoints, evading the interference of irrelevant and redundant connectivity with non-repeatable ones. Furthermore, considering the potential noise in initial keypoints and sampled matchable ones, the MKACA module adopts a matchability-guided attentional aggregation operation for purer data-dependent context propagation. By these means, we achieve the state-of-the-art performance on relative camera estimation, fundamental matrix estimation, and visual localization, while significantly reducing computational and memory complexity compared to typical attentional GNNs.