 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Investigation of the Challenges of Underwater-Visual-Monocular-SLAM
Jun 14, 2023
In this paper, we present a comprehensive investigation of the challenges of Monocular Visual Simultaneous Localization and Mapping (vSLAM) methods for underwater robots. While significant progress has been made in state estimation methods that utilize visual data in the past decade, most evaluations have been limited to controlled indoor and urban environments, where impressive performance was demonstrated. However, these techniques have not been extensively tested in extremely challenging conditions, such as underwater scenarios where factors such as water and light conditions, robot path, and depth can greatly impact algorithm performance. Hence, our evaluation is conducted in real-world AUV scenarios as well as laboratory settings which provide precise external reference. A focus is laid on understanding the impact of environmental conditions, such as optical properties of the water and illumination scenarios, on the performance of monocular vSLAM methods. To this end, we first show that all methods perform very well in in-air settings and subsequently show the degradation of their performance in challenging underwater environments. The final goal of this study is to identify techniques that can improve accuracy and robustness of SLAM methods in such conditions. To achieve this goal, we investigate the potential of image enhancement techniques to improve the quality of input images used by the SLAM methods, specifically in low visibility and extreme lighting scenarios in scattering media. We present a first evaluation on calibration maneuvers and simple image restoration techniques to determine their ability to enable or enhance the performance of monocular SLAM methods in underwater environments.
Fashion Image Retrieval with Multi-Granular Alignment
Feb 27, 2023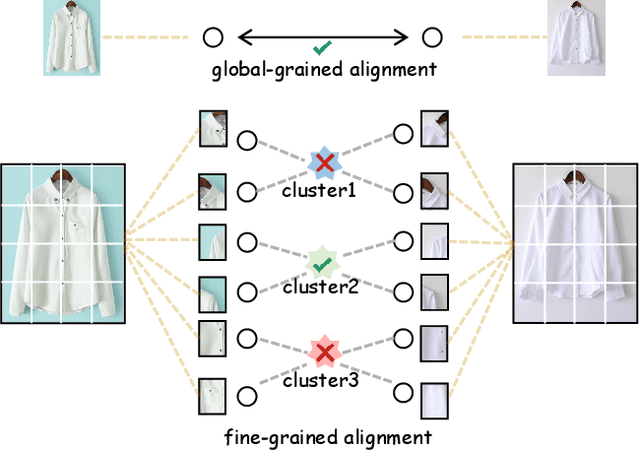
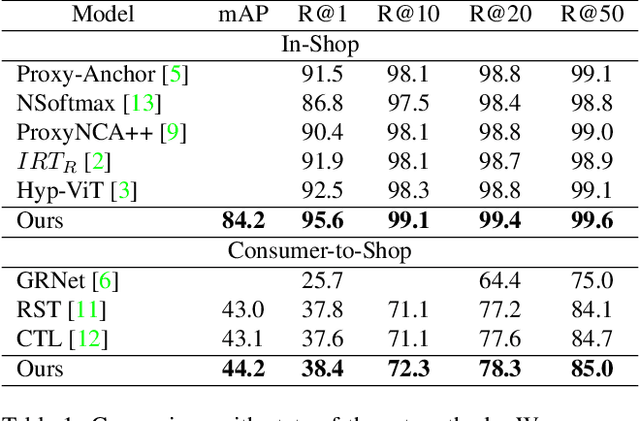
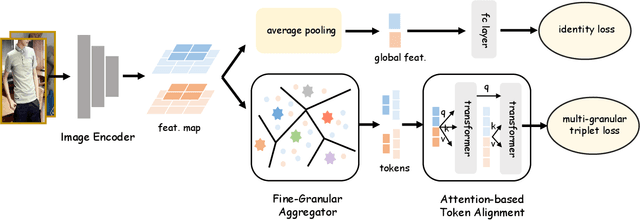

Fashion image retrieval task aims to search relevant clothing items of a query image from the gallery. The previous recipes focus on designing different distance-based loss functions, pulling relevant pairs to be close and pushing irrelevant images apart. However, these methods ignore fine-grained features (e.g. neckband, cuff) of clothing images. In this paper, we propose a novel fashion image retrieval method leveraging both global and fine-grained features, dubbed Multi-Granular Alignment (MGA). Specifically, we design a Fine-Granular Aggregator(FGA) to capture and aggregate detailed patterns. Then we propose Attention-based Token Alignment (ATA) to align image features at the multi-granular level in a coarse-to-fine manner. To prove the effectiveness of our proposed method, we conduct experiments on two sub-tasks (In-Shop & Consumer2Shop) of the public fashion datasets DeepFashion. The experimental results show that our MGA outperforms the state-of-the-art methods by 1.8% and 0.6% in the two sub-tasks on the R@1 metric, respectively.
Model-based demosaicking for acquisitions by a RGBW color filter array
Jun 02, 2023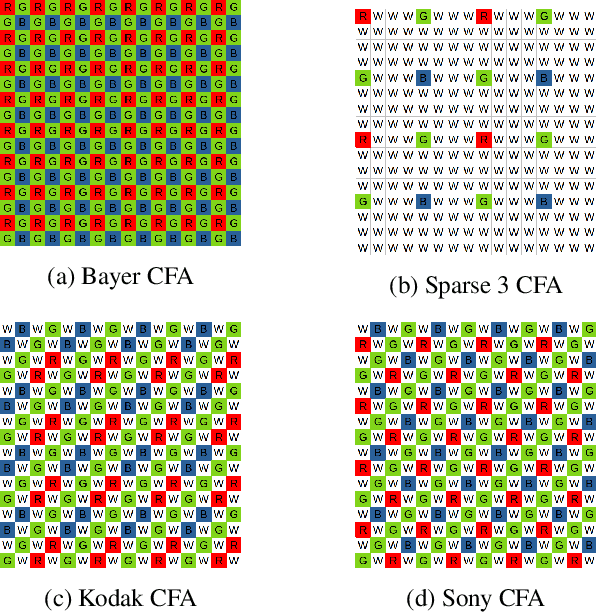



Microsatellites and drones are often equipped with digital cameras whose sensing system is based on color filter arrays (CFAs), which define a pattern of color filter overlaid over the focal plane. Recent commercial cameras have started implementing RGBW patterns, which include some filters with a wideband spectral response together with the more classical RGB ones. This allows for additional light energy to be captured by the relevant pixels and increases the overall SNR of the acquisition. Demosaicking defines reconstructing a multi-spectral image from the raw image and recovering the full color components for all pixels. However, this operation is often tailored for the most widespread patterns, such as the Bayer pattern. Consequently, less common patterns that are still employed in commercial cameras are often neglected. In this work, we present a generalized framework to represent the image formation model of such cameras. This model is then exploited by our proposed demosaicking algorithm to reconstruct the datacube of interest with a Bayesian approach, using a total variation regularizer as prior. Some preliminary experimental results are also presented, which apply to the reconstruction of acquisitions of various RGBW cameras.
Global Context-Aware Person Image Generation
Feb 28, 2023
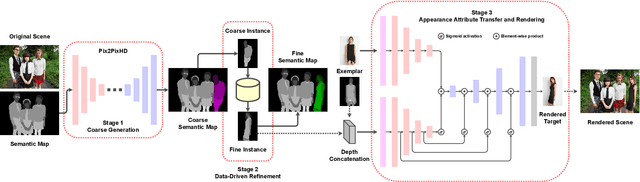

We propose a data-driven approach for context-aware person image generation. Specifically, we attempt to generate a person image such that the synthesized instance can blend into a complex scene. In our method, the position, scale, and appearance of the generated person are semantically conditioned on the existing persons in the scene. The proposed technique is divided into three sequential steps. At first, we employ a Pix2PixHD model to infer a coarse semantic mask that represents the new person's spatial location, scale, and potential pose. Next, we use a data-centric approach to select the closest representation from a precomputed cluster of fine semantic masks. Finally, we adopt a multi-scale, attention-guided architecture to transfer the appearance attributes from an exemplar image. The proposed strategy enables us to synthesize semantically coherent realistic persons that can blend into an existing scene without altering the global context. We conclude our findings with relevant qualitative and quantitative evaluations.
PODIA-3D: Domain Adaptation of 3D Generative Model Across Large Domain Gap Using Pose-Preserved Text-to-Image Diffusion
Apr 04, 2023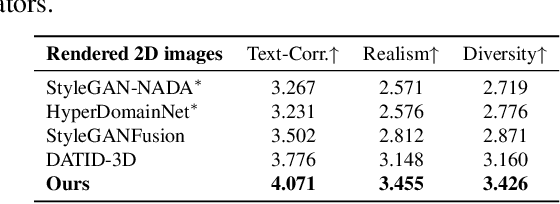

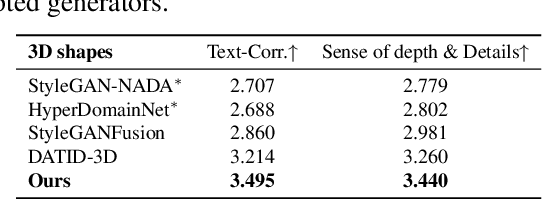
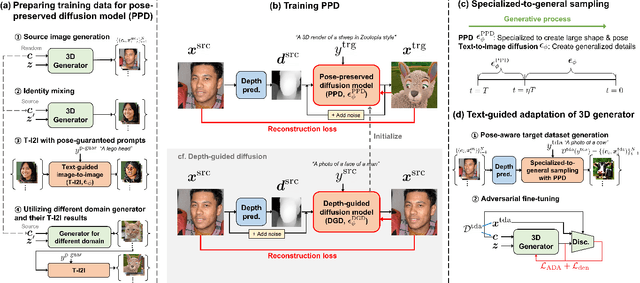
Recently, significant advancements have been made in 3D generative models, however training these models across diverse domains is challenging and requires an huge amount of training data and knowledge of pose distribution. Text-guided domain adaptation methods have allowed the generator to be adapted to the target domains using text prompts, thereby obviating the need for assembling numerous data. Recently, DATID-3D presents impressive quality of samples in text-guided domain, preserving diversity in text by leveraging text-to-image diffusion. However, adapting 3D generators to domains with significant domain gaps from the source domain still remains challenging due to issues in current text-to-image diffusion models as following: 1) shape-pose trade-off in diffusion-based translation, 2) pose bias, and 3) instance bias in the target domain, resulting in inferior 3D shapes, low text-image correspondence, and low intra-domain diversity in the generated samples. To address these issues, we propose a novel pipeline called PODIA-3D, which uses pose-preserved text-to-image diffusion-based domain adaptation for 3D generative models. We construct a pose-preserved text-to-image diffusion model that allows the use of extremely high-level noise for significant domain changes. We also propose specialized-to-general sampling strategies to improve the details of the generated samples. Moreover, to overcome the instance bias, we introduce a text-guided debiasing method that improves intra-domain diversity. Consequently, our method successfully adapts 3D generators across significant domain gaps. Our qualitative results and user study demonstrates that our approach outperforms existing 3D text-guided domain adaptation methods in terms of text-image correspondence, realism, diversity of rendered images, and sense of depth of 3D shapes in the generated samples
MM-BSN: Self-Supervised Image Denoising for Real-World with Multi-Mask based on Blind-Spot Network
Apr 04, 2023

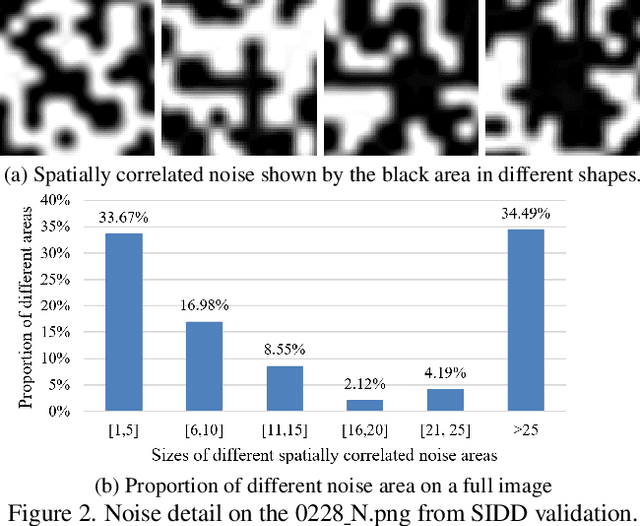
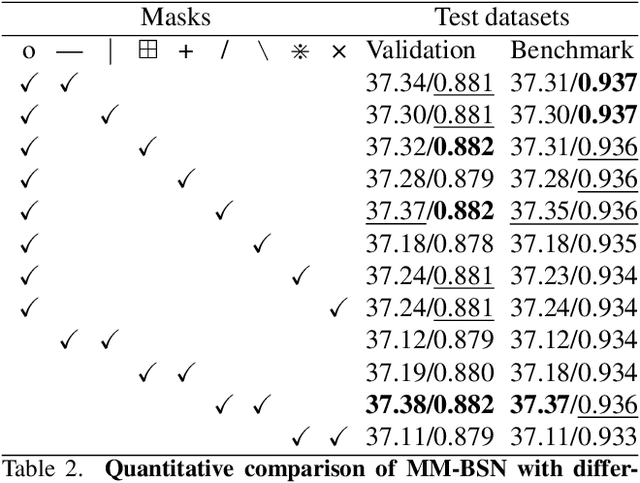
Recent advances in deep learning have been pushing image denoising techniques to a new level. In self-supervised image denoising, blind-spot network (BSN) is one of the most common methods. However, most of the existing BSN algorithms use a dot-based central mask, which is recognized as inefficient for images with large-scale spatially correlated noise. In this paper, we give the definition of large-noise and propose a multi-mask strategy using multiple convolutional kernels masked in different shapes to further break the noise spatial correlation. Furthermore, we propose a novel self-supervised image denoising method that combines the multi-mask strategy with BSN (MM-BSN). We show that different masks can cause significant performance differences, and the proposed MM-BSN can efficiently fuse the features extracted by multi-masked layers, while recovering the texture structures destroyed by multi-masking and information transmission. Our MM-BSN can be used to address the problem of large-noise denoising, which cannot be efficiently handled by other BSN methods. Extensive experiments on public real-world datasets demonstrate that the proposed MM-BSN achieves state-of-the-art performance among self-supervised and even unpaired image denoising methods for sRGB images denoising, without any labelling effort or prior knowledge. Code can be found in https://github.com/dannie125/MM-BSN.
Image Classifiers Leak Sensitive Attributes About Their Classes
Mar 16, 2023
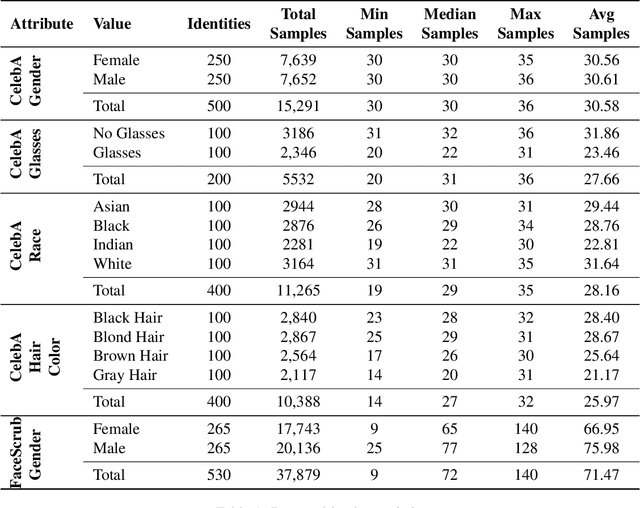

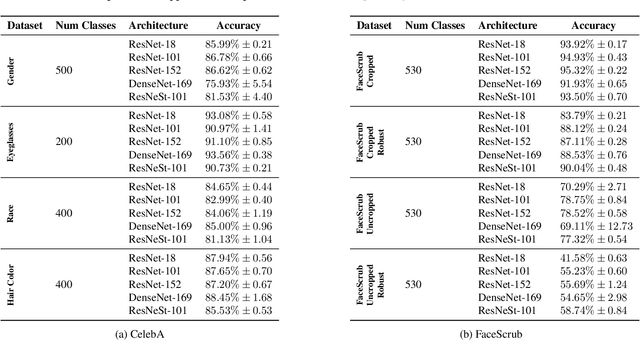
Neural network-based image classifiers are powerful tools for computer vision tasks, but they inadvertently reveal sensitive attribute information about their classes, raising concerns about their privacy. To investigate this privacy leakage, we introduce the first Class Attribute Inference Attack (Caia), which leverages recent advances in text-to-image synthesis to infer sensitive attributes of individual classes in a black-box setting, while remaining competitive with related white-box attacks. Our extensive experiments in the face recognition domain show that Caia can accurately infer undisclosed sensitive attributes, such as an individual's hair color, gender and racial appearance, which are not part of the training labels. Interestingly, we demonstrate that adversarial robust models are even more vulnerable to such privacy leakage than standard models, indicating that a trade-off between robustness and privacy exists.
SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions
Jun 08, 2023

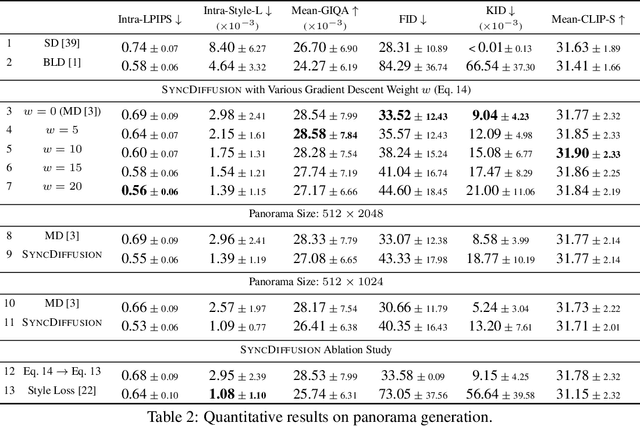

The remarkable capabilities of pretrained image diffusion models have been utilized not only for generating fixed-size images but also for creating panoramas. However, naive stitching of multiple images often results in visible seams. Recent techniques have attempted to address this issue by performing joint diffusions in multiple windows and averaging latent features in overlapping regions. However, these approaches, which focus on seamless montage generation, often yield incoherent outputs by blending different scenes within a single image. To overcome this limitation, we propose SyncDiffusion, a plug-and-play module that synchronizes multiple diffusions through gradient descent from a perceptual similarity loss. Specifically, we compute the gradient of the perceptual loss using the predicted denoised images at each denoising step, providing meaningful guidance for achieving coherent montages. Our experimental results demonstrate that our method produces significantly more coherent outputs compared to previous methods (66.35% vs. 33.65% in our user study) while still maintaining fidelity (as assessed by GIQA) and compatibility with the input prompt (as measured by CLIP score).
Weakly Supervised Vision-and-Language Pre-training with Relative Representations
May 24, 2023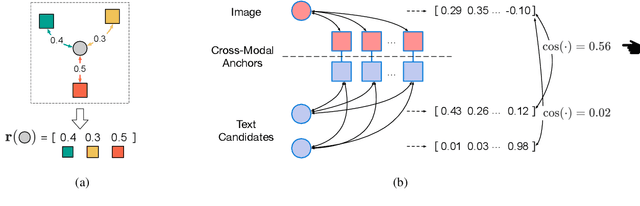
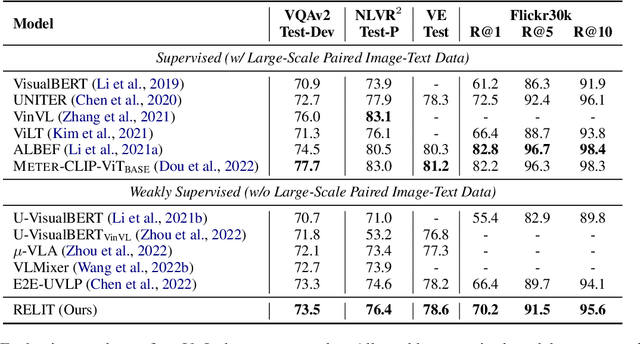
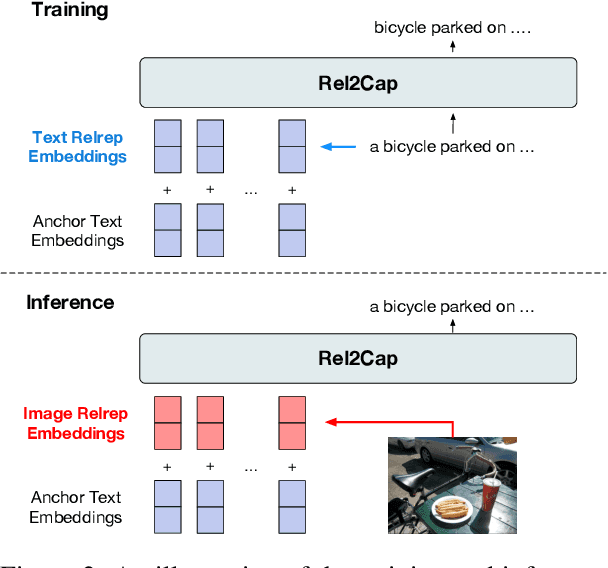
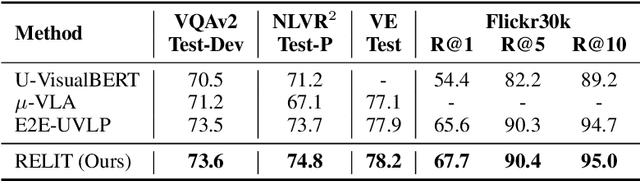
Weakly supervised vision-and-language pre-training (WVLP), which learns cross-modal representations with limited cross-modal supervision, has been shown to effectively reduce the data cost of pre-training while maintaining decent performance on downstream tasks. However, current WVLP methods use only local descriptions of images, i.e., object tags, as cross-modal anchors to construct weakly-aligned image-text pairs for pre-training. This affects the data quality and thus the effectiveness of pre-training. In this paper, we propose to directly take a small number of aligned image-text pairs as anchors, and represent each unaligned image and text by its similarities to these anchors, i.e., relative representations. We build a WVLP framework based on the relative representations, namely RELIT, which collects high-quality weakly-aligned image-text pairs from large-scale image-only and text-only data for pre-training through relative representation-based retrieval and generation. Experiments on four downstream tasks show that RELIT achieves new state-of-the-art results under the weakly supervised setting.
Semantic Image Attack for Visual Model Diagnosis
Mar 23, 2023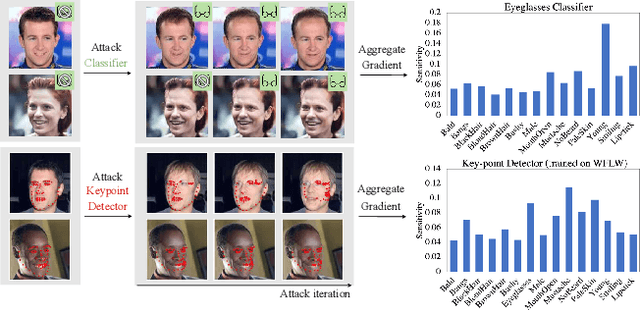

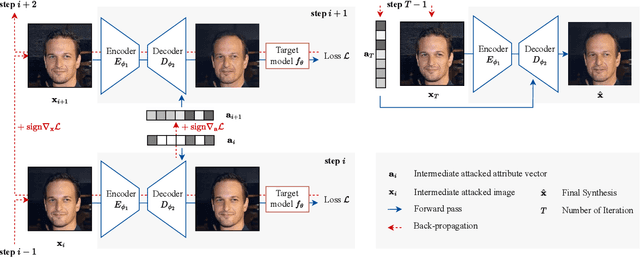
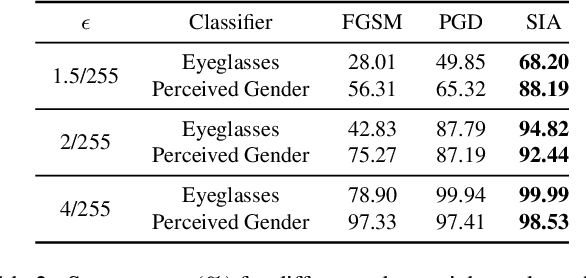
In practice, metric analysis on a specific train and test dataset does not guarantee reliable or fair ML models. This is partially due to the fact that obtaining a balanced, diverse, and perfectly labeled dataset is typically expensive, time-consuming, and error-prone. Rather than relying on a carefully designed test set to assess ML models' failures, fairness, or robustness, this paper proposes Semantic Image Attack (SIA), a method based on the adversarial attack that provides semantic adversarial images to allow model diagnosis, interpretability, and robustness. Traditional adversarial training is a popular methodology for robustifying ML models against attacks. However, existing adversarial methods do not combine the two aspects that enable the interpretation and analysis of the model's flaws: semantic traceability and perceptual quality. SIA combines the two features via iterative gradient ascent on a predefined semantic attribute space and the image space. We illustrate the validity of our approach in three scenarios for keypoint detection and classification. (1) Model diagnosis: SIA generates a histogram of attributes that highlights the semantic vulnerability of the ML model (i.e., attributes that make the model fail). (2) Stronger attacks: SIA generates adversarial examples with visually interpretable attributes that lead to higher attack success rates than baseline methods. The adversarial training on SIA improves the transferable robustness across different gradient-based attacks. (3) Robustness to imbalanced datasets: we use SIA to augment the underrepresented classes, which outperforms strong augmentation and re-balancing baselines.