 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Measured Albedo in the Wild: Filling the Gap in Intrinsics Evaluation
Jun 29, 2023

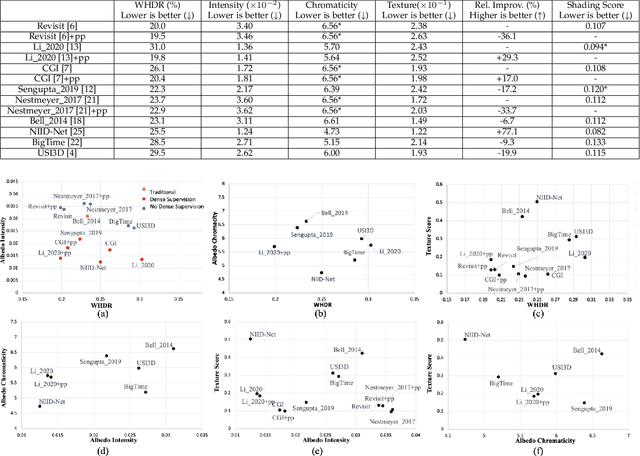


Intrinsic image decomposition and inverse rendering are long-standing problems in computer vision. To evaluate albedo recovery, most algorithms report their quantitative performance with a mean Weighted Human Disagreement Rate (WHDR) metric on the IIW dataset. However, WHDR focuses only on relative albedo values and often fails to capture overall quality of the albedo. In order to comprehensively evaluate albedo, we collect a new dataset, Measured Albedo in the Wild (MAW), and propose three new metrics that complement WHDR: intensity, chromaticity and texture metrics. We show that existing algorithms often improve WHDR metric but perform poorly on other metrics. We then finetune different algorithms on our MAW dataset to significantly improve the quality of the reconstructed albedo both quantitatively and qualitatively. Since the proposed intensity, chromaticity, and texture metrics and the WHDR are all complementary we further introduce a relative performance measure that captures average performance. By analysing existing algorithms we show that there is significant room for improvement. Our dataset and evaluation metrics will enable researchers to develop algorithms that improve albedo reconstruction. Code and Data available at: https://measuredalbedo.github.io/
FarSight: A Physics-Driven Whole-Body Biometric System at Large Distance and Altitude
Jun 29, 2023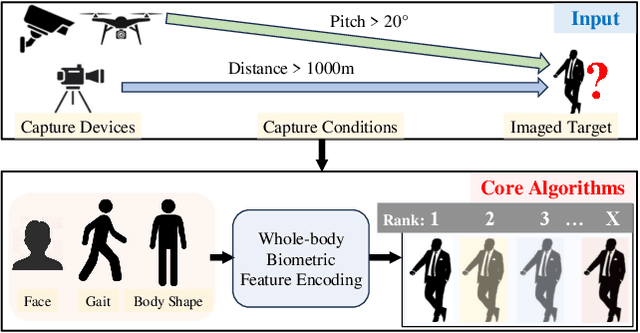
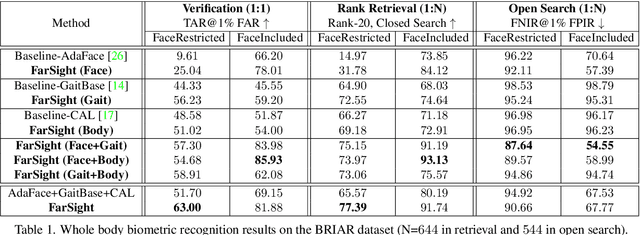
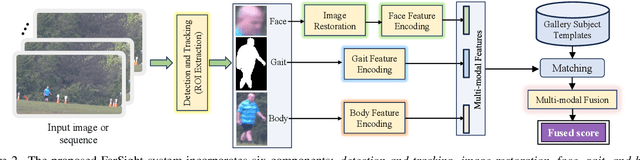

Whole-body biometric recognition is an important area of research due to its vast applications in law enforcement, border security, and surveillance. This paper presents the end-to-end design, development and evaluation of FarSight, an innovative software system designed for whole-body (fusion of face, gait and body shape) biometric recognition. FarSight accepts videos from elevated platforms and drones as input and outputs a candidate list of identities from a gallery. The system is designed to address several challenges, including (i) low-quality imagery, (ii) large yaw and pitch angles, (iii) robust feature extraction to accommodate large intra-person variabilities and large inter-person similarities, and (iv) the large domain gap between training and test sets. FarSight combines the physics of imaging and deep learning models to enhance image restoration and biometric feature encoding. We test FarSight's effectiveness using the newly acquired IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) dataset. Notably, FarSight demonstrated a substantial performance increase on the BRIAR dataset, with gains of +11.82% Rank-20 identification and +11.3% TAR@1% FAR.
Spatial Reasoning via Deep Vision Models for Robotic Sequential Manipulation
Jun 29, 2023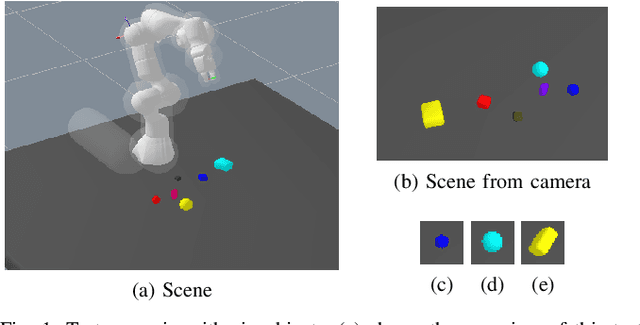

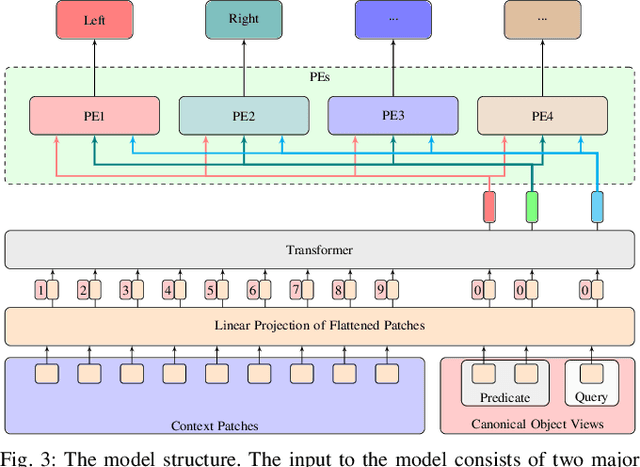
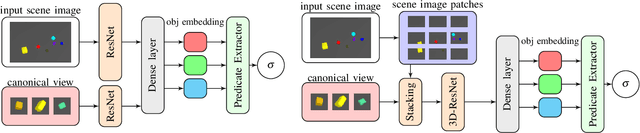
In this paper, we propose using deep neural architectures (i.e., vision transformers and ResNet) as heuristics for sequential decision-making in robotic manipulation problems. This formulation enables predicting the subset of objects that are relevant for completing a task. Such problems are often addressed by task and motion planning (TAMP) formulations combining symbolic reasoning and continuous motion planning. In essence, the action-object relationships are resolved for discrete, symbolic decisions that are used to solve manipulation motions (e.g., via nonlinear trajectory optimization). However, solving long-horizon tasks requires consideration of all possible action-object combinations which limits the scalability of TAMP approaches. To overcome this combinatorial complexity, we introduce a visual perception module integrated with a TAMP-solver. Given a task and an initial image of the scene, the learned model outputs the relevancy of objects to accomplish the task. By incorporating the predictions of the model into a TAMP formulation as a heuristic, the size of the search space is significantly reduced. Results show that our framework finds feasible solutions more efficiently when compared to a state-of-the-art TAMP solver.
Cross-Inferential Networks for Source-free Unsupervised Domain Adaptation
Jun 29, 2023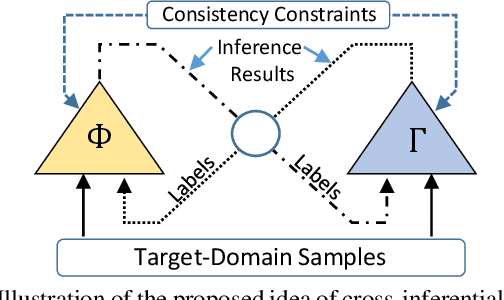
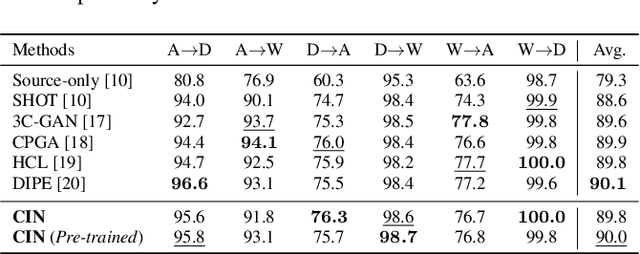
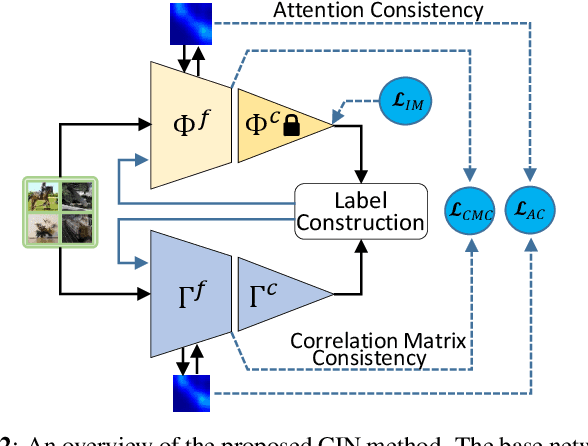
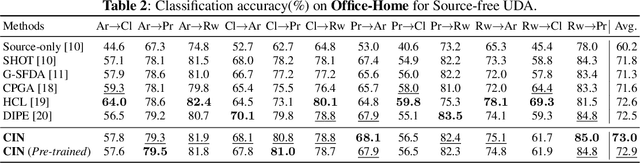
One central challenge in source-free unsupervised domain adaptation (UDA) is the lack of an effective approach to evaluate the prediction results of the adapted network model in the target domain. To address this challenge, we propose to explore a new method called cross-inferential networks (CIN). Our main idea is that, when we adapt the network model to predict the sample labels from encoded features, we use these prediction results to construct new training samples with derived labels to learn a new examiner network that performs a different but compatible task in the target domain. Specifically, in this work, the base network model is performing image classification while the examiner network is tasked to perform relative ordering of triplets of samples whose training labels are carefully constructed from the prediction results of the base network model. Two similarity measures, cross-network correlation matrix similarity and attention consistency, are then developed to provide important guidance for the UDA process. Our experimental results on benchmark datasets demonstrate that our proposed CIN approach can significantly improve the performance of source-free UDA.
GuidedMixup: An Efficient Mixup Strategy Guided by Saliency Maps
Jun 29, 2023
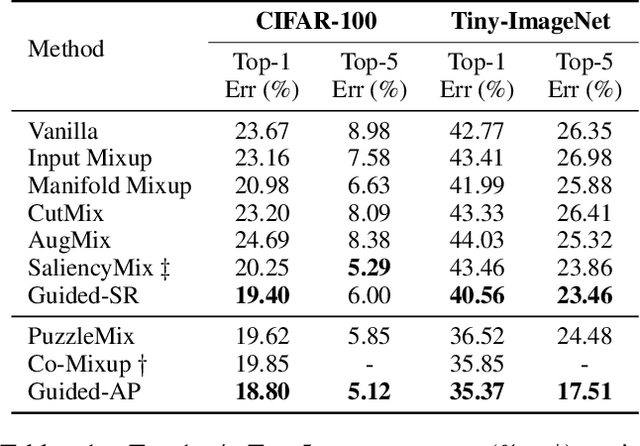
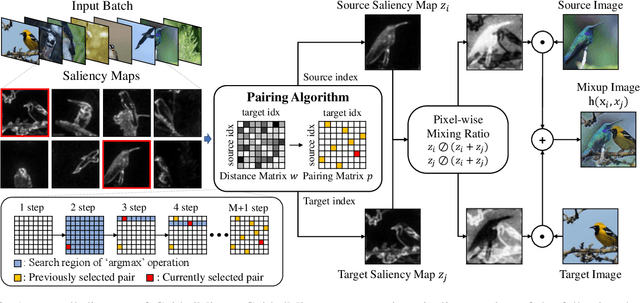
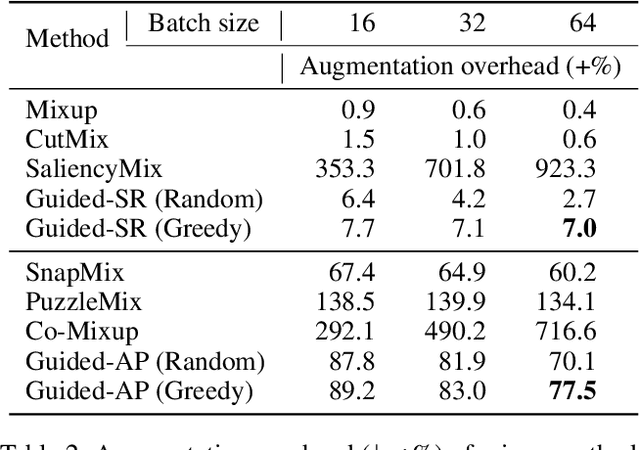
Data augmentation is now an essential part of the image training process, as it effectively prevents overfitting and makes the model more robust against noisy datasets. Recent mixing augmentation strategies have advanced to generate the mixup mask that can enrich the saliency information, which is a supervisory signal. However, these methods incur a significant computational burden to optimize the mixup mask. From this motivation, we propose a novel saliency-aware mixup method, GuidedMixup, which aims to retain the salient regions in mixup images with low computational overhead. We develop an efficient pairing algorithm that pursues to minimize the conflict of salient regions of paired images and achieve rich saliency in mixup images. Moreover, GuidedMixup controls the mixup ratio for each pixel to better preserve the salient region by interpolating two paired images smoothly. The experiments on several datasets demonstrate that GuidedMixup provides a good trade-off between augmentation overhead and generalization performance on classification datasets. In addition, our method shows good performance in experiments with corrupted or reduced datasets.
* Published at AAAI2023 (Oral)
Unified View of Damage leaves Planimetry & Analysis Using Digital Images Processing Techniques
Jun 29, 2023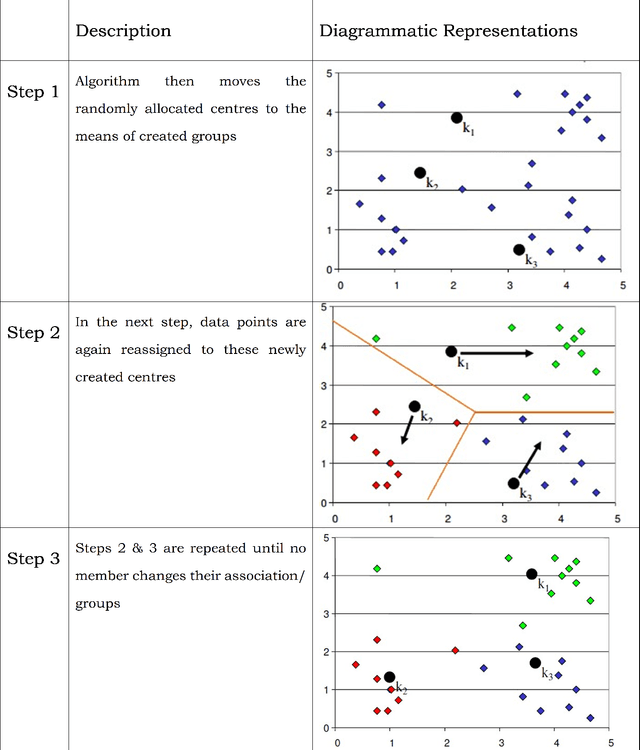
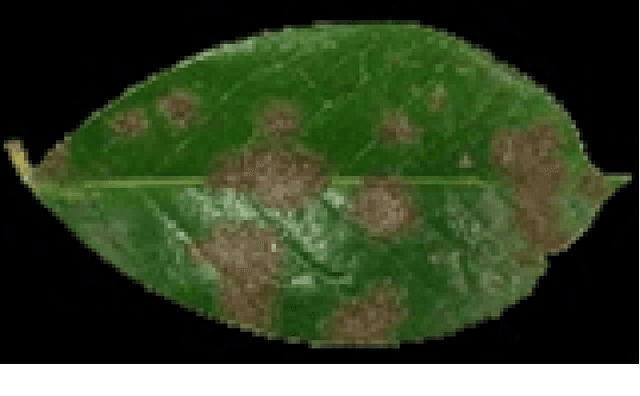
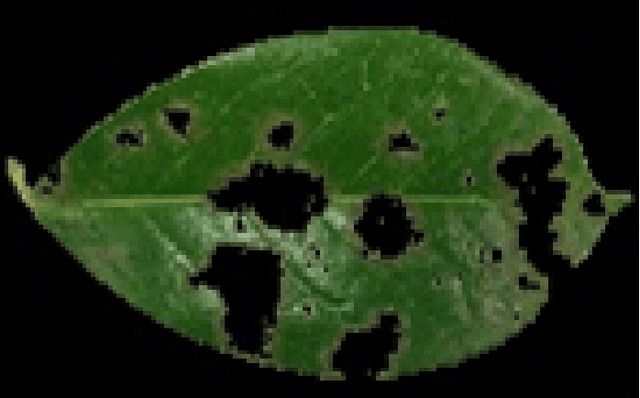

The detection of leaf diseases in plants generally involves visual observation of patterns appearing on the leaf surface. However, there are many diseases that are distinguished based on very subtle changes in these visually observable patterns. This paper attempts to identify plant leaf diseases using image processing techniques. The focus of this study is on the detection of citrus leaf canker disease. Canker is a bacterial infection of leaves. Symptoms of citrus cankers include brown spots on the leaves, often with a watery or oily appearance. The spots (called lesions in botany) are usually yellow. It is surrounded by a halo of the leaves and is found on both the top and bottom of the leaf. This paper describes various methods that have been used to detect citrus leaf canker disease. The methods used are histogram comparison and k-means clustering. Using these methods, citrus canker development was detected based on histograms generated based on leaf patterns. The results thus obtained can be used, after consultation with experts in the field of agriculture, to identify suitable treatments for the processes used.
Joint Level Generation and Translation Using Gameplay Videos
Jun 29, 2023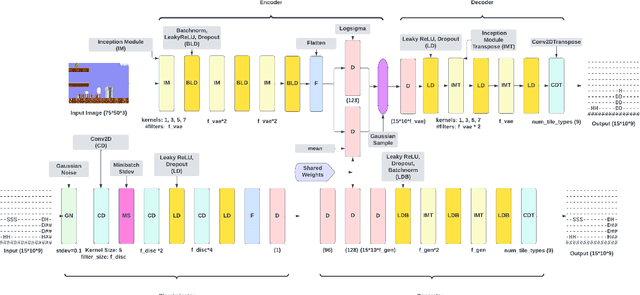
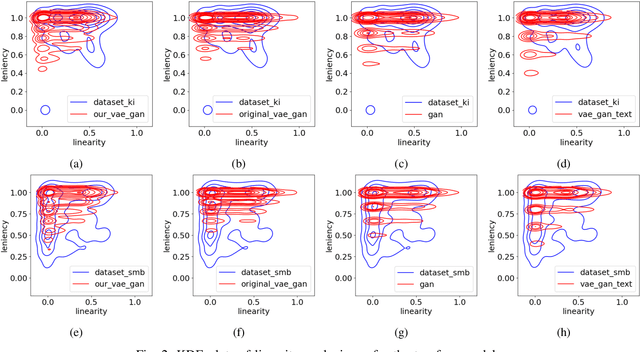
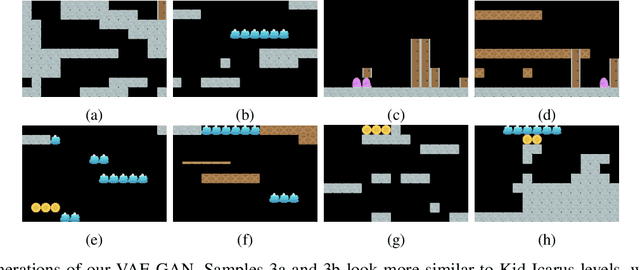
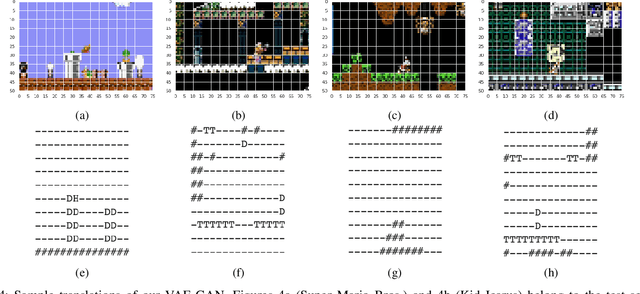
Procedural Content Generation via Machine Learning (PCGML) faces a significant hurdle that sets it apart from other fields, such as image or text generation, which is limited annotated data. Many existing methods for procedural level generation via machine learning require a secondary representation besides level images. However, the current methods for obtaining such representations are laborious and time-consuming, which contributes to this problem. In this work, we aim to address this problem by utilizing gameplay videos of two human-annotated games to develop a novel multi-tail framework that learns to perform simultaneous level translation and generation. The translation tail of our framework can convert gameplay video frames to an equivalent secondary representation, while its generation tail can produce novel level segments. Evaluation results and comparisons between our framework and baselines suggest that combining the level generation and translation tasks can lead to an overall improved performance regarding both tasks. This represents a possible solution to limited annotated level data, and we demonstrate the potential for future versions to generalize to unseen games.
* 8 pages, 4 figures
Visually grounded few-shot word acquisition with fewer shots
May 25, 2023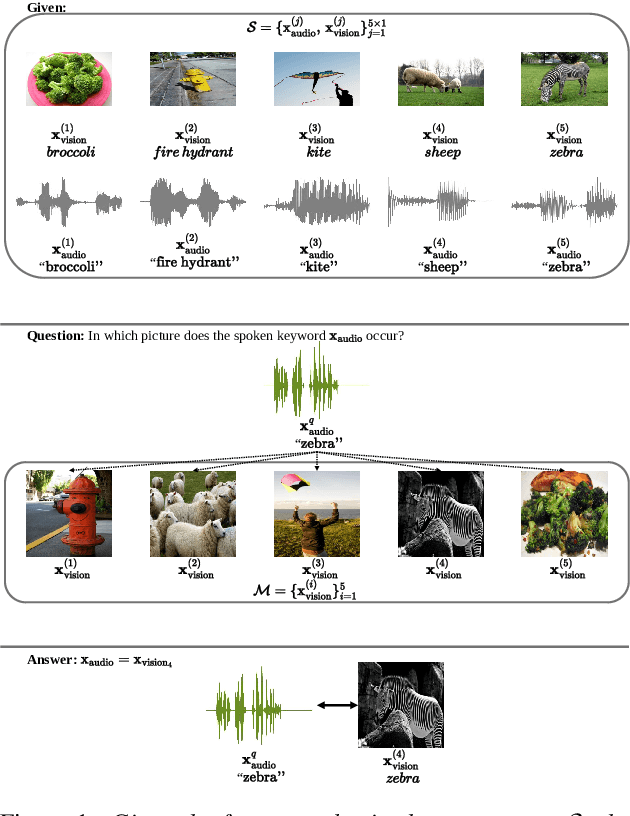

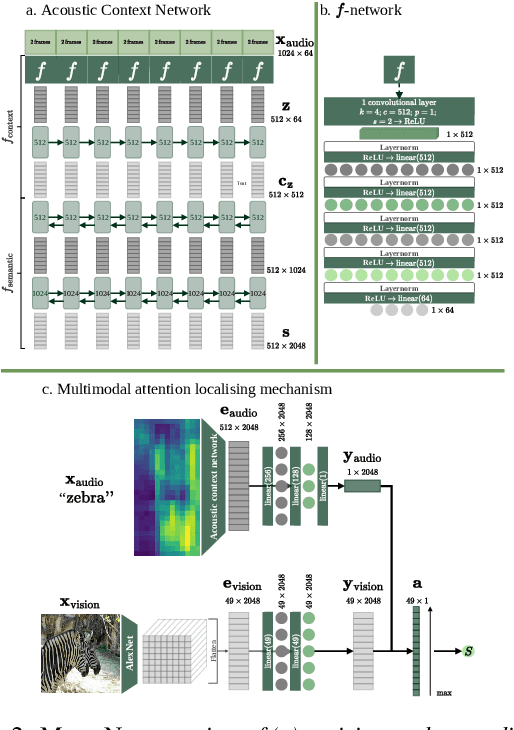
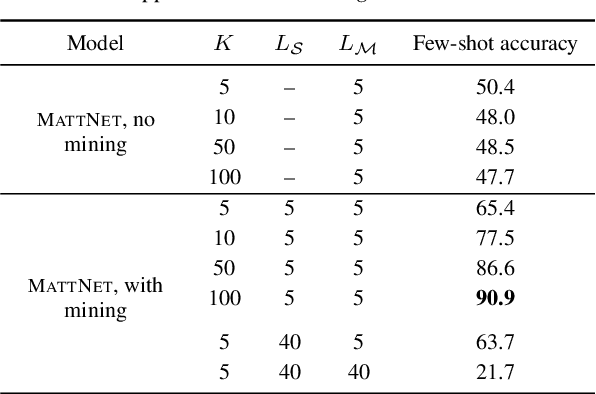
We propose a visually grounded speech model that acquires new words and their visual depictions from just a few word-image example pairs. Given a set of test images and a spoken query, we ask the model which image depicts the query word. Previous work has simplified this problem by either using an artificial setting with digit word-image pairs or by using a large number of examples per class. We propose an approach that can work on natural word-image pairs but with less examples, i.e. fewer shots. Our approach involves using the given word-image example pairs to mine new unsupervised word-image training pairs from large collections of unlabelled speech and images. Additionally, we use a word-to-image attention mechanism to determine word-image similarity. With this new model, we achieve better performance with fewer shots than any existing approach.
Probabilistic Risk Assessment of an Obstacle Detection System for GoA 4 Freight Trains
Jun 26, 2023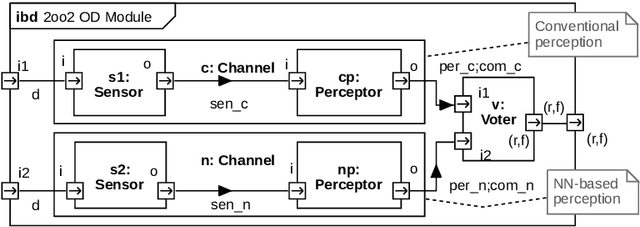

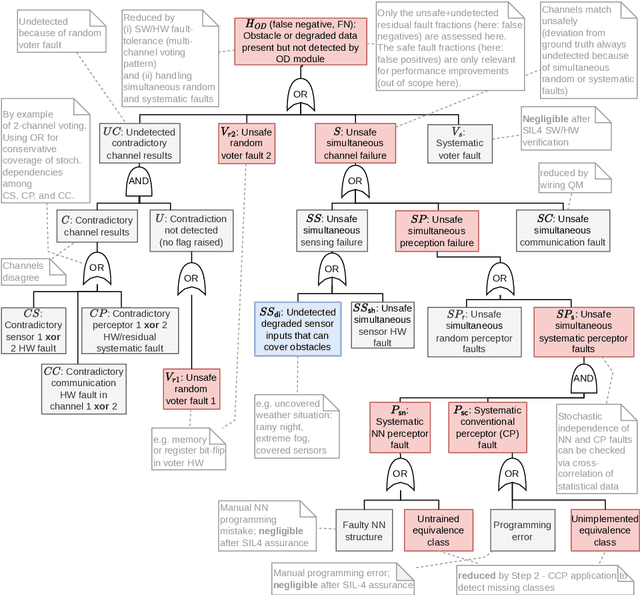
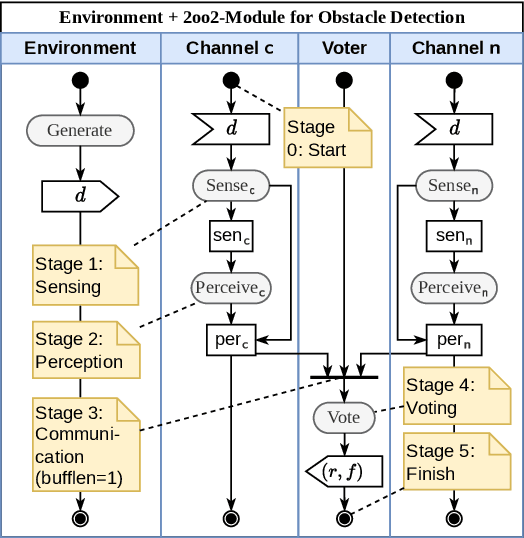
In this paper, a quantitative risk assessment approach is discussed for the design of an obstacle detection function for low-speed freight trains with grade of automation (GoA)~4. In this 5-step approach, starting with single detection channels and ending with a three-out-of-three (3oo3) model constructed of three independent dual-channel modules and a voter, a probabilistic assessment is exemplified, using a combination of statistical methods and parametric stochastic model checking. It is illustrated that, under certain not unreasonable assumptions, the resulting hazard rate becomes acceptable for specific application settings. The statistical approach for assessing the residual risk of misclassifications in convolutional neural networks and conventional image processing software suggests that high confidence can be placed into the safety-critical obstacle detection function, even though its implementation involves realistic machine learning uncertainties.
Toward Fairness Through Fair Multi-Exit Framework for Dermatological Disease Diagnosis
Jun 26, 2023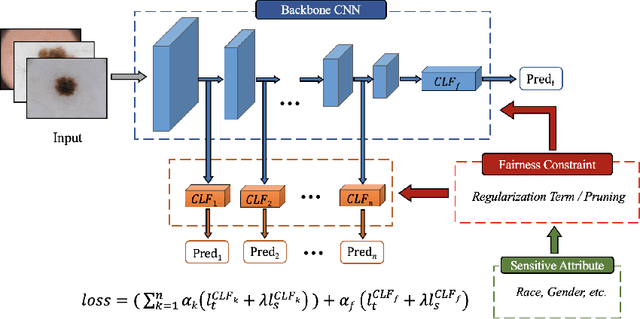
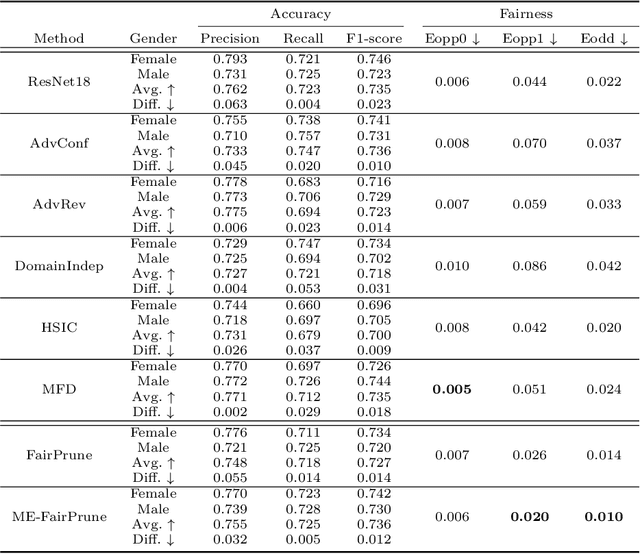
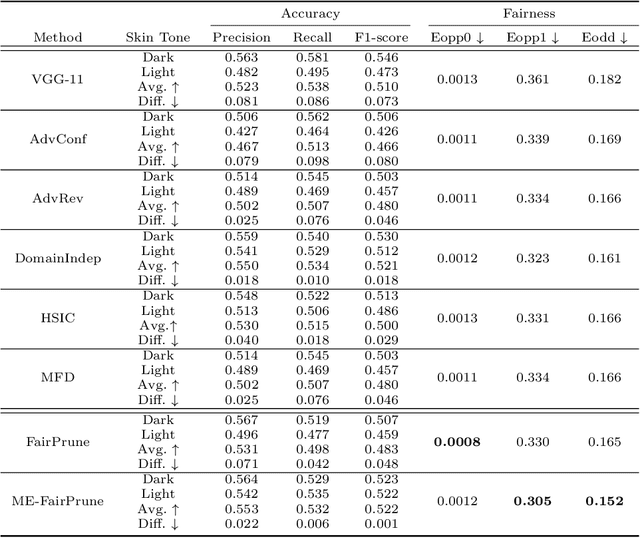
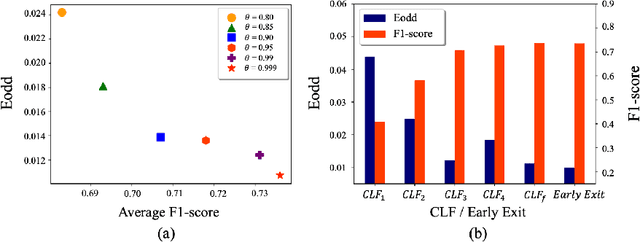
Fairness has become increasingly pivotal in medical image recognition. However, without mitigating bias, deploying unfair medical AI systems could harm the interests of underprivileged populations. In this paper, we observe that while features extracted from the deeper layers of neural networks generally offer higher accuracy, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit frameworks. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented; the internal classifiers are trained to be more accurate and fairer, with high extensibility to apply to most existing fairness-aware frameworks. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Experimental results show that the proposed framework can improve the fairness condition over the state-of-the-art in two dermatological disease datasets.