 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Total Online Unsupervised Anomaly Detection and Localization in Industrial Vision
May 25, 2023
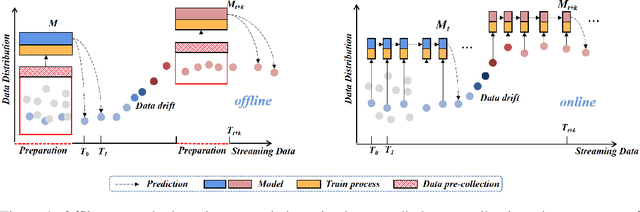

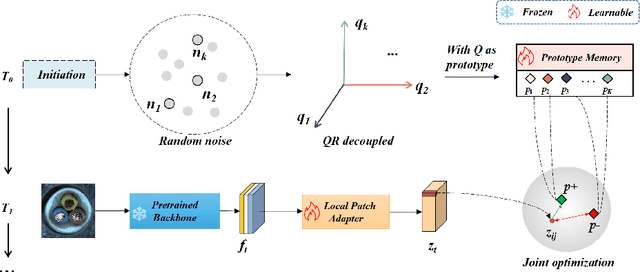
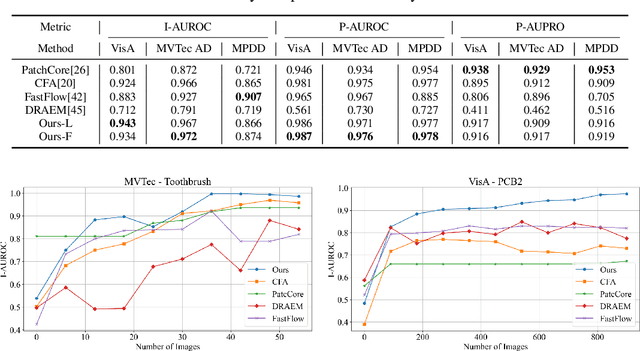
Although existing image anomaly detection methods yield impressive results, they are mostly an offline learning paradigm that requires excessive data pre-collection, limiting their adaptability in industrial scenarios with online streaming data. Online learning-based image anomaly detection methods are more compatible with industrial online streaming data but are rarely noticed. For the first time, this paper presents a fully online learning image anomaly detection method, namely LeMO, learning memory for online image anomaly detection. LeMO leverages learnable memory initialized with orthogonal random noise, eliminating the need for excessive data in memory initialization and circumventing the inefficiencies of offline data collection. Moreover, a contrastive learning-based loss function for anomaly detection is designed to enable online joint optimization of memory and image target-oriented features. The presented method is simple and highly effective. Extensive experiments demonstrate the superior performance of LeMO in the online setting. Additionally, in the offline setting, LeMO is also competitive with the current state-of-the-art methods and achieves excellent performance in few-shot scenarios.
Towards Open-Scenario Semi-supervised Medical Image Classification
Apr 08, 2023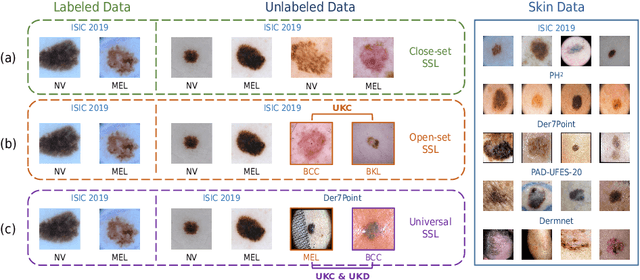
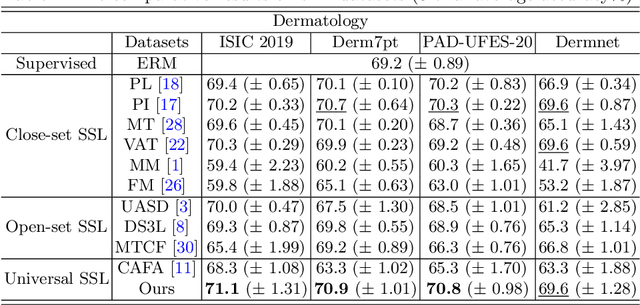
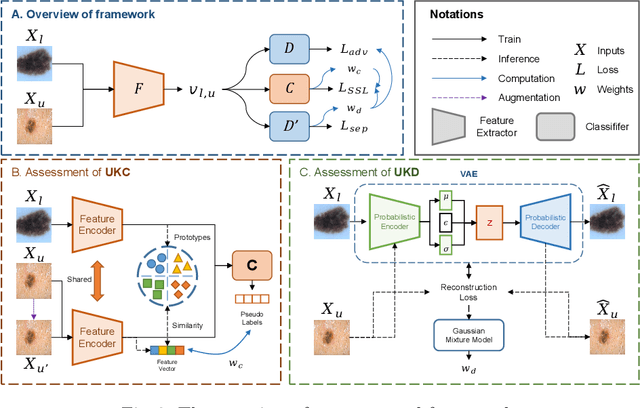
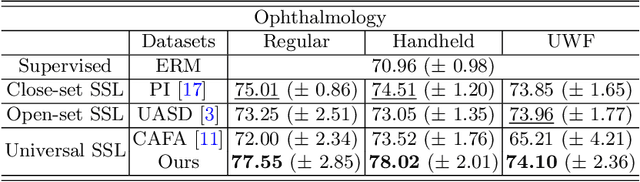
Semi-supervised learning (SSL) has attracted much attention since it reduces the expensive costs of collecting adequate well-labeled training data, especially for deep learning methods. However, traditional SSL is built upon an assumption that labeled and unlabeled data should be from the same distribution e.g., classes and domains. However, in practical scenarios, unlabeled data would be from unseen classes or unseen domains, and it is still challenging to exploit them by existing SSL methods. Therefore, in this paper, we proposed a unified framework to leverage these unseen unlabeled data for open-scenario semi-supervised medical image classification. We first design a novel scoring mechanism, called dual-path outliers estimation, to identify samples from unseen classes. Meanwhile, to extract unseen-domain samples, we then apply an effective variational autoencoder (VAE) pre-training. After that, we conduct domain adaptation to fully exploit the value of the detected unseen-domain samples to boost semi-supervised training. We evaluated our proposed framework on dermatology and ophthalmology tasks. Extensive experiments demonstrate our model can achieve superior classification performance in various medical SSL scenarios.
Dense Pixel-to-Pixel Harmonization via Continuous Image Representation
Mar 03, 2023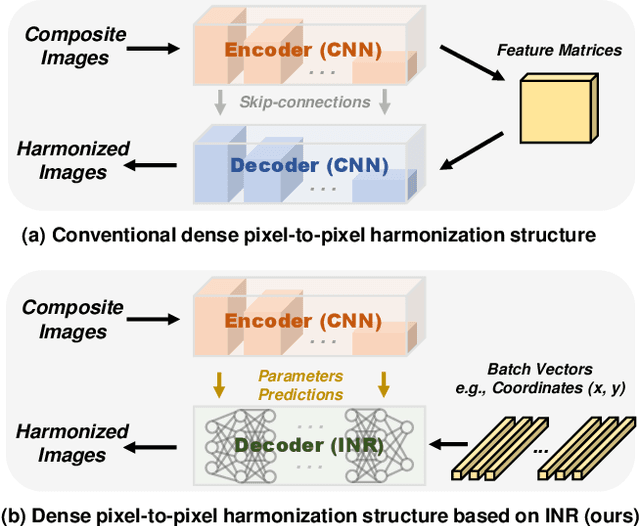
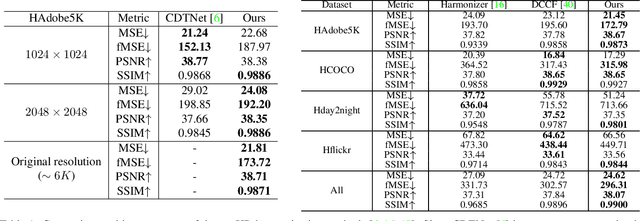
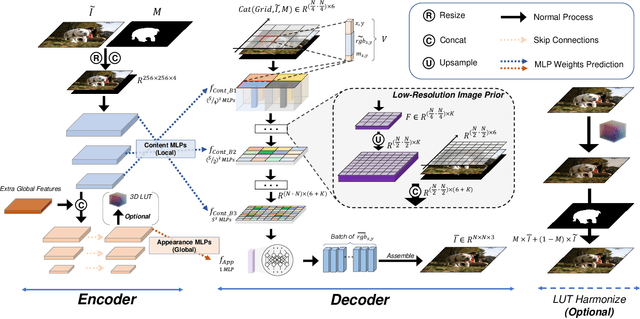
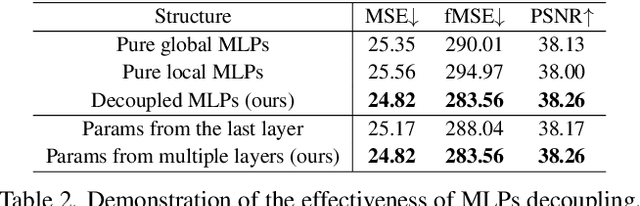
High-resolution (HR) image harmonization is of great significance in real-world applications such as image synthesis and image editing. However, due to the high memory costs, existing dense pixel-to-pixel harmonization methods are mainly focusing on processing low-resolution (LR) images. Some recent works resort to combining with color-to-color transformations but are either limited to certain resolutions or heavily depend on hand-crafted image filters. In this work, we explore leveraging the implicit neural representation (INR) and propose a novel image Harmonization method based on Implicit neural Networks (HINet), which to the best of our knowledge, is the first dense pixel-to-pixel method applicable to HR images without any hand-crafted filter design. Inspired by the Retinex theory, we decouple the MLPs into two parts to respectively capture the content and environment of composite images. A Low-Resolution Image Prior (LRIP) network is designed to alleviate the Boundary Inconsistency problem, and we also propose new designs for the training and inference process. Extensive experiments have demonstrated the effectiveness of our method compared with state-of-the-art methods. Furthermore, some interesting and practical applications of the proposed method are explored. Our code will be available at https://github.com/WindVChen/INR-Harmonization.
PuMer: Pruning and Merging Tokens for Efficient Vision Language Models
May 27, 2023
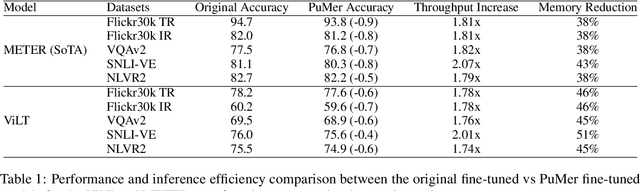
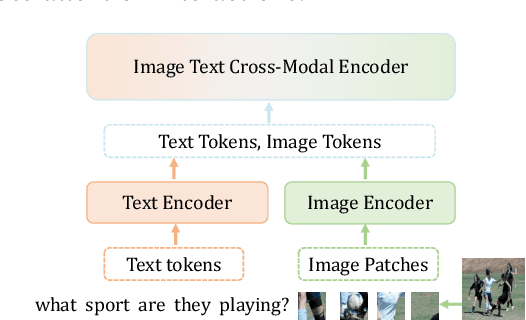
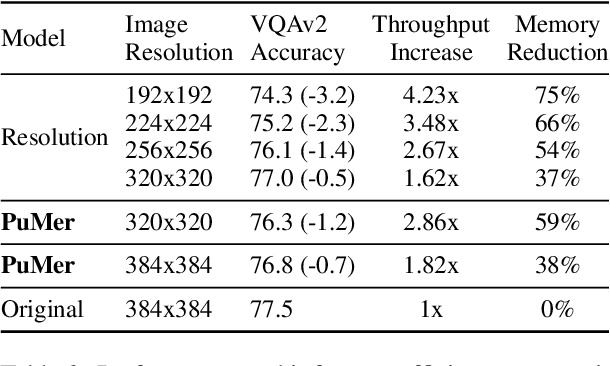
Large-scale vision language (VL) models use Transformers to perform cross-modal interactions between the input text and image. These cross-modal interactions are computationally expensive and memory-intensive due to the quadratic complexity of processing the input image and text. We present PuMer: a token reduction framework that uses text-informed Pruning and modality-aware Merging strategies to progressively reduce the tokens of input image and text, improving model inference speed and reducing memory footprint. PuMer learns to keep salient image tokens related to the input text and merges similar textual and visual tokens by adding lightweight token reducer modules at several cross-modal layers in the VL model. Training PuMer is mostly the same as finetuning the original VL model but faster. Our evaluation for two vision language models on four downstream VL tasks shows PuMer increases inference throughput by up to 2x and reduces memory footprint by over 50% while incurring less than a 1% accuracy drop.
S-CLIP: Semi-supervised Vision-Language Pre-training using Few Specialist Captions
May 23, 2023
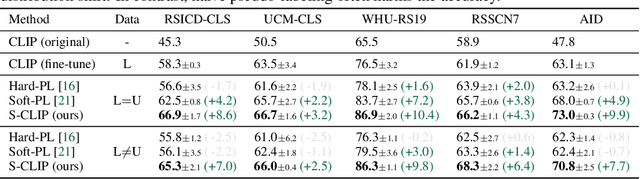

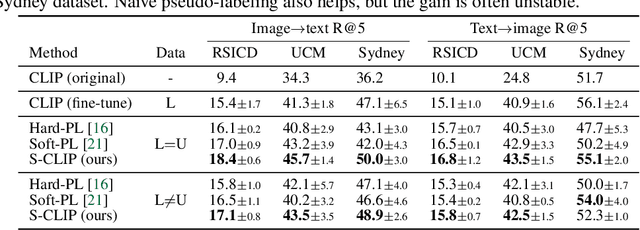
Vision-language models, such as contrastive language-image pre-training (CLIP), have demonstrated impressive results in natural image domains. However, these models often struggle when applied to specialized domains like remote sensing, and adapting to such domains is challenging due to the limited number of image-text pairs available for training. To address this, we propose S-CLIP, a semi-supervised learning method for training CLIP that utilizes additional unpaired images. S-CLIP employs two pseudo-labeling strategies specifically designed for contrastive learning and the language modality. The caption-level pseudo-label is given by a combination of captions of paired images, obtained by solving an optimal transport problem between unpaired and paired images. The keyword-level pseudo-label is given by a keyword in the caption of the nearest paired image, trained through partial label learning that assumes a candidate set of labels for supervision instead of the exact one. By combining these objectives, S-CLIP significantly enhances the training of CLIP using only a few image-text pairs, as demonstrated in various specialist domains, including remote sensing, fashion, scientific figures, and comics. For instance, S-CLIP improves CLIP by 10% for zero-shot classification and 4% for image-text retrieval on the remote sensing benchmark, matching the performance of supervised CLIP while using three times fewer image-text pairs.
Deep Learning of Dynamical System Parameters from Return Maps as Images
Jun 20, 2023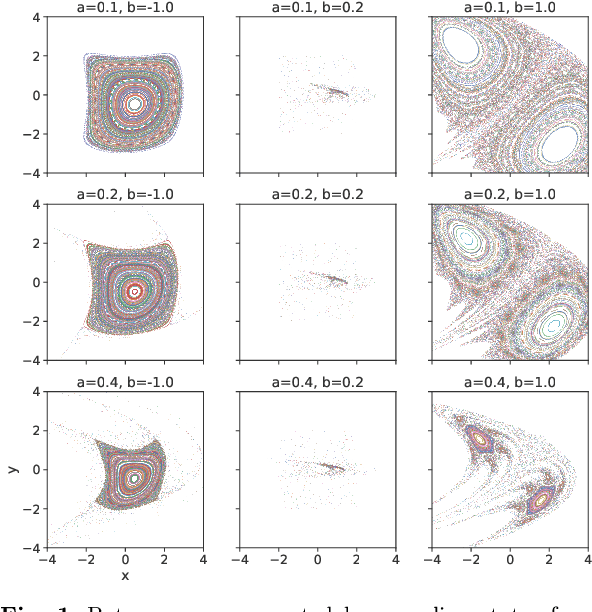
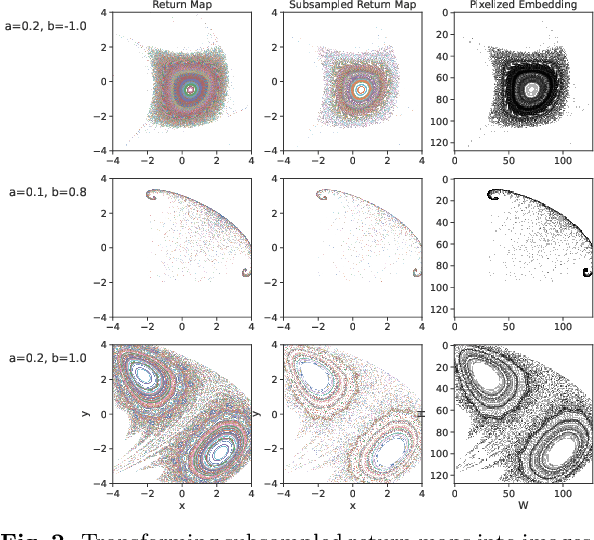
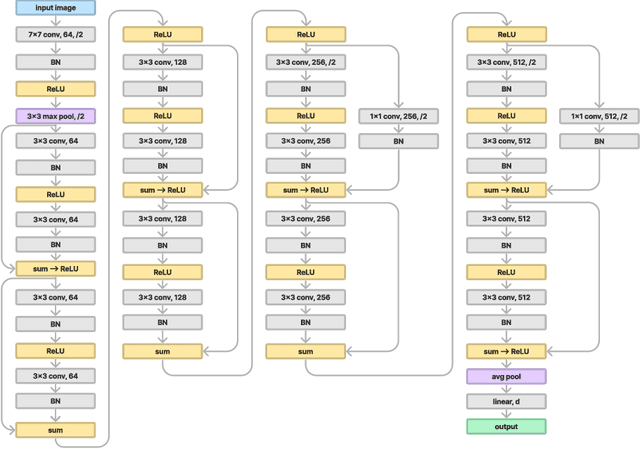
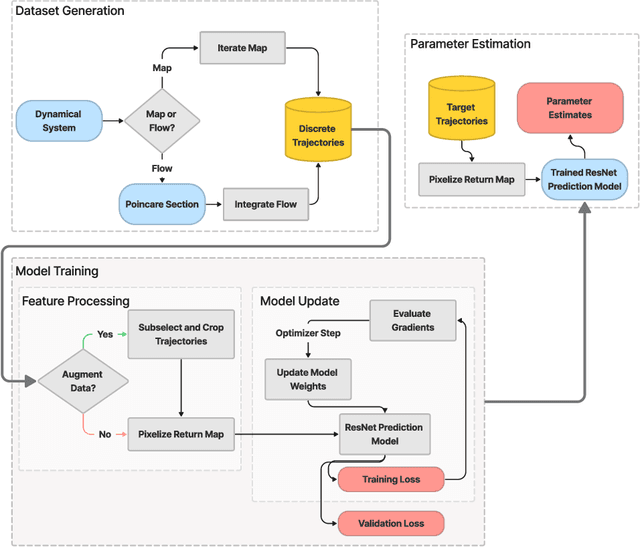
We present a novel approach to system identification (SI) using deep learning techniques. Focusing on parametric system identification (PSI), we use a supervised learning approach for estimating the parameters of discrete and continuous-time dynamical systems, irrespective of chaos. To accomplish this, we transform collections of state-space trajectory observations into image-like data to retain the state-space topology of trajectories from dynamical systems and train convolutional neural networks to estimate the parameters of dynamical systems from these images. We demonstrate that our approach can learn parameter estimation functions for various dynamical systems, and by using training-time data augmentation, we are able to learn estimation functions whose parameter estimates are robust to changes in the sample fidelity of their inputs. Once trained, these estimation models return parameter estimations for new systems with negligible time and computation costs.
A Prompt Log Analysis of Text-to-Image Generation Systems
Mar 16, 2023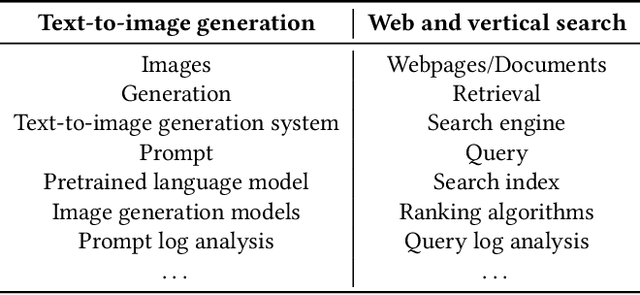
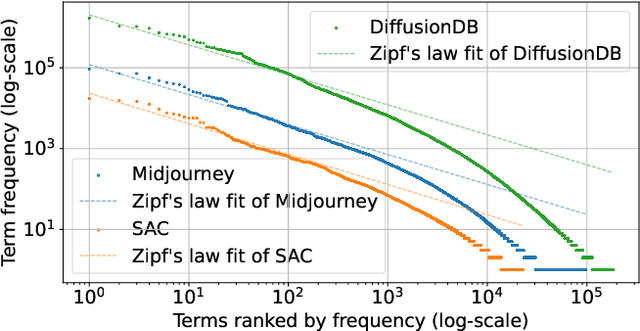
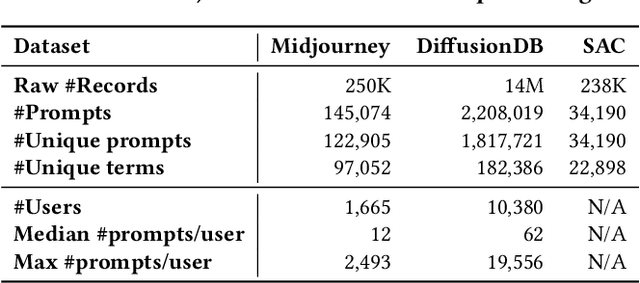
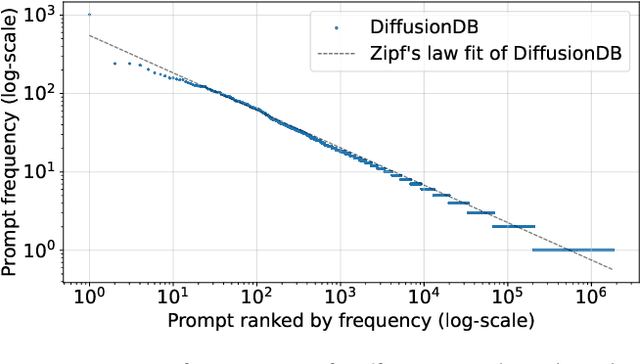
Recent developments in large language models (LLM) and generative AI have unleashed the astonishing capabilities of text-to-image generation systems to synthesize high-quality images that are faithful to a given reference text, known as a "prompt". These systems have immediately received lots of attention from researchers, creators, and common users. Despite the plenty of efforts to improve the generative models, there is limited work on understanding the information needs of the users of these systems at scale. We conduct the first comprehensive analysis of large-scale prompt logs collected from multiple text-to-image generation systems. Our work is analogous to analyzing the query logs of Web search engines, a line of work that has made critical contributions to the glory of the Web search industry and research. Compared with Web search queries, text-to-image prompts are significantly longer, often organized into special structures that consist of the subject, form, and intent of the generation tasks and present unique categories of information needs. Users make more edits within creation sessions, which present remarkable exploratory patterns. There is also a considerable gap between the user-input prompts and the captions of the images included in the open training data of the generative models. Our findings provide concrete implications on how to improve text-to-image generation systems for creation purposes.
A Comprehensive Review of Image Line Segment Detection and Description: Taxonomies, Comparisons, and Challenges
Apr 29, 2023

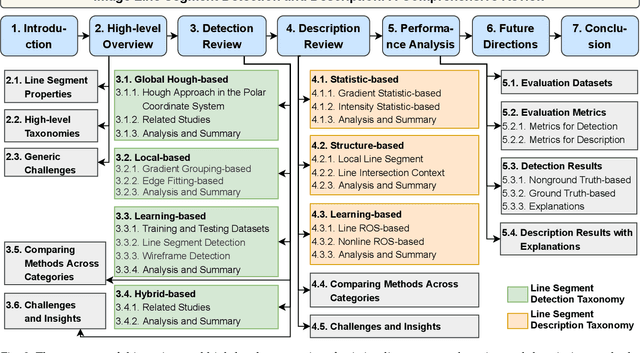
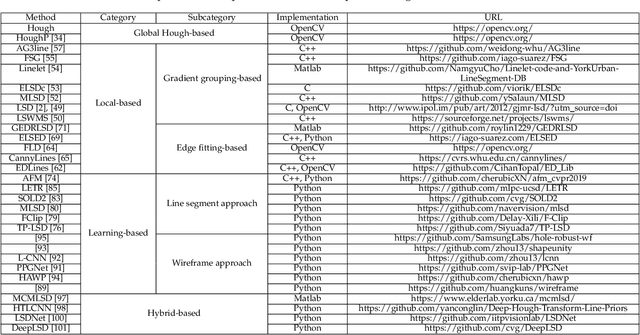
Detection and description of line segments lay the basis for numerous vision tasks. Although many studies have aimed to detect and describe line segments, a comprehensive review is lacking, obstructing their progress. This study fills the gap by comprehensively reviewing related studies on detecting and describing two-dimensional image line segments to provide researchers with an overall picture and deep understanding. Based on their mechanisms, two taxonomies for line segment detection and description are presented to introduce, analyze, and summarize these studies, facilitating researchers to learn about them quickly and extensively. The key issues, core ideas, advantages and disadvantages of existing methods, and their potential applications for each category are analyzed and summarized, including previously unknown findings. The challenges in existing methods and corresponding insights for potentially solving them are also provided to inspire researchers. In addition, some state-of-the-art line segment detection and description algorithms are evaluated without bias, and the evaluation code will be publicly available. The theoretical analysis, coupled with the experimental results, can guide researchers in selecting the best method for their intended vision applications. Finally, this study provides insights for potentially interesting future research directions to attract more attention from researchers to this field.
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Jun 23, 2023
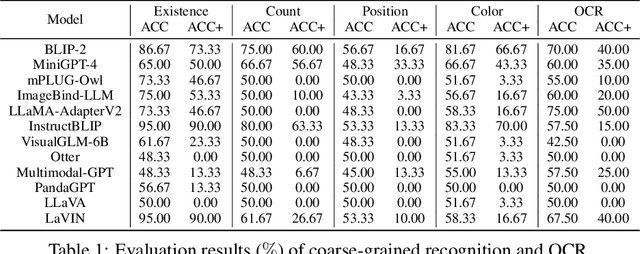
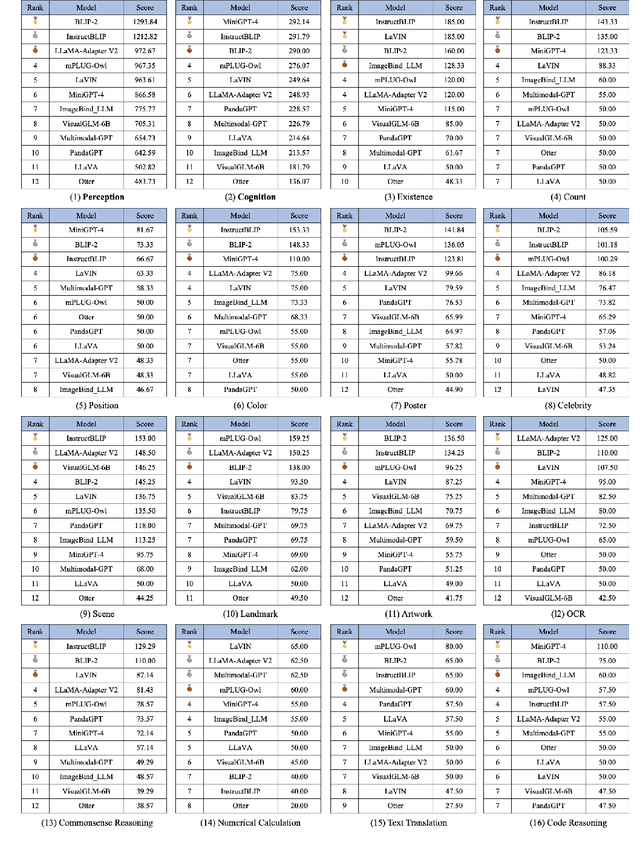
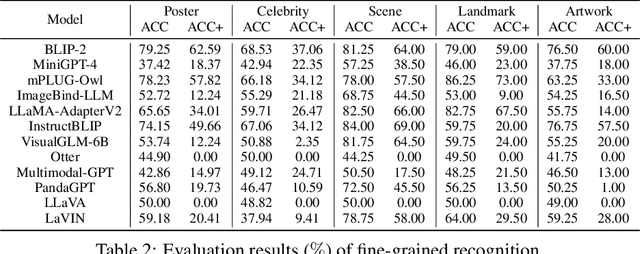
Multimodal Large Language Model (MLLM) relies on the powerful LLM to perform multimodal tasks, showing amazing emergent abilities in recent studies, such as writing poems based on an image. However, it is difficult for these case studies to fully reflect the performance of MLLM, lacking a comprehensive evaluation. In this paper, we fill in this blank, presenting the first MLLM Evaluation benchmark MME. It measures both perception and cognition abilities on a total of 14 subtasks. In order to avoid data leakage that may arise from direct use of public datasets for evaluation, the annotations of instruction-answer pairs are all manually designed. The concise instruction design allows us to fairly compare MLLMs, instead of struggling in prompt engineering. Besides, with such an instruction, we can also easily carry out quantitative statistics. A total of 10 advanced MLLMs are comprehensively evaluated on our MME, which not only suggests that existing MLLMs still have a large room for improvement, but also reveals the potential directions for the subsequent model optimization.
Entity-Level Text-Guided Image Manipulation
Feb 22, 2023


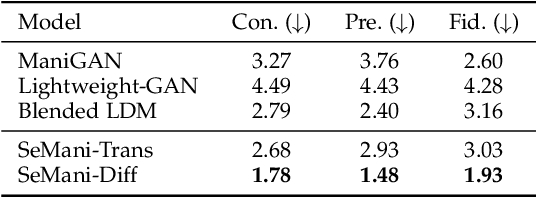
Existing text-guided image manipulation methods aim to modify the appearance of the image or to edit a few objects in a virtual or simple scenario, which is far from practical applications. In this work, we study a novel task on text-guided image manipulation on the entity level in the real world (eL-TGIM). The task imposes three basic requirements, (1) to edit the entity consistent with the text descriptions, (2) to preserve the entity-irrelevant regions, and (3) to merge the manipulated entity into the image naturally. To this end, we propose an elegant framework, dubbed as SeMani, forming the Semantic Manipulation of real-world images that can not only edit the appearance of entities but also generate new entities corresponding to the text guidance. To solve eL-TGIM, SeMani decomposes the task into two phases: the semantic alignment phase and the image manipulation phase. In the semantic alignment phase, SeMani incorporates a semantic alignment module to locate the entity-relevant region to be manipulated. In the image manipulation phase, SeMani adopts a generative model to synthesize new images conditioned on the entity-irrelevant regions and target text descriptions. We discuss and propose two popular generation processes that can be utilized in SeMani, the discrete auto-regressive generation with transformers and the continuous denoising generation with diffusion models, yielding SeMani-Trans and SeMani-Diff, respectively. We conduct extensive experiments on the real datasets CUB, Oxford, and COCO datasets to verify that SeMani can distinguish the entity-relevant and -irrelevant regions and achieve more precise and flexible manipulation in a zero-shot manner compared with baseline methods. Our codes and models will be released at https://github.com/Yikai-Wang/SeMani.