 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LayoutMask: Enhance Text-Layout Interaction in Multi-modal Pre-training for Document Understanding
Jun 09, 2023
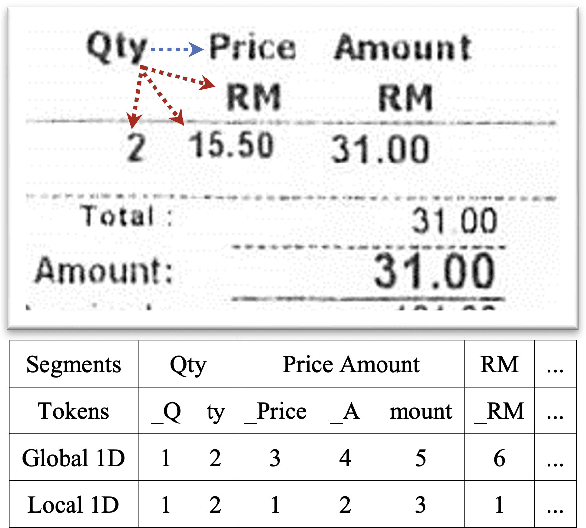
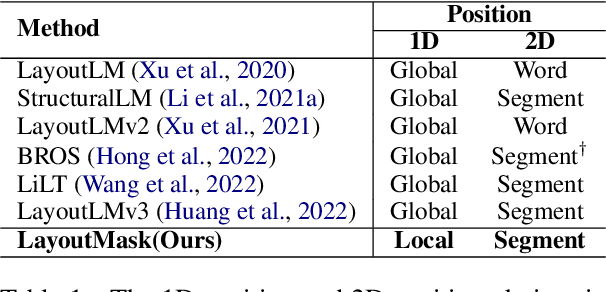
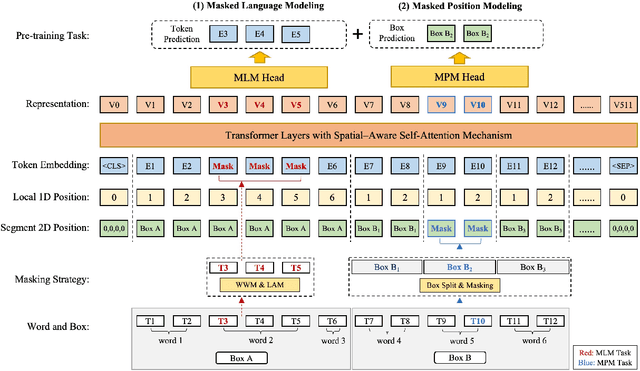
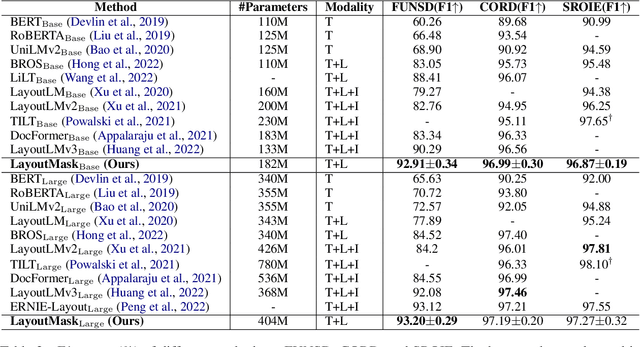
Visually-rich Document Understanding (VrDU) has attracted much research attention over the past years. Pre-trained models on a large number of document images with transformer-based backbones have led to significant performance gains in this field. The major challenge is how to fusion the different modalities (text, layout, and image) of the documents in a unified model with different pre-training tasks. This paper focuses on improving text-layout interactions and proposes a novel multi-modal pre-training model, LayoutMask. LayoutMask uses local 1D position, instead of global 1D position, as layout input and has two pre-training objectives: (1) Masked Language Modeling: predicting masked tokens with two novel masking strategies; (2) Masked Position Modeling: predicting masked 2D positions to improve layout representation learning. LayoutMask can enhance the interactions between text and layout modalities in a unified model and produce adaptive and robust multi-modal representations for downstream tasks. Experimental results show that our proposed method can achieve state-of-the-art results on a wide variety of VrDU problems, including form understanding, receipt understanding, and document image classification.
Better speech synthesis through scaling
May 23, 2023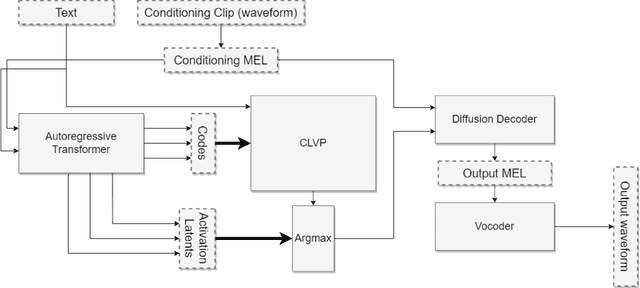

In recent years, the field of image generation has been revolutionized by the application of autoregressive transformers and DDPMs. These approaches model the process of image generation as a step-wise probabilistic processes and leverage large amounts of compute and data to learn the image distribution. This methodology of improving performance need not be confined to images. This paper describes a way to apply advances in the image generative domain to speech synthesis. The result is TorToise -- an expressive, multi-voice text-to-speech system. All model code and trained weights have been open-sourced at https://github.com/neonbjb/tortoise-tts.
Towards Total Online Unsupervised Anomaly Detection and Localization in Industrial Vision
May 25, 2023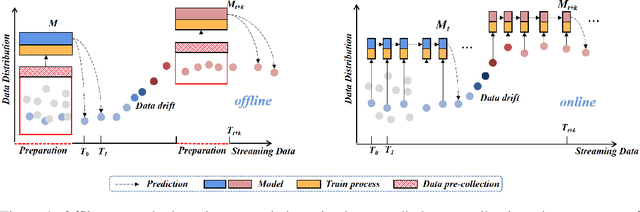

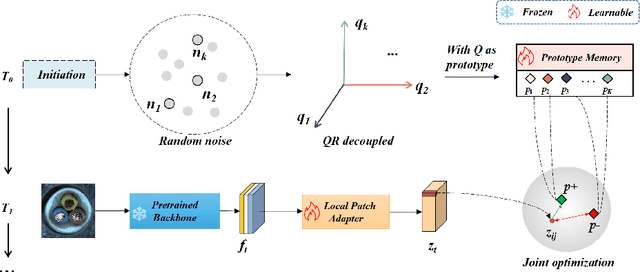
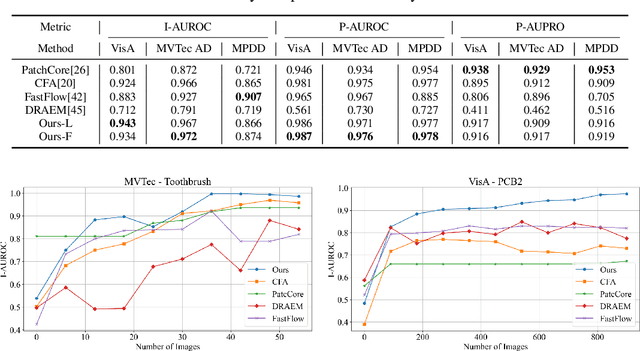
Although existing image anomaly detection methods yield impressive results, they are mostly an offline learning paradigm that requires excessive data pre-collection, limiting their adaptability in industrial scenarios with online streaming data. Online learning-based image anomaly detection methods are more compatible with industrial online streaming data but are rarely noticed. For the first time, this paper presents a fully online learning image anomaly detection method, namely LeMO, learning memory for online image anomaly detection. LeMO leverages learnable memory initialized with orthogonal random noise, eliminating the need for excessive data in memory initialization and circumventing the inefficiencies of offline data collection. Moreover, a contrastive learning-based loss function for anomaly detection is designed to enable online joint optimization of memory and image target-oriented features. The presented method is simple and highly effective. Extensive experiments demonstrate the superior performance of LeMO in the online setting. Additionally, in the offline setting, LeMO is also competitive with the current state-of-the-art methods and achieves excellent performance in few-shot scenarios.
Medical Federated Model with Mixture of Personalized and Sharing Components
Jun 26, 2023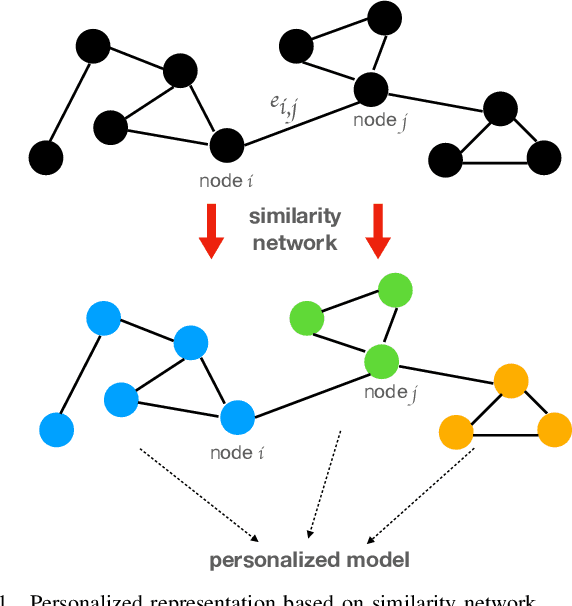
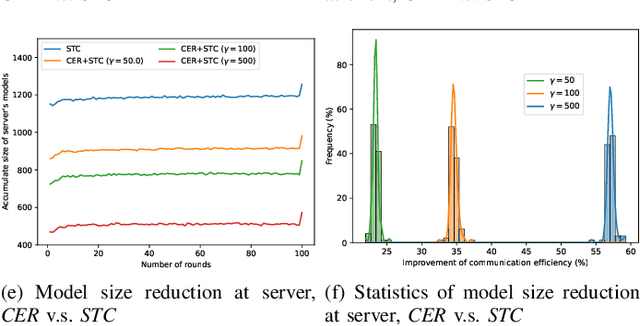

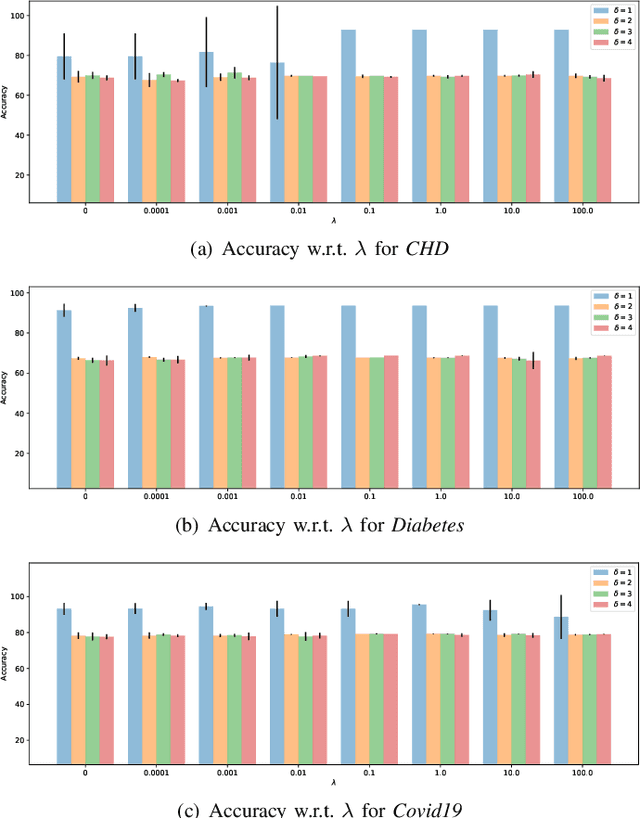
Although data-driven methods usually have noticeable performance on disease diagnosis and treatment, they are suspected of leakage of privacy due to collecting data for model training. Recently, federated learning provides a secure and trustable alternative to collaboratively train model without any exchange of medical data among multiple institutes. Therefore, it has draw much attention due to its natural merit on privacy protection. However, when heterogenous medical data exists between different hospitals, federated learning usually has to face with degradation of performance. In the paper, we propose a new personalized framework of federated learning to handle the problem. It successfully yields personalized models based on awareness of similarity between local data, and achieves better tradeoff between generalization and personalization than existing methods. After that, we further design a differentially sparse regularizer to improve communication efficiency during procedure of model training. Additionally, we propose an effective method to reduce the computational cost, which improves computation efficiency significantly. Furthermore, we collect 5 real medical datasets, including 2 public medical image datasets and 3 private multi-center clinical diagnosis datasets, and evaluate its performance by conducting nodule classification, tumor segmentation, and clinical risk prediction tasks. Comparing with 13 existing related methods, the proposed method successfully achieves the best model performance, and meanwhile up to 60% improvement of communication efficiency. Source code is public, and can be accessed at: https://github.com/ApplicationTechnologyOfMedicalBigData/pFedNet-code.
ResDiff: Combining CNN and Diffusion Model for Image Super-Resolution
Mar 15, 2023
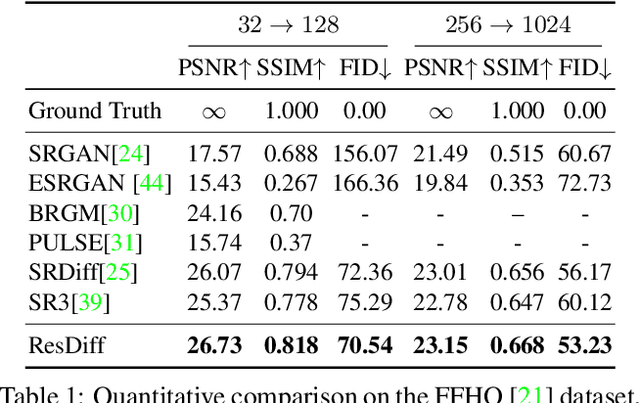
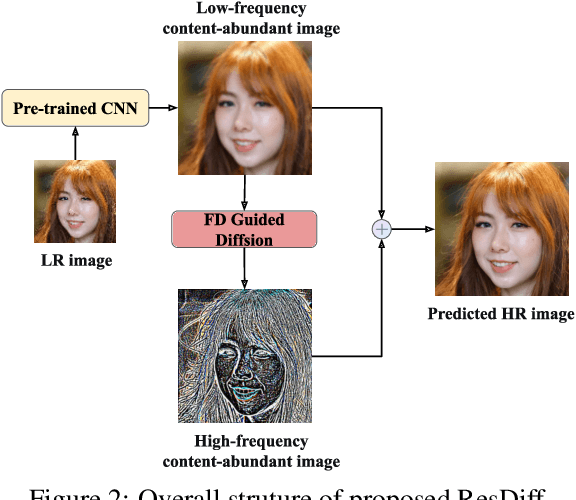
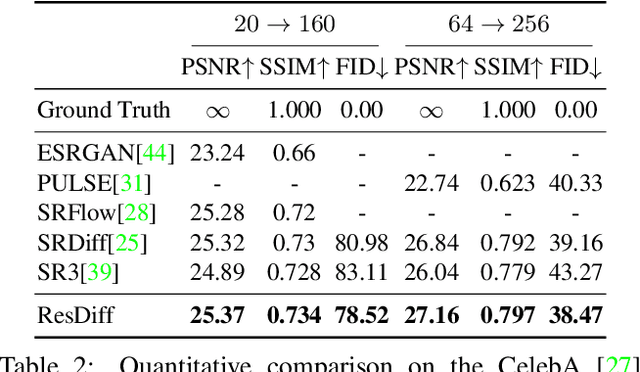
Adapting the Diffusion Probabilistic Model (DPM) for direct image super-resolution is wasteful, given that a simple Convolutional Neural Network (CNN) can recover the main low-frequency content. Therefore, we present ResDiff, a novel Diffusion Probabilistic Model based on Residual structure for Single Image Super-Resolution (SISR). ResDiff utilizes a combination of a CNN, which restores primary low-frequency components, and a DPM, which predicts the residual between the ground-truth image and the CNN-predicted image. In contrast to the common diffusion-based methods that directly use LR images to guide the noise towards HR space, ResDiff utilizes the CNN's initial prediction to direct the noise towards the residual space between HR space and CNN-predicted space, which not only accelerates the generation process but also acquires superior sample quality. Additionally, a frequency-domain-based loss function for CNN is introduced to facilitate its restoration, and a frequency-domain guided diffusion is designed for DPM on behalf of predicting high-frequency details. The extensive experiments on multiple benchmark datasets demonstrate that ResDiff outperforms previous diffusion-based methods in terms of shorter model convergence time, superior generation quality, and more diverse samples.
S-TLLR: STDP-inspired Temporal Local Learning Rule for Spiking Neural Networks
Jun 27, 2023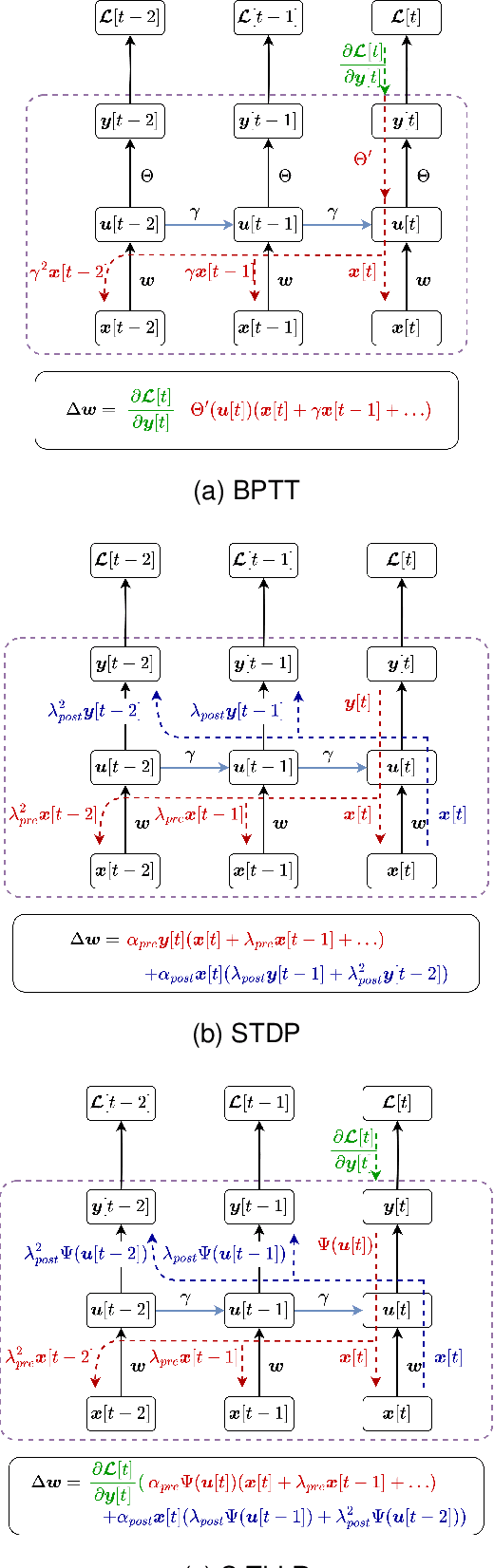
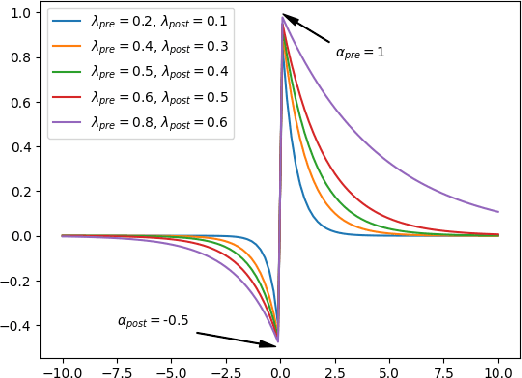
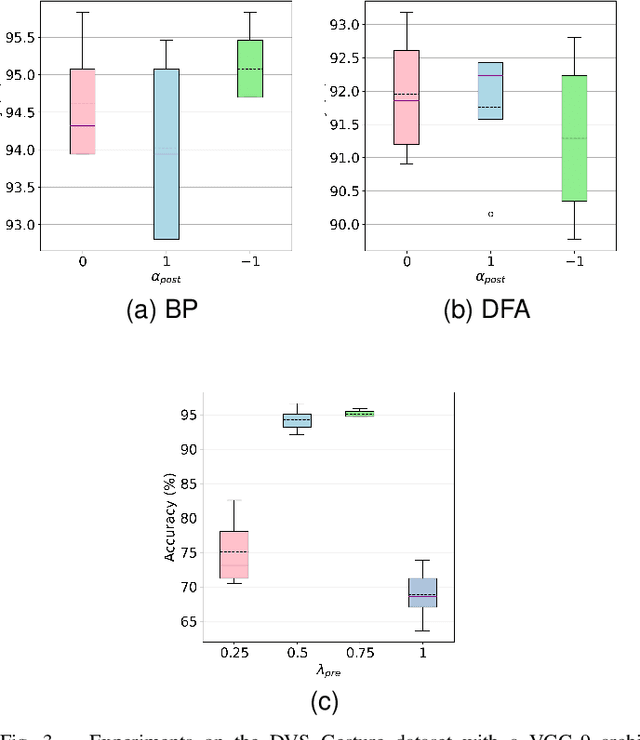
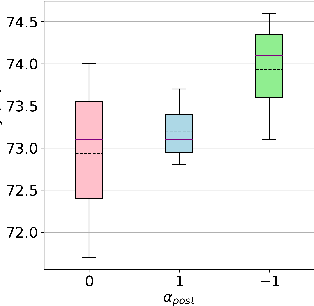
Spiking Neural Networks (SNNs) are biologically plausible models that have been identified as potentially apt for the deployment for energy-efficient intelligence at the edge, particularly for sequential learning tasks. However, training of SNNs poses a significant challenge due to the necessity for precise temporal and spatial credit assignment. Back-propagation through time (BPTT) algorithm, whilst being the most widely used method for addressing these issues, incurs a high computational cost due to its temporal dependency. Moreover, BPTT and its approximations solely utilize causal information derived from the spiking activity to compute the synaptic updates, thus neglecting non-causal relationships. In this work, we propose S-TLLR, a novel three-factor temporal local learning rule inspired by the Spike-Timing Dependent Plasticity (STDP) mechanism, aimed at training SNNs on event-based learning tasks. S-TLLR considers both causal and non-causal relationships between pre and post-synaptic activities, achieving performance comparable to BPTT and enhancing performance relative to methods using only causal information. Furthermore, S-TLLR has low memory and time complexity, which is independent of the number of time steps, rendering it suitable for online learning on low-power devices. To demonstrate the scalability of our proposed method, we have conducted extensive evaluations on event-based datasets spanning a wide range of applications, such as image and gesture recognition, audio classification, and optical flow estimation. In all the experiments, S-TLLR achieved high accuracy with a reduction in the number of computations between $1.1-10\times$.
Novel Hybrid-Learning Algorithms for Improved Millimeter-Wave Imaging Systems
Jun 27, 2023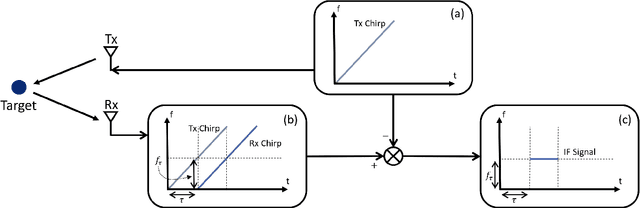
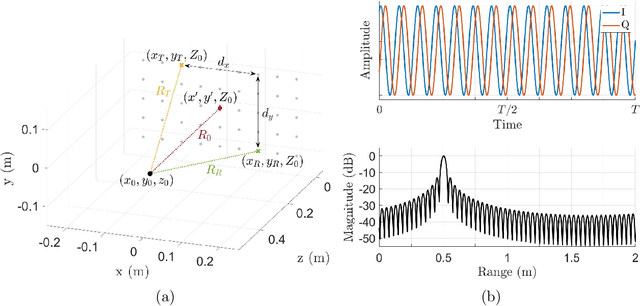

Increasing attention is being paid to millimeter-wave (mmWave), 30 GHz to 300 GHz, and terahertz (THz), 300 GHz to 10 THz, sensing applications including security sensing, industrial packaging, medical imaging, and non-destructive testing. Traditional methods for perception and imaging are challenged by novel data-driven algorithms that offer improved resolution, localization, and detection rates. Over the past decade, deep learning technology has garnered substantial popularity, particularly in perception and computer vision applications. Whereas conventional signal processing techniques are more easily generalized to various applications, hybrid approaches where signal processing and learning-based algorithms are interleaved pose a promising compromise between performance and generalizability. Furthermore, such hybrid algorithms improve model training by leveraging the known characteristics of radio frequency (RF) waveforms, thus yielding more efficiently trained deep learning algorithms and offering higher performance than conventional methods. This dissertation introduces novel hybrid-learning algorithms for improved mmWave imaging systems applicable to a host of problems in perception and sensing. Various problem spaces are explored, including static and dynamic gesture classification; precise hand localization for human computer interaction; high-resolution near-field mmWave imaging using forward synthetic aperture radar (SAR); SAR under irregular scanning geometries; mmWave image super-resolution using deep neural network (DNN) and Vision Transformer (ViT) architectures; and data-level multiband radar fusion using a novel hybrid-learning architecture. Furthermore, we introduce several novel approaches for deep learning model training and dataset synthesis.
HeadSculpt: Crafting 3D Head Avatars with Text
Jun 05, 2023
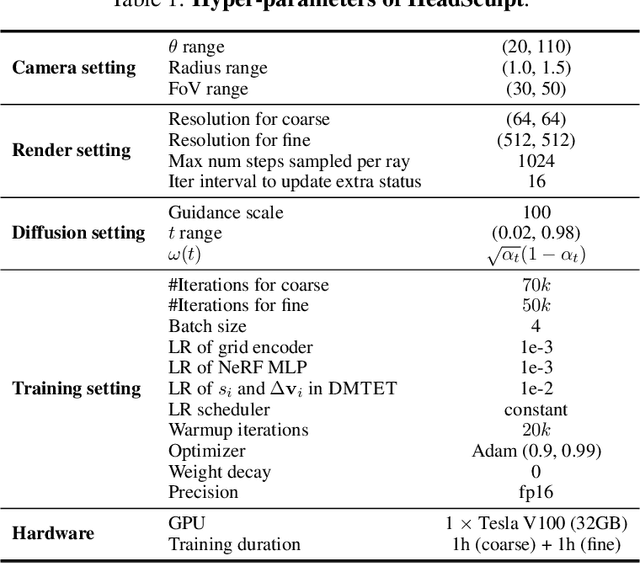
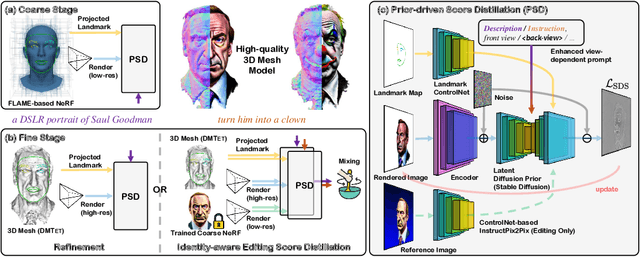

Recently, text-guided 3D generative methods have made remarkable advancements in producing high-quality textures and geometry, capitalizing on the proliferation of large vision-language and image diffusion models. However, existing methods still struggle to create high-fidelity 3D head avatars in two aspects: (1) They rely mostly on a pre-trained text-to-image diffusion model whilst missing the necessary 3D awareness and head priors. This makes them prone to inconsistency and geometric distortions in the generated avatars. (2) They fall short in fine-grained editing. This is primarily due to the inherited limitations from the pre-trained 2D image diffusion models, which become more pronounced when it comes to 3D head avatars. In this work, we address these challenges by introducing a versatile coarse-to-fine pipeline dubbed HeadSculpt for crafting (i.e., generating and editing) 3D head avatars from textual prompts. Specifically, we first equip the diffusion model with 3D awareness by leveraging landmark-based control and a learned textual embedding representing the back view appearance of heads, enabling 3D-consistent head avatar generations. We further propose a novel identity-aware editing score distillation strategy to optimize a textured mesh with a high-resolution differentiable rendering technique. This enables identity preservation while following the editing instruction. We showcase HeadSculpt's superior fidelity and editing capabilities through comprehensive experiments and comparisons with existing methods.
Denoising Diffusion Post-Processing for Low-Light Image Enhancement
Mar 16, 2023

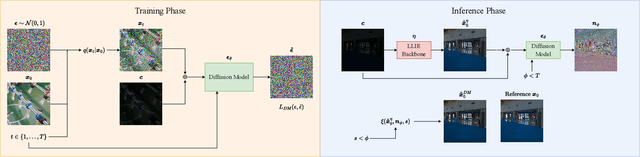
Low-light image enhancement (LLIE) techniques attempt to increase the visibility of images captured in low-light scenarios. However, as a result of enhancement, a variety of image degradations such as noise and color bias are revealed. Furthermore, each particular LLIE approach may introduce a different form of flaw within its enhanced results. To combat these image degradations, post-processing denoisers have widely been used, which often yield oversmoothed results lacking detail. We propose using a diffusion model as a post-processing approach, and we introduce Low-light Post-processing Diffusion Model (LPDM) in order to model the conditional distribution between under-exposed and normally-exposed images. We apply LPDM in a manner which avoids the computationally expensive generative reverse process of typical diffusion models, and post-process images in one pass through LPDM. Extensive experiments demonstrate that our approach outperforms competing post-processing denoisers by increasing the perceptual quality of enhanced low-light images on a variety of challenging low-light datasets. Source code is available at https://github.com/savvaki/LPDM.
Data Roaming and Early Fusion for Composed Image Retrieval
Mar 16, 2023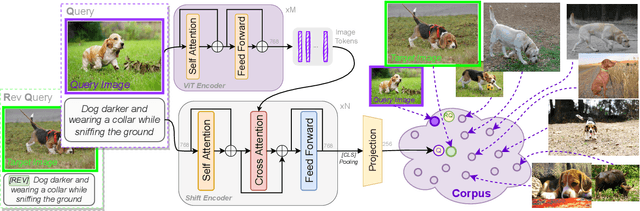
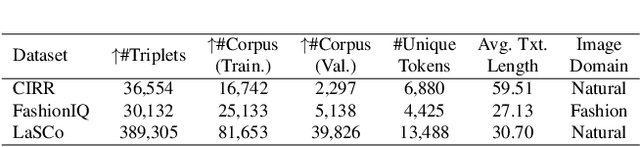
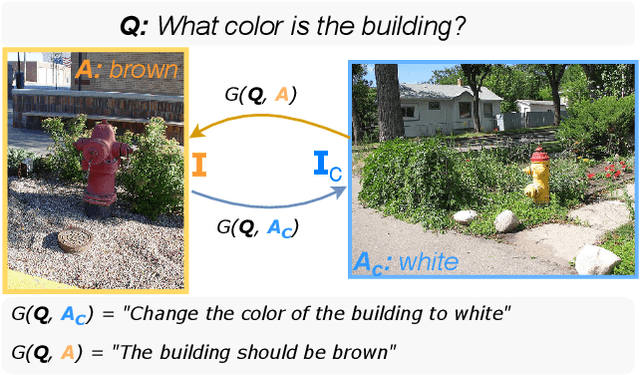
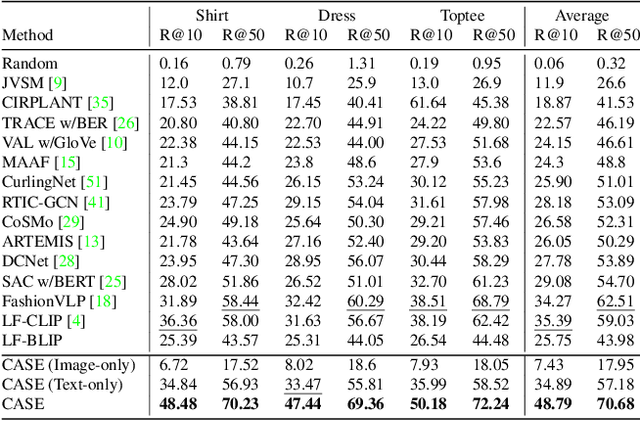
We study the task of Composed Image Retrieval (CoIR), where a query is composed of two modalities, image and text, extending the user's expression ability. Previous methods typically address this task by a separate encoding of each query modality, followed by late fusion of the extracted features. In this paper, we propose a new approach, Cross-Attention driven Shift Encoder (CASE), employing early fusion between modalities through a cross-attention module with an additional auxiliary task. We show that our method outperforms the existing state-of-the-art, on established benchmarks (FashionIQ and CIRR) by a large margin. However, CoIR datasets are a few orders of magnitude smaller compared to other vision and language (V&L) datasets, and some suffer from serious flaws (e.g., queries with a redundant modality). We address these shortcomings by introducing Large Scale Composed Image Retrieval (LaSCo), a new CoIR dataset x10 times larger than current ones. Pre-training on LaSCo yields a further performance boost. We further suggest a new analysis of CoIR datasets and methods, for detecting modality redundancy or necessity, in queries.