 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior
Apr 03, 2023
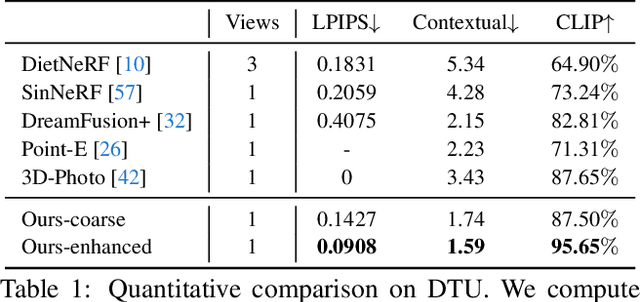
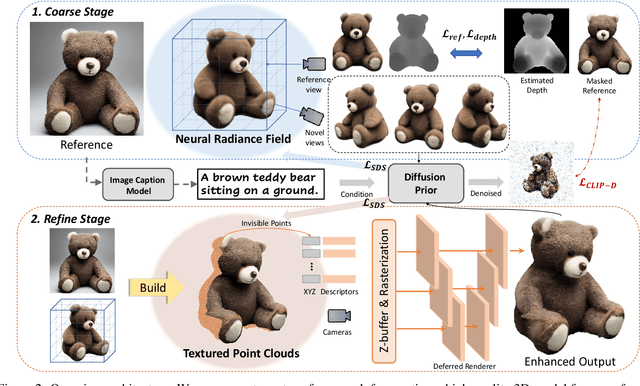
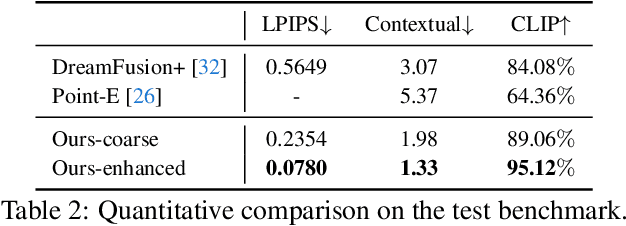

In this work, we investigate the problem of creating high-fidelity 3D content from only a single image. This is inherently challenging: it essentially involves estimating the underlying 3D geometry while simultaneously hallucinating unseen textures. To address this challenge, we leverage prior knowledge from a well-trained 2D diffusion model to act as 3D-aware supervision for 3D creation. Our approach, Make-It-3D, employs a two-stage optimization pipeline: the first stage optimizes a neural radiance field by incorporating constraints from the reference image at the frontal view and diffusion prior at novel views; the second stage transforms the coarse model into textured point clouds and further elevates the realism with diffusion prior while leveraging the high-quality textures from the reference image. Extensive experiments demonstrate that our method outperforms prior works by a large margin, resulting in faithful reconstructions and impressive visual quality. Our method presents the first attempt to achieve high-quality 3D creation from a single image for general objects and enables various applications such as text-to-3D creation and texture editing.
DreamSparse: Escaping from Plato's Cave with 2D Frozen Diffusion Model Given Sparse Views
Jun 14, 2023
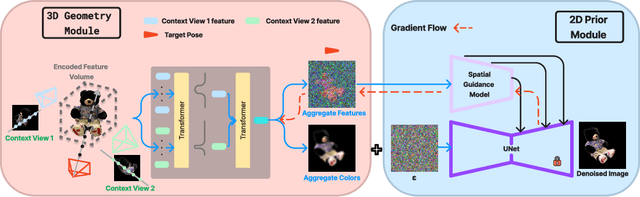


Synthesizing novel view images from a few views is a challenging but practical problem. Existing methods often struggle with producing high-quality results or necessitate per-object optimization in such few-view settings due to the insufficient information provided. In this work, we explore leveraging the strong 2D priors in pre-trained diffusion models for synthesizing novel view images. 2D diffusion models, nevertheless, lack 3D awareness, leading to distorted image synthesis and compromising the identity. To address these problems, we propose DreamSparse, a framework that enables the frozen pre-trained diffusion model to generate geometry and identity-consistent novel view image. Specifically, DreamSparse incorporates a geometry module designed to capture 3D features from sparse views as a 3D prior. Subsequently, a spatial guidance model is introduced to convert these 3D feature maps into spatial information for the generative process. This information is then used to guide the pre-trained diffusion model, enabling it to generate geometrically consistent images without tuning it. Leveraging the strong image priors in the pre-trained diffusion models, DreamSparse is capable of synthesizing high-quality novel views for both object and scene-level images and generalising to open-set images. Experimental results demonstrate that our framework can effectively synthesize novel view images from sparse views and outperforms baselines in both trained and open-set category images. More results can be found on our project page: https://sites.google.com/view/dreamsparse-webpage.
ReContrast: Domain-Specific Anomaly Detection via Contrastive Reconstruction
Jun 05, 2023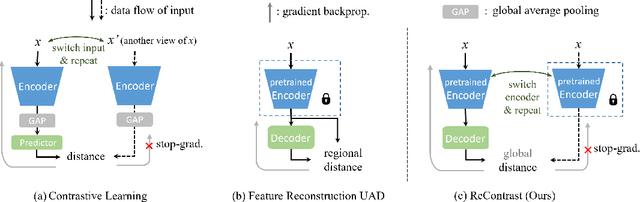
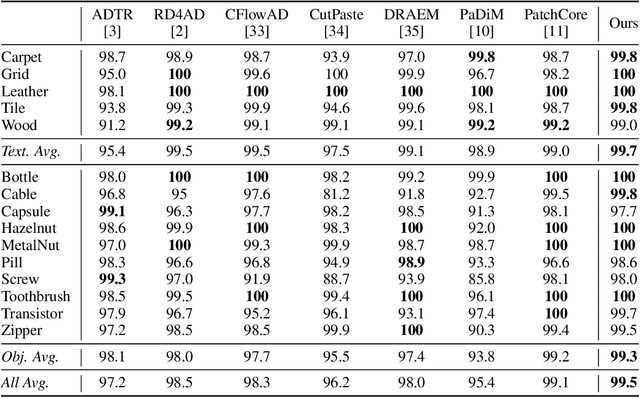
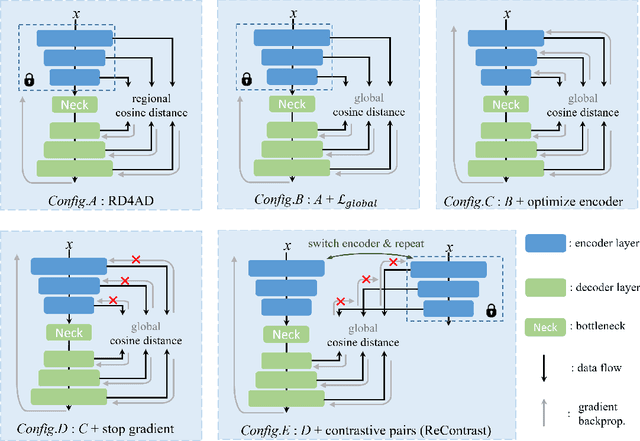

Most advanced unsupervised anomaly detection (UAD) methods rely on modeling feature representations of frozen encoder networks pre-trained on large-scale datasets, e.g. ImageNet. However, the features extracted from the encoders that are borrowed from natural image domains coincide little with the features required in the target UAD domain, such as industrial inspection and medical imaging. In this paper, we propose a novel epistemic UAD method, namely ReContrast, which optimizes the entire network to reduce biases towards the pre-trained image domain and orients the network in the target domain. We start with a feature reconstruction approach that detects anomalies from errors. Essentially, the elements of contrastive learning are elegantly embedded in feature reconstruction to prevent the network from training instability, pattern collapse, and identical shortcut, while simultaneously optimizing both the encoder and decoder on the target domain. To demonstrate our transfer ability on various image domains, we conduct extensive experiments across two popular industrial defect detection benchmarks and three medical image UAD tasks, which shows our superiority over current state-of-the-art methods.
A Framework for Real-time Object Detection and Image Restoration
Mar 16, 2023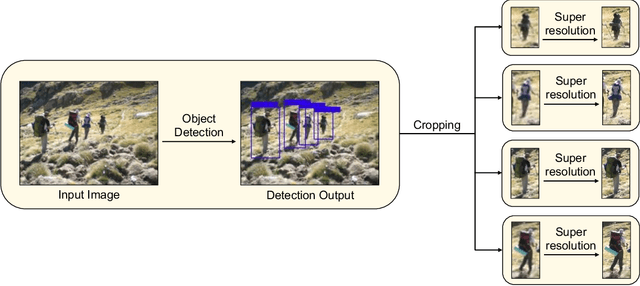
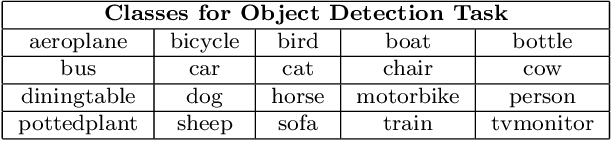
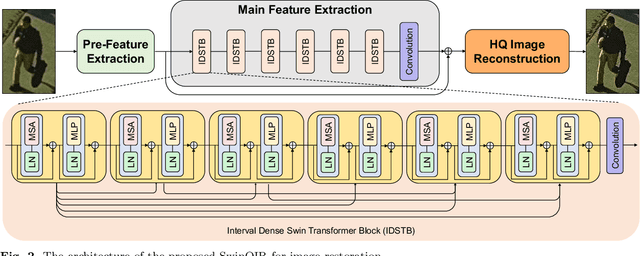
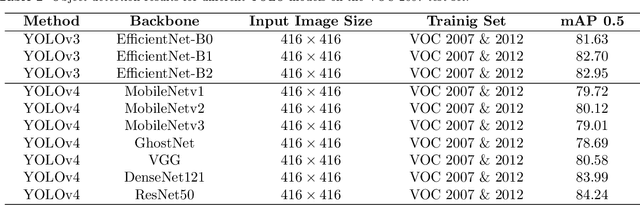
Object detection and single image super-resolution are classic problems in computer vision (CV). The object detection task aims to recognize the objects in input images, while the image restoration task aims to reconstruct high quality images from given low quality images. In this paper, a two-stage framework for object detection and image restoration is proposed. The first stage uses YOLO series algorithms to complete the object detection and then performs image cropping. In the second stage, this work improves Swin Transformer and uses the new proposed algorithm to connect the Swin Transformer layer to design a new neural network architecture. We name the newly proposed network for image restoration SwinOIR. This work compares the model performance of different versions of YOLO detection algorithms on MS COCO dataset and Pascal VOC dataset, demonstrating the suitability of different YOLO network models for the first stage of the framework in different scenarios. For image super-resolution task, it compares the model performance of using different methods of connecting Swin Transformer layers and design different sizes of SwinOIR for use in different life scenarios. Our implementation code is released at https://github.com/Rubbbbbbbbby/SwinOIR.
Unsupervised Style-based Explicit 3D Face Reconstruction from Single Image
Apr 24, 2023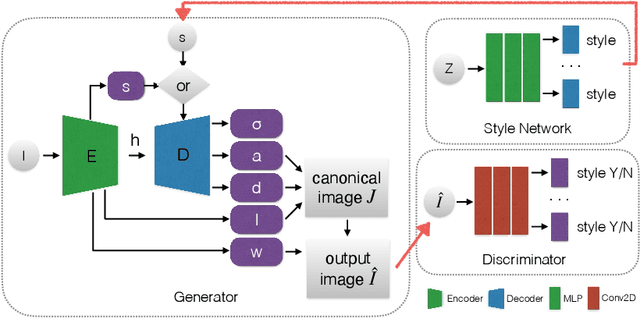
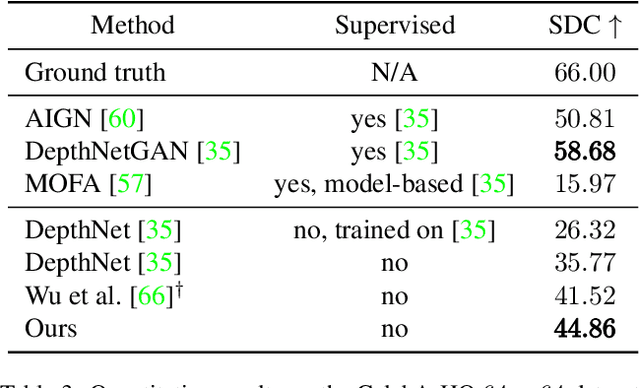
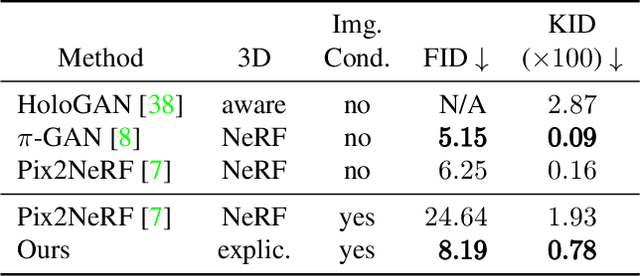

Inferring 3D object structures from a single image is an ill-posed task due to depth ambiguity and occlusion. Typical resolutions in the literature include leveraging 2D or 3D ground truth for supervised learning, as well as imposing hand-crafted symmetry priors or using an implicit representation to hallucinate novel viewpoints for unsupervised methods. In this work, we propose a general adversarial learning framework for solving Unsupervised 2D to Explicit 3D Style Transfer (UE3DST). Specifically, we merge two architectures: the unsupervised explicit 3D reconstruction network of Wu et al.\ and the Generative Adversarial Network (GAN) named StarGAN-v2. We experiment across three facial datasets (Basel Face Model, 3DFAW and CelebA-HQ) and show that our solution is able to outperform well established solutions such as DepthNet in 3D reconstruction and Pix2NeRF in conditional style transfer, while we also justify the individual contributions of our model components via ablation. In contrast to the aforementioned baselines, our scheme produces features for explicit 3D rendering, which can be manipulated and utilized in downstream tasks.
Learning Sparse and Low-Rank Priors for Image Recovery via Iterative Reweighted Least Squares Minimization
Apr 20, 2023
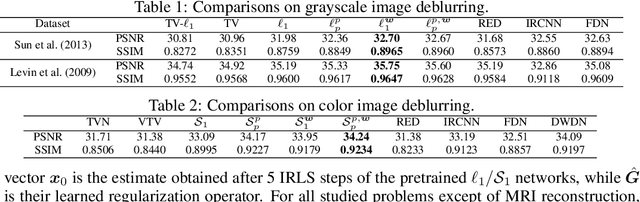


We introduce a novel optimization algorithm for image recovery under learned sparse and low-rank constraints, which we parameterize as weighted extensions of the $\ell_p^p$-vector and $\mathcal S_p^p$ Schatten-matrix quasi-norms for $0\!<p\!\le1$, respectively. Our proposed algorithm generalizes the Iteratively Reweighted Least Squares (IRLS) method, used for signal recovery under $\ell_1$ and nuclear-norm constrained minimization. Further, we interpret our overall minimization approach as a recurrent network that we then employ to deal with inverse low-level computer vision problems. Thanks to the convergence guarantees that our IRLS strategy offers, we are able to train the derived reconstruction networks using a memory-efficient implicit back-propagation scheme, which does not pose any restrictions on their effective depth. To assess our networks' performance, we compare them against other existing reconstruction methods on several inverse problems, namely image deblurring, super-resolution, demosaicking and sparse recovery. Our reconstruction results are shown to be very competitive and in many cases outperform those of existing unrolled networks, whose number of parameters is orders of magnitude higher than that of our learned models.
Chan-Vese Attention U-Net: An attention mechanism for robust segmentation
Jun 28, 2023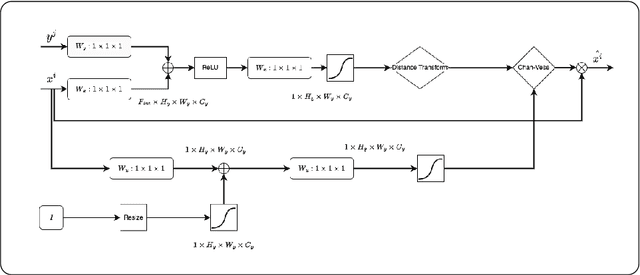
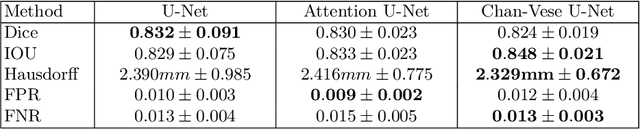
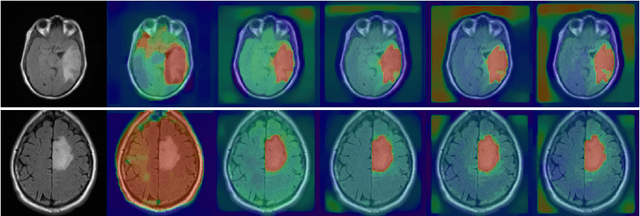
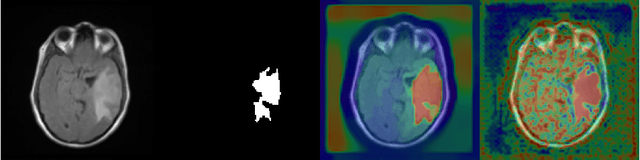
When studying the results of a segmentation algorithm using convolutional neural networks, one wonders about the reliability and consistency of the results. This leads to questioning the possibility of using such an algorithm in applications where there is little room for doubt. We propose in this paper a new attention gate based on the use of Chan-Vese energy minimization to control more precisely the segmentation masks given by a standard CNN architecture such as the U-Net model. This mechanism allows to obtain a constraint on the segmentation based on the resolution of a PDE. The study of the results allows us to observe the spatial information retained by the neural network on the region of interest and obtains competitive results on the binary segmentation. We illustrate the efficiency of this approach for medical image segmentation on a database of MRI brain images.
DDT: Dual-branch Deformable Transformer for Image Denoising
Apr 13, 2023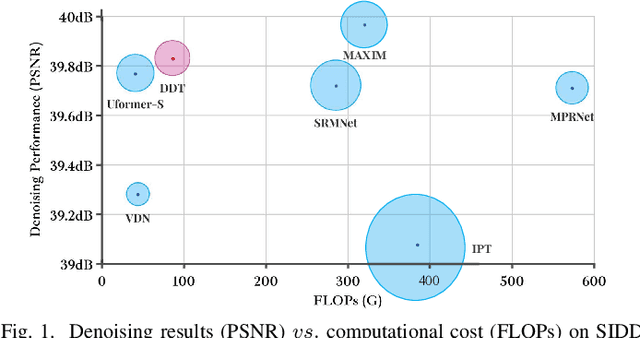
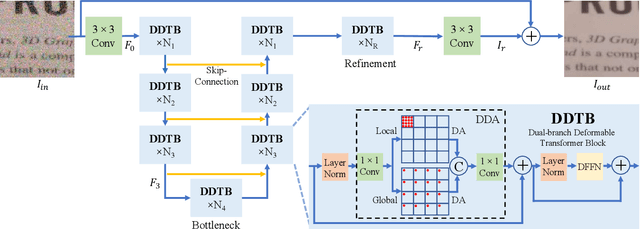
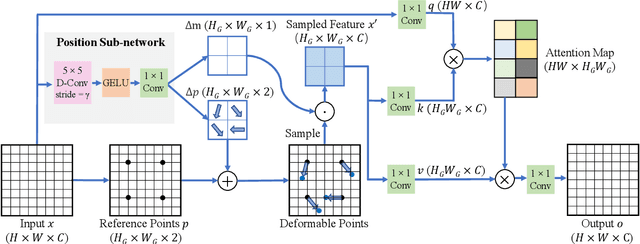

Transformer is beneficial for image denoising tasks since it can model long-range dependencies to overcome the limitations presented by inductive convolutional biases. However, directly applying the transformer structure to remove noise is challenging because its complexity grows quadratically with the spatial resolution. In this paper, we propose an efficient Dual-branch Deformable Transformer (DDT) denoising network which captures both local and global interactions in parallel. We divide features with a fixed patch size and a fixed number of patches in local and global branches, respectively. In addition, we apply deformable attention operation in both branches, which helps the network focus on more important regions and further reduces computational complexity. We conduct extensive experiments on real-world and synthetic denoising tasks, and the proposed DDT achieves state-of-the-art performance with significantly fewer computational costs.
Generating Images with Multimodal Language Models
May 26, 2023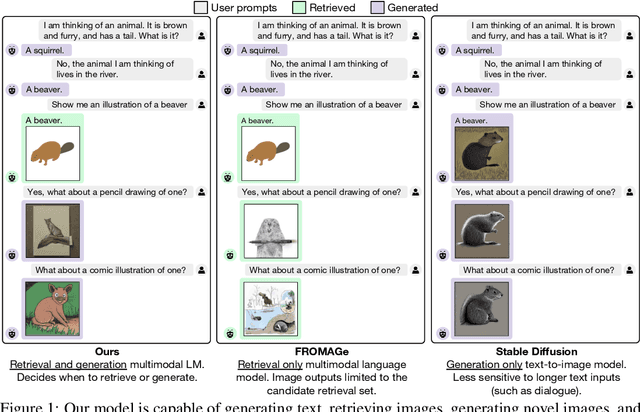
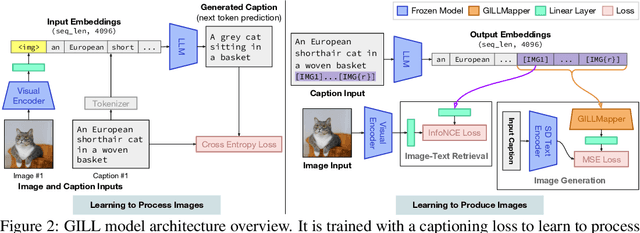

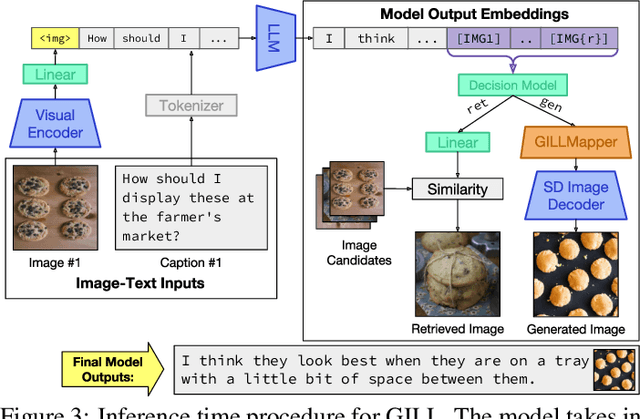
We propose a method to fuse frozen text-only large language models (LLMs) with pre-trained image encoder and decoder models, by mapping between their embedding spaces. Our model demonstrates a wide suite of multimodal capabilities: image retrieval, novel image generation, and multimodal dialogue. Ours is the first approach capable of conditioning on arbitrarily interleaved image and text inputs to generate coherent image (and text) outputs. To achieve strong performance on image generation, we propose an efficient mapping network to ground the LLM to an off-the-shelf text-to-image generation model. This mapping network translates hidden representations of text into the embedding space of the visual models, enabling us to leverage the strong text representations of the LLM for visual outputs. Our approach outperforms baseline generation models on tasks with longer and more complex language. In addition to novel image generation, our model is also capable of image retrieval from a prespecified dataset, and decides whether to retrieve or generate at inference time. This is done with a learnt decision module which conditions on the hidden representations of the LLM. Our model exhibits a wider range of capabilities compared to prior multimodal language models. It can process image-and-text inputs, and produce retrieved images, generated images, and generated text -- outperforming non-LLM based generation models across several text-to-image tasks that measure context dependence.
Easing Color Shifts in Score-Based Diffusion Models
Jun 27, 2023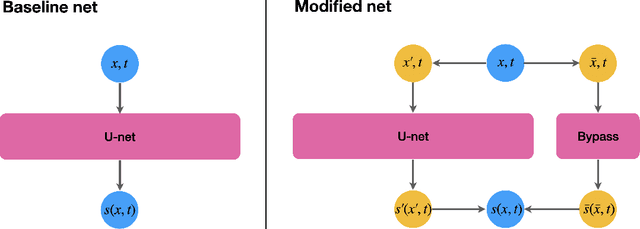

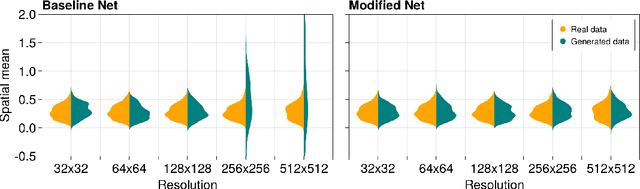
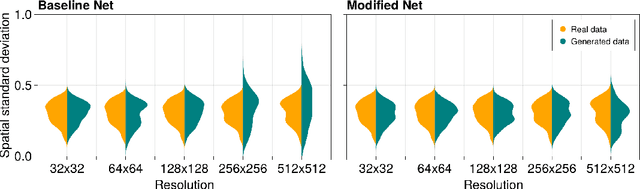
Generated images of score-based models can suffer from errors in their spatial means, an effect, referred to as a color shift, which grows for larger images. This paper introduces a computationally inexpensive solution to mitigate color shifts in score-based diffusion models. We propose a simple nonlinear bypass connection in the score network, designed to process the spatial mean of the input and to predict the mean of the score function. This network architecture substantially improves the resulting spatial means of the generated images, and we show that the improvement is approximately independent of the size of the generated images. As a result, our solution offers a comparatively inexpensive solution for the color shift problem across image sizes. Lastly, we discuss the origin of color shifts in an idealized setting in order to motivate our approach.