 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised MRI Reconstruction with Unrolled Diffusion Models
Jun 29, 2023
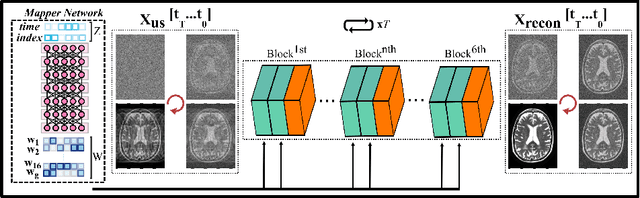

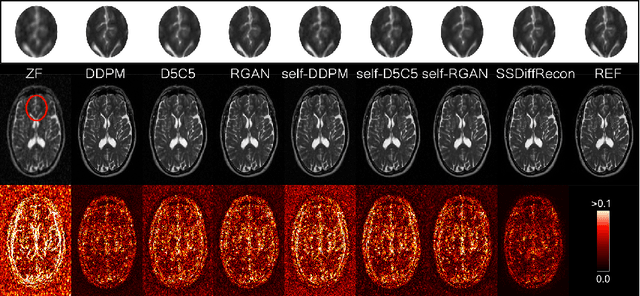
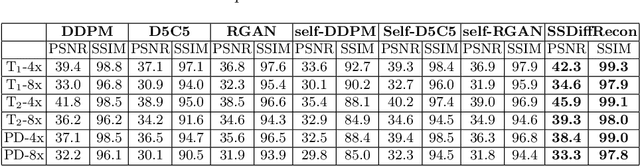
Magnetic Resonance Imaging (MRI) produces excellent soft tissue contrast, albeit it is an inherently slow imaging modality. Promising deep learning methods have recently been proposed to reconstruct accelerated MRI scans. However, existing methods still suffer from various limitations regarding image fidelity, contextual sensitivity, and reliance on fully-sampled acquisitions for model training. To comprehensively address these limitations, we propose a novel self-supervised deep reconstruction model, named Self-Supervised Diffusion Reconstruction (SSDiffRecon). SSDiffRecon expresses a conditional diffusion process as an unrolled architecture that interleaves cross-attention transformers for reverse diffusion steps with data-consistency blocks for physics-driven processing. Unlike recent diffusion methods for MRI reconstruction, a self-supervision strategy is adopted to train SSDiffRecon using only undersampled k-space data. Comprehensive experiments on public brain MR datasets demonstrates the superiority of SSDiffRecon against state-of-the-art supervised, and self-supervised baselines in terms of reconstruction speed and quality. Implementation will be available at https://github.com/yilmazkorkmaz1/SSDiffRecon.
A Novel Site-Agnostic Multimodal Deep Learning Model to Identify Pro-Eating Disorder Content on Social Media
Jul 06, 2023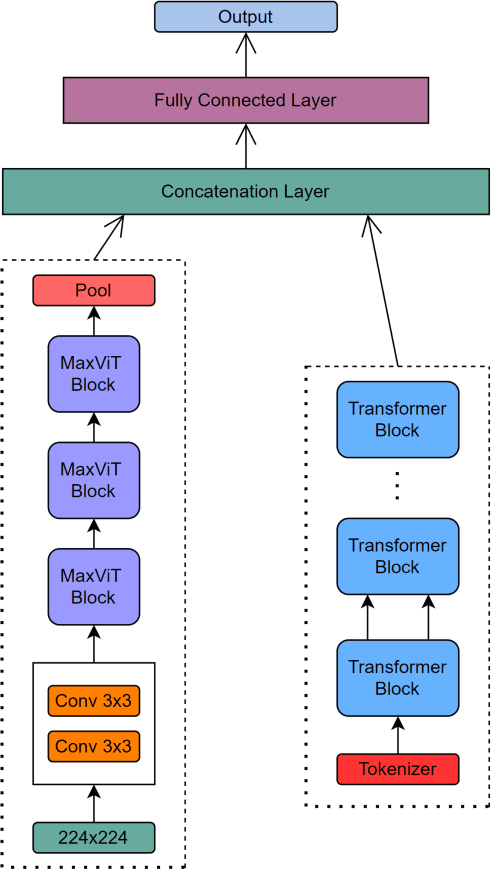
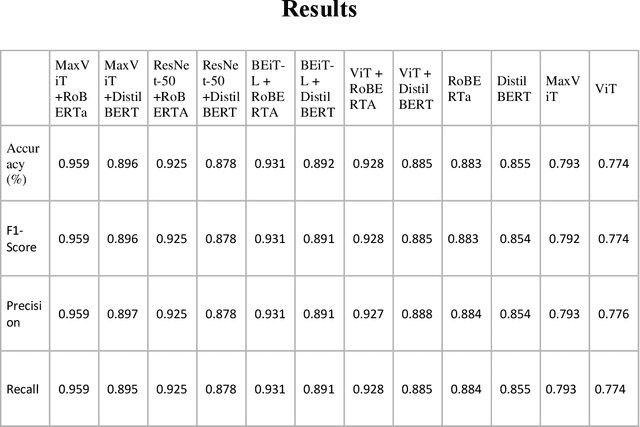
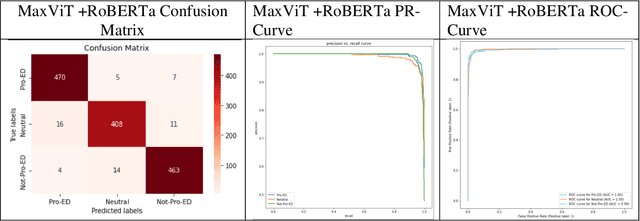
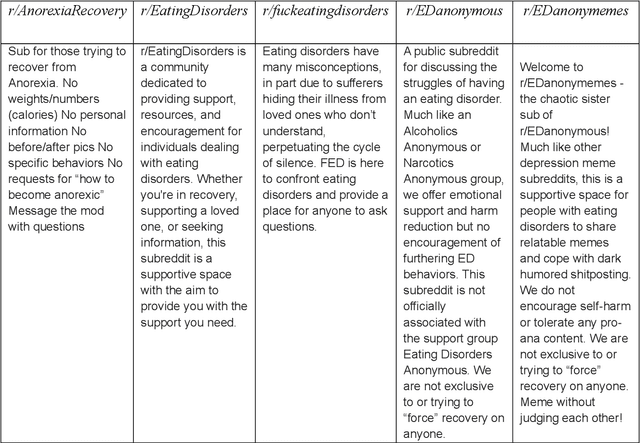
Over the last decade, there has been a vast increase in eating disorder diagnoses and eating disorder-attributed deaths, reaching their zenith during the Covid-19 pandemic. This immense growth derived in part from the stressors of the pandemic but also from increased exposure to social media, which is rife with content that promotes eating disorders. Such content can induce eating disorders in viewers. This study aimed to create a multimodal deep learning model capable of determining whether a given social media post promotes eating disorders based on a combination of visual and textual data. A labeled dataset of Tweets was collected from Twitter, upon which twelve deep learning models were trained and tested. Based on model performance, the most effective deep learning model was the multimodal fusion of the RoBERTa natural language processing model and the MaxViT image classification model, attaining accuracy and F1 scores of 95.9% and 0.959 respectively. The RoBERTa and MaxViT fusion model, deployed to classify an unlabeled dataset of posts from the social media sites Tumblr and Reddit, generated similar classifications as previous research studies that did not employ artificial intelligence, showing that artificial intelligence can develop insights congruent to those of researchers. Additionally, the model was used to conduct a time-series analysis of yet unseen Tweets from eight Twitter hashtags, uncovering that the relative abundance of pro-eating disorder content has decreased drastically. However, since approximately 2018, pro-eating disorder content has either stopped its decline or risen once more in ampleness.
SRCD: Semantic Reasoning with Compound Domains for Single-Domain Generalized Object Detection
Jul 04, 2023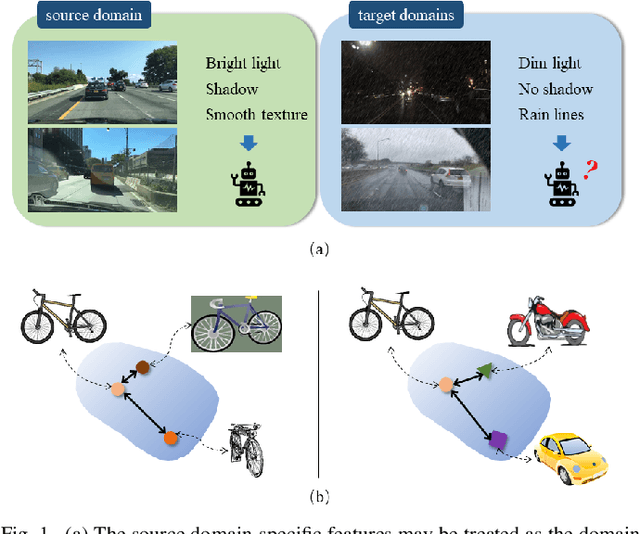

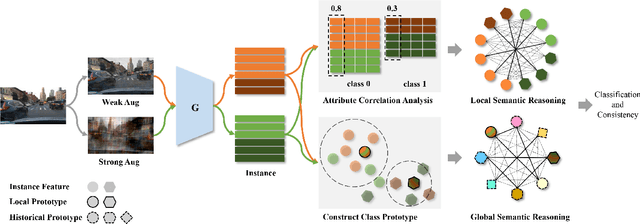

This paper provides a novel framework for single-domain generalized object detection (i.e., Single-DGOD), where we are interested in learning and maintaining the semantic structures of self-augmented compound cross-domain samples to enhance the model's generalization ability. Different from DGOD trained on multiple source domains, Single-DGOD is far more challenging to generalize well to multiple target domains with only one single source domain. Existing methods mostly adopt a similar treatment from DGOD to learn domain-invariant features by decoupling or compressing the semantic space. However, there may have two potential limitations: 1) pseudo attribute-label correlation, due to extremely scarce single-domain data; and 2) the semantic structural information is usually ignored, i.e., we found the affinities of instance-level semantic relations in samples are crucial to model generalization. In this paper, we introduce Semantic Reasoning with Compound Domains (SRCD) for Single-DGOD. Specifically, our SRCD contains two main components, namely, the texture-based self-augmentation (TBSA) module, and the local-global semantic reasoning (LGSR) module. TBSA aims to eliminate the effects of irrelevant attributes associated with labels, such as light, shadow, color, etc., at the image level by a light-yet-efficient self-augmentation. Moreover, LGSR is used to further model the semantic relationships on instance features to uncover and maintain the intrinsic semantic structures. Extensive experiments on multiple benchmarks demonstrate the effectiveness of the proposed SRCD.
TablEye: Seeing small Tables through the Lens of Images
Jul 04, 2023The exploration of few-shot tabular learning becomes imperative. Tabular data is a versatile representation that captures diverse information, yet it is not exempt from limitations, property of data and model size. Labeling extensive tabular data can be challenging, and it may not be feasible to capture every important feature. Few-shot tabular learning, however, remains relatively unexplored, primarily due to scarcity of shared information among independent datasets and the inherent ambiguity in defining boundaries within tabular data. To the best of our knowledge, no meaningful and unrestricted few-shot tabular learning techniques have been developed without imposing constraints on the dataset. In this paper, we propose an innovative framework called TablEye, which aims to overcome the limit of forming prior knowledge for tabular data by adopting domain transformation. It facilitates domain transformation by generating tabular images, which effectively conserve the intrinsic semantics of the original tabular data. This approach harnesses rigorously tested few-shot learning algorithms and embedding functions to acquire and apply prior knowledge. Leveraging shared data domains allows us to utilize this prior knowledge, originally learned from the image domain. Specifically, TablEye demonstrated a superior performance by outstripping the TabLLM in a 4-shot task with a maximum 0.11 AUC and a STUNT in a 1- shot setting, where it led on average by 3.17% accuracy.
A Framework for Real-time Object Detection and Image Restoration
Mar 16, 2023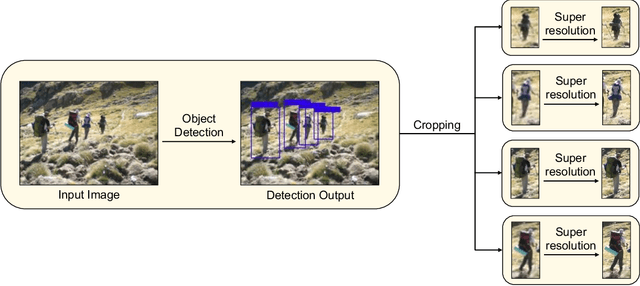
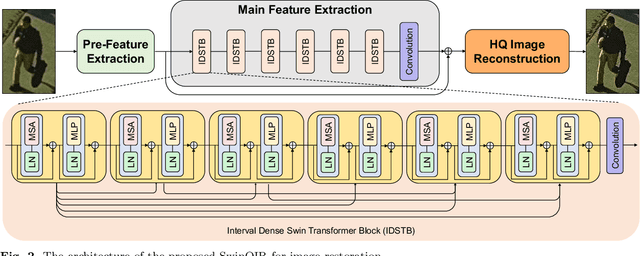
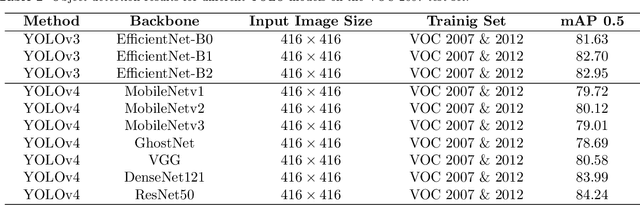
Object detection and single image super-resolution are classic problems in computer vision (CV). The object detection task aims to recognize the objects in input images, while the image restoration task aims to reconstruct high quality images from given low quality images. In this paper, a two-stage framework for object detection and image restoration is proposed. The first stage uses YOLO series algorithms to complete the object detection and then performs image cropping. In the second stage, this work improves Swin Transformer and uses the new proposed algorithm to connect the Swin Transformer layer to design a new neural network architecture. We name the newly proposed network for image restoration SwinOIR. This work compares the model performance of different versions of YOLO detection algorithms on MS COCO dataset and Pascal VOC dataset, demonstrating the suitability of different YOLO network models for the first stage of the framework in different scenarios. For image super-resolution task, it compares the model performance of using different methods of connecting Swin Transformer layers and design different sizes of SwinOIR for use in different life scenarios. Our implementation code is released at https://github.com/Rubbbbbbbbby/SwinOIR.
Dual Arbitrary Scale Super-Resolution for Multi-Contrast MRI
Jul 05, 2023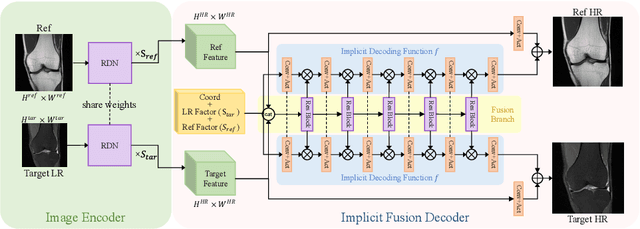
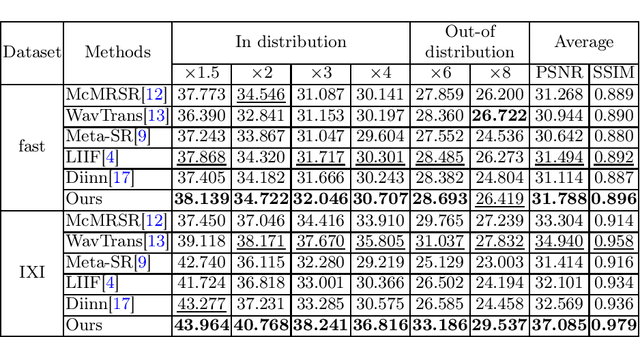
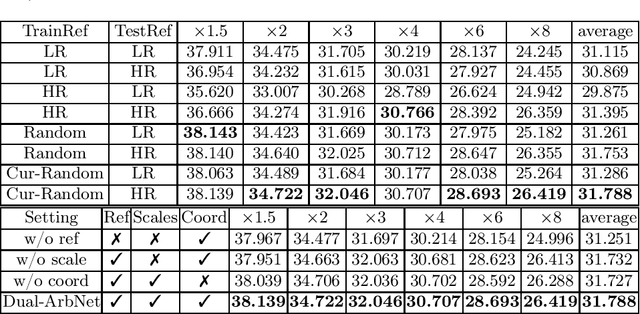
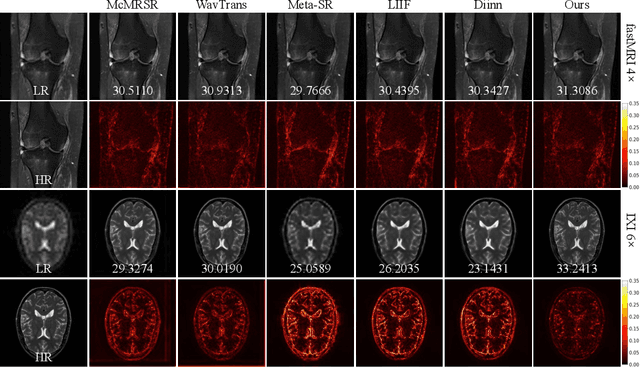
Limited by imaging systems, the reconstruction of Magnetic Resonance Imaging (MRI) images from partial measurement is essential to medical imaging research. Benefiting from the diverse and complementary information of multi-contrast MR images in different imaging modalities, multi-contrast Super-Resolution (SR) reconstruction is promising to yield SR images with higher quality. In the medical scenario, to fully visualize the lesion, radiologists are accustomed to zooming the MR images at arbitrary scales rather than using a fixed scale, as used by most MRI SR methods. In addition, existing multi-contrast MRI SR methods often require a fixed resolution for the reference image, which makes acquiring reference images difficult and imposes limitations on arbitrary scale SR tasks. To address these issues, we proposed an implicit neural representations based dual-arbitrary multi-contrast MRI super-resolution method, called Dual-ArbNet. First, we decouple the resolution of the target and reference images by a feature encoder, enabling the network to input target and reference images at arbitrary scales. Then, an implicit fusion decoder fuses the multi-contrast features and uses an Implicit Decoding Function~(IDF) to obtain the final MRI SR results. Furthermore, we introduce a curriculum learning strategy to train our network, which improves the generalization and performance of our Dual-ArbNet. Extensive experiments in two public MRI datasets demonstrate that our method outperforms state-of-the-art approaches under different scale factors and has great potential in clinical practice.
On the Adversarial Robustness of Generative Autoencoders in the Latent Space
Jul 05, 2023The generative autoencoders, such as the variational autoencoders or the adversarial autoencoders, have achieved great success in lots of real-world applications, including image generation, and signal communication. However, little concern has been devoted to their robustness during practical deployment. Due to the probabilistic latent structure, variational autoencoders (VAEs) may confront problems such as a mismatch between the posterior distribution of the latent and real data manifold, or discontinuity in the posterior distribution of the latent. This leaves a back door for malicious attackers to collapse VAEs from the latent space, especially in scenarios where the encoder and decoder are used separately, such as communication and compressed sensing. In this work, we provide the first study on the adversarial robustness of generative autoencoders in the latent space. Specifically, we empirically demonstrate the latent vulnerability of popular generative autoencoders through attacks in the latent space. We also evaluate the difference between variational autoencoders and their deterministic variants and observe that the latter performs better in latent robustness. Meanwhile, we identify a potential trade-off between the adversarial robustness and the degree of the disentanglement of the latent codes. Additionally, we also verify the feasibility of improvement for the latent robustness of VAEs through adversarial training. In summary, we suggest concerning the adversarial latent robustness of the generative autoencoders, analyze several robustness-relative issues, and give some insights into a series of key challenges.
Multimodal Prompt Learning for Product Title Generation with Extremely Limited Labels
Jul 05, 2023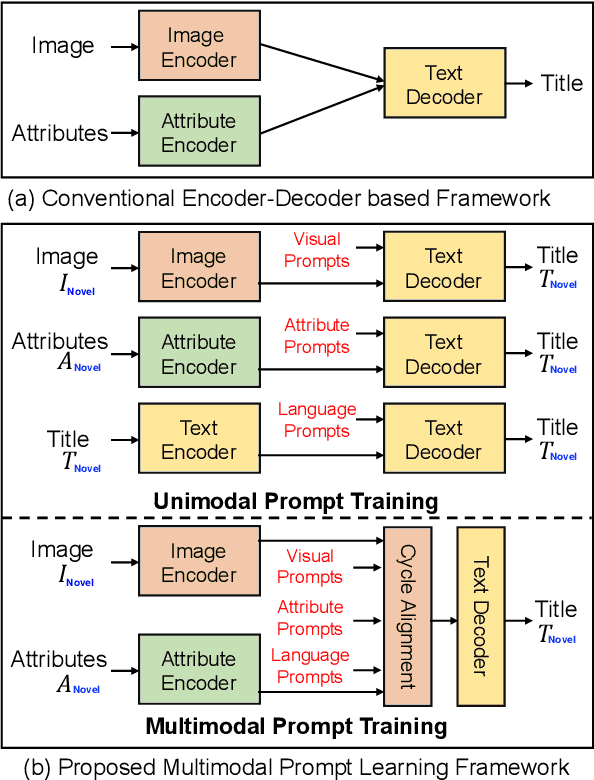
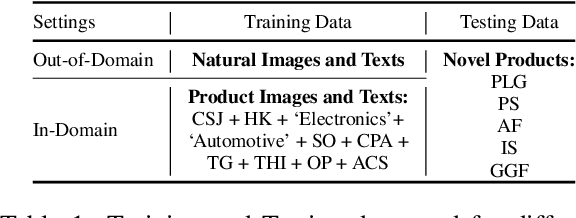
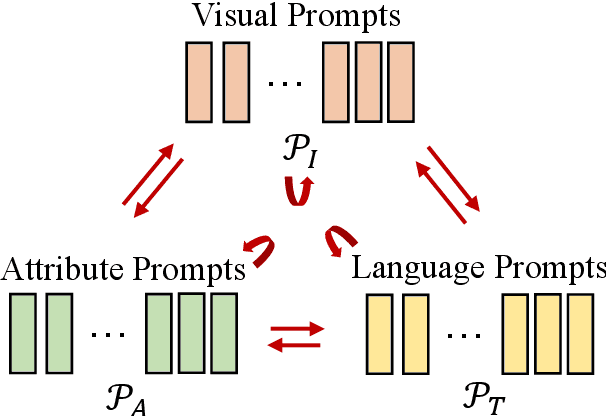
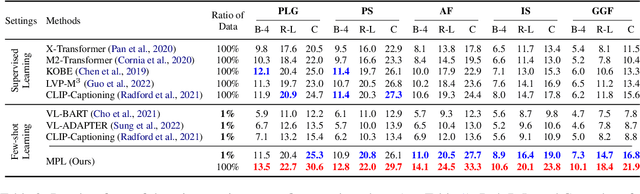
Generating an informative and attractive title for the product is a crucial task for e-commerce. Most existing works follow the standard multimodal natural language generation approaches, e.g., image captioning, and employ the large scale of human-labelled datasets to train desirable models. However, for novel products, especially in a different domain, there are few existing labelled data. In this paper, we propose a prompt-based approach, i.e., the Multimodal Prompt Learning framework, to accurately and efficiently generate titles for novel products with limited labels. We observe that the core challenges of novel product title generation are the understanding of novel product characteristics and the generation of titles in a novel writing style. To this end, we build a set of multimodal prompts from different modalities to preserve the corresponding characteristics and writing styles of novel products. As a result, with extremely limited labels for training, the proposed method can retrieve the multimodal prompts to generate desirable titles for novel products. The experiments and analyses are conducted on five novel product categories under both the in-domain and out-of-domain experimental settings. The results show that, with only 1% of downstream labelled data for training, our proposed approach achieves the best few-shot results and even achieves competitive results with fully-supervised methods trained on 100% of training data; With the full labelled data for training, our method achieves state-of-the-art results.
DARE: Towards Robust Text Explanations in Biomedical and Healthcare Applications
Jul 05, 2023
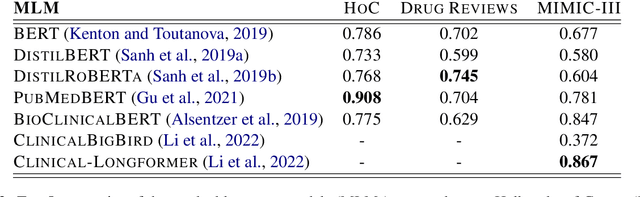
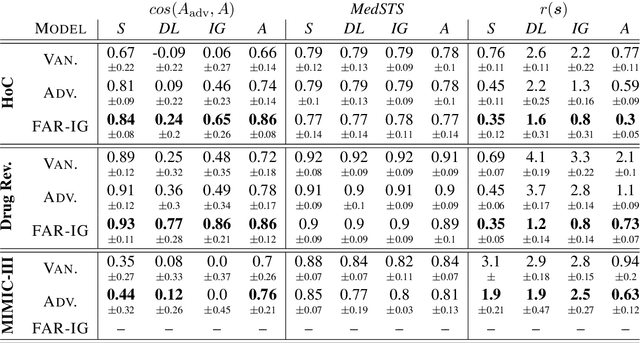

Along with the successful deployment of deep neural networks in several application domains, the need to unravel the black-box nature of these networks has seen a significant increase recently. Several methods have been introduced to provide insight into the inference process of deep neural networks. However, most of these explainability methods have been shown to be brittle in the face of adversarial perturbations of their inputs in the image and generic textual domain. In this work we show that this phenomenon extends to specific and important high stakes domains like biomedical datasets. In particular, we observe that the robustness of explanations should be characterized in terms of the accuracy of the explanation in linking a model's inputs and its decisions - faithfulness - and its relevance from the perspective of domain experts - plausibility. This is crucial to prevent explanations that are inaccurate but still look convincing in the context of the domain at hand. To this end, we show how to adapt current attribution robustness estimation methods to a given domain, so as to take into account domain-specific plausibility. This results in our DomainAdaptiveAREstimator (DARE) attribution robustness estimator, allowing us to properly characterize the domain-specific robustness of faithful explanations. Next, we provide two methods, adversarial training and FAR training, to mitigate the brittleness characterized by DARE, allowing us to train networks that display robust attributions. Finally, we empirically validate our methods with extensive experiments on three established biomedical benchmarks.
SoK: Privacy-Preserving Data Synthesis
Jul 05, 2023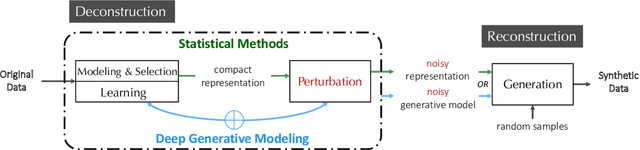
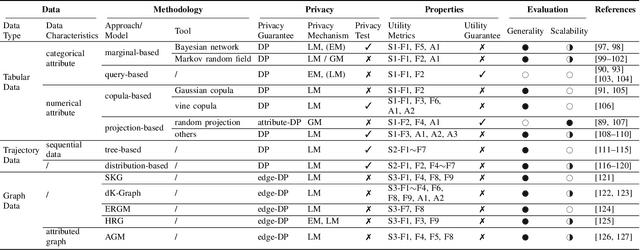
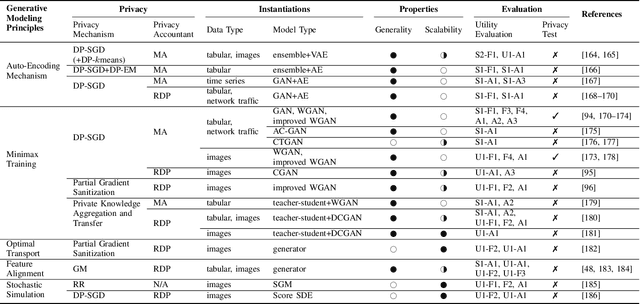
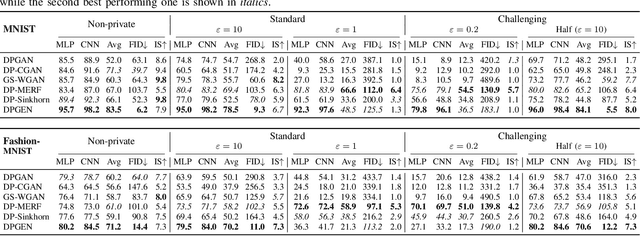
As the prevalence of data analysis grows, safeguarding data privacy has become a paramount concern. Consequently, there has been an upsurge in the development of mechanisms aimed at privacy-preserving data analyses. However, these approaches are task-specific; designing algorithms for new tasks is a cumbersome process. As an alternative, one can create synthetic data that is (ideally) devoid of private information. This paper focuses on privacy-preserving data synthesis (PPDS) by providing a comprehensive overview, analysis, and discussion of the field. Specifically, we put forth a master recipe that unifies two prominent strands of research in PPDS: statistical methods and deep learning (DL)-based methods. Under the master recipe, we further dissect the statistical methods into choices of modeling and representation, and investigate the DL-based methods by different generative modeling principles. To consolidate our findings, we provide comprehensive reference tables, distill key takeaways, and identify open problems in the existing literature. In doing so, we aim to answer the following questions: What are the design principles behind different PPDS methods? How can we categorize these methods, and what are the advantages and disadvantages associated with each category? Can we provide guidelines for method selection in different real-world scenarios? We proceed to benchmark several prominent DL-based methods on the task of private image synthesis and conclude that DP-MERF is an all-purpose approach. Finally, upon systematizing the work over the past decade, we identify future directions and call for actions from researchers.