 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exploring the Role of the Bottleneck in Slot-Based Models Through Covariance Regularization
Jun 05, 2023
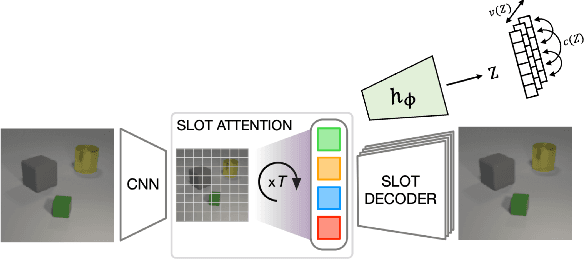



In this project we attempt to make slot-based models with an image reconstruction objective competitive with those that use a feature reconstruction objective on real world datasets. We propose a loss-based approach to constricting the bottleneck of slot-based models, allowing larger-capacity encoder networks to be used with Slot Attention without producing degenerate stripe-shaped masks. We find that our proposed method offers an improvement over the baseline Slot Attention model but does not reach the performance of \dinosaur on the COCO2017 dataset. Throughout this project, we confirm the superiority of a feature reconstruction objective over an image reconstruction objective and explore the role of the architectural bottleneck in slot-based models.
Image comparison and scaling via nonlinear elasticity
Mar 20, 2023A nonlinear elasticity model for comparing images is formulated and analyzed, in which optimal transformations between images are sought as minimizers of an integral functional. The existence of minimizers in a suitable class of homeomorphisms between image domains is established under natural hypotheses. We investigate whether for linearly related images the minimization algorithm delivers the linear transformation as the unique minimizer.
Are aligned neural networks adversarially aligned?
Jun 26, 2023
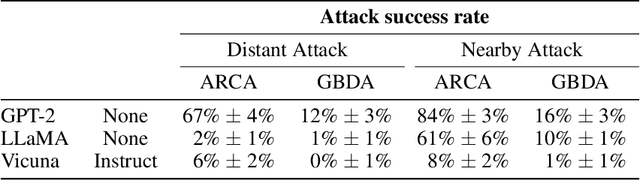


Large language models are now tuned to align with the goals of their creators, namely to be "helpful and harmless." These models should respond helpfully to user questions, but refuse to answer requests that could cause harm. However, adversarial users can construct inputs which circumvent attempts at alignment. In this work, we study to what extent these models remain aligned, even when interacting with an adversarial user who constructs worst-case inputs (adversarial examples). These inputs are designed to cause the model to emit harmful content that would otherwise be prohibited. We show that existing NLP-based optimization attacks are insufficiently powerful to reliably attack aligned text models: even when current NLP-based attacks fail, we can find adversarial inputs with brute force. As a result, the failure of current attacks should not be seen as proof that aligned text models remain aligned under adversarial inputs. However the recent trend in large-scale ML models is multimodal models that allow users to provide images that influence the text that is generated. We show these models can be easily attacked, i.e., induced to perform arbitrary un-aligned behavior through adversarial perturbation of the input image. We conjecture that improved NLP attacks may demonstrate this same level of adversarial control over text-only models.
3D-Aware Adversarial Makeup Generation for Facial Privacy Protection
Jun 26, 2023

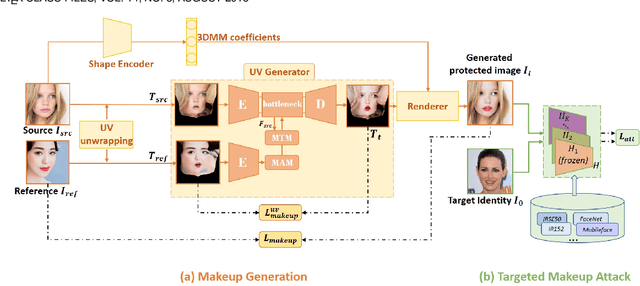
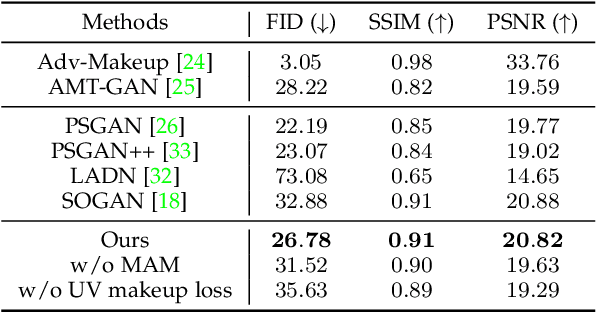
The privacy and security of face data on social media are facing unprecedented challenges as it is vulnerable to unauthorized access and identification. A common practice for solving this problem is to modify the original data so that it could be protected from being recognized by malicious face recognition (FR) systems. However, such ``adversarial examples'' obtained by existing methods usually suffer from low transferability and poor image quality, which severely limits the application of these methods in real-world scenarios. In this paper, we propose a 3D-Aware Adversarial Makeup Generation GAN (3DAM-GAN). which aims to improve the quality and transferability of synthetic makeup for identity information concealing. Specifically, a UV-based generator consisting of a novel Makeup Adjustment Module (MAM) and Makeup Transfer Module (MTM) is designed to render realistic and robust makeup with the aid of symmetric characteristics of human faces. Moreover, a makeup attack mechanism with an ensemble training strategy is proposed to boost the transferability of black-box models. Extensive experiment results on several benchmark datasets demonstrate that 3DAM-GAN could effectively protect faces against various FR models, including both publicly available state-of-the-art models and commercial face verification APIs, such as Face++, Baidu and Aliyun.
Graph-based Representation for Image based on Granular-ball
Mar 04, 2023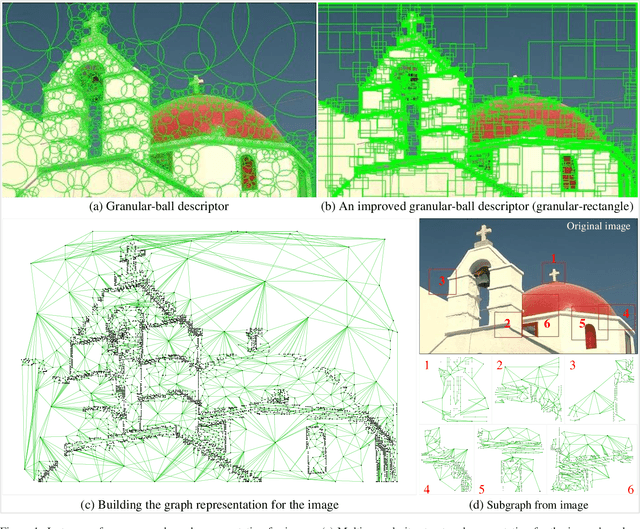


Current image processing methods usually operate on the finest-granularity unit; that is, the pixel, which leads to challenges in terms of efficiency, robustness, and understandability in deep learning models. We present an improved granular-ball computing method to represent the image as a graph, in which each node expresses a structural block in the image and each edge represents the association between two nodes. Specifically:(1) We design a gradient-based strategy for the adaptive reorganization of all pixels in the image into numerous rectangular regions, each of which can be regarded as one node. (2) Each node has a connection edge with the nodes with which it shares regions. (3) We design a low-dimensional vector as the attribute of each node. All nodes and their corresponding edges form a graphical representation of a digital image. In the experiments, our proposed graph representation is applied to benchmark datasets for image classification tasks, and the efficiency and good understandability demonstrate that our proposed method offers significant potential in artificial intelligence theory and application.
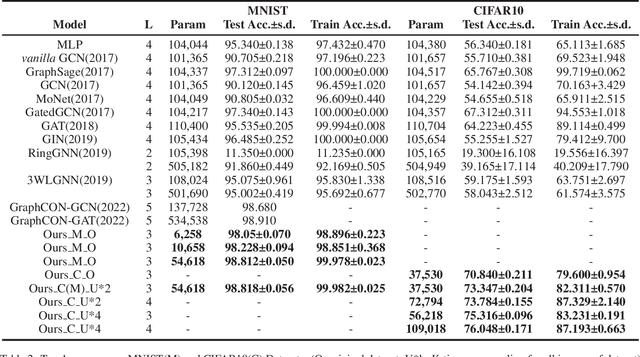
Multi-modal Pre-training for Medical Vision-language Understanding and Generation: An Empirical Study with A New Benchmark
Jun 10, 2023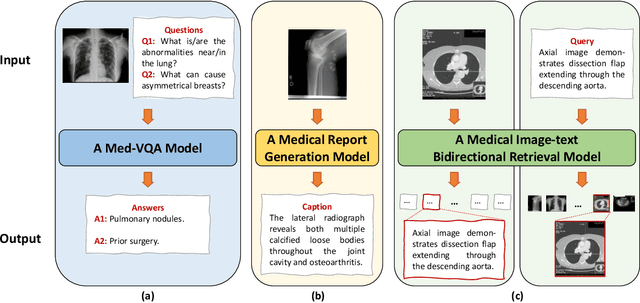

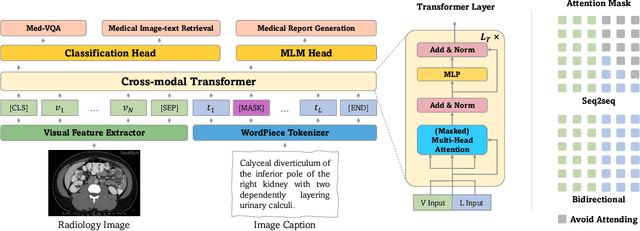

With the availability of large-scale, comprehensive, and general-purpose vision-language (VL) datasets such as MSCOCO, vision-language pre-training (VLP) has become an active area of research and proven to be effective for various VL tasks such as visual-question answering. However, studies on VLP in the medical domain have so far been scanty. To provide a comprehensive perspective on VLP for medical VL tasks, we conduct a thorough experimental analysis to study key factors that may affect the performance of VLP with a unified vision-language Transformer. To allow making sound and quick pre-training decisions, we propose RadioGraphy Captions (RGC), a high-quality, multi-modality radiographic dataset containing 18,434 image-caption pairs collected from an open-access online database MedPix. RGC can be used as a pre-training dataset or a new benchmark for medical report generation and medical image-text retrieval. By utilizing RGC and other available datasets for pre-training, we develop several key insights that can guide future medical VLP research and new strong baselines for various medical VL tasks.
Towards quantum enhanced adversarial robustness in machine learning
Jun 22, 2023Machine learning algorithms are powerful tools for data driven tasks such as image classification and feature detection, however their vulnerability to adversarial examples - input samples manipulated to fool the algorithm - remains a serious challenge. The integration of machine learning with quantum computing has the potential to yield tools offering not only better accuracy and computational efficiency, but also superior robustness against adversarial attacks. Indeed, recent work has employed quantum mechanical phenomena to defend against adversarial attacks, spurring the rapid development of the field of quantum adversarial machine learning (QAML) and potentially yielding a new source of quantum advantage. Despite promising early results, there remain challenges towards building robust real-world QAML tools. In this review we discuss recent progress in QAML and identify key challenges. We also suggest future research directions which could determine the route to practicality for QAML approaches as quantum computing hardware scales up and noise levels are reduced.
* 10 Pages, 4 Figures
Automatic Feature Detection in Lung Ultrasound Images using Wavelet and Radon Transforms
Jun 22, 2023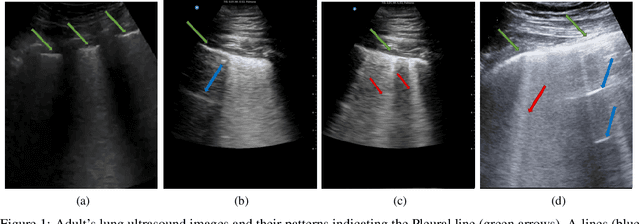

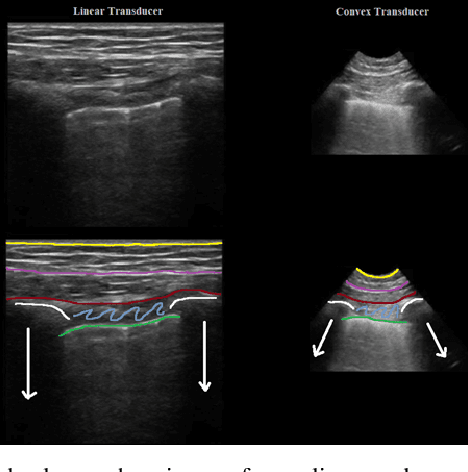
Objective: Lung ultrasonography is a significant advance toward a harmless lung imagery system. This work has investigated the automatic localization of diagnostically significant features in lung ultrasound pictures which are Pleural line, A-lines, and B-lines. Study Design: Wavelet and Radon transforms have been utilized in order to denoise and highlight the presence of clinically significant patterns. The proposed framework is developed and validated using three different lung ultrasound image datasets. Two of them contain synthetic data and the other one is taken from the publicly available POCUS dataset. The efficiency of the proposed method is evaluated using 200 real images. Results: The obtained results prove that the comparison between localized patterns and the baselines yields a promising F2-score of 62%, 86%, and 100% for B-lines, A-lines, and Pleural line, respectively. Conclusion: Finally, the high F-scores attained show that the developed technique is an effective way to automatically extract lung patterns from ultrasound images.
Live image-based neurosurgical guidance and roadmap generation using unsupervised embedding
Mar 31, 2023
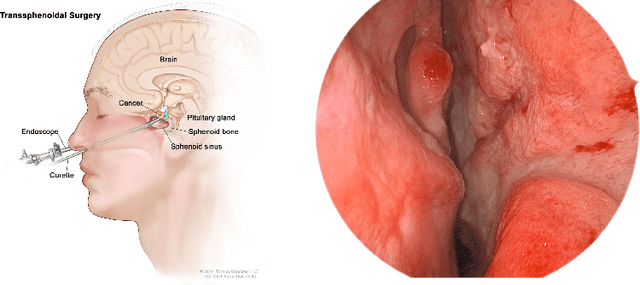
Advanced minimally invasive neurosurgery navigation relies mainly on Magnetic Resonance Imaging (MRI) guidance. MRI guidance, however, only provides pre-operative information in the majority of the cases. Once the surgery begins, the value of this guidance diminishes to some extent because of the anatomical changes due to surgery. Guidance with live image feedback coming directly from the surgical device, e.g., endoscope, can complement MRI-based navigation or be an alternative if MRI guidance is not feasible. With this motivation, we present a method for live image-only guidance leveraging a large data set of annotated neurosurgical videos.First, we report the performance of a deep learning-based object detection method, YOLO, on detecting anatomical structures in neurosurgical images. Second, we present a method for generating neurosurgical roadmaps using unsupervised embedding without assuming exact anatomical matches between patients, presence of an extensive anatomical atlas, or the need for simultaneous localization and mapping. A generated roadmap encodes the common anatomical paths taken in surgeries in the training set. At inference, the roadmap can be used to map a surgeon's current location using live image feedback on the path to provide guidance by being able to predict which structures should appear going forward or backward, much like a mapping application. Even though the embedding is not supervised by position information, we show that it is correlated to the location inside the brain and on the surgical path. We trained and evaluated the proposed method with a data set of 166 transsphenoidal adenomectomy procedures.
Toward Real Flare Removal: A Comprehensive Pipeline and A New Benchmark
Jun 28, 2023

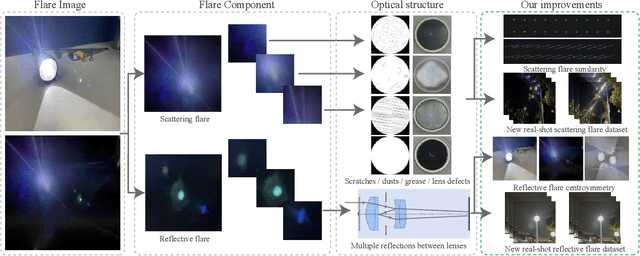

Photographing in the under-illuminated scenes, the presence of complex light sources often leave strong flare artifacts in images, where the intensity, the spectrum, the reflection, and the aberration altogether contribute the deterioration. Besides the image quality, it also influence the performance of down-stream visual applications. Thus, removing the lens flare and ghosts is a challenge issue especially in low-light environment. However, existing methods for flare removal mainly restricted to the problems of inadequate simulation and real-world capture, where the categories of scattered flares are singular and the reflected ghosts are unavailable. Therefore, a comprehensive deterioration procedure is crucial for constructing the dataset of flare removal. Based on the theoretical analysis and real-world evaluation, we propose a well-developed methodology for generating the data-pairs with flare deterioration. The procedure is comprehensive, where the similarity of scattered flares and the symmetric effect of reflected ghosts are realized. Moreover, we also construct a real-shot pipeline that respectively processes the effects of scattering and reflective flares, aiming to directly generate the data for end-to-end methods. Experimental results show that the proposed methodology add diversity to the existing flare datasets and construct a comprehensive mapping procedure for flare data pairs. And our method facilities the data-driven model to realize better restoration in flare images and proposes a better evaluation system based on real shots, resulting promote progress in the area of real flare removal.