 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cheap-fake Detection with LLM using Prompt Engineering
Jun 05, 2023
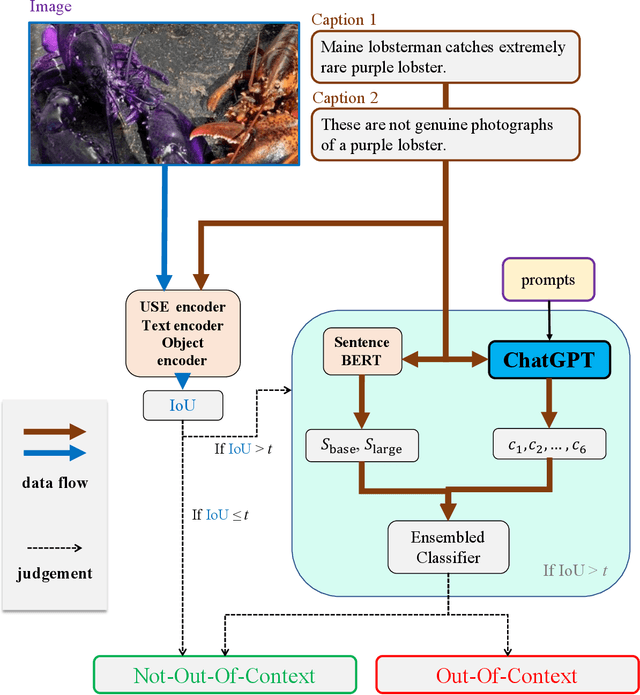
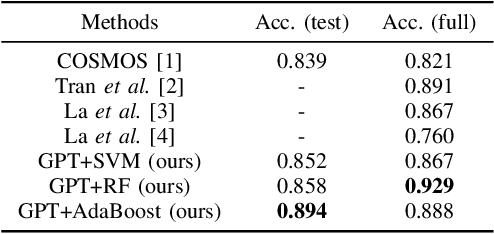
The misuse of real photographs with conflicting image captions in news items is an example of the out-of-context (OOC) misuse of media. In order to detect OOC media, individuals must determine the accuracy of the statement and evaluate whether the triplet (~\textit{i.e.}, the image and two captions) relates to the same event. This paper presents a novel learnable approach for detecting OOC media in ICME'23 Grand Challenge on Detecting Cheapfakes. The proposed method is based on the COSMOS structure, which assesses the coherence between an image and captions, as well as between two captions. We enhance the baseline algorithm by incorporating a Large Language Model (LLM), GPT3.5, as a feature extractor. Specifically, we propose an innovative approach to feature extraction utilizing prompt engineering to develop a robust and reliable feature extractor with GPT3.5 model. The proposed method captures the correlation between two captions and effectively integrates this module into the COSMOS baseline model, which allows for a deeper understanding of the relationship between captions. By incorporating this module, we demonstrate the potential for significant improvements in cheap-fakes detection performance. The proposed methodology holds promising implications for various applications such as natural language processing, image captioning, and text-to-image synthesis. Docker for submission is available at https://hub.docker.com/repository/docker/mulns/ acmmmcheapfakes.
Online learning for X-ray, CT or MRI
Jun 10, 2023
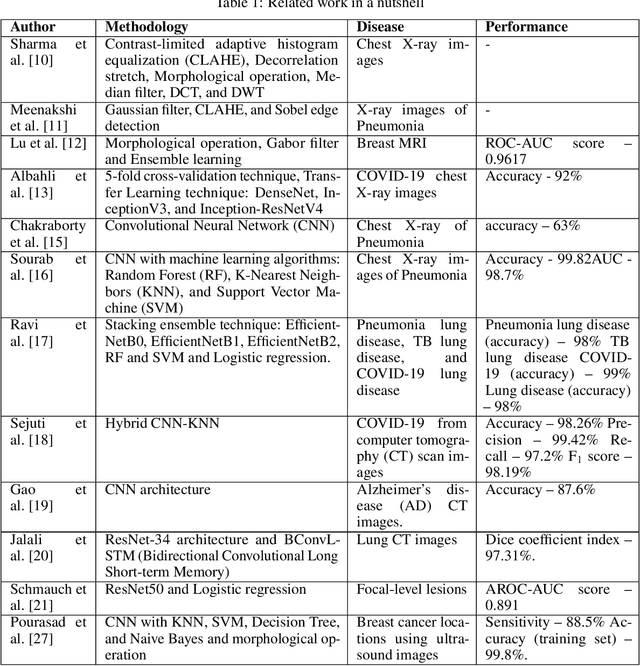
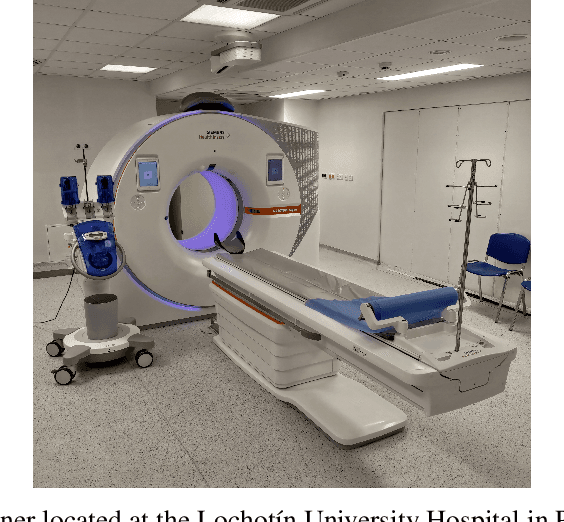
Medical imaging plays an important role in the medical sector in identifying diseases. X-ray, computed tomography (CT) scans, and magnetic resonance imaging (MRI) are a few examples of medical imaging. Most of the time, these imaging techniques are utilized to examine and diagnose diseases. Medical professionals identify the problem after analyzing the images. However, manual identification can be challenging because the human eye is not always able to recognize complex patterns in an image. Because of this, it is difficult for any professional to recognize a disease with rapidity and accuracy. In recent years, medical professionals have started adopting Computer-Aided Diagnosis (CAD) systems to evaluate medical images. This system can analyze the image and detect the disease very precisely and quickly. However, this system has certain drawbacks in that it needs to be processed before analysis. Medical research is already entered a new era of research which is called Artificial Intelligence (AI). AI can automatically find complex patterns from an image and identify diseases. Methods for medical imaging that uses AI techniques will be covered in this chapter.
Transductive few-shot adapters for medical image segmentation
Mar 29, 2023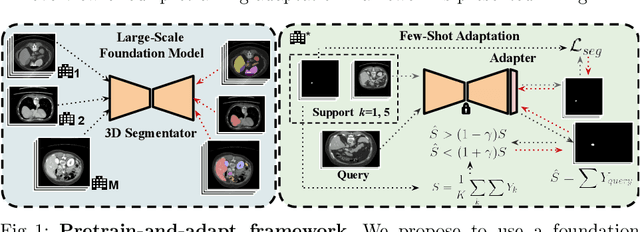

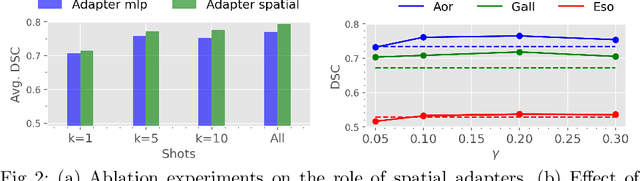
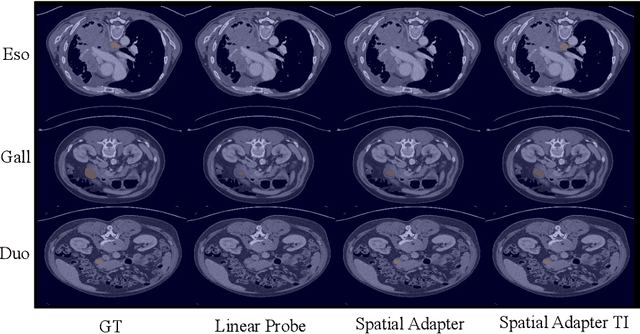
With the recent raise of foundation models in computer vision and NLP, the pretrain-and-adapt strategy, where a large-scale model is fine-tuned on downstream tasks, is gaining popularity. However, traditional fine-tuning approaches may still require significant resources and yield sub-optimal results when the labeled data of the target task is scarce. This is especially the case in clinical settings. To address this challenge, we formalize few-shot efficient fine-tuning (FSEFT), a novel and realistic setting for medical image segmentation. Furthermore, we introduce a novel parameter-efficient fine-tuning strategy tailored to medical image segmentation, with (a) spatial adapter modules that are more appropriate for dense prediction tasks; and (b) a constrained transductive inference, which leverages task-specific prior knowledge. Our comprehensive experiments on a collection of public CT datasets for organ segmentation reveal the limitations of standard fine-tuning methods in few-shot scenarios, point to the potential of vision adapters and transductive inference, and confirm the suitability of foundation models.
Deep learning-based image exposure enhancement as a pre-processing for an accurate 3D colon surface reconstruction
Apr 06, 2023

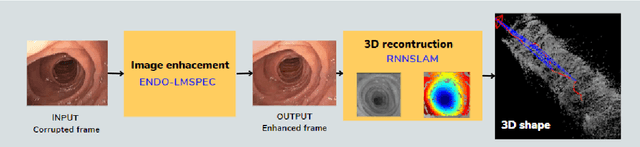
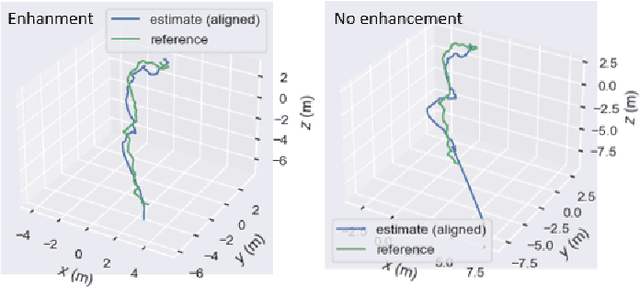
This contribution shows how an appropriate image pre-processing can improve a deep-learning based 3D reconstruction of colon parts. The assumption is that, rather than global image illumination corrections, local under- and over-exposures should be corrected in colonoscopy. An overview of the pipeline including the image exposure correction and a RNN-SLAM is first given. Then, this paper quantifies the reconstruction accuracy of the endoscope trajectory in the colon with and without appropriate illumination correction
Low-frequency Image Deep Steganography: Manipulate the Frequency Distribution to Hide Secrets with Tenacious Robustness
Mar 23, 2023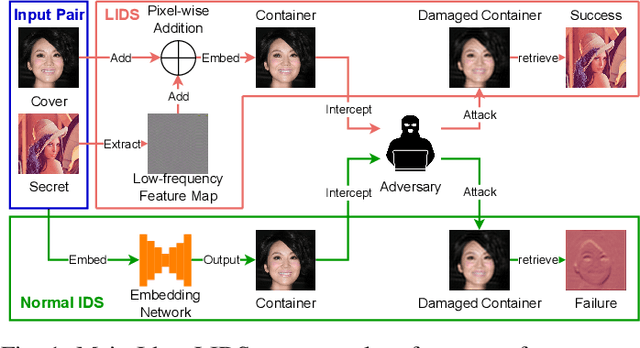


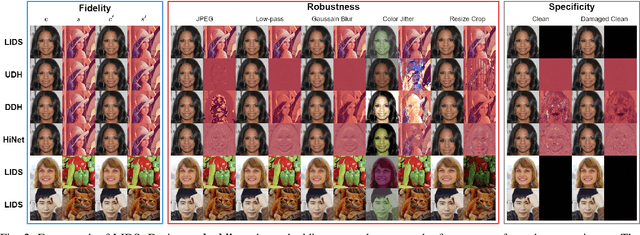
Image deep steganography (IDS) is a technique that utilizes deep learning to embed a secret image invisibly into a cover image to generate a container image. However, the container images generated by convolutional neural networks (CNNs) are vulnerable to attacks that distort their high-frequency components. To address this problem, we propose a novel method called Low-frequency Image Deep Steganography (LIDS) that allows frequency distribution manipulation in the embedding process. LIDS extracts a feature map from the secret image and adds it to the cover image to yield the container image. The container image is not directly output by the CNNs, and thus, it does not contain high-frequency artifacts. The extracted feature map is regulated by a frequency loss to ensure that its frequency distribution mainly concentrates on the low-frequency domain. To further enhance robustness, an attack layer is inserted to damage the container image. The retrieval network then retrieves a recovered secret image from a damaged container image. Our experiments demonstrate that LIDS outperforms state-of-the-art methods in terms of robustness, while maintaining high fidelity and specificity. By avoiding high-frequency artifacts and manipulating the frequency distribution of the embedded feature map, LIDS achieves improved robustness against attacks that distort the high-frequency components of container images.
Generative Image Inpainting with Segmentation Confusion Adversarial Training and Contrastive Learning
Mar 23, 2023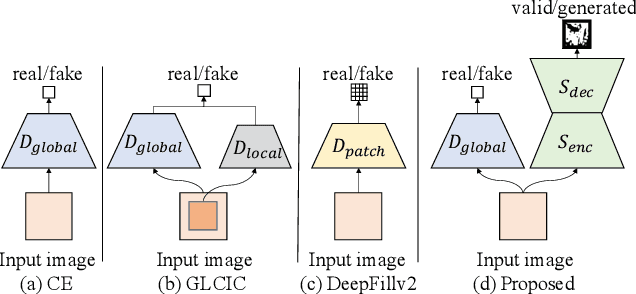

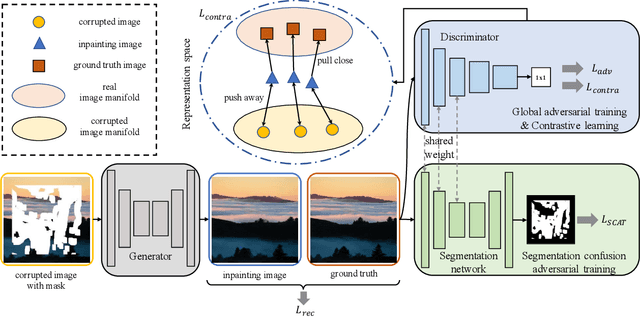
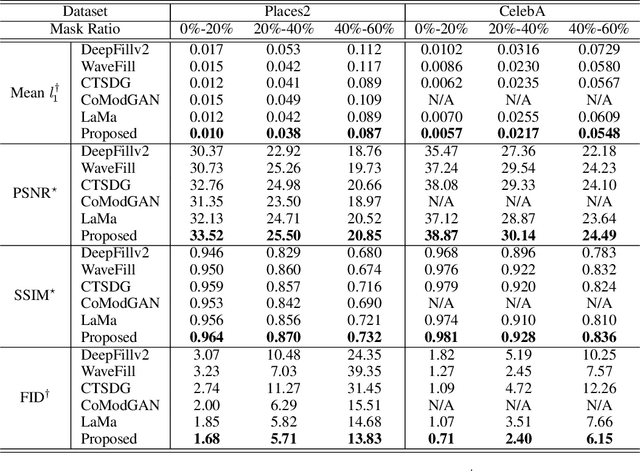
This paper presents a new adversarial training framework for image inpainting with segmentation confusion adversarial training (SCAT) and contrastive learning. SCAT plays an adversarial game between an inpainting generator and a segmentation network, which provides pixel-level local training signals and can adapt to images with free-form holes. By combining SCAT with standard global adversarial training, the new adversarial training framework exhibits the following three advantages simultaneously: (1) the global consistency of the repaired image, (2) the local fine texture details of the repaired image, and (3) the flexibility of handling images with free-form holes. Moreover, we propose the textural and semantic contrastive learning losses to stabilize and improve our inpainting model's training by exploiting the feature representation space of the discriminator, in which the inpainting images are pulled closer to the ground truth images but pushed farther from the corrupted images. The proposed contrastive losses better guide the repaired images to move from the corrupted image data points to the real image data points in the feature representation space, resulting in more realistic completed images. We conduct extensive experiments on two benchmark datasets, demonstrating our model's effectiveness and superiority both qualitatively and quantitatively.
Bridging the Performance Gap between DETR and R-CNN for Graphical Object Detection in Document Images
Jun 23, 2023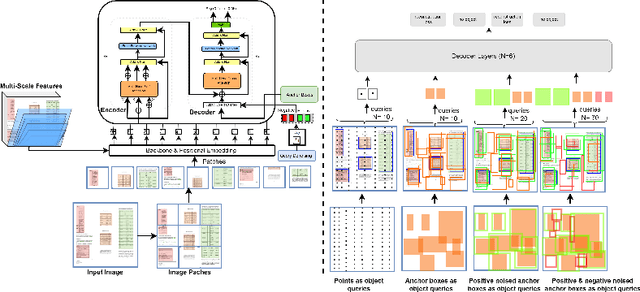
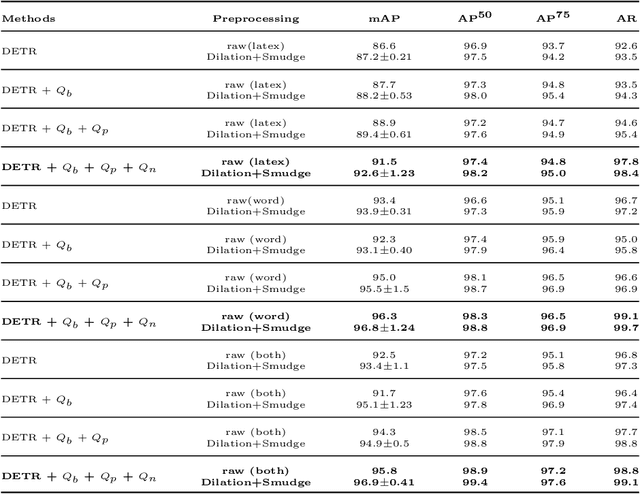
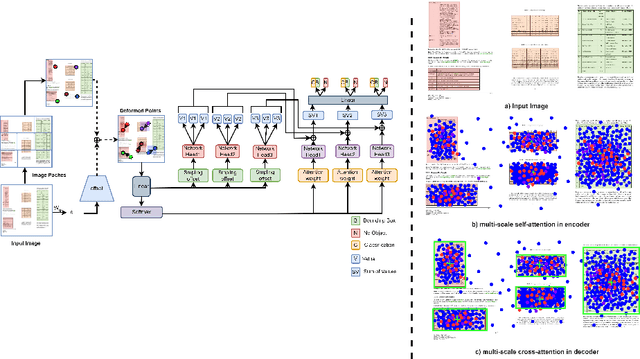
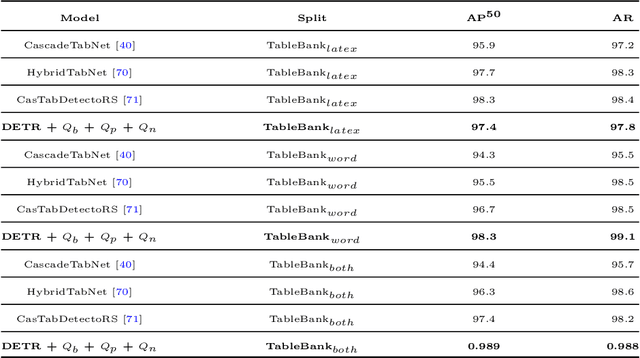
This paper takes an important step in bridging the performance gap between DETR and R-CNN for graphical object detection. Existing graphical object detection approaches have enjoyed recent enhancements in CNN-based object detection methods, achieving remarkable progress. Recently, Transformer-based detectors have considerably boosted the generic object detection performance, eliminating the need for hand-crafted features or post-processing steps such as Non-Maximum Suppression (NMS) using object queries. However, the effectiveness of such enhanced transformer-based detection algorithms has yet to be verified for the problem of graphical object detection. Essentially, inspired by the latest advancements in the DETR, we employ the existing detection transformer with few modifications for graphical object detection. We modify object queries in different ways, using points, anchor boxes and adding positive and negative noise to the anchors to boost performance. These modifications allow for better handling of objects with varying sizes and aspect ratios, more robustness to small variations in object positions and sizes, and improved image discrimination between objects and non-objects. We evaluate our approach on the four graphical datasets: PubTables, TableBank, NTable and PubLaynet. Upon integrating query modifications in the DETR, we outperform prior works and achieve new state-of-the-art results with the mAP of 96.9\%, 95.7\% and 99.3\% on TableBank, PubLaynet, PubTables, respectively. The results from extensive ablations show that transformer-based methods are more effective for document analysis analogous to other applications. We hope this study draws more attention to the research of using detection transformers in document image analysis.
Robust Contrastive Language-Image Pretraining against Adversarial Attacks
Mar 13, 2023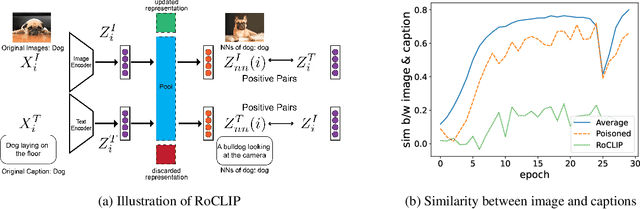
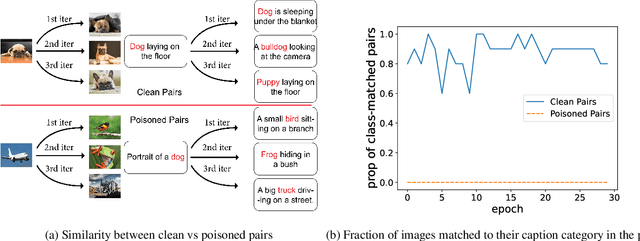
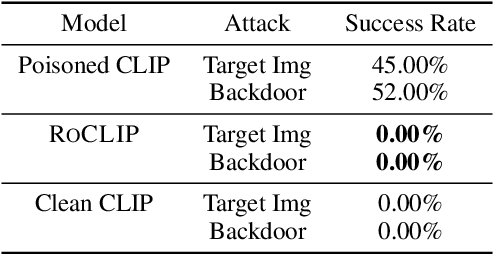
Contrastive vision-language representation learning has achieved state-of-the-art performance for zero-shot classification, by learning from millions of image-caption pairs crawled from the internet. However, the massive data that powers large multimodal models such as CLIP, makes them extremely vulnerable to various types of adversarial attacks, including targeted and backdoor data poisoning attacks. Despite this vulnerability, robust contrastive vision-language pretraining against adversarial attacks has remained unaddressed. In this work, we propose RoCLIP, the first effective method for robust pretraining {and fine-tuning} multimodal vision-language models. RoCLIP effectively breaks the association between poisoned image-caption pairs by considering a pool of random examples, and (1) matching every image with the text that is most similar to its caption in the pool, and (2) matching every caption with the image that is most similar to its image in the pool. Our extensive experiments show that our method renders state-of-the-art targeted data poisoning and backdoor attacks ineffective during pre-training or fine-tuning of CLIP. In particular, RoCLIP decreases the poison and backdoor attack success rates down to 0\% during pre-training and 1\%-4\% during fine-tuning, and effectively improves the model's performance.
Multimodal Deep Learning for Personalized Renal Cell Carcinoma Prognosis: Integrating CT Imaging and Clinical Data
Jul 07, 2023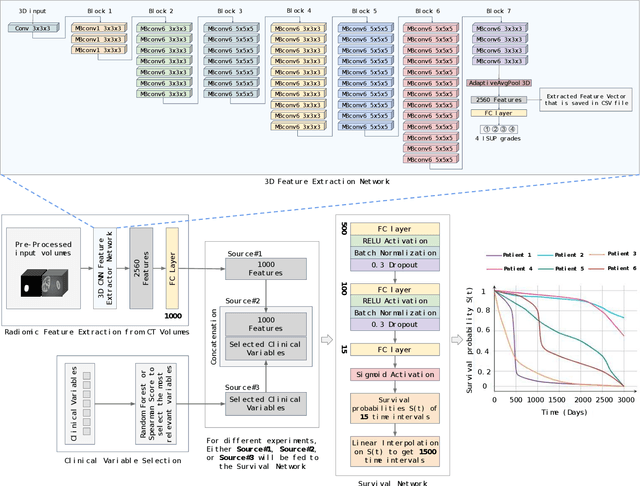
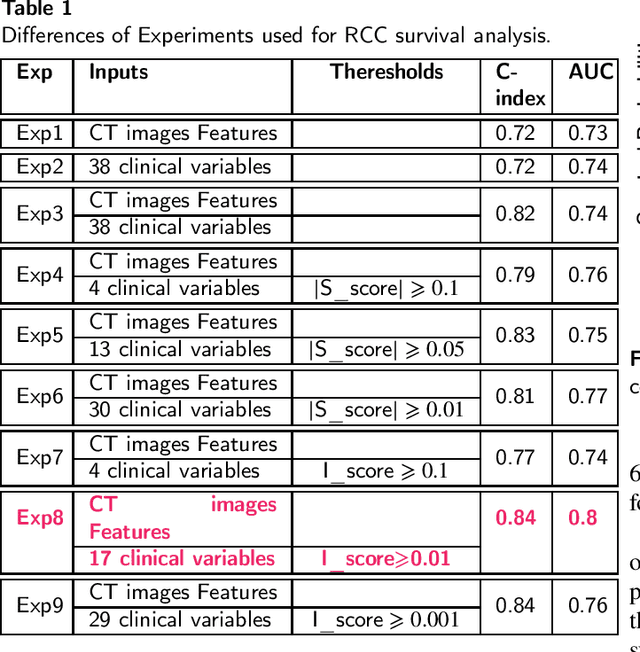
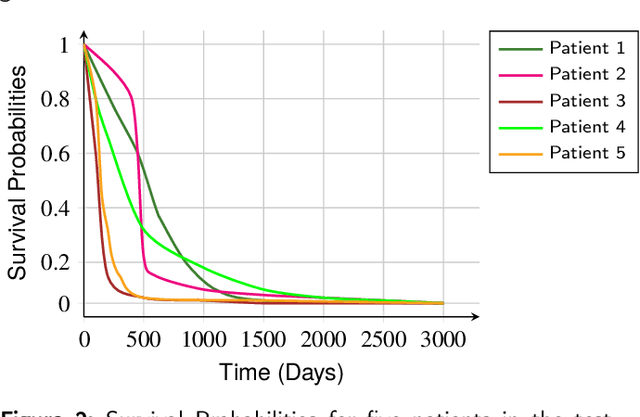
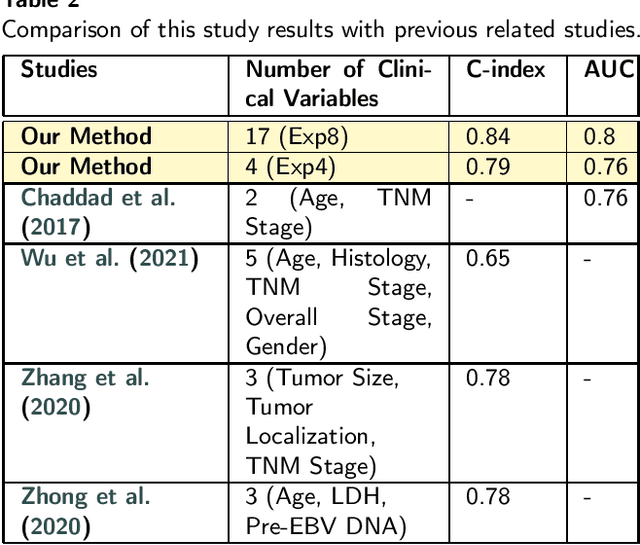
Renal cell carcinoma represents a significant global health challenge with a low survival rate. This research aimed to devise a comprehensive deep-learning model capable of predicting survival probabilities in patients with renal cell carcinoma by integrating CT imaging and clinical data and addressing the limitations observed in prior studies. The aim is to facilitate the identification of patients requiring urgent treatment. The proposed framework comprises three modules: a 3D image feature extractor, clinical variable selection, and survival prediction. The feature extractor module, based on the 3D CNN architecture, predicts the ISUP grade of renal cell carcinoma tumors linked to mortality rates from CT images. A selection of clinical variables is systematically chosen using the Spearman score and random forest importance score as criteria. A deep learning-based network, trained with discrete LogisticHazard-based loss, performs the survival prediction. Nine distinct experiments are performed, with varying numbers of clinical variables determined by different thresholds of the Spearman and importance scores. Our findings demonstrate that the proposed strategy surpasses the current literature on renal cancer prognosis based on CT scans and clinical factors. The best-performing experiment yielded a concordance index of 0.84 and an area under the curve value of 0.8 on the test cohort, which suggests strong predictive power. The multimodal deep-learning approach developed in this study shows promising results in estimating survival probabilities for renal cell carcinoma patients using CT imaging and clinical data. This may have potential implications in identifying patients who require urgent treatment, potentially improving patient outcomes. The code created for this project is available for the public on: \href{https://github.com/Balasingham-AI-Group/Survival_CTplusClinical}{GitHub}
Efficient and fully-automatic retinal choroid segmentation in OCT through DL-based distillation of a hand-crafted pipeline
Jul 03, 2023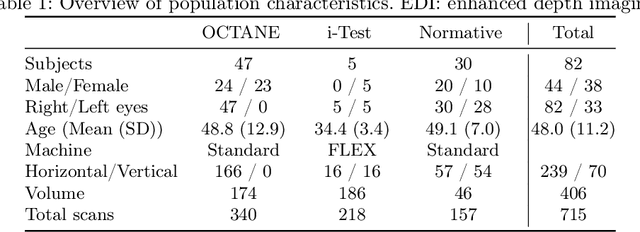
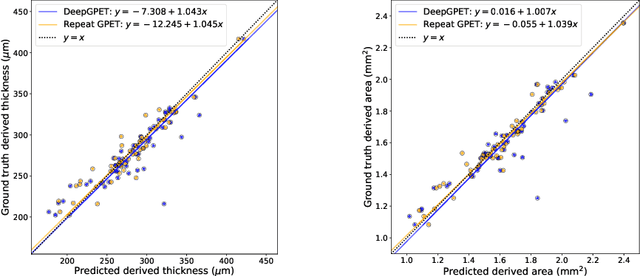
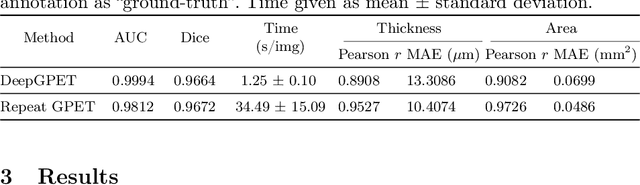
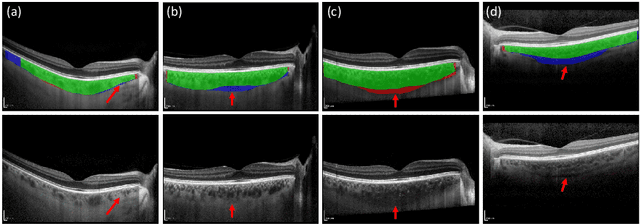
Retinal vascular phenotypes, derived from low-cost, non-invasive retinal imaging, have been linked to systemic conditions such as cardio-, neuro- and reno-vascular disease. Recent high-resolution optical coherence tomography (OCT) allows imaging of the choroidal microvasculature which could provide more information about vascular health that complements the superficial retinal vessels, which current vascular phenotypes are based on. Segmentation of the choroid in OCT is a key step in quantifying choroidal parameters like thickness and area. Gaussian Process Edge Tracing (GPET) is a promising, clinically validated method for this. However, GPET is semi-automatic and thus requires time-consuming manual interventions by specifically trained personnel which introduces subjectivity and limits the potential for analysing larger datasets or deploying GPET into clinical practice. We introduce DeepGPET, which distils GPET into a neural network to yield a fully-automatic and efficient choroidal segmentation method. DeepGPET achieves excellent agreement with GPET on data from 3 clinical studies (AUC=0.9994, Dice=0.9664; Pearson correlation of 0.8908 for choroidal thickness and 0.9082 for choroidal area), while reducing the mean processing time per image from 34.49s ($\pm$15.09) to 1.25s ($\pm$0.10) on a standard laptop CPU and removing all manual interventions. DeepGPET will be made available for researchers upon publication.