 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evaluation of Environmental Conditions on Object Detection using Oriented Bounding Boxes for AR Applications
Jun 29, 2023
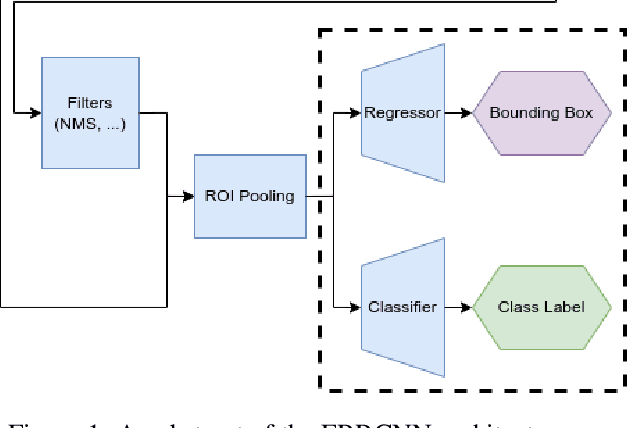
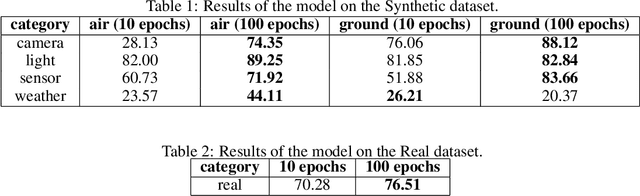
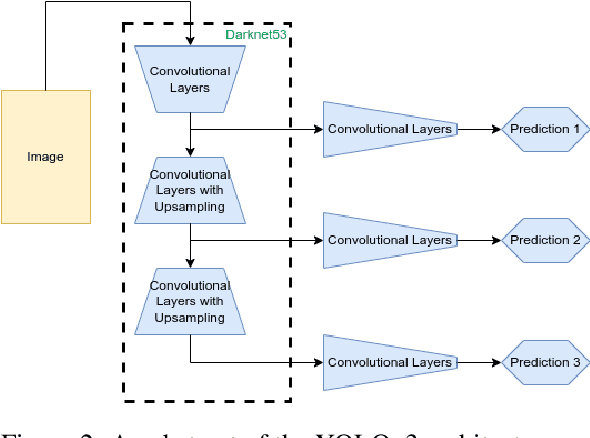

The objective of augmented reality (AR) is to add digital content to natural images and videos to create an interactive experience between the user and the environment. Scene analysis and object recognition play a crucial role in AR, as they must be performed quickly and accurately. In this study, a new approach is proposed that involves using oriented bounding boxes with a detection and recognition deep network to improve performance and processing time. The approach is evaluated using two datasets: a real image dataset (DOTA dataset) commonly used for computer vision tasks, and a synthetic dataset that simulates different environmental, lighting, and acquisition conditions. The focus of the evaluation is on small objects, which are difficult to detect and recognise. The results indicate that the proposed approach tends to produce better Average Precision and greater accuracy for small objects in most of the tested conditions.
Towards Accurate Data-free Quantization for Diffusion Models
Jun 07, 2023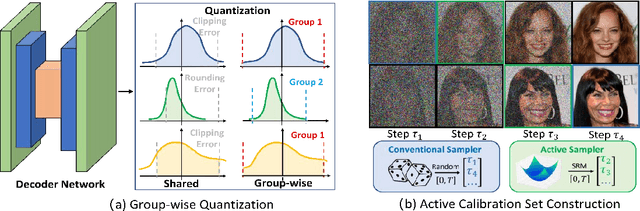
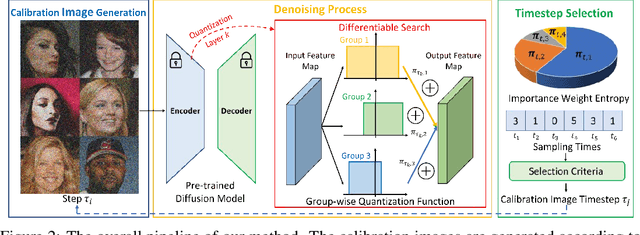

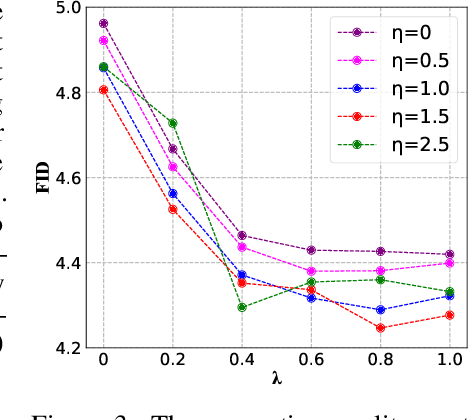
In this paper, we propose an accurate data-free post-training quantization framework of diffusion models (ADP-DM) for efficient image generation. Conventional data-free quantization methods learn shared quantization functions for tensor discretization regardless of the generation timesteps, while the activation distribution differs significantly across various timesteps. The calibration images are acquired in random timesteps which fail to provide sufficient information for generalizable quantization function learning. Both issues cause sizable quantization errors with obvious image generation performance degradation. On the contrary, we design group-wise quantization functions for activation discretization in different timesteps and sample the optimal timestep for informative calibration image generation, so that our quantized diffusion model can reduce the discretization errors with negligible computational overhead. Specifically, we partition the timesteps according to the importance weights of quantization functions in different groups, which are optimized by differentiable search algorithms. We also select the optimal timestep for calibration image generation by structural risk minimizing principle in order to enhance the generalization ability in the deployment of quantized diffusion model. Extensive experimental results show that our method outperforms the state-of-the-art post-training quantization of diffusion model by a sizable margin with similar computational cost.
Improving Negative-Prompt Inversion via Proximal Guidance
Jun 08, 2023
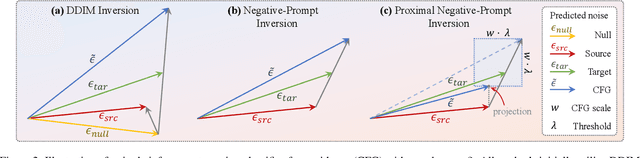
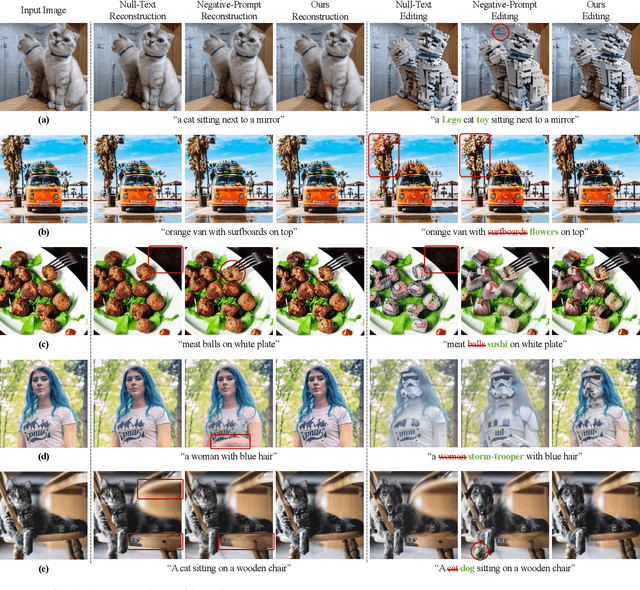

DDIM inversion has revealed the remarkable potential of real image editing within diffusion-based methods. However, the accuracy of DDIM reconstruction degrades as larger classifier-free guidance (CFG) scales being used for enhanced editing. Null-text inversion (NTI) optimizes null embeddings to align the reconstruction and inversion trajectories with larger CFG scales, enabling real image editing with cross-attention control. Negative-prompt inversion (NPI) further offers a training-free closed-form solution of NTI. However, it may introduce artifacts and is still constrained by DDIM reconstruction quality. To overcome these limitations, we propose Proximal Negative-Prompt Inversion (ProxNPI), extending the concepts of NTI and NPI. We enhance NPI with a regularization term and reconstruction guidance, which reduces artifacts while capitalizing on its training-free nature. Our method provides an efficient and straightforward approach, effectively addressing real image editing tasks with minimal computational overhead.
Dual-Gated Fusion with Prefix-Tuning for Multi-Modal Relation Extraction
Jun 19, 2023

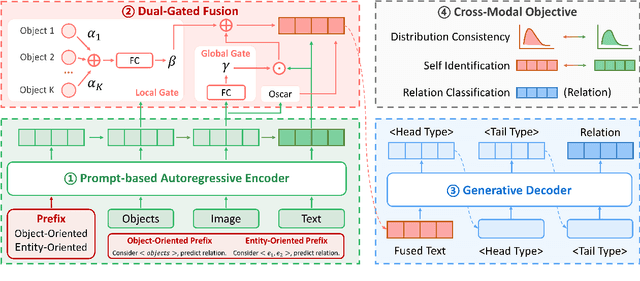
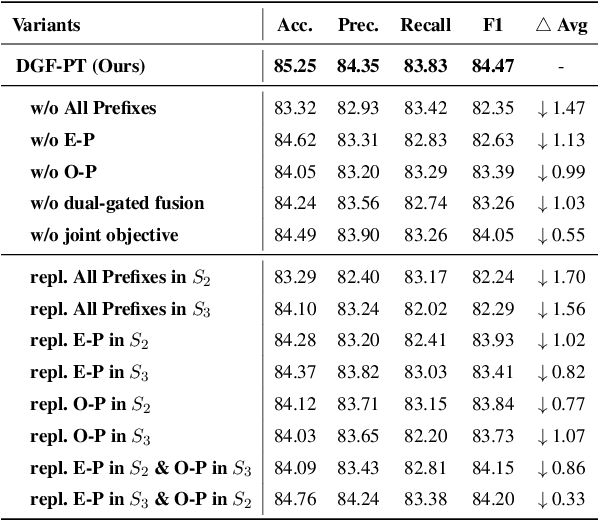
Multi-Modal Relation Extraction (MMRE) aims at identifying the relation between two entities in texts that contain visual clues. Rich visual content is valuable for the MMRE task, but existing works cannot well model finer associations among different modalities, failing to capture the truly helpful visual information and thus limiting relation extraction performance. In this paper, we propose a novel MMRE framework to better capture the deeper correlations of text, entity pair, and image/objects, so as to mine more helpful information for the task, termed as DGF-PT. We first propose a prompt-based autoregressive encoder, which builds the associations of intra-modal and inter-modal features related to the task, respectively by entity-oriented and object-oriented prefixes. To better integrate helpful visual information, we design a dual-gated fusion module to distinguish the importance of image/objects and further enrich text representations. In addition, a generative decoder is introduced with entity type restriction on relations, better filtering out candidates. Extensive experiments conducted on the benchmark dataset show that our approach achieves excellent performance compared to strong competitors, even in the few-shot situation.
CT Multi-Task Learning with a Large Image-Text (LIT) Model
Apr 03, 2023Large language models (LLM) not only empower multiple language tasks but also serve as a general interface across different spaces. Up to now, it has not been demonstrated yet how to effectively translate the successes of LLMs in the computer vision field to the medical imaging field which involves high-dimensional and multi-modal medical images. In this paper, we report a feasibility study of building a multi-task CT large image-text (LIT) model for lung cancer diagnosis by combining an LLM and a large image model (LIM). Specifically, the LLM and LIM are used as encoders to perceive multi-modal information under task-specific text prompts, which synergizes multi-source information and task-specific and patient-specific priors for optimized diagnostic performance. The key components of our LIT model and associated techniques are evaluated with an emphasis on 3D lung CT analysis. Our initial results show that the LIT model performs multiple medical tasks well, including lung segmentation, lung nodule detection, and lung cancer classification. Active efforts are in progress to develop large image-language models for superior medical imaging in diverse applications and optimal patient outcomes.
Tag2Text: Guiding Vision-Language Model via Image Tagging
Mar 10, 2023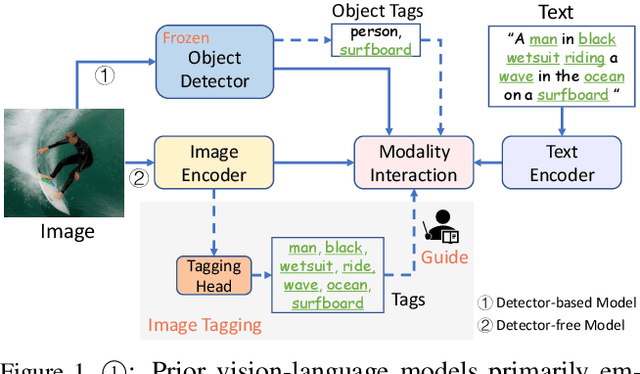
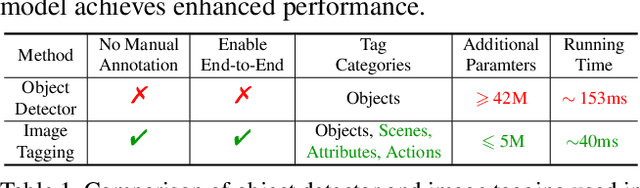

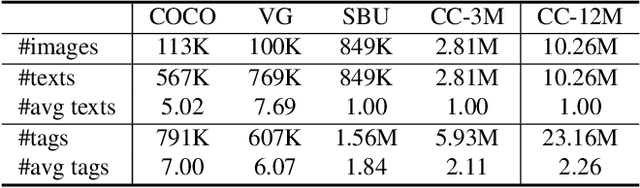
This paper presents Tag2Text, a vision language pre-training (VLP) framework, which introduces image tagging into vision-language models to guide the learning of visual-linguistic features. In contrast to prior works which utilize object tags either manually labeled or automatically detected with a limited detector, our approach utilizes tags parsed from its paired text to learn an image tagger and meanwhile provides guidance to vision-language models. Given that, Tag2Text can utilize large-scale annotation-free image tags in accordance with image-text pairs, and provides more diverse tag categories beyond objects. As a result, Tag2Text achieves a superior image tag recognition ability by exploiting fine-grained text information. Moreover, by leveraging tagging guidance, Tag2Text effectively enhances the performance of vision-language models on both generation-based and alignment-based tasks. Across a wide range of downstream benchmarks, Tag2Text achieves state-of-the-art or competitive results with similar model sizes and data scales, demonstrating the efficacy of the proposed tagging guidance.
Retrieval-augmented Image Captioning
Feb 16, 2023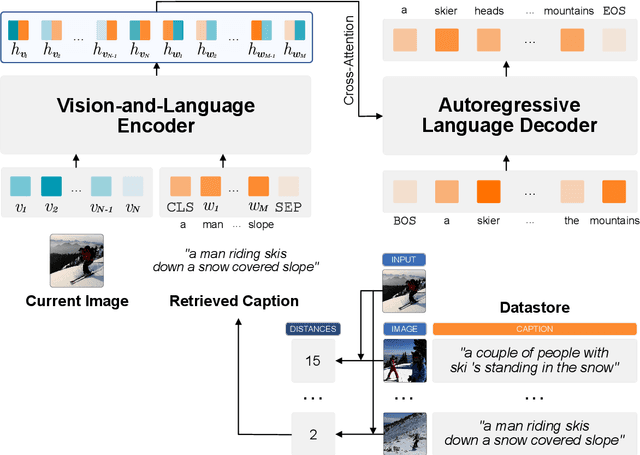
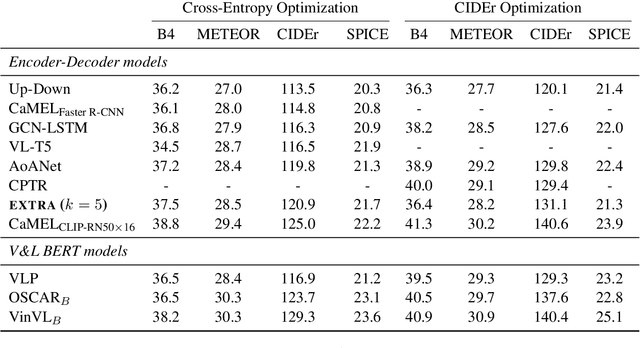
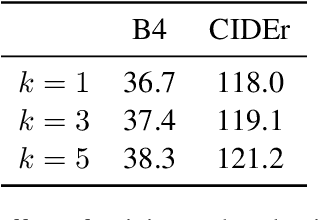
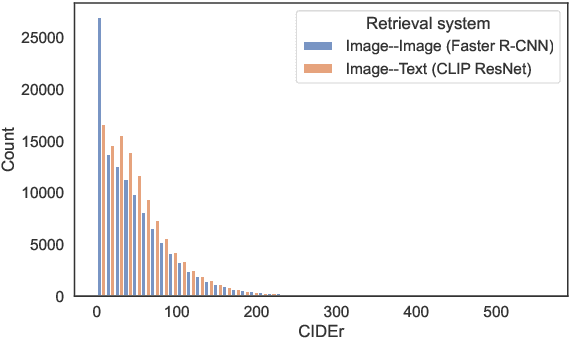
Inspired by retrieval-augmented language generation and pretrained Vision and Language (V&L) encoders, we present a new approach to image captioning that generates sentences given the input image and a set of captions retrieved from a datastore, as opposed to the image alone. The encoder in our model jointly processes the image and retrieved captions using a pretrained V&L BERT, while the decoder attends to the multimodal encoder representations, benefiting from the extra textual evidence from the retrieved captions. Experimental results on the COCO dataset show that image captioning can be effectively formulated from this new perspective. Our model, named EXTRA, benefits from using captions retrieved from the training dataset, and it can also benefit from using an external dataset without the need for retraining. Ablation studies show that retrieving a sufficient number of captions (e.g., k=5) can improve captioning quality. Our work contributes towards using pretrained V&L encoders for generative tasks, instead of standard classification tasks.
Palm: Predicting Actions through Language Models @ Ego4D Long-Term Action Anticipation Challenge 2023
Jun 28, 2023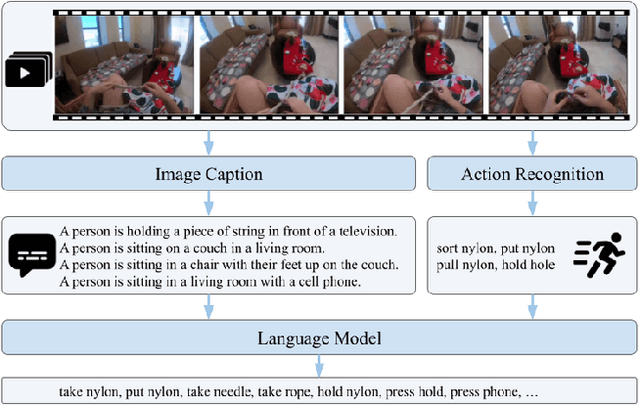
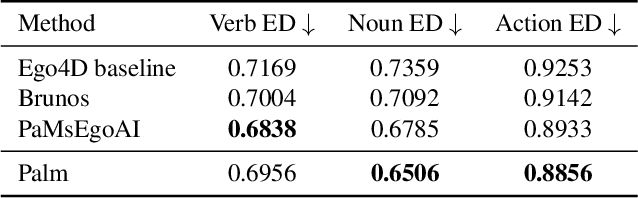

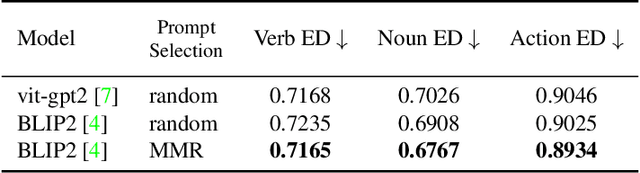
We present Palm, a solution to the Long-Term Action Anticipation (LTA) task utilizing vision-language and large language models. Given an input video with annotated action periods, the LTA task aims to predict possible future actions. We hypothesize that an optimal solution should capture the interdependency between past and future actions, and be able to infer future actions based on the structure and dependency encoded in the past actions. Large language models have demonstrated remarkable commonsense-based reasoning ability. Inspired by that, Palm chains an image captioning model and a large language model. It predicts future actions based on frame descriptions and action labels extracted from the input videos. Our method outperforms other participants in the EGO4D LTA challenge and achieves the best performance in terms of action prediction. Our code is available at https://github.com/DanDoge/Palm
Geometric Ultrasound Localization Microscopy
Jun 28, 2023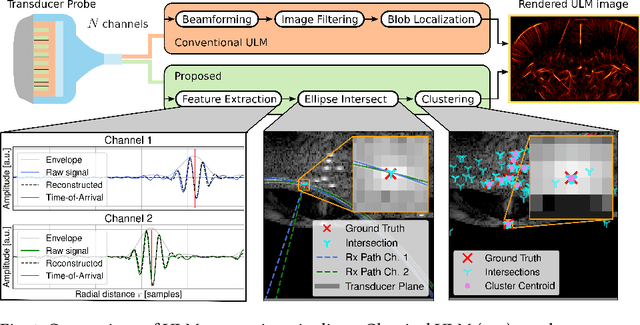
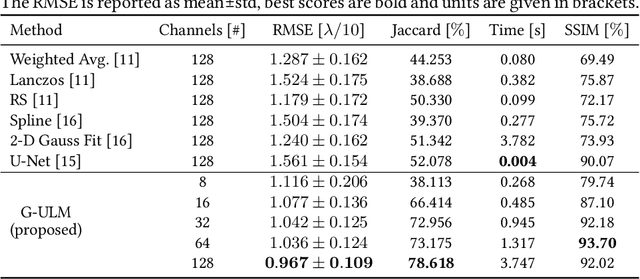
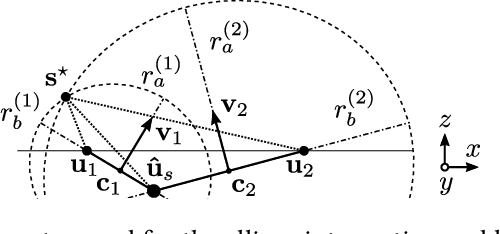
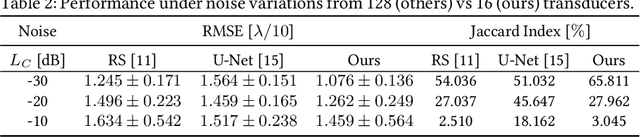
Contrast-Enhanced Ultra-Sound (CEUS) has become a viable method for non-invasive, dynamic visualization in medical diagnostics, yet Ultrasound Localization Microscopy (ULM) has enabled a revolutionary breakthrough by offering ten times higher resolution. To date, Delay-And-Sum (DAS) beamformers are used to render ULM frames, ultimately determining the image resolution capability. To take full advantage of ULM, this study questions whether beamforming is the most effective processing step for ULM, suggesting an alternative approach that relies solely on Time-Difference-of-Arrival (TDoA) information. To this end, a novel geometric framework for micro bubble localization via ellipse intersections is proposed to overcome existing beamforming limitations. We present a benchmark comparison based on a public dataset for which our geometric ULM outperforms existing baseline methods in terms of accuracy and reliability while only utilizing a portion of the available transducer data.
Neglected Free Lunch; Learning Image Classifiers Using Annotation Byproducts
Apr 04, 2023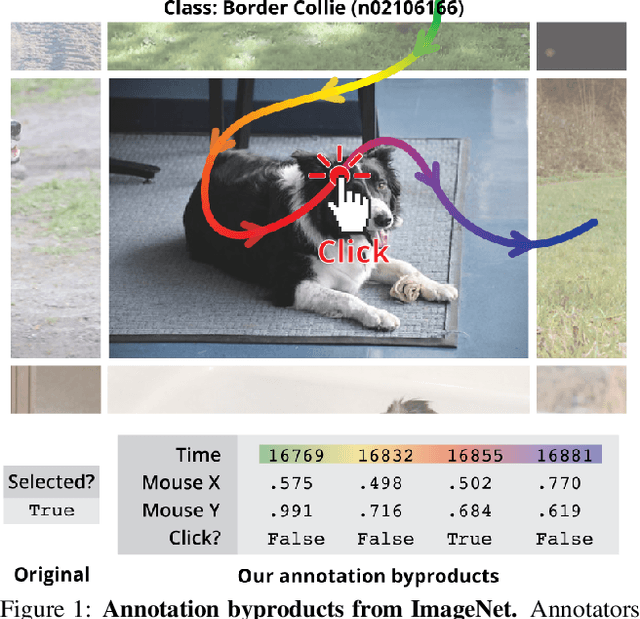
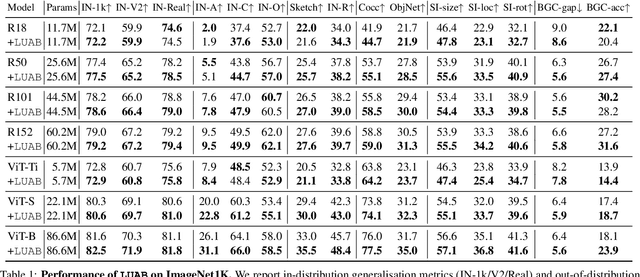
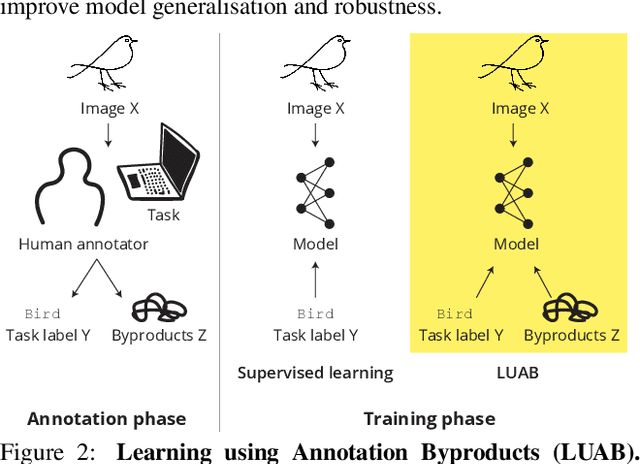
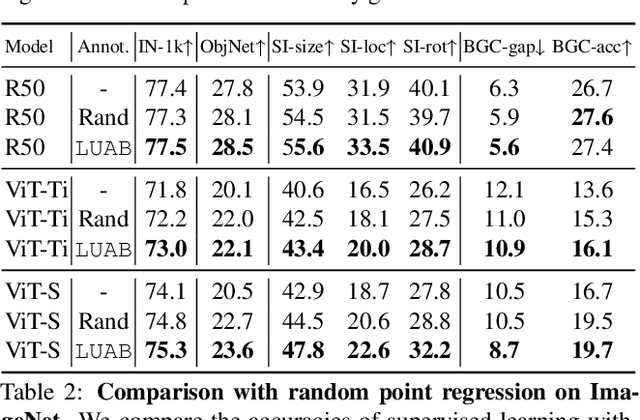
Supervised learning of image classifiers distills human knowledge into a parametric model through pairs of images and corresponding labels (X,Y). We argue that this simple and widely used representation of human knowledge neglects rich auxiliary information from the annotation procedure, such as the time-series of mouse traces and clicks left after image selection. Our insight is that such annotation byproducts Z provide approximate human attention that weakly guides the model to focus on the foreground cues, reducing spurious correlations and discouraging shortcut learning. To verify this, we create ImageNet-AB and COCO-AB. They are ImageNet and COCO training sets enriched with sample-wise annotation byproducts, collected by replicating the respective original annotation tasks. We refer to the new paradigm of training models with annotation byproducts as learning using annotation byproducts (LUAB). We show that a simple multitask loss for regressing Z together with Y already improves the generalisability and robustness of the learned models. Compared to the original supervised learning, LUAB does not require extra annotation costs. ImageNet-AB and COCO-AB are at https://github.com/naver-ai/NeglectedFreeLunch.