 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Efficient Transformer for Simultaneous Learning of BEV and Lane Representations in 3D Lane Detection
Jun 08, 2023
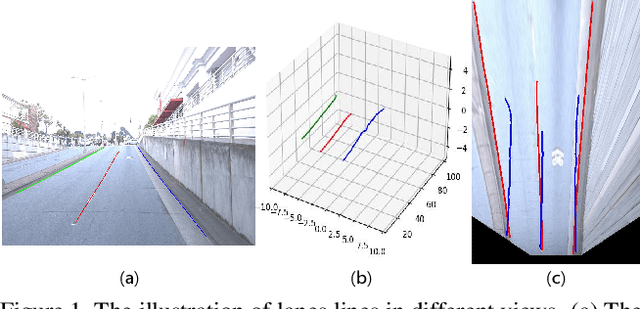

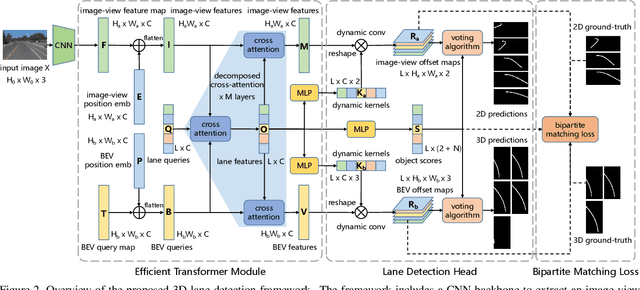
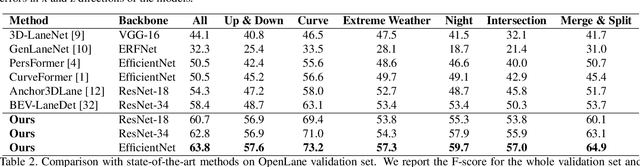
Accurately detecting lane lines in 3D space is crucial for autonomous driving. Existing methods usually first transform image-view features into bird-eye-view (BEV) by aid of inverse perspective mapping (IPM), and then detect lane lines based on the BEV features. However, IPM ignores the changes in road height, leading to inaccurate view transformations. Additionally, the two separate stages of the process can cause cumulative errors and increased complexity. To address these limitations, we propose an efficient transformer for 3D lane detection. Different from the vanilla transformer, our model contains a decomposed cross-attention mechanism to simultaneously learn lane and BEV representations. The mechanism decomposes the cross-attention between image-view and BEV features into the one between image-view and lane features, and the one between lane and BEV features, both of which are supervised with ground-truth lane lines. Our method obtains 2D and 3D lane predictions by applying the lane features to the image-view and BEV features, respectively. This allows for a more accurate view transformation than IPM-based methods, as the view transformation is learned from data with a supervised cross-attention. Additionally, the cross-attention between lane and BEV features enables them to adjust to each other, resulting in more accurate lane detection than the two separate stages. Finally, the decomposed cross-attention is more efficient than the original one. Experimental results on OpenLane and ONCE-3DLanes demonstrate the state-of-the-art performance of our method.
Imagery Tracking of Sun Activity Using 2D Circular Kernel Time Series Transformation, Entropy Measures and Machine Learning Approaches
Jun 14, 2023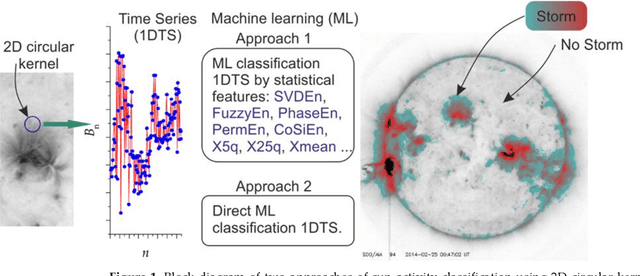
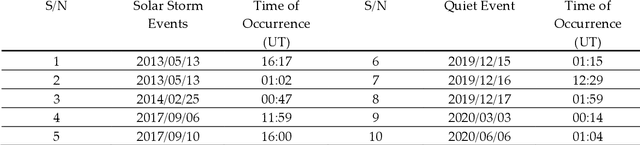

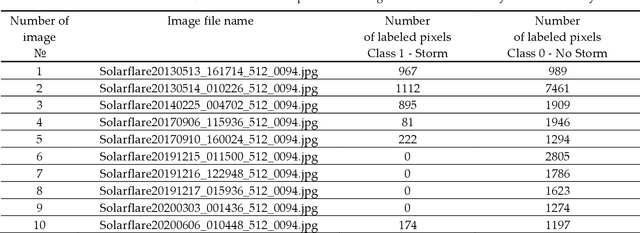
The sun is highly complex in nature and its observatory imagery features is one of the most important sources of information about the sun activity, space and Earth's weather conditions. The NASA, solar Dynamics Observatory captures approximately 70,000 images of the sun activity in a day and the continuous visual inspection of this solar observatory images is challenging. In this study, we developed a technique of tracking the sun's activity using 2D circular kernel time series transformation, statistical and entropy measures, with machine learning approaches. The technique involves transforming the solar observatory image section into 1-Dimensional time series (1-DTS) while the statistical and entropy measures (Approach 1) and direct classification (Approach 2) is used to capture the extraction features from the 1-DTS for machine learning classification into 'solar storm' and 'no storm'. We found that the potential accuracy of the model in tracking the activity of the sun is approximately 0.981 for Approach 1 and 0.999 for Approach 2. The stability of the developed approach to rotational transformation of the solar observatory image is evident. When training on the original dataset for Approach 1, the match index (T90) of the distribution of solar storm areas reaches T90 ~ 0.993, and T90 ~ 0.951 for Approach 2. In addition, when using the extended training base, the match indices increased to T90 ~ 0.994 and T90 ~ 1, respectively. This model consistently classifies areas with swirling magnetic lines associated with solar storms and is robust to image rotation, glare, and optical artifacts.
Aria Digital Twin: A New Benchmark Dataset for Egocentric 3D Machine Perception
Jun 13, 2023
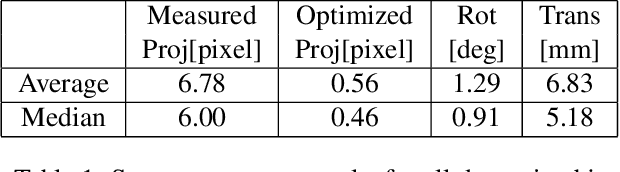
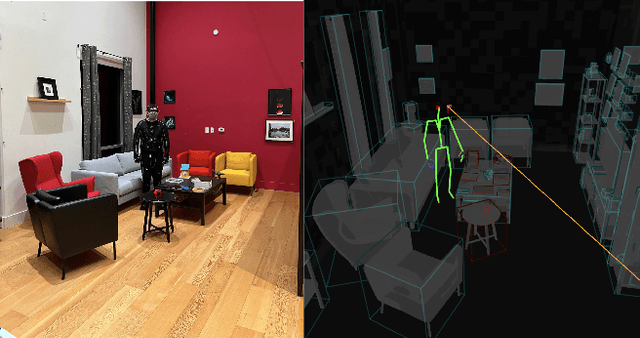
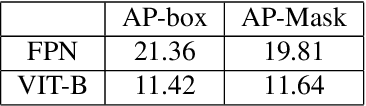
We introduce the Aria Digital Twin (ADT) - an egocentric dataset captured using Aria glasses with extensive object, environment, and human level ground truth. This ADT release contains 200 sequences of real-world activities conducted by Aria wearers in two real indoor scenes with 398 object instances (324 stationary and 74 dynamic). Each sequence consists of: a) raw data of two monochrome camera streams, one RGB camera stream, two IMU streams; b) complete sensor calibration; c) ground truth data including continuous 6-degree-of-freedom (6DoF) poses of the Aria devices, object 6DoF poses, 3D eye gaze vectors, 3D human poses, 2D image segmentations, image depth maps; and d) photo-realistic synthetic renderings. To the best of our knowledge, there is no existing egocentric dataset with a level of accuracy, photo-realism and comprehensiveness comparable to ADT. By contributing ADT to the research community, our mission is to set a new standard for evaluation in the egocentric machine perception domain, which includes very challenging research problems such as 3D object detection and tracking, scene reconstruction and understanding, sim-to-real learning, human pose prediction - while also inspiring new machine perception tasks for augmented reality (AR) applications. To kick start exploration of the ADT research use cases, we evaluated several existing state-of-the-art methods for object detection, segmentation and image translation tasks that demonstrate the usefulness of ADT as a benchmarking dataset.
Compositionally Equivariant Representation Learning
Jun 13, 2023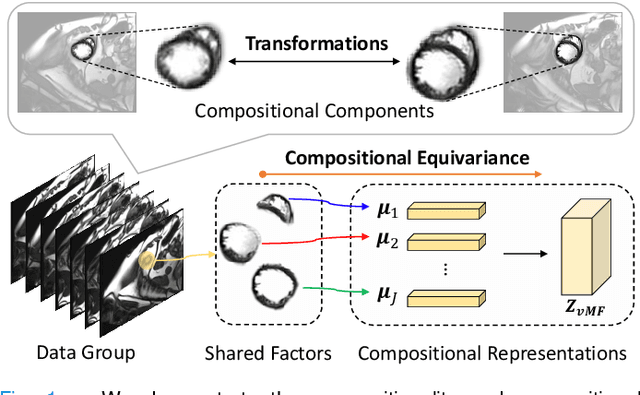
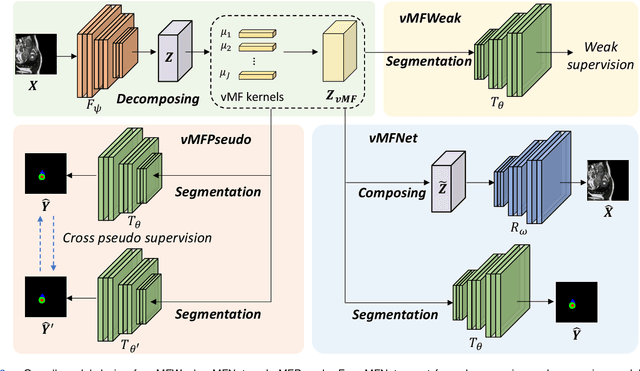
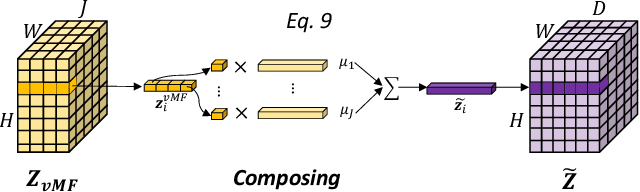
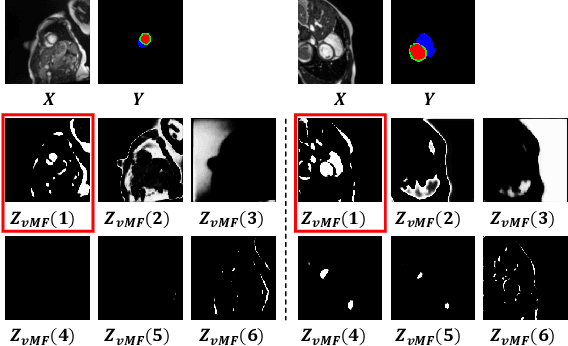
Deep learning models often need sufficient supervision (i.e. labelled data) in order to be trained effectively. By contrast, humans can swiftly learn to identify important anatomy in medical images like MRI and CT scans, with minimal guidance. This recognition capability easily generalises to new images from different medical facilities and to new tasks in different settings. This rapid and generalisable learning ability is largely due to the compositional structure of image patterns in the human brain, which are not well represented in current medical models. In this paper, we study the utilisation of compositionality in learning more interpretable and generalisable representations for medical image segmentation. Overall, we propose that the underlying generative factors that are used to generate the medical images satisfy compositional equivariance property, where each factor is compositional (e.g. corresponds to the structures in human anatomy) and also equivariant to the task. Hence, a good representation that approximates well the ground truth factor has to be compositionally equivariant. By modelling the compositional representations with learnable von-Mises-Fisher (vMF) kernels, we explore how different design and learning biases can be used to enforce the representations to be more compositionally equivariant under un-, weakly-, and semi-supervised settings. Extensive results show that our methods achieve the best performance over several strong baselines on the task of semi-supervised domain-generalised medical image segmentation. Code will be made publicly available upon acceptance at https://github.com/vios-s.
UniDiff: Advancing Vision-Language Models with Generative and Discriminative Learning
Jun 01, 2023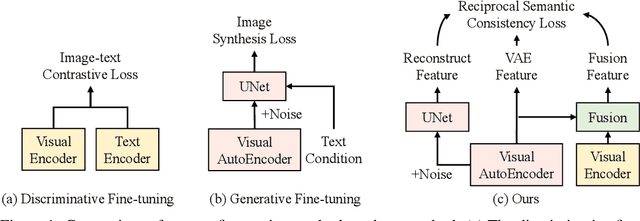
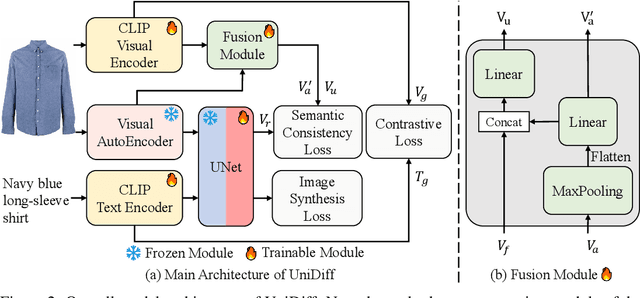

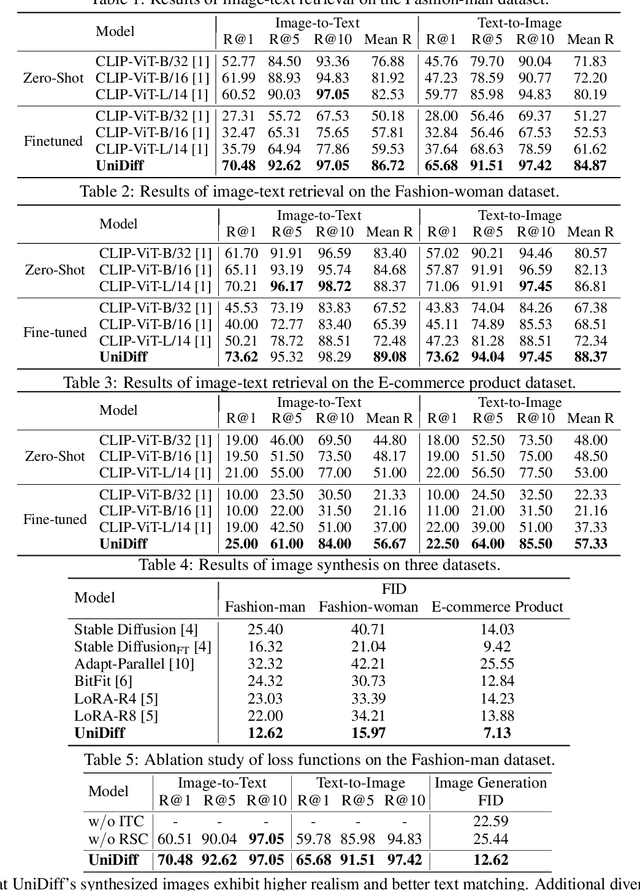
Recent advances in vision-language pre-training have enabled machines to perform better in multimodal object discrimination (e.g., image-text semantic alignment) and image synthesis (e.g., text-to-image generation). On the other hand, fine-tuning pre-trained models with discriminative or generative capabilities such as CLIP and Stable Diffusion on domain-specific datasets has shown to be effective in various tasks by adapting to specific domains. However, few studies have explored the possibility of learning both discriminative and generative capabilities and leveraging their synergistic effects to create a powerful and personalized multimodal model during fine-tuning. This paper presents UniDiff, a unified multi-modal model that integrates image-text contrastive learning (ITC), text-conditioned image synthesis learning (IS), and reciprocal semantic consistency modeling (RSC). UniDiff effectively learns aligned semantics and mitigates the issue of semantic collapse during fine-tuning on small datasets by leveraging RSC on visual features from CLIP and diffusion models, without altering the pre-trained model's basic architecture. UniDiff demonstrates versatility in both multi-modal understanding and generative tasks. Experimental results on three datasets (Fashion-man, Fashion-woman, and E-commercial Product) showcase substantial enhancements in vision-language retrieval and text-to-image generation, illustrating the advantages of combining discriminative and generative fine-tuning. The proposed UniDiff model establishes a robust pipeline for personalized modeling and serves as a benchmark for future comparisons in the field.
UniBoost: Unsupervised Unimodal Pre-training for Boosting Zero-shot Vision-Language Tasks
Jun 07, 2023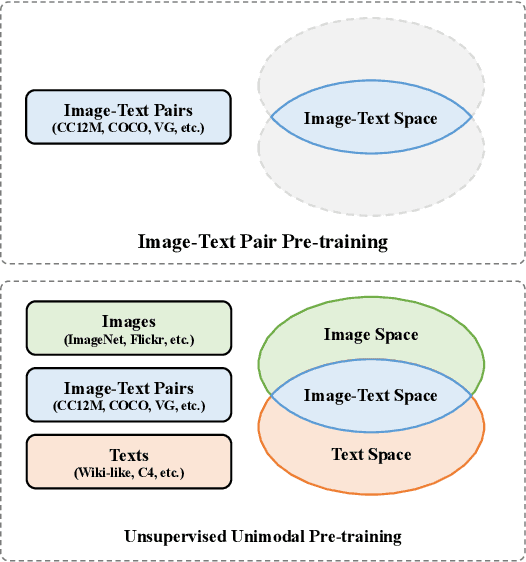

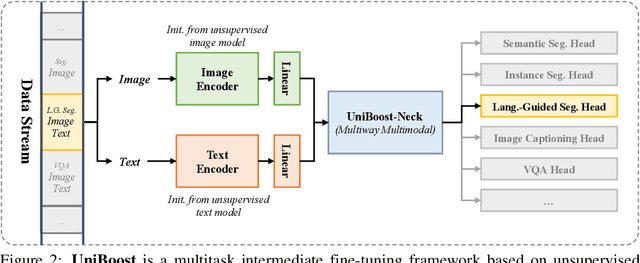
Large-scale joint training of multimodal models, e.g., CLIP, have demonstrated great performance in many vision-language tasks. However, image-text pairs for pre-training are restricted to the intersection of images and texts, limiting their ability to cover a large distribution of real-world data, where noise can also be introduced as misaligned pairs during pre-processing. Conversely, unimodal models trained on text or image data alone through unsupervised techniques can achieve broader coverage of diverse real-world data and are not constrained by the requirement of simultaneous presence of image and text. In this paper, we demonstrate that using large-scale unsupervised unimodal models as pre-training can enhance the zero-shot performance of image-text pair models. Our thorough studies validate that models pre-trained as such can learn rich representations of both modalities, improving their ability to understand how images and text relate to each other. Our experiments show that unimodal pre-training outperforms state-of-the-art CLIP-based models by 6.5% (52.3% $\rightarrow$ 58.8%) on PASCAL-5$^i$ and 6.2% (27.2% $\rightarrow$ 33.4%) on COCO-20$^i$ semantic segmentation under zero-shot setting respectively. By learning representations of both modalities, unimodal pre-training offers broader coverage, reduced misalignment errors, and the ability to capture more complex features and patterns in the real-world data resulting in better performance especially for zero-shot vision-language tasks.
A Semi-supervised Object Detection Algorithm for Underwater Imagery
Jun 07, 2023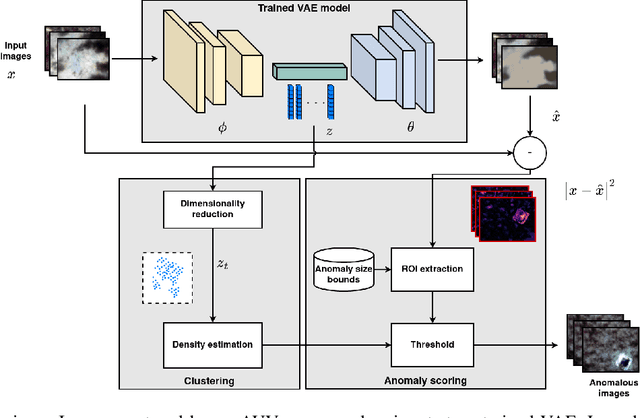

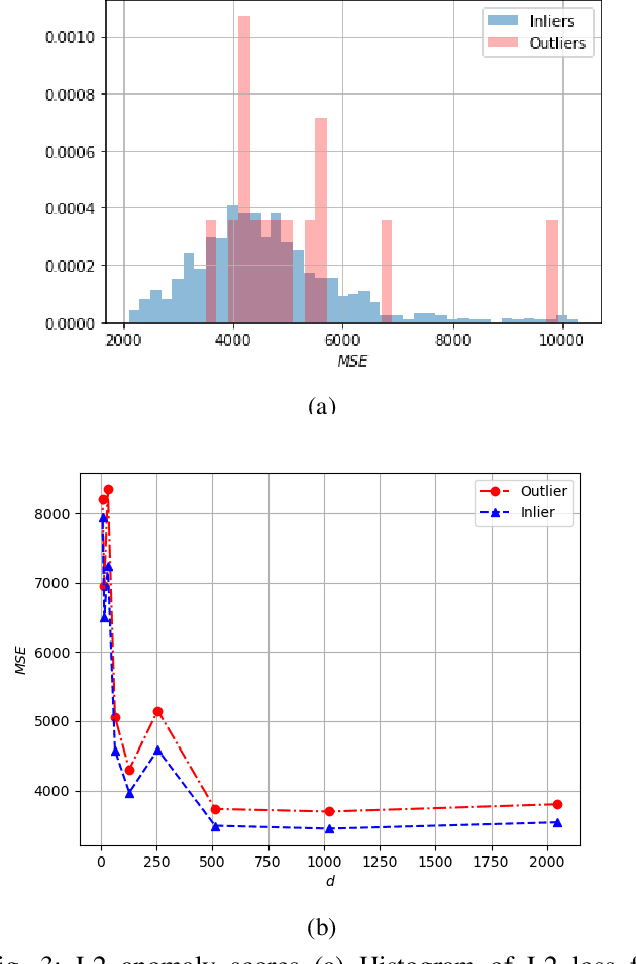
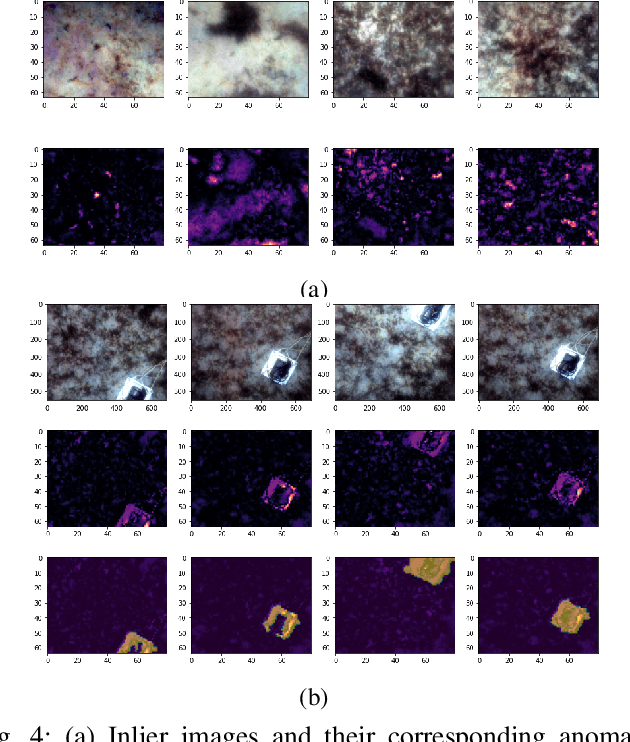
Detection of artificial objects from underwater imagery gathered by Autonomous Underwater Vehicles (AUVs) is a key requirement for many subsea applications. Real-world AUV image datasets tend to be very large and unlabelled. Furthermore, such datasets are typically imbalanced, containing few instances of objects of interest, particularly when searching for unusual objects in a scene. It is therefore, difficult to fit models capable of reliably detecting these objects. Given these factors, we propose to treat artificial objects as anomalies and detect them through a semi-supervised framework based on Variational Autoencoders (VAEs). We develop a method which clusters image data in a learned low-dimensional latent space and extracts images that are likely to contain anomalous features. We also devise an anomaly score based on extracting poorly reconstructed regions of an image. We demonstrate that by applying both methods on large image datasets, human operators can be shown candidate anomalous samples with a low false positive rate to identify objects of interest. We apply our approach to real seafloor imagery gathered by an AUV and evaluate its sensitivity to the dimensionality of the latent representation used by the VAE. We evaluate the precision-recall tradeoff and demonstrate that by choosing an appropriate latent dimensionality and threshold, we are able to achieve an average precision of 0.64 on unlabelled datasets.
Zero-Shot Contrastive Loss for Text-Guided Diffusion Image Style Transfer
Mar 15, 2023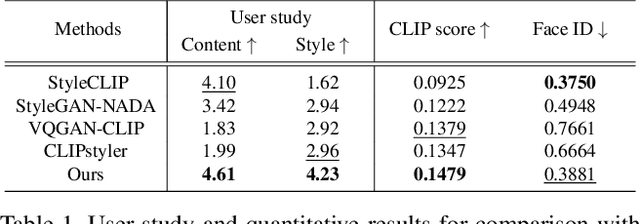
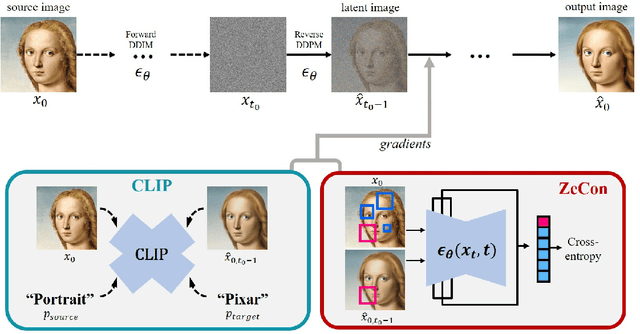
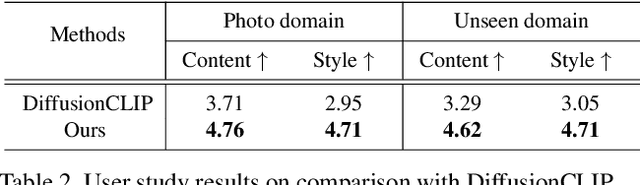
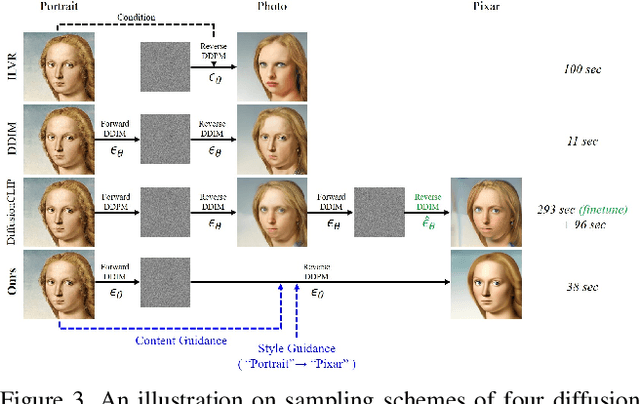
Diffusion models have shown great promise in text-guided image style transfer, but there is a trade-off between style transformation and content preservation due to their stochastic nature. Existing methods require computationally expensive fine-tuning of diffusion models or additional neural network. To address this, here we propose a zero-shot contrastive loss for diffusion models that doesn't require additional fine-tuning or auxiliary networks. By leveraging patch-wise contrastive loss between generated samples and original image embeddings in the pre-trained diffusion model, our method can generate images with the same semantic content as the source image in a zero-shot manner. Our approach outperforms existing methods while preserving content and requiring no additional training, not only for image style transfer but also for image-to-image translation and manipulation. Our experimental results validate the effectiveness of our proposed method.
A Unified Framework to Super-Resolve Face Images of Varied Low Resolutions
Jun 06, 2023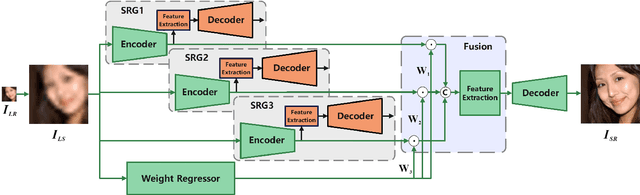
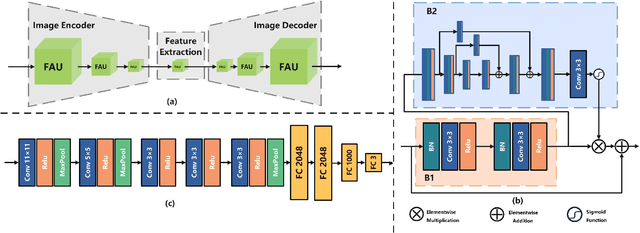
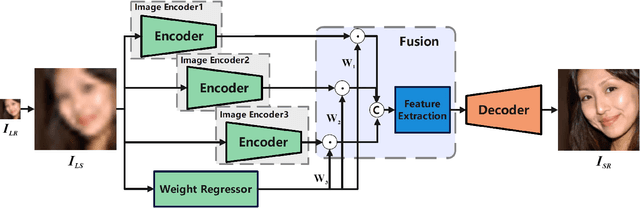

The existing face image super-resolution (FSR) algorithms usually train a specific model for a specific low input resolution for optimal results. By contrast, we explore in this work a unified framework that is trained once and then used to super-resolve input face images of varied low resolutions. For that purpose, we propose a novel neural network architecture that is composed of three anchor auto-encoders, one feature weight regressor and a final image decoder. The three anchor auto-encoders are meant for optimal FSR for three pre-defined low input resolutions, or named anchor resolutions, respectively. An input face image of an arbitrary low resolution is firstly up-scaled to the target resolution by bi-cubic interpolation and then fed to the three auto-encoders in parallel. The three encoded anchor features are then fused with weights determined by the feature weight regressor. At last, the fused feature is sent to the final image decoder to derive the super-resolution result. As shown by experiments, the proposed algorithm achieves robust and state-of-the-art performance over a wide range of low input resolutions by a single framework. Code and models will be made available after the publication of this work.
The Hidden Language of Diffusion Models
Jun 06, 2023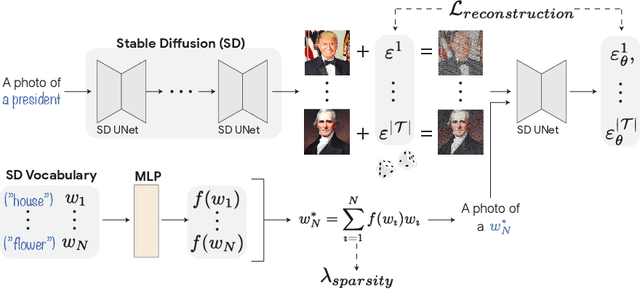
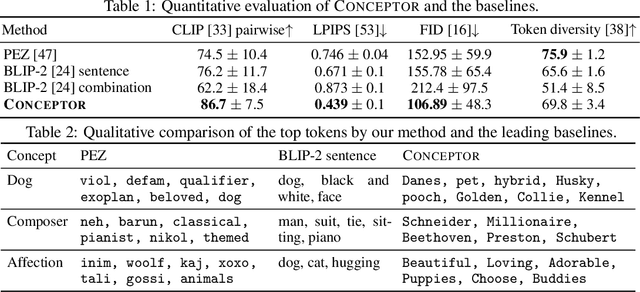
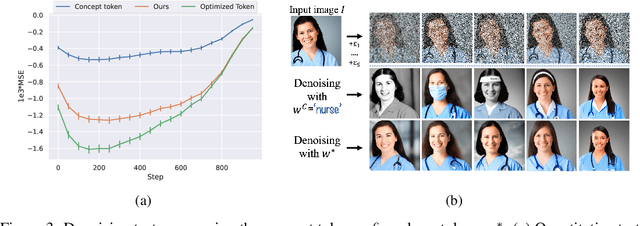

Text-to-image diffusion models have demonstrated an unparalleled ability to generate high-quality, diverse images from a textual concept (e.g., "a doctor", "love"). However, the internal process of mapping text to a rich visual representation remains an enigma. In this work, we tackle the challenge of understanding concept representations in text-to-image models by decomposing an input text prompt into a small set of interpretable elements. This is achieved by learning a pseudo-token that is a sparse weighted combination of tokens from the model's vocabulary, with the objective of reconstructing the images generated for the given concept. Applied over the state-of-the-art Stable Diffusion model, this decomposition reveals non-trivial and surprising structures in the representations of concepts. For example, we find that some concepts such as "a president" or "a composer" are dominated by specific instances (e.g., "Obama", "Biden") and their interpolations. Other concepts, such as "happiness" combine associated terms that can be concrete ("family", "laughter") or abstract ("friendship", "emotion"). In addition to peering into the inner workings of Stable Diffusion, our method also enables applications such as single-image decomposition to tokens, bias detection and mitigation, and semantic image manipulation. Our code will be available at: https://hila-chefer.github.io/Conceptor/