 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DualVAE: Controlling Colours of Generated and Real Images
May 30, 2023



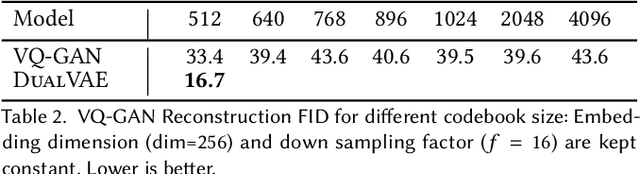
Colour controlled image generation and manipulation are of interest to artists and graphic designers. Vector Quantised Variational AutoEncoders (VQ-VAEs) with autoregressive (AR) prior are able to produce high quality images, but lack an explicit representation mechanism to control colour attributes. We introduce DualVAE, a hybrid representation model that provides such control by learning disentangled representations for colour and geometry. The geometry is represented by an image intensity mapping that identifies structural features. The disentangled representation is obtained by two novel mechanisms: (i) a dual branch architecture that separates image colour attributes from geometric attributes, and (ii) a new ELBO that trains the combined colour and geometry representations. DualVAE can control the colour of generated images, and recolour existing images by transferring the colour latent representation obtained from an exemplar image. We demonstrate that DualVAE generates images with FID nearly two times better than VQ-GAN on a diverse collection of datasets, including animated faces, logos and artistic landscapes.
Image Reconstruction for Accelerated MR Scan with Faster Fourier Convolutional Neural Networks
Jun 05, 2023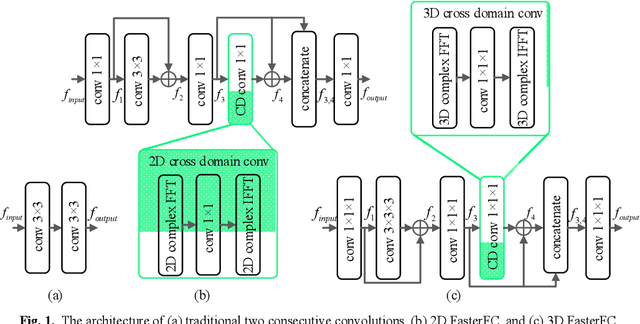
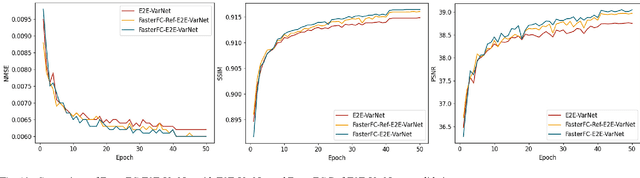
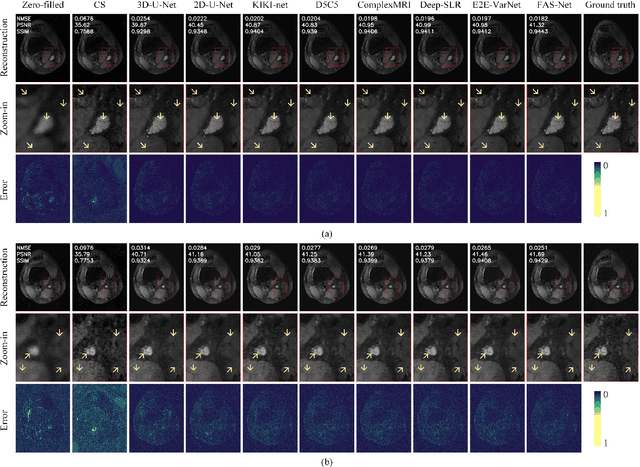
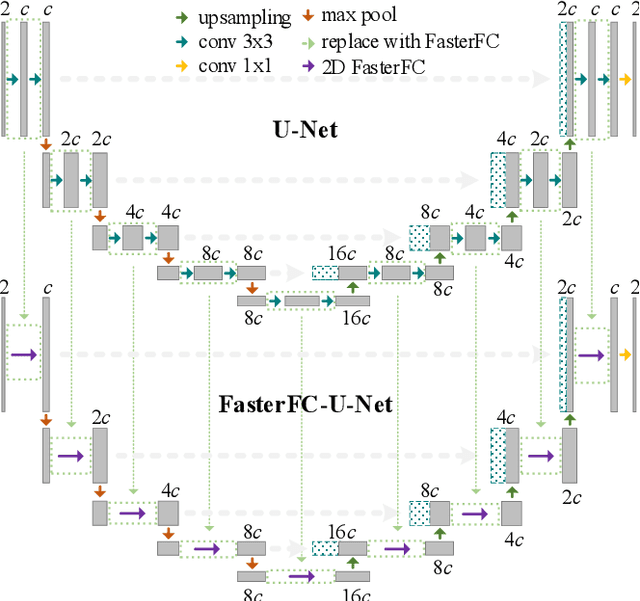
Partial scan is a common approach to accelerate Magnetic Resonance Imaging (MRI) data acquisition in both 2D and 3D settings. However, accurately reconstructing images from partial scan data (i.e., incomplete k-space matrices) remains challenging due to lack of an effectively global receptive field in both spatial and k-space domains. To address this problem, we propose the following: (1) a novel convolutional operator called Faster Fourier Convolution (FasterFC) to replace the two consecutive convolution operations typically used in convolutional neural networks (e.g., U-Net, ResNet). Based on the spectral convolution theorem in Fourier theory, FasterFC employs alternating kernels of size 1 in 3D case) in different domains to extend the dual-domain receptive field to the global and achieves faster calculation speed than traditional Fast Fourier Convolution (FFC). (2) A 2D accelerated MRI method, FasterFC-End-to-End-VarNet, which uses FasterFC to improve the sensitivity maps and reconstruction quality. (3) A multi-stage 3D accelerated MRI method called FasterFC-based Single-to-group Network (FAS-Net) that utilizes a single-to-group algorithm to guide k-space domain reconstruction, followed by FasterFC-based cascaded convolutional neural networks to expand the effective receptive field in the dual-domain. Experimental results on the fastMRI and Stanford MRI Data datasets demonstrate that FasterFC improves the quality of both 2D and 3D reconstruction. Moreover, FAS-Net, as a 3D high-resolution multi-coil (eight) accelerated MRI method, achieves superior reconstruction performance in both qualitative and quantitative results compared with state-of-the-art 2D and 3D methods.
Continuous Cost Aggregation for Dual-Pixel Disparity Extraction
Jun 13, 2023
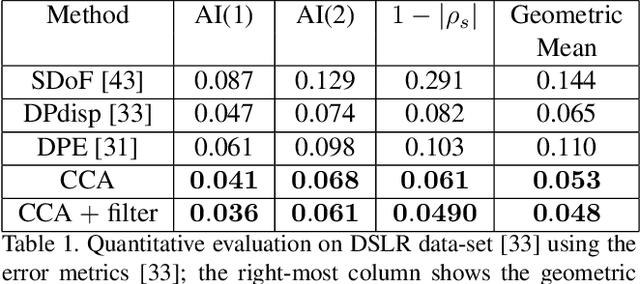
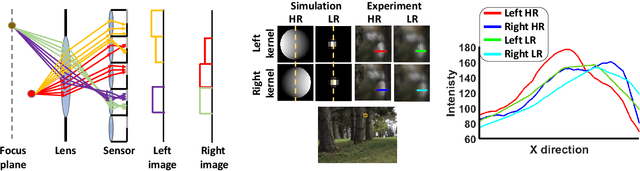

Recent works have shown that depth information can be obtained from Dual-Pixel (DP) sensors. A DP arrangement provides two views in a single shot, thus resembling a stereo image pair with a tiny baseline. However, the different point spread function (PSF) per view, as well as the small disparity range, makes the use of typical stereo matching algorithms problematic. To address the above shortcomings, we propose a Continuous Cost Aggregation (CCA) scheme within a semi-global matching framework that is able to provide accurate continuous disparities from DP images. The proposed algorithm fits parabolas to matching costs and aggregates parabola coefficients along image paths. The aggregation step is performed subject to a quadratic constraint that not only enforces the disparity smoothness but also maintains the quadratic form of the total costs. This gives rise to an inherently efficient disparity propagation scheme with a pixel-wise minimization in closed-form. Furthermore, the continuous form allows for a robust multi-scale aggregation that better compensates for the varying PSF. Experiments on DP data from both DSLR and phone cameras show that the proposed scheme attains state-of-the-art performance in DP disparity estimation.
DiffIR: Efficient Diffusion Model for Image Restoration
Mar 16, 2023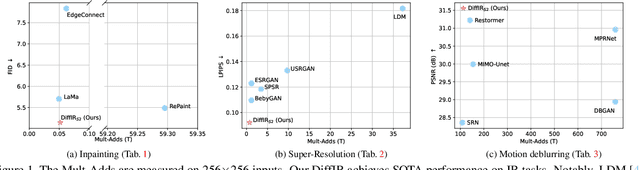
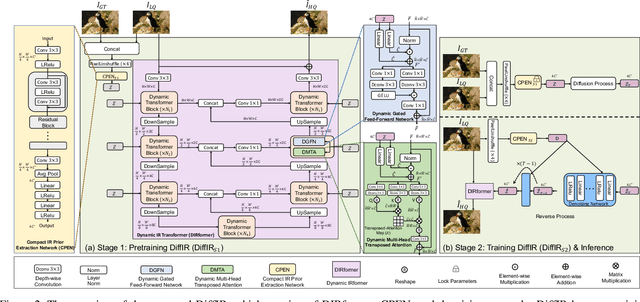
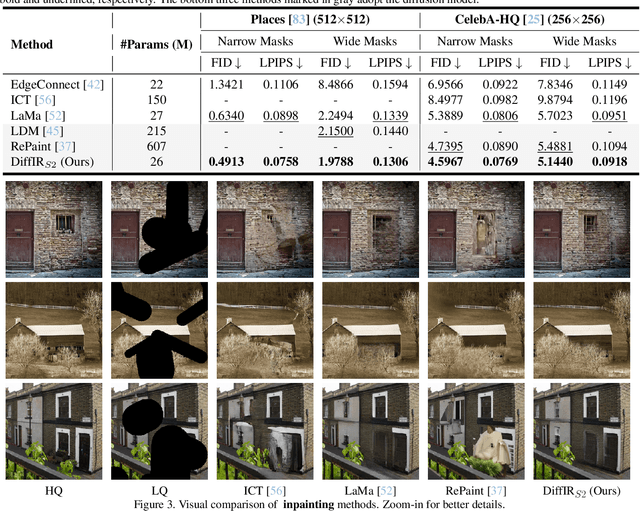
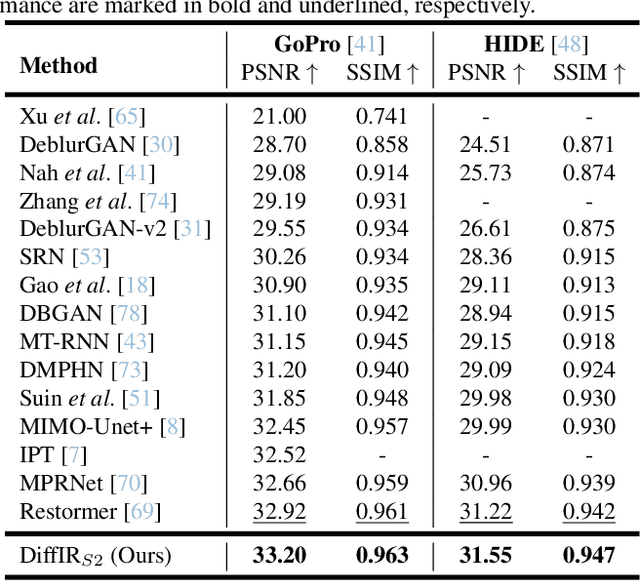
Diffusion model (DM) has achieved SOTA performance by modeling the image synthesis process into a sequential application of a denoising network. However, different from image synthesis generating each pixel from scratch, most pixels of image restoration (IR) are given. Thus, for IR, traditional DMs running massive iterations on a large model to estimate whole images or feature maps is inefficient. To address this issue, we propose an efficient DM for IR (DiffIR), which consists of a compact IR prior extraction network (CPEN), dynamic IR transformer (DIRformer), and denoising network. Specifically, DiffIR has two training stages: pretraining and training DM. In pretraining, we input ground-truth images into CPEN$_{S1}$ to capture a compact IR prior representation (IPR) to guide DIRformer. In the second stage, we train the DM to directly estimate the same IRP as pretrained CPEN$_{S1}$ only using LQ images. We observe that since the IPR is only a compact vector, DiffIR can use fewer iterations than traditional DM to obtain accurate estimations and generate more stable and realistic results. Since the iterations are few, our DiffIR can adopt a joint optimization of CPEN$_{S2}$, DIRformer, and denoising network, which can further reduce the estimation error influence. We conduct extensive experiments on several IR tasks and achieve SOTA performance while consuming less computational costs.
HRS-Bench: Holistic, Reliable and Scalable Benchmark for Text-to-Image Models
Apr 11, 2023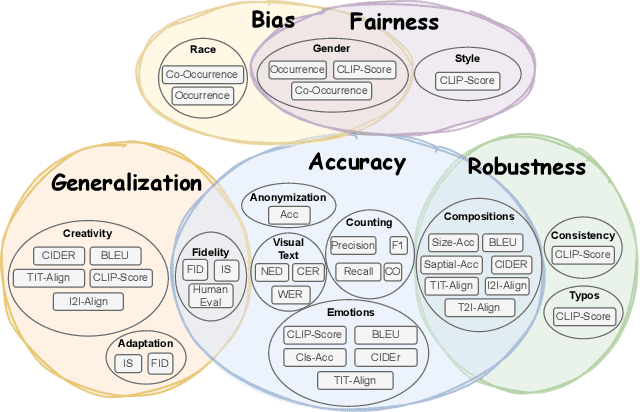

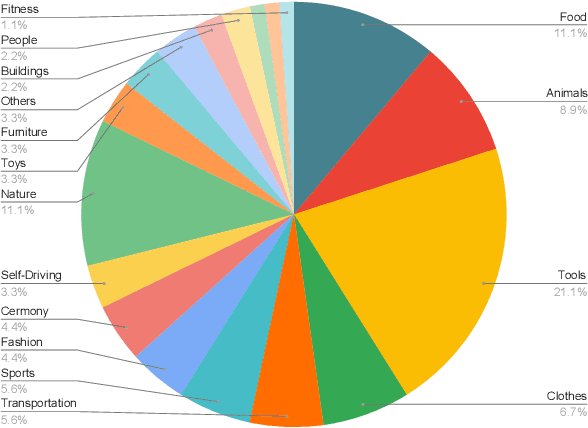

In recent years, Text-to-Image (T2I) models have been extensively studied, especially with the emergence of diffusion models that achieve state-of-the-art results on T2I synthesis tasks. However, existing benchmarks heavily rely on subjective human evaluation, limiting their ability to holistically assess the model's capabilities. Furthermore, there is a significant gap between efforts in developing new T2I architectures and those in evaluation. To address this, we introduce HRS-Bench, a concrete evaluation benchmark for T2I models that is Holistic, Reliable, and Scalable. Unlike existing bench-marks that focus on limited aspects, HRS-Bench measures 13 skills that can be categorized into five major categories: accuracy, robustness, generalization, fairness, and bias. In addition, HRS-Bench covers 50 scenarios, including fashion, animals, transportation, food, and clothes. We evaluate nine recent large-scale T2I models using metrics that cover a wide range of skills. A human evaluation aligned with 95% of our evaluations on average was conducted to probe the effectiveness of HRS-Bench. Our experiments demonstrate that existing models often struggle to generate images with the desired count of objects, visual text, or grounded emotions. We hope that our benchmark help ease future text-to-image generation research. The code and data are available at https://eslambakr.github.io/hrsbench.github.io
Multi-scale Adaptive Fusion Network for Hyperspectral Image Denoising
Apr 19, 2023

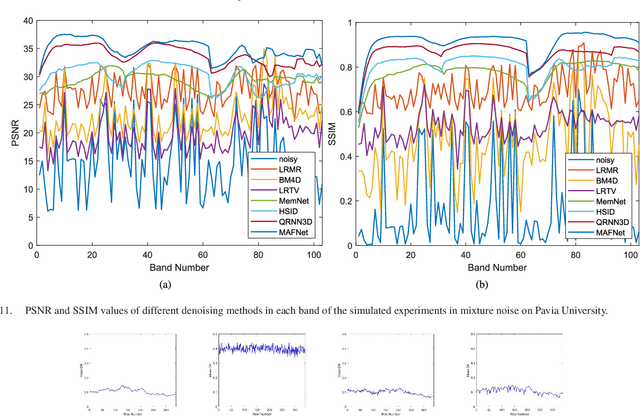
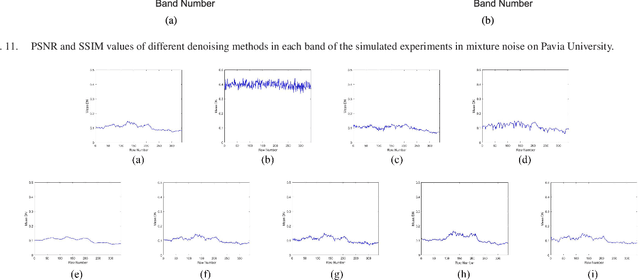
Removing the noise and improving the visual quality of hyperspectral images (HSIs) is challenging in academia and industry. Great efforts have been made to leverage local, global or spectral context information for HSI denoising. However, existing methods still have limitations in feature interaction exploitation among multiple scales and rich spectral structure preservation. In view of this, we propose a novel solution to investigate the HSI denoising using a Multi-scale Adaptive Fusion Network (MAFNet), which can learn the complex nonlinear mapping between clean and noisy HSI. Two key components contribute to improving the hyperspectral image denoising: A progressively multiscale information aggregation network and a co-attention fusion module. Specifically, we first generate a set of multiscale images and feed them into a coarse-fusion network to exploit the contextual texture correlation. Thereafter, a fine fusion network is followed to exchange the information across the parallel multiscale subnetworks. Furthermore, we design a co-attention fusion module to adaptively emphasize informative features from different scales, and thereby enhance the discriminative learning capability for denoising. Extensive experiments on synthetic and real HSI datasets demonstrate that the proposed MAFNet has achieved better denoising performance than other state-of-the-art techniques. Our codes are available at \verb'https://github.com/summitgao/MAFNet'.
Feature Mixing for Writer Retrieval and Identification on Papyri Fragments
Jun 22, 2023This paper proposes a deep-learning-based approach to writer retrieval and identification for papyri, with a focus on identifying fragments associated with a specific writer and those corresponding to the same image. We present a novel neural network architecture that combines a residual backbone with a feature mixing stage to improve retrieval performance, and the final descriptor is derived from a projection layer. The methodology is evaluated on two benchmarks: PapyRow, where we achieve a mAP of 26.6 % and 24.9 % on writer and page retrieval, and HisFragIR20, showing state-of-the-art performance (44.0 % and 29.3 % mAP). Furthermore, our network has an accuracy of 28.7 % for writer identification. Additionally, we conduct experiments on the influence of two binarization techniques on fragments and show that binarizing does not enhance performance. Our code and models are available to the community.
Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
Mar 20, 2023
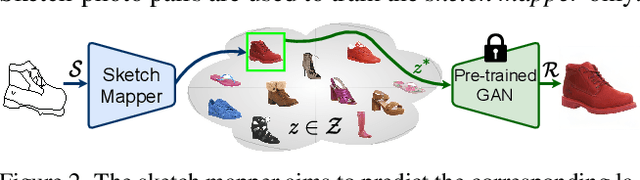
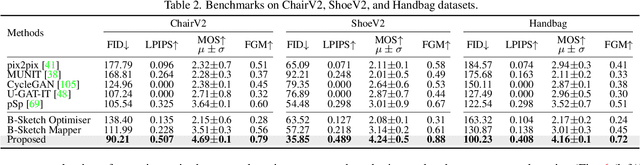
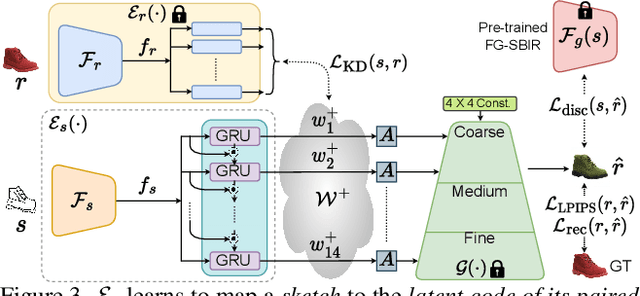
Given an abstract, deformed, ordinary sketch from untrained amateurs like you and me, this paper turns it into a photorealistic image - just like those shown in Fig. 1(a), all non-cherry-picked. We differ significantly from prior art in that we do not dictate an edgemap-like sketch to start with, but aim to work with abstract free-hand human sketches. In doing so, we essentially democratise the sketch-to-photo pipeline, "picturing" a sketch regardless of how good you sketch. Our contribution at the outset is a decoupled encoder-decoder training paradigm, where the decoder is a StyleGAN trained on photos only. This importantly ensures that generated results are always photorealistic. The rest is then all centred around how best to deal with the abstraction gap between sketch and photo. For that, we propose an autoregressive sketch mapper trained on sketch-photo pairs that maps a sketch to the StyleGAN latent space. We further introduce specific designs to tackle the abstract nature of human sketches, including a fine-grained discriminative loss on the back of a trained sketch-photo retrieval model, and a partial-aware sketch augmentation strategy. Finally, we showcase a few downstream tasks our generation model enables, amongst them is showing how fine-grained sketch-based image retrieval, a well-studied problem in the sketch community, can be reduced to an image (generated) to image retrieval task, surpassing state-of-the-arts. We put forward generated results in the supplementary for everyone to scrutinise.
Layer-level activation mechanism
Jun 08, 2023In this work, we propose a novel activation mechanism aimed at establishing layer-level activation (LayerAct) functions. These functions are designed to be more noise-robust compared to traditional element-level activation functions by reducing the layer-level fluctuation of the activation outputs due to shift in inputs. Moreover, the LayerAct functions achieve a zero-like mean activation output without restricting the activation output space. We present an analysis and experiments demonstrating that LayerAct functions exhibit superior noise-robustness compared to element-level activation functions, and empirically show that these functions have a zero-like mean activation. Experimental results on three benchmark image classification tasks show that LayerAct functions excel in handling noisy image datasets, outperforming element-level activation functions, while the performance on clean datasets is also superior in most cases.
Contrastive Learning MRI Reconstruction
Jun 01, 2023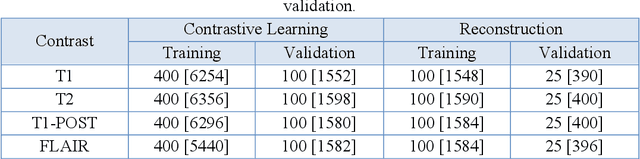
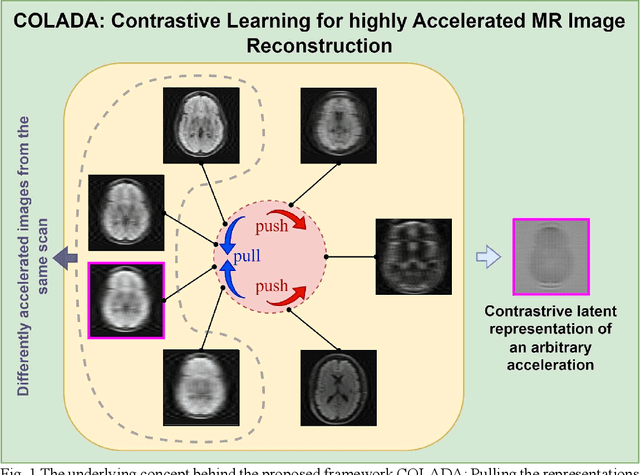
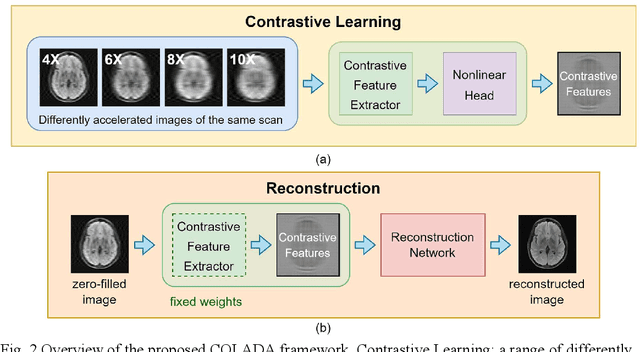
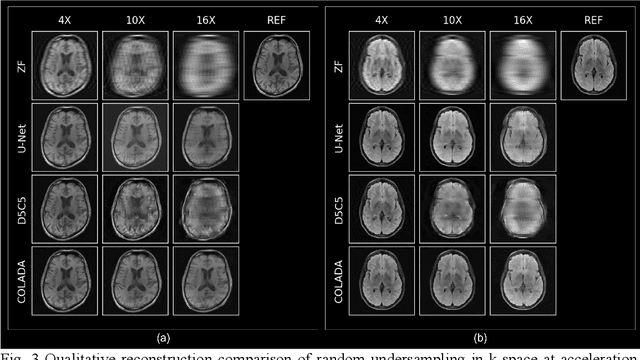
Purpose: We propose a novel contrastive learning latent space representation for MRI datasets with partially acquired scans. We show that this latent space can be utilized for accelerated MR image reconstruction. Theory and Methods: Our novel framework, referred to as COLADA (stands for Contrastive Learning for highly accelerated MR image reconstruction), maximizes the mutual information between differently accelerated images of an MRI scan by using self-supervised contrastive learning. In other words, it attempts to "pull" the latent representations of the same scan together and "push" the latent representations of other scans away. The generated MRI latent space is subsequently utilized for MR image reconstruction and the performance was assessed in comparison to several baseline deep learning reconstruction methods. Furthermore, the quality of the proposed latent space representation was analyzed using Alignment and Uniformity. Results: COLADA comprehensively outperformed other reconstruction methods with robustness to variations in undersampling patterns, pathological abnormalities, and noise in k-space during inference. COLADA proved the high quality of reconstruction on unseen data with minimal fine-tuning. The analysis of representation quality suggests that the contrastive features produced by COLADA are optimally distributed in latent space. Conclusion: To the best of our knowledge, this is the first attempt to utilize contrastive learning on differently accelerated images for MR image reconstruction. The proposed latent space representation has practical usage due to a large number of existing partially sampled datasets. This implies the possibility of exploring self-supervised contrastive learning further to enhance the latent space of MRI for image reconstruction.