 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Conditional Image-to-Video Generation with Latent Flow Diffusion Models
Mar 24, 2023
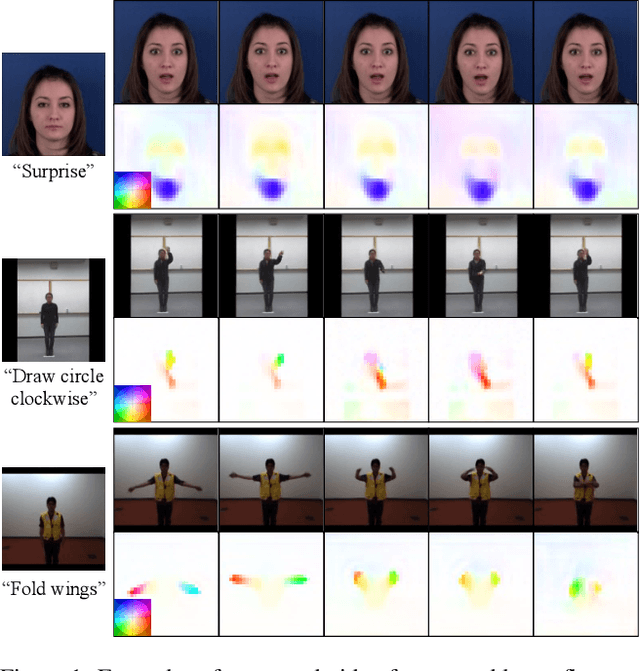

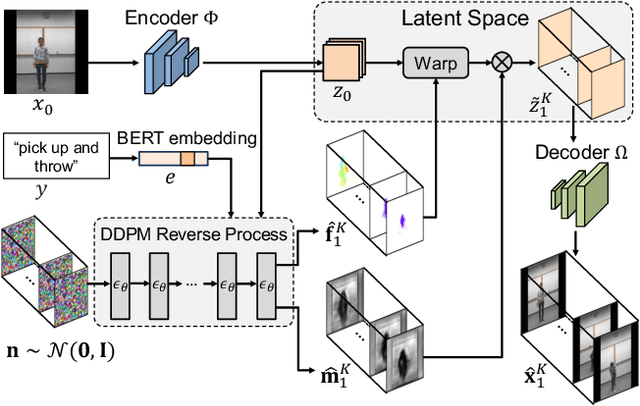
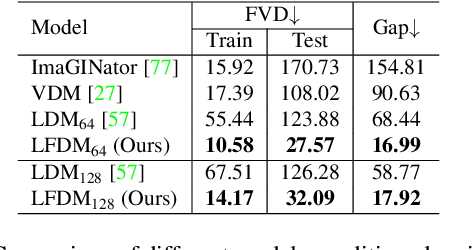
Conditional image-to-video (cI2V) generation aims to synthesize a new plausible video starting from an image (e.g., a person's face) and a condition (e.g., an action class label like smile). The key challenge of the cI2V task lies in the simultaneous generation of realistic spatial appearance and temporal dynamics corresponding to the given image and condition. In this paper, we propose an approach for cI2V using novel latent flow diffusion models (LFDM) that synthesize an optical flow sequence in the latent space based on the given condition to warp the given image. Compared to previous direct-synthesis-based works, our proposed LFDM can better synthesize spatial details and temporal motion by fully utilizing the spatial content of the given image and warping it in the latent space according to the generated temporally-coherent flow. The training of LFDM consists of two separate stages: (1) an unsupervised learning stage to train a latent flow auto-encoder for spatial content generation, including a flow predictor to estimate latent flow between pairs of video frames, and (2) a conditional learning stage to train a 3D-UNet-based diffusion model (DM) for temporal latent flow generation. Unlike previous DMs operating in pixel space or latent feature space that couples spatial and temporal information, the DM in our LFDM only needs to learn a low-dimensional latent flow space for motion generation, thus being more computationally efficient. We conduct comprehensive experiments on multiple datasets, where LFDM consistently outperforms prior arts. Furthermore, we show that LFDM can be easily adapted to new domains by simply finetuning the image decoder. Our code is available at https://github.com/nihaomiao/CVPR23_LFDM.
Inversion by Direct Iteration: An Alternative to Denoising Diffusion for Image Restoration
Mar 20, 2023
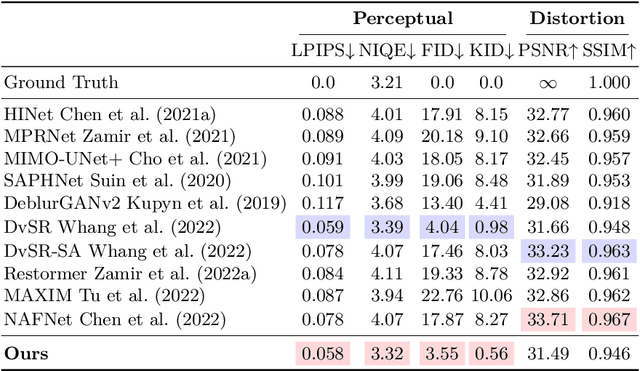


Inversion by Direct Iteration (InDI) is a new formulation for supervised image restoration that avoids the so-called ``regression to the mean'' effect and produces more realistic and detailed images than existing regression-based methods. It does this by gradually improving image quality in small steps, similar to generative denoising diffusion models. Image restoration is an ill-posed problem where multiple high-quality images are plausible reconstructions of a given low-quality input. Therefore, the outcome of a single step regression model is typically an aggregate of all possible explanations, therefore lacking details and realism. % The main advantage of InDI is that it does not try to predict the clean target image in a single step but instead gradually improves the image in small steps, resulting in better perceptual quality. While generative denoising diffusion models also work in small steps, our formulation is distinct in that it does not require knowledge of any analytic form of the degradation process. Instead, we directly learn an iterative restoration process from low-quality and high-quality paired examples. InDI can be applied to virtually any image degradation, given paired training data. In conditional denoising diffusion image restoration the denoising network generates the restored image by repeatedly denoising an initial image of pure noise, conditioned on the degraded input. Contrary to conditional denoising formulations, InDI directly proceeds by iteratively restoring the input low-quality image, producing high-quality results on a variety of image restoration tasks, including motion and out-of-focus deblurring, super-resolution, compression artifact removal, and denoising.
Diffusion Models for Zero-Shot Open-Vocabulary Segmentation
Jun 15, 2023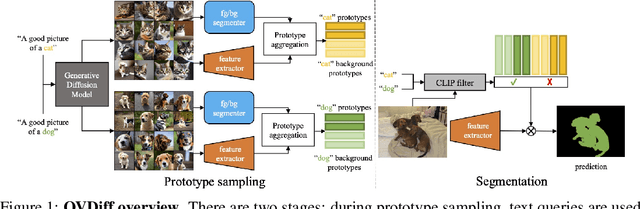
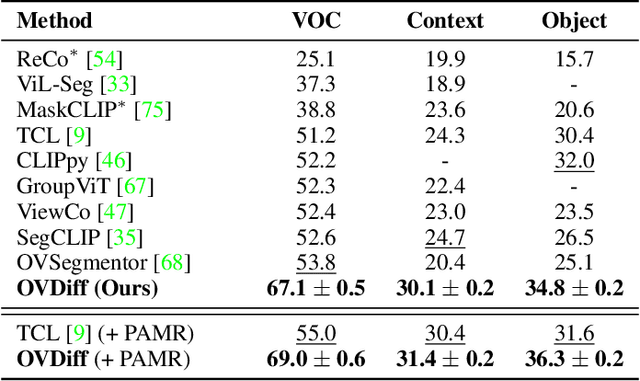


The variety of objects in the real world is nearly unlimited and is thus impossible to capture using models trained on a fixed set of categories. As a result, in recent years, open-vocabulary methods have attracted the interest of the community. This paper proposes a new method for zero-shot open-vocabulary segmentation. Prior work largely relies on contrastive training using image-text pairs, leveraging grouping mechanisms to learn image features that are both aligned with language and well-localised. This however can introduce ambiguity as the visual appearance of images with similar captions often varies. Instead, we leverage the generative properties of large-scale text-to-image diffusion models to sample a set of support images for a given textual category. This provides a distribution of appearances for a given text circumventing the ambiguity problem. We further propose a mechanism that considers the contextual background of the sampled images to better localise objects and segment the background directly. We show that our method can be used to ground several existing pre-trained self-supervised feature extractors in natural language and provide explainable predictions by mapping back to regions in the support set. Our proposal is training-free, relying on pre-trained components only, yet, shows strong performance on a range of open-vocabulary segmentation benchmarks, obtaining a lead of more than 10% on the Pascal VOC benchmark.
DreamSparse: Escaping from Plato's Cave with 2D Frozen Diffusion Model Given Sparse Views
Jun 16, 2023
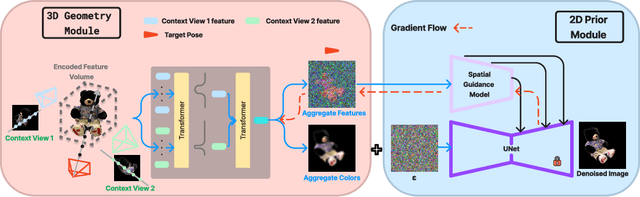


Synthesizing novel view images from a few views is a challenging but practical problem. Existing methods often struggle with producing high-quality results or necessitate per-object optimization in such few-view settings due to the insufficient information provided. In this work, we explore leveraging the strong 2D priors in pre-trained diffusion models for synthesizing novel view images. 2D diffusion models, nevertheless, lack 3D awareness, leading to distorted image synthesis and compromising the identity. To address these problems, we propose DreamSparse, a framework that enables the frozen pre-trained diffusion model to generate geometry and identity-consistent novel view image. Specifically, DreamSparse incorporates a geometry module designed to capture 3D features from sparse views as a 3D prior. Subsequently, a spatial guidance model is introduced to convert these 3D feature maps into spatial information for the generative process. This information is then used to guide the pre-trained diffusion model, enabling it to generate geometrically consistent images without tuning it. Leveraging the strong image priors in the pre-trained diffusion models, DreamSparse is capable of synthesizing high-quality novel views for both object and scene-level images and generalising to open-set images. Experimental results demonstrate that our framework can effectively synthesize novel view images from sparse views and outperforms baselines in both trained and open-set category images. More results can be found on our project page: https://sites.google.com/view/dreamsparse-webpage.
Boundary-aware Backward-Compatible Representation via Adversarial Learning in Image Retrieval
May 04, 2023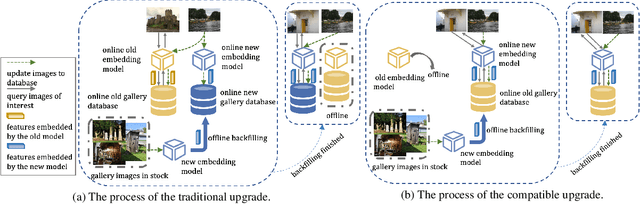
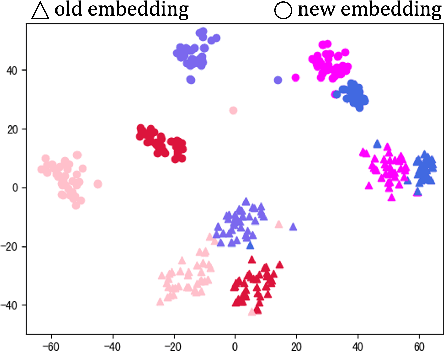
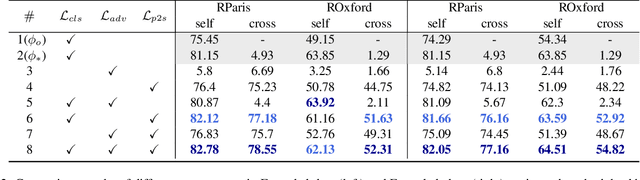
Image retrieval plays an important role in the Internet world. Usually, the core parts of mainstream visual retrieval systems include an online service of the embedding model and a large-scale vector database. For traditional model upgrades, the old model will not be replaced by the new one until the embeddings of all the images in the database are re-computed by the new model, which takes days or weeks for a large amount of data. Recently, backward-compatible training (BCT) enables the new model to be immediately deployed online by making the new embeddings directly comparable to the old ones. For BCT, improving the compatibility of two models with less negative impact on retrieval performance is the key challenge. In this paper, we introduce AdvBCT, an Adversarial Backward-Compatible Training method with an elastic boundary constraint that takes both compatibility and discrimination into consideration. We first employ adversarial learning to minimize the distribution disparity between embeddings of the new model and the old model. Meanwhile, we add an elastic boundary constraint during training to improve compatibility and discrimination efficiently. Extensive experiments on GLDv2, Revisited Oxford (ROxford), and Revisited Paris (RParis) demonstrate that our method outperforms other BCT methods on both compatibility and discrimination. The implementation of AdvBCT will be publicly available at https://github.com/Ashespt/AdvBCT.
Semantic Embedded Deep Neural Network: A Generic Approach to Boost Multi-Label Image Classification Performance
May 09, 2023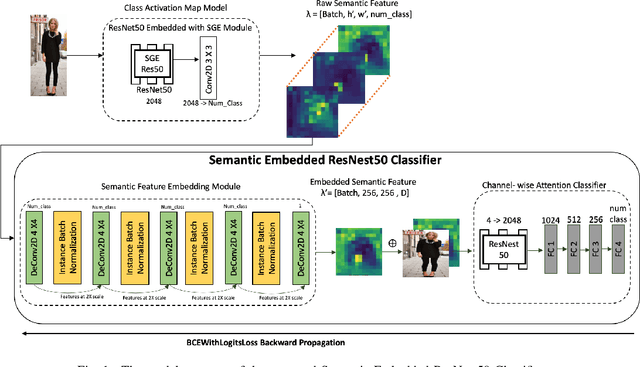
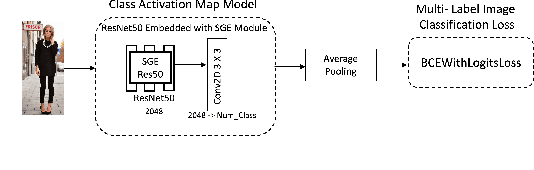

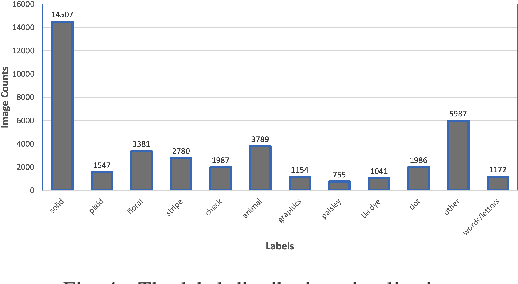
Fine-grained multi-label classification models have broad applications in Amazon production features, such as visual based label predictions ranging from fashion attribute detection to brand recognition. One challenge to achieve satisfactory performance for those classification tasks in real world is the wild visual background signal that contains irrelevant pixels which confuses model to focus onto the region of interest and make prediction upon the specific region. In this paper, we introduce a generic semantic-embedding deep neural network to apply the spatial awareness semantic feature incorporating a channel-wise attention based model to leverage the localization guidance to boost model performance for multi-label prediction. We observed an Avg.relative improvement of 15.27% in terms of AUC score across all labels compared to the baseline approach. Core experiment and ablation studies involve multi-label fashion attribute classification performed on Instagram fashion apparels' image. We compared the model performances among our approach, baseline approach, and 3 alternative approaches to leverage semantic features. Results show favorable performance for our approach.
Stay on topic with Classifier-Free Guidance
Jun 30, 2023

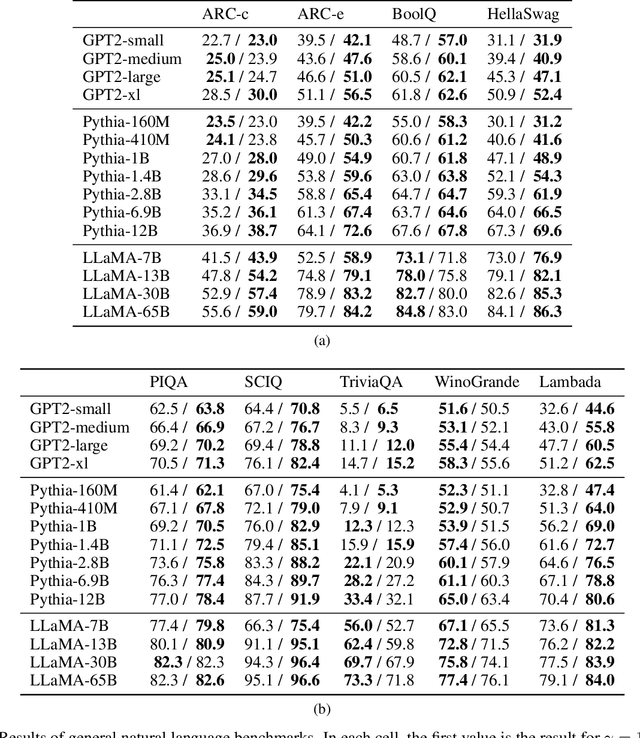
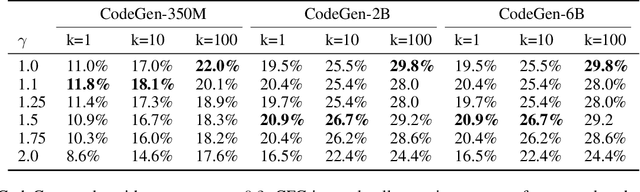
Classifier-Free Guidance (CFG) has recently emerged in text-to-image generation as a lightweight technique to encourage prompt-adherence in generations. In this work, we demonstrate that CFG can be used broadly as an inference-time technique in pure language modeling. We show that CFG (1) improves the performance of Pythia, GPT-2 and LLaMA-family models across an array of tasks: Q\&A, reasoning, code generation, and machine translation, achieving SOTA on LAMBADA with LLaMA-7B over PaLM-540B; (2) brings improvements equivalent to a model with twice the parameter-count; (3) can stack alongside other inference-time methods like Chain-of-Thought and Self-Consistency, yielding further improvements in difficult tasks; (4) can be used to increase the faithfulness and coherence of assistants in challenging form-driven and content-driven prompts: in a human evaluation we show a 75\% preference for GPT4All using CFG over baseline.
CausalVLR: A Toolbox and Benchmark for Visual-Linguistic Causal Reasoning
Jun 30, 2023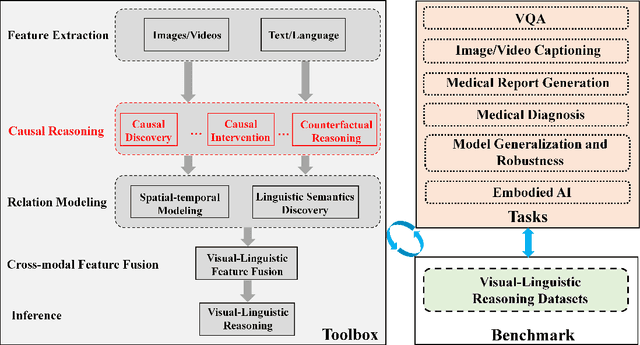
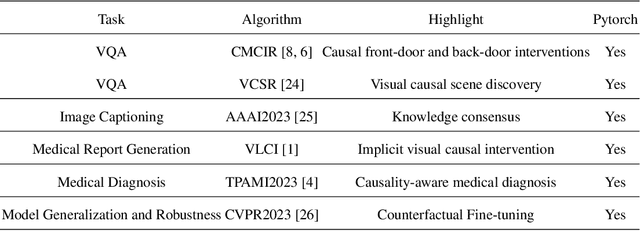
We present CausalVLR (Causal Visual-Linguistic Reasoning), an open-source toolbox containing a rich set of state-of-the-art causal relation discovery and causal inference methods for various visual-linguistic reasoning tasks, such as VQA, image/video captioning, medical report generation, model generalization and robustness, etc. These methods have been included in the toolbox with PyTorch implementations under NVIDIA computing system. It not only includes training and inference codes, but also provides model weights. We believe this toolbox is by far the most complete visual-linguitic causal reasoning toolbox. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to re-implement existing methods and develop their own new causal reasoning methods. Code and models are available at https://github.com/HCPLab-SYSU/Causal-VLReasoning. The project is under active development by HCP-Lab's contributors and we will keep this document updated.
Why does my medical AI look at pictures of birds? Exploring the efficacy of transfer learning across domain boundaries
Jun 30, 2023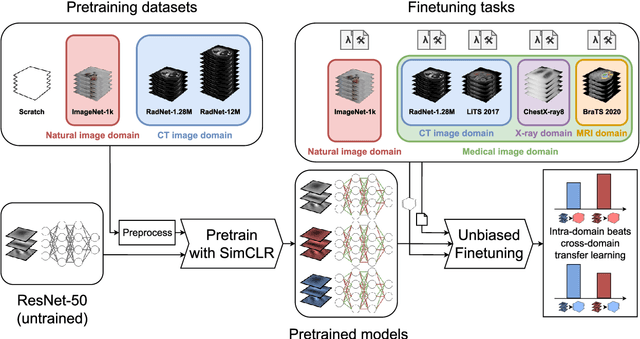
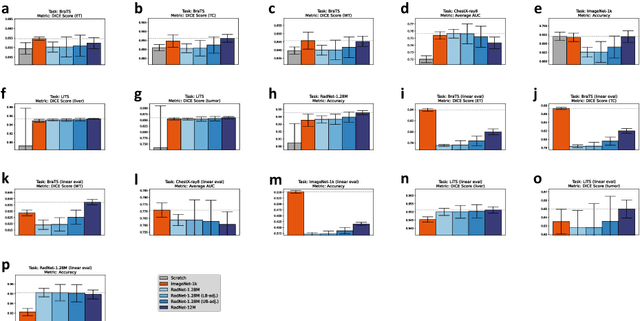
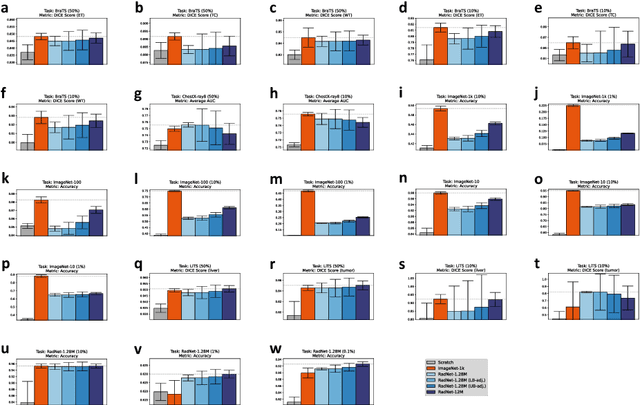
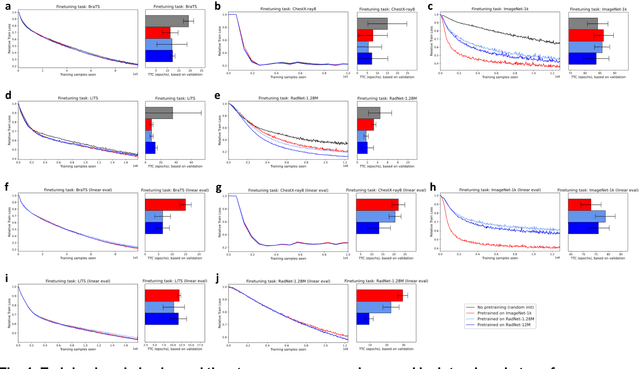
It is an open secret that ImageNet is treated as the panacea of pretraining. Particularly in medical machine learning, models not trained from scratch are often finetuned based on ImageNet-pretrained models. We posit that pretraining on data from the domain of the downstream task should almost always be preferred instead. We leverage RadNet-12M, a dataset containing more than 12 million computed tomography (CT) image slices, to explore the efficacy of self-supervised pretraining on medical and natural images. Our experiments cover intra- and cross-domain transfer scenarios, varying data scales, finetuning vs. linear evaluation, and feature space analysis. We observe that intra-domain transfer compares favorably to cross-domain transfer, achieving comparable or improved performance (0.44% - 2.07% performance increase using RadNet pretraining, depending on the experiment) and demonstrate the existence of a domain boundary-related generalization gap and domain-specific learned features.
Scalable 3D Captioning with Pretrained Models
Jun 16, 2023

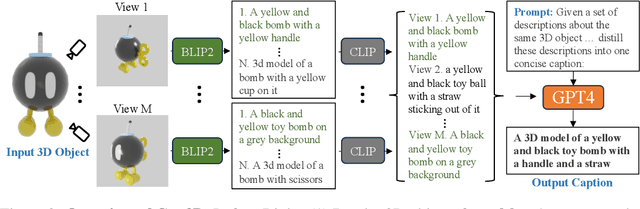
We introduce Cap3D, an automatic approach for generating descriptive text for 3D objects. This approach utilizes pretrained models from image captioning, image-text alignment, and LLM to consolidate captions from multiple views of a 3D asset, completely side-stepping the time-consuming and costly process of manual annotation. We apply Cap3D to the recently introduced large-scale 3D dataset, Objaverse, resulting in 660k 3D-text pairs. Our evaluation, conducted using 41k human annotations from the same dataset, demonstrates that Cap3D surpasses human-authored descriptions in terms of quality, cost, and speed. Through effective prompt engineering, Cap3D rivals human performance in generating geometric descriptions on 17k collected annotations from the ABO dataset. Finally, we finetune Text-to-3D models on Cap3D and human captions, and show Cap3D outperforms; and benchmark the SOTA including Point-E, Shape-E, and DreamFusion.