 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detector-Free Structure from Motion
Jun 27, 2023
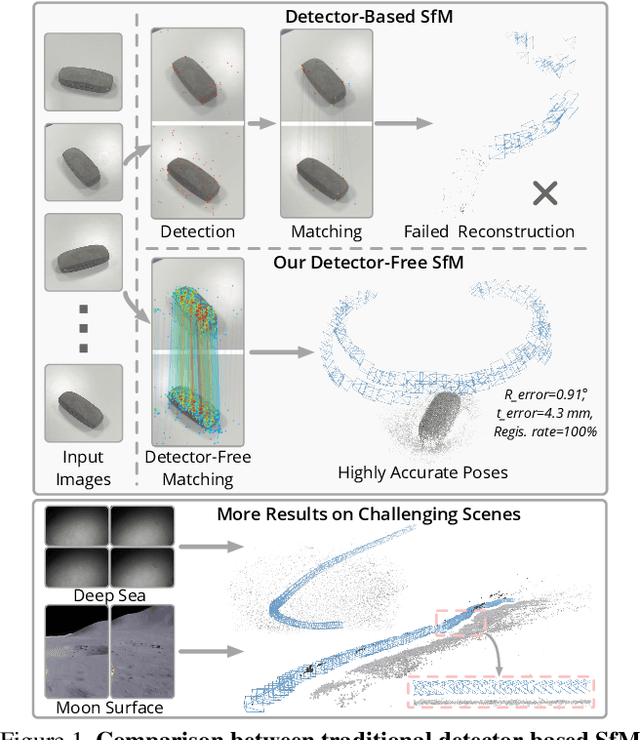
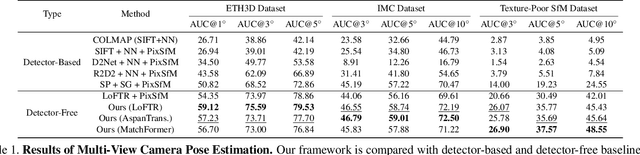
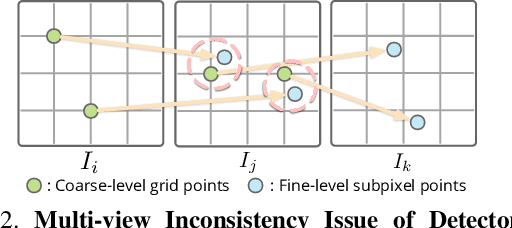

We propose a new structure-from-motion framework to recover accurate camera poses and point clouds from unordered images. Traditional SfM systems typically rely on the successful detection of repeatable keypoints across multiple views as the first step, which is difficult for texture-poor scenes, and poor keypoint detection may break down the whole SfM system. We propose a new detector-free SfM framework to draw benefits from the recent success of detector-free matchers to avoid the early determination of keypoints, while solving the multi-view inconsistency issue of detector-free matchers. Specifically, our framework first reconstructs a coarse SfM model from quantized detector-free matches. Then, it refines the model by a novel iterative refinement pipeline, which iterates between an attention-based multi-view matching module to refine feature tracks and a geometry refinement module to improve the reconstruction accuracy. Experiments demonstrate that the proposed framework outperforms existing detector-based SfM systems on common benchmark datasets. We also collect a texture-poor SfM dataset to demonstrate the capability of our framework to reconstruct texture-poor scenes. Based on this framework, we take $\textit{first place}$ in Image Matching Challenge 2023.
Advancing Adversarial Training by Injecting Booster Signal
Jun 27, 2023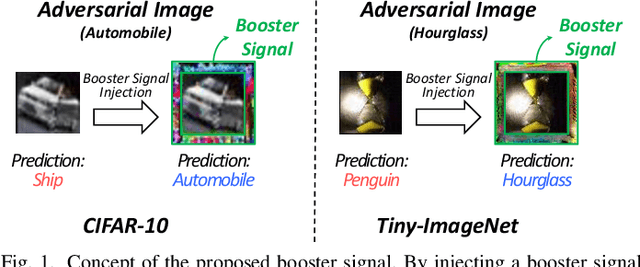
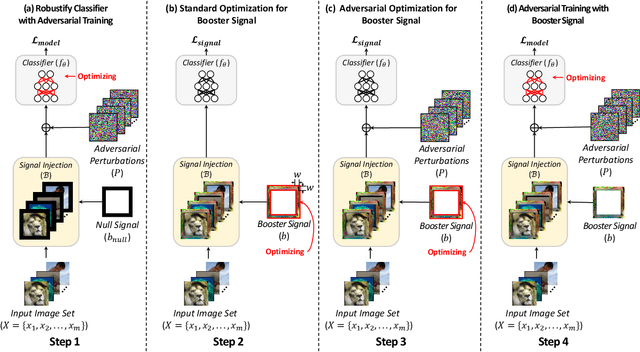
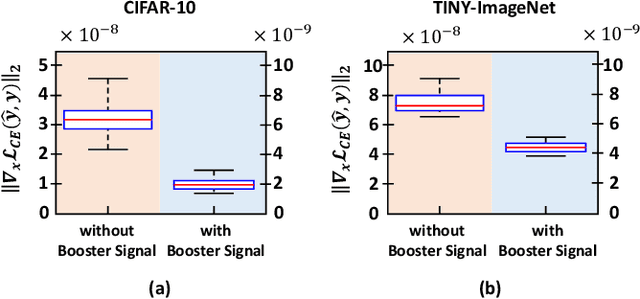
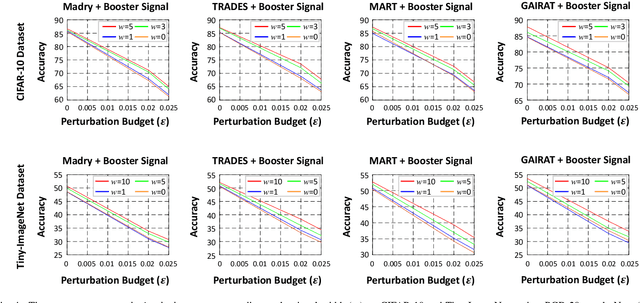
Recent works have demonstrated that deep neural networks (DNNs) are highly vulnerable to adversarial attacks. To defend against adversarial attacks, many defense strategies have been proposed, among which adversarial training has been demonstrated to be the most effective strategy. However, it has been known that adversarial training sometimes hurts natural accuracy. Then, many works focus on optimizing model parameters to handle the problem. Different from the previous approaches, in this paper, we propose a new approach to improve the adversarial robustness by using an external signal rather than model parameters. In the proposed method, a well-optimized universal external signal called a booster signal is injected into the outside of the image which does not overlap with the original content. Then, it boosts both adversarial robustness and natural accuracy. The booster signal is optimized in parallel to model parameters step by step collaboratively. Experimental results show that the booster signal can improve both the natural and robust accuracies over the recent state-of-the-art adversarial training methods. Also, optimizing the booster signal is general and flexible enough to be adopted on any existing adversarial training methods.
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Jun 27, 2023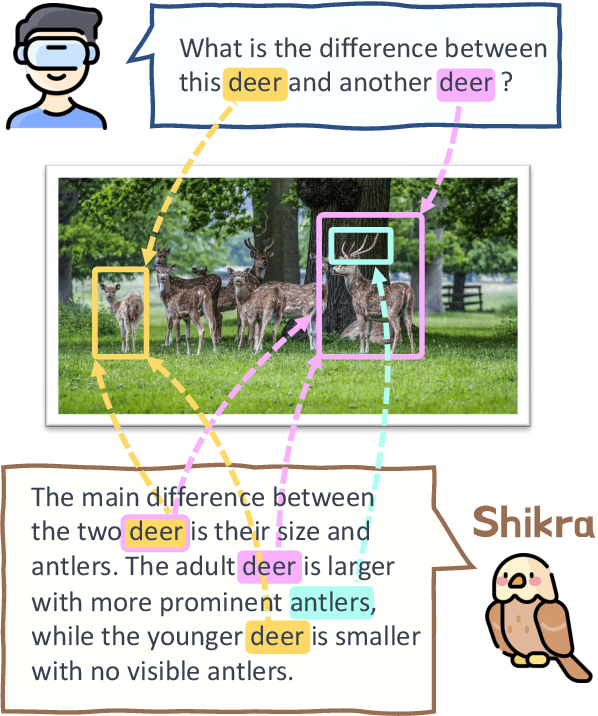
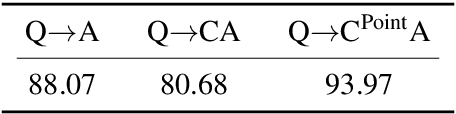

In human conversations, individuals can indicate relevant regions within a scene while addressing others. In turn, the other person can then respond by referring to specific regions if necessary. This natural referential ability in dialogue remains absent in current Multimodal Large Language Models (MLLMs). To fill this gap, this paper proposes an MLLM called Shikra, which can handle spatial coordinate inputs and outputs in natural language. Its architecture consists of a vision encoder, an alignment layer, and a LLM. It is designed to be straightforward and simple, without the need for extra vocabularies, position encoder, pre-/post-detection modules, or external plug-in models. All inputs and outputs are in natural language form. Referential dialogue is a superset of various vision-language (VL) tasks. Shikra can naturally handle location-related tasks like REC and PointQA, as well as conventional VL tasks such as Image Captioning and VQA. Experimental results showcase Shikra's promising performance. Furthermore, it enables numerous exciting applications, like providing mentioned objects' coordinates in chains of thoughts and comparing user-pointed regions similarities. Our code and model are accessed at https://github.com/shikras/shikra.
Depth video data-enabled predictions of longitudinal dairy cow body weight using thresholding and Mask R-CNN algorithms
Jul 03, 2023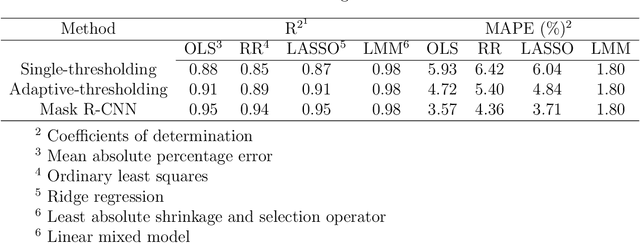

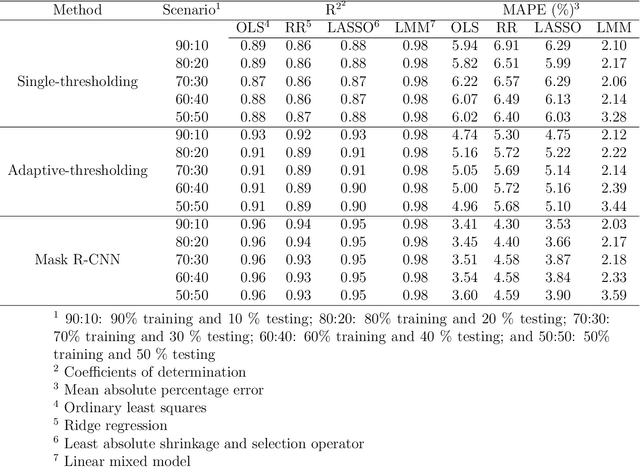
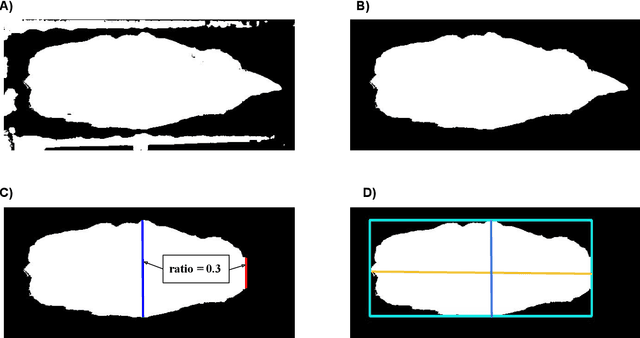
Monitoring cow body weight is crucial to support farm management decisions due to its direct relationship with the growth, nutritional status, and health of dairy cows. Cow body weight is a repeated trait, however, the majority of previous body weight prediction research only used data collected at a single point in time. Furthermore, the utility of deep learning-based segmentation for body weight prediction using videos remains unanswered. Therefore, the objectives of this study were to predict cow body weight from repeatedly measured video data, to compare the performance of the thresholding and Mask R-CNN deep learning approaches, to evaluate the predictive ability of body weight regression models, and to promote open science in the animal science community by releasing the source code for video-based body weight prediction. A total of 40,405 depth images and depth map files were obtained from 10 lactating Holstein cows and 2 non-lactating Jersey cows. Three approaches were investigated to segment the cow's body from the background, including single thresholding, adaptive thresholding, and Mask R-CNN. Four image-derived biometric features, such as dorsal length, abdominal width, height, and volume, were estimated from the segmented images. On average, the Mask-RCNN approach combined with a linear mixed model resulted in the best prediction coefficient of determination and mean absolute percentage error of 0.98 and 2.03%, respectively, in the forecasting cross-validation. The Mask-RCNN approach was also the best in the leave-three-cows-out cross-validation. The prediction coefficients of determination and mean absolute percentage error of the Mask-RCNN coupled with the linear mixed model were 0.90 and 4.70%, respectively. Our results suggest that deep learning-based segmentation improves the prediction performance of cow body weight from longitudinal depth video data.
Squeezing nnU-Nets with Knowledge Distillation for On-Board Cloud Detection
Jun 16, 2023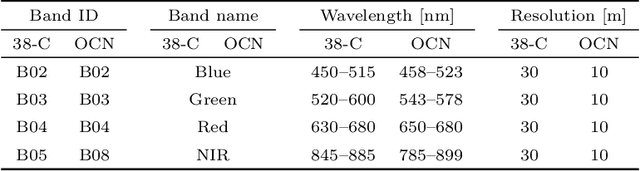
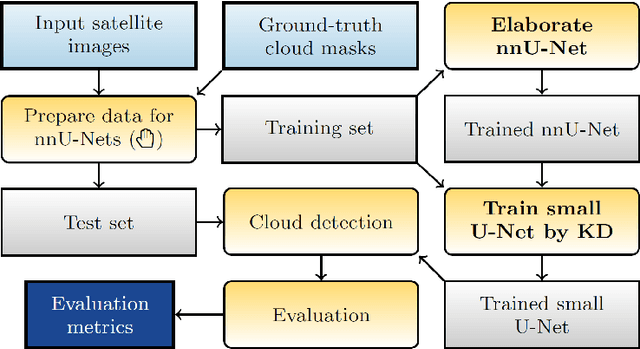
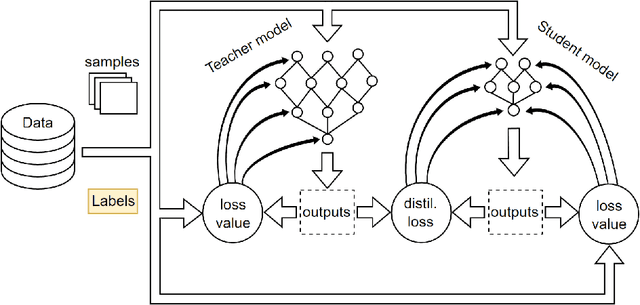
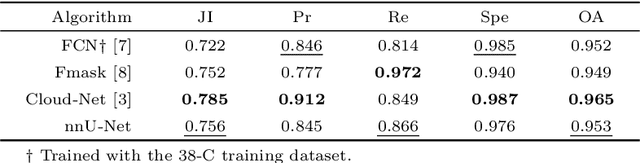
Cloud detection is a pivotal satellite image pre-processing step that can be performed both on the ground and on board a satellite to tag useful images. In the latter case, it can reduce the amount of data to downlink by pruning the cloudy areas, or to make a satellite more autonomous through data-driven acquisition re-scheduling. We approach this task with nnU-Nets, a self-reconfigurable framework able to perform meta-learning of a segmentation network over various datasets. Unfortunately, such models are commonly memory-inefficient due to their (very) large architectures. To benefit from them in on-board processing, we compress nnU-Nets with knowledge distillation into much smaller and compact U-Nets. Our experiments, performed over Sentinel-2 and Landsat-8 images revealed that nnU-Nets deliver state-of-the-art performance without any manual design. Our approach was ranked within the top 7% best solutions (across 847 teams) in the On Cloud N: Cloud Cover Detection Challenge, where we reached the Jaccard index of 0.882 over more than 10k unseen Sentinel-2 images (the winners obtained 0.897, the baseline U-Net with the ResNet-34 backbone: 0.817, and the classic Sentinel-2 image thresholding: 0.652). Finally, we showed that knowledge distillation enables to elaborate dramatically smaller (almost 280x) U-Nets when compared to nnU-Nets while still maintaining their segmentation capabilities.
EBSR: Enhanced Binary Neural Network for Image Super-Resolution
Mar 22, 2023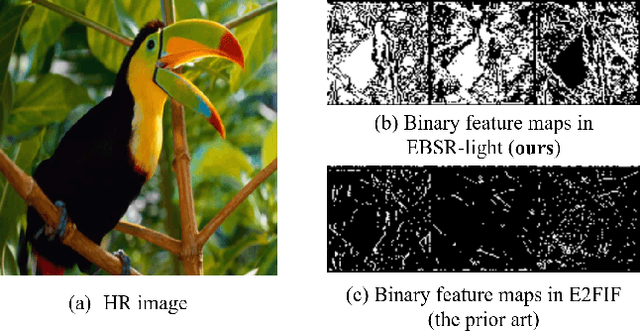

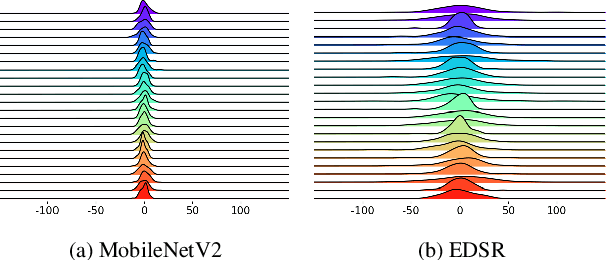
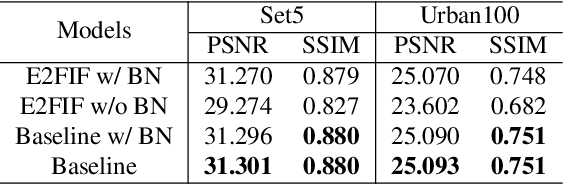
While the performance of deep convolutional neural networks for image super-resolution (SR) has improved significantly, the rapid increase of memory and computation requirements hinders their deployment on resource-constrained devices. Quantized networks, especially binary neural networks (BNN) for SR have been proposed to significantly improve the model inference efficiency but suffer from large performance degradation. We observe the activation distribution of SR networks demonstrates very large pixel-to-pixel, channel-to-channel, and image-to-image variation, which is important for high performance SR but gets lost during binarization. To address the problem, we propose two effective methods, including the spatial re-scaling as well as channel-wise shifting and re-scaling, which augments binary convolutions by retaining more spatial and channel-wise information. Our proposed models, dubbed EBSR, demonstrate superior performance over prior art methods both quantitatively and qualitatively across different datasets and different model sizes. Specifically, for x4 SR on Set5 and Urban100, EBSRlight improves the PSNR by 0.31 dB and 0.28 dB compared to SRResNet-E2FIF, respectively, while EBSR outperforms EDSR-E2FIF by 0.29 dB and 0.32 dB PSNR, respectively.
Marginal Thresholding in Noisy Image Segmentation
Apr 08, 2023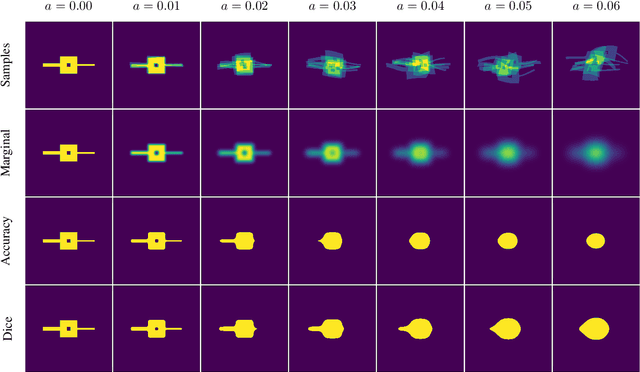
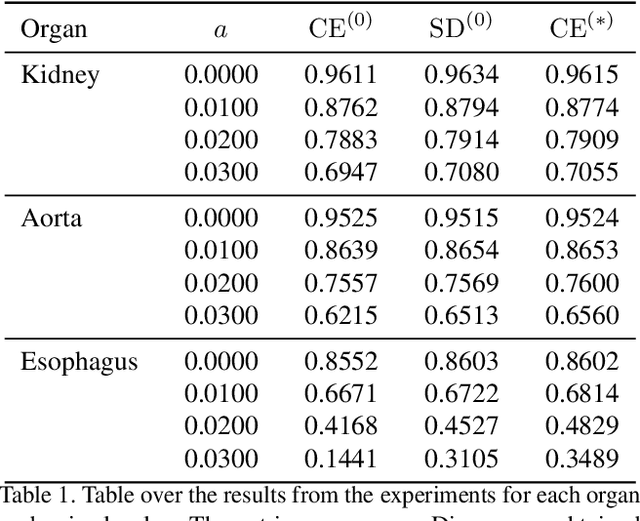
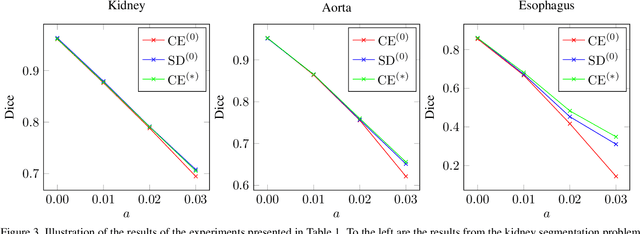
This work presents a study on label noise in medical image segmentation by considering a noise model based on Gaussian field deformations. Such noise is of interest because it yields realistic looking segmentations and because it is unbiased in the sense that the expected deformation is the identity mapping. Efficient methods for sampling and closed form solutions for the marginal probabilities are provided. Moreover, theoretically optimal solutions to the loss functions cross-entropy and soft-Dice are studied and it is shown how they diverge as the level of noise increases. Based on recent work on loss function characterization, it is shown that optimal solutions to soft-Dice can be recovered by thresholding solutions to cross-entropy with a particular a priori unknown threshold that efficiently can be computed. This raises the question whether the decrease in performance seen when using cross-entropy as compared to soft-Dice is caused by using the wrong threshold. The hypothesis is validated in 5-fold studies on three organ segmentation problems from the TotalSegmentor data set, using 4 different strengths of noise. The results show that changing the threshold leads the performance of cross-entropy to go from systematically worse than soft-Dice to similar or better results than soft-Dice.
STM-UNet: An Efficient U-shaped Architecture Based on Swin Transformer and Multi-scale MLP for Medical Image Segmentation
Apr 25, 2023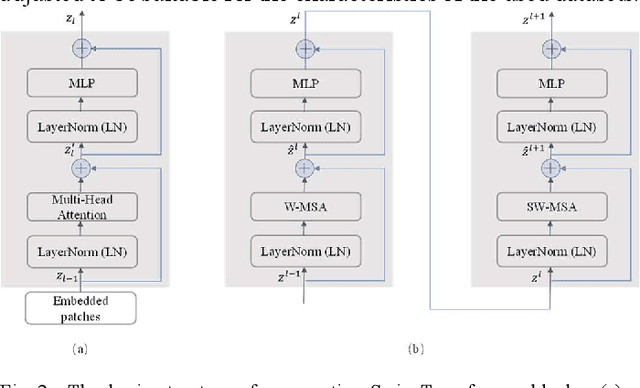
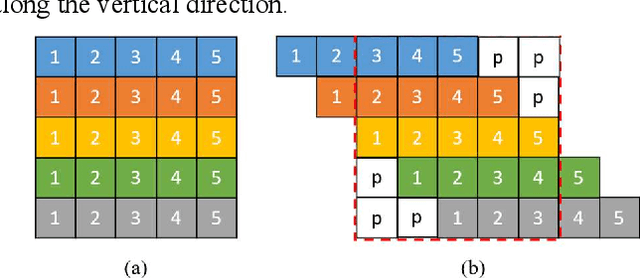
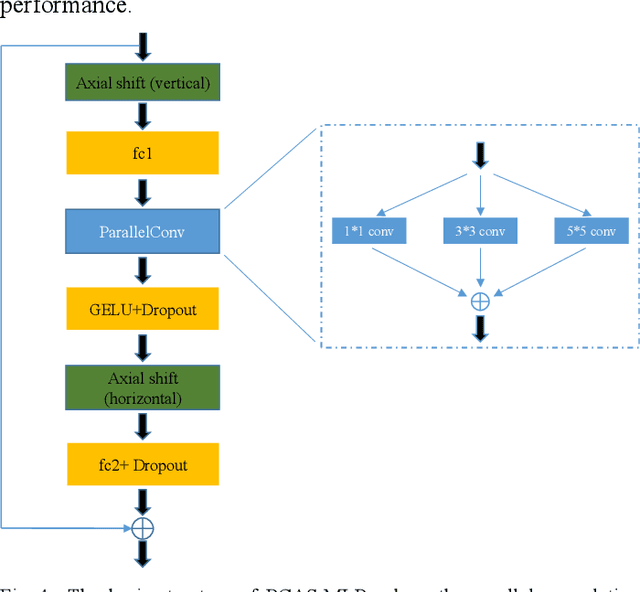

Automated medical image segmentation can assist doctors to diagnose faster and more accurate. Deep learning based models for medical image segmentation have made great progress in recent years. However, the existing models fail to effectively leverage Transformer and MLP for improving U-shaped architecture efficiently. In addition, the multi-scale features of the MLP have not been fully extracted in the bottleneck of U-shaped architecture. In this paper, we propose an efficient U-shaped architecture based on Swin Transformer and multi-scale MLP, namely STM-UNet. Specifically, the Swin Transformer block is added to skip connection of STM-UNet in form of residual connection, which can enhance the modeling ability of global features and long-range dependency. Meanwhile, a novel PCAS-MLP with parallel convolution module is designed and placed into the bottleneck of our architecture to contribute to the improvement of segmentation performance. The experimental results on ISIC 2016 and ISIC 2018 demonstrate the effectiveness of our proposed method. Our method also outperforms several state-of-the-art methods in terms of IoU and Dice. Our method has achieved a better trade-off between high segmentation accuracy and low model complexity.
Neglected Free Lunch -- Learning Image Classifiers Using Annotation Byproducts
Mar 30, 2023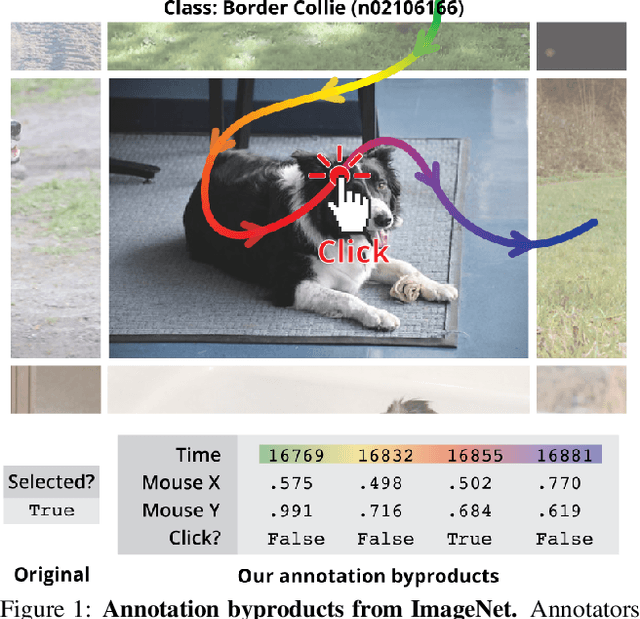
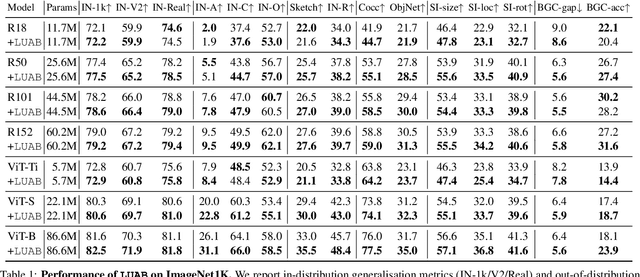
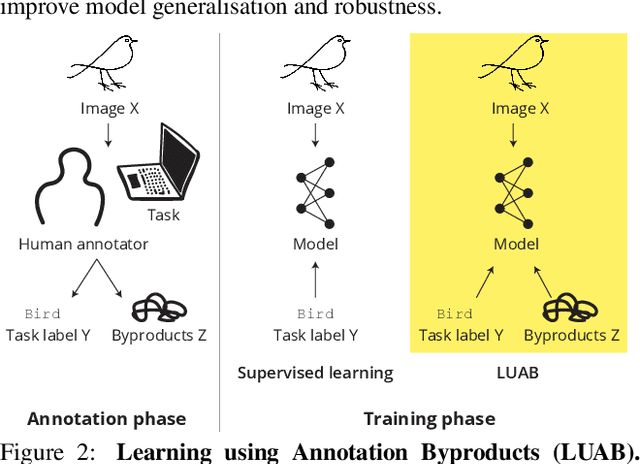
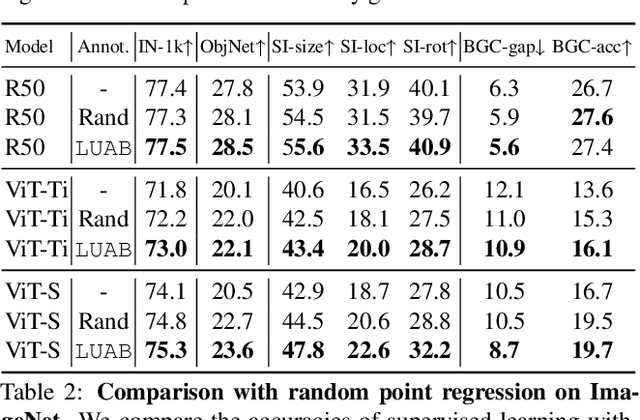
Supervised learning of image classifiers distills human knowledge into a parametric model through pairs of images and corresponding labels (X,Y). We argue that this simple and widely used representation of human knowledge neglects rich auxiliary information from the annotation procedure, such as the time-series of mouse traces and clicks left after image selection. Our insight is that such annotation byproducts Z provide approximate human attention that weakly guides the model to focus on the foreground cues, reducing spurious correlations and discouraging shortcut learning. To verify this, we create ImageNet-AB and COCO-AB. They are ImageNet and COCO training sets enriched with sample-wise annotation byproducts, collected by replicating the respective original annotation tasks. We refer to the new paradigm of training models with annotation byproducts as learning using annotation byproducts (LUAB). We show that a simple multitask loss for regressing Z together with Y already improves the generalisability and robustness of the learned models. Compared to the original supervised learning, LUAB does not require extra annotation costs. ImageNet-AB and COCO-AB are at https://github.com/naver-ai/NeglectedFreeLunch.
LPFormer: LiDAR Pose Estimation Transformer with Multi-Task Network
Jun 21, 2023

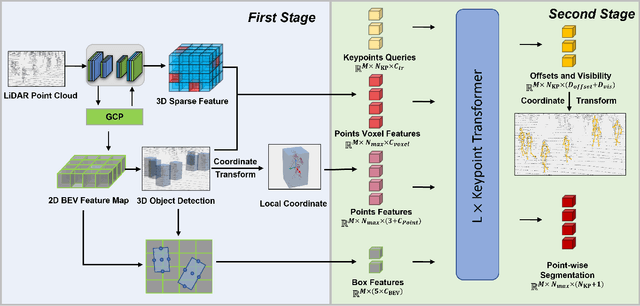
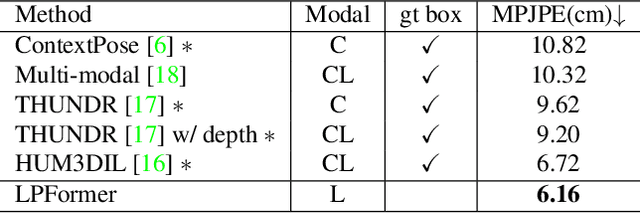
In this technical report, we present the 1st place solution for the 2023 Waymo Open Dataset Pose Estimation challenge. Due to the difficulty of acquiring large-scale 3D human keypoint annotation, previous methods have commonly relied on 2D image features and 2D sequential annotations for 3D human pose estimation. In contrast, our proposed method, named LPFormer, uses only LiDAR as its input along with its corresponding 3D annotations. LPFormer consists of two stages: the first stage detects the human bounding box and extracts multi-level feature representations, while the second stage employs a transformer-based network to regress the human keypoints using these features. Experimental results on the Waymo Open Dataset demonstrate the top performance, and improvements even compared to previous multi-modal solutions.