 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bi-VLGM : Bi-Level Class-Severity-Aware Vision-Language Graph Matching for Text Guided Medical Image Segmentation
May 20, 2023
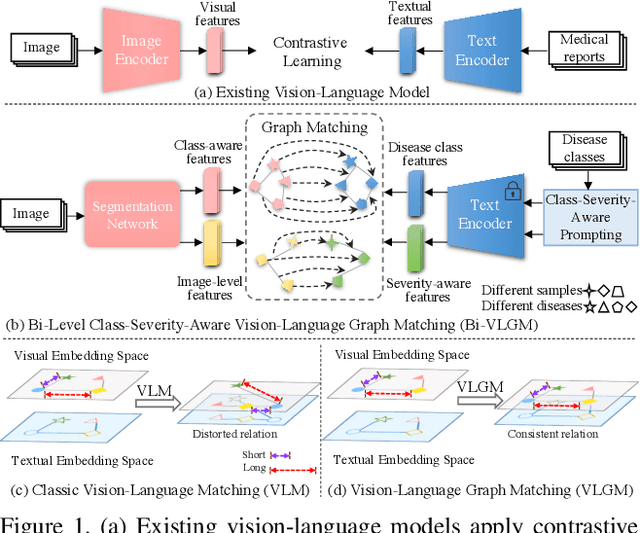

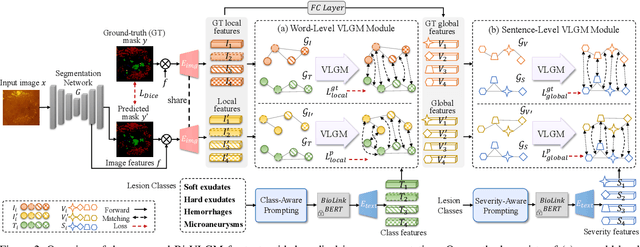
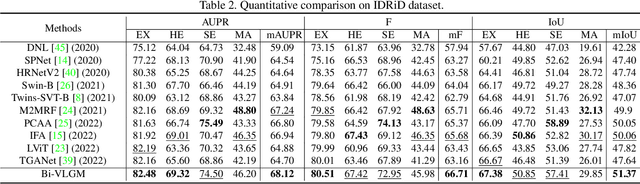
Medical reports with substantial information can be naturally complementary to medical images for computer vision tasks, and the modality gap between vision and language can be solved by vision-language matching (VLM). However, current vision-language models distort the intra-model relation and mainly include class information in prompt learning that is insufficient for segmentation task. In this paper, we introduce a Bi-level class-severity-aware Vision-Language Graph Matching (Bi-VLGM) for text guided medical image segmentation, composed of a word-level VLGM module and a sentence-level VLGM module, to exploit the class-severity-aware relation among visual-textual features. In word-level VLGM, to mitigate the distorted intra-modal relation during VLM, we reformulate VLM as graph matching problem and introduce a vision-language graph matching (VLGM) to exploit the high-order relation among visual-textual features. Then, we perform VLGM between the local features for each class region and class-aware prompts to bridge their gap. In sentence-level VLGM, to provide disease severity information for segmentation task, we introduce a severity-aware prompting to quantify the severity level of retinal lesion, and perform VLGM between the global features and the severity-aware prompts. By exploiting the relation between the local (global) and class (severity) features, the segmentation model can selectively learn the class-aware and severity-aware information to promote performance. Extensive experiments prove the effectiveness of our method and its superiority to existing methods. Source code is to be released.
Novel Categories Discovery from probability matrix perspective
Jul 07, 2023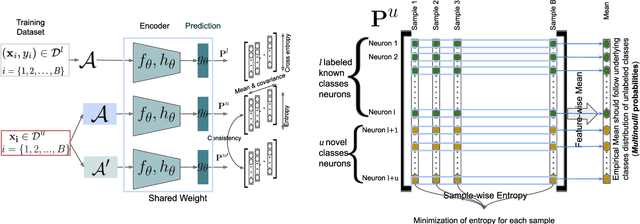
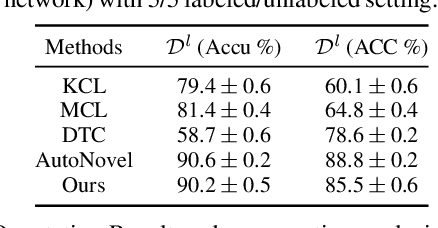
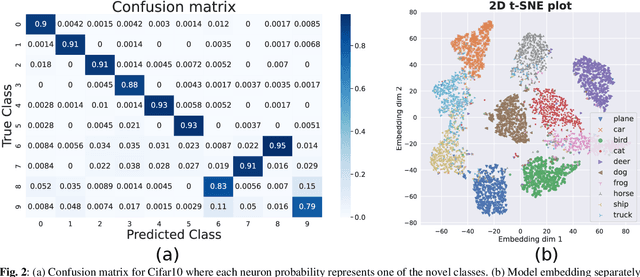
Novel Categories Discovery (NCD) tackles the open-world problem of classifying known and clustering novel categories based on the class semantics using partial class space annotated data. Unlike traditional pseudo-label and retraining, we investigate NCD from the novel data probability matrix perspective. We leverage the connection between NCD novel data sampling with provided novel class Multinoulli (categorical) distribution and hypothesize to implicitly achieve semantic-based novel data clustering by learning their class distribution. We propose novel constraints on first-order (mean) and second-order (covariance) statistics of probability matrix features while applying instance-wise information constraints. In particular, we align the neuron distribution (activation patterns) under a large batch of Monte-Carlo novel data sampling by matching their empirical features mean and covariance with the provided Multinoulli-distribution. Simultaneously, we minimize entropy and enforce prediction consistency for each instance. Our simple approach successfully realizes semantic-based novel data clustering provided the semantic similarity between label-unlabeled classes. We demonstrate the discriminative capacity of our approaches in image and video modalities. Moreover, we perform extensive ablation studies regarding data, networks, and our framework components to provide better insights. Our approach maintains ~94%, ~93%, and ~85%, classification accuracy in labeled data while achieving ~90%, ~84%, and ~72% clustering accuracy for novel categories for Cifar10, UCF101, and MPSC-ARL datasets that matches state-of-the-art approaches without any external clustering.
Intelligent Robotic Sonographer: Mutual Information-based Disentangled Reward Learning from Few Demonstrations
Jul 07, 2023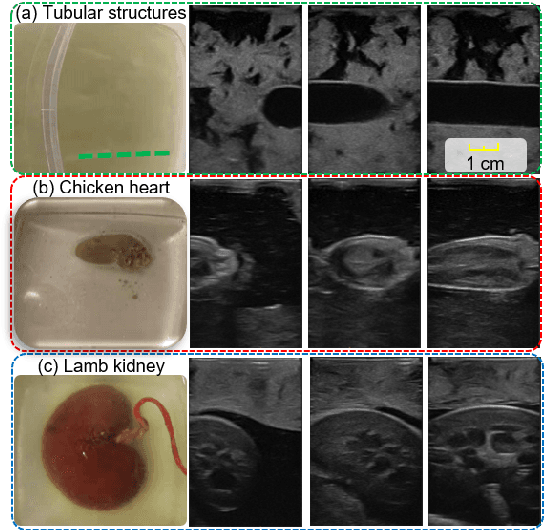
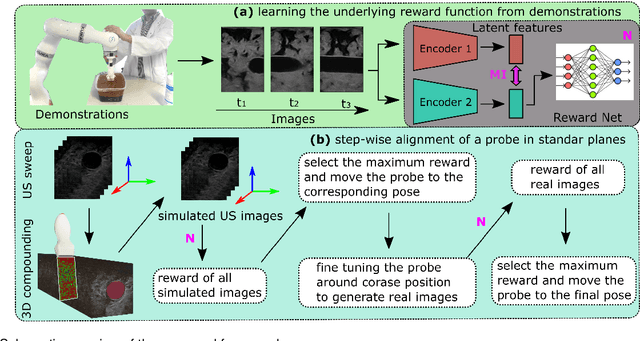
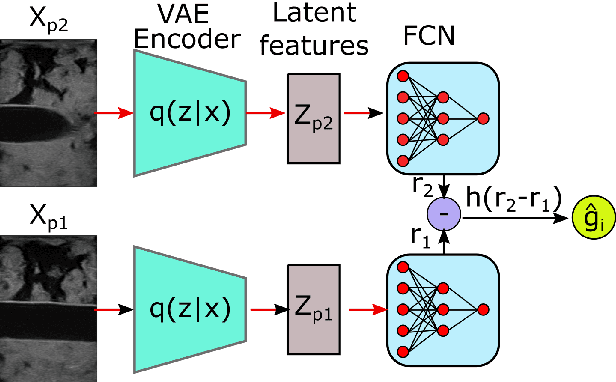
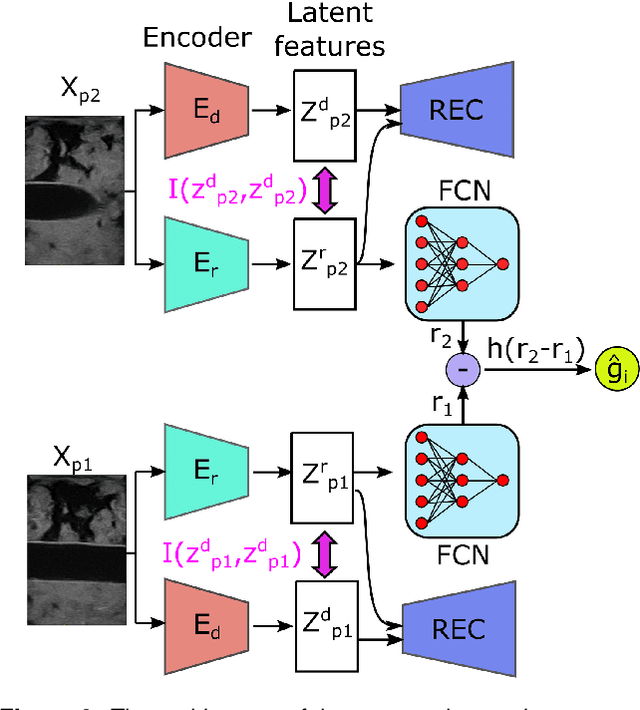
Ultrasound (US) imaging is widely used for biometric measurement and diagnosis of internal organs due to the advantages of being real-time and radiation-free. However, due to high inter-operator variability, resulting images highly depend on operators' experience. In this work, an intelligent robotic sonographer is proposed to autonomously "explore" target anatomies and navigate a US probe to a relevant 2D plane by learning from expert. The underlying high-level physiological knowledge from experts is inferred by a neural reward function, using a ranked pairwise image comparisons approach in a self-supervised fashion. This process can be referred to as understanding the "language of sonography". Considering the generalization capability to overcome inter-patient variations, mutual information is estimated by a network to explicitly extract the task-related and domain features in latent space. Besides, a Gaussian distribution-based filter is developed to automatically evaluate and take the quality of the expert's demonstrations into account. The robotic localization is carried out in coarse-to-fine mode based on the predicted reward associated to B-mode images. To demonstrate the performance of the proposed approach, representative experiments for the "line" target and "point" target are performed on vascular phantom and two ex-vivo animal organ phantoms (chicken heart and lamb kidney), respectively. The results demonstrated that the proposed advanced framework can robustly work on different kinds of known and unseen phantoms.
Language-free Compositional Action Generation via Decoupling Refinement
Jul 07, 2023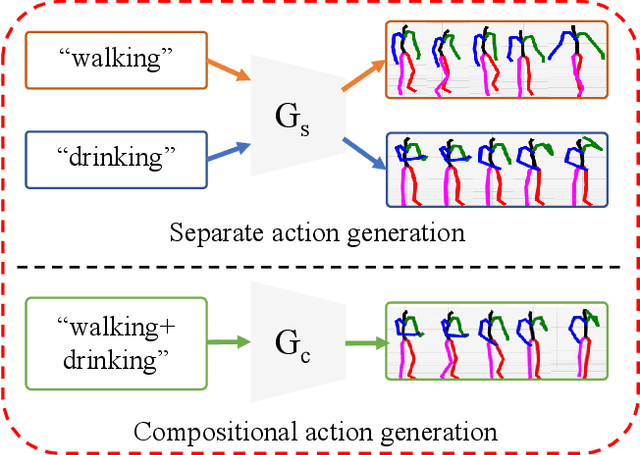

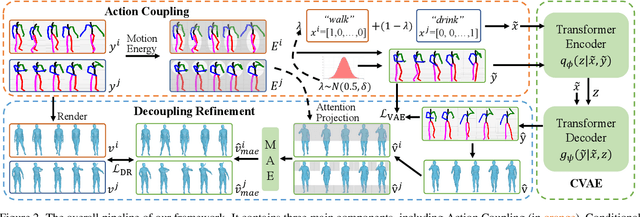
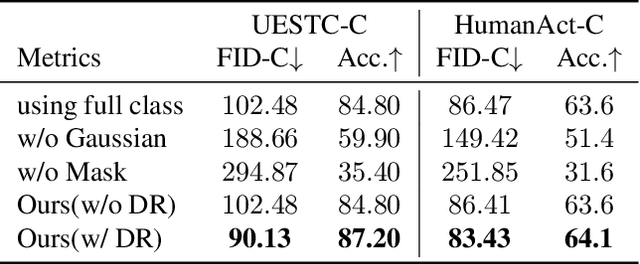
Composing simple elements into complex concepts is crucial yet challenging, especially for 3D action generation. Existing methods largely rely on extensive neural language annotations to discern composable latent semantics, a process that is often costly and labor-intensive. In this study, we introduce a novel framework to generate compositional actions without reliance on language auxiliaries. Our approach consists of three main components: Action Coupling, Conditional Action Generation, and Decoupling Refinement. Action Coupling utilizes an energy model to extract the attention masks of each sub-action, subsequently integrating two actions using these attentions to generate pseudo-training examples. Then, we employ a conditional generative model, CVAE, to learn a latent space, facilitating the diverse generation. Finally, we propose Decoupling Refinement, which leverages a self-supervised pre-trained model MAE to ensure semantic consistency between the sub-actions and compositional actions. This refinement process involves rendering generated 3D actions into 2D space, decoupling these images into two sub-segments, using the MAE model to restore the complete image from sub-segments, and constraining the recovered images to match images rendered from raw sub-actions. Due to the lack of existing datasets containing both sub-actions and compositional actions, we created two new datasets, named HumanAct-C and UESTC-C, and present a corresponding evaluation metric. Both qualitative and quantitative assessments are conducted to show our efficacy.
Equivariant Single View Pose Prediction Via Induced and Restricted Representations
Jul 07, 2023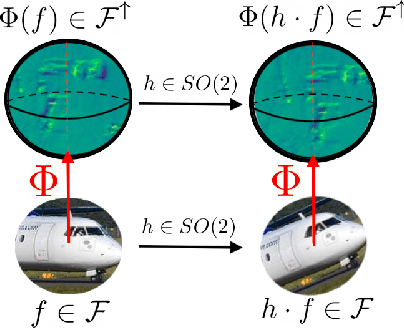
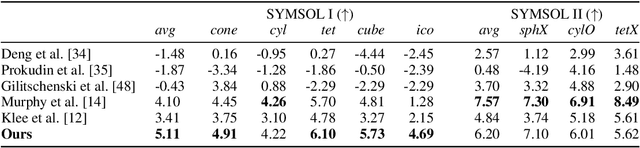
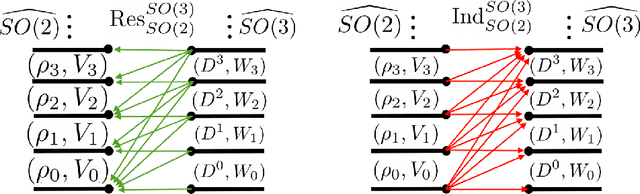

Learning about the three-dimensional world from two-dimensional images is a fundamental problem in computer vision. An ideal neural network architecture for such tasks would leverage the fact that objects can be rotated and translated in three dimensions to make predictions about novel images. However, imposing SO(3)-equivariance on two-dimensional inputs is difficult because the group of three-dimensional rotations does not have a natural action on the two-dimensional plane. Specifically, it is possible that an element of SO(3) will rotate an image out of plane. We show that an algorithm that learns a three-dimensional representation of the world from two dimensional images must satisfy certain geometric consistency properties which we formulate as SO(2)-equivariance constraints. We use the induced and restricted representations of SO(2) on SO(3) to construct and classify architectures which satisfy these geometric consistency constraints. We prove that any architecture which respects said consistency constraints can be realized as an instance of our construction. We show that three previously proposed neural architectures for 3D pose prediction are special cases of our construction. We propose a new algorithm that is a learnable generalization of previously considered methods. We test our architecture on three pose predictions task and achieve SOTA results on both the PASCAL3D+ and SYMSOL pose estimation tasks.
Hamming Similarity and Graph Laplacians for Class Partitioning and Adversarial Image Detection
May 02, 2023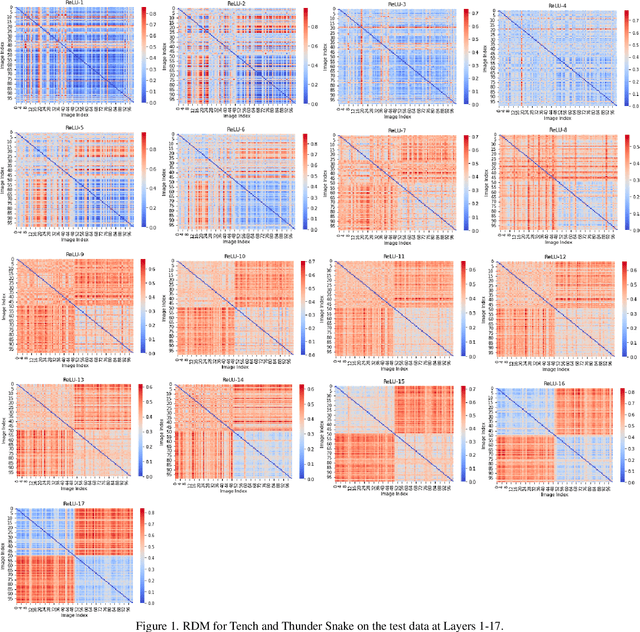

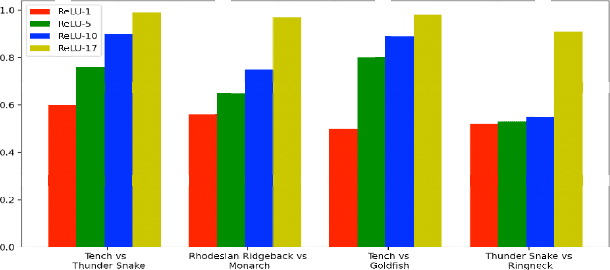

Researchers typically investigate neural network representations by examining activation outputs for one or more layers of a network. Here, we investigate the potential for ReLU activation patterns (encoded as bit vectors) to aid in understanding and interpreting the behavior of neural networks. We utilize Representational Dissimilarity Matrices (RDMs) to investigate the coherence of data within the embedding spaces of a deep neural network. From each layer of a network, we extract and utilize bit vectors to construct similarity scores between images. From these similarity scores, we build a similarity matrix for a collection of images drawn from 2 classes. We then apply Fiedler partitioning to the associated Laplacian matrix to separate the classes. Our results indicate, through bit vector representations, that the network continues to refine class detectability with the last ReLU layer achieving better than 95\% separation accuracy. Additionally, we demonstrate that bit vectors aid in adversarial image detection, again achieving over 95\% accuracy in separating adversarial and non-adversarial images using a simple classifier.
Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation
Jun 13, 2023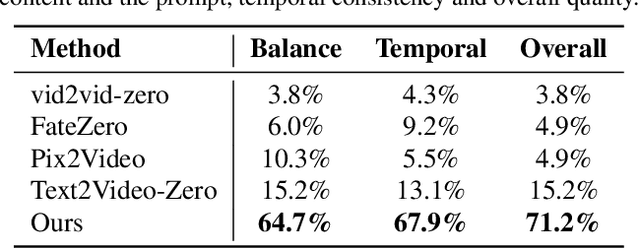

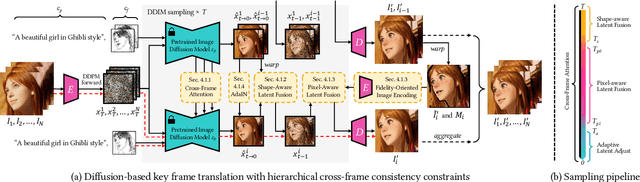

Large text-to-image diffusion models have exhibited impressive proficiency in generating high-quality images. However, when applying these models to video domain, ensuring temporal consistency across video frames remains a formidable challenge. This paper proposes a novel zero-shot text-guided video-to-video translation framework to adapt image models to videos. The framework includes two parts: key frame translation and full video translation. The first part uses an adapted diffusion model to generate key frames, with hierarchical cross-frame constraints applied to enforce coherence in shapes, textures and colors. The second part propagates the key frames to other frames with temporal-aware patch matching and frame blending. Our framework achieves global style and local texture temporal consistency at a low cost (without re-training or optimization). The adaptation is compatible with existing image diffusion techniques, allowing our framework to take advantage of them, such as customizing a specific subject with LoRA, and introducing extra spatial guidance with ControlNet. Extensive experimental results demonstrate the effectiveness of our proposed framework over existing methods in rendering high-quality and temporally-coherent videos.
Robotic Ultrasound Imaging: State-of-the-Art and Future Perspectives
Jul 08, 2023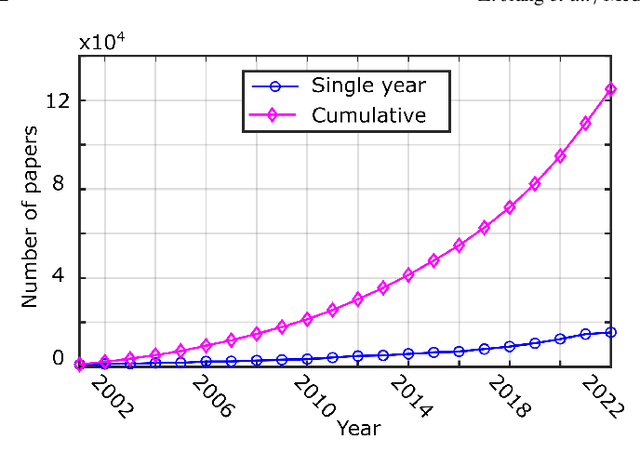
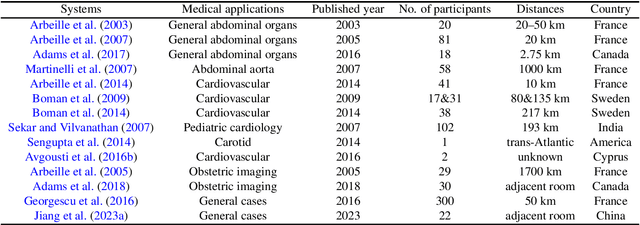
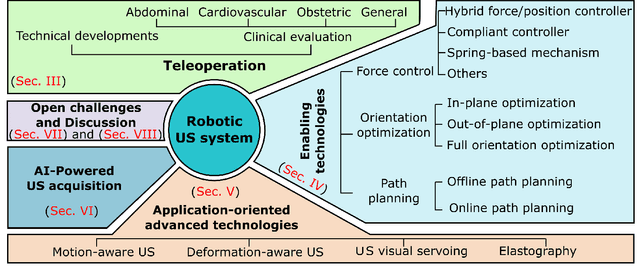
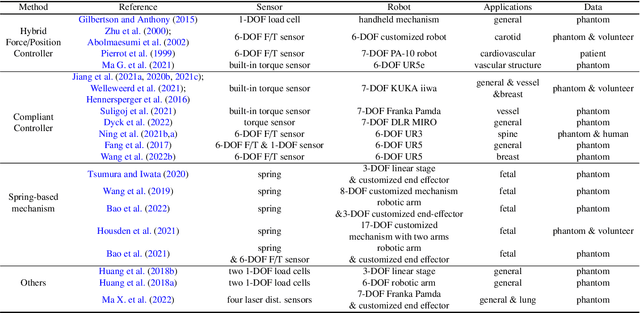
Ultrasound (US) is one of the most widely used modalities for clinical intervention and diagnosis due to the merits of providing non-invasive, radiation-free, and real-time images. However, free-hand US examinations are highly operator-dependent. Robotic US System (RUSS) aims at overcoming this shortcoming by offering reproducibility, while also aiming at improving dexterity, and intelligent anatomy and disease-aware imaging. In addition to enhancing diagnostic outcomes, RUSS also holds the potential to provide medical interventions for populations suffering from the shortage of experienced sonographers. In this paper, we categorize RUSS as teleoperated or autonomous. Regarding teleoperated RUSS, we summarize their technical developments, and clinical evaluations, respectively. This survey then focuses on the review of recent work on autonomous robotic US imaging. We demonstrate that machine learning and artificial intelligence present the key techniques, which enable intelligent patient and process-specific, motion and deformation-aware robotic image acquisition. We also show that the research on artificial intelligence for autonomous RUSS has directed the research community toward understanding and modeling expert sonographers' semantic reasoning and action. Here, we call this process, the recovery of the "language of sonography". This side result of research on autonomous robotic US acquisitions could be considered as valuable and essential as the progress made in the robotic US examination itself. This article will provide both engineers and clinicians with a comprehensive understanding of RUSS by surveying underlying techniques.
End-to-End Supervised Multilabel Contrastive Learning
Jul 08, 2023
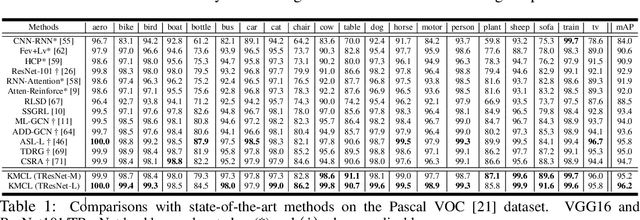
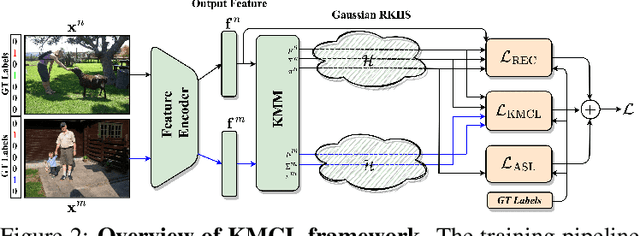

Multilabel representation learning is recognized as a challenging problem that can be associated with either label dependencies between object categories or data-related issues such as the inherent imbalance of positive/negative samples. Recent advances address these challenges from model- and data-centric viewpoints. In model-centric, the label correlation is obtained by an external model designs (e.g., graph CNN) to incorporate an inductive bias for training. However, they fail to design an end-to-end training framework, leading to high computational complexity. On the contrary, in data-centric, the realistic nature of the dataset is considered for improving the classification while ignoring the label dependencies. In this paper, we propose a new end-to-end training framework -- dubbed KMCL (Kernel-based Mutlilabel Contrastive Learning) -- to address the shortcomings of both model- and data-centric designs. The KMCL first transforms the embedded features into a mixture of exponential kernels in Gaussian RKHS. It is then followed by encoding an objective loss that is comprised of (a) reconstruction loss to reconstruct kernel representation, (b) asymmetric classification loss to address the inherent imbalance problem, and (c) contrastive loss to capture label correlation. The KMCL models the uncertainty of the feature encoder while maintaining a low computational footprint. Extensive experiments are conducted on image classification tasks to showcase the consistent improvements of KMCL over the SOTA methods. PyTorch implementation is provided in \url{https://github.com/mahdihosseini/KMCL}.
I2Edit: Towards Multi-turn Interactive Image Editing via Dialogue
Mar 20, 2023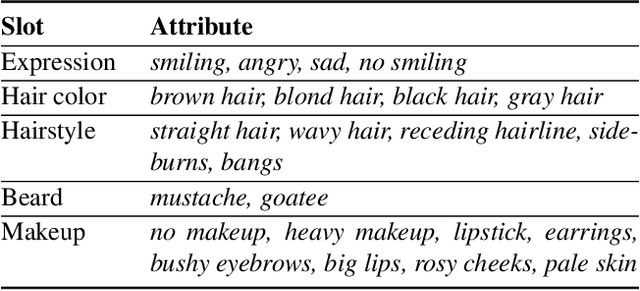

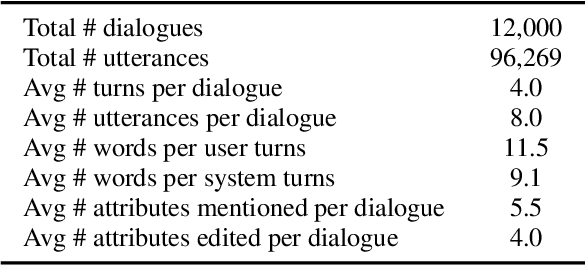
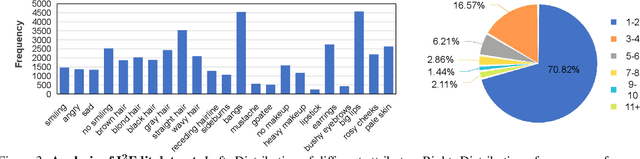
Although there have been considerable research efforts on controllable facial image editing, the desirable interactive setting where the users can interact with the system to adjust their requirements dynamically hasn't been well explored. This paper focuses on facial image editing via dialogue and introduces a new benchmark dataset, Multi-turn Interactive Image Editing (I2Edit), for evaluating image editing quality and interaction ability in real-world interactive facial editing scenarios. The dataset is constructed upon the CelebA-HQ dataset with images annotated with a multi-turn dialogue that corresponds to the user editing requirements. I2Edit is challenging, as it needs to 1) track the dynamically updated user requirements and edit the images accordingly, as well as 2) generate the appropriate natural language response to communicate with the user. To address these challenges, we propose a framework consisting of a dialogue module and an image editing module. The former is for user edit requirements tracking and generating the corresponding indicative responses, while the latter edits the images conditioned on the tracked user edit requirements. In contrast to previous works that simply treat multi-turn interaction as a sequence of single-turn interactions, we extract the user edit requirements from the whole dialogue history instead of the current single turn. The extracted global user edit requirements enable us to directly edit the input raw image to avoid error accumulation and attribute forgetting issues. Extensive quantitative and qualitative experiments on the I2Edit dataset demonstrate the advantage of our proposed framework over the previous single-turn methods. We believe our new dataset could serve as a valuable resource to push forward the exploration of real-world, complex interactive image editing. Code and data will be made public.