 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn
Jun 28, 2023
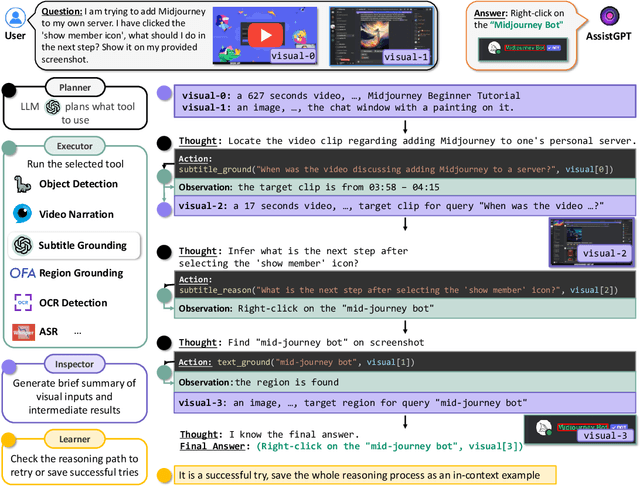


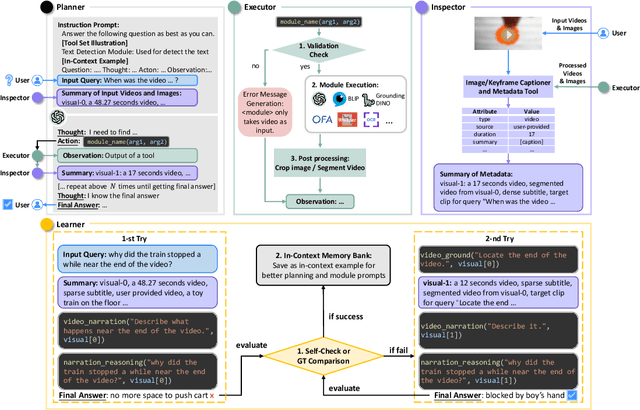
Recent research on Large Language Models (LLMs) has led to remarkable advancements in general NLP AI assistants. Some studies have further explored the use of LLMs for planning and invoking models or APIs to address more general multi-modal user queries. Despite this progress, complex visual-based tasks still remain challenging due to the diverse nature of visual tasks. This diversity is reflected in two aspects: 1) Reasoning paths. For many real-life applications, it is hard to accurately decompose a query simply by examining the query itself. Planning based on the specific visual content and the results of each step is usually required. 2) Flexible inputs and intermediate results. Input forms could be flexible for in-the-wild cases, and involves not only a single image or video but a mixture of videos and images, e.g., a user-view image with some reference videos. Besides, a complex reasoning process will also generate diverse multimodal intermediate results, e.g., video narrations, segmented video clips, etc. To address such general cases, we propose a multi-modal AI assistant, AssistGPT, with an interleaved code and language reasoning approach called Plan, Execute, Inspect, and Learn (PEIL) to integrate LLMs with various tools. Specifically, the Planner is capable of using natural language to plan which tool in Executor should do next based on the current reasoning progress. Inspector is an efficient memory manager to assist the Planner to feed proper visual information into a specific tool. Finally, since the entire reasoning process is complex and flexible, a Learner is designed to enable the model to autonomously explore and discover the optimal solution. We conducted experiments on A-OKVQA and NExT-QA benchmarks, achieving state-of-the-art results. Moreover, showcases demonstrate the ability of our system to handle questions far more complex than those found in the benchmarks.
Read, Look or Listen? What's Needed for Solving a Multimodal Dataset
Jul 06, 2023

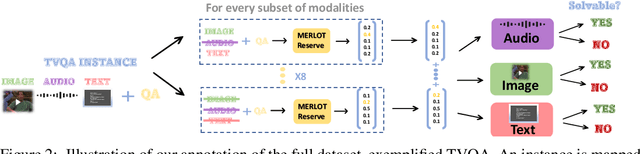
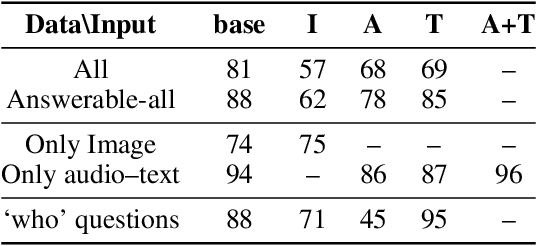
The prevalence of large-scale multimodal datasets presents unique challenges in assessing dataset quality. We propose a two-step method to analyze multimodal datasets, which leverages a small seed of human annotation to map each multimodal instance to the modalities required to process it. Our method sheds light on the importance of different modalities in datasets, as well as the relationship between them. We apply our approach to TVQA, a video question-answering dataset, and discover that most questions can be answered using a single modality, without a substantial bias towards any specific modality. Moreover, we find that more than 70% of the questions are solvable using several different single-modality strategies, e.g., by either looking at the video or listening to the audio, highlighting the limited integration of multiple modalities in TVQA. We leverage our annotation and analyze the MERLOT Reserve, finding that it struggles with image-based questions compared to text and audio, but also with auditory speaker identification. Based on our observations, we introduce a new test set that necessitates multiple modalities, observing a dramatic drop in model performance. Our methodology provides valuable insights into multimodal datasets and highlights the need for the development of more robust models.
Cross-Modal Content Inference and Feature Enrichment for Cold-Start Recommendation
Jul 06, 2023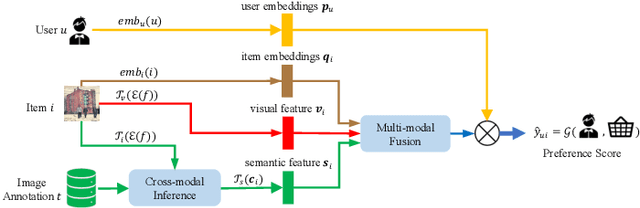
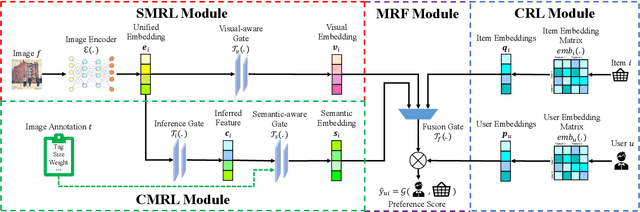
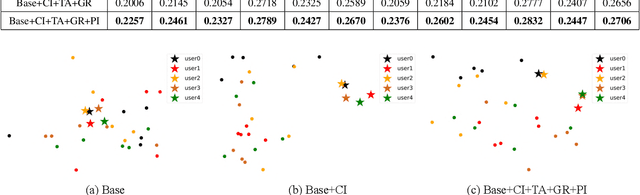
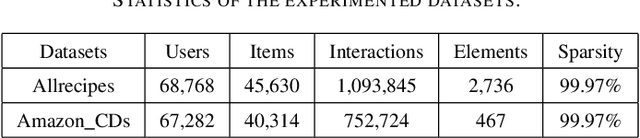
Multimedia recommendation aims to fuse the multi-modal information of items for feature enrichment to improve the recommendation performance. However, existing methods typically introduce multi-modal information based on collaborative information to improve the overall recommendation precision, while failing to explore its cold-start recommendation performance. Meanwhile, these above methods are only applicable when such multi-modal data is available. To address this problem, this paper proposes a recommendation framework, named Cross-modal Content Inference and Feature Enrichment Recommendation (CIERec), which exploits the multi-modal information to improve its cold-start recommendation performance. Specifically, CIERec first introduces image annotation as the privileged information to help guide the mapping of unified features from the visual space to the semantic space in the training phase. And then CIERec enriches the content representation with the fusion of collaborative, visual, and cross-modal inferred representations, so as to improve its cold-start recommendation performance. Experimental results on two real-world datasets show that the content representations learned by CIERec are able to achieve superior cold-start recommendation performance over existing visually-aware recommendation algorithms. More importantly, CIERec can consistently achieve significant improvements with different conventional visually-aware backbones, which verifies its universality and effectiveness.
Revisiting Computer-Aided Tuberculosis Diagnosis
Jul 06, 2023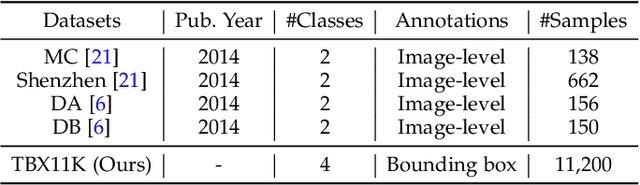
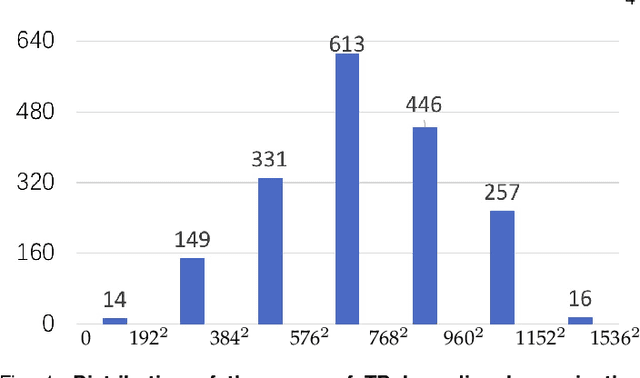
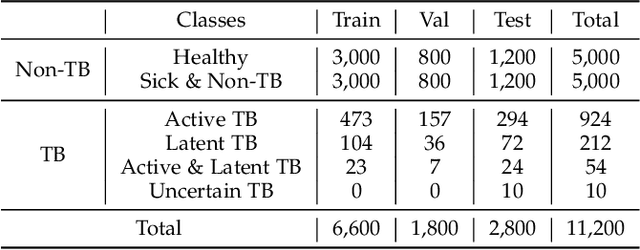
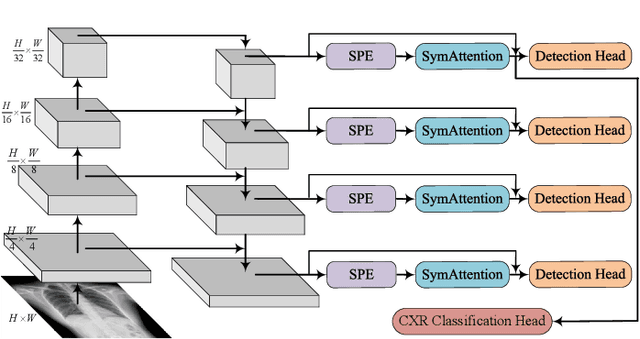
Tuberculosis (TB) is a major global health threat, causing millions of deaths annually. Although early diagnosis and treatment can greatly improve the chances of survival, it remains a major challenge, especially in developing countries. Recently, computer-aided tuberculosis diagnosis (CTD) using deep learning has shown promise, but progress is hindered by limited training data. To address this, we establish a large-scale dataset, namely the Tuberculosis X-ray (TBX11K) dataset, which contains 11,200 chest X-ray (CXR) images with corresponding bounding box annotations for TB areas. This dataset enables the training of sophisticated detectors for high-quality CTD. Furthermore, we propose a strong baseline, SymFormer, for simultaneous CXR image classification and TB infection area detection. SymFormer incorporates Symmetric Search Attention (SymAttention) to tackle the bilateral symmetry property of CXR images for learning discriminative features. Since CXR images may not strictly adhere to the bilateral symmetry property, we also propose Symmetric Positional Encoding (SPE) to facilitate SymAttention through feature recalibration. To promote future research on CTD, we build a benchmark by introducing evaluation metrics, evaluating baseline models reformed from existing detectors, and running an online challenge. Experiments show that SymFormer achieves state-of-the-art performance on the TBX11K dataset. The data, code, and models will be released.
Implicit Anatomical Rendering for Medical Image Segmentation with Stochastic Experts
Apr 06, 2023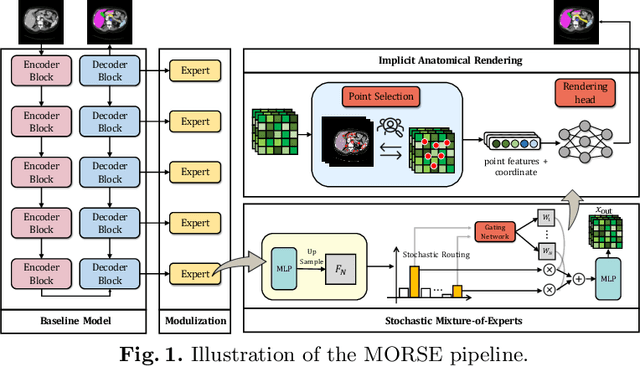
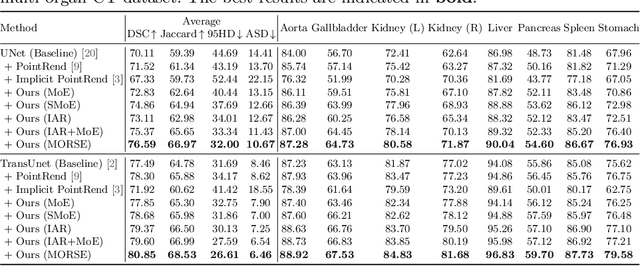
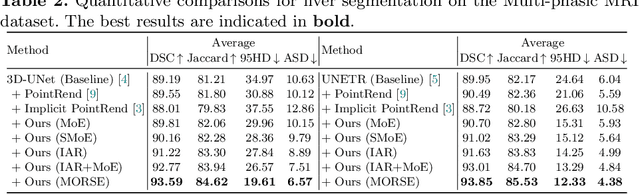
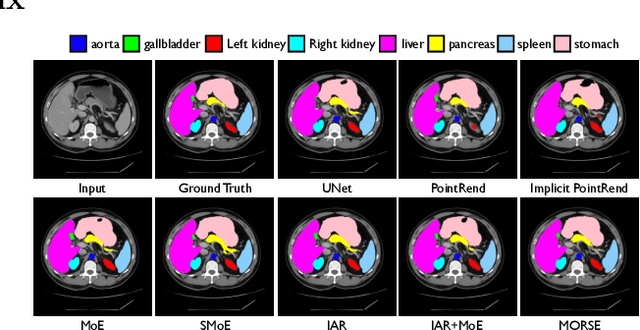
Integrating high-level semantically correlated contents and low-level anatomical features is of central importance in medical image segmentation. Towards this end, recent deep learning-based medical segmentation methods have shown great promise in better modeling such information. However, convolution operators for medical segmentation typically operate on regular grids, which inherently blur the high-frequency regions, i.e., boundary regions. In this work, we propose MORSE, a generic implicit neural rendering framework designed at an anatomical level to assist learning in medical image segmentation. Our method is motivated by the fact that implicit neural representation has been shown to be more effective in fitting complex signals and solving computer graphics problems than discrete grid-based representation. The core of our approach is to formulate medical image segmentation as a rendering problem in an end-to-end manner. Specifically, we continuously align the coarse segmentation prediction with the ambiguous coordinate-based point representations and aggregate these features to adaptively refine the boundary region. To parallelly optimize multi-scale pixel-level features, we leverage the idea from Mixture-of-Expert (MoE) to design and train our MORSE with a stochastic gating mechanism. Our experiments demonstrate that MORSE can work well with different medical segmentation backbones, consistently achieving competitive performance improvements in both 2D and 3D supervised medical segmentation methods. We also theoretically analyze the superiority of MORSE.
A Comparison of Image Denoising Methods
Apr 18, 2023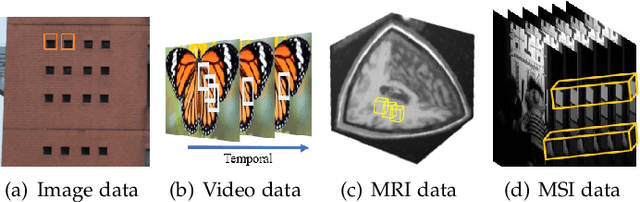
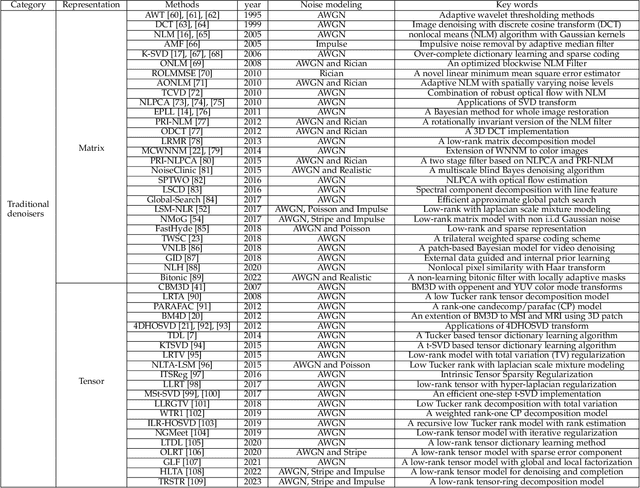
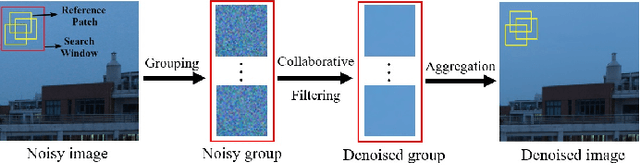
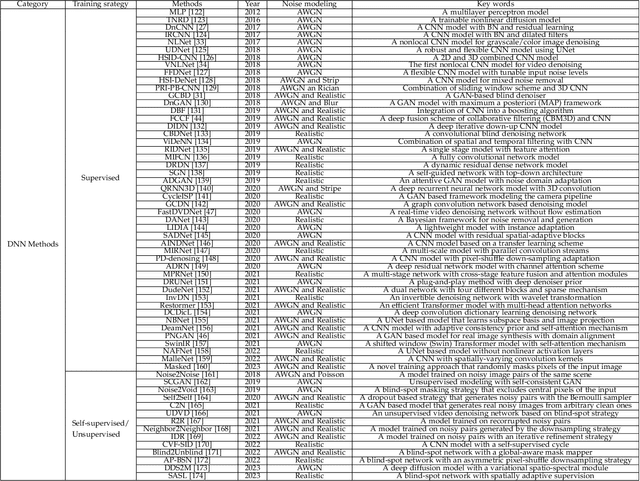
The advancement of imaging devices and countless images generated everyday pose an increasingly high demand on image denoising, which still remains a challenging task in terms of both effectiveness and efficiency. To improve denoising quality, numerous denoising techniques and approaches have been proposed in the past decades, including different transforms, regularization terms, algebraic representations and especially advanced deep neural network (DNN) architectures. Despite their sophistication, many methods may fail to achieve desirable results for simultaneous noise removal and fine detail preservation. In this paper, to investigate the applicability of existing denoising techniques, we compare a variety of denoising methods on both synthetic and real-world datasets for different applications. We also introduce a new dataset for benchmarking, and the evaluations are performed from four different perspectives including quantitative metrics, visual effects, human ratings and computational cost. Our experiments demonstrate: (i) the effectiveness and efficiency of representative traditional denoisers for various denoising tasks, (ii) a simple matrix-based algorithm may be able to produce similar results compared with its tensor counterparts, and (iii) the notable achievements of DNN models, which exhibit impressive generalization ability and show state-of-the-art performance on various datasets. In spite of the progress in recent years, we discuss shortcomings and possible extensions of existing techniques. Datasets, code and results are made publicly available and will be continuously updated at https://github.com/ZhaomingKong/Denoising-Comparison.
CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion
Mar 21, 2023
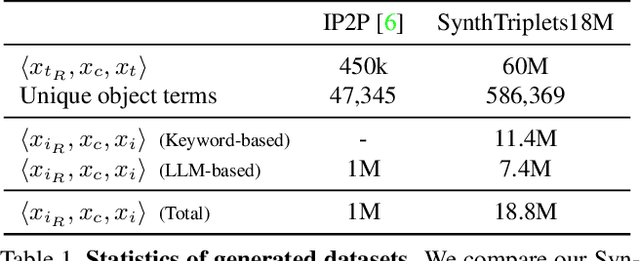
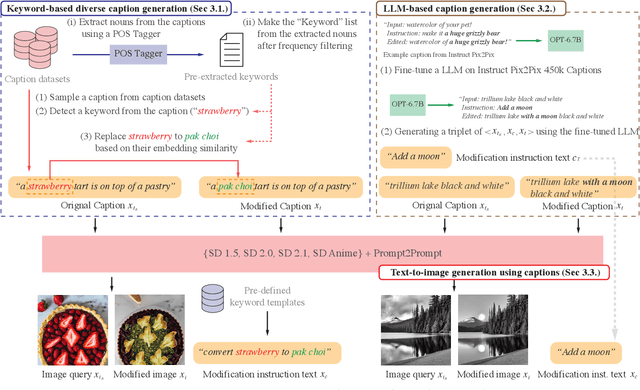

This paper proposes a novel diffusion-based model, CompoDiff, for solving Composed Image Retrieval (CIR) with latent diffusion and presents a newly created dataset of 18 million reference images, conditions, and corresponding target image triplets to train the model. CompoDiff not only achieves a new zero-shot state-of-the-art on a CIR benchmark such as FashionIQ but also enables a more versatile CIR by accepting various conditions, such as negative text and image mask conditions, which are unavailable with existing CIR methods. In addition, the CompoDiff features are on the intact CLIP embedding space so that they can be directly used for all existing models exploiting the CLIP space. The code and dataset used for the training, and the pre-trained weights are available at https://github.com/navervision/CompoDiff
Pseudo Supervised Metrics: Evaluating Unsupervised Image to Image Translation Models In Unsupervised Cross-Domain Classification Frameworks
Mar 18, 2023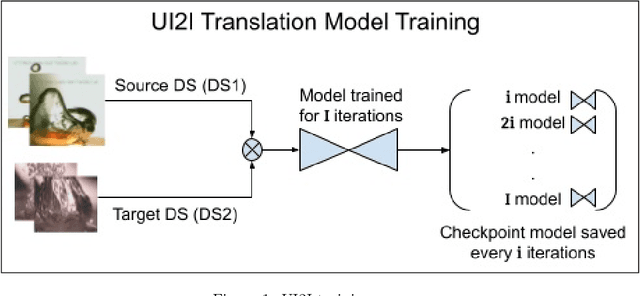

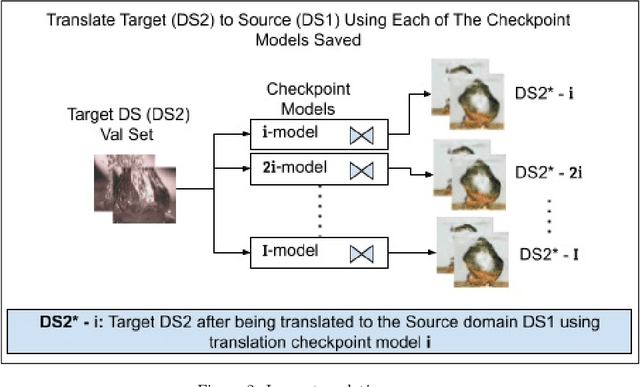
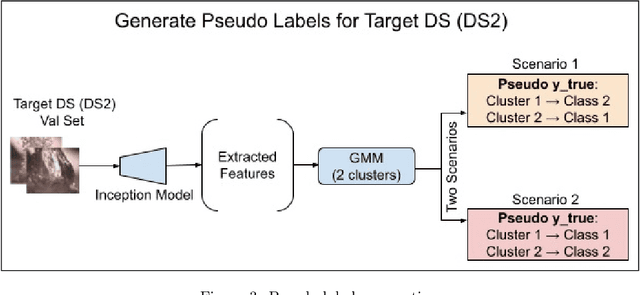
The ability to classify images accurately and efficiently is dependent on having access to large labeled datasets and testing on data from the same domain that the model is trained on. Classification becomes more challenging when dealing with new data from a different domain, where collecting a large labeled dataset and training a new classifier from scratch is time-consuming, expensive, and sometimes infeasible or impossible. Cross-domain classification frameworks were developed to handle this data domain shift problem by utilizing unsupervised image-to-image (UI2I) translation models to translate an input image from the unlabeled domain to the labeled domain. The problem with these unsupervised models lies in their unsupervised nature. For lack of annotations, it is not possible to use the traditional supervised metrics to evaluate these translation models to pick the best-saved checkpoint model. In this paper, we introduce a new method called Pseudo Supervised Metrics that was designed specifically to support cross-domain classification applications contrary to other typically used metrics such as the FID which was designed to evaluate the model in terms of the quality of the generated image from a human-eye perspective. We show that our metric not only outperforms unsupervised metrics such as the FID, but is also highly correlated with the true supervised metrics, robust, and explainable. Furthermore, we demonstrate that it can be used as a standard metric for future research in this field by applying it to a critical real-world problem (the boiling crisis problem).
ACE: Zero-Shot Image to Image Translation via Pretrained Auto-Contrastive-Encoder
Feb 22, 2023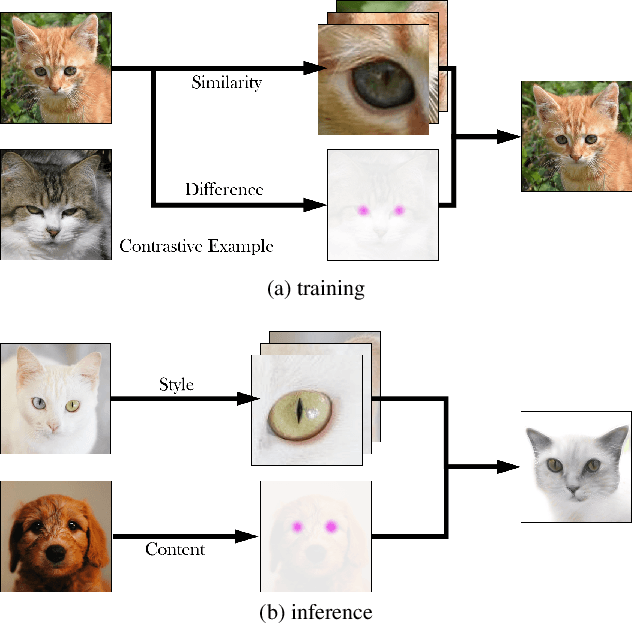
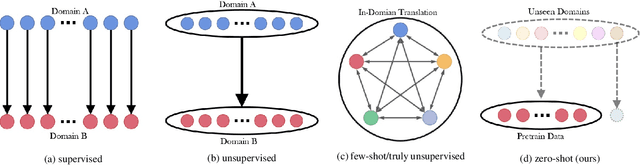
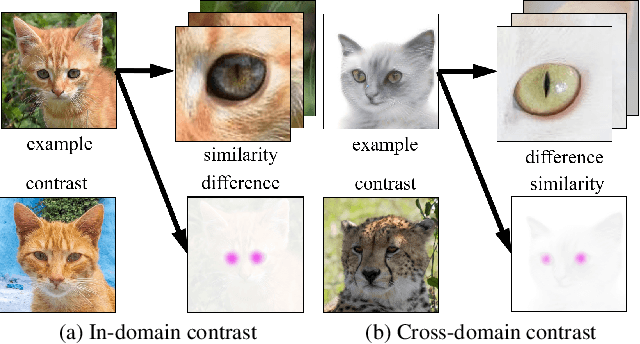
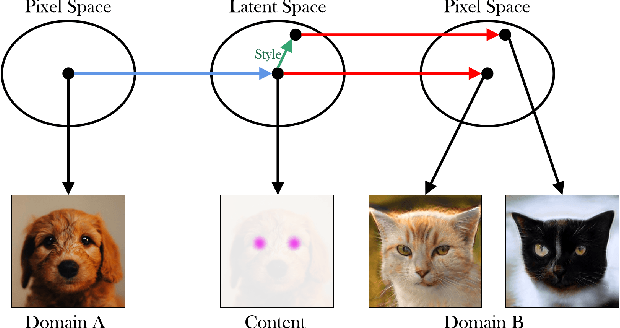
Image-to-image translation is a fundamental task in computer vision. It transforms images from one domain to images in another domain so that they have particular domain-specific characteristics. Most prior works train a generative model to learn the mapping from a source domain to a target domain. However, learning such mapping between domains is challenging because data from different domains can be highly unbalanced in terms of both quality and quantity. To address this problem, we propose a new approach to extract image features by learning the similarities and differences of samples within the same data distribution via a novel contrastive learning framework, which we call Auto-Contrastive-Encoder (ACE). ACE learns the content code as the similarity between samples with the same content information and different style perturbations. The design of ACE enables us to achieve zero-shot image-to-image translation with no training on image translation tasks for the first time. Moreover, our learning method can learn the style features of images on different domains effectively. Consequently, our model achieves competitive results on multimodal image translation tasks with zero-shot learning as well. Additionally, we demonstrate the potential of our method in transfer learning. With fine-tuning, the quality of translated images improves in unseen domains. Even though we use contrastive learning, all of our training can be performed on a single GPU with the batch size of 8.
MedLSAM: Localize and Segment Anything Model for 3D Medical Images
Jun 26, 2023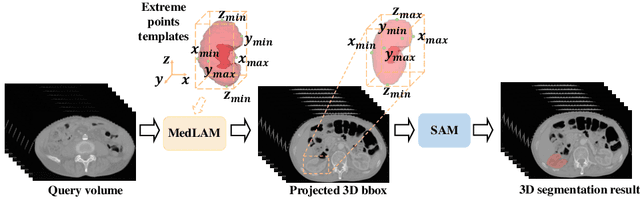
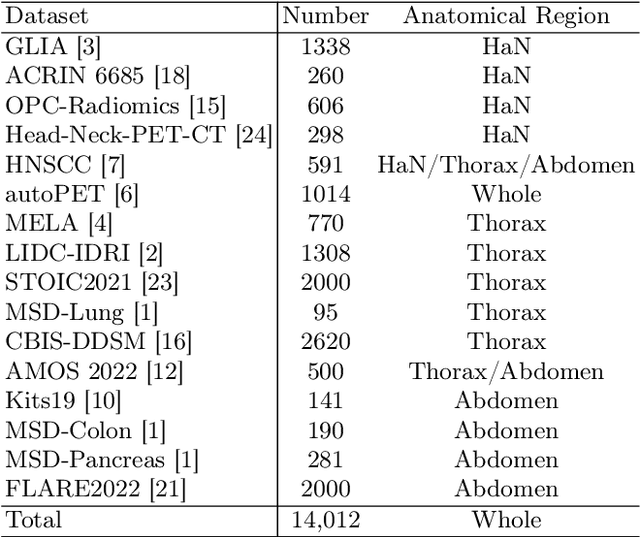
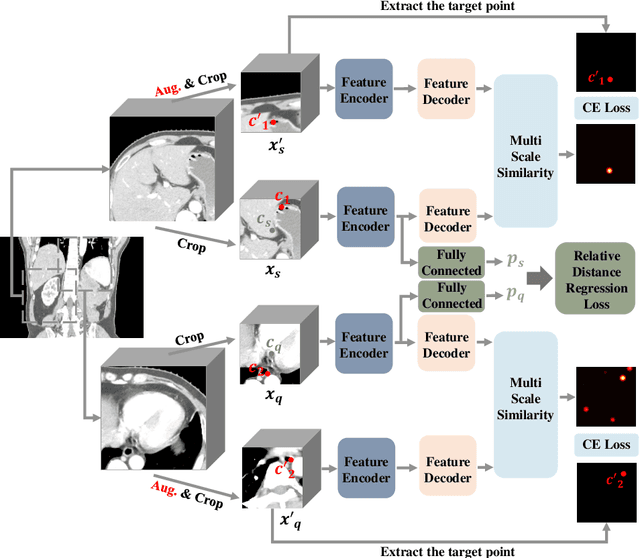
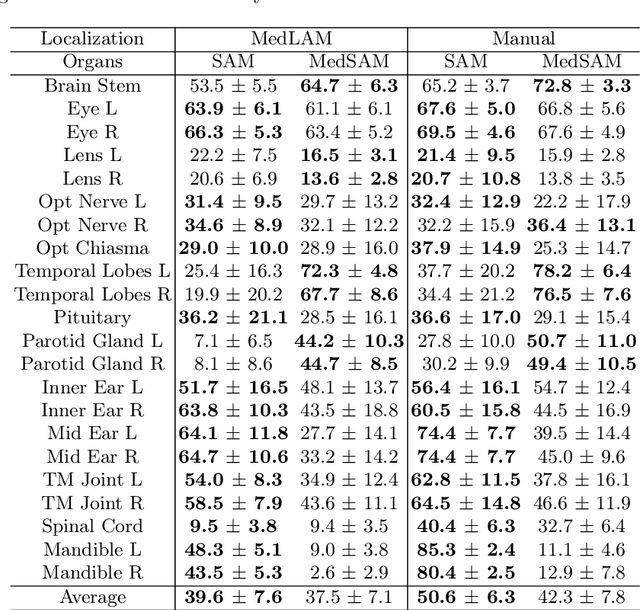
The Segment Anything Model (SAM) has recently emerged as a groundbreaking model in the field of image segmentation. Nevertheless, both the original SAM and its medical adaptations necessitate slice-by-slice annotations, which directly increase the annotation workload with the size of the dataset. We propose MedLSAM to address this issue, ensuring a constant annotation workload irrespective of dataset size and thereby simplifying the annotation process. Our model introduces a few-shot localization framework capable of localizing any target anatomical part within the body. To achieve this, we develop a Localize Anything Model for 3D Medical Images (MedLAM), utilizing two self-supervision tasks: relative distance regression (RDR) and multi-scale similarity (MSS) across a comprehensive dataset of 14,012 CT scans. We then establish a methodology for accurate segmentation by integrating MedLAM with SAM. By annotating only six extreme points across three directions on a few templates, our model can autonomously identify the target anatomical region on all data scheduled for annotation. This allows our framework to generate a 2D bounding box for every slice of the image, which are then leveraged by SAM to carry out segmentations. We conducted experiments on two 3D datasets covering 38 organs and found that MedLSAM matches the performance of SAM and its medical adaptations while requiring only minimal extreme point annotations for the entire dataset. Furthermore, MedLAM has the potential to be seamlessly integrated with future 3D SAM models, paving the way for enhanced performance. Our code is public at \href{https://github.com/openmedlab/MedLSAM}{https://github.com/openmedlab/MedLSAM}.