 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Degradation-Noise-Aware Deep Unfolding Transformer for Hyperspectral Image Denoising
May 06, 2023
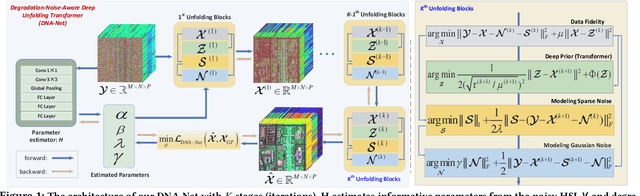
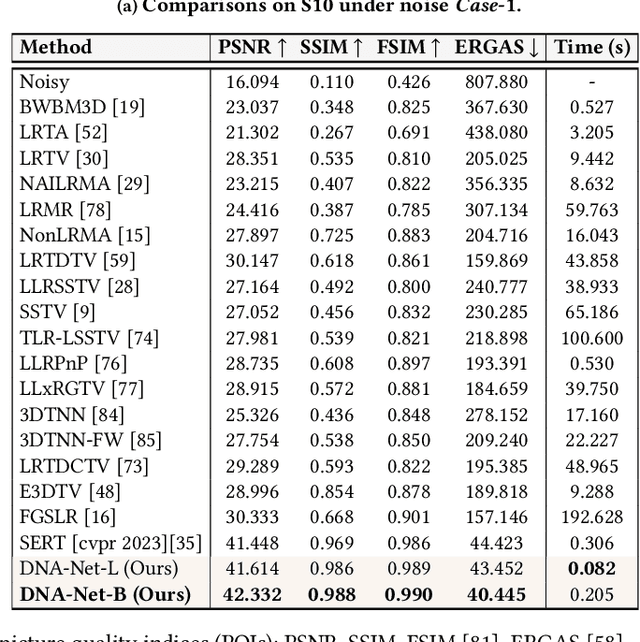
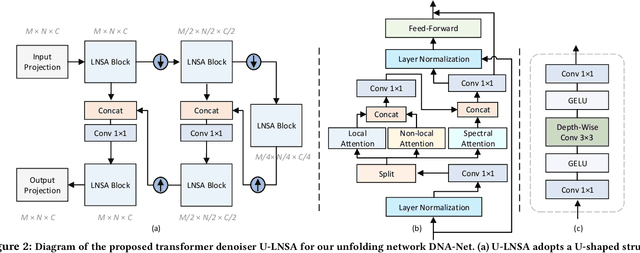
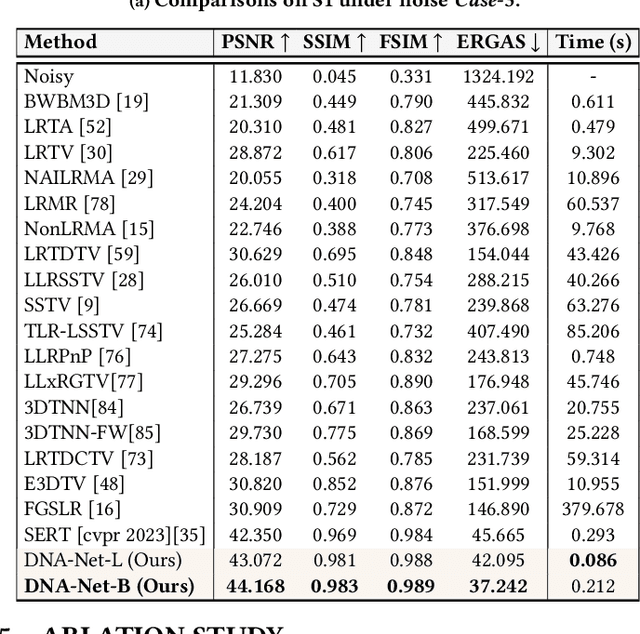
Hyperspectral imaging (HI) has emerged as a powerful tool in diverse fields such as medical diagnosis, industrial inspection, and agriculture, owing to its ability to detect subtle differences in physical properties through high spectral resolution. However, hyperspectral images (HSIs) are often quite noisy because of narrow band spectral filtering. To reduce the noise in HSI data cubes, both model-driven and learning-based denoising algorithms have been proposed. However, model-based approaches rely on hand-crafted priors and hyperparameters, while learning-based methods are incapable of estimating the inherent degradation patterns and noise distributions in the imaging procedure, which could inform supervised learning. Secondly, learning-based algorithms predominantly rely on CNN and fail to capture long-range dependencies, resulting in limited interpretability. This paper proposes a Degradation-Noise-Aware Unfolding Network (DNA-Net) that addresses these issues. Firstly, DNA-Net models sparse noise, Gaussian noise, and explicitly represent image prior using transformer. Then the model is unfolded into an end-to-end network, the hyperparameters within the model are estimated from the noisy HSI and degradation model and utilizes them to control each iteration. Additionally, we introduce a novel U-Shaped Local-Non-local-Spectral Transformer (U-LNSA) that captures spectral correlation, local contents, and non-local dependencies simultaneously. By integrating U-LNSA into DNA-Net, we present the first Transformer-based deep unfolding HSI denoising method. Experimental results show that DNA-Net outperforms state-of-the-art methods, and the modeling of noise distributions helps in cases with heavy noise.
Real-time Controllable Denoising for Image and Video
Mar 29, 2023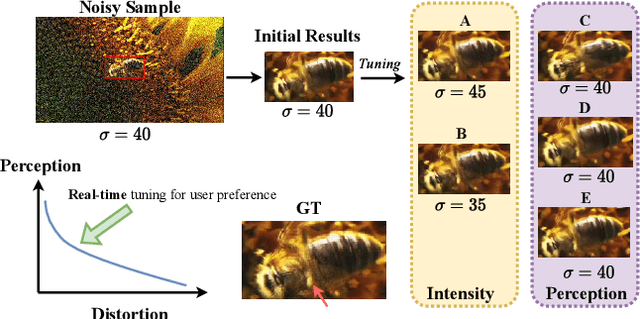
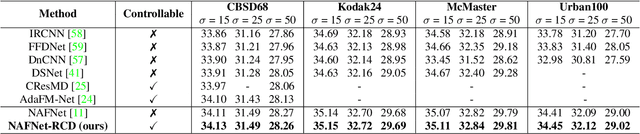
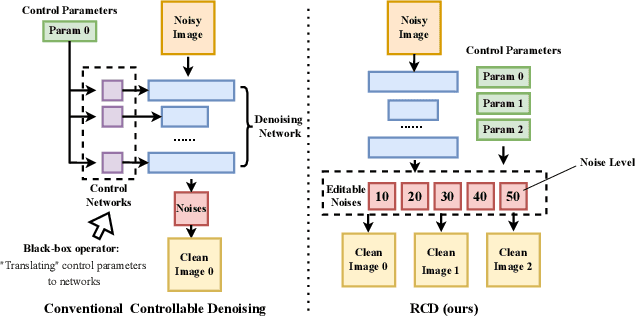

Controllable image denoising aims to generate clean samples with human perceptual priors and balance sharpness and smoothness. In traditional filter-based denoising methods, this can be easily achieved by adjusting the filtering strength. However, for NN (Neural Network)-based models, adjusting the final denoising strength requires performing network inference each time, making it almost impossible for real-time user interaction. In this paper, we introduce Real-time Controllable Denoising (RCD), the first deep image and video denoising pipeline that provides a fully controllable user interface to edit arbitrary denoising levels in real-time with only one-time network inference. Unlike existing controllable denoising methods that require multiple denoisers and training stages, RCD replaces the last output layer (which usually outputs a single noise map) of an existing CNN-based model with a lightweight module that outputs multiple noise maps. We propose a novel Noise Decorrelation process to enforce the orthogonality of the noise feature maps, allowing arbitrary noise level control through noise map interpolation. This process is network-free and does not require network inference. Our experiments show that RCD can enable real-time editable image and video denoising for various existing heavy-weight models without sacrificing their original performance.
RIDCP: Revitalizing Real Image Dehazing via High-Quality Codebook Priors
Apr 08, 2023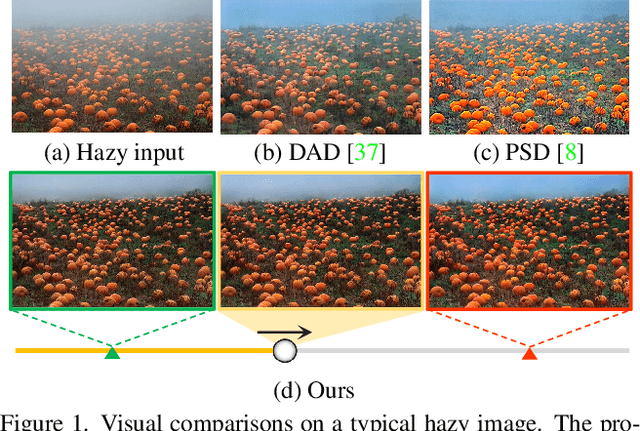
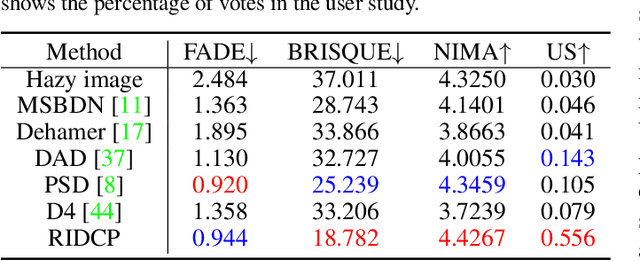
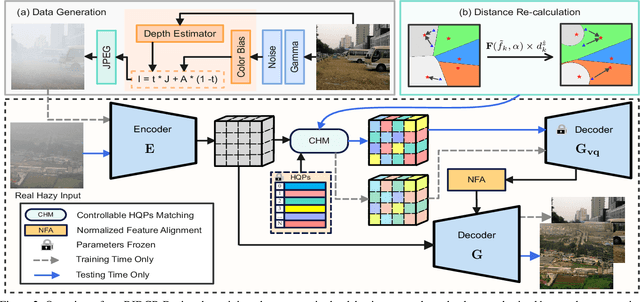
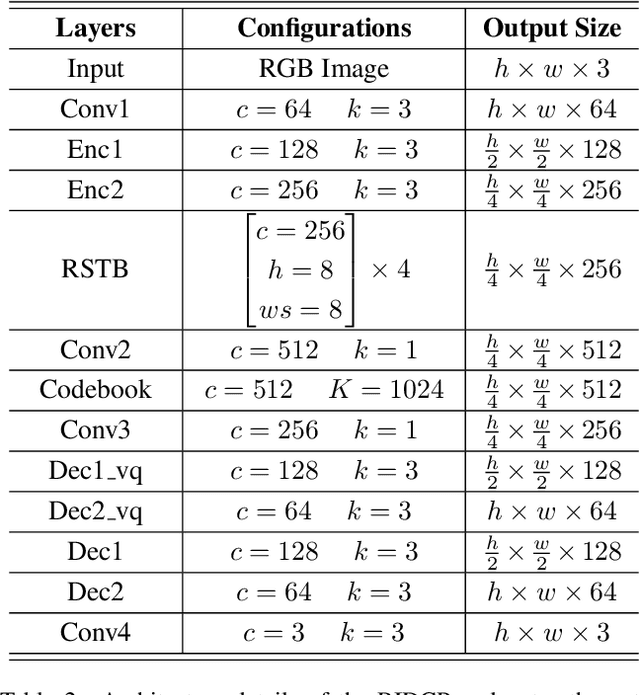
Existing dehazing approaches struggle to process real-world hazy images owing to the lack of paired real data and robust priors. In this work, we present a new paradigm for real image dehazing from the perspectives of synthesizing more realistic hazy data and introducing more robust priors into the network. Specifically, (1) instead of adopting the de facto physical scattering model, we rethink the degradation of real hazy images and propose a phenomenological pipeline considering diverse degradation types. (2) We propose a Real Image Dehazing network via high-quality Codebook Priors (RIDCP). Firstly, a VQGAN is pre-trained on a large-scale high-quality dataset to obtain the discrete codebook, encapsulating high-quality priors (HQPs). After replacing the negative effects brought by haze with HQPs, the decoder equipped with a novel normalized feature alignment module can effectively utilize high-quality features and produce clean results. However, although our degradation pipeline drastically mitigates the domain gap between synthetic and real data, it is still intractable to avoid it, which challenges HQPs matching in the wild. Thus, we re-calculate the distance when matching the features to the HQPs by a controllable matching operation, which facilitates finding better counterparts. We provide a recommendation to control the matching based on an explainable solution. Users can also flexibly adjust the enhancement degree as per their preference. Extensive experiments verify the effectiveness of our data synthesis pipeline and the superior performance of RIDCP in real image dehazing.
Let the Chart Spark: Embedding Semantic Context into Chart with Text-to-Image Generative Model
Apr 28, 2023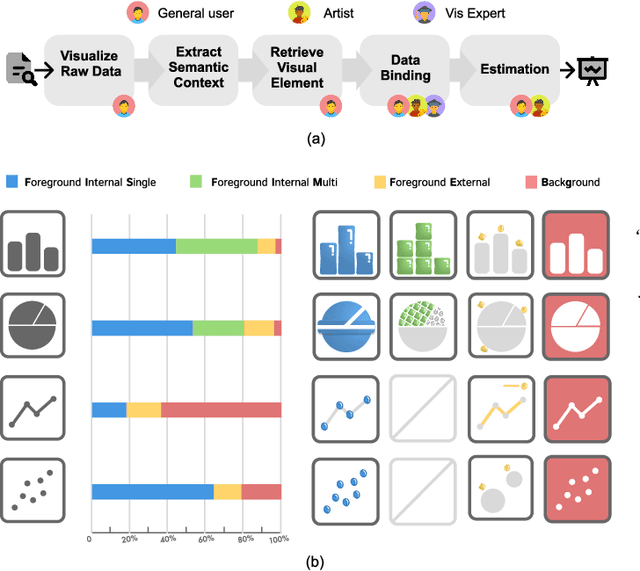
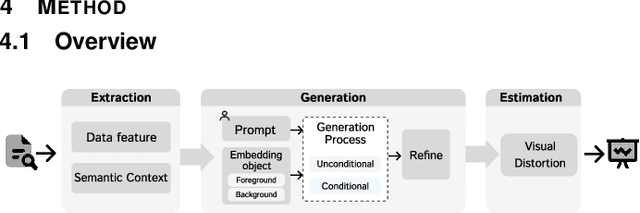
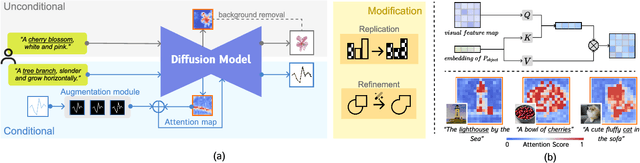
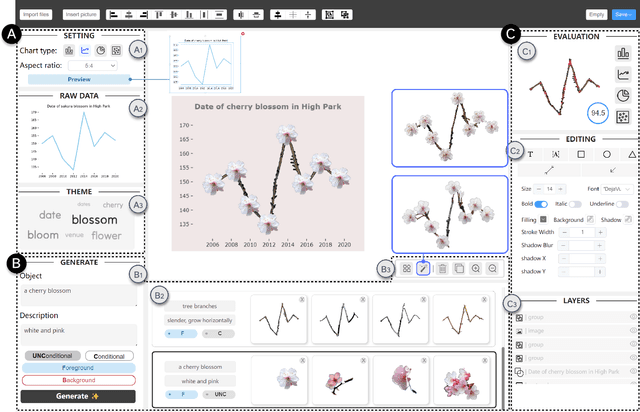
Pictorial visualization seamlessly integrates data and semantic context into visual representation, conveying complex information in a manner that is both engaging and informative. Extensive studies have been devoted to developing authoring tools to simplify the creation of pictorial visualizations. However, mainstream works mostly follow a retrieving-and-editing pipeline that heavily relies on retrieved visual elements from a dedicated corpus, which often compromise the data integrity. Text-guided generation methods are emerging, but may have limited applicability due to its predefined recognized entities. In this work, we propose ChartSpark, a novel system that embeds semantic context into chart based on text-to-image generative model. ChartSpark generates pictorial visualizations conditioned on both semantic context conveyed in textual inputs and data information embedded in plain charts. The method is generic for both foreground and background pictorial generation, satisfying the design practices identified from an empirical research into existing pictorial visualizations. We further develop an interactive visual interface that integrates a text analyzer, editing module, and evaluation module to enable users to generate, modify, and assess pictorial visualizations. We experimentally demonstrate the usability of our tool, and conclude with a discussion of the potential of using text-to-image generative model combined with interactive interface for visualization design.
Make It So: Steering StyleGAN for Any Image Inversion and Editing
Apr 27, 2023
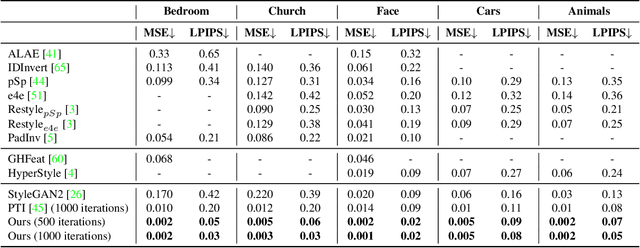

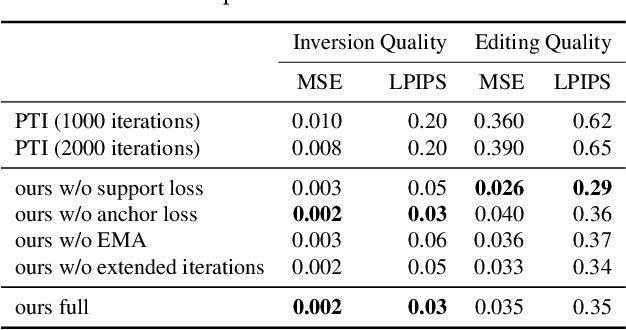
StyleGAN's disentangled style representation enables powerful image editing by manipulating the latent variables, but accurately mapping real-world images to their latent variables (GAN inversion) remains a challenge. Existing GAN inversion methods struggle to maintain editing directions and produce realistic results. To address these limitations, we propose Make It So, a novel GAN inversion method that operates in the $\mathcal{Z}$ (noise) space rather than the typical $\mathcal{W}$ (latent style) space. Make It So preserves editing capabilities, even for out-of-domain images. This is a crucial property that was overlooked in prior methods. Our quantitative evaluations demonstrate that Make It So outperforms the state-of-the-art method PTI~\cite{roich2021pivotal} by a factor of five in inversion accuracy and achieves ten times better edit quality for complex indoor scenes.
CT-based Subchondral Bone Microstructural Analysis in Knee Osteoarthritis via MR-Guided Distillation Learning
Jul 11, 2023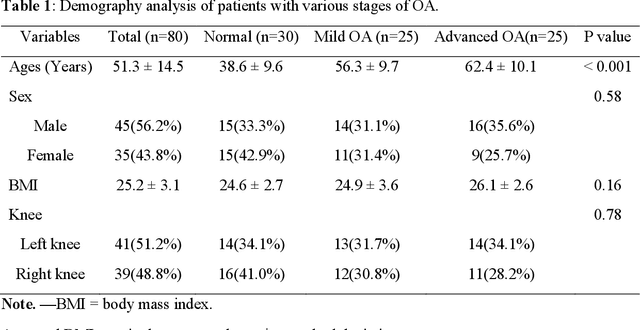

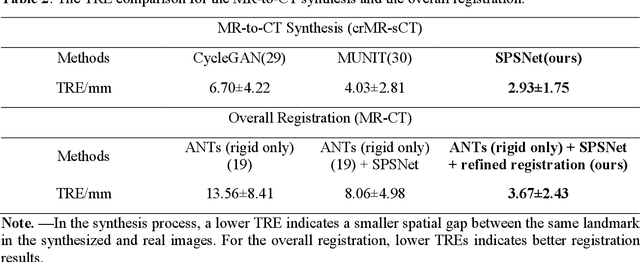
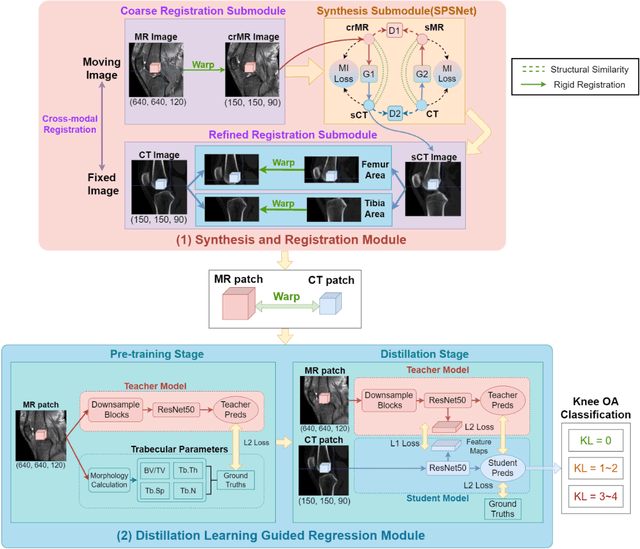
Background: MR-based subchondral bone effectively predicts knee osteoarthritis. However, its clinical application is limited by the cost and time of MR. Purpose: We aim to develop a novel distillation-learning-based method named SRRD for subchondral bone microstructural analysis using easily-acquired CT images, which leverages paired MR images to enhance the CT-based analysis model during training. Materials and Methods: Knee joint images of both CT and MR modalities were collected from October 2020 to May 2021. Firstly, we developed a GAN-based generative model to transform MR images into CT images, which was used to establish the anatomical correspondence between the two modalities. Next, we obtained numerous patches of subchondral bone regions of MR images, together with their trabecular parameters (BV / TV, Tb. Th, Tb. Sp, Tb. N) from the corresponding CT image patches via regression. The distillation-learning technique was used to train the regression model and transfer MR structural information to the CT-based model. The regressed trabecular parameters were further used for knee osteoarthritis classification. Results: A total of 80 participants were evaluated. CT-based regression results of trabecular parameters achieved intra-class correlation coefficients (ICCs) of 0.804, 0.773, 0.711, and 0.622 for BV / TV, Tb. Th, Tb. Sp, and Tb. N, respectively. The use of distillation learning significantly improved the performance of the CT-based knee osteoarthritis classification method using the CNN approach, yielding an AUC score of 0.767 (95% CI, 0.681-0.853) instead of 0.658 (95% CI, 0.574-0.742) (p<.001). Conclusions: The proposed SRRD method showed high reliability and validity in MR-CT registration, regression, and knee osteoarthritis classification, indicating the feasibility of subchondral bone microstructural analysis based on CT images.
Novel Pipeline for Diagnosing Acute Lymphoblastic Leukemia Sensitive to Related Biomarkers
Jul 11, 2023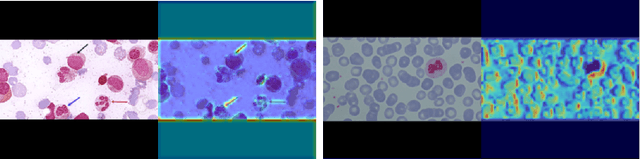
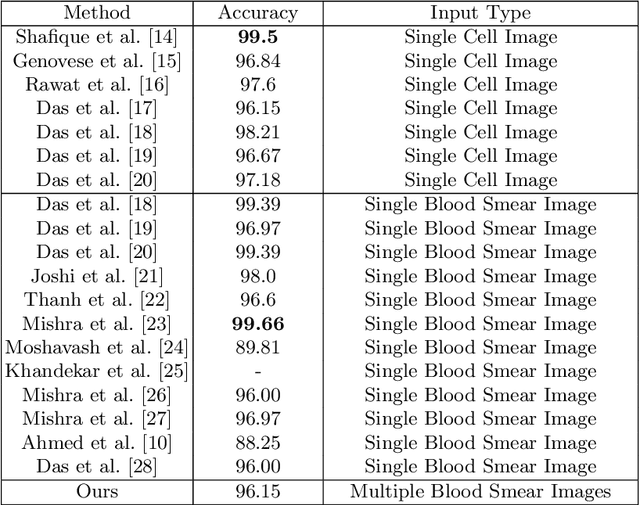
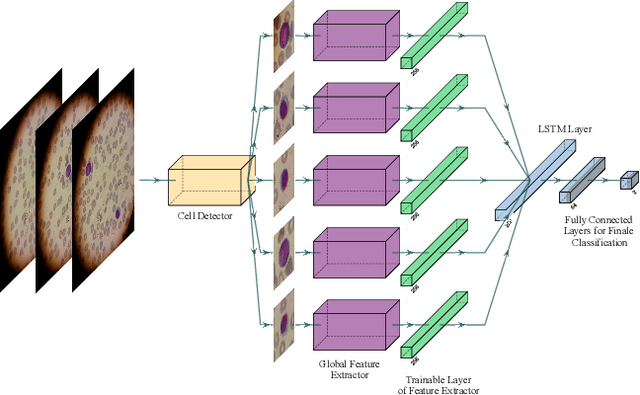
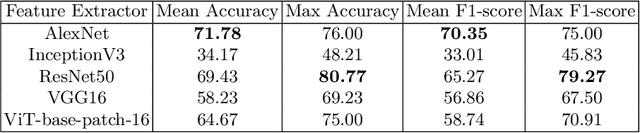
Acute Lymphoblastic Leukemia (ALL) is one of the most common types of childhood blood cancer. The quick start of the treatment process is critical to saving the patient's life, and for this reason, early diagnosis of this disease is essential. Examining the blood smear images of these patients is one of the methods used by expert doctors to diagnose this disease. Deep learning-based methods have numerous applications in medical fields, as they have significantly advanced in recent years. ALL diagnosis is not an exception in this field, and several machine learning-based methods for this problem have been proposed. In previous methods, high diagnostic accuracy was reported, but our work showed that this alone is not sufficient, as it can lead to models taking shortcuts and not making meaningful decisions. This issue arises due to the small size of medical training datasets. To address this, we constrained our model to follow a pipeline inspired by experts' work. We also demonstrated that, since a judgement based on only one image is insufficient, redefining the problem as a multiple-instance learning problem is necessary for achieving a practical result. Our model is the first to provide a solution to this problem in a multiple-instance learning setup. We introduced a novel pipeline for diagnosing ALL that approximates the process used by hematologists, is sensitive to disease biomarkers, and achieves an accuracy of 96.15%, an F1-score of 94.24%, a sensitivity of 97.56%, and a specificity of 90.91% on ALL IDB 1. Our method was further evaluated on an out-of-distribution dataset, which posed a challenging test and had acceptable performance. Notably, our model was trained on a relatively small dataset, highlighting the potential for our approach to be applied to other medical datasets with limited data availability.
AxonCallosumEM Dataset: Axon Semantic Segmentation of Whole Corpus Callosum cross section from EM Images
Jul 05, 2023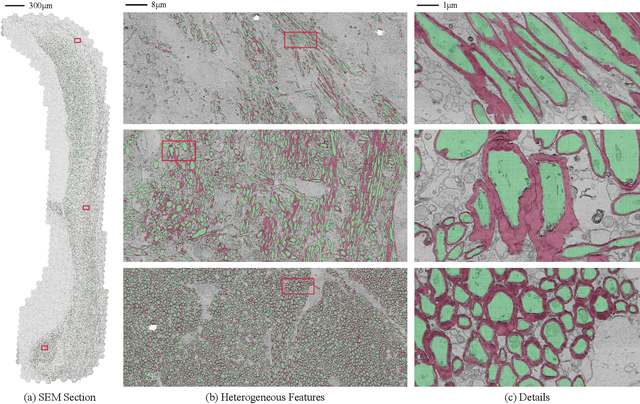
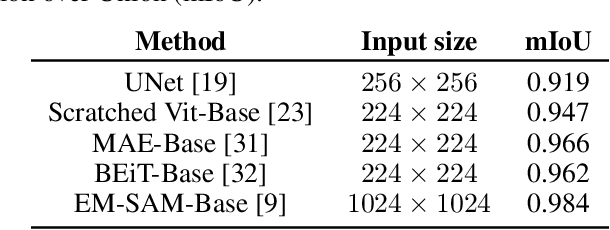
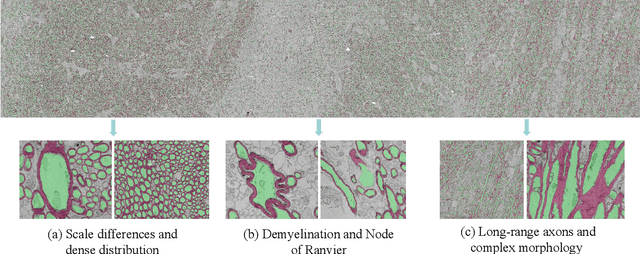
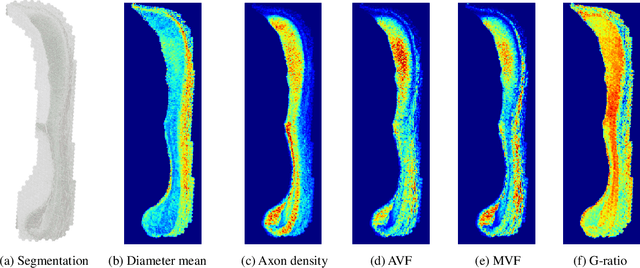
The electron microscope (EM) remains the predominant technique for elucidating intricate details of the animal nervous system at the nanometer scale. However, accurately reconstructing the complex morphology of axons and myelin sheaths poses a significant challenge. Furthermore, the absence of publicly available, large-scale EM datasets encompassing complete cross sections of the corpus callosum, with dense ground truth segmentation for axons and myelin sheaths, hinders the advancement and evaluation of holistic corpus callosum reconstructions. To surmount these obstacles, we introduce the AxonCallosumEM dataset, comprising a 1.83 times 5.76mm EM image captured from the corpus callosum of the Rett Syndrome (RTT) mouse model, which entail extensive axon bundles. We meticulously proofread over 600,000 patches at a resolution of 1024 times 1024, thus providing a comprehensive ground truth for myelinated axons and myelin sheaths. Additionally, we extensively annotated three distinct regions within the dataset for the purposes of training, testing, and validation. Utilizing this dataset, we develop a fine-tuning methodology that adapts Segment Anything Model (SAM) to EM images segmentation tasks, called EM-SAM, enabling outperforms other state-of-the-art methods. Furthermore, we present the evaluation results of EM-SAM as a baseline.
SVDM: Single-View Diffusion Model for Pseudo-Stereo 3D Object Detection
Jul 05, 2023

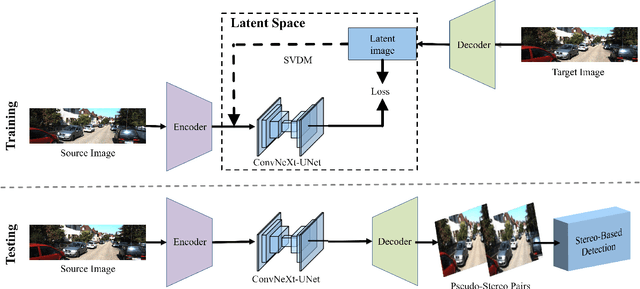

One of the key problems in 3D object detection is to reduce the accuracy gap between methods based on LiDAR sensors and those based on monocular cameras. A recently proposed framework for monocular 3D detection based on Pseudo-Stereo has received considerable attention in the community. However, so far these two problems are discovered in existing practices, including (1) monocular depth estimation and Pseudo-Stereo detector must be trained separately, (2) Difficult to be compatible with different stereo detectors and (3) the overall calculation is large, which affects the reasoning speed. In this work, we propose an end-to-end, efficient pseudo-stereo 3D detection framework by introducing a Single-View Diffusion Model (SVDM) that uses a few iterations to gradually deliver right informative pixels to the left image. SVDM allows the entire pseudo-stereo 3D detection pipeline to be trained end-to-end and can benefit from the training of stereo detectors. Afterwards, we further explore the application of SVDM in depth-free stereo 3D detection, and the final framework is compatible with most stereo detectors. Among multiple benchmarks on the KITTI dataset, we achieve new state-of-the-art performance.
What Matters in Training a GPT4-Style Language Model with Multimodal Inputs?
Jul 05, 2023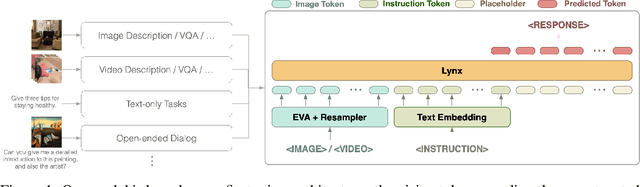
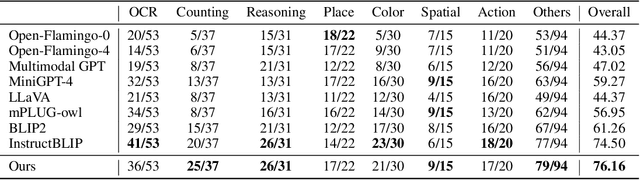
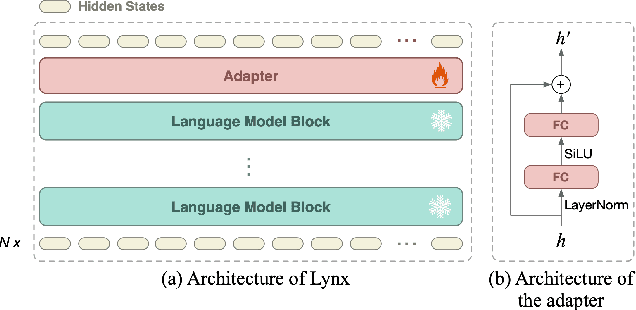
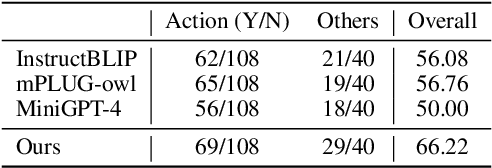
Recent advancements in Large Language Models (LLMs) such as GPT4 have displayed exceptional multi-modal capabilities in following open-ended instructions given images. However, the performance of these models heavily relies on design choices such as network structures, training data, and training strategies, and these choices have not been extensively discussed in the literature, making it difficult to quantify progress in this field. To address this issue, this paper presents a systematic and comprehensive study, quantitatively and qualitatively, on training such models. We implement over 20 variants with controlled settings. Concretely, for network structures, we compare different LLM backbones and model designs. For training data, we investigate the impact of data and sampling strategies. For instructions, we explore the influence of diversified prompts on the instruction-following ability of the trained models. For benchmarks, we contribute the first, to our best knowledge, comprehensive evaluation set including both image and video tasks through crowd-sourcing. Based on our findings, we present Lynx, which performs the most accurate multi-modal understanding while keeping the best multi-modal generation ability compared to existing open-sourced GPT4-style models.