 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Probabilistic Attention Model with Occlusion-aware Texture Regression for 3D Hand Reconstruction from a Single RGB Image
Apr 27, 2023
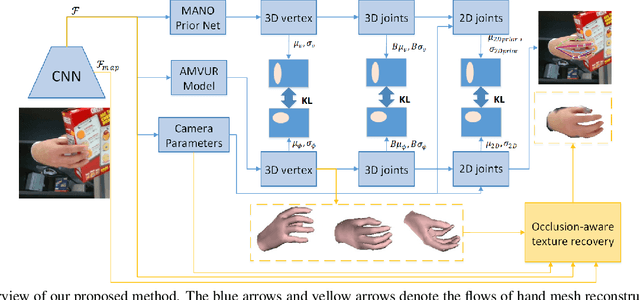
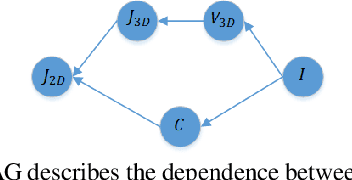
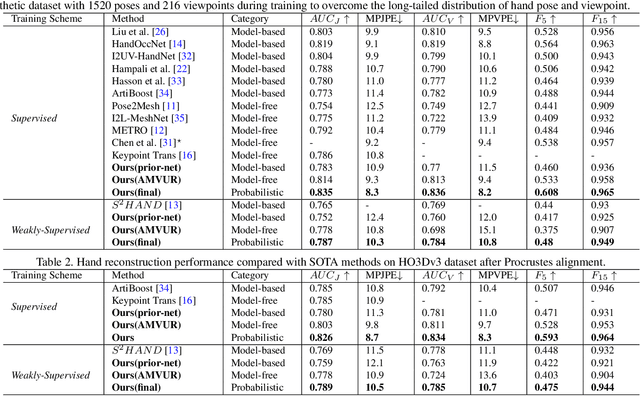
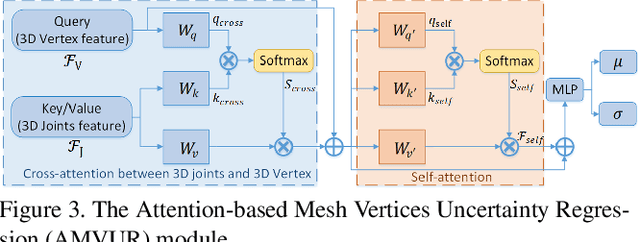
Recently, deep learning based approaches have shown promising results in 3D hand reconstruction from a single RGB image. These approaches can be roughly divided into model-based approaches, which are heavily dependent on the model's parameter space, and model-free approaches, which require large numbers of 3D ground truths to reduce depth ambiguity and struggle in weakly-supervised scenarios. To overcome these issues, we propose a novel probabilistic model to achieve the robustness of model-based approaches and reduced dependence on the model's parameter space of model-free approaches. The proposed probabilistic model incorporates a model-based network as a prior-net to estimate the prior probability distribution of joints and vertices. An Attention-based Mesh Vertices Uncertainty Regression (AMVUR) model is proposed to capture dependencies among vertices and the correlation between joints and mesh vertices to improve their feature representation. We further propose a learning based occlusion-aware Hand Texture Regression model to achieve high-fidelity texture reconstruction. We demonstrate the flexibility of the proposed probabilistic model to be trained in both supervised and weakly-supervised scenarios. The experimental results demonstrate our probabilistic model's state-of-the-art accuracy in 3D hand and texture reconstruction from a single image in both training schemes, including in the presence of severe occlusions.
Discovering Novel Biological Traits From Images Using Phylogeny-Guided Neural Networks
Jun 05, 2023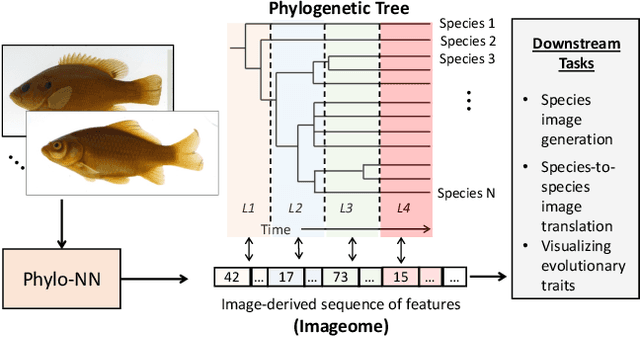
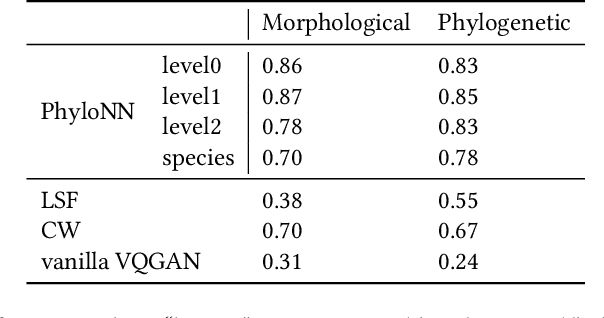
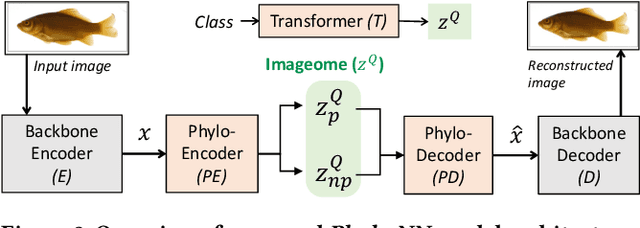
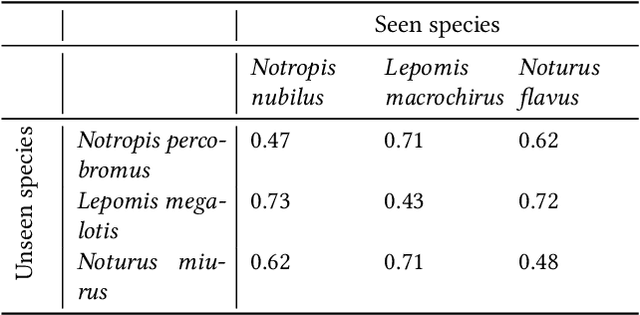
Discovering evolutionary traits that are heritable across species on the tree of life (also referred to as a phylogenetic tree) is of great interest to biologists to understand how organisms diversify and evolve. However, the measurement of traits is often a subjective and labor-intensive process, making trait discovery a highly label-scarce problem. We present a novel approach for discovering evolutionary traits directly from images without relying on trait labels. Our proposed approach, Phylo-NN, encodes the image of an organism into a sequence of quantized feature vectors -- or codes -- where different segments of the sequence capture evolutionary signals at varying ancestry levels in the phylogeny. We demonstrate the effectiveness of our approach in producing biologically meaningful results in a number of downstream tasks including species image generation and species-to-species image translation, using fish species as a target example.
Unsupervised Domain Adaption with Pixel-level Discriminator for Image-aware Layout Generation
Mar 25, 2023

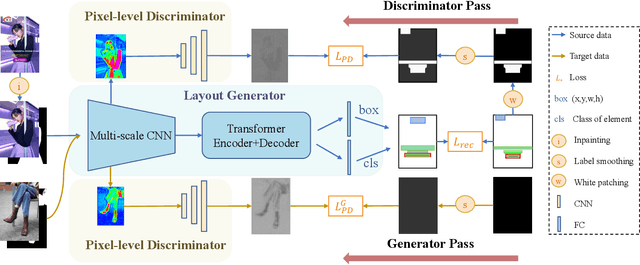

Layout is essential for graphic design and poster generation. Recently, applying deep learning models to generate layouts has attracted increasing attention. This paper focuses on using the GAN-based model conditioned on image contents to generate advertising poster graphic layouts, which requires an advertising poster layout dataset with paired product images and graphic layouts. However, the paired images and layouts in the existing dataset are collected by inpainting and annotating posters, respectively. There exists a domain gap between inpainted posters (source domain data) and clean product images (target domain data). Therefore, this paper combines unsupervised domain adaption techniques to design a GAN with a novel pixel-level discriminator (PD), called PDA-GAN, to generate graphic layouts according to image contents. The PD is connected to the shallow level feature map and computes the GAN loss for each input-image pixel. Both quantitative and qualitative evaluations demonstrate that PDA-GAN can achieve state-of-the-art performances and generate high-quality image-aware graphic layouts for advertising posters.
DiffSketcher: Text Guided Vector Sketch Synthesis through Latent Diffusion Models
Jun 26, 2023
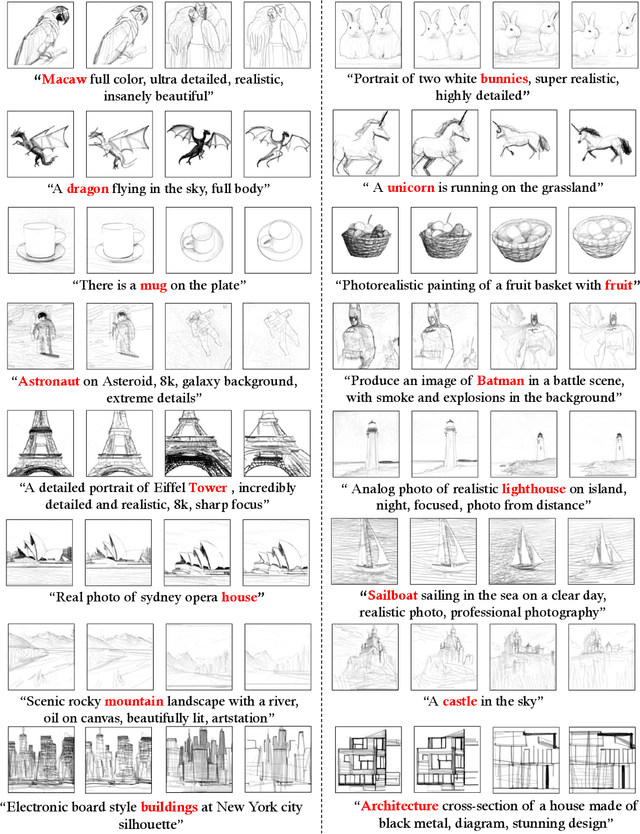
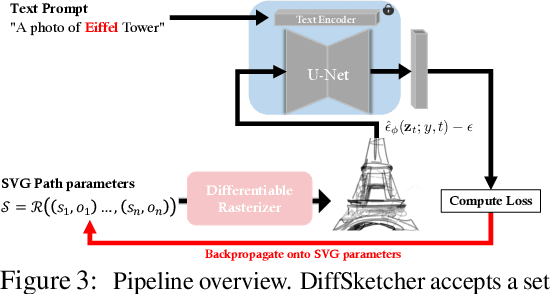
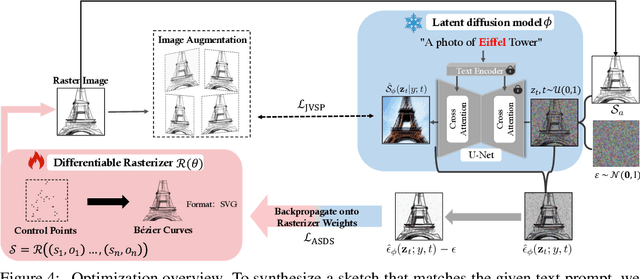
Even though trained mainly on images, we discover that pretrained diffusion models show impressive power in guiding sketch synthesis. In this paper, we present DiffSketcher, an innovative algorithm that creates vectorized free-hand sketches using natural language input. DiffSketcher is developed based on a pre-trained text-to-image diffusion model. It performs the task by directly optimizing a set of Bezier curves with an extended version of the score distillation sampling (SDS) loss, which allows us to use a raster-level diffusion model as a prior for optimizing a parametric vectorized sketch generator. Furthermore, we explore attention maps embedded in the diffusion model for effective stroke initialization to speed up the generation process. The generated sketches demonstrate multiple levels of abstraction while maintaining recognizability, underlying structure, and essential visual details of the subject drawn. Our experiments show that DiffSketcher achieves greater quality than prior work.
Cross-scale Multi-instance Learning for Pathological Image Diagnosis
Apr 01, 2023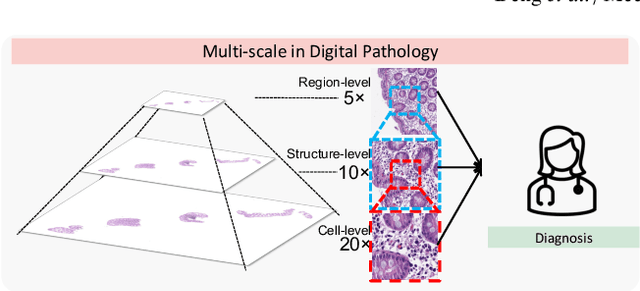
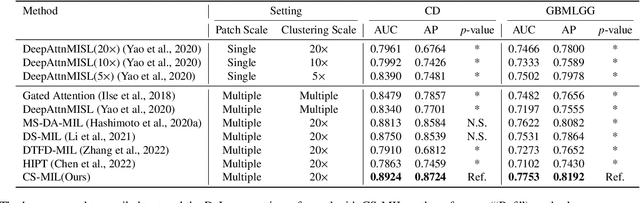
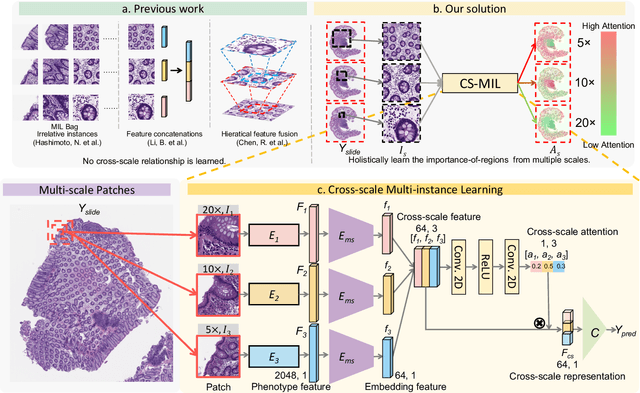

Analyzing high resolution whole slide images (WSIs) with regard to information across multiple scales poses a significant challenge in digital pathology. Multi-instance learning (MIL) is a common solution for working with high resolution images by classifying bags of objects (i.e. sets of smaller image patches). However, such processing is typically performed at a single scale (e.g., 20x magnification) of WSIs, disregarding the vital inter-scale information that is key to diagnoses by human pathologists. In this study, we propose a novel cross-scale MIL algorithm to explicitly aggregate inter-scale relationships into a single MIL network for pathological image diagnosis. The contribution of this paper is three-fold: (1) A novel cross-scale MIL (CS-MIL) algorithm that integrates the multi-scale information and the inter-scale relationships is proposed; (2) A toy dataset with scale-specific morphological features is created and released to examine and visualize differential cross-scale attention; (3) Superior performance on both in-house and public datasets is demonstrated by our simple cross-scale MIL strategy. The official implementation is publicly available at https://github.com/hrlblab/CS-MIL.
Investigating Prompting Techniques for Zero- and Few-Shot Visual Question Answering
Jun 16, 2023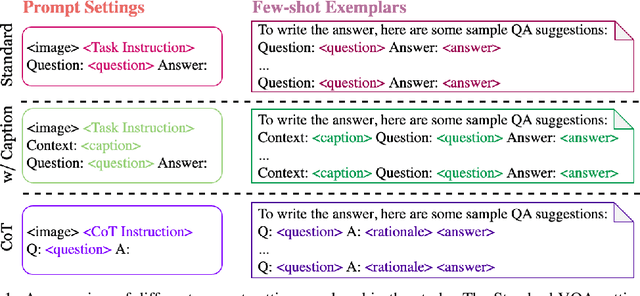
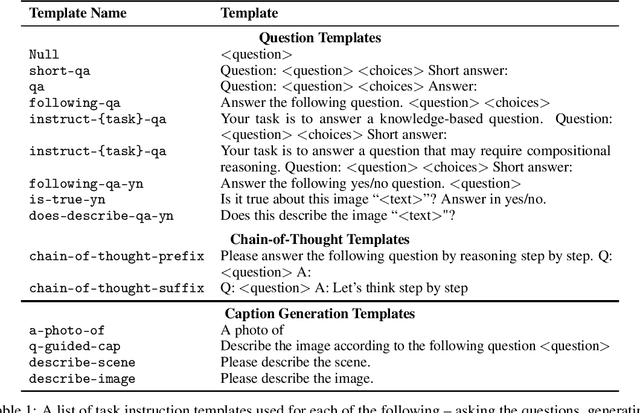
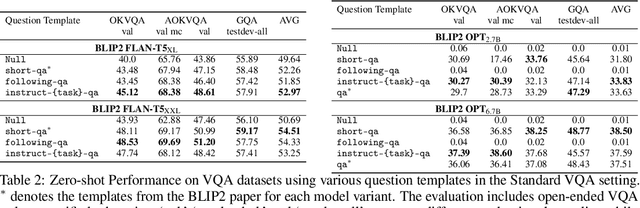

Visual question answering (VQA) is a challenging task that requires the ability to comprehend and reason with visual information. While recent vision-language models have made strides, they continue to struggle with zero-shot VQA, particularly in handling complex compositional questions and adapting to new domains i.e. knowledge-based reasoning. This paper explores the use of various prompting strategies, focusing on the BLIP2 model, to enhance zero-shot VQA performance. We conduct a comprehensive investigation across several VQA datasets, examining the effectiveness of different question templates, the role of few-shot exemplars, the impact of chain-of-thought (CoT) reasoning, and the benefits of incorporating image captions as additional visual cues. Despite the varied outcomes, our findings demonstrate that carefully designed question templates and the integration of additional visual cues, like image captions, can contribute to improved VQA performance, especially when used in conjunction with few-shot examples. However, we also identify a limitation in the use of chain-of-thought rationalization, which negatively affects VQA accuracy. Our study thus provides critical insights into the potential of prompting for improving zero-shot VQA performance.
Reprogramming Audio-driven Talking Face Synthesis into Text-driven
Jun 28, 2023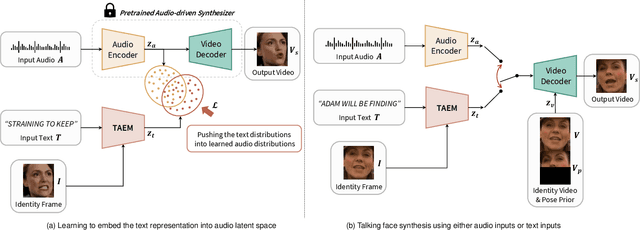
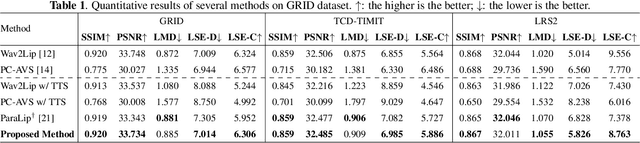
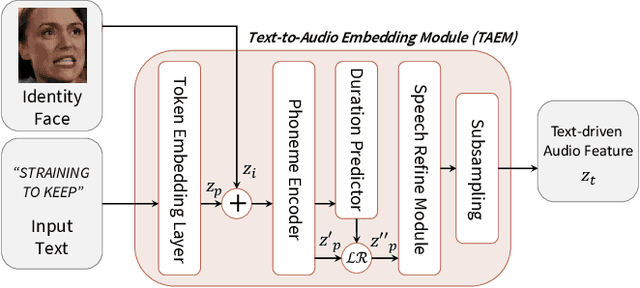
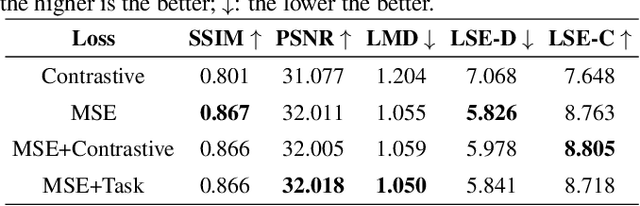
In this paper, we propose a method to reprogram pre-trained audio-driven talking face synthesis models to be able to operate with text inputs. As the audio-driven talking face synthesis model takes speech audio as inputs, in order to generate a talking avatar with the desired speech content, speech recording needs to be performed in advance. However, this is burdensome to record audio for every video to be generated. In order to alleviate this problem, we propose a novel method that embeds input text into the learned audio latent space of the pre-trained audio-driven model. To this end, we design a Text-to-Audio Embedding Module (TAEM) which is guided to learn to map a given text input to the audio latent features. Moreover, to model the speaker characteristics lying in the audio features, we propose to inject visual speaker embedding into the TAEM, which is obtained from a single face image. After training, we can synthesize talking face videos with either text or speech audio.
RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation based on Visual Foundation Model
Jun 28, 2023
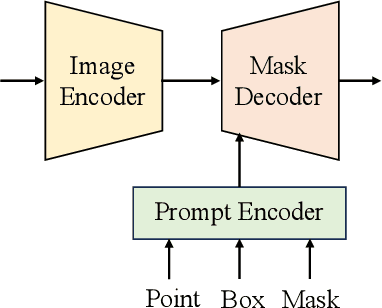
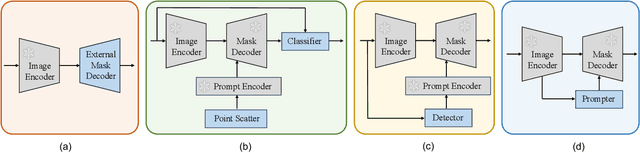
Leveraging vast training data (SA-1B), the foundation Segment Anything Model (SAM) proposed by Meta AI Research exhibits remarkable generalization and zero-shot capabilities. Nonetheless, as a category-agnostic instance segmentation method, SAM heavily depends on prior manual guidance involving points, boxes, and coarse-grained masks. Additionally, its performance on remote sensing image segmentation tasks has yet to be fully explored and demonstrated. In this paper, we consider designing an automated instance segmentation approach for remote sensing images based on the SAM foundation model, incorporating semantic category information. Inspired by prompt learning, we propose a method to learn the generation of appropriate prompts for SAM input. This enables SAM to produce semantically discernible segmentation results for remote sensing images, which we refer to as RSPrompter. We also suggest several ongoing derivatives for instance segmentation tasks, based on recent developments in the SAM community, and compare their performance with RSPrompter. Extensive experimental results on the WHU building, NWPU VHR-10, and SSDD datasets validate the efficacy of our proposed method. Our code is accessible at \url{https://kyanchen.github.io/RSPrompter}.
Incremental Learning on Food Instance Segmentation
Jun 28, 2023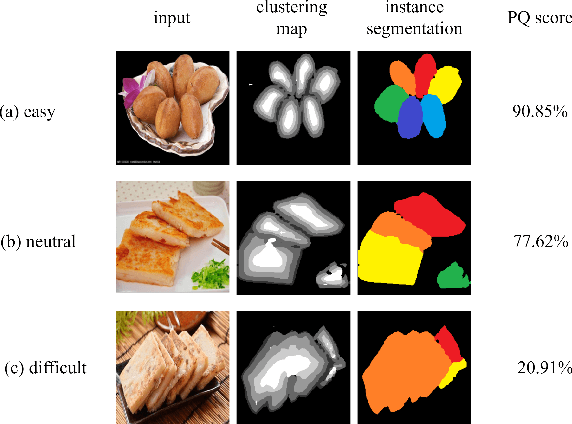
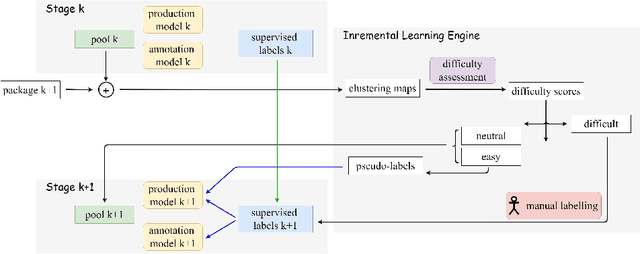

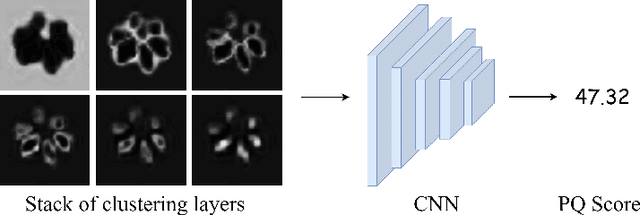
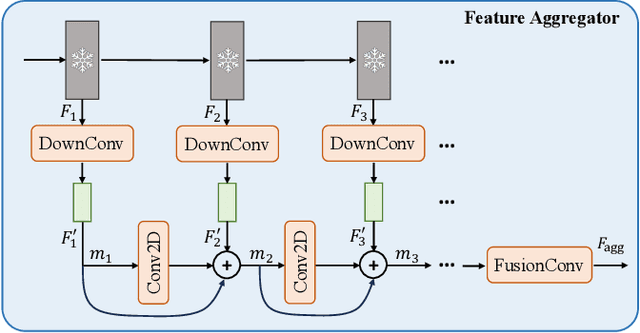
Food instance segmentation is essential to estimate the serving size of dishes in a food image. The recent cutting-edge techniques for instance segmentation are deep learning networks with impressive segmentation quality and fast computation. Nonetheless, they are hungry for data and expensive for annotation. This paper proposes an incremental learning framework to optimize the model performance given a limited data labelling budget. The power of the framework is a novel difficulty assessment model, which forecasts how challenging an unlabelled sample is to the latest trained instance segmentation model. The data collection procedure is divided into several stages, each in which a new sample package is collected. The framework allocates the labelling budget to the most difficult samples. The unlabelled samples that meet a certain qualification from the assessment model are used to generate pseudo-labels. Eventually, the manual labels and pseudo-labels are sent to the training data to improve the instance segmentation model. On four large-scale food datasets, our proposed framework outperforms current incremental learning benchmarks and achieves competitive performance with the model trained on fully annotated samples.
$P+$: Extended Textual Conditioning in Text-to-Image Generation
Mar 16, 2023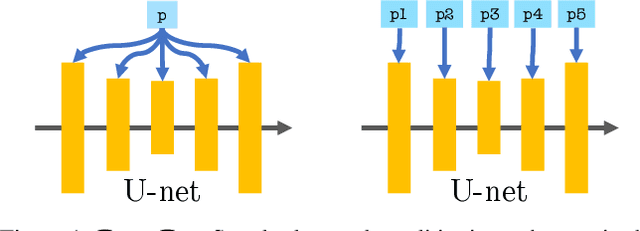



We introduce an Extended Textual Conditioning space in text-to-image models, referred to as $P+$. This space consists of multiple textual conditions, derived from per-layer prompts, each corresponding to a layer of the denoising U-net of the diffusion model. We show that the extended space provides greater disentangling and control over image synthesis. We further introduce Extended Textual Inversion (XTI), where the images are inverted into $P+$, and represented by per-layer tokens. We show that XTI is more expressive and precise, and converges faster than the original Textual Inversion (TI) space. The extended inversion method does not involve any noticeable trade-off between reconstruction and editability and induces more regular inversions. We conduct a series of extensive experiments to analyze and understand the properties of the new space, and to showcase the effectiveness of our method for personalizing text-to-image models. Furthermore, we utilize the unique properties of this space to achieve previously unattainable results in object-style mixing using text-to-image models. Project page: https://prompt-plus.github.io