 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional Transformer for Autonomous Recognition and Grading of Tomatoes Under Various Lighting, Occlusion, and Ripeness Conditions
Jul 04, 2023
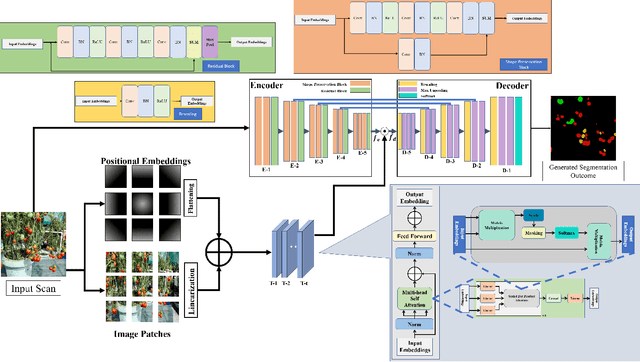


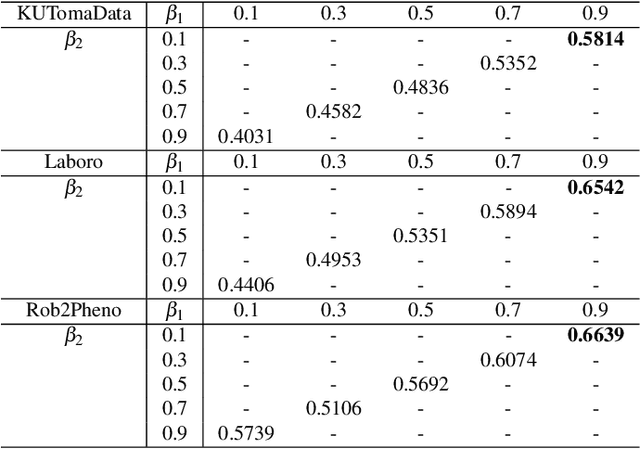
Harvesting fully ripe tomatoes with mobile robots presents significant challenges in real-world scenarios. These challenges arise from factors such as occlusion caused by leaves and branches, as well as the color similarity between tomatoes and the surrounding foliage during the fruit development stage. The natural environment further compounds these issues with varying light conditions, viewing angles, occlusion factors, and different maturity levels. To overcome these obstacles, this research introduces a novel framework that leverages a convolutional transformer architecture to autonomously recognize and grade tomatoes, irrespective of their occlusion level, lighting conditions, and ripeness. The proposed model is trained and tested using carefully annotated images curated specifically for this purpose. The dataset is prepared under various lighting conditions, viewing perspectives, and employs different mobile camera sensors, distinguishing it from existing datasets such as Laboro Tomato and Rob2Pheno Annotated Tomato. The effectiveness of the proposed framework in handling cluttered and occluded tomato instances was evaluated using two additional public datasets, Laboro Tomato and Rob2Pheno Annotated Tomato, as benchmarks. The evaluation results across these three datasets demonstrate the exceptional performance of our proposed framework, surpassing the state-of-the-art by 58.14%, 65.42%, and 66.39% in terms of mean average precision scores for KUTomaData, Laboro Tomato, and Rob2Pheno Annotated Tomato, respectively. The results underscore the superiority of the proposed model in accurately detecting and delineating tomatoes compared to baseline methods and previous approaches. Specifically, the model achieves an F1-score of 80.14%, a Dice coefficient of 73.26%, and a mean IoU of 66.41% on the KUTomaData image dataset.
RRCNN: A novel signal decomposition approach based on recurrent residue convolutional neural network
Jul 04, 2023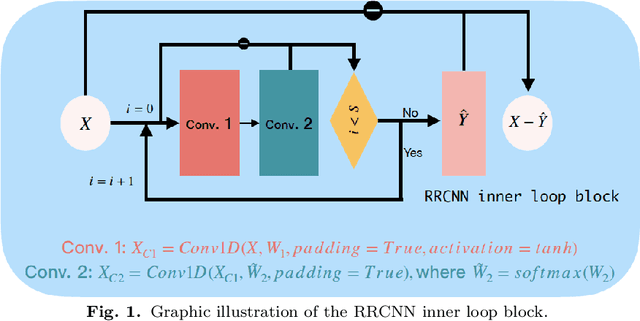
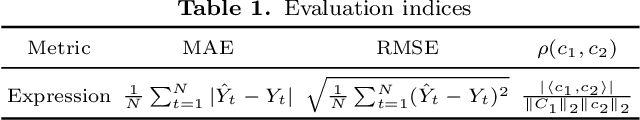
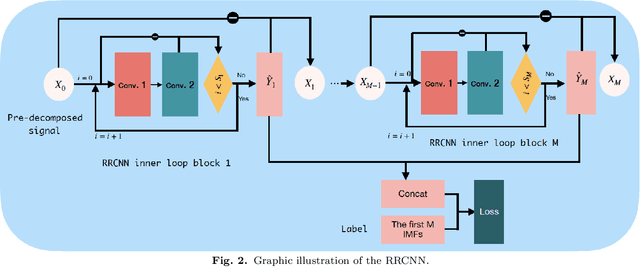

The decomposition of non-stationary signals is an important and challenging task in the field of signal time-frequency analysis. In the recent two decades, many signal decomposition methods led by the empirical mode decomposition, which was pioneered by Huang et al. in 1998, have been proposed by different research groups. However, they still have some limitations. For example, they are generally prone to boundary and mode mixing effects and are not very robust to noise. Inspired by the successful applications of deep learning in fields like image processing and natural language processing, and given the lack in the literature of works in which deep learning techniques are used directly to decompose non-stationary signals into simple oscillatory components, we use the convolutional neural network, residual structure and nonlinear activation function to compute in an innovative way the local average of the signal, and study a new non-stationary signal decomposition method under the framework of deep learning. We discuss the training process of the proposed model and study the convergence analysis of the learning algorithm. In the experiments, we evaluate the performance of the proposed model from two points of view: the calculation of the local average and the signal decomposition. Furthermore, we study the mode mixing, noise interference, and orthogonality properties of the decomposed components produced by the proposed method. All results show that the proposed model allows for better handling boundary effect, mode mixing effect, robustness, and the orthogonality of the decomposed components than existing methods.
Learning Feature Matching via Matchable Keypoint-Assisted Graph Neural Network
Jul 04, 2023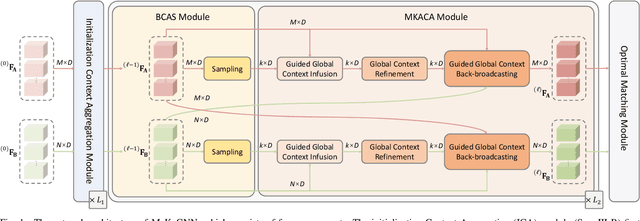
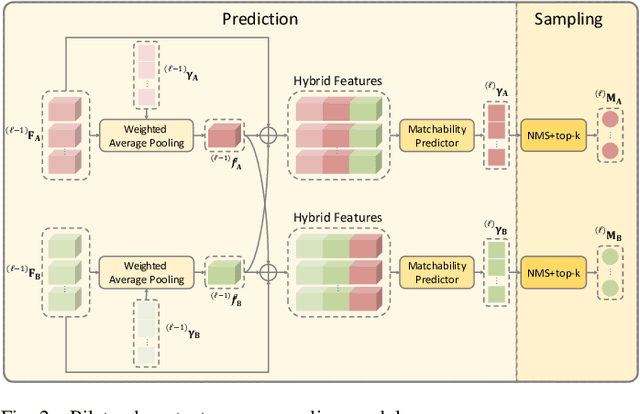
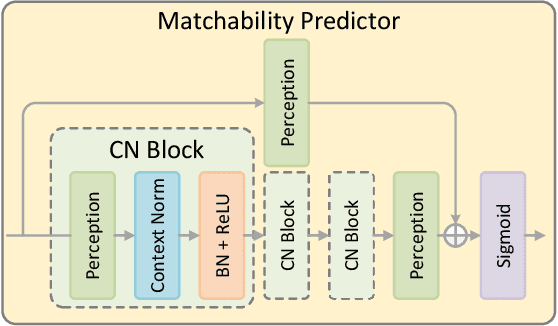
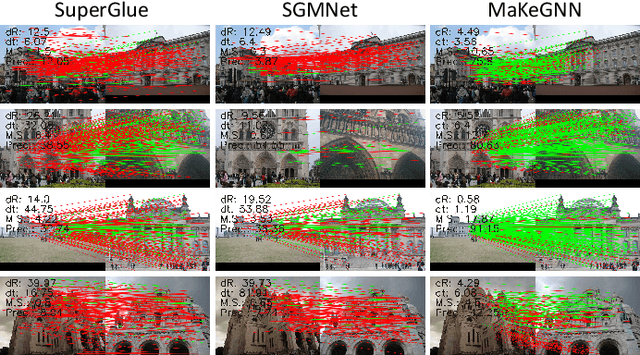
Accurately matching local features between a pair of images is a challenging computer vision task. Previous studies typically use attention based graph neural networks (GNNs) with fully-connected graphs over keypoints within/across images for visual and geometric information reasoning. However, in the context of feature matching, considerable keypoints are non-repeatable due to occlusion and failure of the detector, and thus irrelevant for message passing. The connectivity with non-repeatable keypoints not only introduces redundancy, resulting in limited efficiency, but also interferes with the representation aggregation process, leading to limited accuracy. Targeting towards high accuracy and efficiency, we propose MaKeGNN, a sparse attention-based GNN architecture which bypasses non-repeatable keypoints and leverages matchable ones to guide compact and meaningful message passing. More specifically, our Bilateral Context-Aware Sampling Module first dynamically samples two small sets of well-distributed keypoints with high matchability scores from the image pair. Then, our Matchable Keypoint-Assisted Context Aggregation Module regards sampled informative keypoints as message bottlenecks and thus constrains each keypoint only to retrieve favorable contextual information from intra- and inter- matchable keypoints, evading the interference of irrelevant and redundant connectivity with non-repeatable ones. Furthermore, considering the potential noise in initial keypoints and sampled matchable ones, the MKACA module adopts a matchability-guided attentional aggregation operation for purer data-dependent context propagation. By these means, we achieve the state-of-the-art performance on relative camera estimation, fundamental matrix estimation, and visual localization, while significantly reducing computational and memory complexity compared to typical attentional GNNs.
Human-to-Human Interaction Detection
Jul 02, 2023
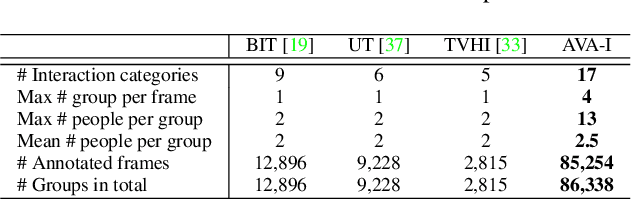
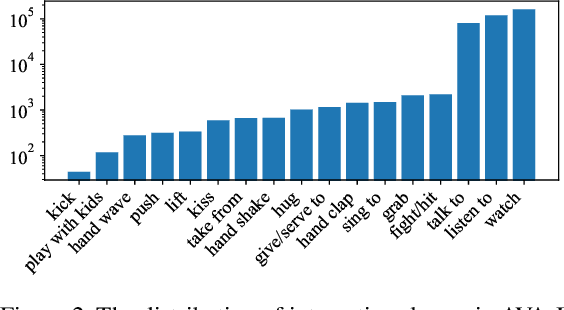
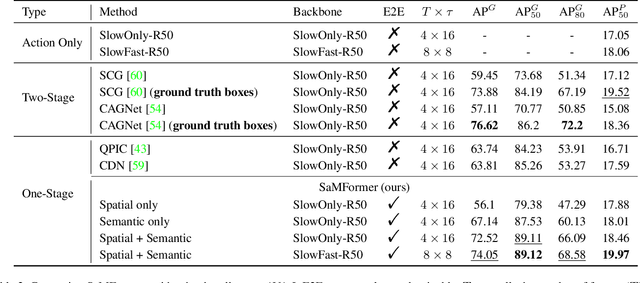
A comprehensive understanding of interested human-to-human interactions in video streams, such as queuing, handshaking, fighting and chasing, is of immense importance to the surveillance of public security in regions like campuses, squares and parks. Different from conventional human interaction recognition, which uses choreographed videos as inputs, neglects concurrent interactive groups, and performs detection and recognition in separate stages, we introduce a new task named human-to-human interaction detection (HID). HID devotes to detecting subjects, recognizing person-wise actions, and grouping people according to their interactive relations, in one model. First, based on the popular AVA dataset created for action detection, we establish a new HID benchmark, termed AVA-Interaction (AVA-I), by adding annotations on interactive relations in a frame-by-frame manner. AVA-I consists of 85,254 frames and 86,338 interactive groups, and each image includes up to 4 concurrent interactive groups. Second, we present a novel baseline approach SaMFormer for HID, containing a visual feature extractor, a split stage which leverages a Transformer-based model to decode action instances and interactive groups, and a merging stage which reconstructs the relationship between instances and groups. All SaMFormer components are jointly trained in an end-to-end manner. Extensive experiments on AVA-I validate the superiority of SaMFormer over representative methods. The dataset and code will be made public to encourage more follow-up studies.
AoM: Detecting Aspect-oriented Information for Multimodal Aspect-Based Sentiment Analysis
May 31, 2023
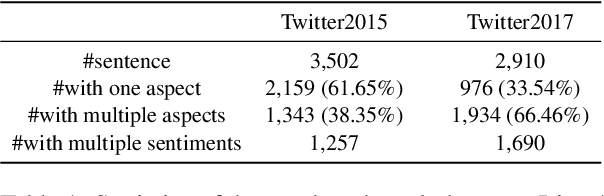
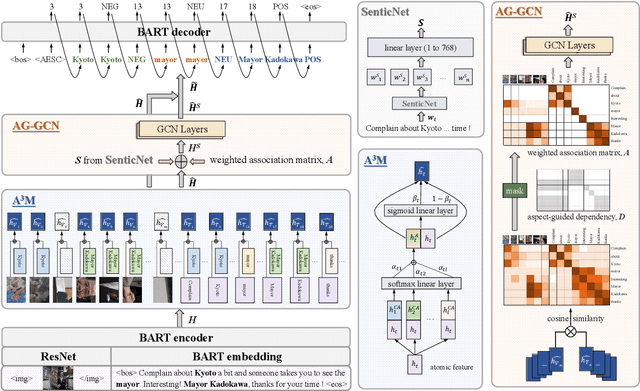
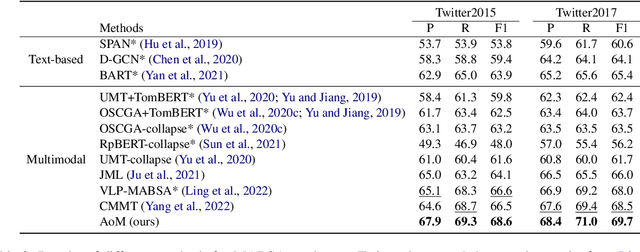
Multimodal aspect-based sentiment analysis (MABSA) aims to extract aspects from text-image pairs and recognize their sentiments. Existing methods make great efforts to align the whole image to corresponding aspects. However, different regions of the image may relate to different aspects in the same sentence, and coarsely establishing image-aspect alignment will introduce noise to aspect-based sentiment analysis (i.e., visual noise). Besides, the sentiment of a specific aspect can also be interfered by descriptions of other aspects (i.e., textual noise). Considering the aforementioned noises, this paper proposes an Aspect-oriented Method (AoM) to detect aspect-relevant semantic and sentiment information. Specifically, an aspect-aware attention module is designed to simultaneously select textual tokens and image blocks that are semantically related to the aspects. To accurately aggregate sentiment information, we explicitly introduce sentiment embedding into AoM, and use a graph convolutional network to model the vision-text and text-text interaction. Extensive experiments demonstrate the superiority of AoM to existing methods. The source code is publicly released at https://github.com/SilyRab/AoM.
Unveiling the Potential of Spike Streams for Foreground Occlusion Removal from Densely Continuous Views
Jul 03, 2023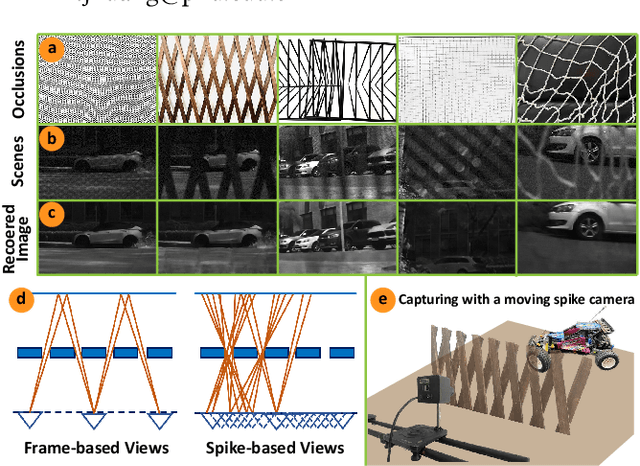
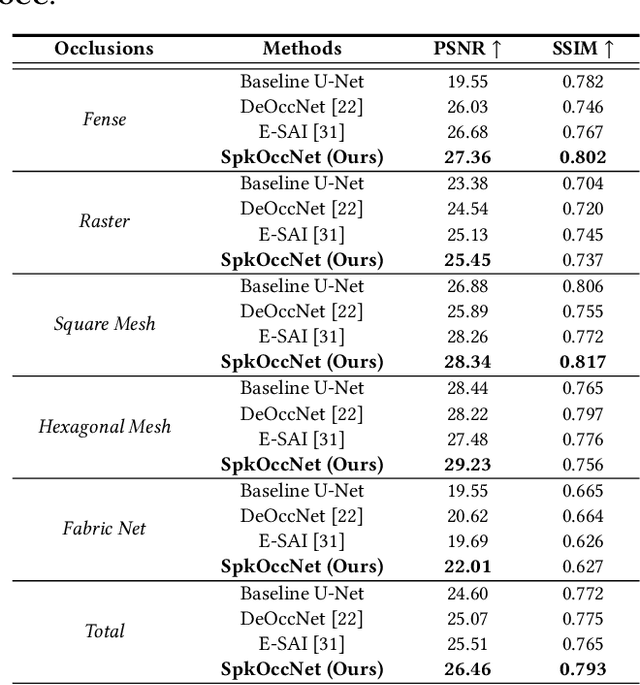
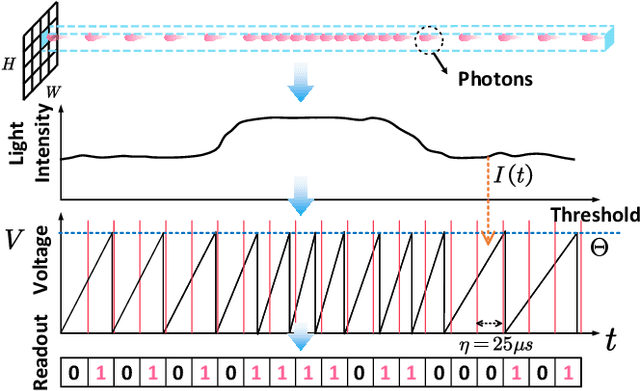
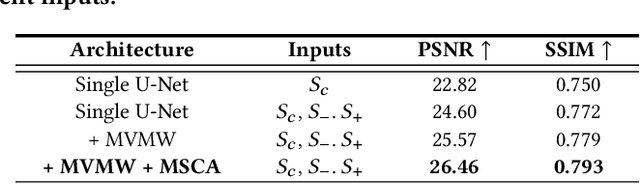
The extraction of a clean background image by removing foreground occlusion holds immense practical significance, but it also presents several challenges. Presently, the majority of de-occlusion research focuses on addressing this issue through the extraction and synthesis of discrete images from calibrated camera arrays. Nonetheless, the restoration quality tends to suffer when faced with dense occlusions or high-speed motions due to limited perspectives and motion blur. To successfully remove dense foreground occlusion, an effective multi-view visual information integration approach is required. Introducing the spike camera as a novel type of neuromorphic sensor offers promising capabilities with its ultra-high temporal resolution and high dynamic range. In this paper, we propose an innovative solution for tackling the de-occlusion problem through continuous multi-view imaging using only one spike camera without any prior knowledge of camera intrinsic parameters and camera poses. By rapidly moving the spike camera, we continually capture the dense stream of spikes from the occluded scene. To process the spikes, we build a novel model \textbf{SpkOccNet}, in which we integrate information of spikes from continuous viewpoints within multi-windows, and propose a novel cross-view mutual attention mechanism for effective fusion and refinement. In addition, we contribute the first real-world spike-based dataset \textbf{S-OCC} for occlusion removal. The experimental results demonstrate that our proposed model efficiently removes dense occlusions in diverse scenes while exhibiting strong generalization.
Self-Supervised Pre-Training for Deep Image Prior-Based Robust PET Image Denoising
Feb 27, 2023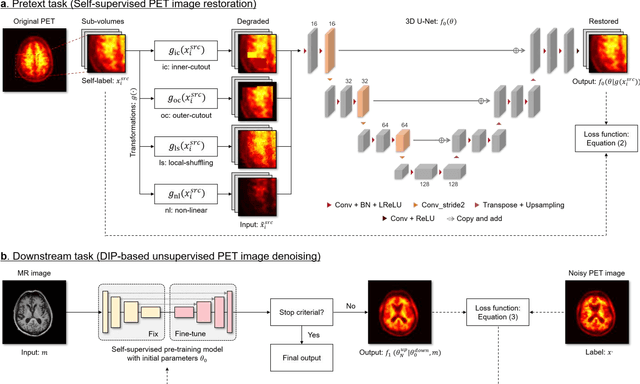
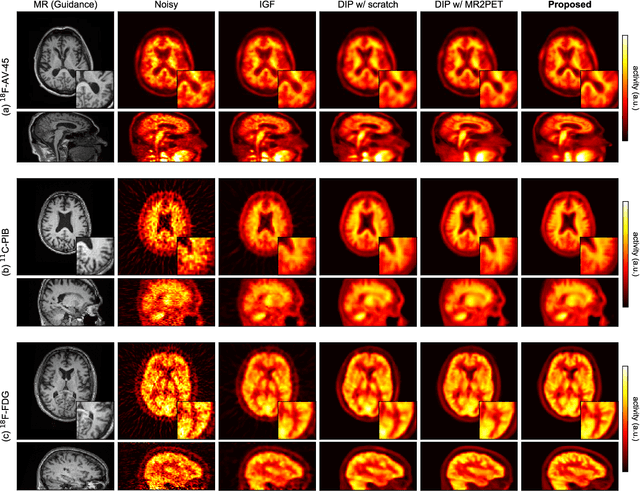
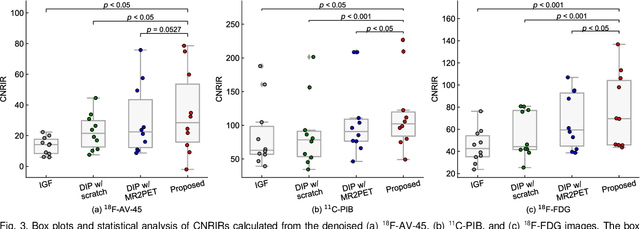

Deep image prior (DIP) has been successfully applied to positron emission tomography (PET) image restoration, enabling represent implicit prior using only convolutional neural network architecture without training dataset, whereas the general supervised approach requires massive low- and high-quality PET image pairs. To answer the increased need for PET imaging with DIP, it is indispensable to improve the performance of the underlying DIP itself. Here, we propose a self-supervised pre-training model to improve the DIP-based PET image denoising performance. Our proposed pre-training model acquires transferable and generalizable visual representations from only unlabeled PET images by restoring various degraded PET images in a self-supervised approach. We evaluated the proposed method using clinical brain PET data with various radioactive tracers ($^{18}$F-florbetapir, $^{11}$C-Pittsburgh compound-B, $^{18}$F-fluoro-2-deoxy-D-glucose, and $^{15}$O-CO$_{2}$) acquired from different PET scanners. The proposed method using the self-supervised pre-training model achieved robust and state-of-the-art denoising performance while retaining spatial details and quantification accuracy compared to other unsupervised methods and pre-training model. These results highlight the potential that the proposed method is particularly effective against rare diseases and probes and helps reduce the scan time or the radiotracer dose without affecting the patients.
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Jun 12, 2023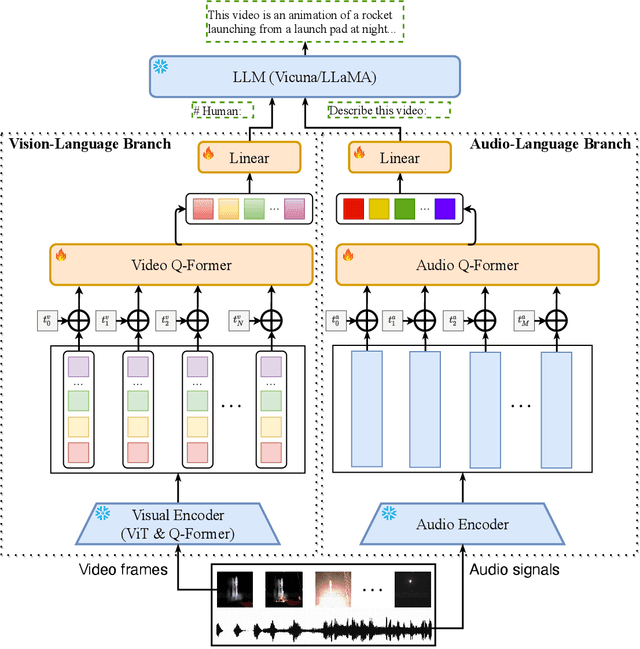
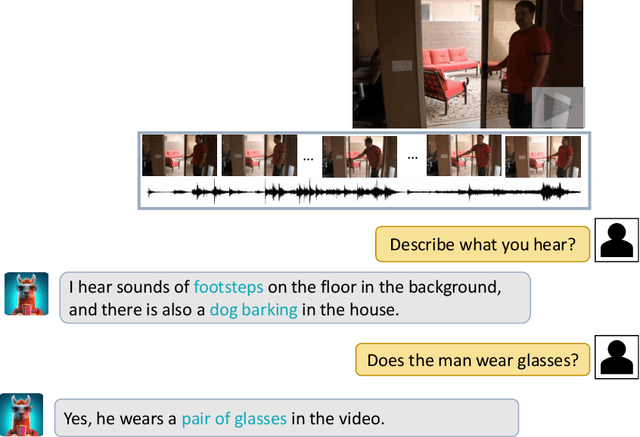
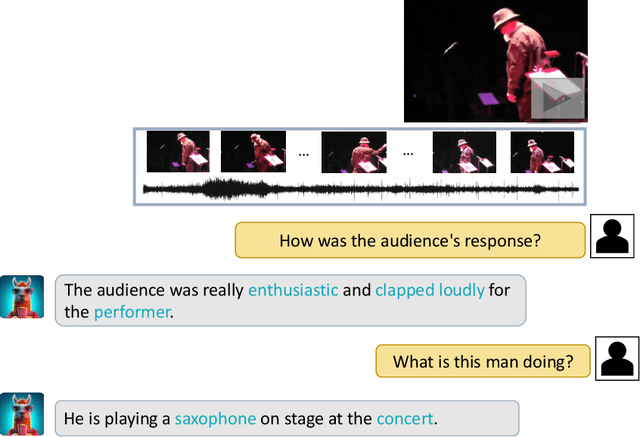
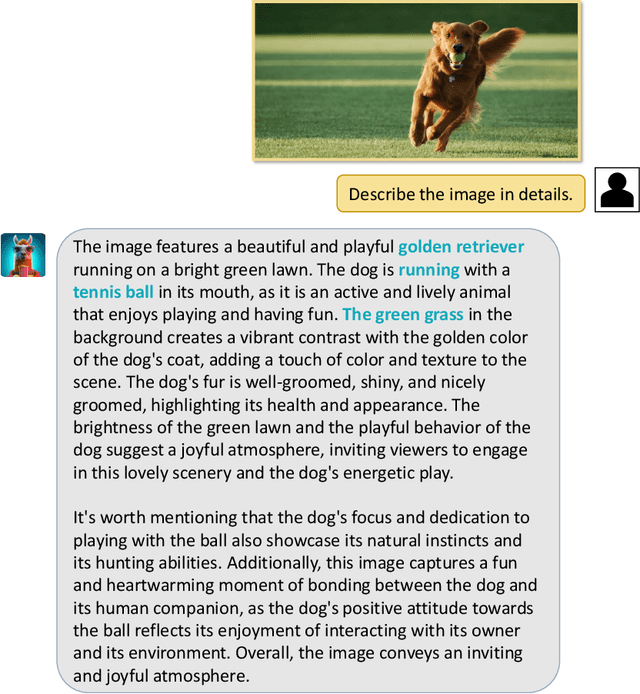
We present Video-LLaMA, a multi-modal framework that empowers Large Language Models (LLMs) with the capability of understanding both visual and auditory content in the video. Video-LLaMA bootstraps cross-modal training from the frozen pre-trained visual & audio encoders and the frozen LLMs. Unlike previous vision-LLMs that focus on static image comprehensions such as MiniGPT-4 and LLaVA, Video-LLaMA mainly tackles two challenges in video understanding: (1) capturing the temporal changes in visual scenes, (2) integrating audio-visual signals. To counter the first challenge, we propose a Video Q-former to assemble the pre-trained image encoder into our video encoder and introduce a video-to-text generation task to learn video-language correspondence. For the second challenge, we leverage ImageBind, a universal embedding model aligning multiple modalities as the pre-trained audio encoder, and introduce an Audio Q-former on top of ImageBind to learn reasonable auditory query embeddings for the LLM module. To align the output of both visual & audio encoders with LLM's embedding space, we train Video-LLaMA on massive video/image-caption pairs as well as visual-instruction-tuning datasets of moderate amount but higher quality. We found Video-LLaMA showcases the ability to perceive and comprehend video content, generating meaningful responses that are grounded in the visual and auditory information presented in the videos. This highlights the potential of Video-LLaMA as a promising prototype for audio-visual AI assistants.
Image Blind Denoising Using Dual Convolutional Neural Network with Skip Connection
Apr 04, 2023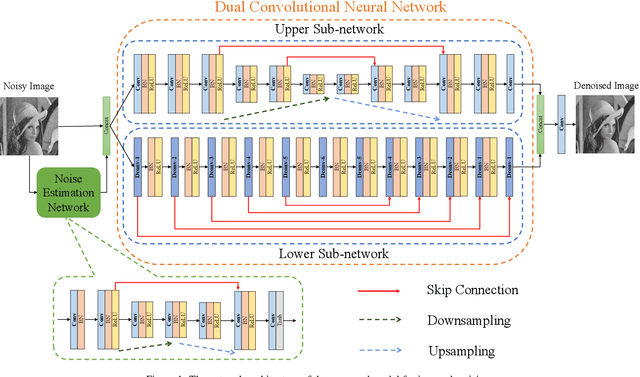

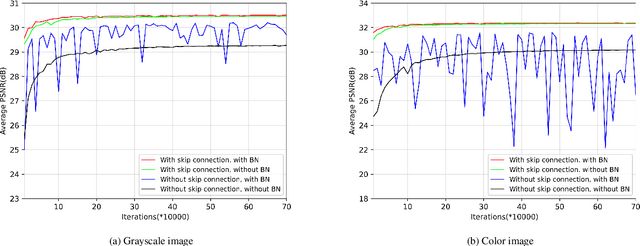
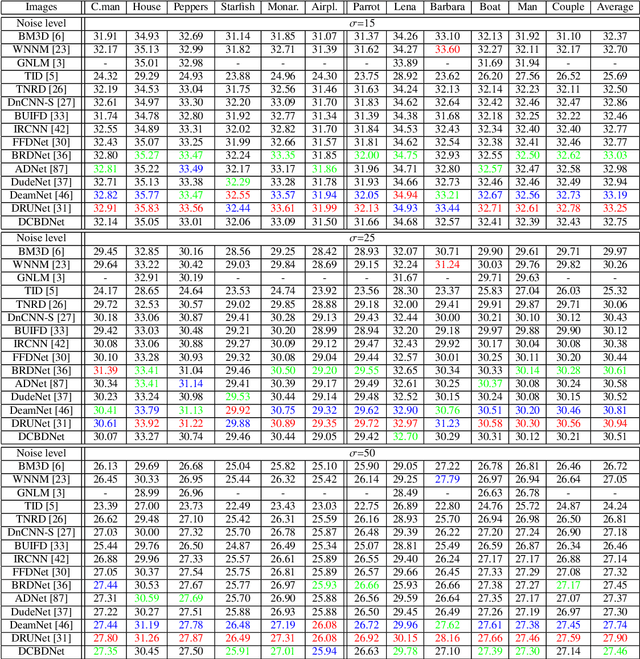
In recent years, deep convolutional neural networks have shown fascinating performance in the field of image denoising. However, deeper network architectures are often accompanied with large numbers of model parameters, leading to high training cost and long inference time, which limits their application in practical denoising tasks. In this paper, we propose a novel dual convolutional blind denoising network with skip connection (DCBDNet), which is able to achieve a desirable balance between the denoising effect and network complexity. The proposed DCBDNet consists of a noise estimation network and a dual convolutional neural network (CNN). The noise estimation network is used to estimate the noise level map, which improves the flexibility of the proposed model. The dual CNN contains two branches: a u-shaped sub-network is designed for the upper branch, and the lower branch is composed of the dilated convolution layers. Skip connections between layers are utilized in both the upper and lower branches. The proposed DCBDNet was evaluated on several synthetic and real-world image denoising benchmark datasets. Experimental results have demonstrated that the proposed DCBDNet can effectively remove gaussian noise in a wide range of levels, spatially variant noise and real noise. With a simple model structure, our proposed DCBDNet still can obtain competitive denoising performance compared to the state-of-the-art image denoising models containing complex architectures. Namely, a favorable trade-off between denoising performance and model complexity is achieved. Codes are available at https://github.com/WenCongWu/DCBDNet.
Scalable 3D Captioning with Pretrained Models
Jun 12, 2023

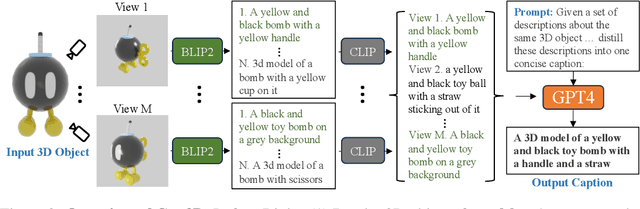
We introduce Cap3D, an automatic approach for generating descriptive text for 3D objects. This approach utilizes pretrained models from image captioning, image-text alignment, and LLM to consolidate captions from multiple views of a 3D asset, completely side-stepping the time-consuming and costly process of manual annotation. We apply Cap3D to the recently introduced large-scale 3D dataset, Objaverse, resulting in 660k 3D-text pairs. Our evaluation, conducted using 41k human annotations from the same dataset, demonstrates that Cap3D surpasses human-authored descriptions in terms of quality, cost, and speed. Through effective prompt engineering, Cap3D rivals human performance in generating geometric descriptions on 17k collected annotations from the ABO dataset. Finally, we finetune Text-to-3D models on Cap3D and human captions, and show Cap3D outperforms; and benchmark the SOTA including Point-E, Shape-E, and DreamFusion.