 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Methods and advancement of content-based fashion image retrieval: A Review
Mar 30, 2023
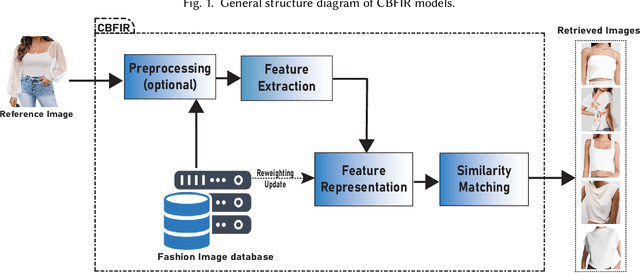
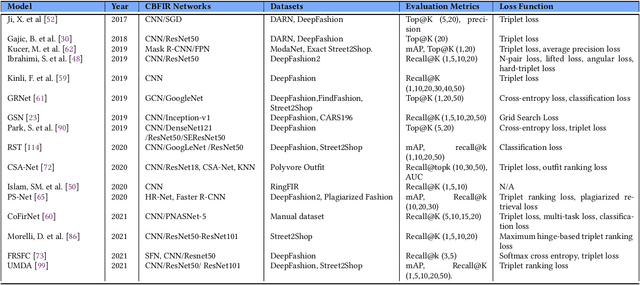

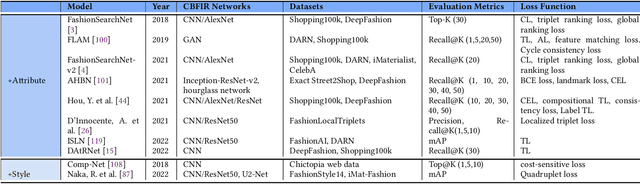
Content-based fashion image retrieval (CBFIR) has been widely used in our daily life for searching fashion images or items from online platforms. In e-commerce purchasing, the CBFIR system can retrieve fashion items or products with the same or comparable features when a consumer uploads a reference image, image with text, sketch or visual stream from their daily life. This lowers the CBFIR system reliance on text and allows for a more accurate and direct searching of the desired fashion product. Considering recent developments, CBFIR still has limits when it comes to visual searching in the real world due to the simultaneous availability of multiple fashion items, occlusion of fashion products, and shape deformation. This paper focuses on CBFIR methods with the guidance of images, images with text, sketches, and videos. Accordingly, we categorized CBFIR methods into four main categories, i.e., image-guided CBFIR (with the addition of attributes and styles), image and text-guided, sketch-guided, and video-guided CBFIR methods. The baseline methodologies have been thoroughly analyzed, and the most recent developments in CBFIR over the past six years (2017 to 2022) have been thoroughly examined. Finally, key issues are highlighted for CBFIR with promising directions for future research.
ClothFit: Cloth-Human-Attribute Guided Virtual Try-On Network Using 3D Simulated Dataset
Jun 24, 2023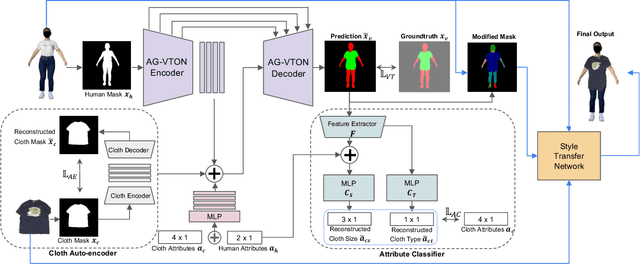
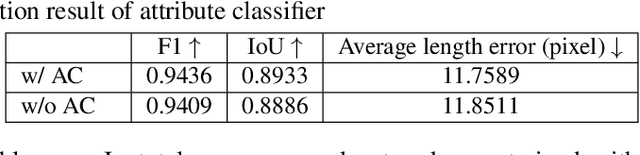
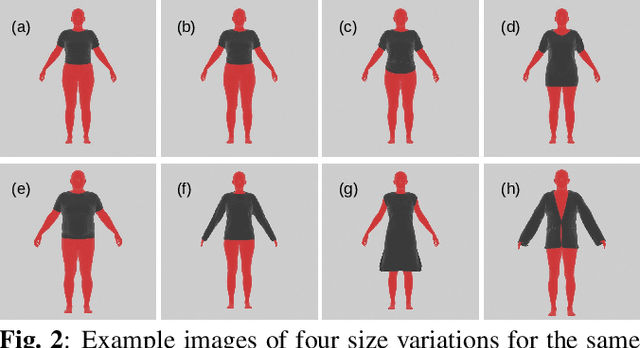

Online clothing shopping has become increasingly popular, but the high rate of returns due to size and fit issues has remained a major challenge. To address this problem, virtual try-on systems have been developed to provide customers with a more realistic and personalized way to try on clothing. In this paper, we propose a novel virtual try-on method called ClothFit, which can predict the draping shape of a garment on a target body based on the actual size of the garment and human attributes. Unlike existing try-on models, ClothFit considers the actual body proportions of the person and available cloth sizes for clothing virtualization, making it more appropriate for current online apparel outlets. The proposed method utilizes a U-Net-based network architecture that incorporates cloth and human attributes to guide the realistic virtual try-on synthesis. Specifically, we extract features from a cloth image using an auto-encoder and combine them with features from the user's height, weight, and cloth size. The features are concatenated with the features from the U-Net encoder, and the U-Net decoder synthesizes the final virtual try-on image. Our experimental results demonstrate that ClothFit can significantly improve the existing state-of-the-art methods in terms of photo-realistic virtual try-on results.
Evidence-based Hand Hygiene. Can You Trust the Fluorescent-based Assessment Methods?
Jul 11, 2023Healthcare-Associated Infections present a major threat to patient safety globally. According to studies, more than 50% of HAI could be prevented by proper hand hygiene. Effectiveness of hand hygiene is regularly evaluated with the fluorescent method: performing hand hygiene with a handrub containing an ultra violet (UV) fluorescent marker. Typically, human experts evaluate the hands under UV-A light, and decide whether the applied handrub covered the whole hand surface. The aim of this study was to investigate how different experts judge the same UV-pattern, and compare that to microbiology for objective validation. Hands of volunteer participants were contaminated with high concentration of a Staphylococcus epidermidis suspension. Hands were incompletely disinfected with UV-labeled handrub. Four different UV-box type devices were used to take CCD pictures of the hands under UV light. Size of inadequately disinfected areas on the hands were determined in two different ways. First, based on microbiology; the areas where colonies were grown were measured. Second, four independent senior infection control specialists were asked to mark the missed areas on printed image, captured under UV light. 8 hands of healthy volunteers were examined. Expert evaluations were highly uncorrelated (regarding interrater reliability) and inconsistent. Microbiology results weakly correlated with the expert evaluations. In half of the cases, there were more than 10% difference in the size of properly disinfected area, as measured by microbiology versus human experts. Considering the result of the expert evaluations, variability was disconcertingly high. Evaluating the fluorescent method is challenging, even for highly experienced professionals. A patient safety quality assurance system cannot be built on these data quality.
Picking Up Quantization Steps for Compressed Image Classification
Apr 21, 2023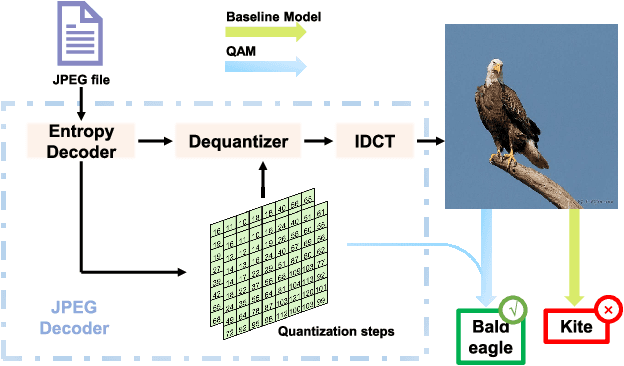
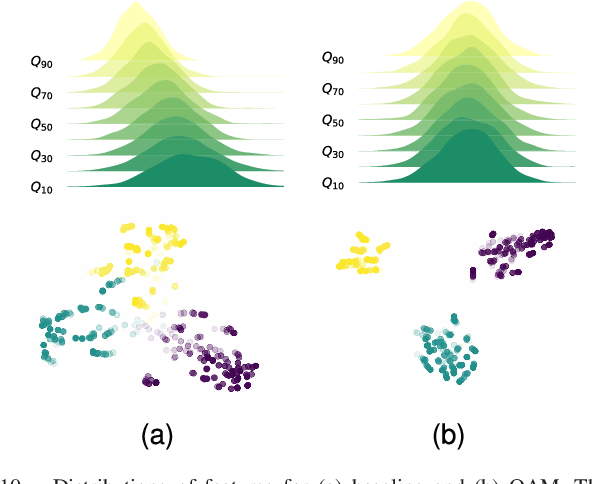
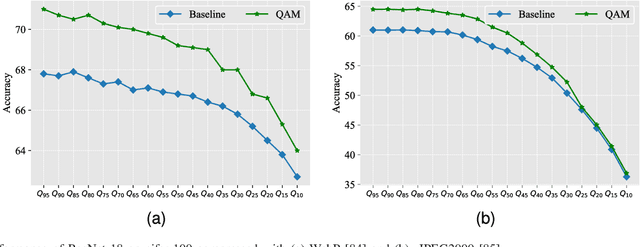
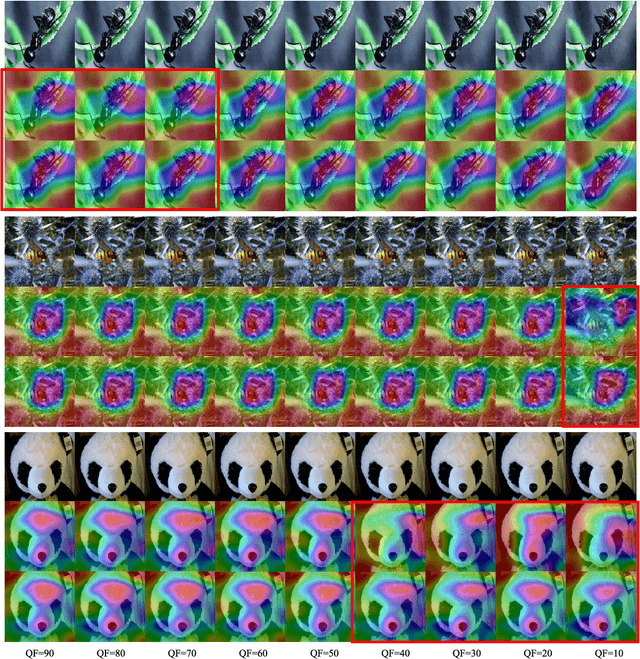
The sensitivity of deep neural networks to compressed images hinders their usage in many real applications, which means classification networks may fail just after taking a screenshot and saving it as a compressed file. In this paper, we argue that neglected disposable coding parameters stored in compressed files could be picked up to reduce the sensitivity of deep neural networks to compressed images. Specifically, we resort to using one of the representative parameters, quantization steps, to facilitate image classification. Firstly, based on quantization steps, we propose a novel quantization aware confidence (QAC), which is utilized as sample weights to reduce the influence of quantization on network training. Secondly, we utilize quantization steps to alleviate the variance of feature distributions, where a quantization aware batch normalization (QABN) is proposed to replace batch normalization of classification networks. Extensive experiments show that the proposed method significantly improves the performance of classification networks on CIFAR-10, CIFAR-100, and ImageNet. The code is released on https://github.com/LiMaPKU/QSAM.git
MoViT: Memorizing Vision Transformers for Medical Image Analysis
Mar 27, 2023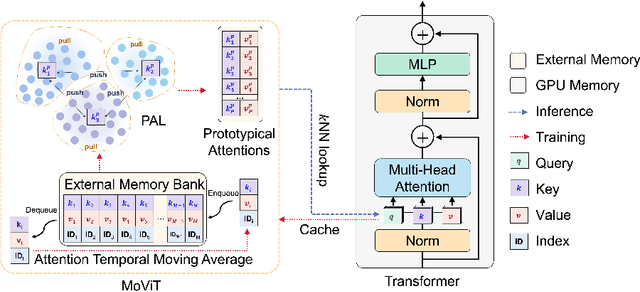
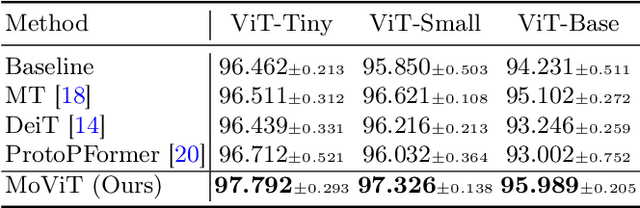
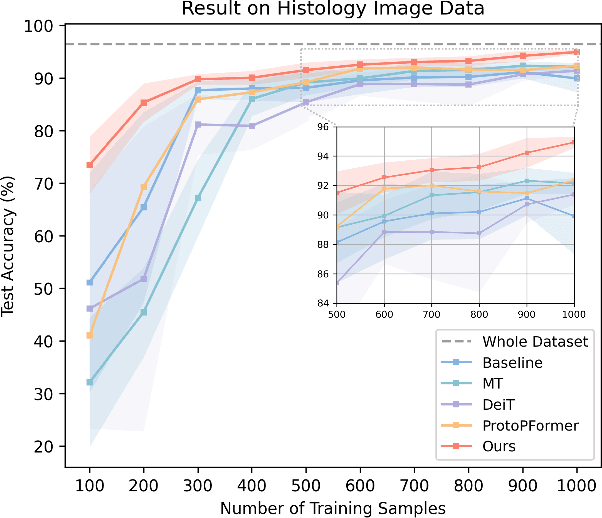
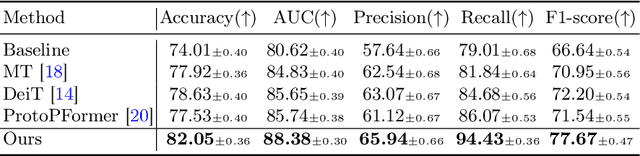
The synergy of long-range dependencies from transformers and local representations of image content from convolutional neural networks (CNNs) has led to advanced architectures and increased performance for various medical image analysis tasks due to their complementary benefits. However, compared with CNNs, transformers require considerably more training data, due to a larger number of parameters and an absence of inductive bias. The need for increasingly large datasets continues to be problematic, particularly in the context of medical imaging, where both annotation efforts and data protection result in limited data availability. In this work, inspired by the human decision-making process of correlating new ``evidence'' with previously memorized ``experience'', we propose a Memorizing Vision Transformer (MoViT) to alleviate the need for large-scale datasets to successfully train and deploy transformer-based architectures. MoViT leverages an external memory structure to cache history attention snapshots during the training stage. To prevent overfitting, we incorporate an innovative memory update scheme, attention temporal moving average, to update the stored external memories with the historical moving average. For inference speedup, we design a prototypical attention learning method to distill the external memory into smaller representative subsets. We evaluate our method on a public histology image dataset and an in-house MRI dataset, demonstrating that MoViT applied to varied medical image analysis tasks, can outperform vanilla transformer models across varied data regimes, especially in cases where only a small amount of annotated data is available. More importantly, MoViT can reach a competitive performance of ViT with only 3.0% of the training data.
Detecting the Sensing Area of A Laparoscopic Probe in Minimally Invasive Cancer Surgery
Jul 07, 2023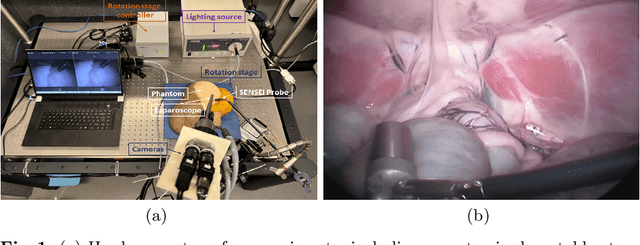
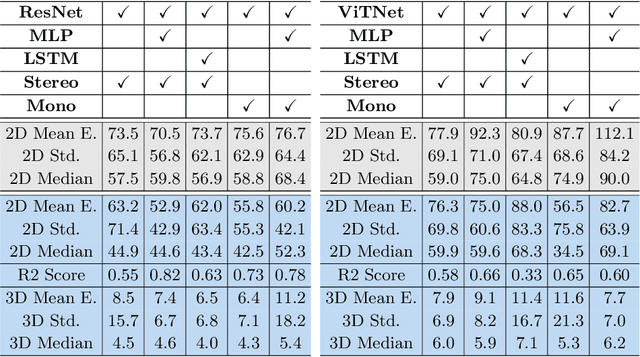


In surgical oncology, it is challenging for surgeons to identify lymph nodes and completely resect cancer even with pre-operative imaging systems like PET and CT, because of the lack of reliable intraoperative visualization tools. Endoscopic radio-guided cancer detection and resection has recently been evaluated whereby a novel tethered laparoscopic gamma detector is used to localize a preoperatively injected radiotracer. This can both enhance the endoscopic imaging and complement preoperative nuclear imaging data. However, gamma activity visualization is challenging to present to the operator because the probe is non-imaging and it does not visibly indicate the activity origination on the tissue surface. Initial failed attempts used segmentation or geometric methods, but led to the discovery that it could be resolved by leveraging high-dimensional image features and probe position information. To demonstrate the effectiveness of this solution, we designed and implemented a simple regression network that successfully addressed the problem. To further validate the proposed solution, we acquired and publicly released two datasets captured using a custom-designed, portable stereo laparoscope system. Through intensive experimentation, we demonstrated that our method can successfully and effectively detect the sensing area, establishing a new performance benchmark. Code and data are available at https://github.com/br0202/Sensing_area_detection.git
Generalization Across Experimental Parameters in Machine Learning Analysis of High Resolution Transmission Electron Microscopy Datasets
Jun 20, 2023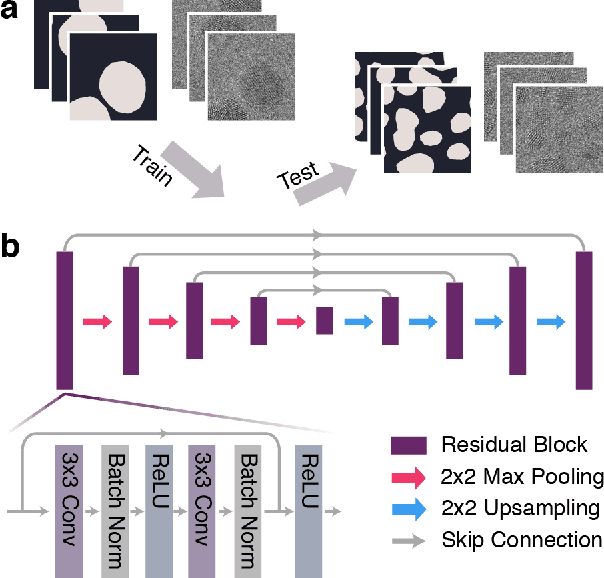
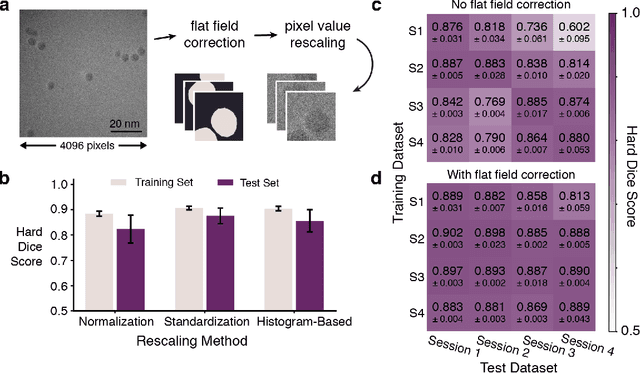
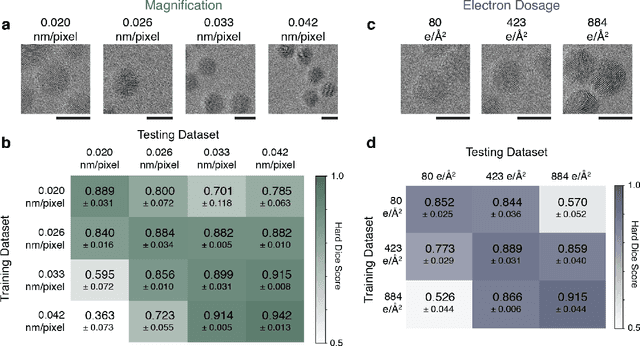
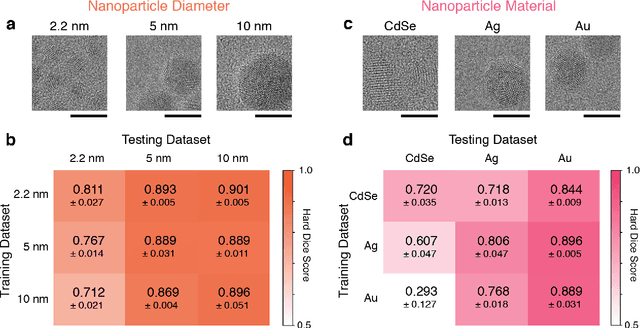
Neural networks are promising tools for high-throughput and accurate transmission electron microscopy (TEM) analysis of nanomaterials, but are known to generalize poorly on data that is "out-of-distribution" from their training data. Given the limited set of image features typically seen in high-resolution TEM imaging, it is unclear which images are considered out-of-distribution from others. Here, we investigate how the choice of metadata features in the training dataset influences neural network performance, focusing on the example task of nanoparticle segmentation. We train and validate neural networks across curated, experimentally-collected high-resolution TEM image datasets of nanoparticles under controlled imaging and material parameters, including magnification, dosage, nanoparticle diameter, and nanoparticle material. Overall, we find that our neural networks are not robust across microscope parameters, but do generalize across certain sample parameters. Additionally, data preprocessing heavily influences the generalizability of neural networks trained on nominally similar datasets. Our results highlight the need to understand how dataset features affect deployment of data-driven algorithms.
A primal-dual data-driven method for computational optical imaging with a photonic lantern
Jun 20, 2023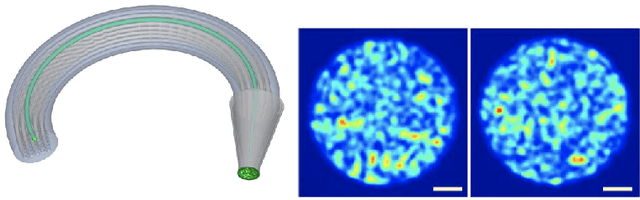

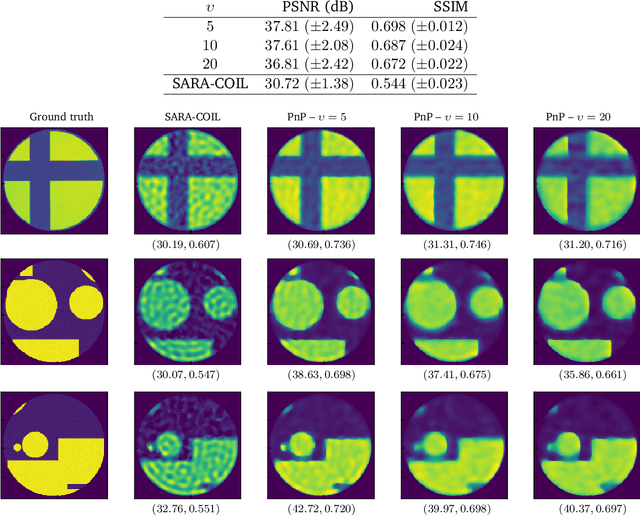

Optical fibres aim to image in-vivo biological processes. In this context, high spatial resolution and stability to fibre movements are key to enable decision-making processes (e.g., for microendoscopy). Recently, a single-pixel imaging technique based on a multicore fibre photonic lantern has been designed, named computational optical imaging using a lantern (COIL). A proximal algorithm based on a sparsity prior, dubbed SARA-COIL, has been further proposed to enable image reconstructions for high resolution COIL microendoscopy. In this work, we develop a data-driven approach for COIL. We replace the sparsity prior in the proximal algorithm by a learned denoiser, leading to a plug-and-play (PnP) algorithm. We use recent results in learning theory to train a network with desirable Lipschitz properties. We show that the resulting primal-dual PnP algorithm converges to a solution to a monotone inclusion problem. Our simulations highlight that the proposed data-driven approach improves the reconstruction quality over variational SARA-COIL method on both simulated and real data.
Joint Salient Object Detection and Camouflaged Object Detection via Uncertainty-aware Learning
Jul 10, 2023
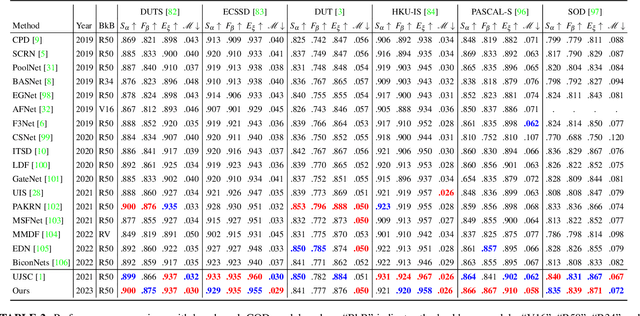

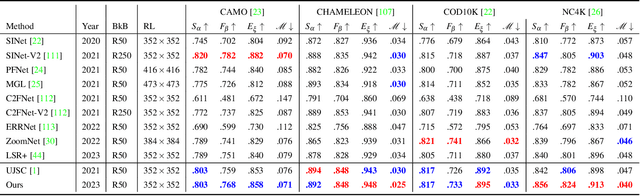
Salient objects attract human attention and usually stand out clearly from their surroundings. In contrast, camouflaged objects share similar colors or textures with the environment. In this case, salient objects are typically non-camouflaged, and camouflaged objects are usually not salient. Due to this inherent contradictory attribute, we introduce an uncertainty-aware learning pipeline to extensively explore the contradictory information of salient object detection (SOD) and camouflaged object detection (COD) via data-level and task-wise contradiction modeling. We first exploit the dataset correlation of these two tasks and claim that the easy samples in the COD dataset can serve as hard samples for SOD to improve the robustness of the SOD model. Based on the assumption that these two models should lead to activation maps highlighting different regions of the same input image, we further introduce a contrastive module with a joint-task contrastive learning framework to explicitly model the contradictory attributes of these two tasks. Different from conventional intra-task contrastive learning for unsupervised representation learning, our contrastive module is designed to model the task-wise correlation, leading to cross-task representation learning. To better understand the two tasks from the perspective of uncertainty, we extensively investigate the uncertainty estimation techniques for modeling the main uncertainties of the two tasks, namely task uncertainty (for SOD) and data uncertainty (for COD), and aiming to effectively estimate the challenging regions for each task to achieve difficulty-aware learning. Experimental results on benchmark datasets demonstrate that our solution leads to both state-of-the-art performance and informative uncertainty estimation.
Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement
Apr 14, 2023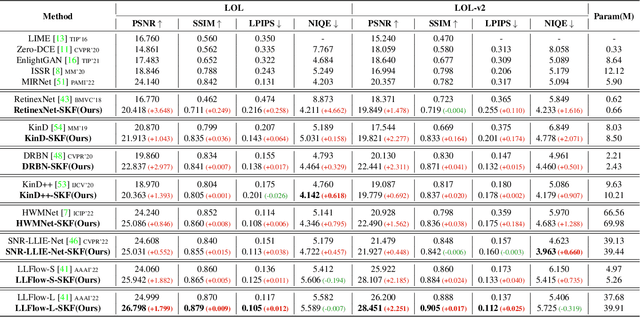
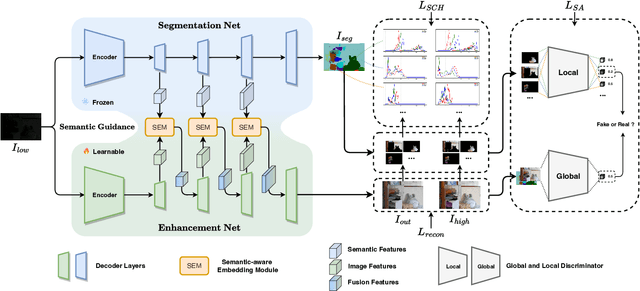
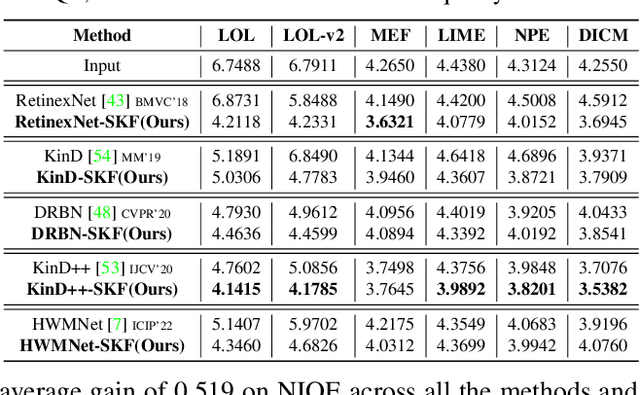
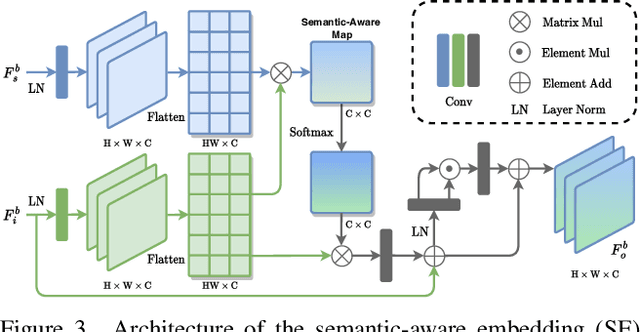
Low-light image enhancement (LLIE) investigates how to improve illumination and produce normal-light images. The majority of existing methods improve low-light images via a global and uniform manner, without taking into account the semantic information of different regions. Without semantic priors, a network may easily deviate from a region's original color. To address this issue, we propose a novel semantic-aware knowledge-guided framework (SKF) that can assist a low-light enhancement model in learning rich and diverse priors encapsulated in a semantic segmentation model. We concentrate on incorporating semantic knowledge from three key aspects: a semantic-aware embedding module that wisely integrates semantic priors in feature representation space, a semantic-guided color histogram loss that preserves color consistency of various instances, and a semantic-guided adversarial loss that produces more natural textures by semantic priors. Our SKF is appealing in acting as a general framework in LLIE task. Extensive experiments show that models equipped with the SKF significantly outperform the baselines on multiple datasets and our SKF generalizes to different models and scenes well. The code is available at Semantic-Aware-Low-Light-Image-Enhancement.