 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Review of Large Vision Models and Visual Prompt Engineering
Jul 03, 2023
Visual prompt engineering is a fundamental technology in the field of visual and image Artificial General Intelligence, serving as a key component for achieving zero-shot capabilities. As the development of large vision models progresses, the importance of prompt engineering becomes increasingly evident. Designing suitable prompts for specific visual tasks has emerged as a meaningful research direction. This review aims to summarize the methods employed in the computer vision domain for large vision models and visual prompt engineering, exploring the latest advancements in visual prompt engineering. We present influential large models in the visual domain and a range of prompt engineering methods employed on these models. It is our hope that this review provides a comprehensive and systematic description of prompt engineering methods based on large visual models, offering valuable insights for future researchers in their exploration of this field.
SAMAug: Point Prompt Augmentation for Segment Anything Model
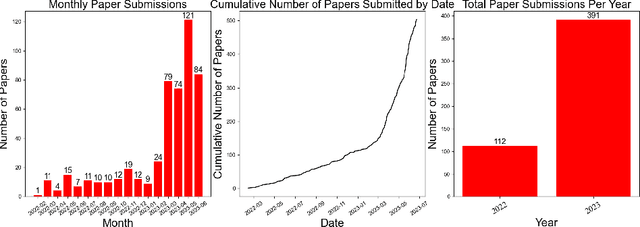
Jul 03, 2023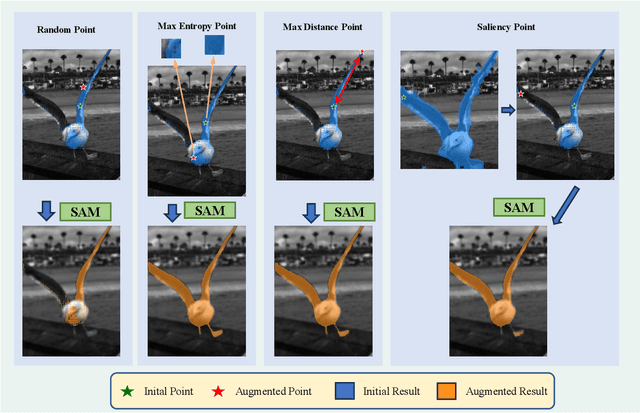
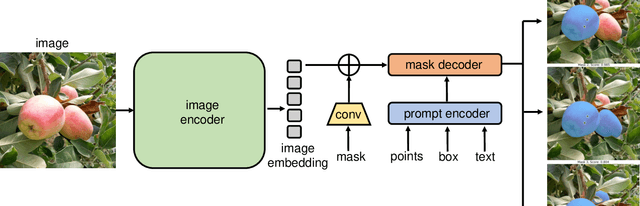

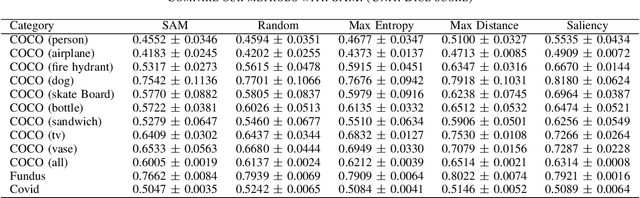
This paper introduces SAMAug, a novel visual point augmentation method for the Segment Anything Model (SAM) that enhances interactive image segmentation performance. SAMAug generates augmented point prompts to provide more information to SAM. From the initial point prompt, SAM produces the initial mask, which is then fed into our proposed SAMAug to generate augmented point prompts. By incorporating these extra points, SAM can generate augmented segmentation masks based on the augmented point prompts and the initial prompt, resulting in improved segmentation performance. We evaluate four point augmentation techniques: random selection, maximum difference entropy, maximum distance, and a saliency model. Experiments on the COCO, Fundus, and Chest X-ray datasets demonstrate that SAMAug can boost SAM's segmentation results, especially using the maximum distance and saliency model methods. SAMAug underscores the potential of visual prompt engineering to advance interactive computer vision models.
Creating Realistic Anterior Segment Optical Coherence Tomography Images using Generative Adversarial Networks
Jun 24, 2023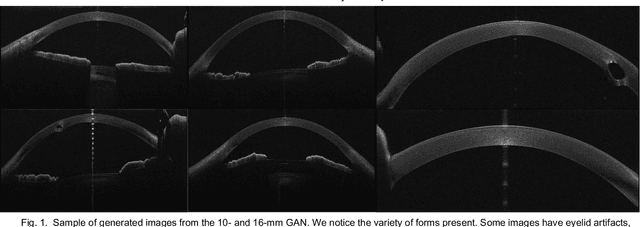

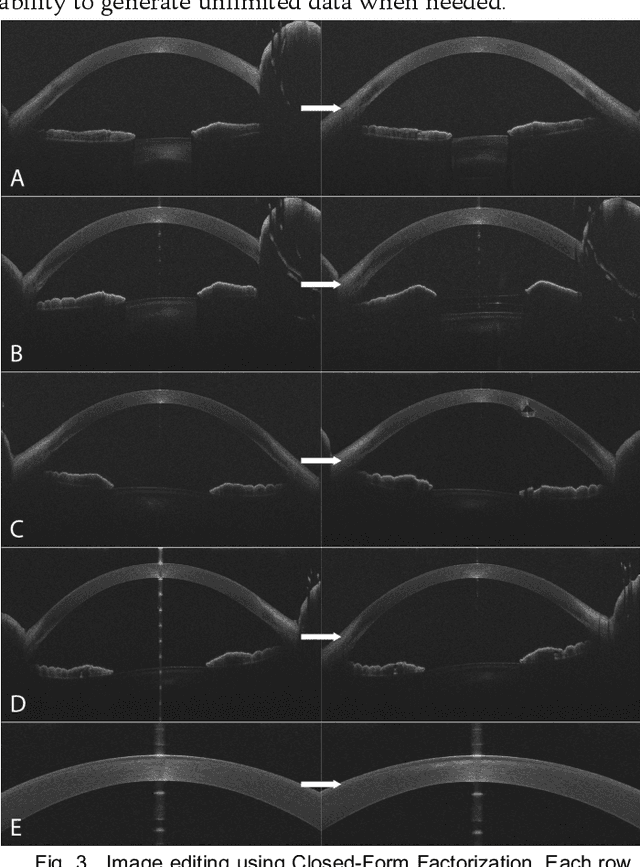
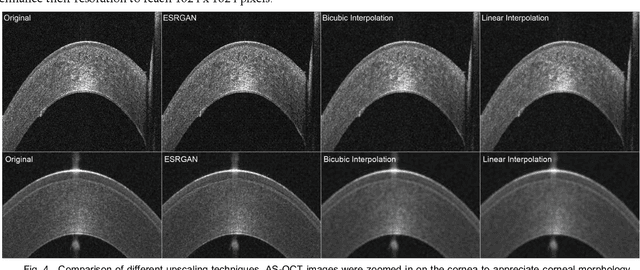
This paper presents the development and validation of a Generative Adversarial Network (GAN) purposed to create high-resolution, realistic Anterior Segment Optical Coherence Tomography (AS-OCT) images. We trained the Style and WAvelet based GAN (SWAGAN) on 142,628 AS-OCT B-scans. Three experienced refractive surgeons performed a blinded assessment to evaluate the realism of the generated images; their results were not significantly better than chance in distinguishing between real and synthetic images, thus demonstrating a high degree of image realism. To gauge their suitability for machine learning tasks, a convolutional neural network (CNN) classifier was trained with a dataset containing both real and GAN-generated images. The CNN demonstrated an accuracy rate of 78% trained on real images alone, but this accuracy rose to 100% when training included the generated images. This underscores the utility of synthetic images for machine learning applications. We further improved the resolution of the generated images by up-sampling them twice (2x) using an Enhanced Super Resolution GAN (ESRGAN), which outperformed traditional up-sampling techniques. In conclusion, GANs can effectively generate high-definition, realistic AS-OCT images, proving highly beneficial for machine learning and image analysis tasks.
TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering
Mar 28, 2023
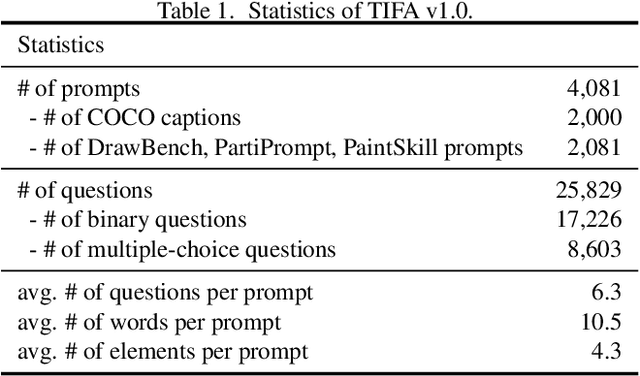
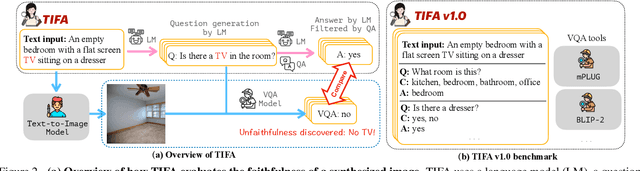
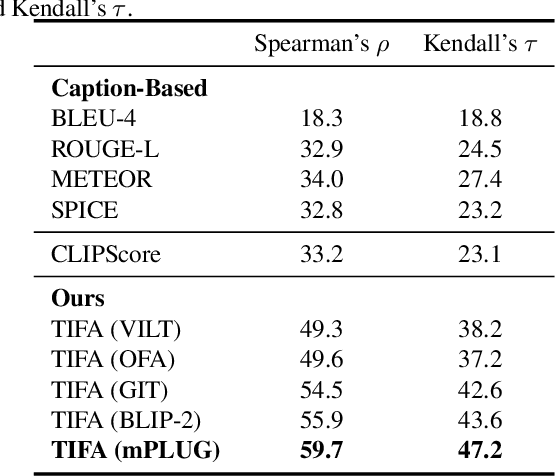
Despite thousands of researchers, engineers, and artists actively working on improving text-to-image generation models, systems often fail to produce images that accurately align with the text inputs. We introduce TIFA (Text-to-Image Faithfulness evaluation with question Answering), an automatic evaluation metric that measures the faithfulness of a generated image to its text input via visual question answering (VQA). Specifically, given a text input, we automatically generate several question-answer pairs using a language model. We calculate image faithfulness by checking whether existing VQA models can answer these questions using the generated image. TIFA is a reference-free metric that allows for fine-grained and interpretable evaluations of generated images. TIFA also has better correlations with human judgments than existing metrics. Based on this approach, we introduce TIFA v1.0, a benchmark consisting of 4K diverse text inputs and 25K questions across 12 categories (object, counting, etc.). We present a comprehensive evaluation of existing text-to-image models using TIFA v1.0 and highlight the limitations and challenges of current models. For instance, we find that current text-to-image models, despite doing well on color and material, still struggle in counting, spatial relations, and composing multiple objects. We hope our benchmark will help carefully measure the research progress in text-to-image synthesis and provide valuable insights for further research.
LF-PGVIO: A Visual-Inertial-Odometry Framework for Large Field-of-View Cameras using Points and Geodesic Segments
Jun 11, 2023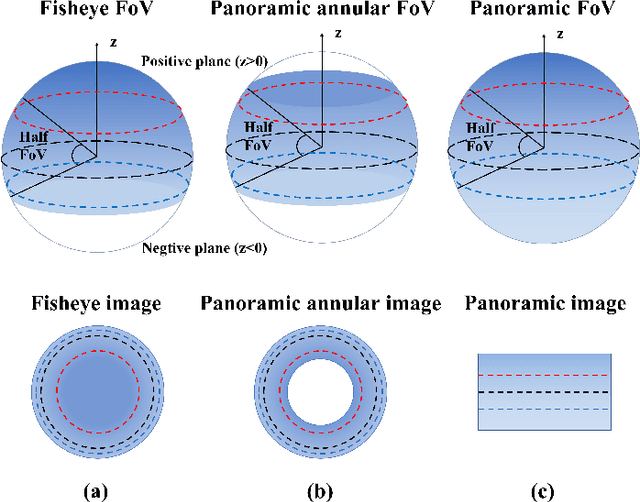
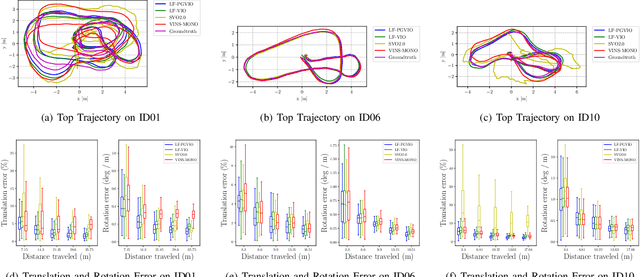
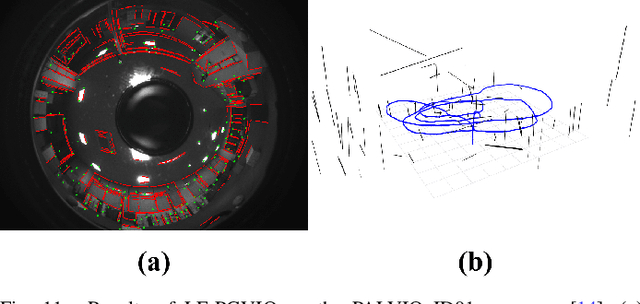
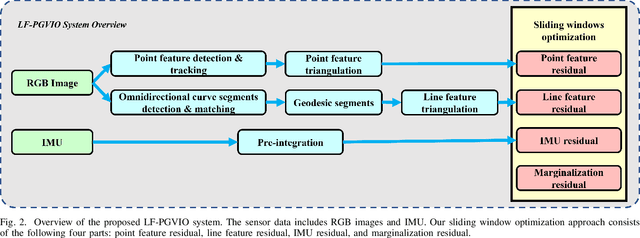
In this paper, we propose LF-PGVIO, a Visual-Inertial-Odometry (VIO) framework for large Field-of-View (FoV) cameras with a negative plane using points and geodesic segments. Notoriously, when the FoV of a panoramic camera reaches the negative half-plane, the image cannot be unfolded into a single pinhole image. Moreover, if a traditional straight-line detection method is directly applied to the original panoramic image, it cannot be normally used due to the large distortions in the panoramas and remains under-explored in the literature. To address these challenges, we put forward LF-PGVIO, which can provide line constraints for cameras with large FoV, even for cameras with negative-plane FoV, and directly extract omnidirectional curve segments from the raw omnidirectional image. We propose an Omnidirectional Curve Segment Detection (OCSD) method combined with a camera model which is applicable to images with large distortions, such as panoramic annular images, fisheye images, and various panoramic images. Each point on the image is projected onto the sphere, and the detected omnidirectional curve segments in the image named geodesic segments must satisfy the criterion of being a geodesic segment on the unit sphere. The detected geodesic segment is sliced into multiple straight-line segments according to the radian of the geodesic, and descriptors are extracted separately and recombined to obtain new descriptors. Based on descriptor matching, we obtain the constraint relationship of the 3D line segments between multiple frames. In our VIO system, we use sliding window optimization using point feature residuals, line feature residuals, and IMU residuals. Our evaluation of the proposed system on public datasets demonstrates that LF-PGVIO outperforms state-of-the-art methods in terms of accuracy and robustness. Code will be open-sourced at https://github.com/flysoaryun/LF-PGVIO.
3D Cinemagraphy from a Single Image
Mar 10, 2023
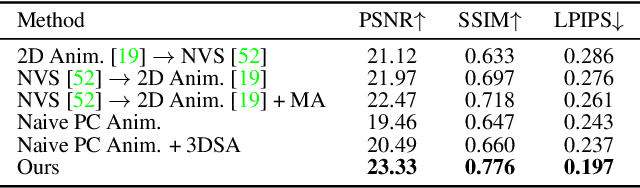
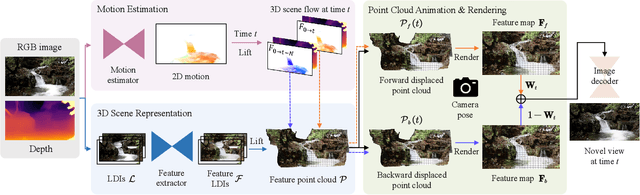

We present 3D Cinemagraphy, a new technique that marries 2D image animation with 3D photography. Given a single still image as input, our goal is to generate a video that contains both visual content animation and camera motion. We empirically find that naively combining existing 2D image animation and 3D photography methods leads to obvious artifacts or inconsistent animation. Our key insight is that representing and animating the scene in 3D space offers a natural solution to this task. To this end, we first convert the input image into feature-based layered depth images using predicted depth values, followed by unprojecting them to a feature point cloud. To animate the scene, we perform motion estimation and lift the 2D motion into the 3D scene flow. Finally, to resolve the problem of hole emergence as points move forward, we propose to bidirectionally displace the point cloud as per the scene flow and synthesize novel views by separately projecting them into target image planes and blending the results. Extensive experiments demonstrate the effectiveness of our method. A user study is also conducted to validate the compelling rendering results of our method.
Do DL models and training environments have an impact on energy consumption?
Jul 07, 2023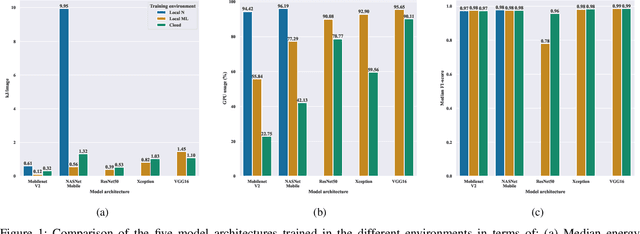
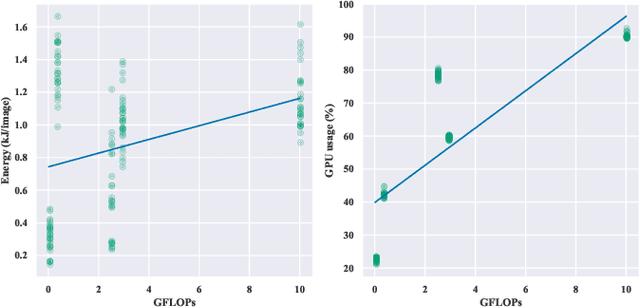
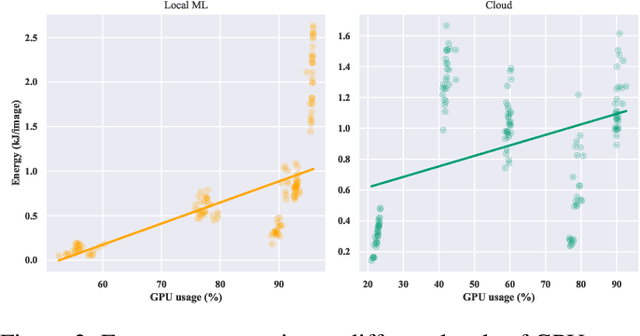
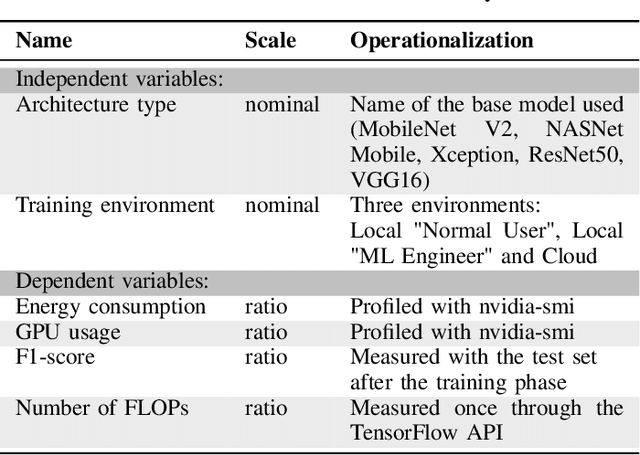
Current research in the computer vision field mainly focuses on improving Deep Learning (DL) correctness and inference time performance. However, there is still little work on the huge carbon footprint that has training DL models. This study aims to analyze the impact of the model architecture and training environment when training greener computer vision models. We divide this goal into two research questions. First, we analyze the effects of model architecture on achieving greener models while keeping correctness at optimal levels. Second, we study the influence of the training environment on producing greener models. To investigate these relationships, we collect multiple metrics related to energy efficiency and model correctness during the models' training. Then, we outline the trade-offs between the measured energy efficiency and the models' correctness regarding model architecture, and their relationship with the training environment. We conduct this research in the context of a computer vision system for image classification. In conclusion, we show that selecting the proper model architecture and training environment can reduce energy consumption dramatically (up to 98.83\%) at the cost of negligible decreases in correctness. Also, we find evidence that GPUs should scale with the models' computational complexity for better energy efficiency.
Zero-shot Medical Image Translation via Frequency-Guided Diffusion Models
Apr 05, 2023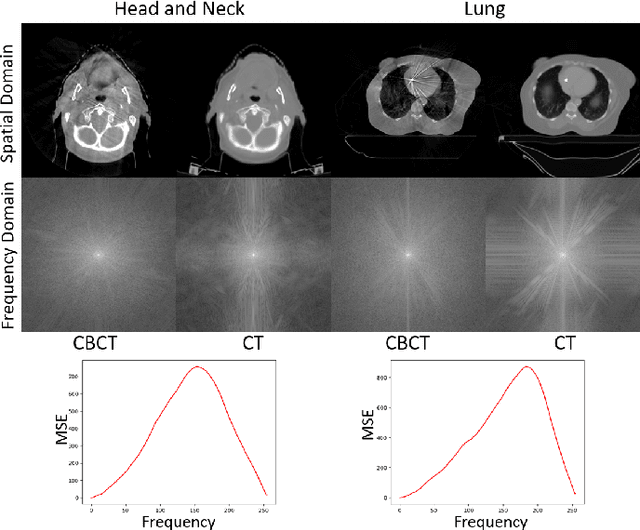

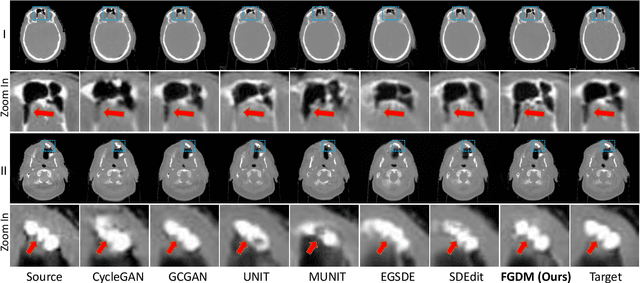
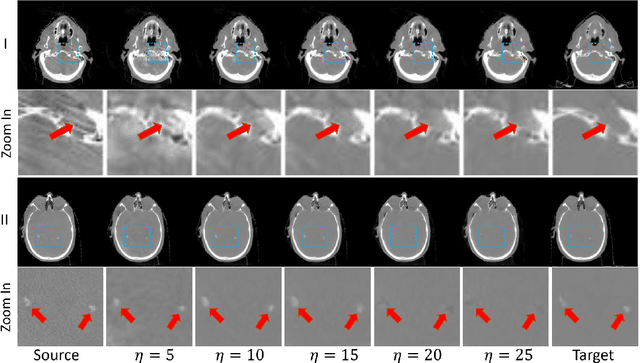
Recently, the diffusion model has emerged as a superior generative model that can produce high-quality images with excellent realism. There is a growing interest in applying diffusion models to image translation tasks. However, for medical image translation, the existing diffusion models are deficient in accurately retaining structural information since the structure details of source domain images are lost during the forward diffusion process and cannot be fully recovered through learned reverse diffusion, while the integrity of anatomical structures is extremely important in medical images. Training and conditioning diffusion models using paired source and target images with matching anatomy can help. However, such paired data are very difficult and costly to obtain, and may also reduce the robustness of the developed model to out-of-distribution testing data. We propose a frequency-guided diffusion model (FGDM) that employs frequency-domain filters to guide the diffusion model for structure-preserving image translation. Based on its design, FGDM allows zero-shot learning, as it can be trained solely on the data from the target domain, and used directly for source-to-target domain translation without any exposure to the source-domain data during training. We trained FGDM solely on the head-and-neck CT data, and evaluated it on both head-and-neck and lung cone-beam CT (CBCT)-to-CT translation tasks. FGDM outperformed the state-of-the-art methods (GAN-based, VAE-based, and diffusion-based) in all metrics, showing its significant advantages in zero-shot medical image translation.
MeMaHand: Exploiting Mesh-Mano Interaction for Single Image Two-Hand Reconstruction
Apr 17, 2023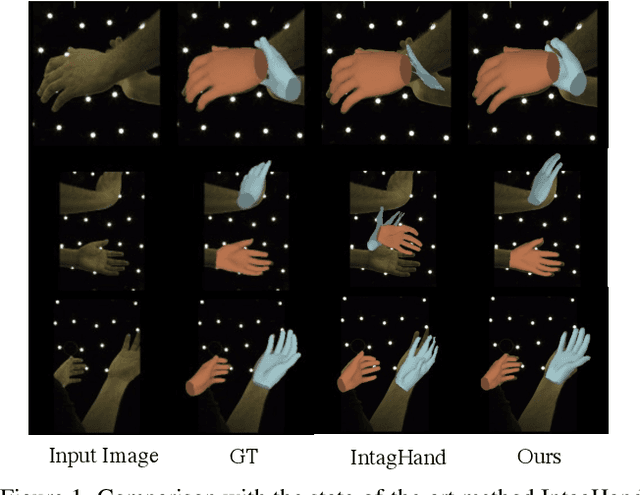
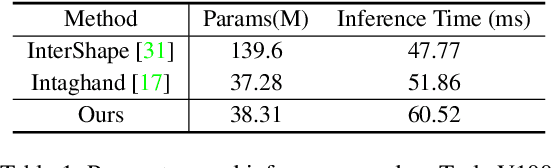
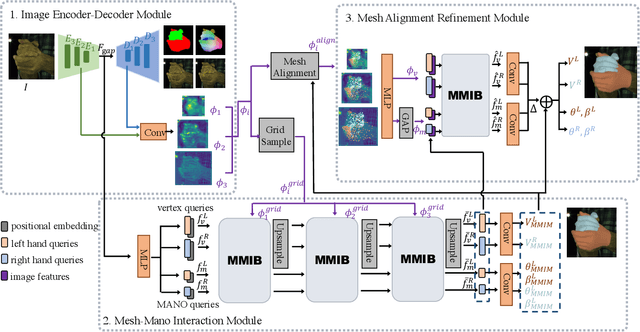
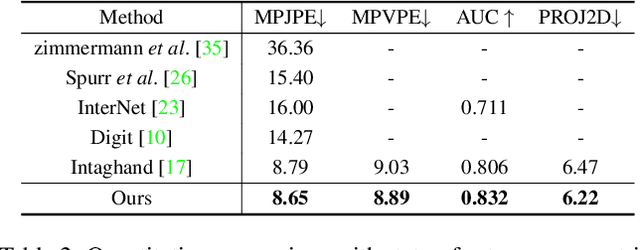
Existing methods proposed for hand reconstruction tasks usually parameterize a generic 3D hand model or predict hand mesh positions directly. The parametric representations consisting of hand shapes and rotational poses are more stable, while the non-parametric methods can predict more accurate mesh positions. In this paper, we propose to reconstruct meshes and estimate MANO parameters of two hands from a single RGB image simultaneously to utilize the merits of two kinds of hand representations. To fulfill this target, we propose novel Mesh-Mano interaction blocks (MMIBs), which take mesh vertices positions and MANO parameters as two kinds of query tokens. MMIB consists of one graph residual block to aggregate local information and two transformer encoders to model long-range dependencies. The transformer encoders are equipped with different asymmetric attention masks to model the intra-hand and inter-hand attention, respectively. Moreover, we introduce the mesh alignment refinement module to further enhance the mesh-image alignment. Extensive experiments on the InterHand2.6M benchmark demonstrate promising results over the state-of-the-art hand reconstruction methods.
Synthesizing Realistic Image Restoration Training Pairs: A Diffusion Approach
Mar 13, 2023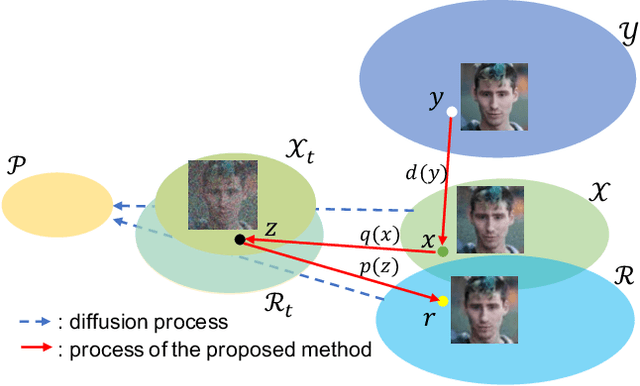


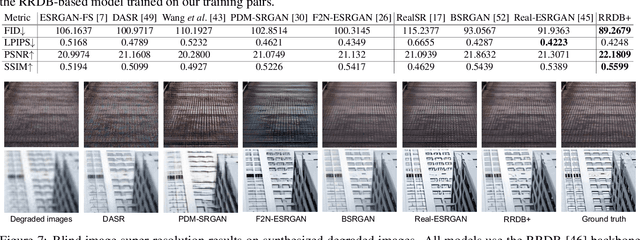
In supervised image restoration tasks, one key issue is how to obtain the aligned high-quality (HQ) and low-quality (LQ) training image pairs. Unfortunately, such HQ-LQ training pairs are hard to capture in practice, and hard to synthesize due to the complex unknown degradation in the wild. While several sophisticated degradation models have been manually designed to synthesize LQ images from their HQ counterparts, the distribution gap between the synthesized and real-world LQ images remains large. We propose a new approach to synthesizing realistic image restoration training pairs using the emerging denoising diffusion probabilistic model (DDPM). First, we train a DDPM, which could convert a noisy input into the desired LQ image, with a large amount of collected LQ images, which define the target data distribution. Then, for a given HQ image, we synthesize an initial LQ image by using an off-the-shelf degradation model, and iteratively add proper Gaussian noises to it. Finally, we denoise the noisy LQ image using the pre-trained DDPM to obtain the final LQ image, which falls into the target distribution of real-world LQ images. Thanks to the strong capability of DDPM in distribution approximation, the synthesized HQ-LQ image pairs can be used to train robust models for real-world image restoration tasks, such as blind face image restoration and blind image super-resolution. Experiments demonstrated the superiority of our proposed approach to existing degradation models. Code and data will be released.