 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NCL++: Nested Collaborative Learning for Long-Tailed Visual Recognition
Jun 29, 2023
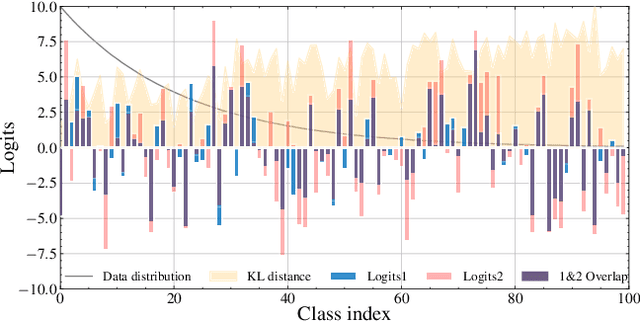
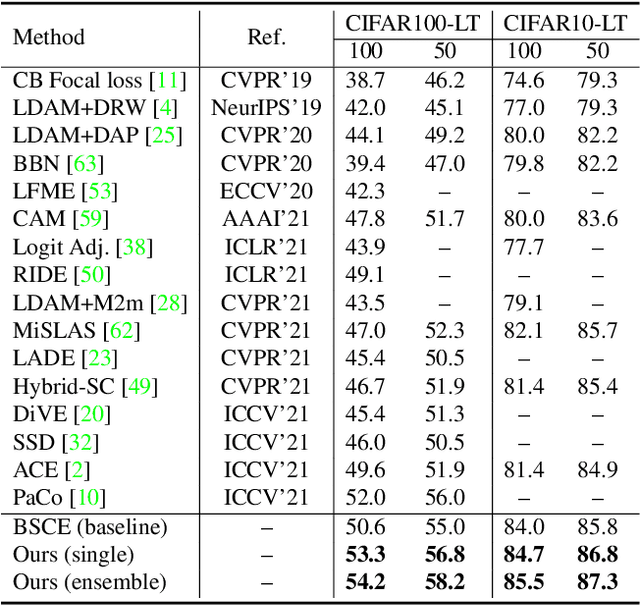
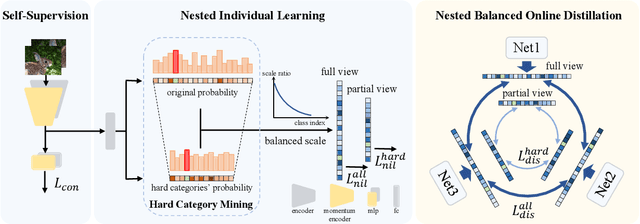
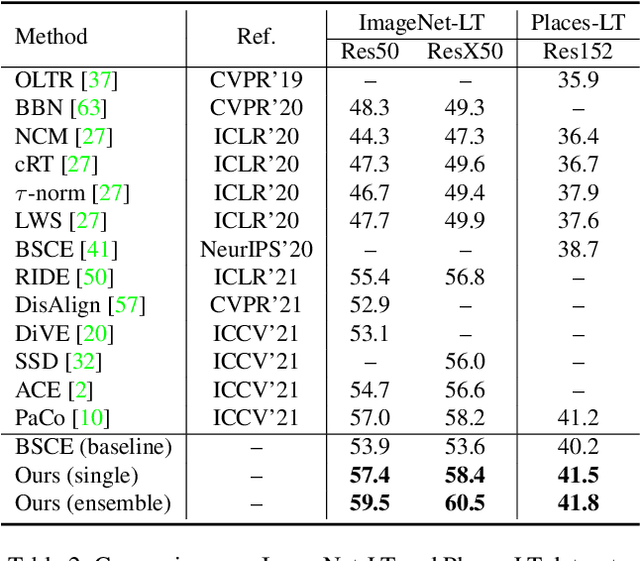
Long-tailed visual recognition has received increasing attention in recent years. Due to the extremely imbalanced data distribution in long-tailed learning, the learning process shows great uncertainties. For example, the predictions of different experts on the same image vary remarkably despite the same training settings. To alleviate the uncertainty, we propose a Nested Collaborative Learning (NCL++) which tackles the long-tailed learning problem by a collaborative learning. To be specific, the collaborative learning consists of two folds, namely inter-expert collaborative learning (InterCL) and intra-expert collaborative learning (IntraCL). In-terCL learns multiple experts collaboratively and concurrently, aiming to transfer the knowledge among different experts. IntraCL is similar to InterCL, but it aims to conduct the collaborative learning on multiple augmented copies of the same image within the single expert. To achieve the collaborative learning in long-tailed learning, the balanced online distillation is proposed to force the consistent predictions among different experts and augmented copies, which reduces the learning uncertainties. Moreover, in order to improve the meticulous distinguishing ability on the confusing categories, we further propose a Hard Category Mining (HCM), which selects the negative categories with high predicted scores as the hard categories. Then, the collaborative learning is formulated in a nested way, in which the learning is conducted on not just all categories from a full perspective but some hard categories from a partial perspective. Extensive experiments manifest the superiority of our method with outperforming the state-of-the-art whether with using a single model or an ensemble. The code will be publicly released.
Increasing Textual Context Size Boosts Medical Image-Text Matching
Mar 23, 2023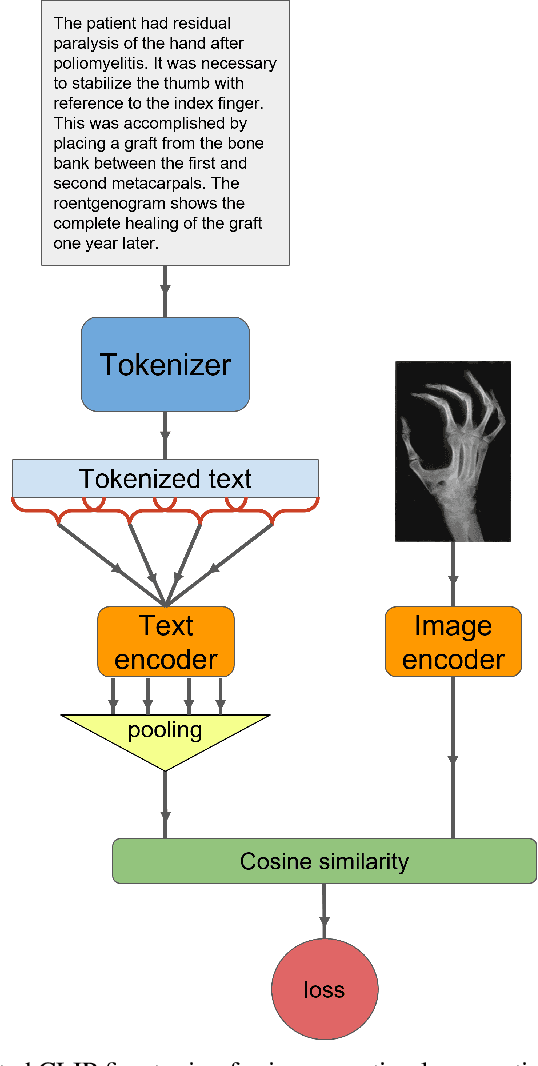
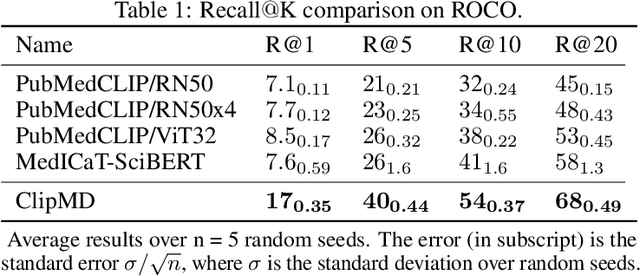
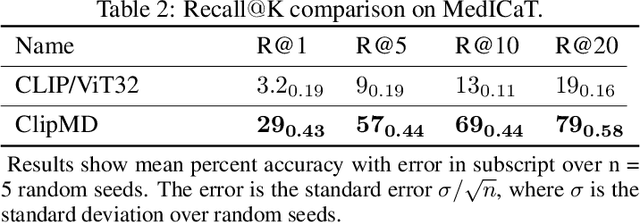
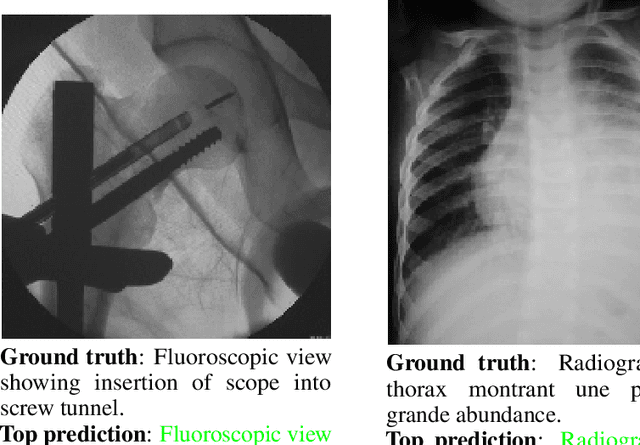
This short technical report demonstrates a simple technique that yields state of the art results in medical image-text matching tasks. We analyze the use of OpenAI's CLIP, a general image-text matching model, and observe that CLIP's limited textual input size has negative impact on downstream performance in the medical domain where encoding longer textual contexts is often required. We thus train and release ClipMD, which is trained with a simple sliding window technique to encode textual captions. ClipMD was tested on two medical image-text datasets and compared with other image-text matching models. The results show that ClipMD outperforms other models on both datasets by a large margin. We make our code and pretrained model publicly available.
Joint multi-modal Self-Supervised pre-training in Remote Sensing: Application to Methane Source Classification
Jun 16, 2023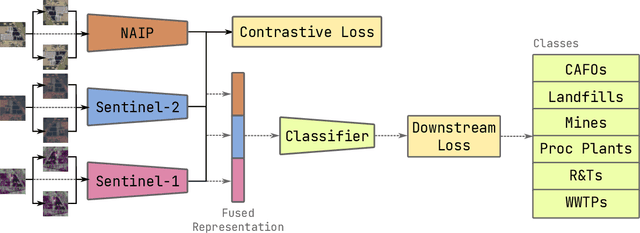
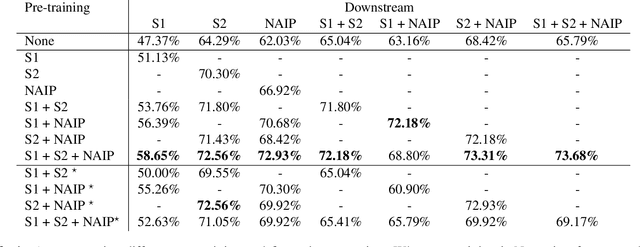
With the current ubiquity of deep learning methods to solve computer vision and remote sensing specific tasks, the need for labelled data is growing constantly. However, in many cases, the annotation process can be long and tedious depending on the expertise needed to perform reliable annotations. In order to alleviate this need for annotations, several self-supervised methods have recently been proposed in the literature. The core principle behind these methods is to learn an image encoder using solely unlabelled data samples. In earth observation, there are opportunities to exploit domain-specific remote sensing image data in order to improve these methods. Specifically, by leveraging the geographical position associated with each image, it is possible to cross reference a location captured from multiple sensors, leading to multiple views of the same locations. In this paper, we briefly review the core principles behind so-called joint-embeddings methods and investigate the usage of multiple remote sensing modalities in self-supervised pre-training. We evaluate the final performance of the resulting encoders on the task of methane source classification.
DreamCatcher: Revealing the Language of the Brain with fMRI using GPT Embedding
Jun 16, 2023

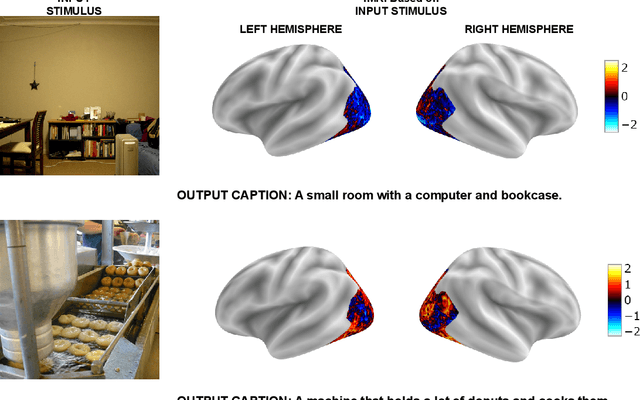
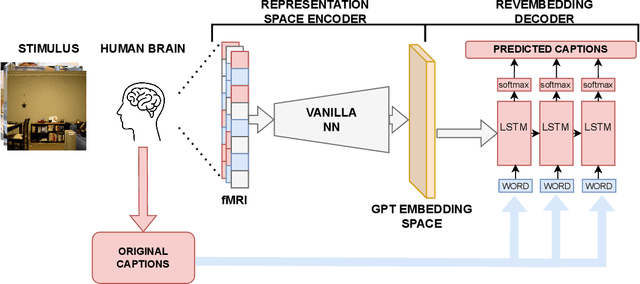
The human brain possesses remarkable abilities in visual processing, including image recognition and scene summarization. Efforts have been made to understand the cognitive capacities of the visual brain, but a comprehensive understanding of the underlying mechanisms still needs to be discovered. Advancements in brain decoding techniques have led to sophisticated approaches like fMRI-to-Image reconstruction, which has implications for cognitive neuroscience and medical imaging. However, challenges persist in fMRI-to-image reconstruction, such as incorporating global context and contextual information. In this article, we propose fMRI captioning, where captions are generated based on fMRI data to gain insight into the neural correlates of visual perception. This research presents DreamCatcher, a novel framework for fMRI captioning. DreamCatcher consists of the Representation Space Encoder (RSE) and the RevEmbedding Decoder, which transform fMRI vectors into a latent space and generate captions, respectively. We evaluated the framework through visualization, dataset training, and testing on subjects, demonstrating strong performance. fMRI-based captioning has diverse applications, including understanding neural mechanisms, Human-Computer Interaction, and enhancing learning and training processes.
Parameter-Free Channel Attention for Image Classification and Super-Resolution
Mar 20, 2023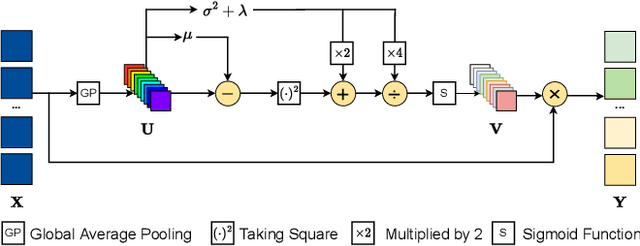
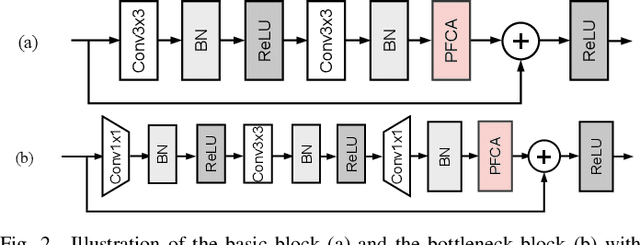
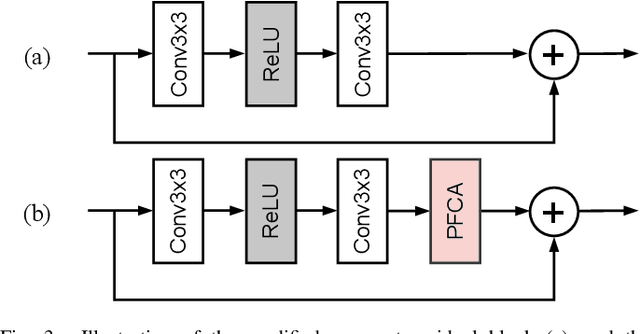
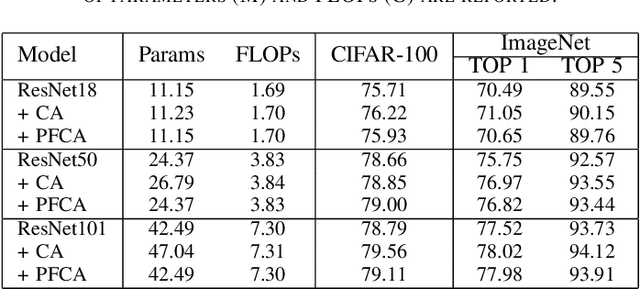
The channel attention mechanism is a useful technique widely employed in deep convolutional neural networks to boost the performance for image processing tasks, eg, image classification and image super-resolution. It is usually designed as a parameterized sub-network and embedded into the convolutional layers of the network to learn more powerful feature representations. However, current channel attention induces more parameters and therefore leads to higher computational costs. To deal with this issue, in this work, we propose a Parameter-Free Channel Attention (PFCA) module to boost the performance of popular image classification and image super-resolution networks, but completely sweep out the parameter growth of channel attention. Experiments on CIFAR-100, ImageNet, and DIV2K validate that our PFCA module improves the performance of ResNet on image classification and improves the performance of MSRResNet on image super-resolution tasks, respectively, while bringing little growth of parameters and FLOPs.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Apr 01, 2023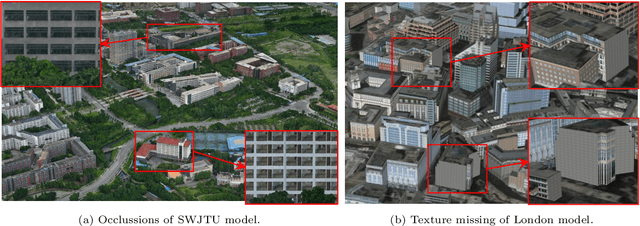
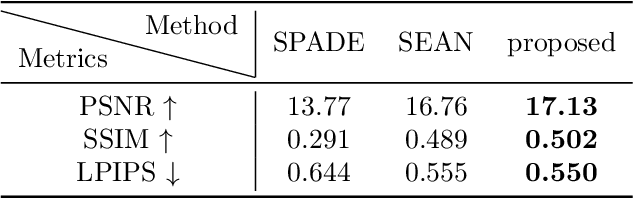
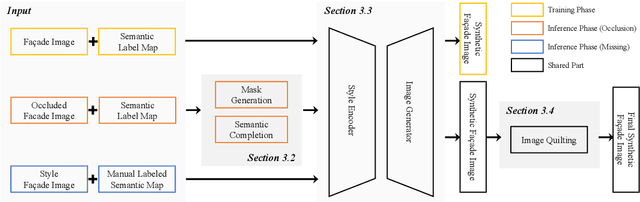

The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.
Self-Consuming Generative Models Go MAD
Jul 04, 2023

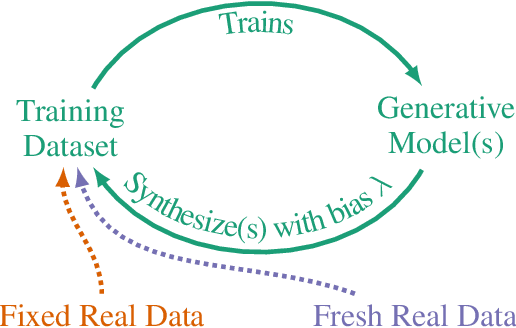
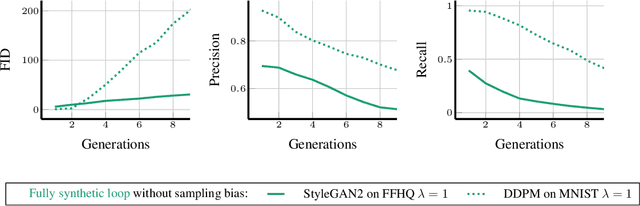
Seismic advances in generative AI algorithms for imagery, text, and other data types has led to the temptation to use synthetic data to train next-generation models. Repeating this process creates an autophagous (self-consuming) loop whose properties are poorly understood. We conduct a thorough analytical and empirical analysis using state-of-the-art generative image models of three families of autophagous loops that differ in how fixed or fresh real training data is available through the generations of training and in whether the samples from previous generation models have been biased to trade off data quality versus diversity. Our primary conclusion across all scenarios is that without enough fresh real data in each generation of an autophagous loop, future generative models are doomed to have their quality (precision) or diversity (recall) progressively decrease. We term this condition Model Autophagy Disorder (MAD), making analogy to mad cow disease.
$P+$: Extended Textual Conditioning in Text-to-Image Generation
Mar 27, 2023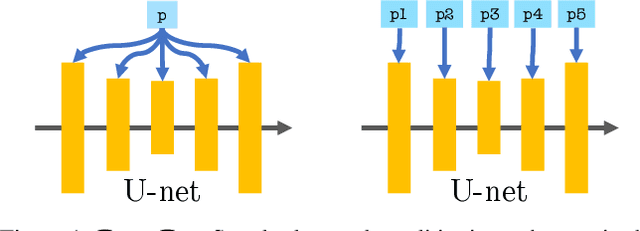



We introduce an Extended Textual Conditioning space in text-to-image models, referred to as $P+$. This space consists of multiple textual conditions, derived from per-layer prompts, each corresponding to a layer of the denoising U-net of the diffusion model. We show that the extended space provides greater disentangling and control over image synthesis. We further introduce Extended Textual Inversion (XTI), where the images are inverted into $P+$, and represented by per-layer tokens. We show that XTI is more expressive and precise, and converges faster than the original Textual Inversion (TI) space. The extended inversion method does not involve any noticeable trade-off between reconstruction and editability and induces more regular inversions. We conduct a series of extensive experiments to analyze and understand the properties of the new space, and to showcase the effectiveness of our method for personalizing text-to-image models. Furthermore, we utilize the unique properties of this space to achieve previously unattainable results in object-style mixing using text-to-image models. Project page: https://prompt-plus.github.io
Broken Rail Detection With Texture Image Processing Using Two-Dimensional Gray Level Co-occurrence Matrix
Apr 23, 2023Application of electronic railway systems as well as the implication of Automatic Train Control (ATC) System has increased the safety of rail transportation. However, one of the most important causes of accidents on the railway is rail damage and breakage. In this paper, we have proposed a method that the rail region is first recognized from the observation area, then by investigating the image texture processing data, the types of rail defects including cracks, wear, peeling, disintegration, and breakage are detected. In order to reduce the computational cost, the image is changed from the RGB color spectrum to the gray spectrum. Image texture processing data is obtained by the two-dimensional Gray Levels Co-occurrence Matrix (GLCM) at different angles; this data demonstrates second-order features of the images. Large data of features has a negative effect on the overall accuracy of the classifiers. To tackle this issue and acquire faster response, Principal Component Analysis (PCA) algorithm is used, before entering the band into the classifier. Then the features extracted from the images are compared by three different classifiers including Support Vector Machine (SVM), Random Forest (RF), and K-Nearest Neighbor (KNN) classification. The results obtained from this method indicate that the Random Forest classifier has better performance (accuracy 97%, precision 96%, and recall 96%) than other classifiers.
Neural Image-based Avatars: Generalizable Radiance Fields for Human Avatar Modeling
Apr 10, 2023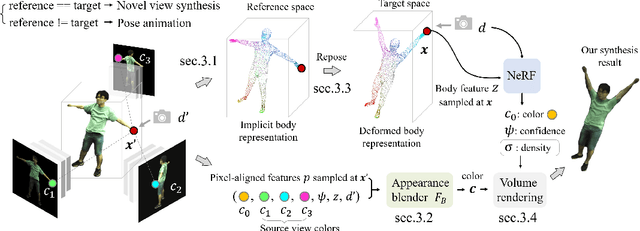
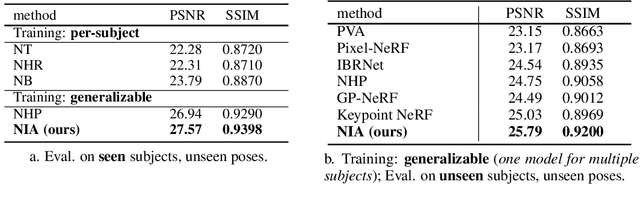


We present a method that enables synthesizing novel views and novel poses of arbitrary human performers from sparse multi-view images. A key ingredient of our method is a hybrid appearance blending module that combines the advantages of the implicit body NeRF representation and image-based rendering. Existing generalizable human NeRF methods that are conditioned on the body model have shown robustness against the geometric variation of arbitrary human performers. Yet they often exhibit blurry results when generalized onto unseen identities. Meanwhile, image-based rendering shows high-quality results when sufficient observations are available, whereas it suffers artifacts in sparse-view settings. We propose Neural Image-based Avatars (NIA) that exploits the best of those two methods: to maintain robustness under new articulations and self-occlusions while directly leveraging the available (sparse) source view colors to preserve appearance details of new subject identities. Our hybrid design outperforms recent methods on both in-domain identity generalization as well as challenging cross-dataset generalization settings. Also, in terms of the pose generalization, our method outperforms even the per-subject optimized animatable NeRF methods. The video results are available at https://youngjoongunc.github.io/nia