 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Motion Plane Adaptive Motion Modeling for Spherical Video Coding in H.266/VVC
Jun 23, 2023

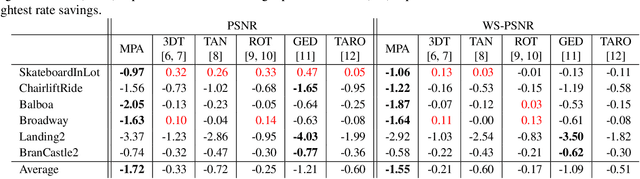
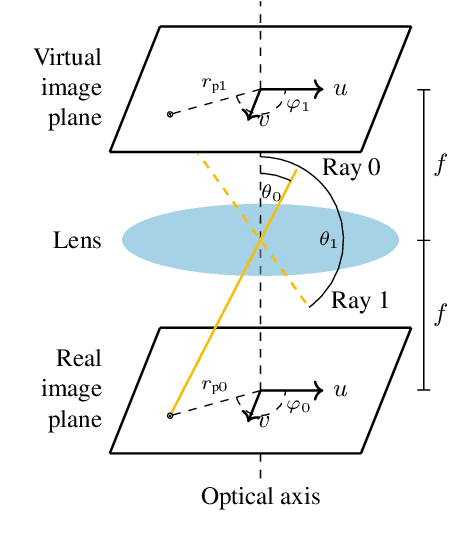
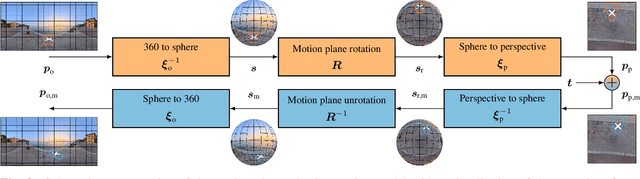
Motion compensation is one of the key technologies enabling the high compression efficiency of modern video coding standards. To allow compression of spherical video content, special mapping functions are required to project the video to the 2D image plane. Distortions inevitably occurring in these mappings impair the performance of classical motion models. In this paper, we propose a novel motion plane adaptive motion modeling technique (MPA) for spherical video that allows to perform motion compensation on different motion planes in 3D space instead of having to work on the - in theory arbitrarily mapped - 2D image representation directly. The integration of MPA into the state-of-the-art H.266/VVC video coding standard shows average Bj{\o}ntegaard Delta rate savings of 1.72\% with a peak of 3.37\% based on PSNR and 1.55\% with a peak of 2.92\% based on WS-PSNR compared to VTM-14.2.
Incorporating Deep Q -- Network with Multiclass Classification Algorithms
Jul 08, 2023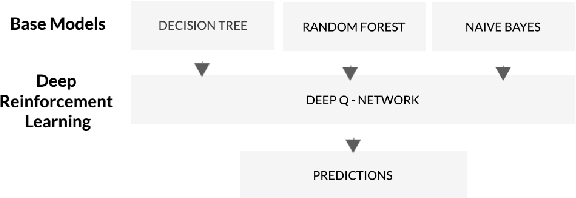
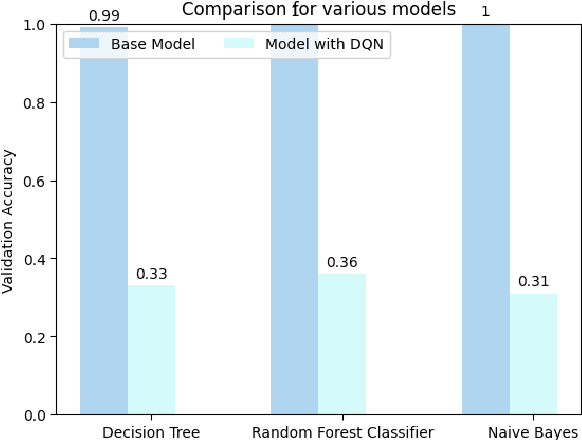
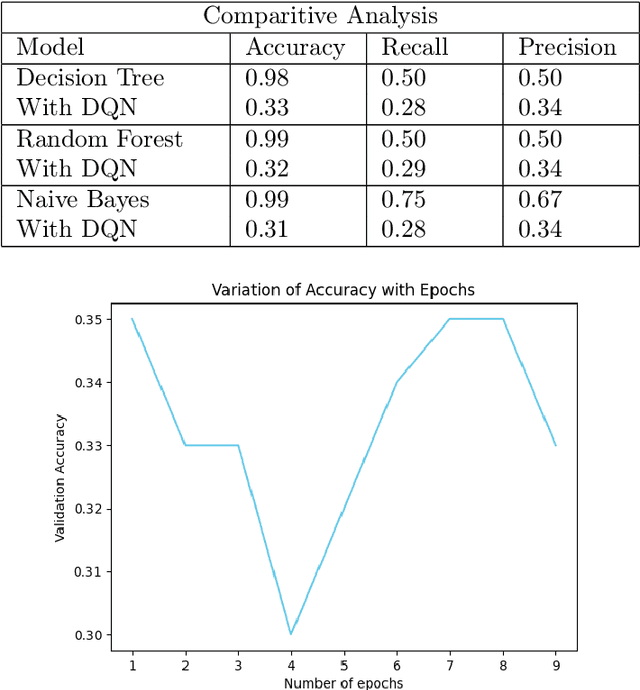
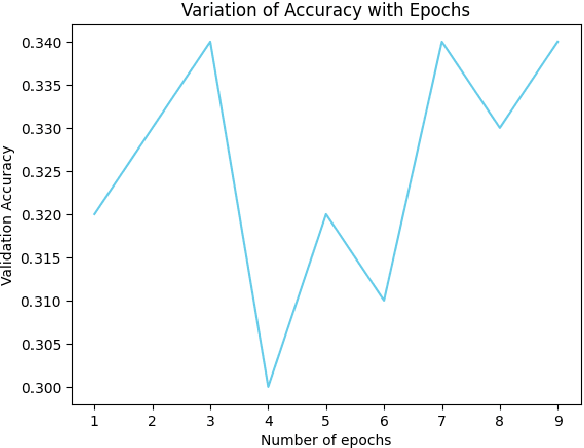
In this study, we explore how Deep Q-Network (DQN) might improve the functionality of multiclass classification algorithms. We will use a benchmark dataset from Kaggle to create a framework incorporating DQN with existing supervised multiclass classification algorithms. The findings of this study will bring insight into how deep reinforcement learning strategies may be used to increase multiclass classification accuracy. They have been used in a number of fields, including image recognition, natural language processing, and bioinformatics. This study is focused on the prediction of financial distress in companies in addition to the wider application of Deep Q-Network in multiclass classification. Identifying businesses that are likely to experience financial distress is a crucial task in the fields of finance and risk management. Whenever a business experiences serious challenges keeping its operations going and meeting its financial responsibilities, it is said to be in financial distress. It commonly happens when a company has a sharp and sustained recession in profitability, cash flow issues, or an unsustainable level of debt.
Calibration-Aware Margin Loss: Pushing the Accuracy-Calibration Consistency Pareto Frontier for Deep Metric Learning
Jul 08, 2023
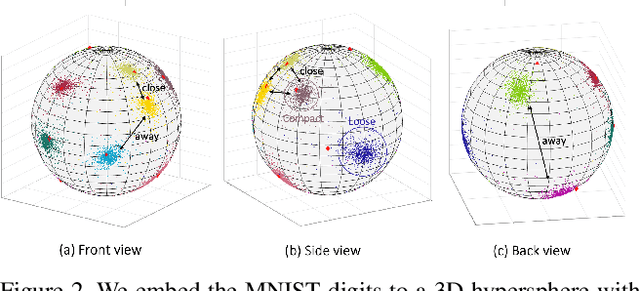

The ability to use the same distance threshold across different test classes / distributions is highly desired for a frictionless deployment of commercial image retrieval systems. However, state-of-the-art deep metric learning losses often result in highly varied intra-class and inter-class embedding structures, making threshold calibration a non-trivial process in practice. In this paper, we propose a novel metric named Operating-Point-Incosistency-Score (OPIS) that measures the variance in the operating characteristics across different classes in a target calibration range, and demonstrate that high accuracy of a metric learning embedding model does not guarantee calibration consistency for both seen and unseen classes. We find that, in the high-accuracy regime, there exists a Pareto frontier where accuracy improvement comes at the cost of calibration consistency. To address this, we develop a novel regularization, named Calibration-Aware Margin (CAM) loss, to encourage uniformity in the representation structures across classes during training. Extensive experiments demonstrate CAM's effectiveness in improving calibration-consistency while retaining or even enhancing accuracy, outperforming state-of-the-art deep metric learning methods.
GlyphDraw: Learning to Draw Chinese Characters in Image Synthesis Models Coherently
Mar 31, 2023
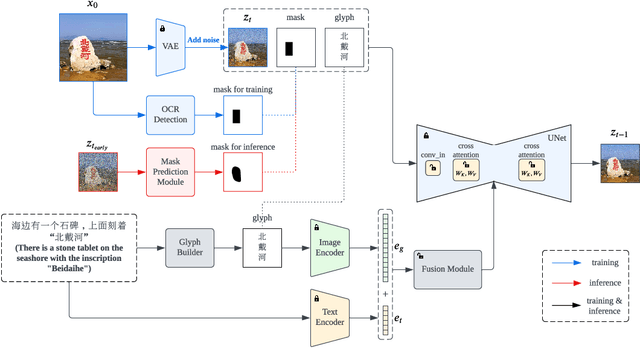

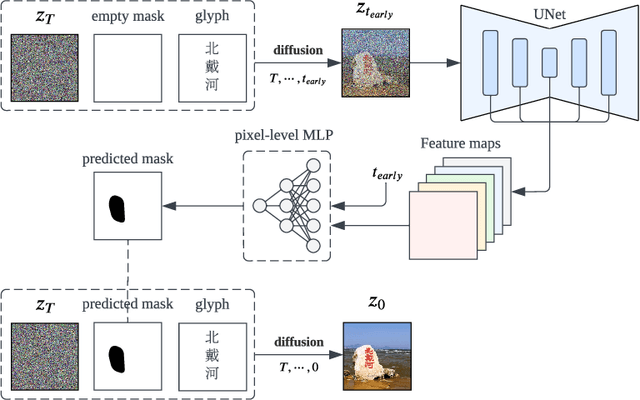
Recent breakthroughs in the field of language-guided image generation have yielded impressive achievements, enabling the creation of high-quality and diverse images based on user instructions. Although the synthesis performance is fascinating, one significant limitation of current image generation models is their insufficient ability to generate coherent text within images, particularly for complex glyph structures like Chinese characters. To address this problem, we introduce GlyphDraw, a general learning framework aiming at endowing image generation models with the capacity to generate images embedded with coherent text. To the best of our knowledge, this is the first work in the field of image synthesis to address the generation of Chinese characters. % we first adopt the OCR technique to collect images with Chinese characters as training samples, and extract the text and locations as auxiliary information. We first sophisticatedly design the image-text dataset's construction strategy, then build our model specifically on a diffusion-based image generator and carefully modify the network structure to allow the model to learn drawing Chinese characters with the help of glyph and position information. Furthermore, we maintain the model's open-domain image synthesis capability by preventing catastrophic forgetting by using a variety of training techniques. Extensive qualitative and quantitative experiments demonstrate that our method not only produces accurate Chinese characters as in prompts, but also naturally blends the generated text into the background. Please refer to https://1073521013.github.io/glyph-draw.github.io
Understanding Depth Map Progressively: Adaptive Distance Interval Separation for Monocular 3d Object Detection
Jun 19, 2023
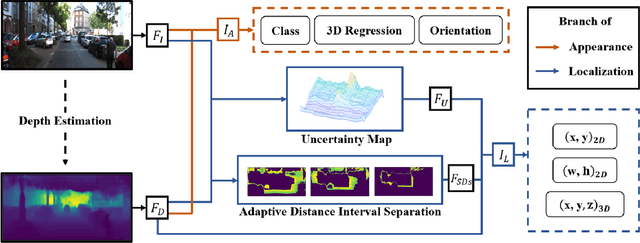
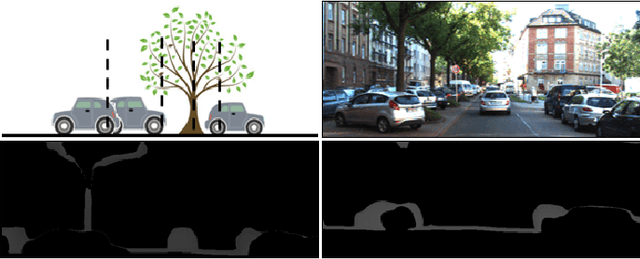
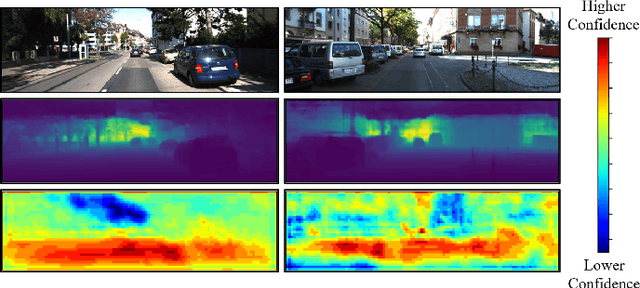
Monocular 3D object detection aims to locate objects in different scenes with just a single image. Due to the absence of depth information, several monocular 3D detection techniques have emerged that rely on auxiliary depth maps from the depth estimation task. There are multiple approaches to understanding the representation of depth maps, including treating them as pseudo-LiDAR point clouds, leveraging implicit end-to-end learning of depth information, or considering them as an image input. However, these methods have certain drawbacks, such as their reliance on the accuracy of estimated depth maps and suboptimal utilization of depth maps due to their image-based nature. While LiDAR-based methods and convolutional neural networks (CNNs) can be utilized for pseudo point clouds and depth maps, respectively, it is always an alternative. In this paper, we propose a framework named the Adaptive Distance Interval Separation Network (ADISN) that adopts a novel perspective on understanding depth maps, as a form that lies between LiDAR and images. We utilize an adaptive separation approach that partitions the depth map into various subgraphs based on distance and treats each of these subgraphs as an individual image for feature extraction. After adaptive separations, each subgraph solely contains pixels within a learned interval range. If there is a truncated object within this range, an evident curved edge will appear, which we can leverage for texture extraction using CNNs to obtain rich depth information in pixels. Meanwhile, to mitigate the inaccuracy of depth estimation, we designed an uncertainty module. To take advantage of both images and depth maps, we use different branches to learn localization detection tasks and appearance tasks separately.
altiro3D: Scene representation from single image and novel view synthesis
Apr 02, 2023


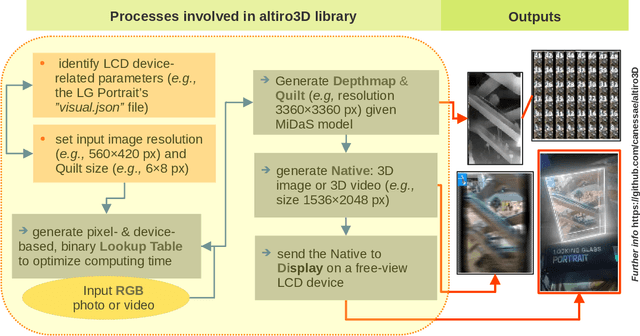
We introduce altiro3D, a free extended library developed to represent reality starting from a given original RGB image or flat video. It allows to generate a light-field (or Native) image or video and get a realistic 3D experience. To synthesize N-number of virtual images and add them sequentially into a Quilt collage, we apply MiDaS models for the monocular depth estimation, simple OpenCV and Telea inpainting techniques to map all pixels, and implement a 'Fast' algorithm to handle 3D projection camera and scene transformations along N-viewpoints. We use the degree of depth to move proportionally the pixels, assuming the original image to be at the center of all the viewpoints. altiro3D can also be used with DIBR algorithm to compute intermediate snapshots from a equivalent 'Real (slower)' camera with N-geometric viewpoints, which requires to calibrate a priori several intrinsic and extrinsic camera parameters. We adopt a pixel- and device-based Lookup Table to optimize computing time. The multiple viewpoints and video generated from a single image or frame can be displayed in a free-view LCD display.
ChiENN: Embracing Molecular Chirality with Graph Neural Networks
Jul 05, 2023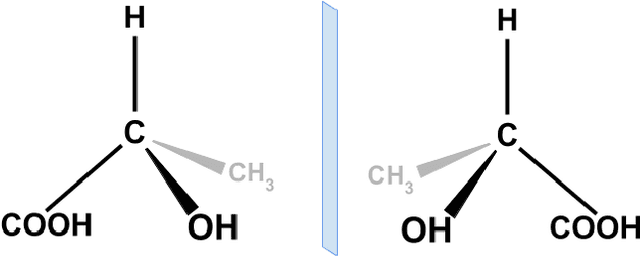
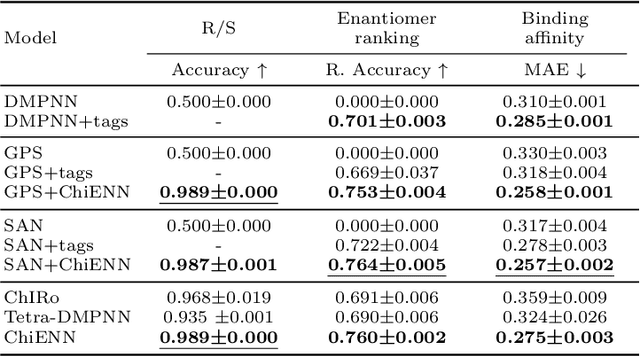
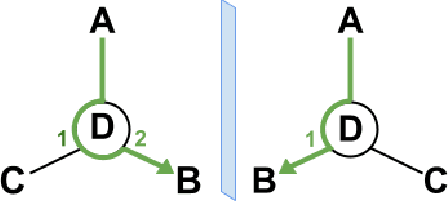
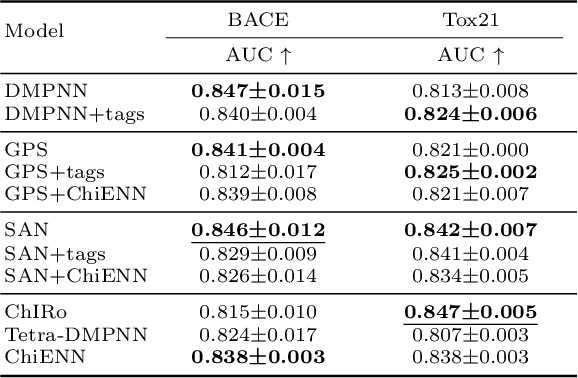
Graph Neural Networks (GNNs) play a fundamental role in many deep learning problems, in particular in cheminformatics. However, typical GNNs cannot capture the concept of chirality, which means they do not distinguish between the 3D graph of a chemical compound and its mirror image (enantiomer). The ability to distinguish between enantiomers is important especially in drug discovery because enantiomers can have very distinct biochemical properties. In this paper, we propose a theoretically justified message-passing scheme, which makes GNNs sensitive to the order of node neighbors. We apply that general concept in the context of molecular chirality to construct Chiral Edge Neural Network (ChiENN) layer which can be appended to any GNN model to enable chirality-awareness. Our experiments show that adding ChiENN layers to a GNN outperforms current state-of-the-art methods in chiral-sensitive molecular property prediction tasks.
Blended-NeRF: Zero-Shot Object Generation and Blending in Existing Neural Radiance Fields
Jun 22, 2023Editing a local region or a specific object in a 3D scene represented by a NeRF is challenging, mainly due to the implicit nature of the scene representation. Consistently blending a new realistic object into the scene adds an additional level of difficulty. We present Blended-NeRF, a robust and flexible framework for editing a specific region of interest in an existing NeRF scene, based on text prompts or image patches, along with a 3D ROI box. Our method leverages a pretrained language-image model to steer the synthesis towards a user-provided text prompt or image patch, along with a 3D MLP model initialized on an existing NeRF scene to generate the object and blend it into a specified region in the original scene. We allow local editing by localizing a 3D ROI box in the input scene, and seamlessly blend the content synthesized inside the ROI with the existing scene using a novel volumetric blending technique. To obtain natural looking and view-consistent results, we leverage existing and new geometric priors and 3D augmentations for improving the visual fidelity of the final result. We test our framework both qualitatively and quantitatively on a variety of real 3D scenes and text prompts, demonstrating realistic multi-view consistent results with much flexibility and diversity compared to the baselines. Finally, we show the applicability of our framework for several 3D editing applications, including adding new objects to a scene, removing/replacing/altering existing objects, and texture conversion.
Restart Sampling for Improving Generative Processes
Jun 26, 2023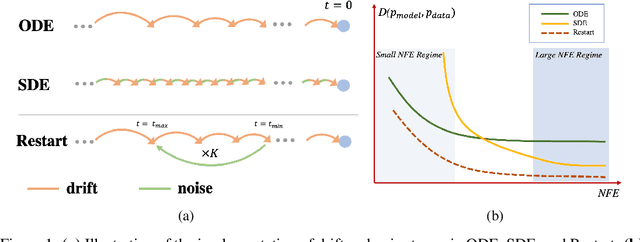
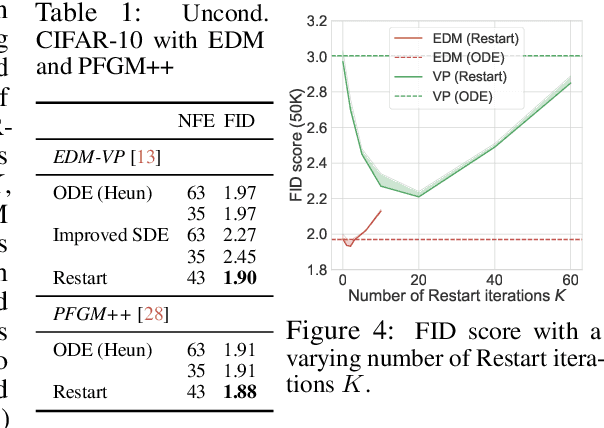
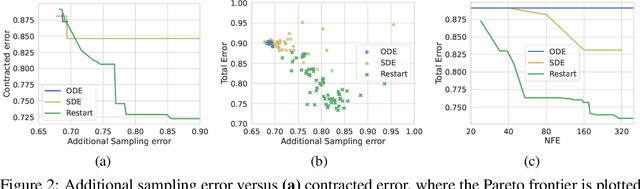

Generative processes that involve solving differential equations, such as diffusion models, frequently necessitate balancing speed and quality. ODE-based samplers are fast but plateau in performance while SDE-based samplers deliver higher sample quality at the cost of increased sampling time. We attribute this difference to sampling errors: ODE-samplers involve smaller discretization errors while stochasticity in SDE contracts accumulated errors. Based on these findings, we propose a novel sampling algorithm called Restart in order to better balance discretization errors and contraction. The sampling method alternates between adding substantial noise in additional forward steps and strictly following a backward ODE. Empirically, Restart sampler surpasses previous SDE and ODE samplers in both speed and accuracy. Restart not only outperforms the previous best SDE results, but also accelerates the sampling speed by 10-fold / 2-fold on CIFAR-10 / ImageNet $64 \times 64$. In addition, it attains significantly better sample quality than ODE samplers within comparable sampling times. Moreover, Restart better balances text-image alignment/visual quality versus diversity than previous samplers in the large-scale text-to-image Stable Diffusion model pre-trained on LAION $512 \times 512$. Code is available at https://github.com/Newbeeer/diffusion_restart_sampling
Score-based Conditional Generation with Fewer Labeled Data by Self-calibrating Classifier Guidance
Jul 09, 2023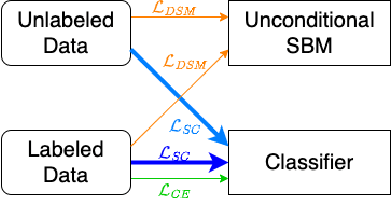
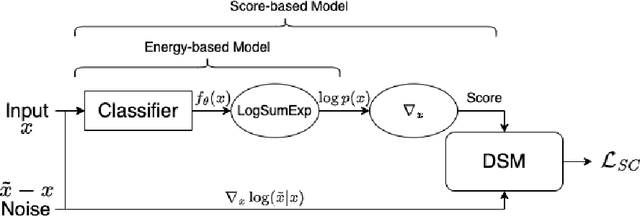
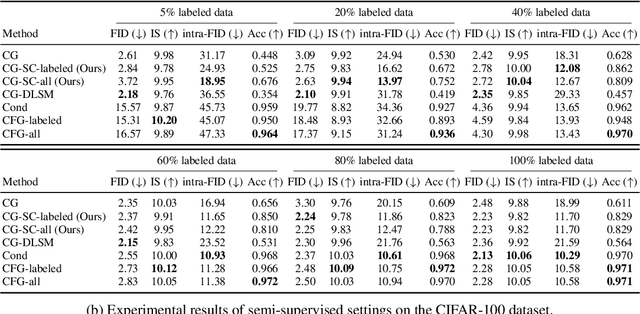
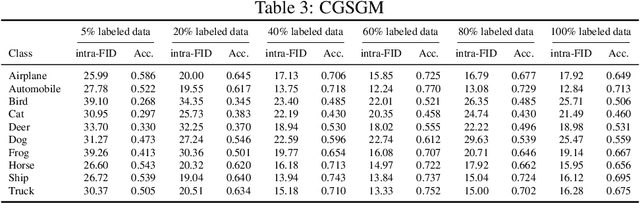
Score-based Generative Models (SGMs) are a popular family of deep generative models that achieves leading image generation quality. Earlier studies have extended SGMs to tackle class-conditional generation by coupling an unconditional SGM with the guidance of a trained classifier. Nevertheless, such classifier-guided SGMs do not always achieve accurate conditional generation, especially when trained with fewer labeled data. We argue that the issue is rooted in unreliable gradients of the classifier and the inability to fully utilize unlabeled data during training. We then propose to improve classifier-guided SGMs by letting the classifier calibrate itself. Our key idea is to use principles from energy-based models to convert the classifier as another view of the unconditional SGM. Then, existing loss for the unconditional SGM can be adopted to calibrate the classifier using both labeled and unlabeled data. Empirical results validate that the proposed approach significantly improves the conditional generation quality across different percentages of labeled data. The improved performance makes the proposed approach consistently superior to other conditional SGMs when using fewer labeled data. The results confirm the potential of the proposed approach for generative modeling with limited labeled data.