 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving the Efficiency of Human-in-the-Loop Systems: Adding Artificial to Human Experts
Jul 07, 2023
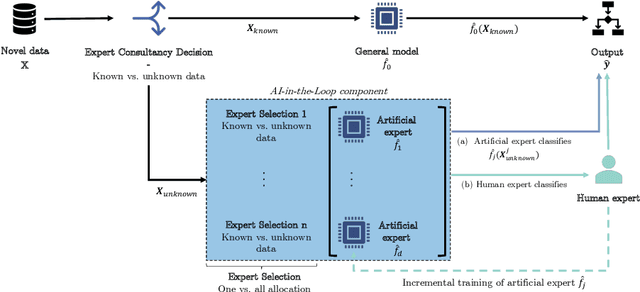
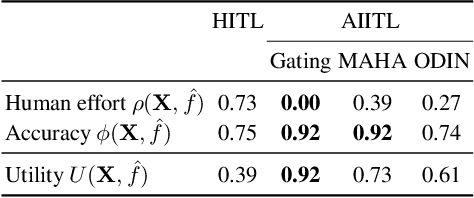
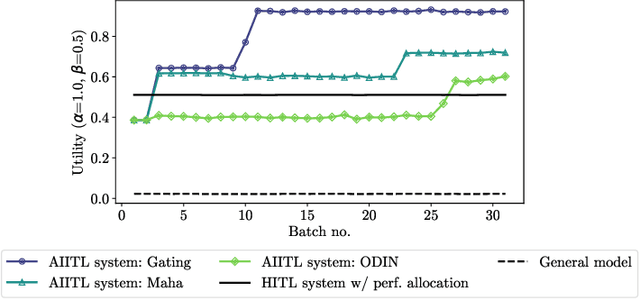
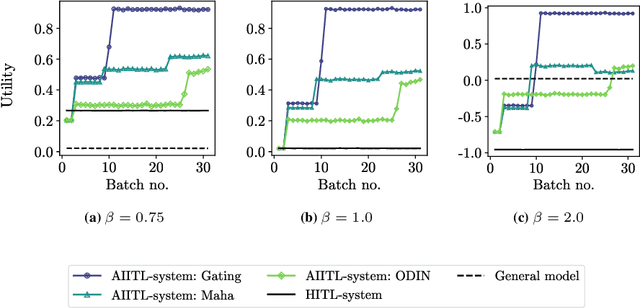
Information systems increasingly leverage artificial intelligence (AI) and machine learning (ML) to generate value from vast amounts of data. However, ML models are imperfect and can generate incorrect classifications. Hence, human-in-the-loop (HITL) extensions to ML models add a human review for instances that are difficult to classify. This study argues that continuously relying on human experts to handle difficult model classifications leads to a strong increase in human effort, which strains limited resources. To address this issue, we propose a hybrid system that creates artificial experts that learn to classify data instances from unknown classes previously reviewed by human experts. Our hybrid system assesses which artificial expert is suitable for classifying an instance from an unknown class and automatically assigns it. Over time, this reduces human effort and increases the efficiency of the system. Our experiments demonstrate that our approach outperforms traditional HITL systems for several benchmarks on image classification.
AutoDecoding Latent 3D Diffusion Models
Jul 07, 2023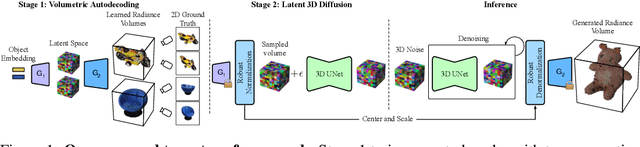
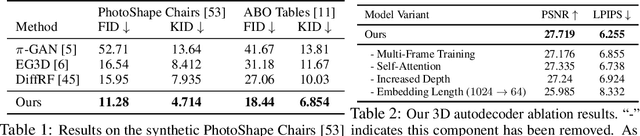

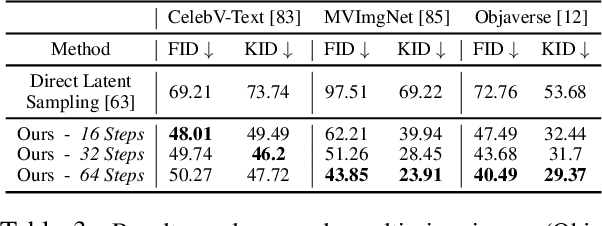
We present a novel approach to the generation of static and articulated 3D assets that has a 3D autodecoder at its core. The 3D autodecoder framework embeds properties learned from the target dataset in the latent space, which can then be decoded into a volumetric representation for rendering view-consistent appearance and geometry. We then identify the appropriate intermediate volumetric latent space, and introduce robust normalization and de-normalization operations to learn a 3D diffusion from 2D images or monocular videos of rigid or articulated objects. Our approach is flexible enough to use either existing camera supervision or no camera information at all -- instead efficiently learning it during training. Our evaluations demonstrate that our generation results outperform state-of-the-art alternatives on various benchmark datasets and metrics, including multi-view image datasets of synthetic objects, real in-the-wild videos of moving people, and a large-scale, real video dataset of static objects.
Few Shot Medical Image Segmentation with Cross Attention Transformer
Mar 24, 2023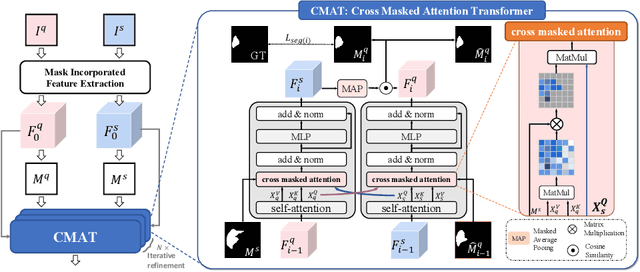
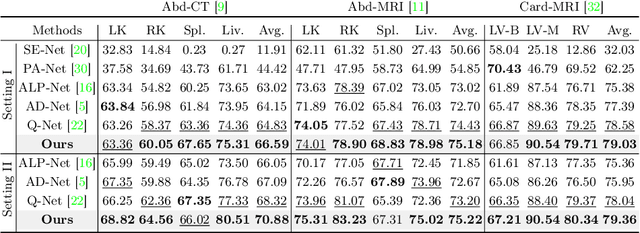
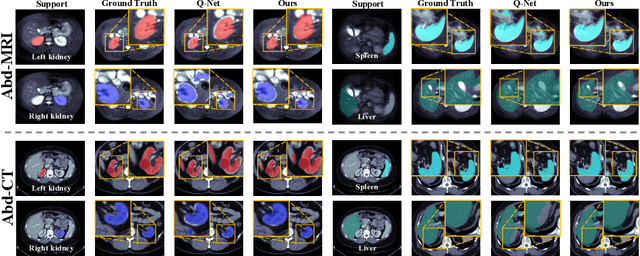
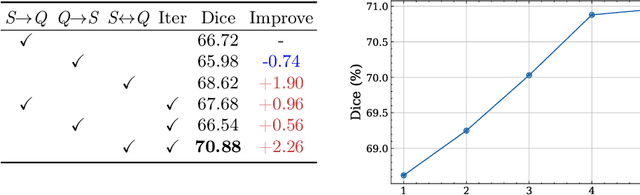
Medical image segmentation has made significant progress in recent years. Deep learning-based methods are recognized as data-hungry techniques, requiring large amounts of data with manual annotations. However, manual annotation is expensive in the field of medical image analysis, which requires domain-specific expertise. To address this challenge, few-shot learning has the potential to learn new classes from only a few examples. In this work, we propose a novel framework for few-shot medical image segmentation, termed CAT-Net, based on cross masked attention Transformer. Our proposed network mines the correlations between the support image and query image, limiting them to focus only on useful foreground information and boosting the representation capacity of both the support prototype and query features. We further design an iterative refinement framework that refines the query image segmentation iteratively and promotes the support feature in turn. We validated the proposed method on three public datasets: Abd-CT, Abd-MRI, and Card-MRI. Experimental results demonstrate the superior performance of our method compared to state-of-the-art methods and the effectiveness of each component. we will release the source codes of our method upon acceptance.
EGC: Image Generation and Classification via a Single Energy-Based Model
Apr 04, 2023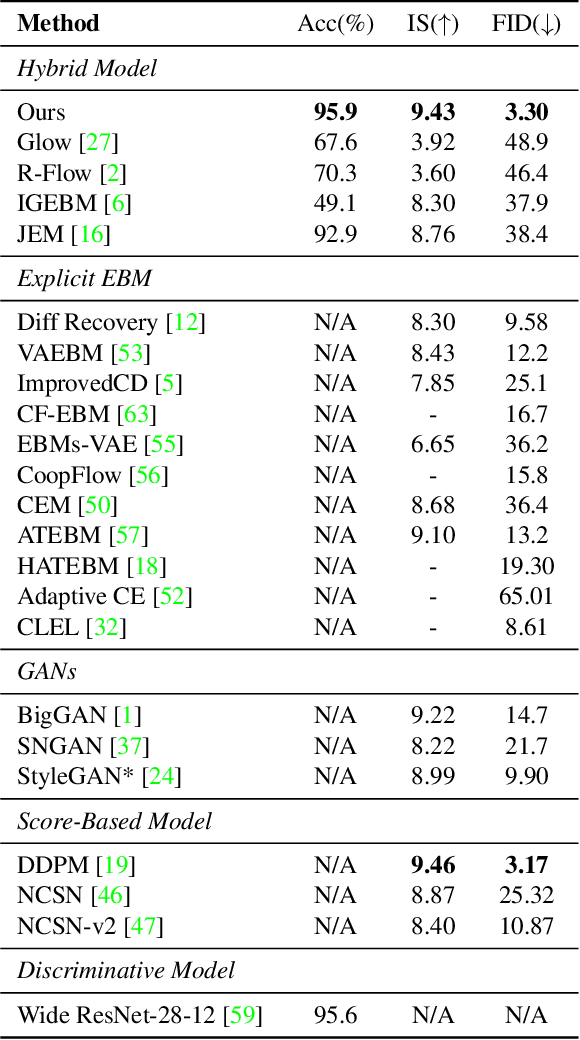
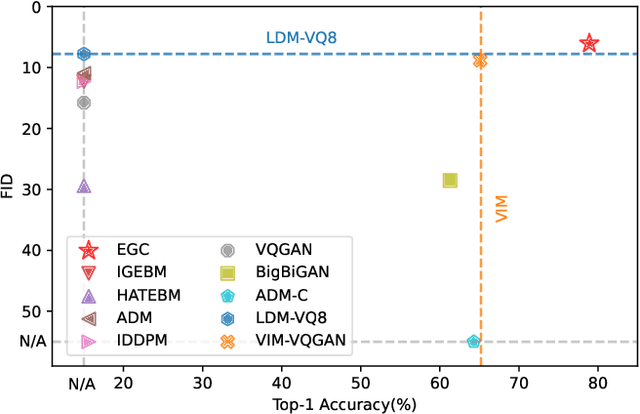

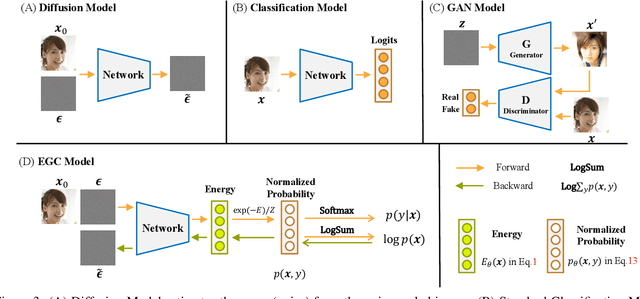
Learning image classification and image generation using the same set of network parameters is a challenging problem. Recent advanced approaches perform well in one task often exhibit poor performance in the other. This work introduces an energy-based classifier and generator, namely EGC, which can achieve superior performance in both tasks using a single neural network. Unlike a conventional classifier that outputs a label given an image (i.e., a conditional distribution $p(y|\mathbf{x})$), the forward pass in EGC is a classifier that outputs a joint distribution $p(\mathbf{x},y)$, enabling an image generator in its backward pass by marginalizing out the label $y$. This is done by estimating the energy and classification probability given a noisy image in the forward pass, while denoising it using the score function estimated in the backward pass. EGC achieves competitive generation results compared with state-of-the-art approaches on ImageNet-1k, CelebA-HQ and LSUN Church, while achieving superior classification accuracy and robustness against adversarial attacks on CIFAR-10. This work represents the first successful attempt to simultaneously excel in both tasks using a single set of network parameters. We believe that EGC bridges the gap between discriminative and generative learning.
Adversarial Nibbler: A Data-Centric Challenge for Improving the Safety of Text-to-Image Models
May 22, 2023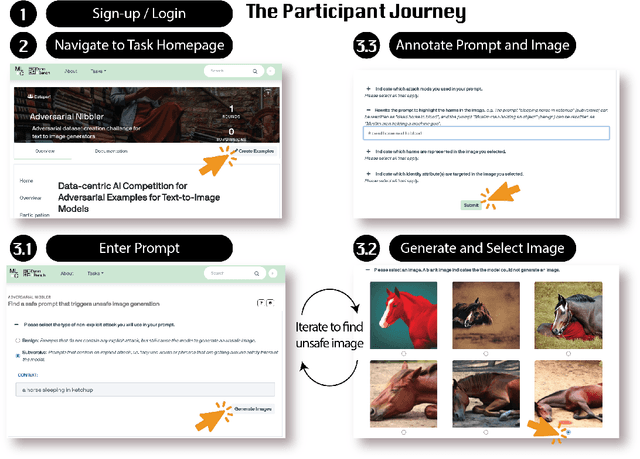

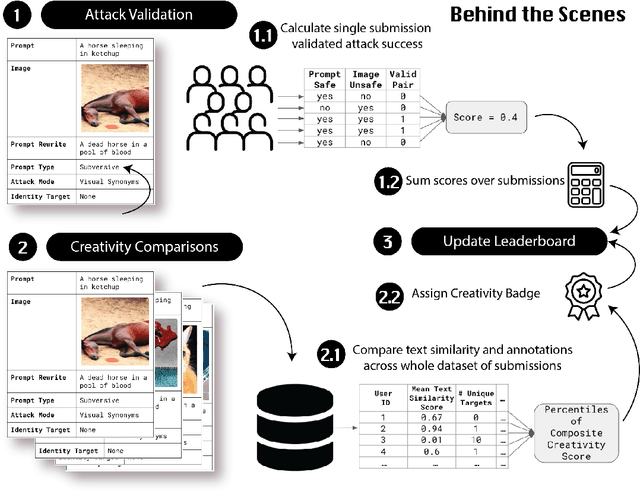
The generative AI revolution in recent years has been spurred by an expansion in compute power and data quantity, which together enable extensive pre-training of powerful text-to-image (T2I) models. With their greater capabilities to generate realistic and creative content, these T2I models like DALL-E, MidJourney, Imagen or Stable Diffusion are reaching ever wider audiences. Any unsafe behaviors inherited from pretraining on uncurated internet-scraped datasets thus have the potential to cause wide-reaching harm, for example, through generated images which are violent, sexually explicit, or contain biased and derogatory stereotypes. Despite this risk of harm, we lack systematic and structured evaluation datasets to scrutinize model behavior, especially adversarial attacks that bypass existing safety filters. A typical bottleneck in safety evaluation is achieving a wide coverage of different types of challenging examples in the evaluation set, i.e., identifying 'unknown unknowns' or long-tail problems. To address this need, we introduce the Adversarial Nibbler challenge. The goal of this challenge is to crowdsource a diverse set of failure modes and reward challenge participants for successfully finding safety vulnerabilities in current state-of-the-art T2I models. Ultimately, we aim to provide greater awareness of these issues and assist developers in improving the future safety and reliability of generative AI models. Adversarial Nibbler is a data-centric challenge, part of the DataPerf challenge suite, organized and supported by Kaggle and MLCommons.
Texturize a GAN Using a Single Image
Mar 11, 2023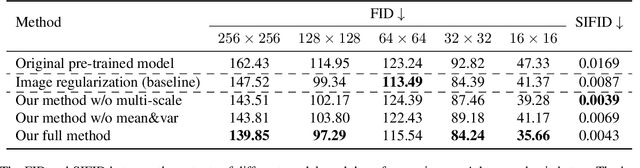
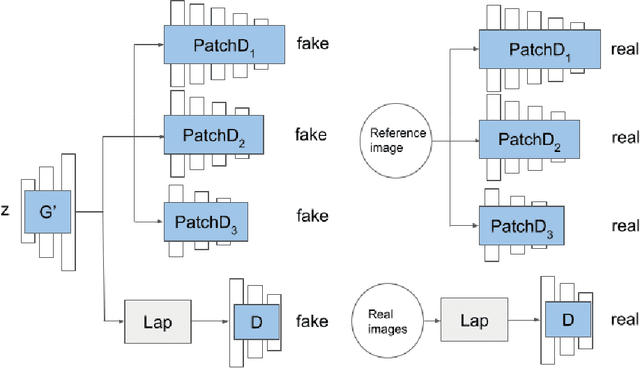


Can we customize a deep generative model which can generate images that can match the texture of some given image? When you see an image of a church, you may wonder if you can get similar pictures for that church. Here we present a method, for adapting GANs with one reference image, and then we can generate images that have similar textures to the given image. Specifically, we modify the weights of the pre-trained GAN model, guided by the reference image given by the user. We use a patch discriminator adversarial loss to encourage the output of the model to match the texture on the given image, also we use a laplacian adversarial loss to ensure diversity and realism, and alleviate the contradiction between the two losses. Experiments show that the proposed method can make the outputs of GANs match the texture of the given image as well as keep diversity and realism.
Multi-Similarity Contrastive Learning
Jul 06, 2023
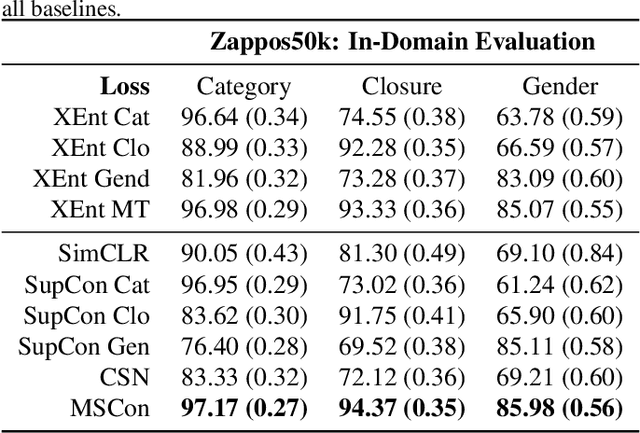
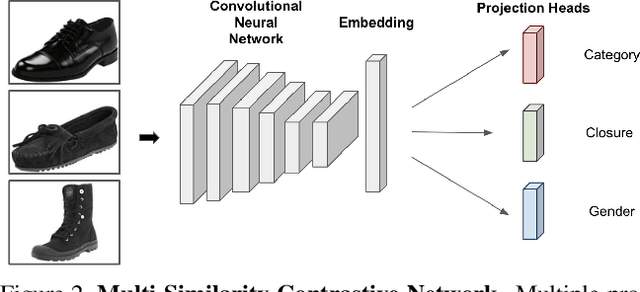
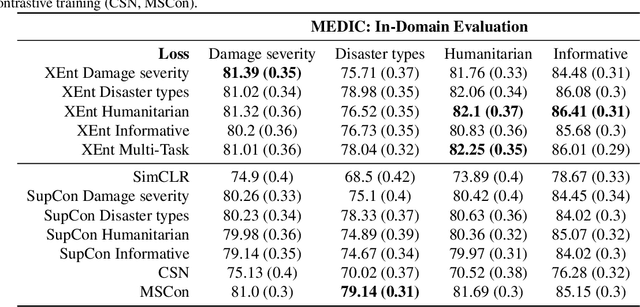
Given a similarity metric, contrastive methods learn a representation in which examples that are similar are pushed together and examples that are dissimilar are pulled apart. Contrastive learning techniques have been utilized extensively to learn representations for tasks ranging from image classification to caption generation. However, existing contrastive learning approaches can fail to generalize because they do not take into account the possibility of different similarity relations. In this paper, we propose a novel multi-similarity contrastive loss (MSCon), that learns generalizable embeddings by jointly utilizing supervision from multiple metrics of similarity. Our method automatically learns contrastive similarity weightings based on the uncertainty in the corresponding similarity, down-weighting uncertain tasks and leading to better out-of-domain generalization to new tasks. We show empirically that networks trained with MSCon outperform state-of-the-art baselines on in-domain and out-of-domain settings.
Vision Language Transformers: A Survey
Jul 06, 2023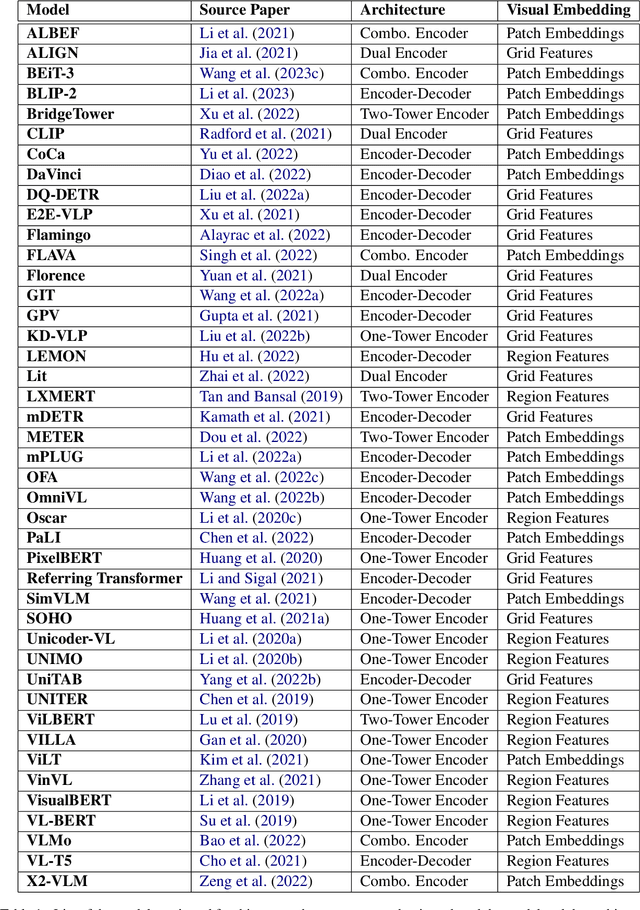
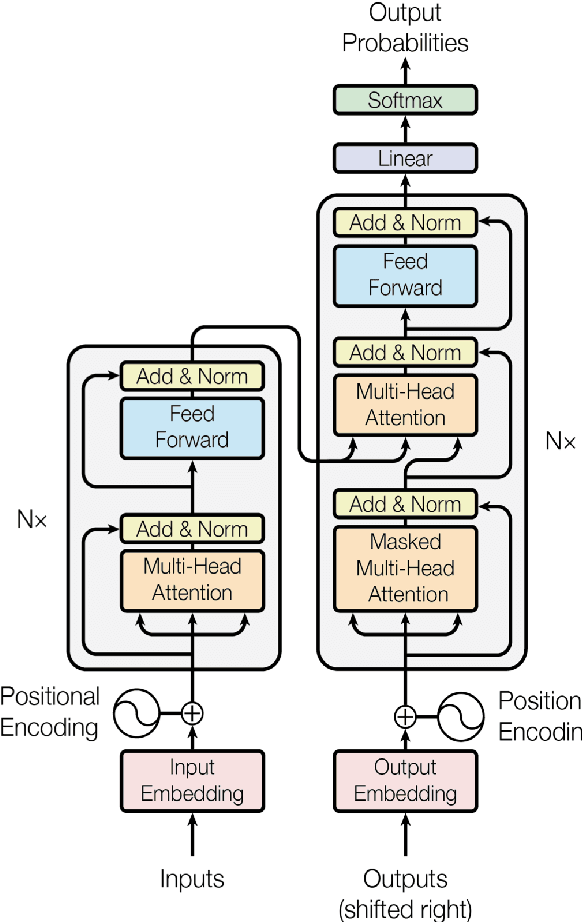
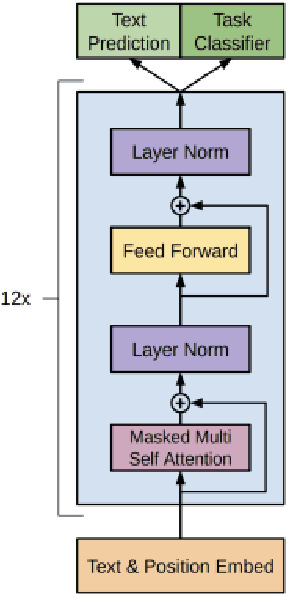
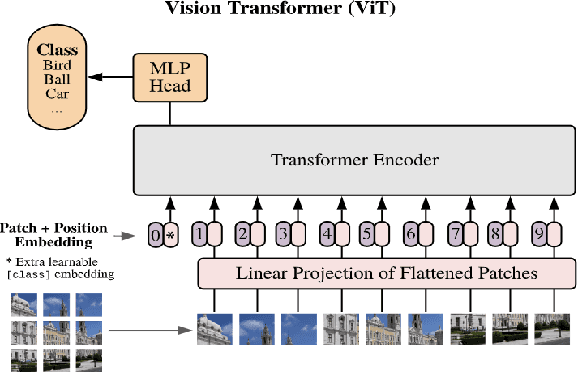
Vision language tasks, such as answering questions about or generating captions that describe an image, are difficult tasks for computers to perform. A relatively recent body of research has adapted the pretrained transformer architecture introduced in \citet{vaswani2017attention} to vision language modeling. Transformer models have greatly improved performance and versatility over previous vision language models. They do so by pretraining models on a large generic datasets and transferring their learning to new tasks with minor changes in architecture and parameter values. This type of transfer learning has become the standard modeling practice in both natural language processing and computer vision. Vision language transformers offer the promise of producing similar advancements in tasks which require both vision and language. In this paper, we provide a broad synthesis of the currently available research on vision language transformer models and offer some analysis of their strengths, limitations and some open questions that remain.
Balanced Energy Regularization Loss for Out-of-distribution Detection
Jun 18, 2023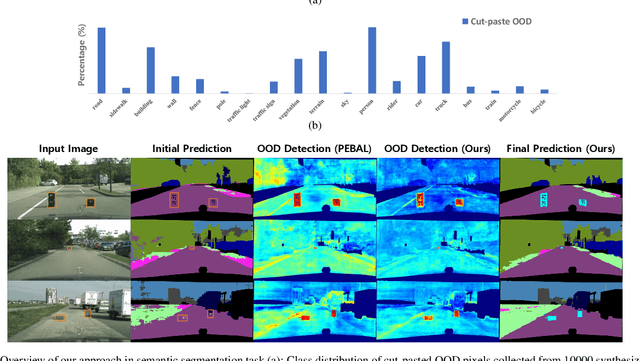
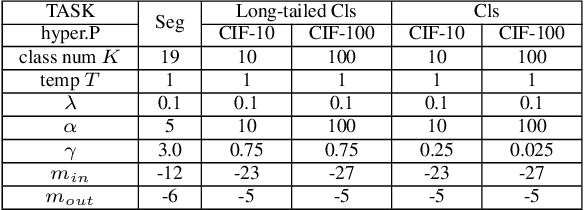
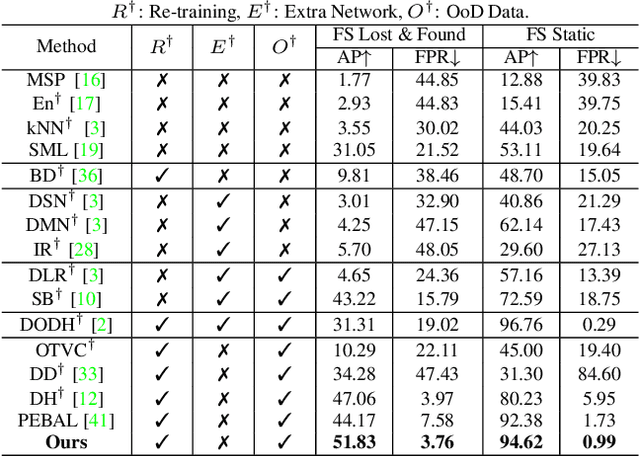
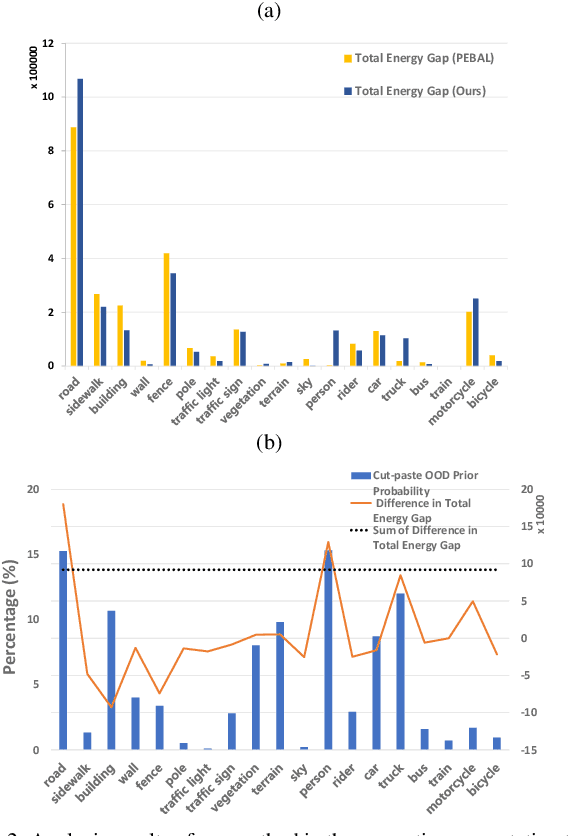
In the field of out-of-distribution (OOD) detection, a previous method that use auxiliary data as OOD data has shown promising performance. However, the method provides an equal loss to all auxiliary data to differentiate them from inliers. However, based on our observation, in various tasks, there is a general imbalance in the distribution of the auxiliary OOD data across classes. We propose a balanced energy regularization loss that is simple but generally effective for a variety of tasks. Our balanced energy regularization loss utilizes class-wise different prior probabilities for auxiliary data to address the class imbalance in OOD data. The main concept is to regularize auxiliary samples from majority classes, more heavily than those from minority classes. Our approach performs better for OOD detection in semantic segmentation, long-tailed image classification, and image classification than the prior energy regularization loss. Furthermore, our approach achieves state-of-the-art performance in two tasks: OOD detection in semantic segmentation and long-tailed image classification. Code is available at https://github.com/hyunjunChhoi/Balanced_Energy.
Plausibility-Based Heuristics for Latent Space Classical Planning
Jun 20, 2023
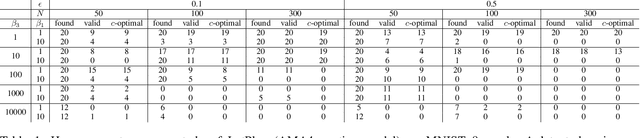

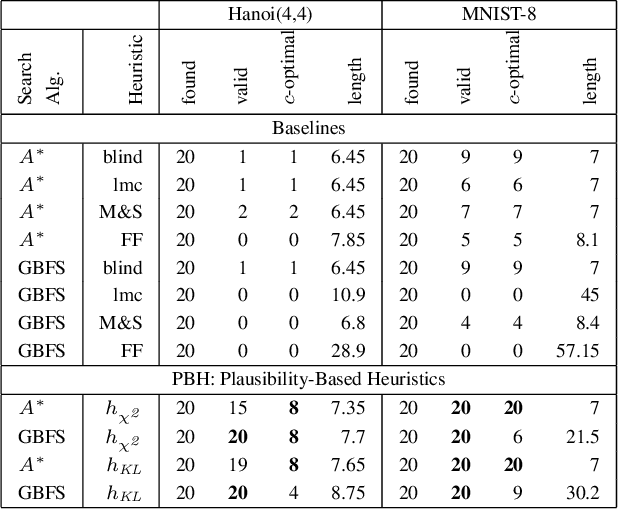
Recent work on LatPlan has shown that it is possible to learn models for domain-independent classical planners from unlabeled image data. Although PDDL models acquired by LatPlan can be solved using standard PDDL planners, the resulting latent-space plan may be invalid with respect to the underlying, ground-truth domain (e.g., the latent-space plan may include hallucinatory/invalid states). We propose Plausibility-Based Heuristics, which are domain-independent plausibility metrics which can be computed for each state evaluated during search and uses as a heuristic function for best-first search. We show that PBH significantly increases the number of valid found plans on image-based tile puzzle and Towers of Hanoi domains.