 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RefSAM: Efficiently Adapting Segmenting Anything Model for Referring Video Object Segmentation
Jul 03, 2023
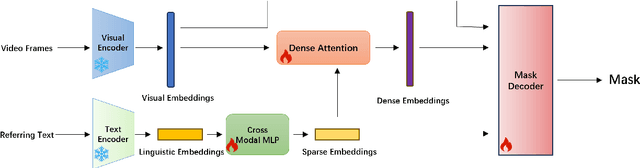

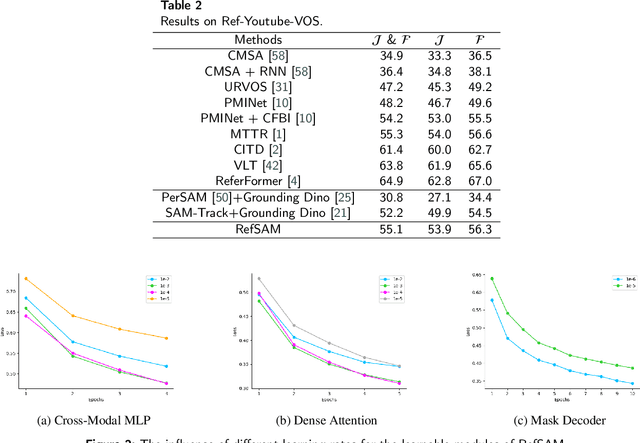

The Segment Anything Model (SAM) has gained significant attention for its impressive performance in image segmentation. However, it lacks proficiency in referring video object segmentation (RVOS) due to the need for precise user-interactive prompts and limited understanding of different modalities, such as language and vision. This paper presents the RefSAM model, which for the first time explores the potential of SAM for RVOS by incorporating multi-view information from diverse modalities and successive frames at different timestamps. Our proposed approach adapts the original SAM model to enhance cross-modality learning by employing a lightweight Cross-Modal MLP that projects the text embedding of the referring expression into sparse and dense embeddings, serving as user-interactive prompts. Subsequently, a parameter-efficient tuning strategy is employed to effectively align and fuse the language and vision features. Through comprehensive ablation studies, we demonstrate the practical and effective design choices of our strategy. Extensive experiments conducted on Ref-Youtu-VOS and Ref-DAVIS17 datasets validate the superiority and effectiveness of our RefSAM model over existing methods. The code and models will be made publicly at \href{https://github.com/LancasterLi/RefSAM}{github.com/LancasterLi/RefSAM}.
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Jul 03, 2023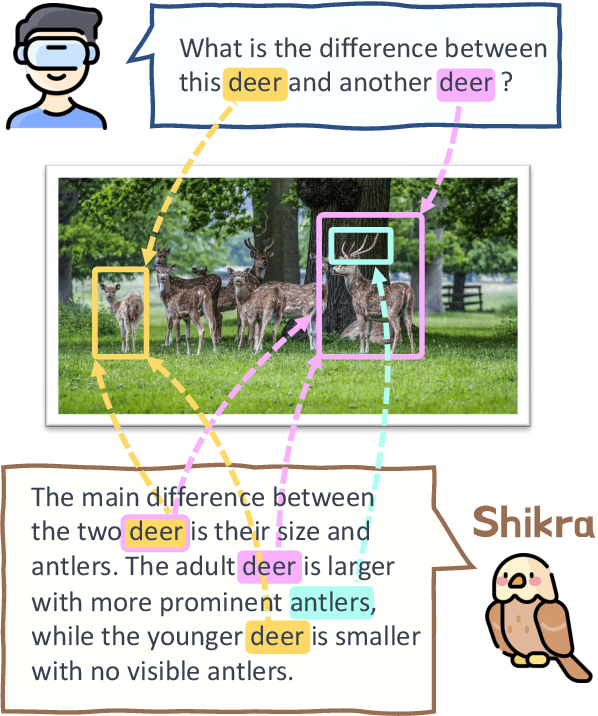
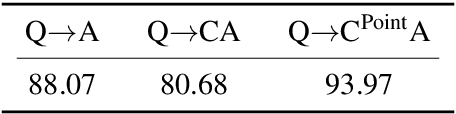

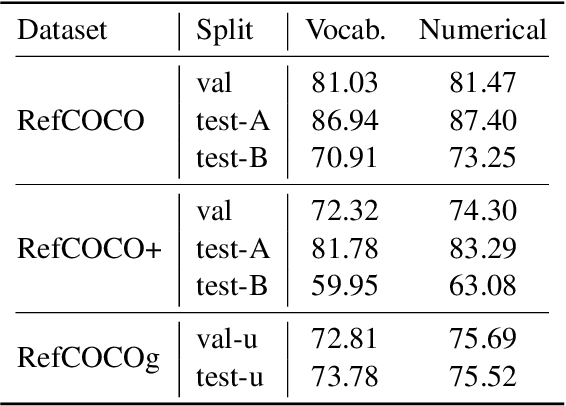
In human conversations, individuals can indicate relevant regions within a scene while addressing others. In turn, the other person can then respond by referring to specific regions if necessary. This natural referential ability in dialogue remains absent in current Multimodal Large Language Models (MLLMs). To fill this gap, this paper proposes an MLLM called Shikra, which can handle spatial coordinate inputs and outputs in natural language. Its architecture consists of a vision encoder, an alignment layer, and a LLM. It is designed to be straightforward and simple, without the need for extra vocabularies, position encoder, pre-/post-detection modules, or external plug-in models. All inputs and outputs are in natural language form. Referential dialogue is a superset of various vision-language (VL) tasks. Shikra can naturally handle location-related tasks like REC and PointQA, as well as conventional VL tasks such as Image Captioning and VQA. Experimental results showcase Shikra's promising performance. Furthermore, it enables numerous exciting applications, like providing mentioned objects' coordinates in chains of thoughts and comparing user-pointed regions similarities. Our code, model and dataset are accessed at https://github.com/shikras/shikra.
Cross-modality Attention Adapter: A Glioma Segmentation Fine-tuning Method for SAM Using Multimodal Brain MR Images
Jul 03, 2023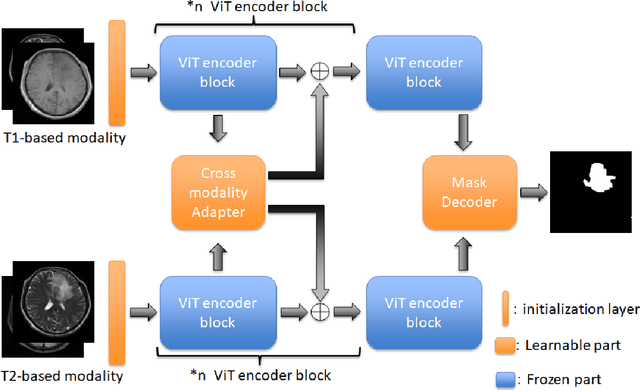
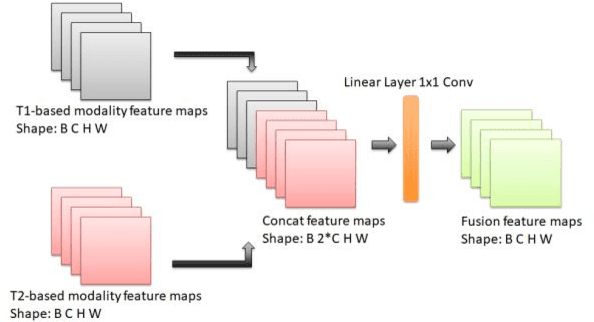

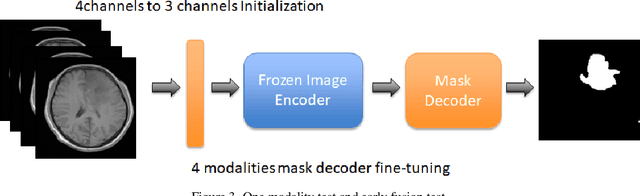
According to the 2021 World Health Organization (WHO) Classification scheme for gliomas, glioma segmentation is a very important basis for diagnosis and genotype prediction. In general, 3D multimodal brain MRI is an effective diagnostic tool. In the past decade, there has been an increase in the use of machine learning, particularly deep learning, for medical images processing. Thanks to the development of foundation models, models pre-trained with large-scale datasets have achieved better results on a variety of tasks. However, for medical images with small dataset sizes, deep learning methods struggle to achieve better results on real-world image datasets. In this paper, we propose a cross-modality attention adapter based on multimodal fusion to fine-tune the foundation model to accomplish the task of glioma segmentation in multimodal MRI brain images with better results. The effectiveness of the proposed method is validated via our private glioma data set from the First Affiliated Hospital of Zhengzhou University (FHZU) in Zhengzhou, China. Our proposed method is superior to current state-of-the-art methods with a Dice of 88.38% and Hausdorff distance of 10.64, thereby exhibiting a 4% increase in Dice to segment the glioma region for glioma treatment.
Energy-Efficient Routing Protocol Based on Multi-Threshold Segmentation in Wireless Sensors Networks for Precision Agriculture
Jul 03, 2023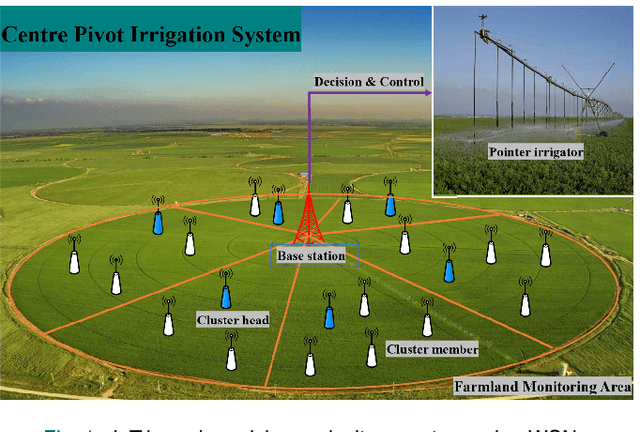
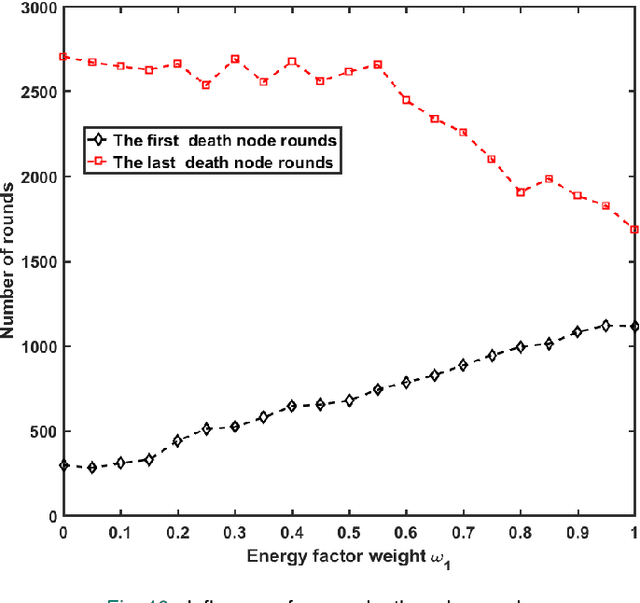
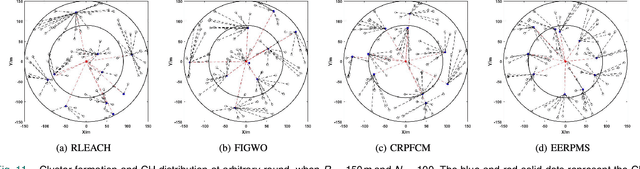
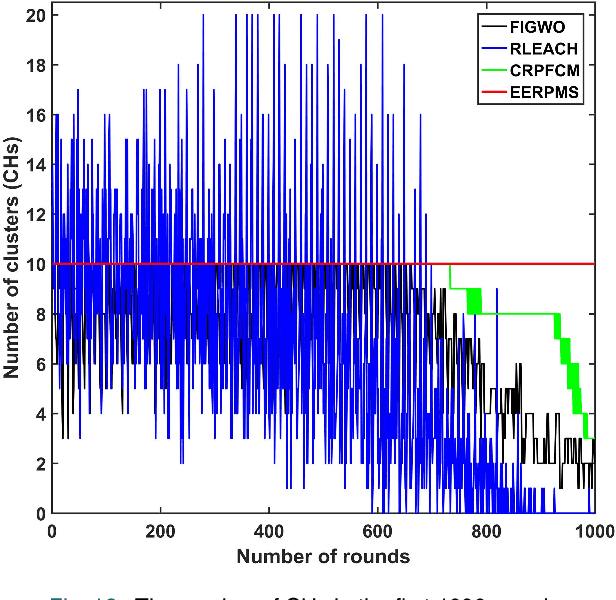
Wireless sensor networks (WSNs), one of the fundamental technologies of the Internet of Things (IoT), can provide sensing and communication services efficiently for IoT-based applications, especially energy-limited applications. Clustering routing protocol plays an important role in reducing energy consumption and prolonging network lifetime. The cluster formation and cluster head selection are the key to improving the performance of the clustering routing protocol. An energy-efficient routing protocol based on multi-threshold segmentation (EERPMS) was proposed in this paper to improve the rationality of cluster formation and cluster head selection. In the stage of cluster formation, inspired by multi-threshold image segmentation, an innovative node clustering algorithm was developed. In the stage of cluster head selection, aiming at minimizing the network energy consumption, a calculation theory of the optimal number and location of cluster heads was established. Furthermore, a novel cluster head selection algorithm was constructed based on the residual energy and optimal location of cluster heads. Simulation results show that EERPMS can improve the distribution uniformity of cluster heads, prolong the network lifetime and save up to 64.50%, 58.60%, and 56.15% network energy as compared to RLEACH, CRPFCM, and FIGWO protocols respectively.
* 16 pages, 24 figure, 4 tables
Feasibility of Universal Anomaly Detection without Knowing the Abnormality in Medical Images
Jul 03, 2023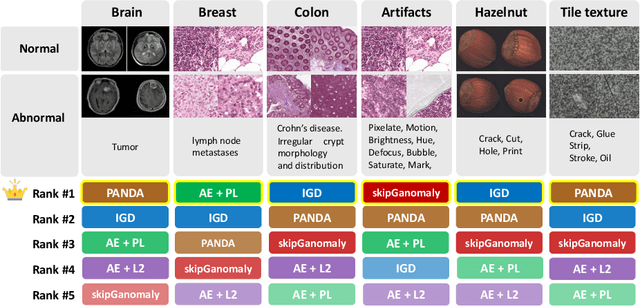
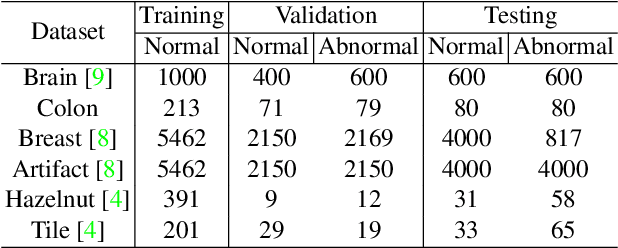
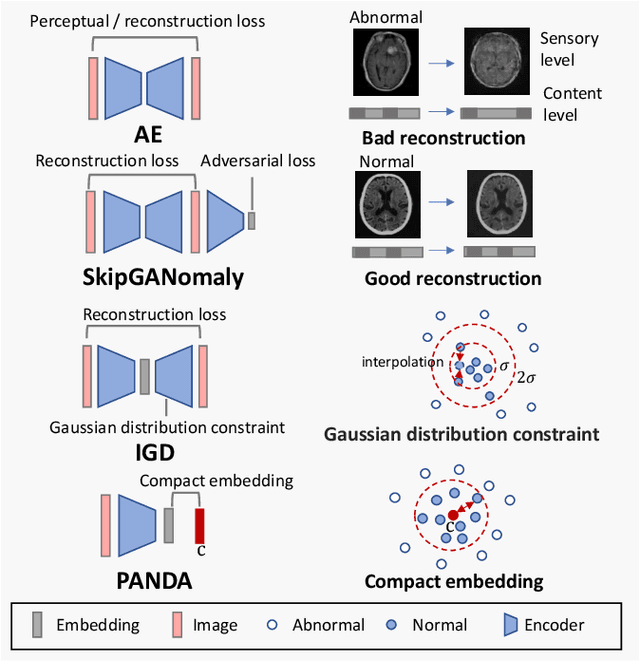
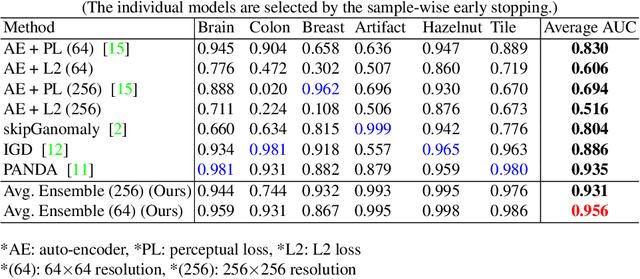
Many anomaly detection approaches, especially deep learning methods, have been recently developed to identify abnormal image morphology by only employing normal images during training. Unfortunately, many prior anomaly detection methods were optimized for a specific "known" abnormality (e.g., brain tumor, bone fraction, cell types). Moreover, even though only the normal images were used in the training process, the abnormal images were oftenly employed during the validation process (e.g., epoch selection, hyper-parameter tuning), which might leak the supposed ``unknown" abnormality unintentionally. In this study, we investigated these two essential aspects regarding universal anomaly detection in medical images by (1) comparing various anomaly detection methods across four medical datasets, (2) investigating the inevitable but often neglected issues on how to unbiasedly select the optimal anomaly detection model during the validation phase using only normal images, and (3) proposing a simple decision-level ensemble method to leverage the advantage of different kinds of anomaly detection without knowing the abnormality. The results of our experiments indicate that none of the evaluated methods consistently achieved the best performance across all datasets. Our proposed method enhanced the robustness of performance in general (average AUC 0.956).
Multi-network Contrastive Learning Based on Global and Local Representations
Jun 28, 2023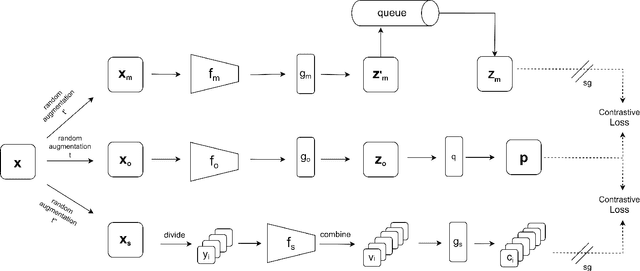
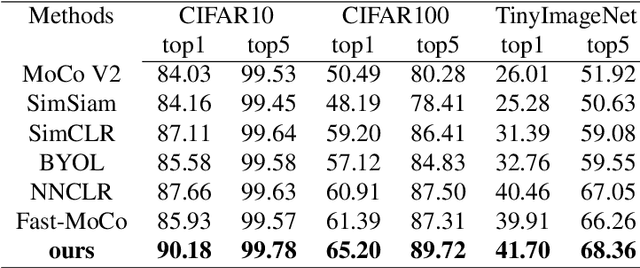

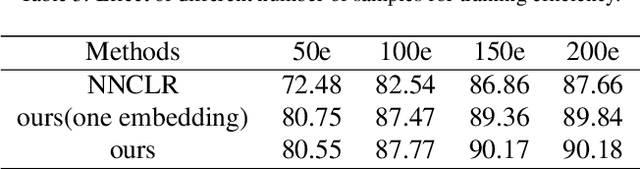
The popularity of self-supervised learning has made it possible to train models without relying on labeled data, which saves expensive annotation costs. However, most existing self-supervised contrastive learning methods often overlook the combination of global and local feature information. This paper proposes a multi-network contrastive learning framework based on global and local representations. We introduce global and local feature information for self-supervised contrastive learning through multiple networks. The model learns feature information at different scales of an image by contrasting the embedding pairs generated by multiple networks. The framework also expands the number of samples used for contrast and improves the training efficiency of the model. Linear evaluation results on three benchmark datasets show that our method outperforms several existing classical self-supervised learning methods.
When to Use Efficient Self Attention? Profiling Text, Speech and Image Transformer Variants
Jun 14, 2023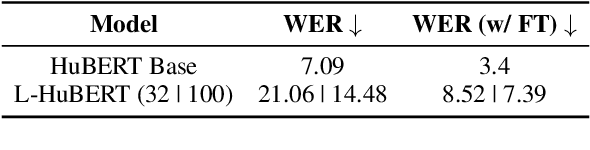
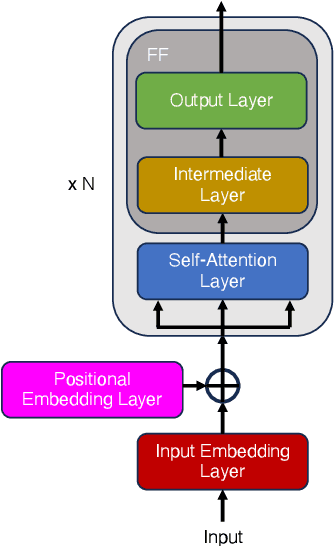
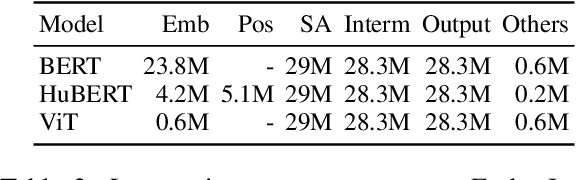
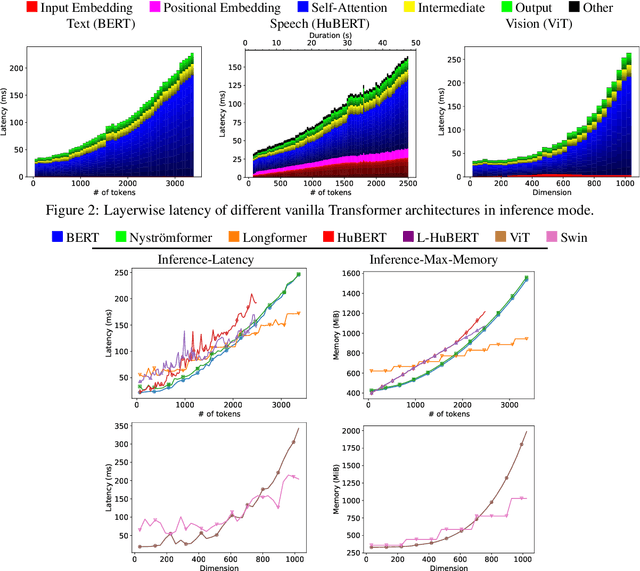
We present the first unified study of the efficiency of self-attention-based Transformer variants spanning text, speech and vision. We identify input length thresholds (tipping points) at which efficient Transformer variants become more efficient than vanilla models, using a variety of efficiency metrics (latency, throughput, and memory). To conduct this analysis for speech, we introduce L-HuBERT, a novel local-attention variant of a self-supervised speech model. We observe that these thresholds are (a) much higher than typical dataset sequence lengths and (b) dependent on the metric and modality, showing that choosing the right model depends on modality, task type (long-form vs. typical context) and resource constraints (time vs. memory). By visualising the breakdown of the computational costs for transformer components, we also show that non-self-attention components exhibit significant computational costs. We release our profiling toolkit at https://github.com/ajd12342/profiling-transformers .
Inversion by Direct Iteration: An Alternative to Denoising Diffusion for Image Restoration
Mar 20, 2023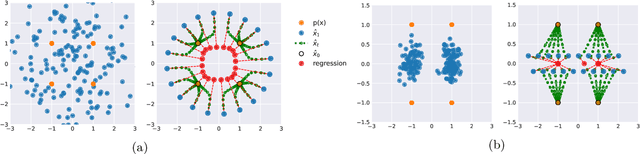
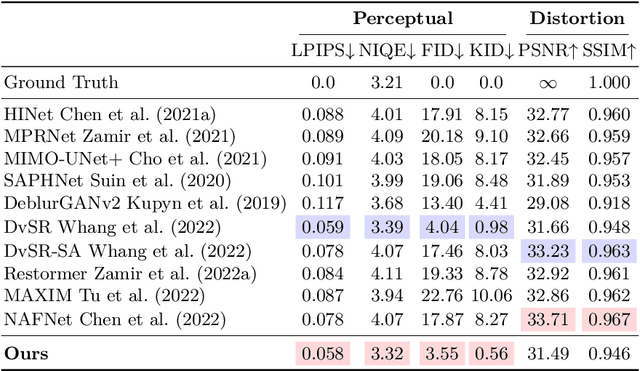


Inversion by Direct Iteration (InDI) is a new formulation for supervised image restoration that avoids the so-called ``regression to the mean'' effect and produces more realistic and detailed images than existing regression-based methods. It does this by gradually improving image quality in small steps, similar to generative denoising diffusion models. Image restoration is an ill-posed problem where multiple high-quality images are plausible reconstructions of a given low-quality input. Therefore, the outcome of a single step regression model is typically an aggregate of all possible explanations, therefore lacking details and realism. % The main advantage of InDI is that it does not try to predict the clean target image in a single step but instead gradually improves the image in small steps, resulting in better perceptual quality. While generative denoising diffusion models also work in small steps, our formulation is distinct in that it does not require knowledge of any analytic form of the degradation process. Instead, we directly learn an iterative restoration process from low-quality and high-quality paired examples. InDI can be applied to virtually any image degradation, given paired training data. In conditional denoising diffusion image restoration the denoising network generates the restored image by repeatedly denoising an initial image of pure noise, conditioned on the degraded input. Contrary to conditional denoising formulations, InDI directly proceeds by iteratively restoring the input low-quality image, producing high-quality results on a variety of image restoration tasks, including motion and out-of-focus deblurring, super-resolution, compression artifact removal, and denoising.
Likelihood-Based Generative Radiance Field with Latent Space Energy-Based Model for 3D-Aware Disentangled Image Representation
Apr 16, 2023
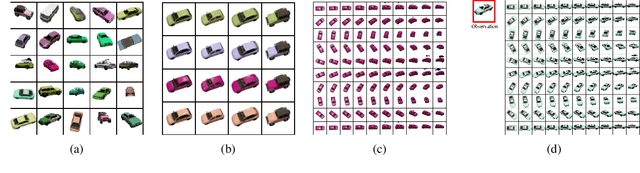

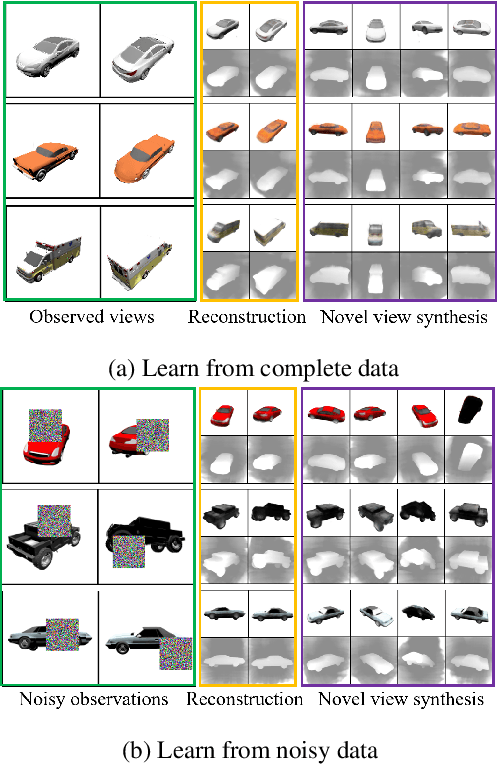
We propose the NeRF-LEBM, a likelihood-based top-down 3D-aware 2D image generative model that incorporates 3D representation via Neural Radiance Fields (NeRF) and 2D imaging process via differentiable volume rendering. The model represents an image as a rendering process from 3D object to 2D image and is conditioned on some latent variables that account for object characteristics and are assumed to follow informative trainable energy-based prior models. We propose two likelihood-based learning frameworks to train the NeRF-LEBM: (i) maximum likelihood estimation with Markov chain Monte Carlo-based inference and (ii) variational inference with the reparameterization trick. We study our models in the scenarios with both known and unknown camera poses. Experiments on several benchmark datasets demonstrate that the NeRF-LEBM can infer 3D object structures from 2D images, generate 2D images with novel views and objects, learn from incomplete 2D images, and learn from 2D images with known or unknown camera poses.
Compete to Win: Enhancing Pseudo Labels for Barely-supervised Medical Image Segmentation
Apr 15, 2023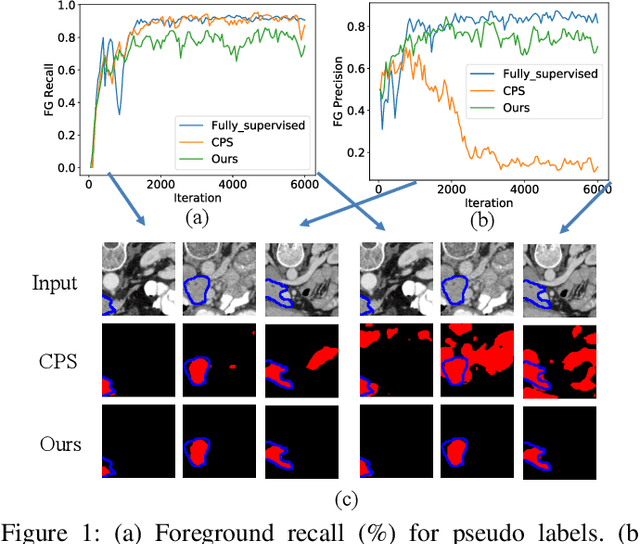
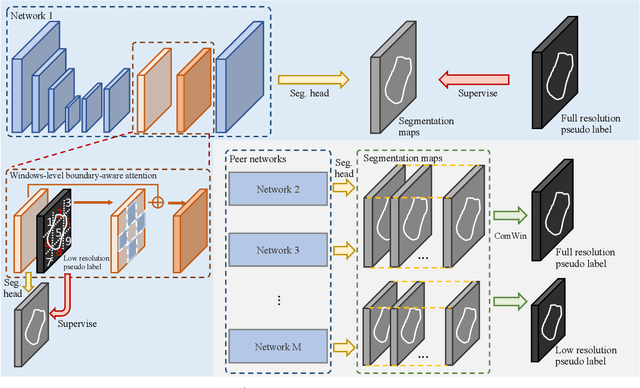
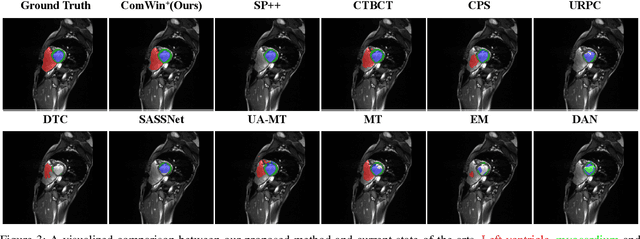
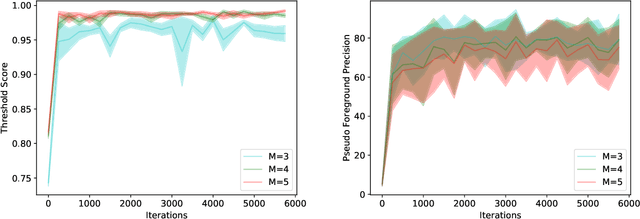
This study investigates barely-supervised medical image segmentation where only few labeled data, i.e., single-digit cases are available. We observe the key limitation of the existing state-of-the-art semi-supervised solution cross pseudo supervision is the unsatisfactory precision of foreground classes, leading to a degenerated result under barely-supervised learning. In this paper, we propose a novel Compete-to-Win method (ComWin) to enhance the pseudo label quality. In contrast to directly using one model's predictions as pseudo labels, our key idea is that high-quality pseudo labels should be generated by comparing multiple confidence maps produced by different networks to select the most confident one (a compete-to-win strategy). To further refine pseudo labels at near-boundary areas, an enhanced version of ComWin, namely, ComWin+, is proposed by integrating a boundary-aware enhancement module. Experiments show that our method can achieve the best performance on three public medical image datasets for cardiac structure segmentation, pancreas segmentation and colon tumor segmentation, respectively. The source code is now available at https://github.com/Huiimin5/comwin.