 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning A Sparse Transformer Network for Effective Image Deraining
Mar 21, 2023

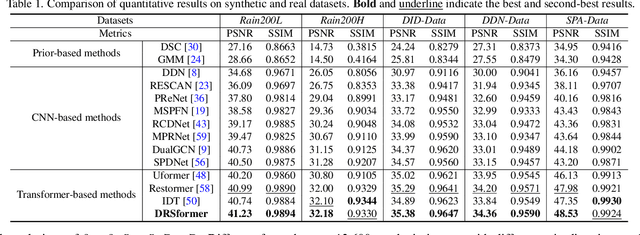
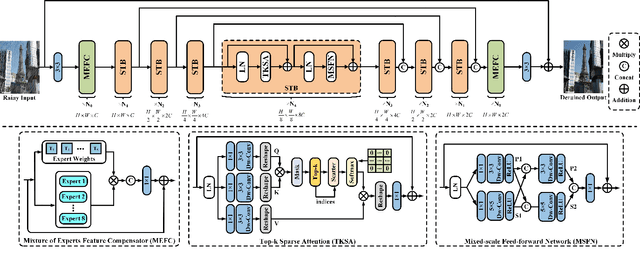

Transformers-based methods have achieved significant performance in image deraining as they can model the non-local information which is vital for high-quality image reconstruction. In this paper, we find that most existing Transformers usually use all similarities of the tokens from the query-key pairs for the feature aggregation. However, if the tokens from the query are different from those of the key, the self-attention values estimated from these tokens also involve in feature aggregation, which accordingly interferes with the clear image restoration. To overcome this problem, we propose an effective DeRaining network, Sparse Transformer (DRSformer) that can adaptively keep the most useful self-attention values for feature aggregation so that the aggregated features better facilitate high-quality image reconstruction. Specifically, we develop a learnable top-k selection operator to adaptively retain the most crucial attention scores from the keys for each query for better feature aggregation. Simultaneously, as the naive feed-forward network in Transformers does not model the multi-scale information that is important for latent clear image restoration, we develop an effective mixed-scale feed-forward network to generate better features for image deraining. To learn an enriched set of hybrid features, which combines local context from CNN operators, we equip our model with mixture of experts feature compensator to present a cooperation refinement deraining scheme. Extensive experimental results on the commonly used benchmarks demonstrate that the proposed method achieves favorable performance against state-of-the-art approaches. The source code and trained models are available at https://github.com/cschenxiang/DRSformer.
* Accepted as a highlight paper in CVPR 2023
I2Edit: Towards Multi-turn Interactive Image Editing via Dialogue
Mar 20, 2023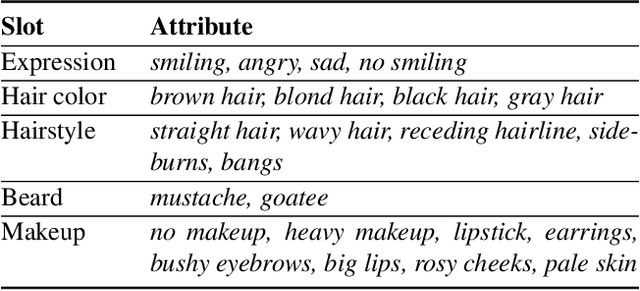

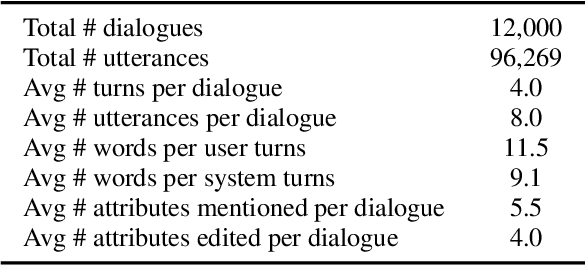
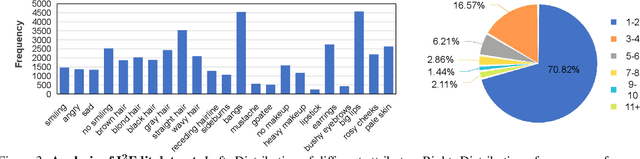
Although there have been considerable research efforts on controllable facial image editing, the desirable interactive setting where the users can interact with the system to adjust their requirements dynamically hasn't been well explored. This paper focuses on facial image editing via dialogue and introduces a new benchmark dataset, Multi-turn Interactive Image Editing (I2Edit), for evaluating image editing quality and interaction ability in real-world interactive facial editing scenarios. The dataset is constructed upon the CelebA-HQ dataset with images annotated with a multi-turn dialogue that corresponds to the user editing requirements. I2Edit is challenging, as it needs to 1) track the dynamically updated user requirements and edit the images accordingly, as well as 2) generate the appropriate natural language response to communicate with the user. To address these challenges, we propose a framework consisting of a dialogue module and an image editing module. The former is for user edit requirements tracking and generating the corresponding indicative responses, while the latter edits the images conditioned on the tracked user edit requirements. In contrast to previous works that simply treat multi-turn interaction as a sequence of single-turn interactions, we extract the user edit requirements from the whole dialogue history instead of the current single turn. The extracted global user edit requirements enable us to directly edit the input raw image to avoid error accumulation and attribute forgetting issues. Extensive quantitative and qualitative experiments on the I2Edit dataset demonstrate the advantage of our proposed framework over the previous single-turn methods. We believe our new dataset could serve as a valuable resource to push forward the exploration of real-world, complex interactive image editing. Code and data will be made public.
Exploring the Power of Generative Deep Learning for Image-to-Image Translation and MRI Reconstruction: A Cross-Domain Review
Mar 16, 2023


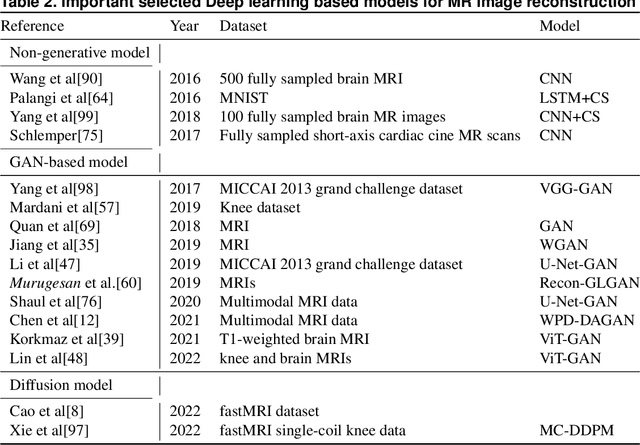
Deep learning has become a prominent computational modeling tool in the areas of computer vision and image processing in recent years. This research comprehensively analyzes the different deep-learning methods used for image-to-image translation and reconstruction in the natural and medical imaging domains. We examine the famous deep learning frameworks, such as convolutional neural networks and generative adversarial networks, and their variants, delving into the fundamental principles and difficulties of each. In the field of natural computer vision, we investigate the development and extension of various deep-learning generative models. In comparison, we investigate the possible applications of deep learning to generative medical imaging problems, including medical image translation, MRI reconstruction, and multi-contrast MRI synthesis. This thorough review provides scholars and practitioners in the areas of generative computer vision and medical imaging with useful insights for summarizing past works and getting insight into future research paths.
Discriminative Class Tokens for Text-to-Image Diffusion Models
Mar 30, 2023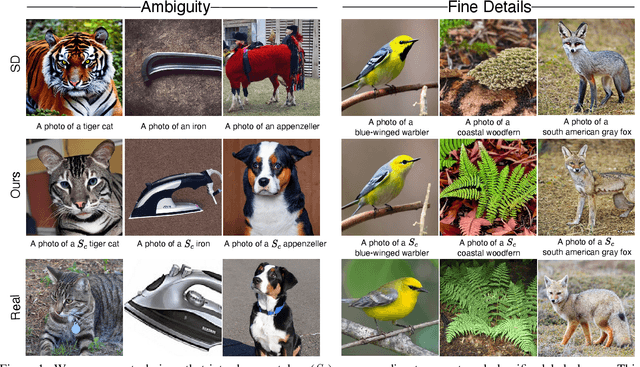
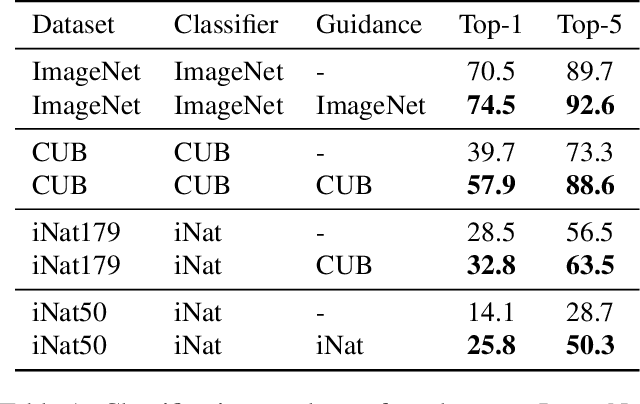
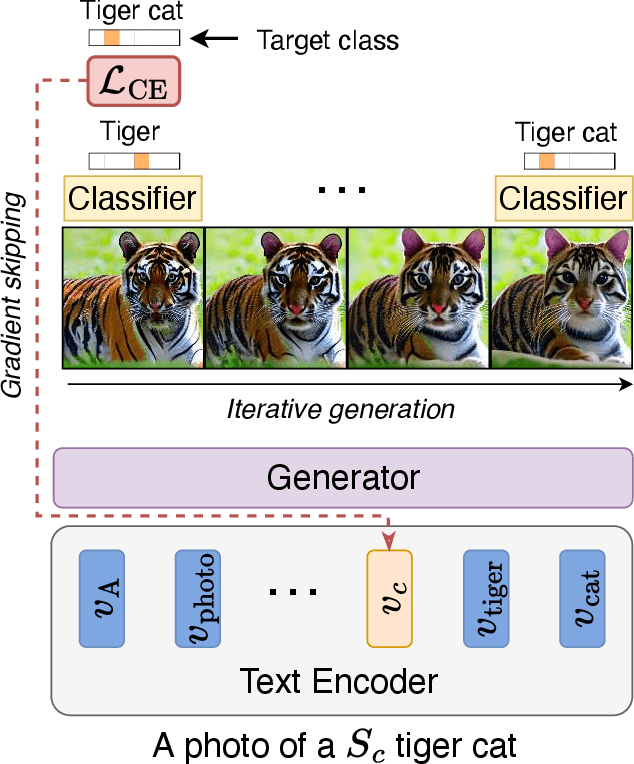
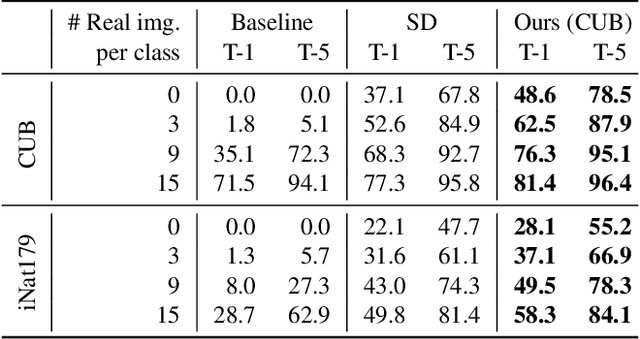
Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. However, generated images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This comes with a downside, doing so limits their expressive power: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, and so the quality and diversity of generated images are severely affected, or (ii) the input is a hard-coded label, as opposed to free-form text, which limits the control over the generated images. In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier. The code is available at \url{https://github.com/idansc/discriminative_class_tokens}
Learning Structure-Guided Diffusion Model for 2D Human Pose Estimation
Jun 29, 2023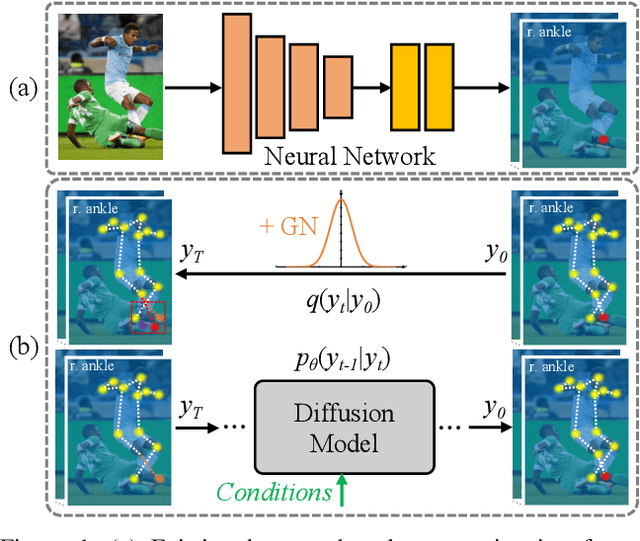

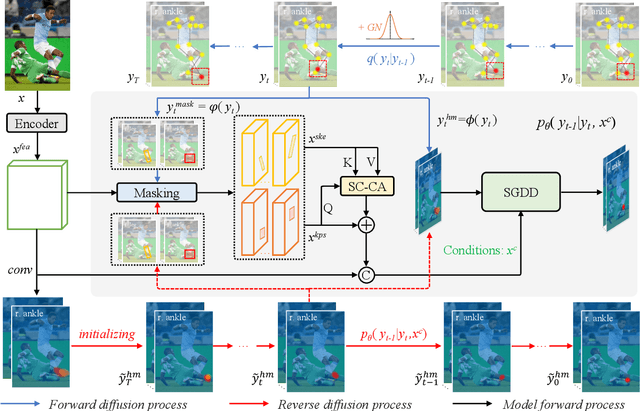
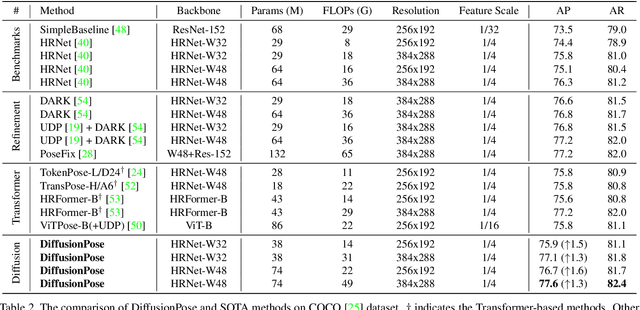
One of the mainstream schemes for 2D human pose estimation (HPE) is learning keypoints heatmaps by a neural network. Existing methods typically improve the quality of heatmaps by customized architectures, such as high-resolution representation and vision Transformers. In this paper, we propose \textbf{DiffusionPose}, a new scheme that formulates 2D HPE as a keypoints heatmaps generation problem from noised heatmaps. During training, the keypoints are diffused to random distribution by adding noises and the diffusion model learns to recover ground-truth heatmaps from noised heatmaps with respect to conditions constructed by image feature. During inference, the diffusion model generates heatmaps from initialized heatmaps in a progressive denoising way. Moreover, we further explore improving the performance of DiffusionPose with conditions from human structural information. Extensive experiments show the prowess of our DiffusionPose, with improvements of 1.6, 1.2, and 1.2 mAP on widely-used COCO, CrowdPose, and AI Challenge datasets, respectively.
Evaluation of Environmental Conditions on Object Detection using Oriented Bounding Boxes for AR Applications
Jun 29, 2023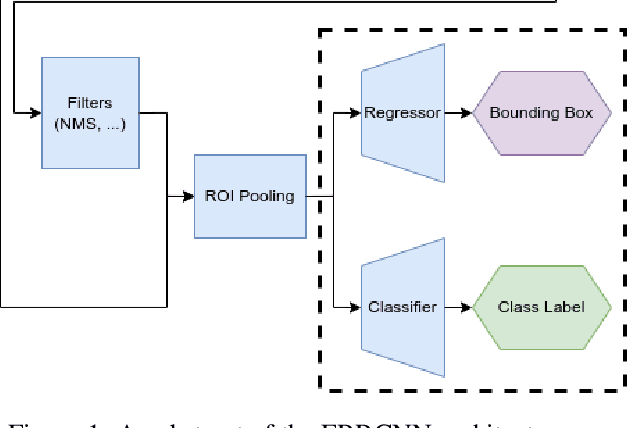
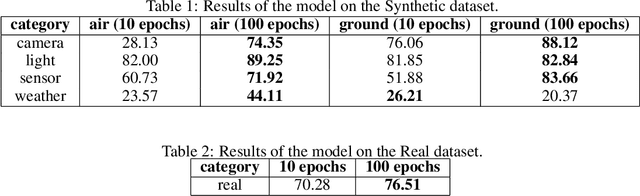

The objective of augmented reality (AR) is to add digital content to natural images and videos to create an interactive experience between the user and the environment. Scene analysis and object recognition play a crucial role in AR, as they must be performed quickly and accurately. In this study, a new approach is proposed that involves using oriented bounding boxes with a detection and recognition deep network to improve performance and processing time. The approach is evaluated using two datasets: a real image dataset (DOTA dataset) commonly used for computer vision tasks, and a synthetic dataset that simulates different environmental, lighting, and acquisition conditions. The focus of the evaluation is on small objects, which are difficult to detect and recognise. The results indicate that the proposed approach tends to produce better Average Precision and greater accuracy for small objects in most of the tested conditions.
Mask Reference Image Quality Assessment
Feb 27, 2023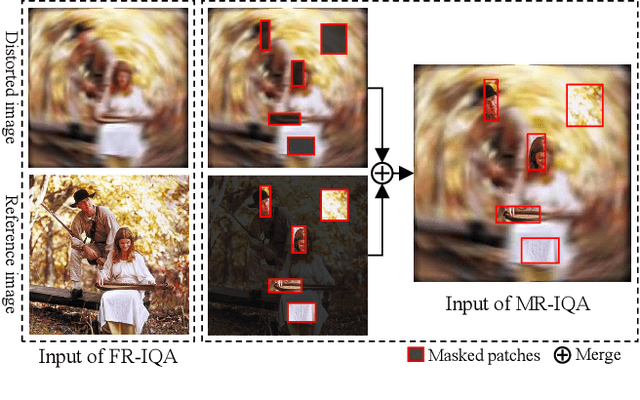

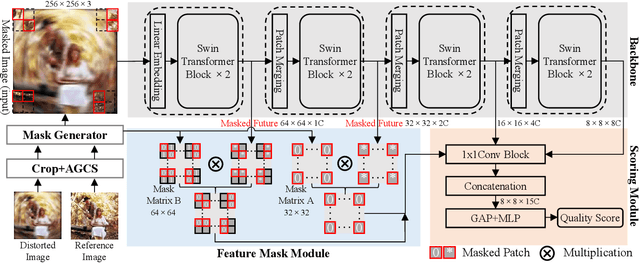
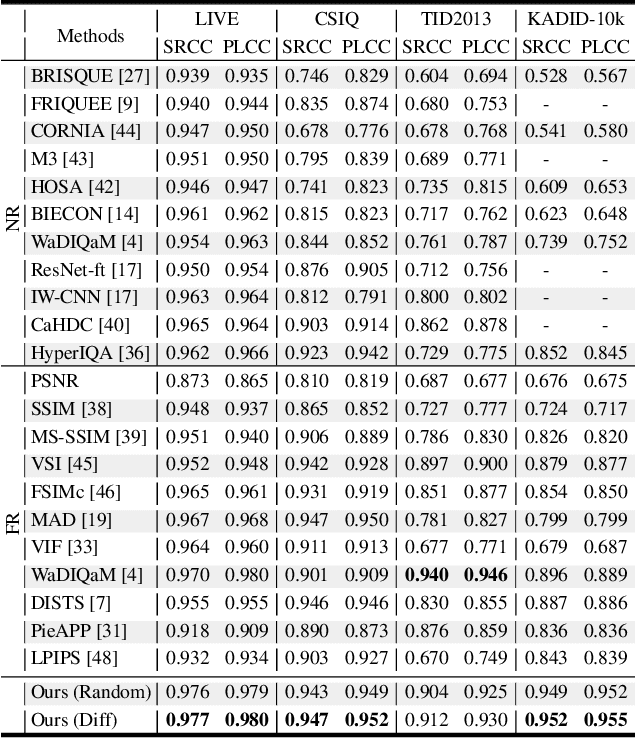
Understanding semantic information is an essential step in knowing what is being learned in both full-reference (FR) and no-reference (NR) image quality assessment (IQA) methods. However, especially for many severely distorted images, even if there is an undistorted image as a reference (FR-IQA), it is difficult to perceive the lost semantic and texture information of distorted images directly. In this paper, we propose a Mask Reference IQA (MR-IQA) method that masks specific patches of a distorted image and supplements missing patches with the reference image patches. In this way, our model only needs to input the reconstructed image for quality assessment. First, we design a mask generator to select the best candidate patches from reference images and supplement the lost semantic information in distorted images, thus providing more reference for quality assessment; in addition, the different masked patches imply different data augmentations, which favors model training and reduces overfitting. Second, we provide a Mask Reference Network (MRNet): the dedicated modules can prevent disturbances due to masked patches and help eliminate the patch discontinuity in the reconstructed image. Our method achieves state-of-the-art performances on the benchmark KADID-10k, LIVE and CSIQ datasets and has better generalization performance across datasets. The code and results are available in the supplementary material.
Semantic-Preserving Augmentation for Robust Image-Text Retrieval
Mar 10, 2023

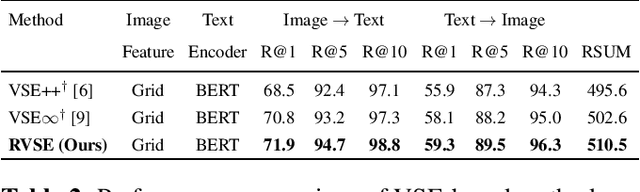
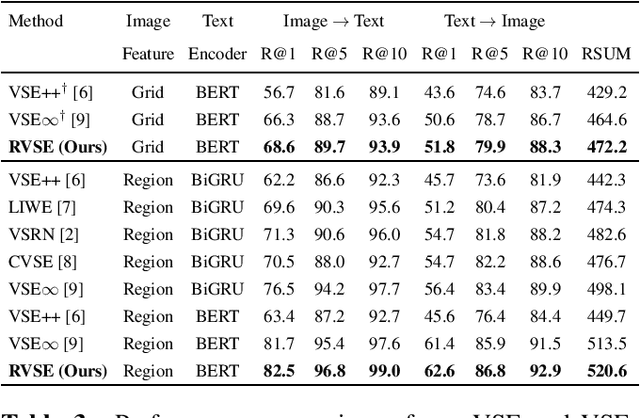
Image text retrieval is a task to search for the proper textual descriptions of the visual world and vice versa. One challenge of this task is the vulnerability to input image and text corruptions. Such corruptions are often unobserved during the training, and degrade the retrieval model decision quality substantially. In this paper, we propose a novel image text retrieval technique, referred to as robust visual semantic embedding (RVSE), which consists of novel image-based and text-based augmentation techniques called semantic preserving augmentation for image (SPAugI) and text (SPAugT). Since SPAugI and SPAugT change the original data in a way that its semantic information is preserved, we enforce the feature extractors to generate semantic aware embedding vectors regardless of the corruption, improving the model robustness significantly. From extensive experiments using benchmark datasets, we show that RVSE outperforms conventional retrieval schemes in terms of image-text retrieval performance.
Text-Conditioned Sampling Framework for Text-to-Image Generation with Masked Generative Models
Apr 04, 2023
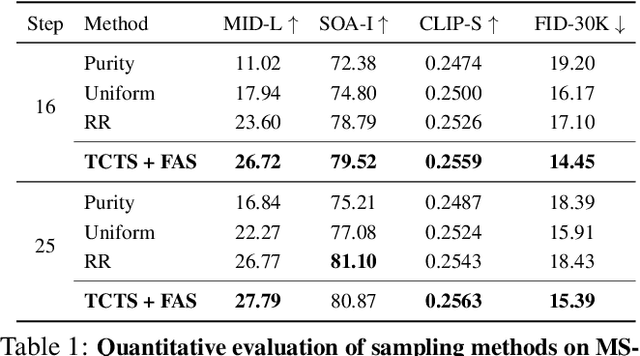

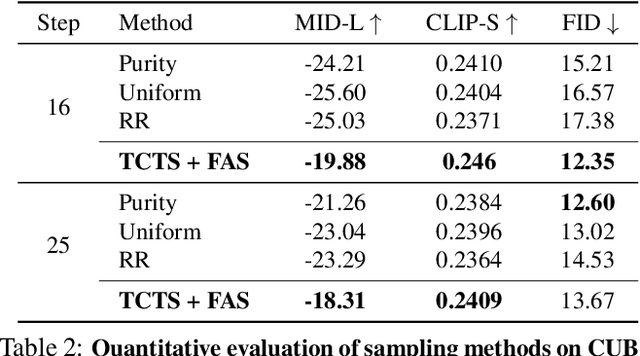
Token-based masked generative models are gaining popularity for their fast inference time with parallel decoding. While recent token-based approaches achieve competitive performance to diffusion-based models, their generation performance is still suboptimal as they sample multiple tokens simultaneously without considering the dependence among them. We empirically investigate this problem and propose a learnable sampling model, Text-Conditioned Token Selection (TCTS), to select optimal tokens via localized supervision with text information. TCTS improves not only the image quality but also the semantic alignment of the generated images with the given texts. To further improve the image quality, we introduce a cohesive sampling strategy, Frequency Adaptive Sampling (FAS), to each group of tokens divided according to the self-attention maps. We validate the efficacy of TCTS combined with FAS with various generative tasks, demonstrating that it significantly outperforms the baselines in image-text alignment and image quality. Our text-conditioned sampling framework further reduces the original inference time by more than 50% without modifying the original generative model.
Semantic Embedded Deep Neural Network: A Generic Approach to Boost Multi-Label Image Classification Performance
May 09, 2023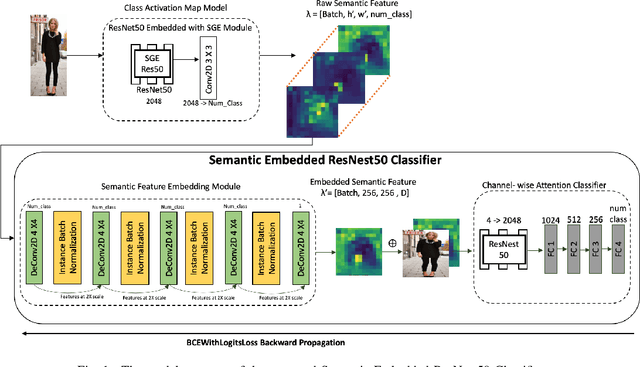
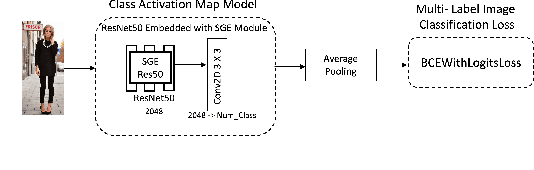

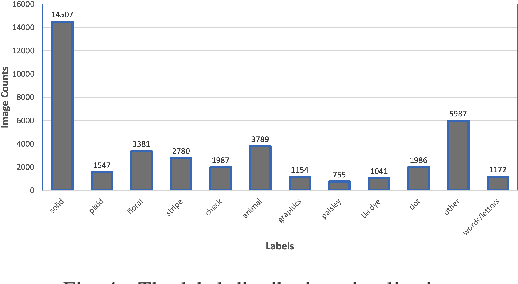
Fine-grained multi-label classification models have broad applications in Amazon production features, such as visual based label predictions ranging from fashion attribute detection to brand recognition. One challenge to achieve satisfactory performance for those classification tasks in real world is the wild visual background signal that contains irrelevant pixels which confuses model to focus onto the region of interest and make prediction upon the specific region. In this paper, we introduce a generic semantic-embedding deep neural network to apply the spatial awareness semantic feature incorporating a channel-wise attention based model to leverage the localization guidance to boost model performance for multi-label prediction. We observed an Avg.relative improvement of 15.27% in terms of AUC score across all labels compared to the baseline approach. Core experiment and ablation studies involve multi-label fashion attribute classification performed on Instagram fashion apparels' image. We compared the model performances among our approach, baseline approach, and 3 alternative approaches to leverage semantic features. Results show favorable performance for our approach.