 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Autoencoders for Real-Time SUEP Detection
Jun 26, 2023
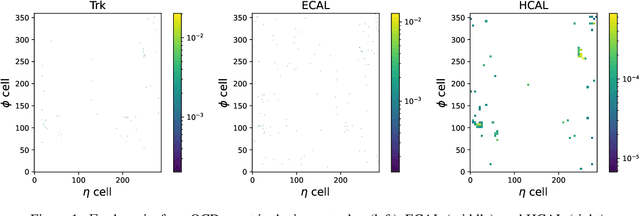
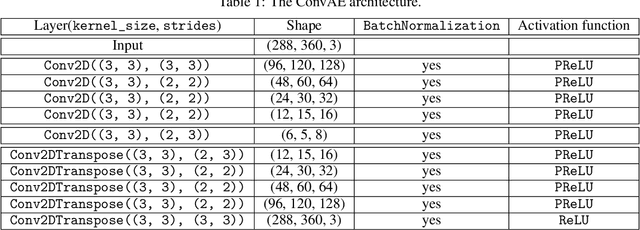
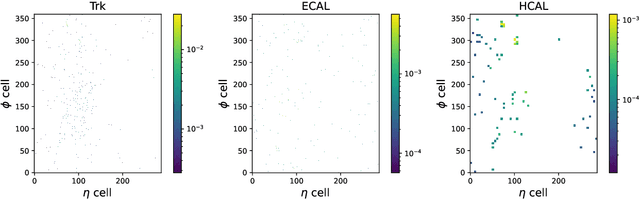
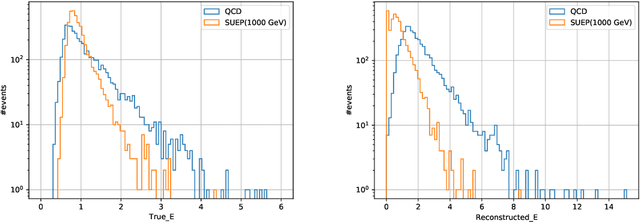
Confining dark sectors with pseudo-conformal dynamics can produce Soft Unclustered Energy Patterns, or SUEPs, at the Large Hadron Collider: the production of dark quarks in proton-proton collisions leading to a dark shower and the high-multiplicity production of dark hadrons. The final experimental signature is spherically-symmetric energy deposits by an anomalously large number of soft Standard Model particles with a transverse energy of a few hundred MeV. The dominant background for the SUEP search, if it gets produced via gluon-gluon fusion, is multi-jet QCD events. We have developed a deep learning-based Anomaly Detection technique to reject QCD jets and identify any anomalous signature, including SUEP, in real-time in the High-Level Trigger system of the Compact Muon Solenoid experiment at the Large Hadron Collider. A deep convolutional neural autoencoder network has been trained using QCD events by taking transverse energy deposits in the inner tracker, electromagnetic calorimeter, and hadron calorimeter sub-detectors as 3-channel image data. To tackle the biggest challenge of the task, due to the sparse nature of the data: only ~0.5% of the total ~300 k image pixels have non-zero values, a non-standard loss function, the inverse of the so-called Dice Loss, has been exploited. The trained autoencoder with learned spatial features of QCD jets can detect 40% of the SUEP events, with a QCD event mistagging rate as low as 2%. The model inference time has been measured using the Intel CoreTM i5-9600KF processor and found to be ~20 ms, which perfectly satisfies the High-Level Trigger system's latency of O(100) ms. Given the virtue of the unsupervised learning of the autoencoders, the trained model can be applied to any new physics model that predicts an experimental signature anomalous to QCD jets.
When to Use Efficient Self Attention? Profiling Text, Speech and Image Transformer Variants
Jun 14, 2023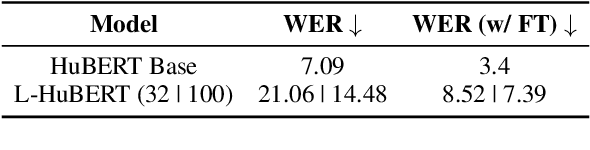
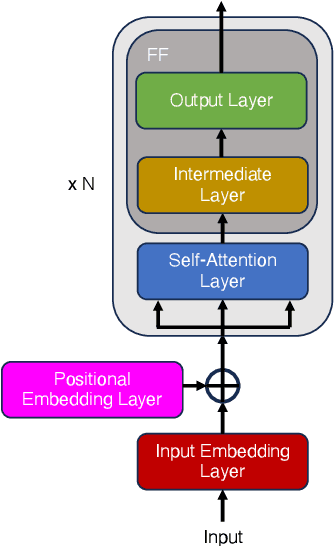
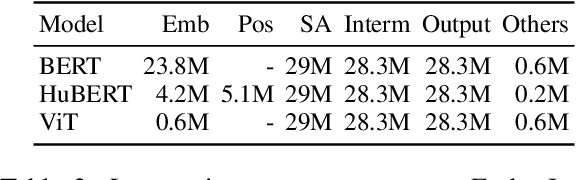
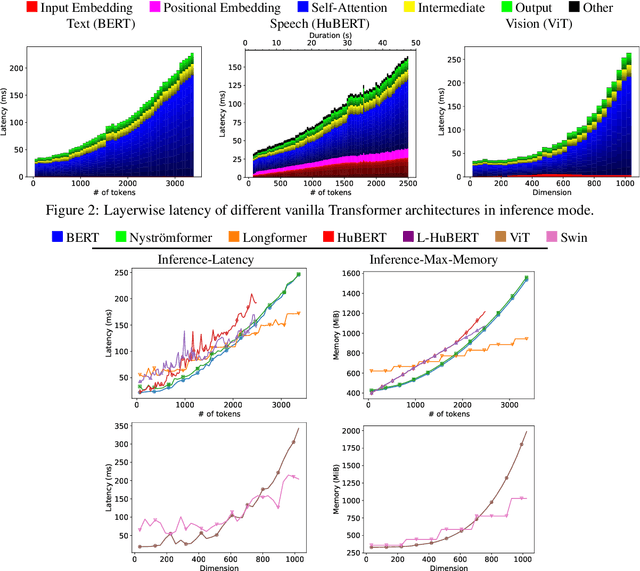
We present the first unified study of the efficiency of self-attention-based Transformer variants spanning text, speech and vision. We identify input length thresholds (tipping points) at which efficient Transformer variants become more efficient than vanilla models, using a variety of efficiency metrics (latency, throughput, and memory). To conduct this analysis for speech, we introduce L-HuBERT, a novel local-attention variant of a self-supervised speech model. We observe that these thresholds are (a) much higher than typical dataset sequence lengths and (b) dependent on the metric and modality, showing that choosing the right model depends on modality, task type (long-form vs. typical context) and resource constraints (time vs. memory). By visualising the breakdown of the computational costs for transformer components, we also show that non-self-attention components exhibit significant computational costs. We release our profiling toolkit at https://github.com/ajd12342/profiling-transformers .
A Comparison of Self-Supervised Pretraining Approaches for Predicting Disease Risk from Chest Radiograph Images
Jun 15, 2023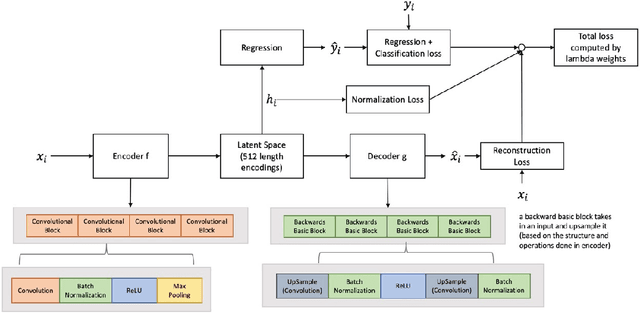
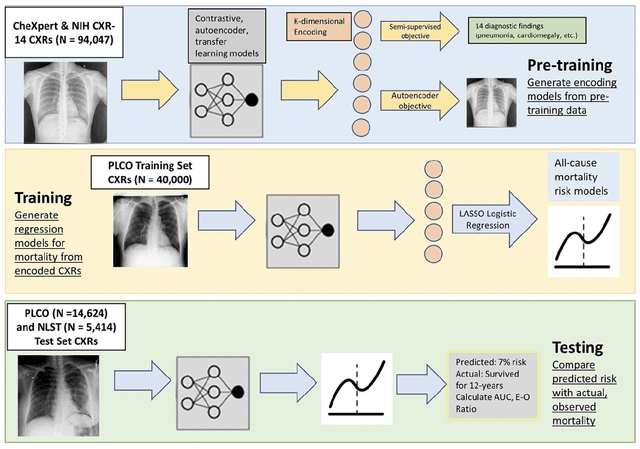
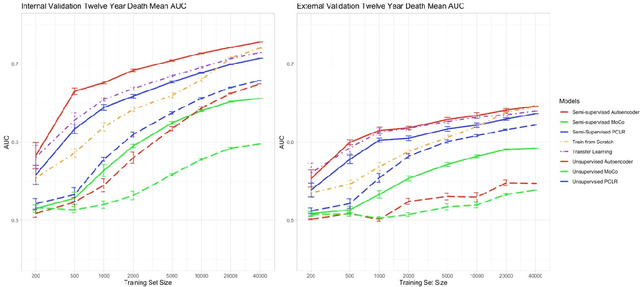
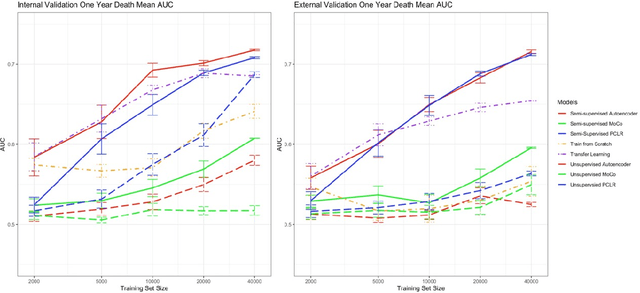
Deep learning is the state-of-the-art for medical imaging tasks, but requires large, labeled datasets. For risk prediction, large datasets are rare since they require both imaging and follow-up (e.g., diagnosis codes). However, the release of publicly available imaging data with diagnostic labels presents an opportunity for self and semi-supervised approaches to improve label efficiency for risk prediction. Though several studies have compared self-supervised approaches in natural image classification, object detection, and medical image interpretation, there is limited data on which approaches learn robust representations for risk prediction. We present a comparison of semi- and self-supervised learning to predict mortality risk using chest x-ray images. We find that a semi-supervised autoencoder outperforms contrastive and transfer learning in internal and external validation.
Noisy Image Segmentation With Soft-Dice
Apr 04, 2023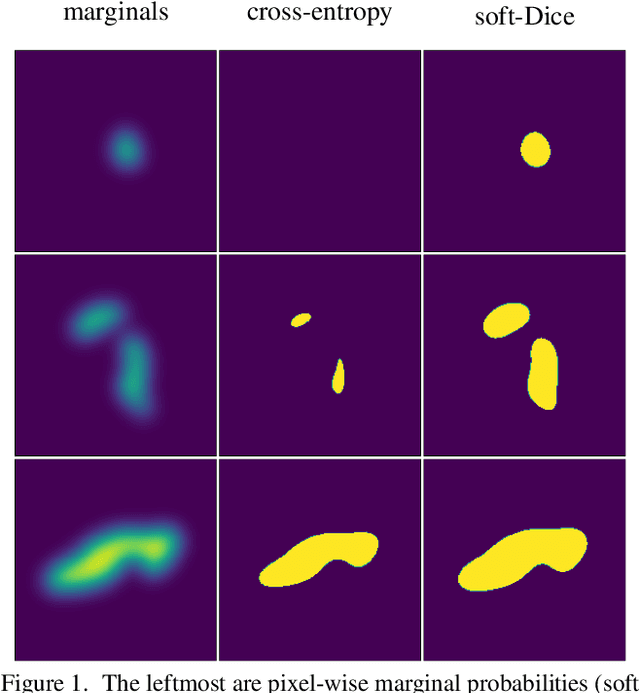
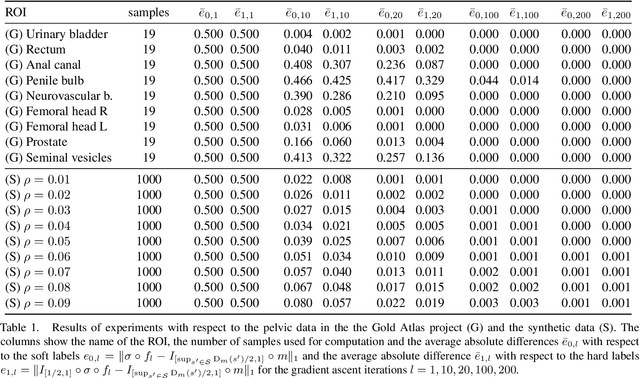
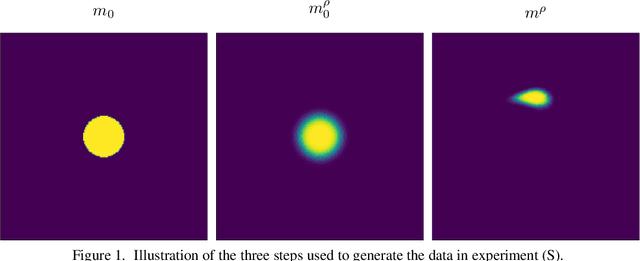
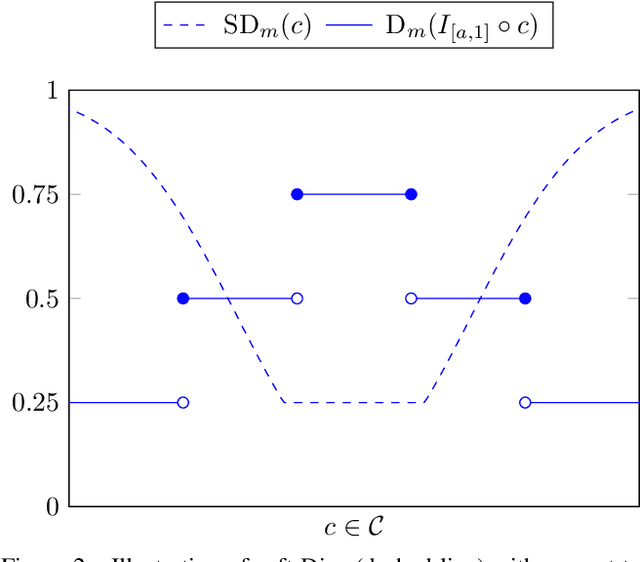
This paper presents a study on the soft-Dice loss, one of the most popular loss functions in medical image segmentation, for situations where noise is present in target labels. In particular, the set of optimal solutions are characterized and sharp bounds on the volume bias of these solutions are provided. It is further shown that a sequence of soft segmentations converging to optimal soft-Dice also converges to optimal Dice when converted to hard segmentations using thresholding. This is an important result because soft-Dice is often used as a proxy for maximizing the Dice metric. Finally, experiments confirming the theoretical results are provided.
CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion
Mar 21, 2023
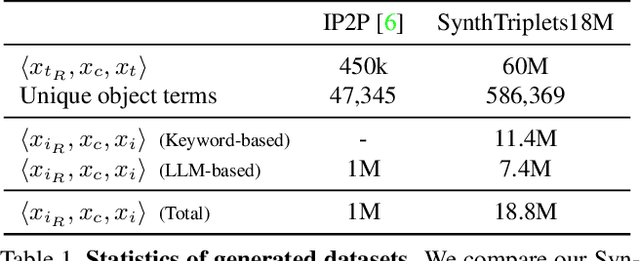
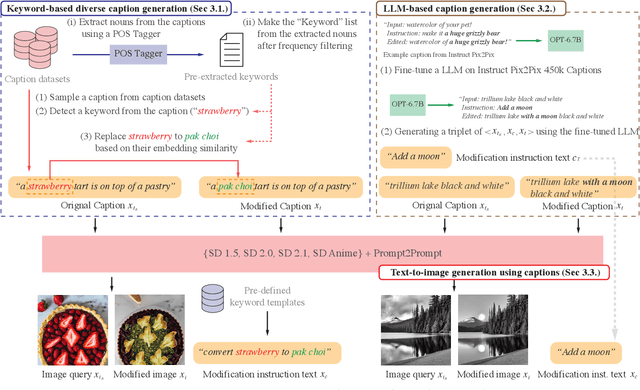

This paper proposes a novel diffusion-based model, CompoDiff, for solving Composed Image Retrieval (CIR) with latent diffusion and presents a newly created dataset of 18 million reference images, conditions, and corresponding target image triplets to train the model. CompoDiff not only achieves a new zero-shot state-of-the-art on a CIR benchmark such as FashionIQ but also enables a more versatile CIR by accepting various conditions, such as negative text and image mask conditions, which are unavailable with existing CIR methods. In addition, the CompoDiff features are on the intact CLIP embedding space so that they can be directly used for all existing models exploiting the CLIP space. The code and dataset used for the training, and the pre-trained weights are available at https://github.com/navervision/CompoDiff
Pseudo Supervised Metrics: Evaluating Unsupervised Image to Image Translation Models In Unsupervised Cross-Domain Classification Frameworks
Mar 18, 2023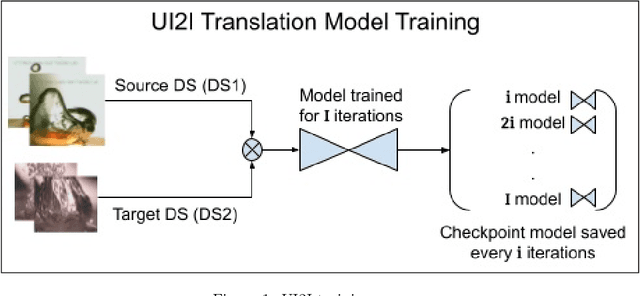

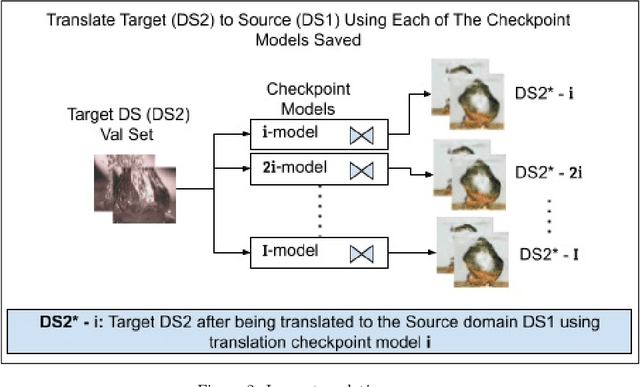
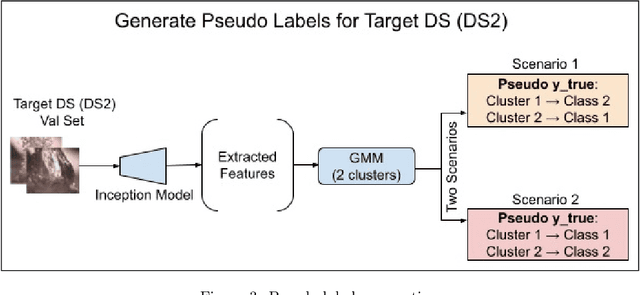
The ability to classify images accurately and efficiently is dependent on having access to large labeled datasets and testing on data from the same domain that the model is trained on. Classification becomes more challenging when dealing with new data from a different domain, where collecting a large labeled dataset and training a new classifier from scratch is time-consuming, expensive, and sometimes infeasible or impossible. Cross-domain classification frameworks were developed to handle this data domain shift problem by utilizing unsupervised image-to-image (UI2I) translation models to translate an input image from the unlabeled domain to the labeled domain. The problem with these unsupervised models lies in their unsupervised nature. For lack of annotations, it is not possible to use the traditional supervised metrics to evaluate these translation models to pick the best-saved checkpoint model. In this paper, we introduce a new method called Pseudo Supervised Metrics that was designed specifically to support cross-domain classification applications contrary to other typically used metrics such as the FID which was designed to evaluate the model in terms of the quality of the generated image from a human-eye perspective. We show that our metric not only outperforms unsupervised metrics such as the FID, but is also highly correlated with the true supervised metrics, robust, and explainable. Furthermore, we demonstrate that it can be used as a standard metric for future research in this field by applying it to a critical real-world problem (the boiling crisis problem).
Class-Incremental Learning using Diffusion Model for Distillation and Replay
Jun 30, 2023
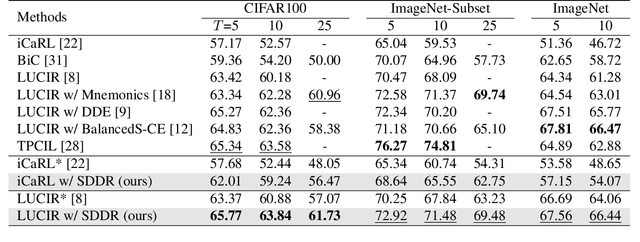
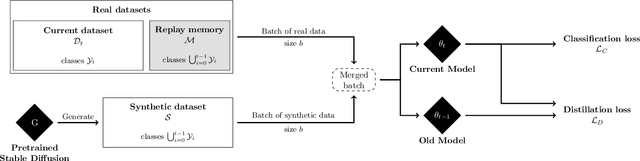
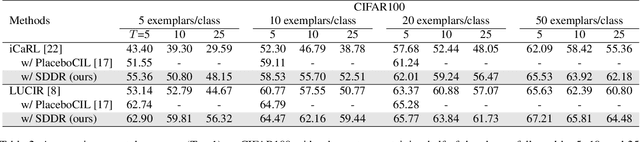
Class-incremental learning aims to learn new classes in an incremental fashion without forgetting the previously learned ones. Several research works have shown how additional data can be used by incremental models to help mitigate catastrophic forgetting. In this work, following the recent breakthrough in text-to-image generative models and their wide distribution, we propose the use of a pretrained Stable Diffusion model as a source of additional data for class-incremental learning. Compared to competitive methods that rely on external, often unlabeled, datasets of real images, our approach can generate synthetic samples belonging to the same classes as the previously encountered images. This allows us to use those additional data samples not only in the distillation loss but also for replay in the classification loss. Experiments on the competitive benchmarks CIFAR100, ImageNet-Subset, and ImageNet demonstrate how this new approach can be used to further improve the performance of state-of-the-art methods for class-incremental learning on large scale datasets.
RBSR: Efficient and Flexible Recurrent Network for Burst Super-Resolution
Jun 30, 2023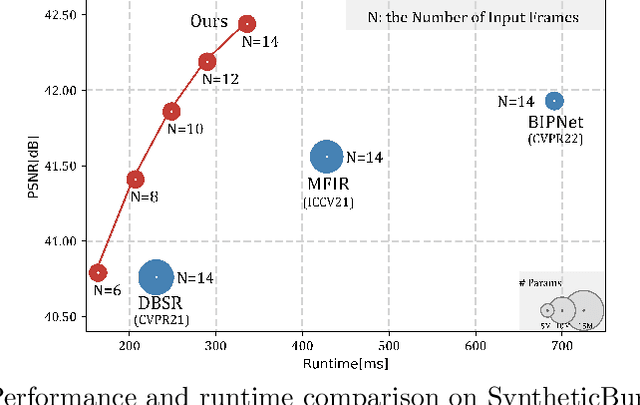
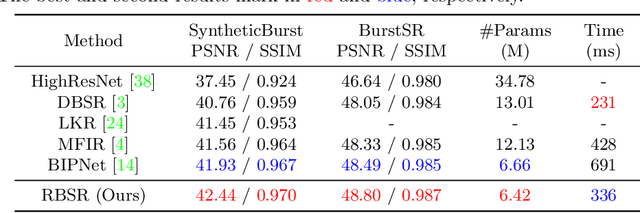
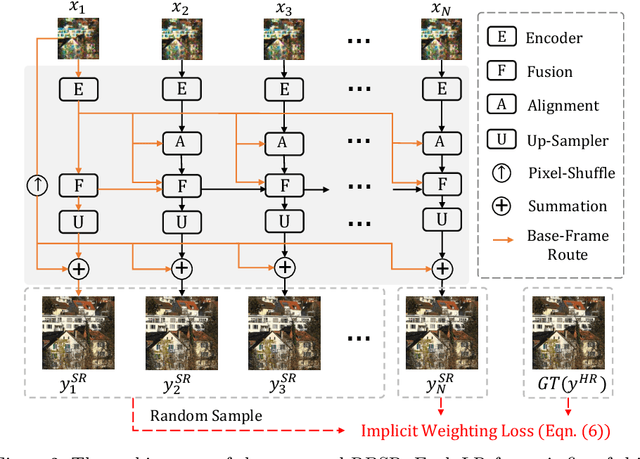
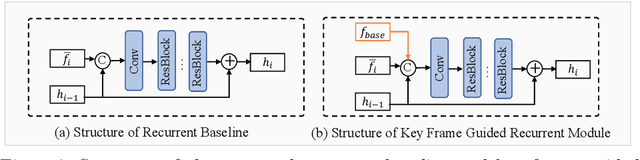
Burst super-resolution (BurstSR) aims at reconstructing a high-resolution (HR) image from a sequence of low-resolution (LR) and noisy images, which is conducive to enhancing the imaging effects of smartphones with limited sensors. The main challenge of BurstSR is to effectively combine the complementary information from input frames, while existing methods still struggle with it. In this paper, we suggest fusing cues frame-by-frame with an efficient and flexible recurrent network. In particular, we emphasize the role of the base-frame and utilize it as a key prompt to guide the knowledge acquisition from other frames in every recurrence. Moreover, we introduce an implicit weighting loss to improve the model's flexibility in facing input frames with variable numbers. Extensive experiments on both synthetic and real-world datasets demonstrate that our method achieves better results than state-of-the-art ones. Codes and pre-trained models are available at https://github.com/ZcsrenlongZ/RBSR.
Shortest Length Total Orders Do Not Minimize Irregularity in Vector-Valued Mathematical Morphology
Jun 30, 2023
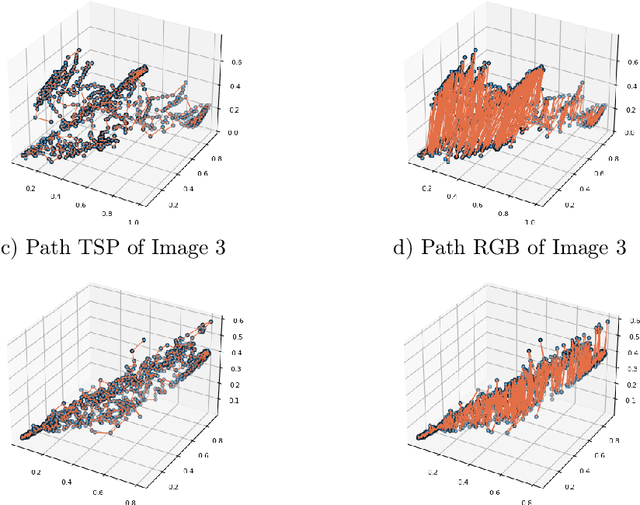
Mathematical morphology is a theory concerned with non-linear operators for image processing and analysis. The underlying framework for mathematical morphology is a partially ordered set with well-defined supremum and infimum operations. Because vectors can be ordered in many ways, finding appropriate ordering schemes is a major challenge in mathematical morphology for vector-valued images, such as color and hyperspectral images. In this context, the irregularity issue plays a key role in designing effective morphological operators. Briefly, the irregularity follows from a disparity between the ordering scheme and a metric in the value set. Determining an ordering scheme using a metric provide reasonable approaches to vector-valued mathematical morphology. Because total orderings correspond to paths on the value space, one attempt to reduce the irregularity of morphological operators would be defining a total order based on the shortest length path. However, this paper shows that the total ordering associated with the shortest length path does not necessarily imply minimizing the irregularity.
Mole Recruitment: Poisoning of Image Classifiers via Selective Batch Sampling
Mar 30, 2023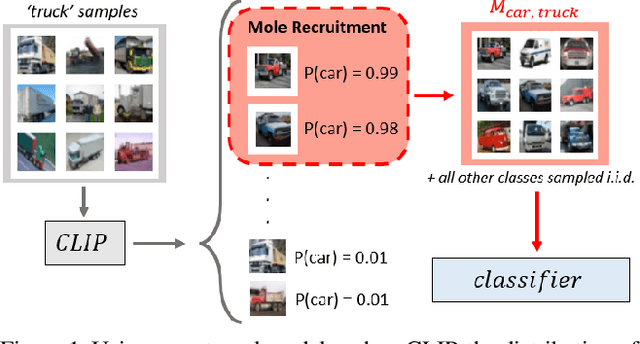
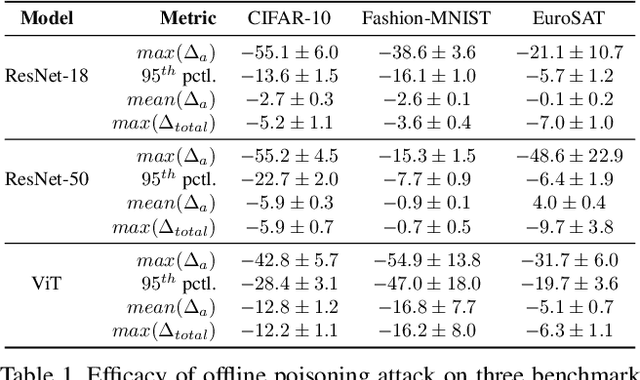

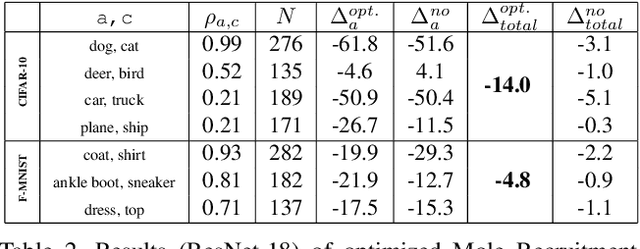
In this work, we present a data poisoning attack that confounds machine learning models without any manipulation of the image or label. This is achieved by simply leveraging the most confounding natural samples found within the training data itself, in a new form of a targeted attack coined "Mole Recruitment." We define moles as the training samples of a class that appear most similar to samples of another class, and show that simply restructuring training batches with an optimal number of moles can lead to significant degradation in the performance of the targeted class. We show the efficacy of this novel attack in an offline setting across several standard image classification datasets, and demonstrate the real-world viability of this attack in a continual learning (CL) setting. Our analysis reveals that state-of-the-art models are susceptible to Mole Recruitment, thereby exposing a previously undetected vulnerability of image classifiers.