 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fermat Distances: Metric Approximation, Spectral Convergence, and Clustering Algorithms
Jul 07, 2023


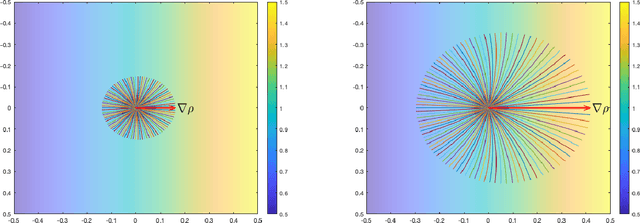
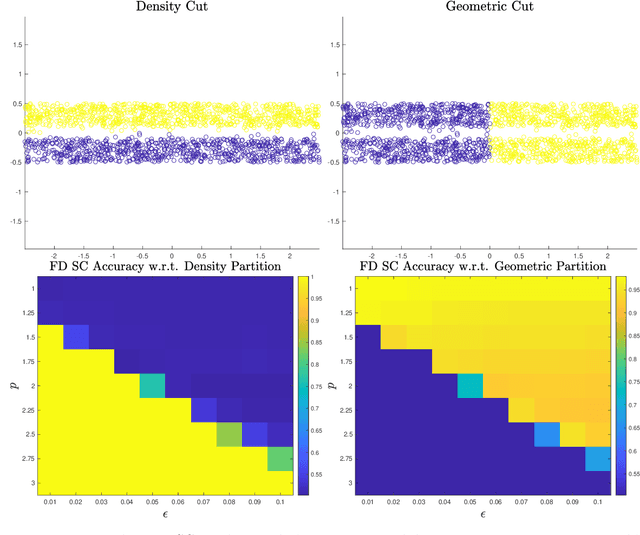
We analyze the convergence properties of Fermat distances, a family of density-driven metrics defined on Riemannian manifolds with an associated probability measure. Fermat distances may be defined either on discrete samples from the underlying measure, in which case they are random, or in the continuum setting, in which they are induced by geodesics under a density-distorted Riemannian metric. We prove that discrete, sample-based Fermat distances converge to their continuum analogues in small neighborhoods with a precise rate that depends on the intrinsic dimensionality of the data and the parameter governing the extent of density weighting in Fermat distances. This is done by leveraging novel geometric and statistical arguments in percolation theory that allow for non-uniform densities and curved domains. Our results are then used to prove that discrete graph Laplacians based on discrete, sample-driven Fermat distances converge to corresponding continuum operators. In particular, we show the discrete eigenvalues and eigenvectors converge to their continuum analogues at a dimension-dependent rate, which allows us to interpret the efficacy of discrete spectral clustering using Fermat distances in terms of the resulting continuum limit. The perspective afforded by our discrete-to-continuum Fermat distance analysis leads to new clustering algorithms for data and related insights into efficient computations associated to density-driven spectral clustering. Our theoretical analysis is supported with numerical simulations and experiments on synthetic and real image data.
Fill-Up: Balancing Long-Tailed Data with Generative Models
Jun 12, 2023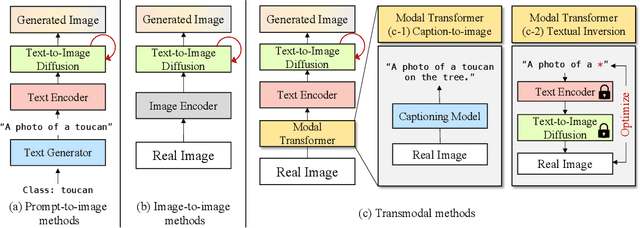

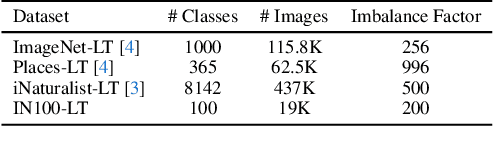
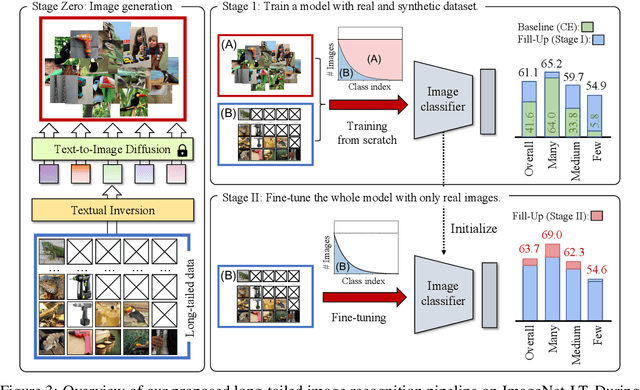
Modern text-to-image synthesis models have achieved an exceptional level of photorealism, generating high-quality images from arbitrary text descriptions. In light of the impressive synthesis ability, several studies have exhibited promising results in exploiting generated data for image recognition. However, directly supplementing data-hungry situations in the real-world (e.g. few-shot or long-tailed scenarios) with existing approaches result in marginal performance gains, as they suffer to thoroughly reflect the distribution of the real data. Through extensive experiments, this paper proposes a new image synthesis pipeline for long-tailed situations using Textual Inversion. The study demonstrates that generated images from textual-inverted text tokens effectively aligns with the real domain, significantly enhancing the recognition ability of a standard ResNet50 backbone. We also show that real-world data imbalance scenarios can be successfully mitigated by filling up the imbalanced data with synthetic images. In conjunction with techniques in the area of long-tailed recognition, our method achieves state-of-the-art results on standard long-tailed benchmarks when trained from scratch.
Learning with Explicit Shape Priors for Medical Image Segmentation
Mar 31, 2023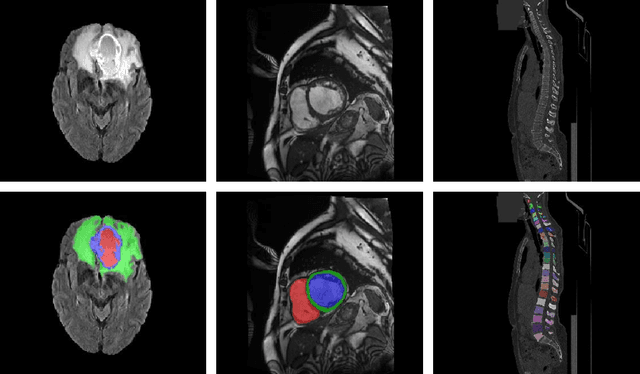
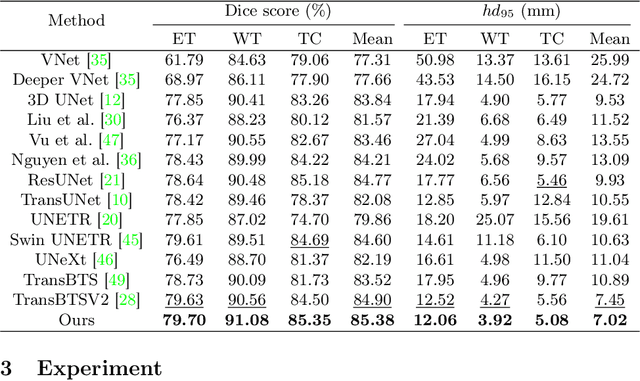
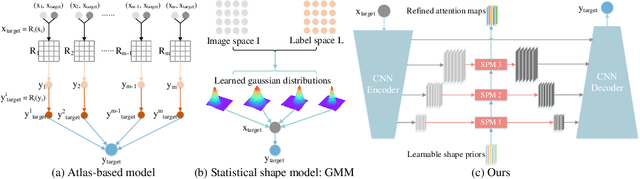
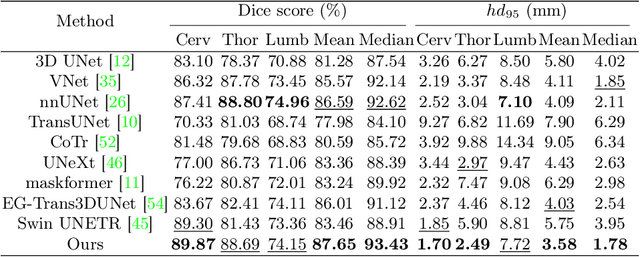
Medical image segmentation is considered as the basic step for medical image analysis and surgical intervention. And many previous works attempted to incorporate shape priors for designing segmentation models, which is beneficial to attain finer masks with anatomical shape information. Here in our work, we detailedly discuss three types of segmentation models with shape priors, which consist of atlas-based models, statistical-based models and UNet-based models. On the ground that the former two kinds of methods show a poor generalization ability, UNet-based models have dominated the field of medical image segmentation in recent years. However, existing UNet-based models tend to employ implicit shape priors, which do not have a good interpretability and generalization ability on different organs with distinctive shapes. Thus, we proposed a novel shape prior module (SPM), which could explicitly introduce shape priors to promote the segmentation performance of UNet-based models. To evaluate the effectiveness of SPM, we conduct experiments on three challenging public datasets. And our proposed model achieves state-of-the-art performance. Furthermore, SPM shows an outstanding generalization ability on different classic convolution-neural-networks (CNNs) and recent Transformer-based backbones, which can serve as a plug-and-play structure for the segmentation task of different datasets.
Text-to-image Diffusion Model in Generative AI: A Survey
Mar 14, 2023


This survey reviews text-to-image diffusion models in the context that diffusion models have emerged to be popular for a wide range of generative tasks. As a self-contained work, this survey starts with a brief introduction of how a basic diffusion model works for image synthesis, followed by how condition or guidance improves learning. Based on that, we present a review of state-of-the-art methods on text-conditioned image synthesis, i.e., text-to-image. We further summarize applications beyond text-to-image generation: text-guided creative generation and text-guided image editing. Beyond the progress made so far, we discuss existing challenges and promising future directions.
Zoom is what you need: An empirical study of the power of zoom and spatial biases in image classification
Apr 11, 2023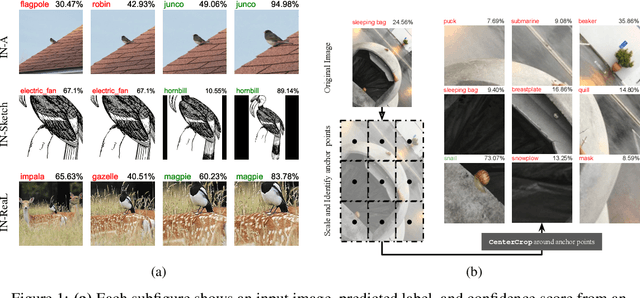



Image classifiers are information-discarding machines, by design. Yet, how these models discard information remains mysterious. We hypothesize that one way for image classifiers to reach high accuracy is to first zoom to the most discriminative region in the image and then extract features from there to predict image labels. We study six popular networks ranging from AlexNet to CLIP and find that proper framing of the input image can lead to the correct classification of 98.91% of ImageNet images. Furthermore, we explore the potential and limits of zoom transforms in image classification and uncover positional biases in various datasets, especially a strong center bias in two popular datasets: ImageNet-A and ObjectNet. Finally, leveraging our insights into the potential of zoom, we propose a state-of-the-art test-time augmentation (TTA) technique that improves classification accuracy by forcing models to explicitly perform zoom-in operations before making predictions. Our method is more interpretable, accurate, and faster than MEMO, a state-of-the-art TTA method. Additionally, we propose ImageNet-Hard, a new benchmark where zooming in alone often does not help state-of-the-art models better label images.
StyleGAN knows Normal, Depth, Albedo, and More
Jun 01, 2023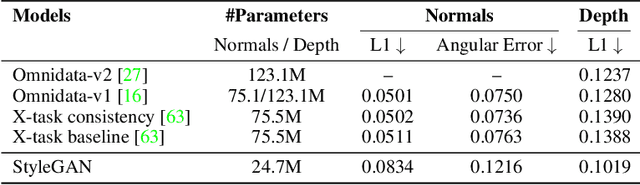
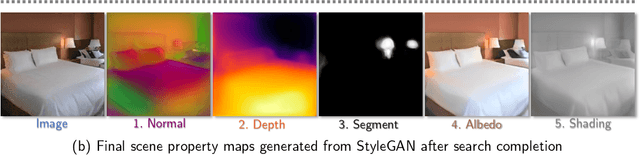
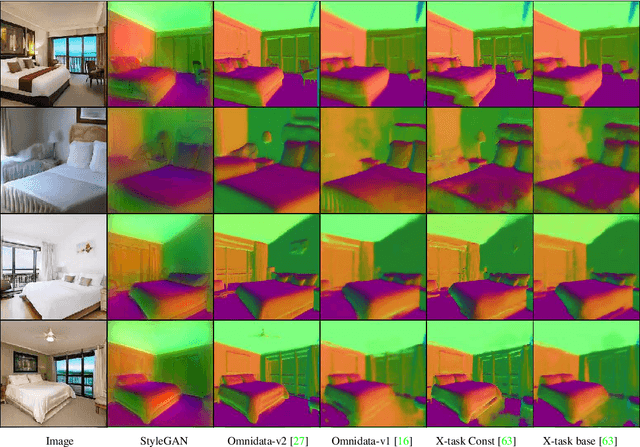
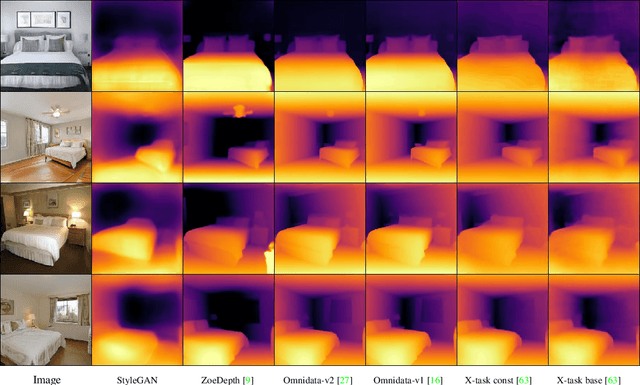
Intrinsic images, in the original sense, are image-like maps of scene properties like depth, normal, albedo or shading. This paper demonstrates that StyleGAN can easily be induced to produce intrinsic images. The procedure is straightforward. We show that, if StyleGAN produces $G({w})$ from latents ${w}$, then for each type of intrinsic image, there is a fixed offset ${d}_c$ so that $G({w}+{d}_c)$ is that type of intrinsic image for $G({w})$. Here ${d}_c$ is {\em independent of ${w}$}. The StyleGAN we used was pretrained by others, so this property is not some accident of our training regime. We show that there are image transformations StyleGAN will {\em not} produce in this fashion, so StyleGAN is not a generic image regression engine. It is conceptually exciting that an image generator should ``know'' and represent intrinsic images. There may also be practical advantages to using a generative model to produce intrinsic images. The intrinsic images obtained from StyleGAN compare well both qualitatively and quantitatively with those obtained by using SOTA image regression techniques; but StyleGAN's intrinsic images are robust to relighting effects, unlike SOTA methods.
Deep learning estimation of modified Zernike coefficients for image point spread functions
Apr 05, 2023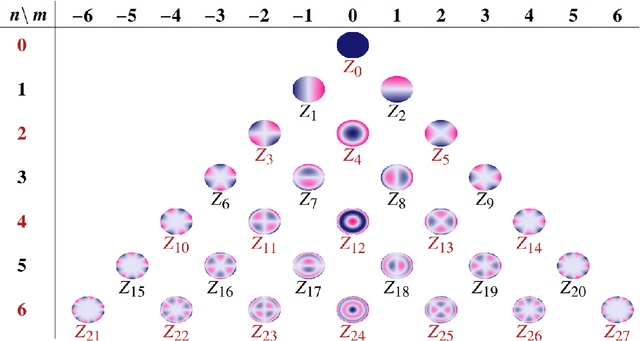
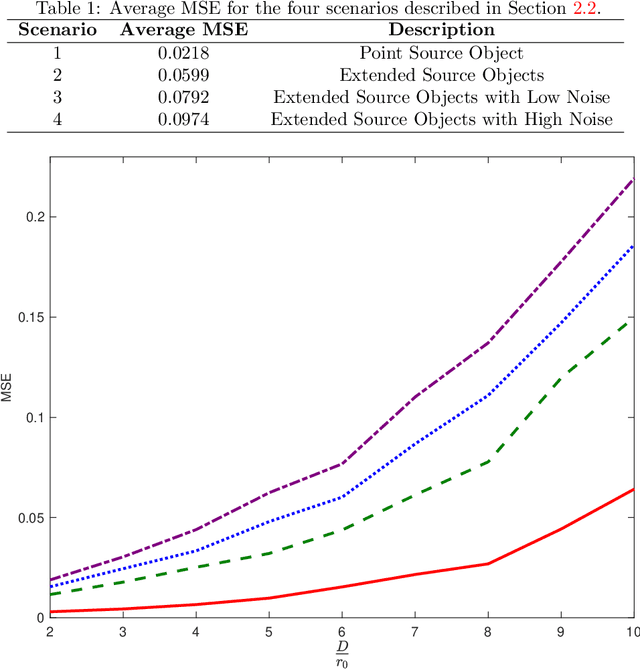
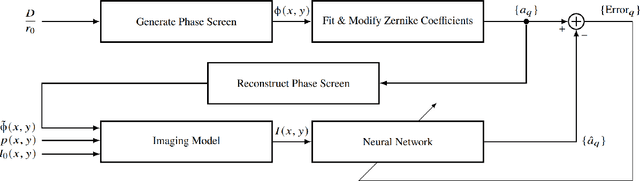
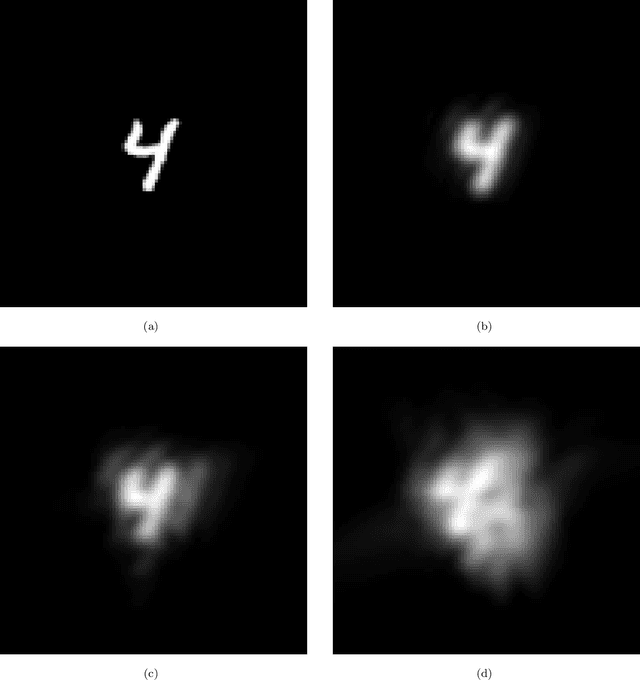
Recovering the turbulence-degraded point spread function from a single intensity image is important for a variety of imaging applications. Here, a deep learning model based on a convolution neural network is applied to intensity images to predict a modified set of Zernike polynomial coefficients corresponding to wavefront aberrations in the pupil due to turbulence. The modified set assigns an absolute value to coefficients of even radial orders due to a sign ambiguity associated with this problem and is shown to be sufficient for specifying the intensity point spread function. Simulated image data of a point object and simple extended objects over a range of turbulence and detection noise levels are created for the learning model. The MSE results for the learning model show that the best prediction is found when observing a point object, but it is possible to recover a useful set of modified Zernike coefficients from an extended object image that is subject to detection noise and turbulence.
Uncertainty-informed Mutual Learning for Joint Medical Image Classification and Segmentation
Mar 30, 2023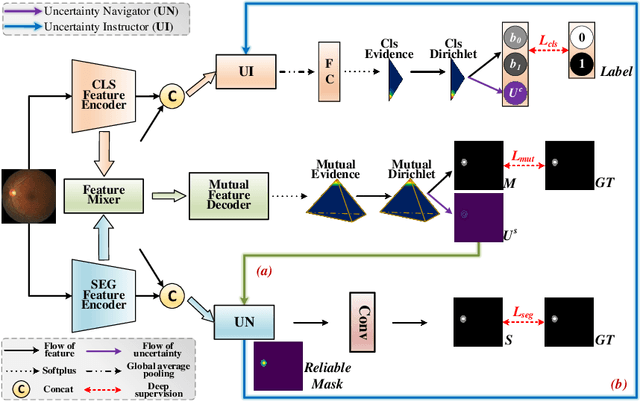
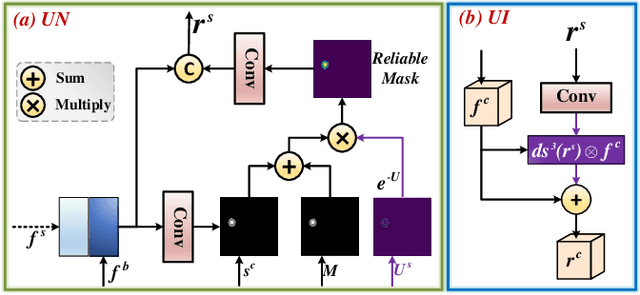
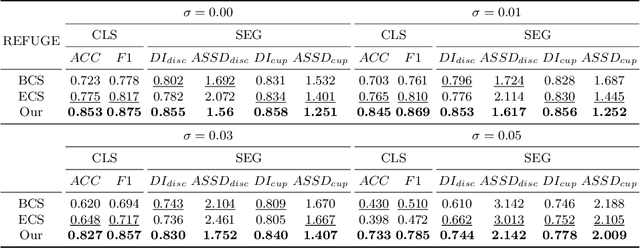
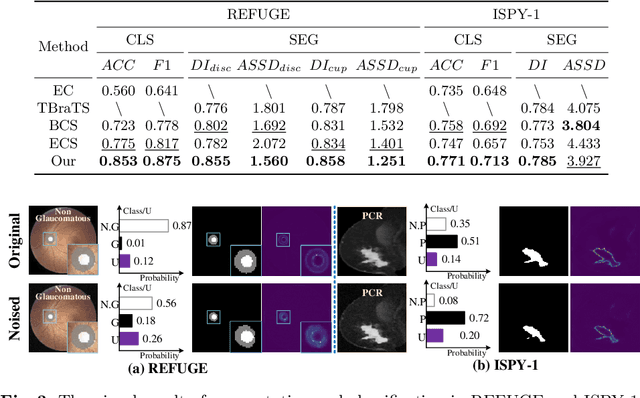
Classification and segmentation are crucial in medical image analysis as they enable accurate diagnosis and disease monitoring. However, current methods often prioritize the mutual learning features and shared model parameters, while neglecting the reliability of features and performances. In this paper, we propose a novel Uncertainty-informed Mutual Learning (UML) framework for reliable and interpretable medical image analysis. Our UML introduces reliability to joint classification and segmentation tasks, leveraging mutual learning with uncertainty to improve performance. To achieve this, we first use evidential deep learning to provide image-level and pixel-wise confidences. Then, an Uncertainty Navigator Decoder is constructed for better using mutual features and generating segmentation results. Besides, an Uncertainty Instructor is proposed to screen reliable masks for classification. Overall, UML could produce confidence estimation in features and performance for each link (classification and segmentation). The experiments on the public datasets demonstrate that our UML outperforms existing methods in terms of both accuracy and robustness. Our UML has the potential to explore the development of more reliable and explainable medical image analysis models. We will release the codes for reproduction after acceptance.
DeepMIM: Deep Supervision for Masked Image Modeling
Mar 16, 2023Deep supervision, which involves extra supervisions to the intermediate features of a neural network, was widely used in image classification in the early deep learning era since it significantly reduces the training difficulty and eases the optimization like avoiding gradient vanish over the vanilla training. Nevertheless, with the emergence of normalization techniques and residual connection, deep supervision in image classification was gradually phased out. In this paper, we revisit deep supervision for masked image modeling (MIM) that pre-trains a Vision Transformer (ViT) via a mask-and-predict scheme. Experimentally, we find that deep supervision drives the shallower layers to learn more meaningful representations, accelerates model convergence, and expands attention diversities. Our approach, called DeepMIM, significantly boosts the representation capability of each layer. In addition, DeepMIM is compatible with many MIM models across a range of reconstruction targets. For instance, using ViT-B, DeepMIM on MAE achieves 84.2 top-1 accuracy on ImageNet, outperforming MAE by +0.6. By combining DeepMIM with a stronger tokenizer CLIP, our model achieves state-of-the-art performance on various downstream tasks, including image classification (85.6 top-1 accuracy on ImageNet-1K, outperforming MAE-CLIP by +0.8), object detection (52.8 APbox on COCO) and semantic segmentation (53.1 mIoU on ADE20K). Code and models are available at https://github.com/OliverRensu/DeepMIM.
Stay on topic with Classifier-Free Guidance
Jun 30, 2023

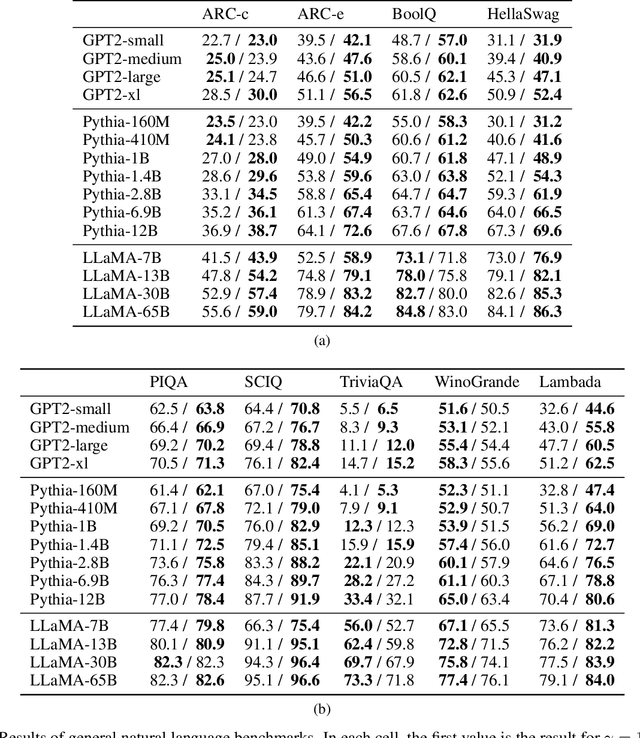
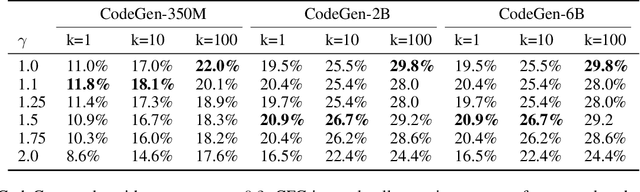
Classifier-Free Guidance (CFG) has recently emerged in text-to-image generation as a lightweight technique to encourage prompt-adherence in generations. In this work, we demonstrate that CFG can be used broadly as an inference-time technique in pure language modeling. We show that CFG (1) improves the performance of Pythia, GPT-2 and LLaMA-family models across an array of tasks: Q\&A, reasoning, code generation, and machine translation, achieving SOTA on LAMBADA with LLaMA-7B over PaLM-540B; (2) brings improvements equivalent to a model with twice the parameter-count; (3) can stack alongside other inference-time methods like Chain-of-Thought and Self-Consistency, yielding further improvements in difficult tasks; (4) can be used to increase the faithfulness and coherence of assistants in challenging form-driven and content-driven prompts: in a human evaluation we show a 75\% preference for GPT4All using CFG over baseline.