 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
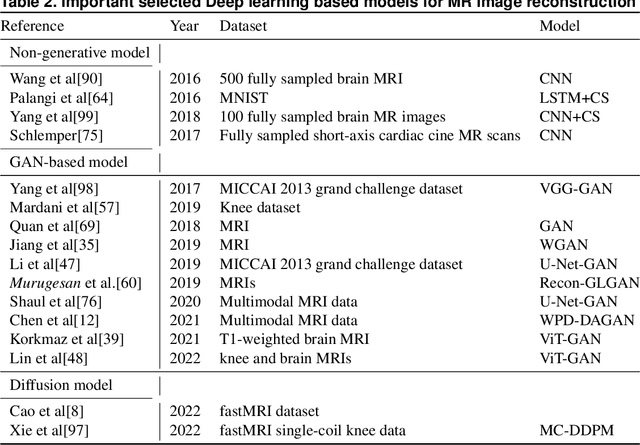
Exploring the Power of Generative Deep Learning for Image-to-Image Translation and MRI Reconstruction: A Cross-Domain Review
Mar 16, 2023
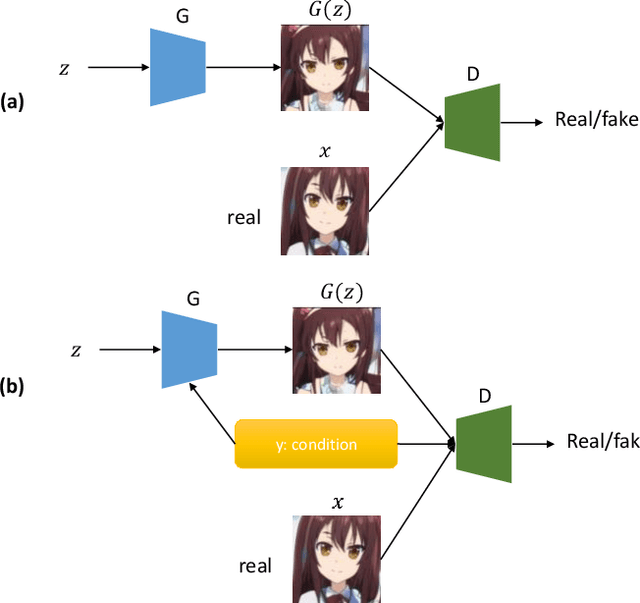


Deep learning has become a prominent computational modeling tool in the areas of computer vision and image processing in recent years. This research comprehensively analyzes the different deep-learning methods used for image-to-image translation and reconstruction in the natural and medical imaging domains. We examine the famous deep learning frameworks, such as convolutional neural networks and generative adversarial networks, and their variants, delving into the fundamental principles and difficulties of each. In the field of natural computer vision, we investigate the development and extension of various deep-learning generative models. In comparison, we investigate the possible applications of deep learning to generative medical imaging problems, including medical image translation, MRI reconstruction, and multi-contrast MRI synthesis. This thorough review provides scholars and practitioners in the areas of generative computer vision and medical imaging with useful insights for summarizing past works and getting insight into future research paths.
MMNet: Multi-Collaboration and Multi-Supervision Network for Sequential Deepfake Detection
Jul 06, 2023Advanced manipulation techniques have provided criminals with opportunities to make social panic or gain illicit profits through the generation of deceptive media, such as forged face images. In response, various deepfake detection methods have been proposed to assess image authenticity. Sequential deepfake detection, which is an extension of deepfake detection, aims to identify forged facial regions with the correct sequence for recovery. Nonetheless, due to the different combinations of spatial and sequential manipulations, forged face images exhibit substantial discrepancies that severely impact detection performance. Additionally, the recovery of forged images requires knowledge of the manipulation model to implement inverse transformations, which is difficult to ascertain as relevant techniques are often concealed by attackers. To address these issues, we propose Multi-Collaboration and Multi-Supervision Network (MMNet) that handles various spatial scales and sequential permutations in forged face images and achieve recovery without requiring knowledge of the corresponding manipulation method. Furthermore, existing evaluation metrics only consider detection accuracy at a single inferring step, without accounting for the matching degree with ground-truth under continuous multiple steps. To overcome this limitation, we propose a novel evaluation metric called Complete Sequence Matching (CSM), which considers the detection accuracy at multiple inferring steps, reflecting the ability to detect integrally forged sequences. Extensive experiments on several typical datasets demonstrate that MMNet achieves state-of-the-art detection performance and independent recovery performance.
ACE: Zero-Shot Image to Image Translation via Pretrained Auto-Contrastive-Encoder
Feb 22, 2023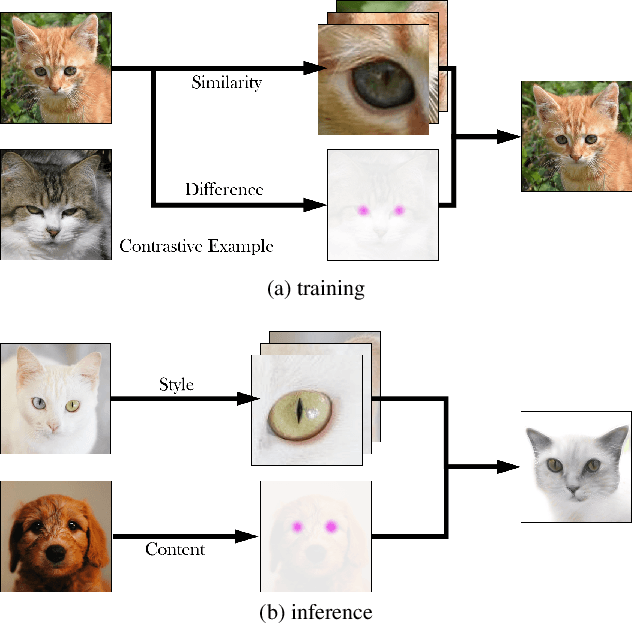
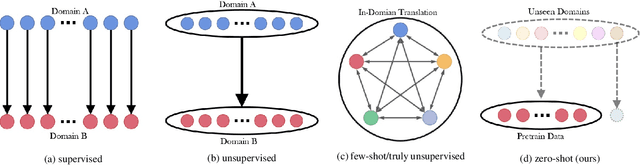
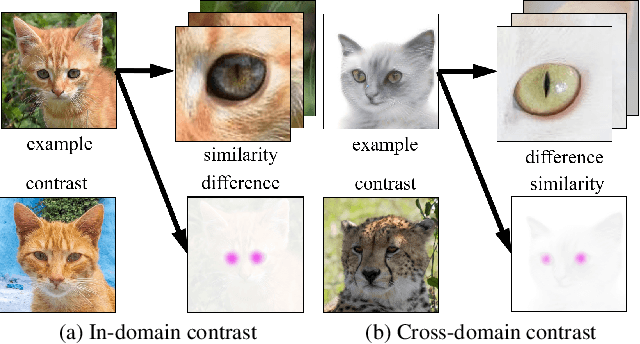
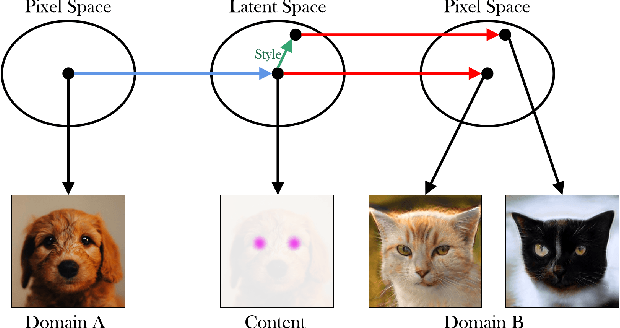
Image-to-image translation is a fundamental task in computer vision. It transforms images from one domain to images in another domain so that they have particular domain-specific characteristics. Most prior works train a generative model to learn the mapping from a source domain to a target domain. However, learning such mapping between domains is challenging because data from different domains can be highly unbalanced in terms of both quality and quantity. To address this problem, we propose a new approach to extract image features by learning the similarities and differences of samples within the same data distribution via a novel contrastive learning framework, which we call Auto-Contrastive-Encoder (ACE). ACE learns the content code as the similarity between samples with the same content information and different style perturbations. The design of ACE enables us to achieve zero-shot image-to-image translation with no training on image translation tasks for the first time. Moreover, our learning method can learn the style features of images on different domains effectively. Consequently, our model achieves competitive results on multimodal image translation tasks with zero-shot learning as well. Additionally, we demonstrate the potential of our method in transfer learning. With fine-tuning, the quality of translated images improves in unseen domains. Even though we use contrastive learning, all of our training can be performed on a single GPU with the batch size of 8.
Fermat Distances: Metric Approximation, Spectral Convergence, and Clustering Algorithms
Jul 07, 2023

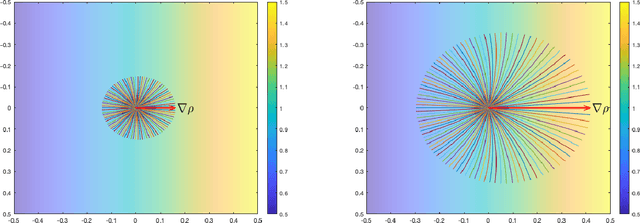
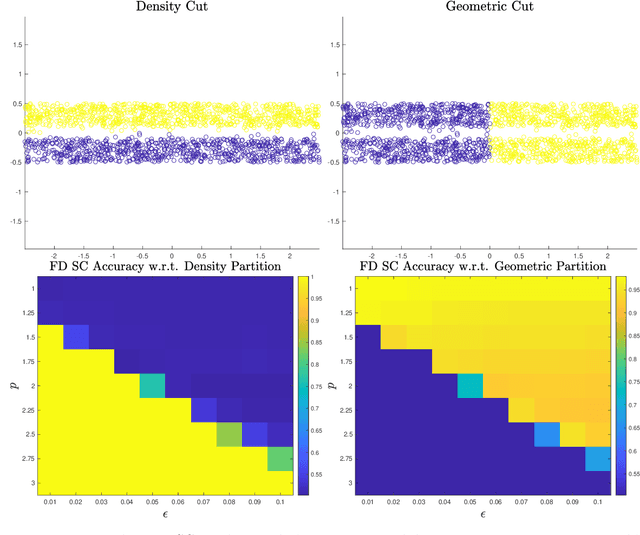
We analyze the convergence properties of Fermat distances, a family of density-driven metrics defined on Riemannian manifolds with an associated probability measure. Fermat distances may be defined either on discrete samples from the underlying measure, in which case they are random, or in the continuum setting, in which they are induced by geodesics under a density-distorted Riemannian metric. We prove that discrete, sample-based Fermat distances converge to their continuum analogues in small neighborhoods with a precise rate that depends on the intrinsic dimensionality of the data and the parameter governing the extent of density weighting in Fermat distances. This is done by leveraging novel geometric and statistical arguments in percolation theory that allow for non-uniform densities and curved domains. Our results are then used to prove that discrete graph Laplacians based on discrete, sample-driven Fermat distances converge to corresponding continuum operators. In particular, we show the discrete eigenvalues and eigenvectors converge to their continuum analogues at a dimension-dependent rate, which allows us to interpret the efficacy of discrete spectral clustering using Fermat distances in terms of the resulting continuum limit. The perspective afforded by our discrete-to-continuum Fermat distance analysis leads to new clustering algorithms for data and related insights into efficient computations associated to density-driven spectral clustering. Our theoretical analysis is supported with numerical simulations and experiments on synthetic and real image data.
Semantic-Preserving Augmentation for Robust Image-Text Retrieval
Mar 10, 2023

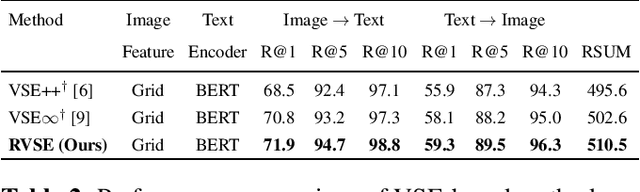
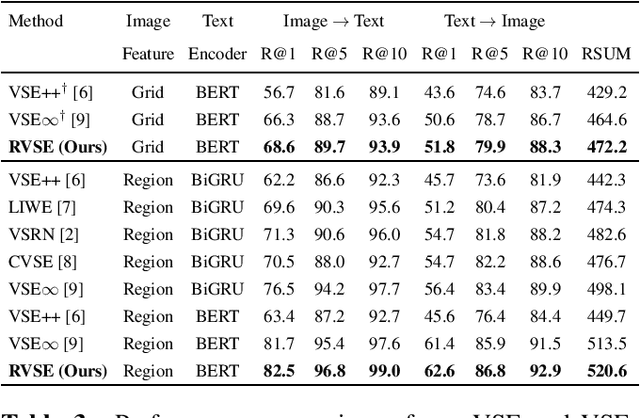
Image text retrieval is a task to search for the proper textual descriptions of the visual world and vice versa. One challenge of this task is the vulnerability to input image and text corruptions. Such corruptions are often unobserved during the training, and degrade the retrieval model decision quality substantially. In this paper, we propose a novel image text retrieval technique, referred to as robust visual semantic embedding (RVSE), which consists of novel image-based and text-based augmentation techniques called semantic preserving augmentation for image (SPAugI) and text (SPAugT). Since SPAugI and SPAugT change the original data in a way that its semantic information is preserved, we enforce the feature extractors to generate semantic aware embedding vectors regardless of the corruption, improving the model robustness significantly. From extensive experiments using benchmark datasets, we show that RVSE outperforms conventional retrieval schemes in terms of image-text retrieval performance.
A Novel Dual-pooling Attention Module for UAV Vehicle Re-identification
Jun 25, 2023
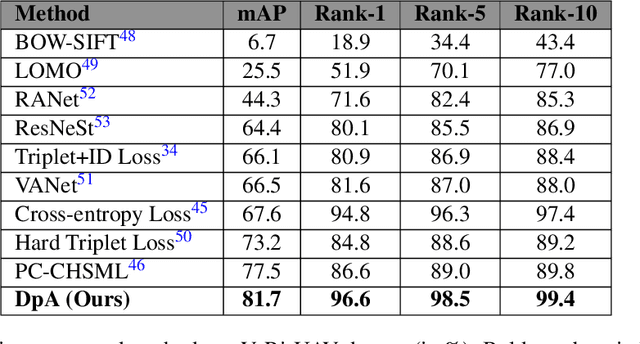
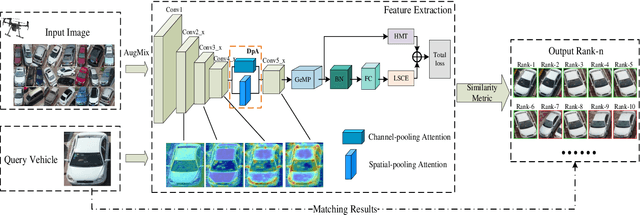
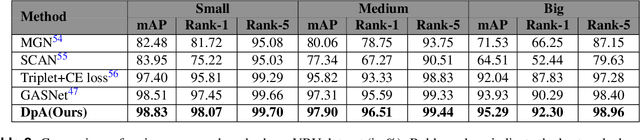
Vehicle re-identification (Re-ID) involves identifying the same vehicle captured by other cameras, given a vehicle image. It plays a crucial role in the development of safe cities and smart cities. With the rapid growth and implementation of unmanned aerial vehicles (UAVs) technology, vehicle Re-ID in UAV aerial photography scenes has garnered significant attention from researchers. However, due to the high altitude of UAVs, the shooting angle of vehicle images sometimes approximates vertical, resulting in fewer local features for Re-ID. Therefore, this paper proposes a novel dual-pooling attention (DpA) module, which achieves the extraction and enhancement of locally important information about vehicles from both channel and spatial dimensions by constructing two branches of channel-pooling attention (CpA) and spatial-pooling attention (SpA), and employing multiple pooling operations to enhance the attention to fine-grained information of vehicles. Specifically, the CpA module operates between the channels of the feature map and splices features by combining four pooling operations so that vehicle regions containing discriminative information are given greater attention. The SpA module uses the same pooling operations strategy to identify discriminative representations and merge vehicle features in image regions in a weighted manner. The feature information of both dimensions is finally fused and trained jointly using label smoothing cross-entropy loss and hard mining triplet loss, thus solving the problem of missing detail information due to the high height of UAV shots. The proposed method's effectiveness is demonstrated through extensive experiments on the UAV-based vehicle datasets VeRi-UAV and VRU.
Discriminative Class Tokens for Text-to-Image Diffusion Models
Mar 30, 2023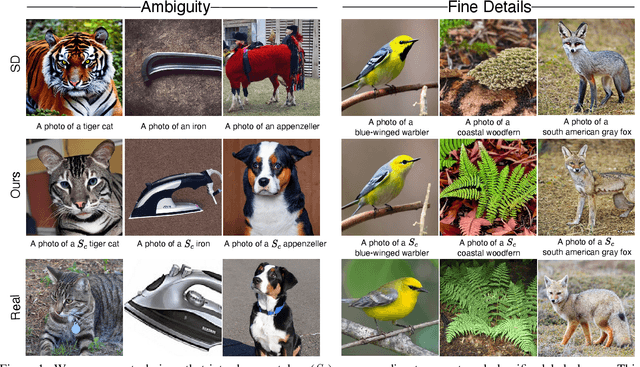
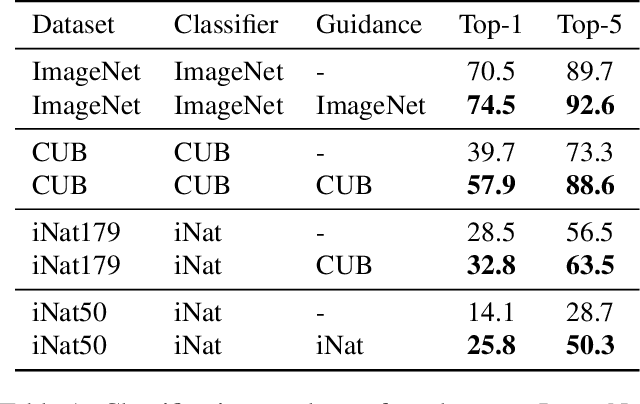
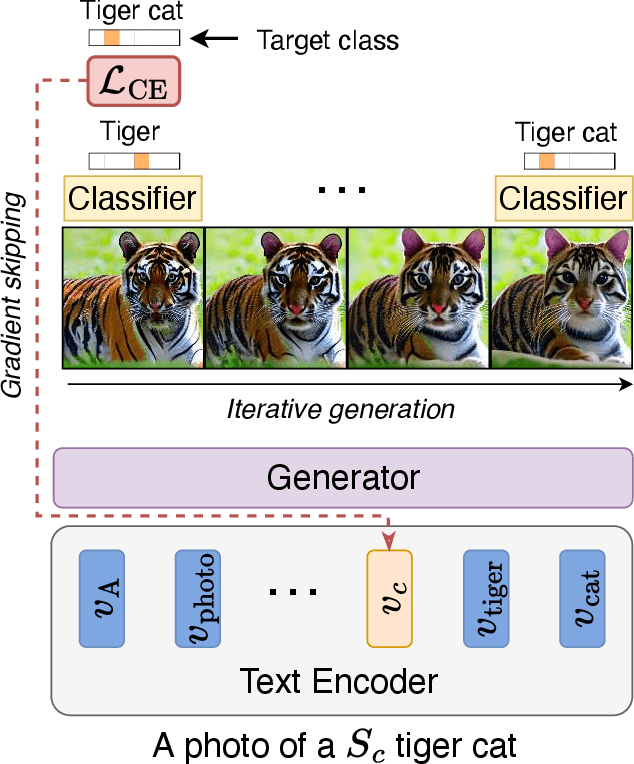
Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. However, generated images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This comes with a downside, doing so limits their expressive power: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, and so the quality and diversity of generated images are severely affected, or (ii) the input is a hard-coded label, as opposed to free-form text, which limits the control over the generated images. In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier. The code is available at \url{https://github.com/idansc/discriminative_class_tokens}
Image as Set of Points
Mar 02, 2023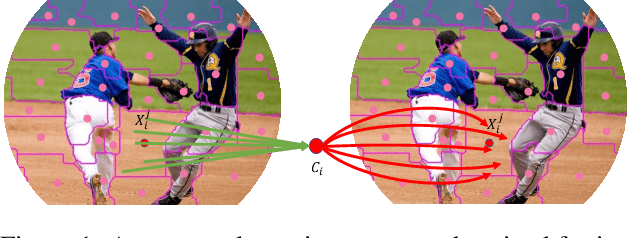
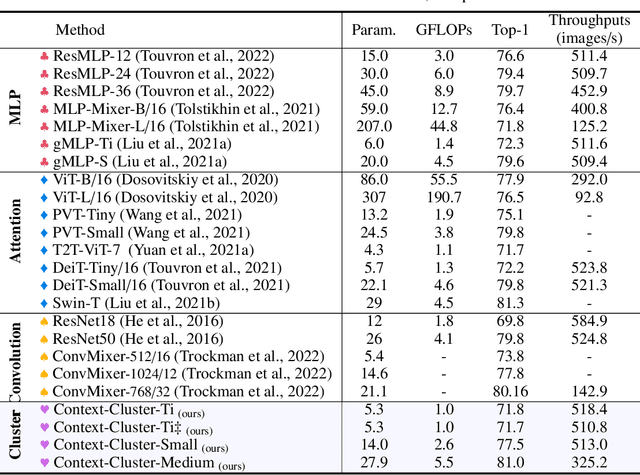
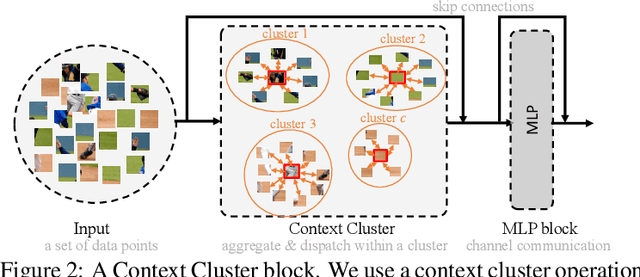
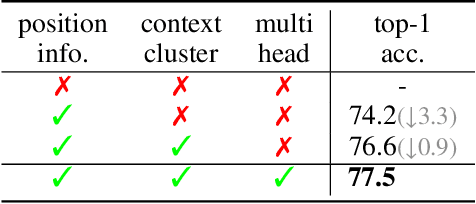
What is an image and how to extract latent features? Convolutional Networks (ConvNets) consider an image as organized pixels in a rectangular shape and extract features via convolutional operation in local region; Vision Transformers (ViTs) treat an image as a sequence of patches and extract features via attention mechanism in a global range. In this work, we introduce a straightforward and promising paradigm for visual representation, which is called Context Clusters. Context clusters (CoCs) view an image as a set of unorganized points and extract features via simplified clustering algorithm. In detail, each point includes the raw feature (e.g., color) and positional information (e.g., coordinates), and a simplified clustering algorithm is employed to group and extract deep features hierarchically. Our CoCs are convolution- and attention-free, and only rely on clustering algorithm for spatial interaction. Owing to the simple design, we show CoCs endow gratifying interpretability via the visualization of clustering process. Our CoCs aim at providing a new perspective on image and visual representation, which may enjoy broad applications in different domains and exhibit profound insights. Even though we are not targeting SOTA performance, COCs still achieve comparable or even better results than ConvNets or ViTs on several benchmarks. Codes are available at: https://github.com/ma-xu/Context-Cluster.
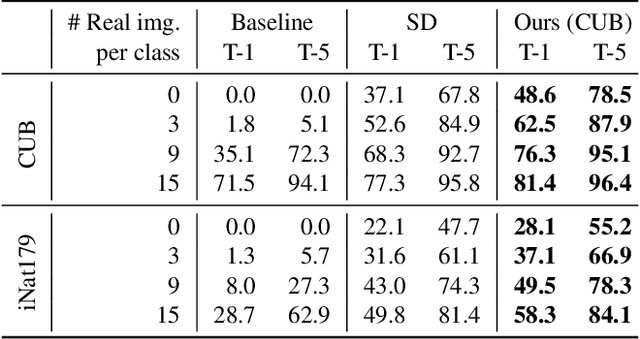
Fill-Up: Balancing Long-Tailed Data with Generative Models
Jun 12, 2023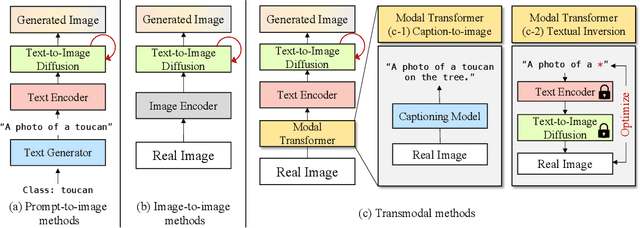

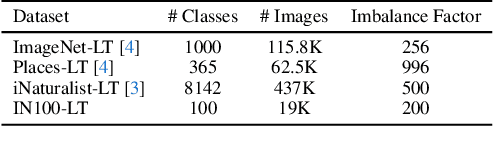
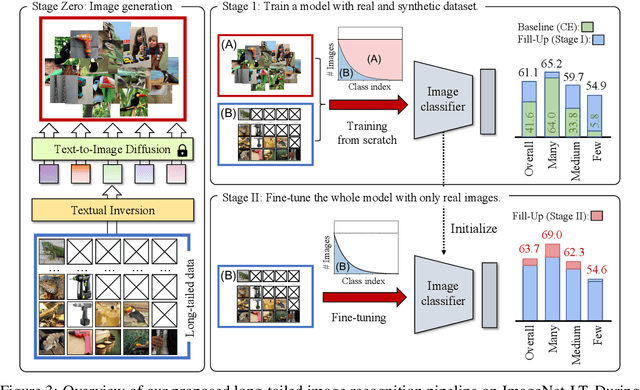
Modern text-to-image synthesis models have achieved an exceptional level of photorealism, generating high-quality images from arbitrary text descriptions. In light of the impressive synthesis ability, several studies have exhibited promising results in exploiting generated data for image recognition. However, directly supplementing data-hungry situations in the real-world (e.g. few-shot or long-tailed scenarios) with existing approaches result in marginal performance gains, as they suffer to thoroughly reflect the distribution of the real data. Through extensive experiments, this paper proposes a new image synthesis pipeline for long-tailed situations using Textual Inversion. The study demonstrates that generated images from textual-inverted text tokens effectively aligns with the real domain, significantly enhancing the recognition ability of a standard ResNet50 backbone. We also show that real-world data imbalance scenarios can be successfully mitigated by filling up the imbalanced data with synthetic images. In conjunction with techniques in the area of long-tailed recognition, our method achieves state-of-the-art results on standard long-tailed benchmarks when trained from scratch.
Learning Iterative Neural Optimizers for Image Steganography
Mar 27, 2023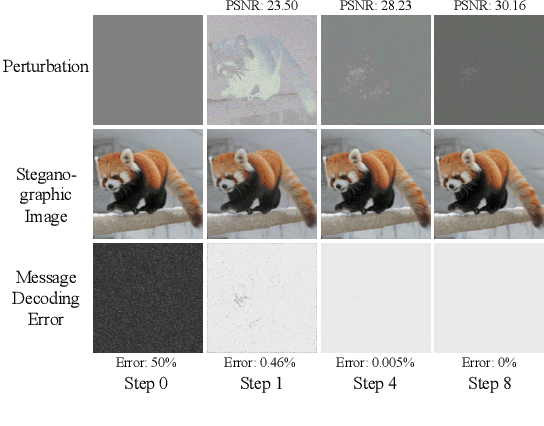
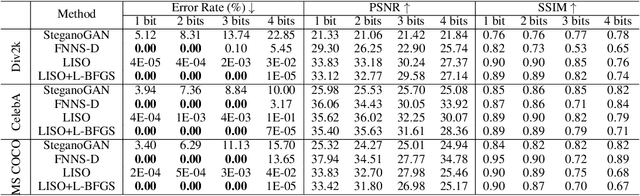
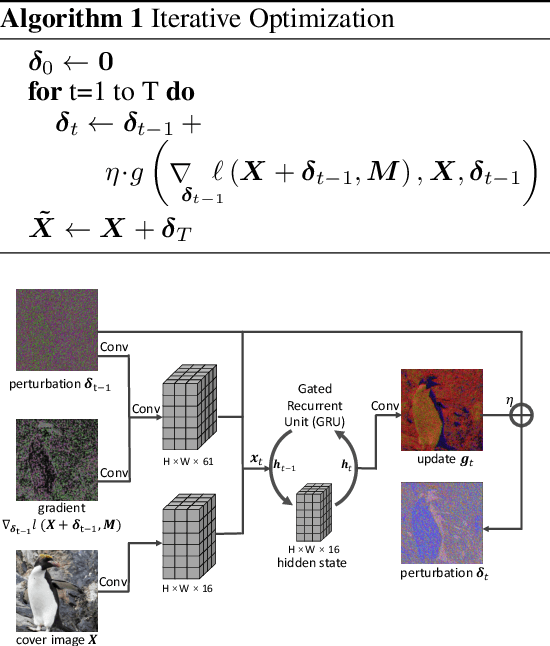

Image steganography is the process of concealing secret information in images through imperceptible changes. Recent work has formulated this task as a classic constrained optimization problem. In this paper, we argue that image steganography is inherently performed on the (elusive) manifold of natural images, and propose an iterative neural network trained to perform the optimization steps. In contrast to classical optimization methods like L-BFGS or projected gradient descent, we train the neural network to also stay close to the manifold of natural images throughout the optimization. We show that our learned neural optimization is faster and more reliable than classical optimization approaches. In comparison to previous state-of-the-art encoder-decoder-based steganography methods, it reduces the recovery error rate by multiple orders of magnitude and achieves zero error up to 3 bits per pixel (bpp) without the need for error-correcting codes.