 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Critical Look at the Current Usage of Foundation Model for Dense Recognition Task
Jul 06, 2023
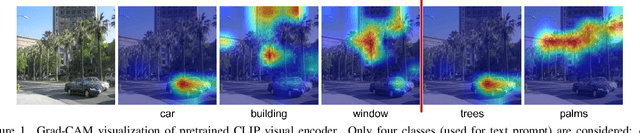
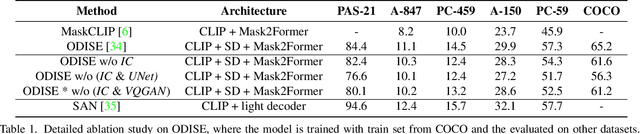


In recent years large model trained on huge amount of cross-modality data, which is usually be termed as foundation model, achieves conspicuous accomplishment in many fields, such as image recognition and generation. Though achieving great success in their original application case, it is still unclear whether those foundation models can be applied to other different downstream tasks. In this paper, we conduct a short survey on the current methods for discriminative dense recognition tasks, which are built on the pretrained foundation model. And we also provide some preliminary experimental analysis of an existing open-vocabulary segmentation method based on Stable Diffusion, which indicates the current way of deploying diffusion model for segmentation is not optimal. This aims to provide insights for future research on adopting foundation model for downstream task.
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
Jul 12, 2023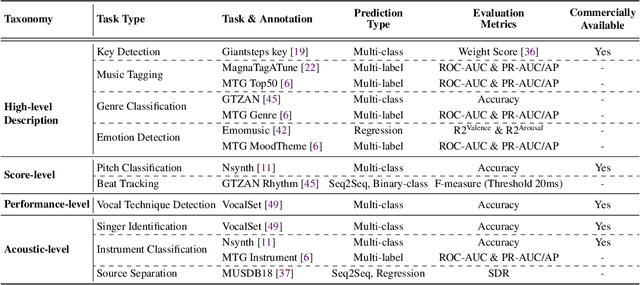
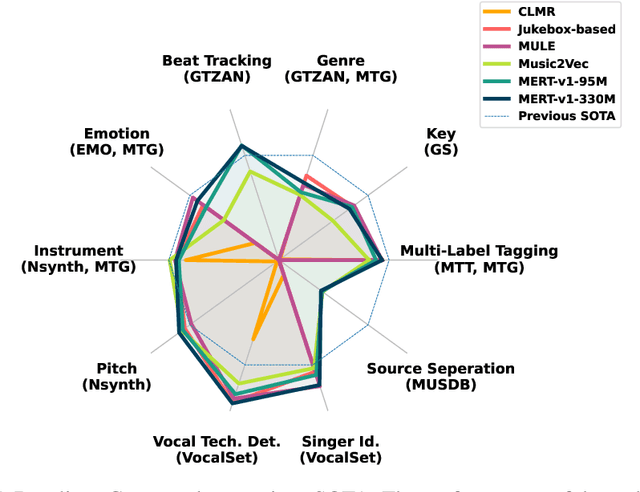
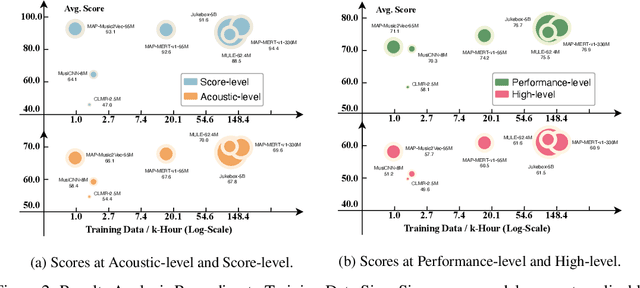
In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.
Unveiling the Invisible: Enhanced Detection and Analysis of Deteriorated Areas in Solar PV Modules Using Unsupervised Sensing Algorithms and 3D Augmented Reality
Jul 12, 2023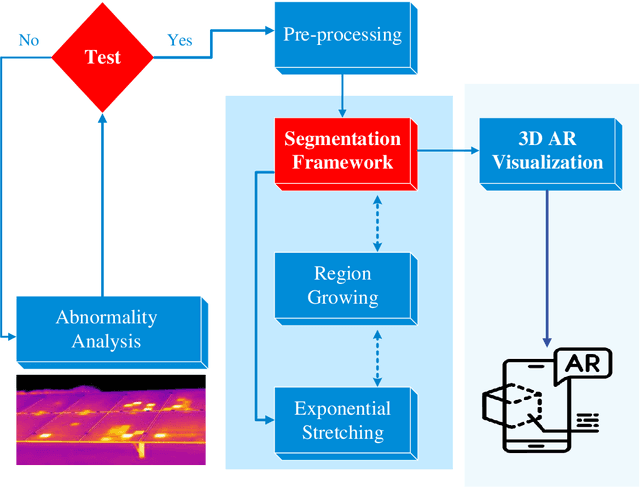

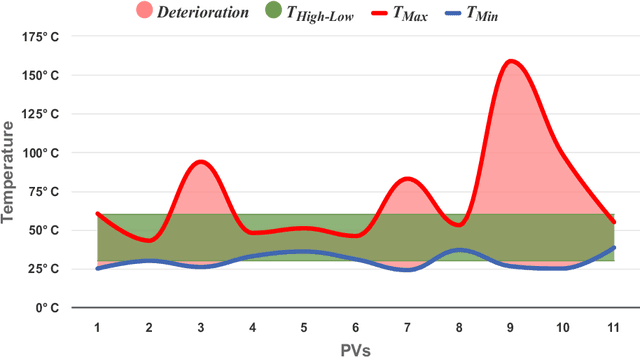
Solar Photovoltaic (PV) is increasingly being used to address the global concern of energy security. However, hot spot and snail trails in PV modules caused mostly by crakes reduce their efficiency and power capacity. This article presents a groundbreaking methodology for automatically identifying and analyzing anomalies like hot spots and snail trails in Solar Photovoltaic (PV) modules, leveraging unsupervised sensing algorithms and 3D Augmented Reality (AR) visualization. By transforming the traditional methods of diagnosis and repair, our approach not only enhances efficiency but also substantially cuts down the cost of PV system maintenance. Validated through computer simulations and real-world image datasets, the proposed framework accurately identifies dirty regions, emphasizing the critical role of regular maintenance in optimizing the power capacity of solar PV modules. Our immediate objective is to leverage drone technology for real-time, automatic solar panel detection, significantly boosting the efficacy of PV maintenance. The proposed methodology could revolutionize solar PV maintenance, enabling swift, precise anomaly detection without human intervention. This could result in significant cost savings, heightened energy production, and improved overall performance of solar PV systems. Moreover, the novel combination of unsupervised sensing algorithms with 3D AR visualization heralds new opportunities for further research and development in solar PV maintenance.
GVCCI: Lifelong Learning of Visual Grounding for Language-Guided Robotic Manipulation
Jul 12, 2023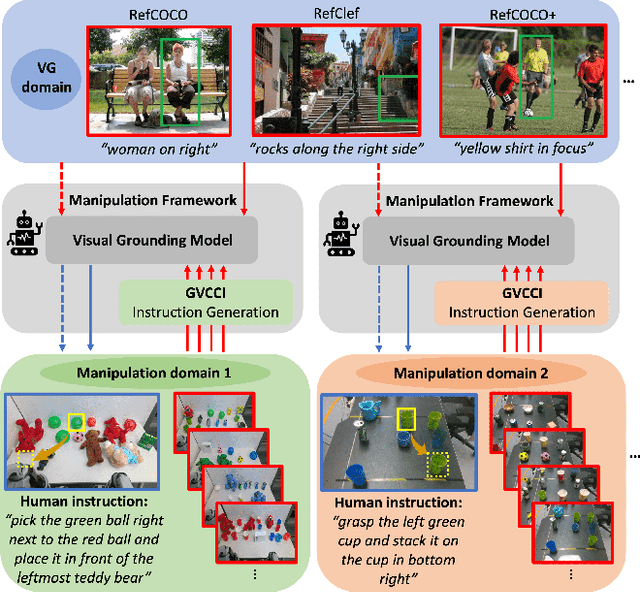

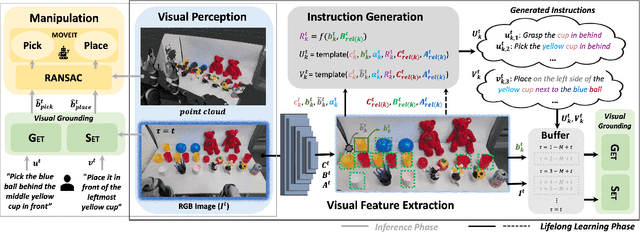

Language-Guided Robotic Manipulation (LGRM) is a challenging task as it requires a robot to understand human instructions to manipulate everyday objects. Recent approaches in LGRM rely on pre-trained Visual Grounding (VG) models to detect objects without adapting to manipulation environments. This results in a performance drop due to a substantial domain gap between the pre-training and real-world data. A straightforward solution is to collect additional training data, but the cost of human-annotation is extortionate. In this paper, we propose Grounding Vision to Ceaselessly Created Instructions (GVCCI), a lifelong learning framework for LGRM, which continuously learns VG without human supervision. GVCCI iteratively generates synthetic instruction via object detection and trains the VG model with the generated data. We validate our framework in offline and online settings across diverse environments on different VG models. Experimental results show that accumulating synthetic data from GVCCI leads to a steady improvement in VG by up to 56.7% and improves resultant LGRM by up to 29.4%. Furthermore, the qualitative analysis shows that the unadapted VG model often fails to find correct objects due to a strong bias learned from the pre-training data. Finally, we introduce a novel VG dataset for LGRM, consisting of nearly 252k triplets of image-object-instruction from diverse manipulation environments.
PrefGen: Preference Guided Image Generation with Relative Attributes
Apr 01, 2023

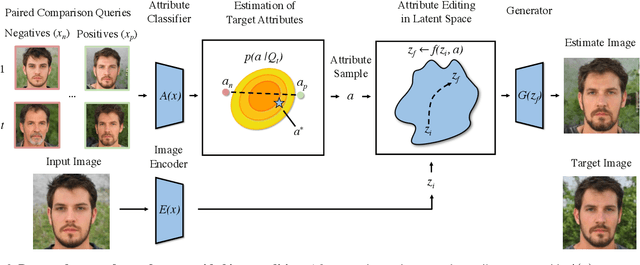
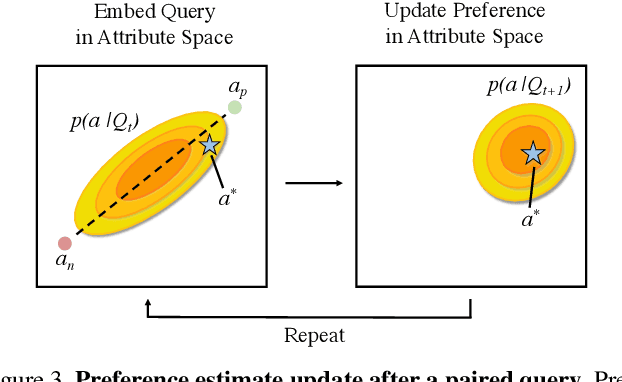
Deep generative models have the capacity to render high fidelity images of content like human faces. Recently, there has been substantial progress in conditionally generating images with specific quantitative attributes, like the emotion conveyed by one's face. These methods typically require a user to explicitly quantify the desired intensity of a visual attribute. A limitation of this method is that many attributes, like how "angry" a human face looks, are difficult for a user to precisely quantify. However, a user would be able to reliably say which of two faces seems "angrier". Following this premise, we develop the $\textit{PrefGen}$ system, which allows users to control the relative attributes of generated images by presenting them with simple paired comparison queries of the form "do you prefer image $a$ or image $b$?" Using information from a sequence of query responses, we can estimate user preferences over a set of image attributes and perform preference-guided image editing and generation. Furthermore, to make preference localization feasible and efficient, we apply an active query selection strategy. We demonstrate the success of this approach using a StyleGAN2 generator on the task of human face editing. Additionally, we demonstrate how our approach can be combined with CLIP, allowing a user to edit the relative intensity of attributes specified by text prompts. Code at https://github.com/helblazer811/PrefGen.
Multiplicative update rules for accelerating deep learning training and increasing robustness
Jul 14, 2023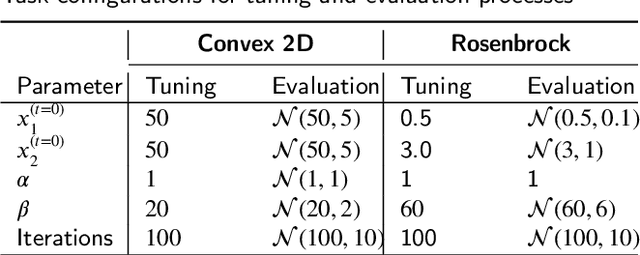
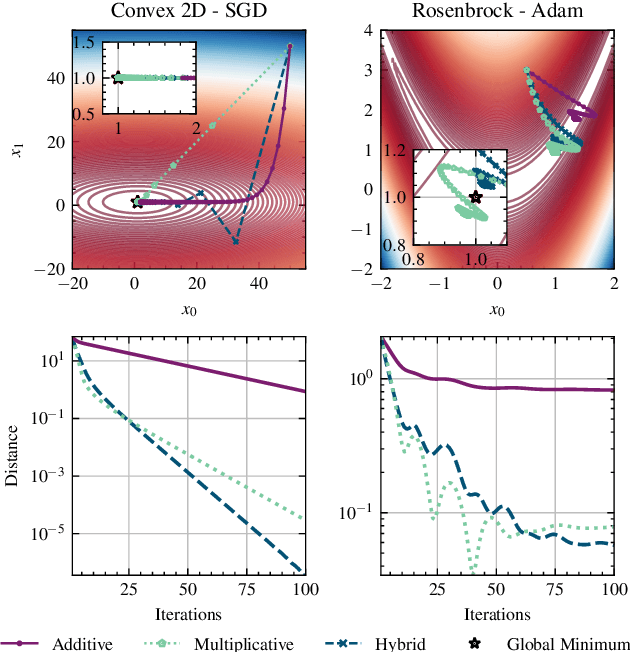
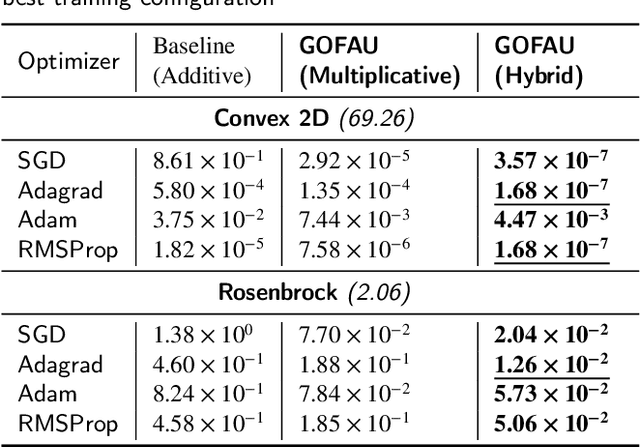
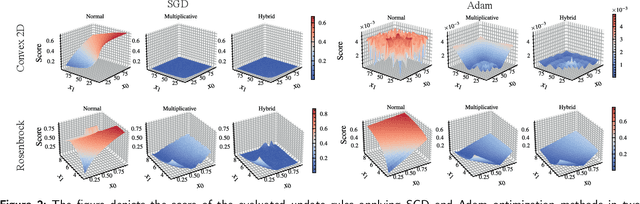
Even nowadays, where Deep Learning (DL) has achieved state-of-the-art performance in a wide range of research domains, accelerating training and building robust DL models remains a challenging task. To this end, generations of researchers have pursued to develop robust methods for training DL architectures that can be less sensitive to weight distributions, model architectures and loss landscapes. However, such methods are limited to adaptive learning rate optimizers, initialization schemes, and clipping gradients without investigating the fundamental rule of parameters update. Although multiplicative updates have contributed significantly to the early development of machine learning and hold strong theoretical claims, to best of our knowledge, this is the first work that investigate them in context of DL training acceleration and robustness. In this work, we propose an optimization framework that fits to a wide range of optimization algorithms and enables one to apply alternative update rules. To this end, we propose a novel multiplicative update rule and we extend their capabilities by combining it with a traditional additive update term, under a novel hybrid update method. We claim that the proposed framework accelerates training, while leading to more robust models in contrast to traditionally used additive update rule and we experimentally demonstrate their effectiveness in a wide range of task and optimization methods. Such tasks ranging from convex and non-convex optimization to difficult image classification benchmarks applying a wide range of traditionally used optimization methods and Deep Neural Network (DNN) architectures.
Transient Neural Radiance Fields for Lidar View Synthesis and 3D Reconstruction
Jul 14, 2023


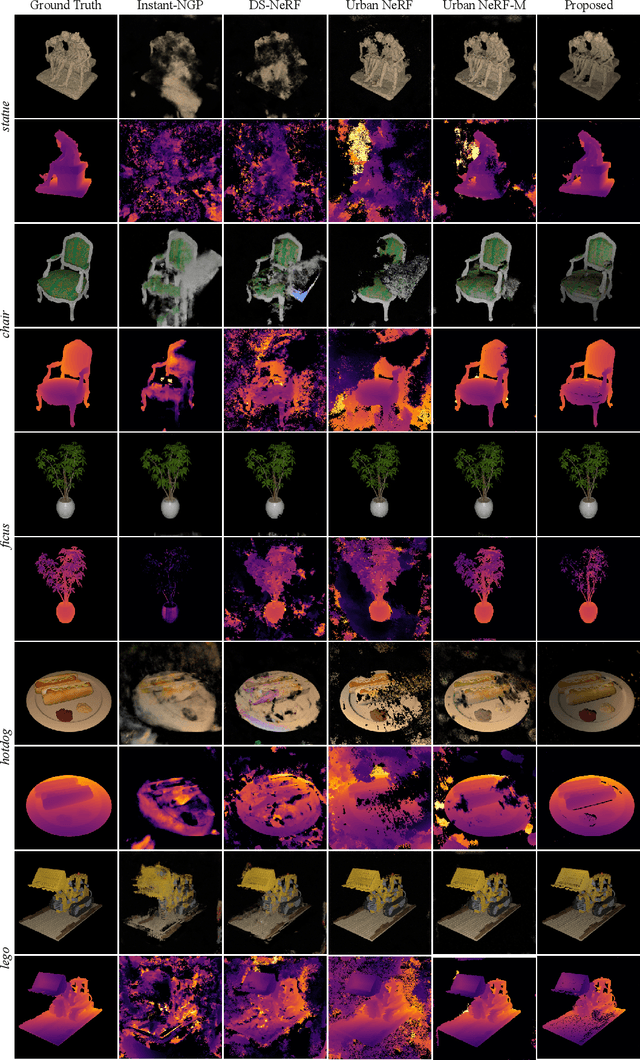
Neural radiance fields (NeRFs) have become a ubiquitous tool for modeling scene appearance and geometry from multiview imagery. Recent work has also begun to explore how to use additional supervision from lidar or depth sensor measurements in the NeRF framework. However, previous lidar-supervised NeRFs focus on rendering conventional camera imagery and use lidar-derived point cloud data as auxiliary supervision; thus, they fail to incorporate the underlying image formation model of the lidar. Here, we propose a novel method for rendering transient NeRFs that take as input the raw, time-resolved photon count histograms measured by a single-photon lidar system, and we seek to render such histograms from novel views. Different from conventional NeRFs, the approach relies on a time-resolved version of the volume rendering equation to render the lidar measurements and capture transient light transport phenomena at picosecond timescales. We evaluate our method on a first-of-its-kind dataset of simulated and captured transient multiview scans from a prototype single-photon lidar. Overall, our work brings NeRFs to a new dimension of imaging at transient timescales, newly enabling rendering of transient imagery from novel views. Additionally, we show that our approach recovers improved geometry and conventional appearance compared to point cloud-based supervision when training on few input viewpoints. Transient NeRFs may be especially useful for applications which seek to simulate raw lidar measurements for downstream tasks in autonomous driving, robotics, and remote sensing.
Unlocking Masked Autoencoders as Loss Function for Image and Video Restoration
Mar 29, 2023
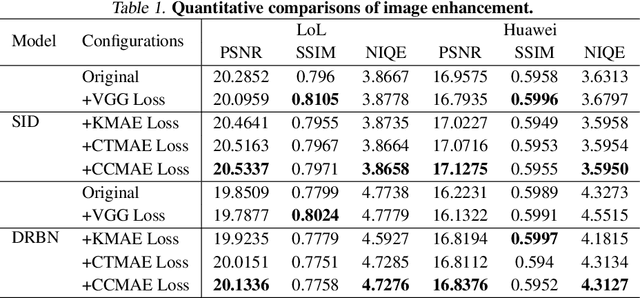
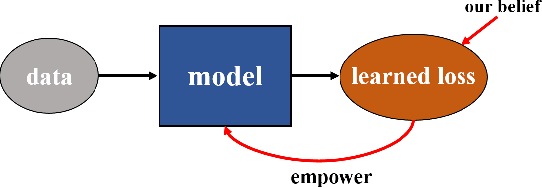
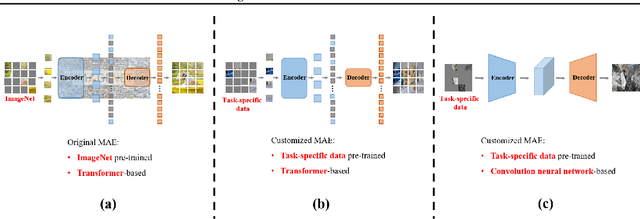
Image and video restoration has achieved a remarkable leap with the advent of deep learning. The success of deep learning paradigm lies in three key components: data, model, and loss. Currently, many efforts have been devoted to the first two while seldom study focuses on loss function. With the question ``are the de facto optimization functions e.g., $L_1$, $L_2$, and perceptual losses optimal?'', we explore the potential of loss and raise our belief ``learned loss function empowers the learning capability of neural networks for image and video restoration''. Concretely, we stand on the shoulders of the masked Autoencoders (MAE) and formulate it as a `learned loss function', owing to the fact the pre-trained MAE innately inherits the prior of image reasoning. We investigate the efficacy of our belief from three perspectives: 1) from task-customized MAE to native MAE, 2) from image task to video task, and 3) from transformer structure to convolution neural network structure. Extensive experiments across multiple image and video tasks, including image denoising, image super-resolution, image enhancement, guided image super-resolution, video denoising, and video enhancement, demonstrate the consistent performance improvements introduced by the learned loss function. Besides, the learned loss function is preferable as it can be directly plugged into existing networks during training without involving computations in the inference stage. Code will be publicly available.
Defect Detection Approaches Based on Simulated Reference Image
Mar 21, 2023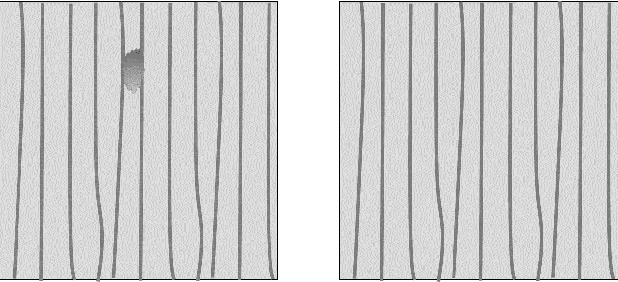

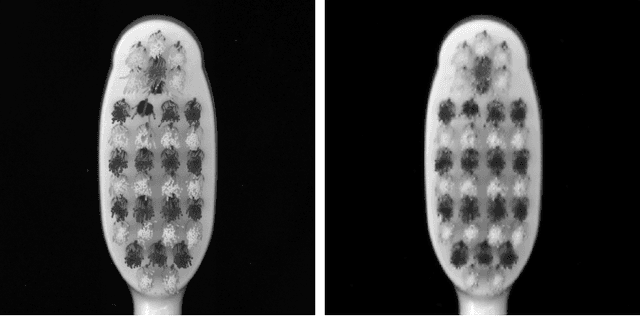

This work is addressing the problem of defect anomaly detection based on a clean reference image. Specifically, we focus on SEM semiconductor defects in addition to several natural image anomalies. There are well-known methods to create a simulation of an artificial reference image by its defect specimen. In this work, we introduce several applications for this capability, that the simulated reference is beneficial for improving their results. Among these defect detection methods are classic computer vision applied on difference-image, supervised deep-learning (DL) based on human labels, and unsupervised DL which is trained on feature-level patterns of normal reference images. We show in this study how to incorporate correctly the simulated reference image for these defect and anomaly detection applications. As our experiment demonstrates, simulated reference achieves higher performance than the real reference of an image of a defect and anomaly. This advantage of simulated reference occurs mainly due to the less noise and geometric variations together with better alignment and registration to the original defect background.
Computationally-efficient and perceptually-motivated rendering of diffuse reflections in room acoustics simulation
Jun 29, 2023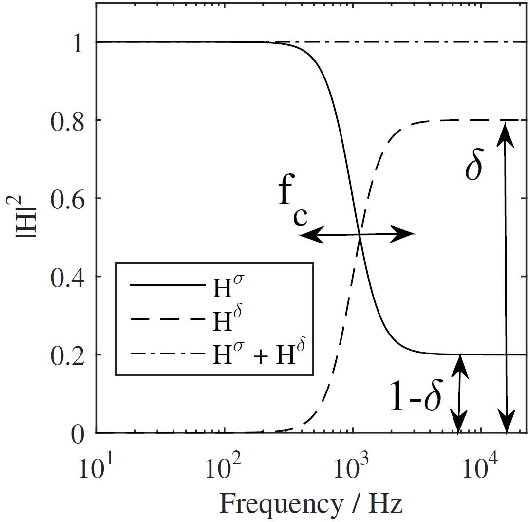
Geometrical acoustics is well suited for simulating room reverberation in interactive real-time applications. While the image source model (ISM) is exceptionally fast, the restriction to specular reflections impacts its perceptual plausibility. To account for diffuse late reverberation, hybrid approaches have been proposed, e.g., using a feedback delay network (FDN) in combination with the ISM. Here, a computationally-efficient, digital-filter approach is suggested to account for effects of non-specular reflections in the ISM and to couple scattered sound into a diffuse reverberation model using a spatially rendered FDN. Depending on the scattering coefficient of a room boundary, energy of each image source is split into a specular and a scattered part which is added to the diffuse sound field. Temporal effects as observed for an infinite ideal diffuse (Lambertian) reflector are simulated using cascaded all-pass filters. Effects of scattering and multiple (inter-) reflections caused by larger geometric disturbances at walls and by objects in the room are accounted for in a highly simplified manner. Using a single parameter to quantify deviations from an empty shoebox room, each reflection is temporally smeared using cascaded all-pass filters. The proposed method was perceptually evaluated against dummy head recordings of real rooms.