 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
Jun 28, 2023
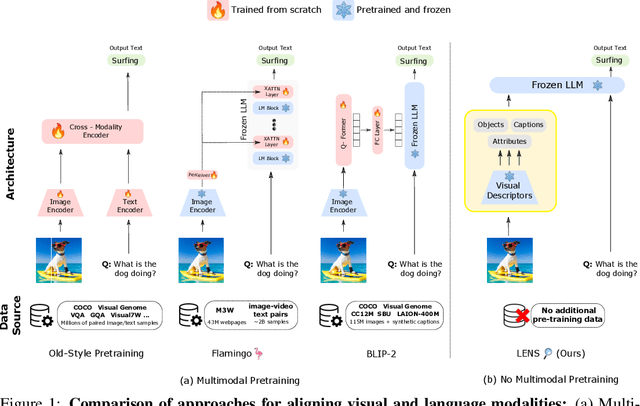
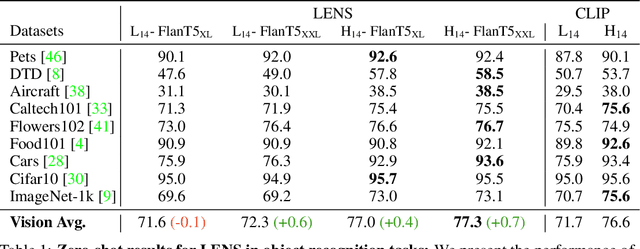
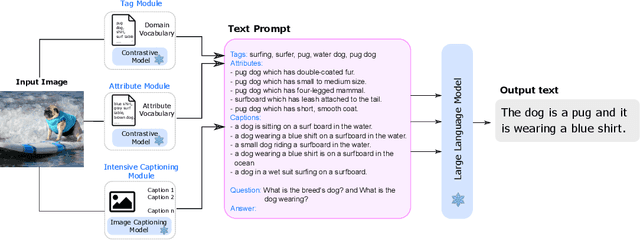
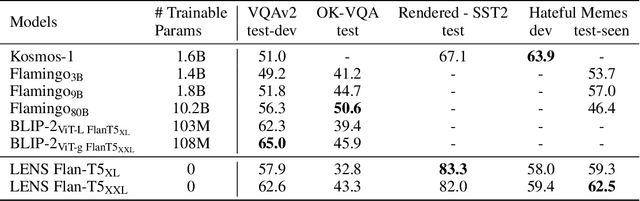
We propose LENS, a modular approach for tackling computer vision problems by leveraging the power of large language models (LLMs). Our system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. We evaluate the approach on pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and we find that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever. We open-source our code at https://github.com/ContextualAI/lens and provide an interactive demo.
RIDCP: Revitalizing Real Image Dehazing via High-Quality Codebook Priors
Apr 08, 2023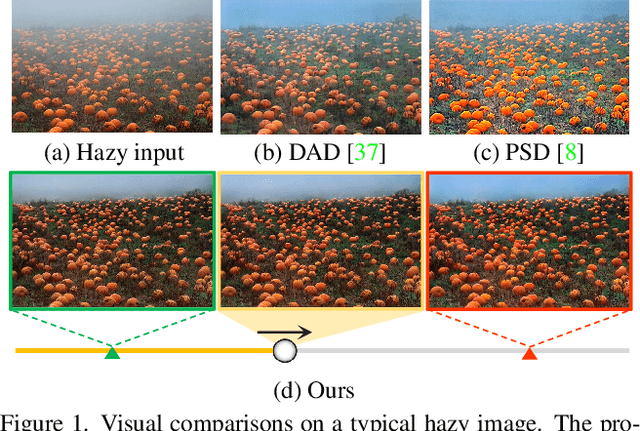
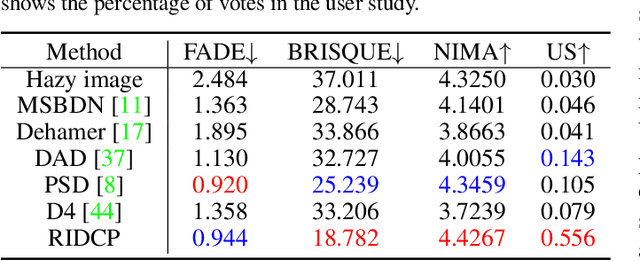
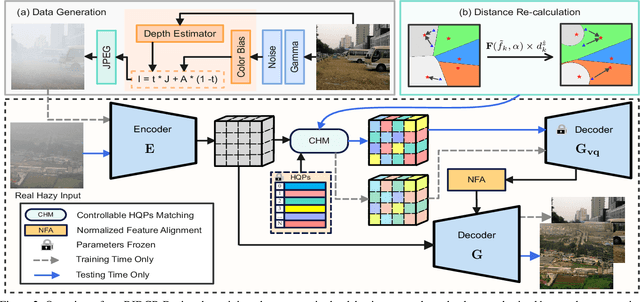
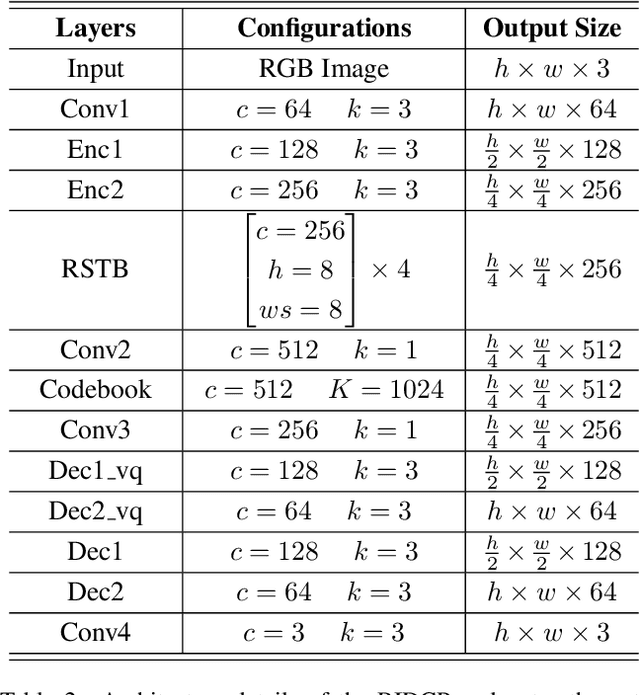
Existing dehazing approaches struggle to process real-world hazy images owing to the lack of paired real data and robust priors. In this work, we present a new paradigm for real image dehazing from the perspectives of synthesizing more realistic hazy data and introducing more robust priors into the network. Specifically, (1) instead of adopting the de facto physical scattering model, we rethink the degradation of real hazy images and propose a phenomenological pipeline considering diverse degradation types. (2) We propose a Real Image Dehazing network via high-quality Codebook Priors (RIDCP). Firstly, a VQGAN is pre-trained on a large-scale high-quality dataset to obtain the discrete codebook, encapsulating high-quality priors (HQPs). After replacing the negative effects brought by haze with HQPs, the decoder equipped with a novel normalized feature alignment module can effectively utilize high-quality features and produce clean results. However, although our degradation pipeline drastically mitigates the domain gap between synthetic and real data, it is still intractable to avoid it, which challenges HQPs matching in the wild. Thus, we re-calculate the distance when matching the features to the HQPs by a controllable matching operation, which facilitates finding better counterparts. We provide a recommendation to control the matching based on an explainable solution. Users can also flexibly adjust the enhancement degree as per their preference. Extensive experiments verify the effectiveness of our data synthesis pipeline and the superior performance of RIDCP in real image dehazing.
SMRVIS: Point cloud extraction from 3-D ultrasound for non-destructive testing
Jun 16, 2023
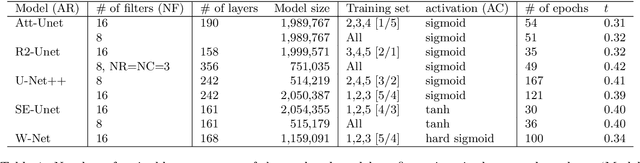
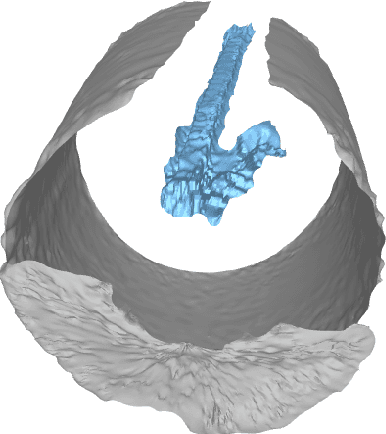

We propose to formulate point cloud extraction from ultrasound volumes as an image segmentation problem. Through this convenient formulation, a quick prototype exploring various variants of the Residual Network, U-Net, and the Squeeze and Excitation Network was developed and evaluated. This report documents the experimental results compiled using a training dataset of five labeled ultrasound volumes and 84 unlabeled volumes that got completed in a two-week period as part of a submission to the open challenge "3D Surface Mesh Estimation for CVPR workshop on Deep Learning in Ultrasound Image Analysis". Based on external evaluation performed by the challenge's organizers, the framework came first place on the challenge's \href{https://www.cvpr2023-dl-ultrasound.com/}{Leaderboard}. Source code is shared with the research community at a \href{https://github.com/lisatwyw/smrvis}{public repository}.
A Novel Dual-pooling Attention Module for UAV Vehicle Re-identification
Jun 25, 2023
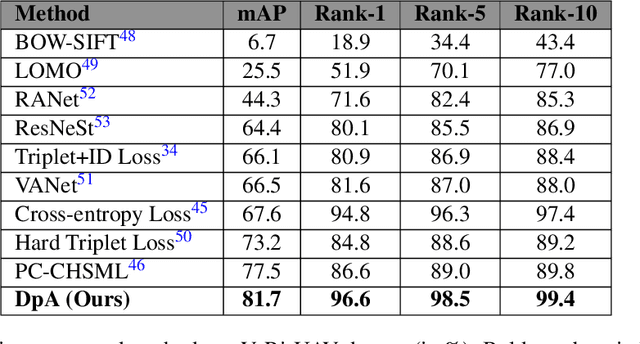
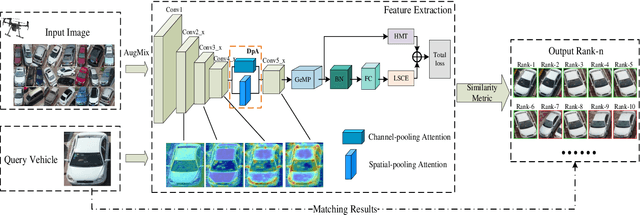
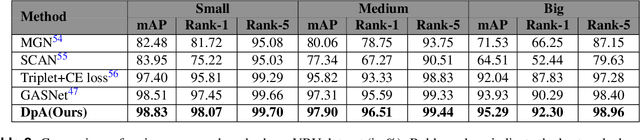
Vehicle re-identification (Re-ID) involves identifying the same vehicle captured by other cameras, given a vehicle image. It plays a crucial role in the development of safe cities and smart cities. With the rapid growth and implementation of unmanned aerial vehicles (UAVs) technology, vehicle Re-ID in UAV aerial photography scenes has garnered significant attention from researchers. However, due to the high altitude of UAVs, the shooting angle of vehicle images sometimes approximates vertical, resulting in fewer local features for Re-ID. Therefore, this paper proposes a novel dual-pooling attention (DpA) module, which achieves the extraction and enhancement of locally important information about vehicles from both channel and spatial dimensions by constructing two branches of channel-pooling attention (CpA) and spatial-pooling attention (SpA), and employing multiple pooling operations to enhance the attention to fine-grained information of vehicles. Specifically, the CpA module operates between the channels of the feature map and splices features by combining four pooling operations so that vehicle regions containing discriminative information are given greater attention. The SpA module uses the same pooling operations strategy to identify discriminative representations and merge vehicle features in image regions in a weighted manner. The feature information of both dimensions is finally fused and trained jointly using label smoothing cross-entropy loss and hard mining triplet loss, thus solving the problem of missing detail information due to the high height of UAV shots. The proposed method's effectiveness is demonstrated through extensive experiments on the UAV-based vehicle datasets VeRi-UAV and VRU.
Real-time Controllable Denoising for Image and Video
Mar 29, 2023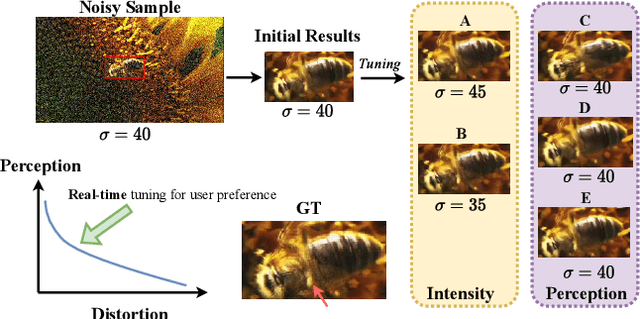
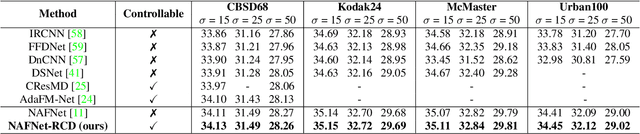
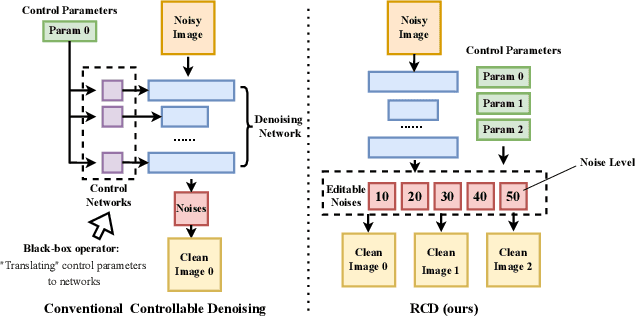

Controllable image denoising aims to generate clean samples with human perceptual priors and balance sharpness and smoothness. In traditional filter-based denoising methods, this can be easily achieved by adjusting the filtering strength. However, for NN (Neural Network)-based models, adjusting the final denoising strength requires performing network inference each time, making it almost impossible for real-time user interaction. In this paper, we introduce Real-time Controllable Denoising (RCD), the first deep image and video denoising pipeline that provides a fully controllable user interface to edit arbitrary denoising levels in real-time with only one-time network inference. Unlike existing controllable denoising methods that require multiple denoisers and training stages, RCD replaces the last output layer (which usually outputs a single noise map) of an existing CNN-based model with a lightweight module that outputs multiple noise maps. We propose a novel Noise Decorrelation process to enforce the orthogonality of the noise feature maps, allowing arbitrary noise level control through noise map interpolation. This process is network-free and does not require network inference. Our experiments show that RCD can enable real-time editable image and video denoising for various existing heavy-weight models without sacrificing their original performance.
MetaRegNet: Metamorphic Image Registration Using Flow-Driven Residual Networks
Mar 16, 2023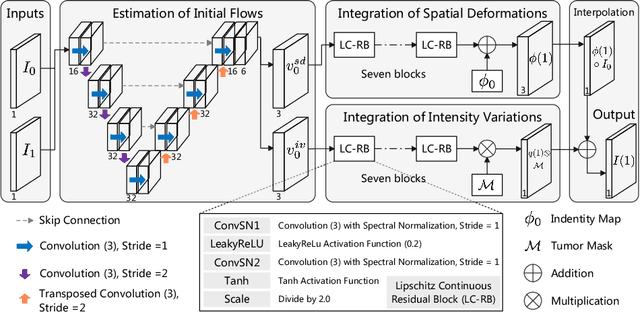
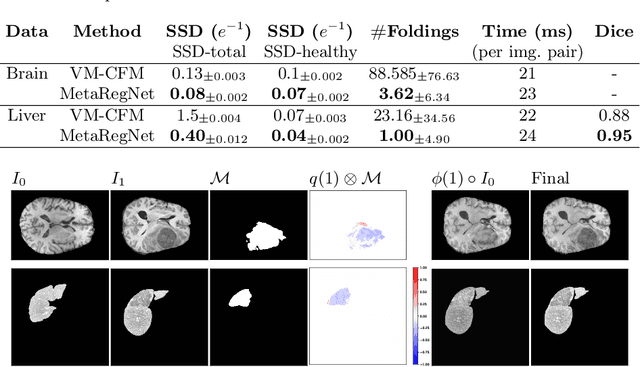
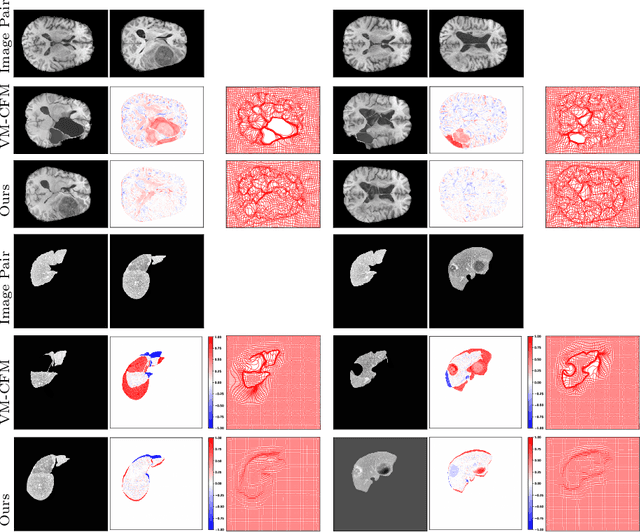
Deep learning based methods provide efficient solutions to medical image registration, including the challenging problem of diffeomorphic image registration. However, most methods register normal image pairs, facing difficulty handling those with missing correspondences, e.g., in the presence of pathology like tumors. We desire an efficient solution to jointly account for spatial deformations and appearance changes in the pathological regions where the correspondences are missing, i.e., finding a solution to metamorphic image registration. Some approaches are proposed to tackle this problem, but they cannot properly handle large pathological regions and deformations around pathologies. In this paper, we propose a deep metamorphic image registration network (MetaRegNet), which adopts time-varying flows to drive spatial diffeomorphic deformations and generate intensity variations. We evaluate MetaRegNet on two datasets, i.e., BraTS 2021 with brain tumors and 3D-IRCADb-01 with liver tumors, showing promising results in registering a healthy and tumor image pair. The source code is available online.
Hamming Similarity and Graph Laplacians for Class Partitioning and Adversarial Image Detection
May 02, 2023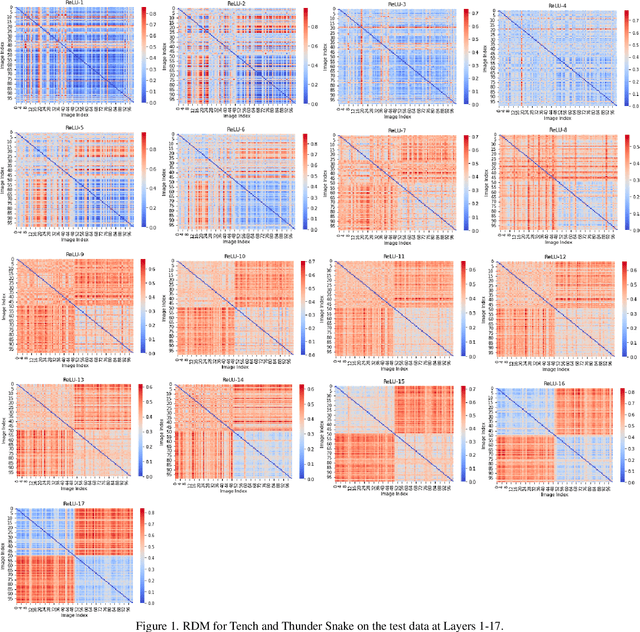

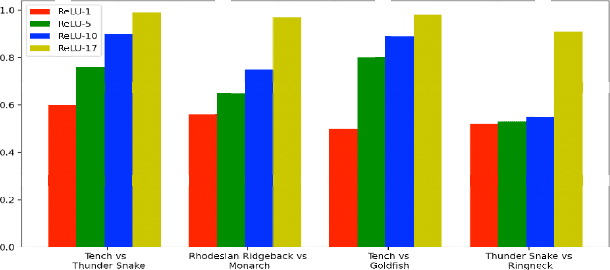

Researchers typically investigate neural network representations by examining activation outputs for one or more layers of a network. Here, we investigate the potential for ReLU activation patterns (encoded as bit vectors) to aid in understanding and interpreting the behavior of neural networks. We utilize Representational Dissimilarity Matrices (RDMs) to investigate the coherence of data within the embedding spaces of a deep neural network. From each layer of a network, we extract and utilize bit vectors to construct similarity scores between images. From these similarity scores, we build a similarity matrix for a collection of images drawn from 2 classes. We then apply Fiedler partitioning to the associated Laplacian matrix to separate the classes. Our results indicate, through bit vector representations, that the network continues to refine class detectability with the last ReLU layer achieving better than 95\% separation accuracy. Additionally, we demonstrate that bit vectors aid in adversarial image detection, again achieving over 95\% accuracy in separating adversarial and non-adversarial images using a simple classifier.
Differentially Private Image Classification by Learning Priors from Random Processes
Jun 08, 2023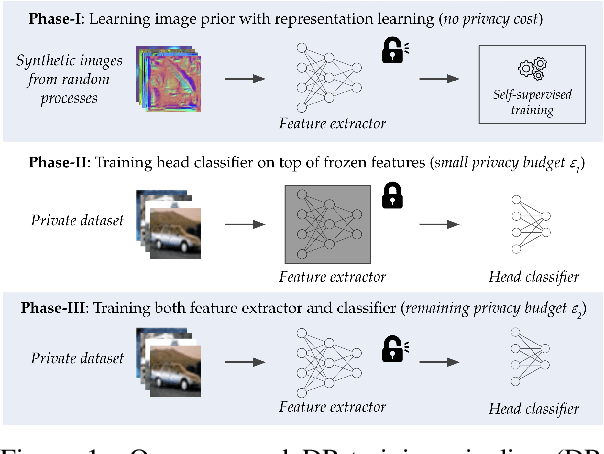
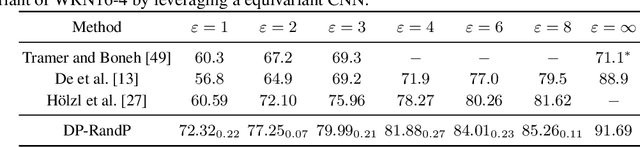
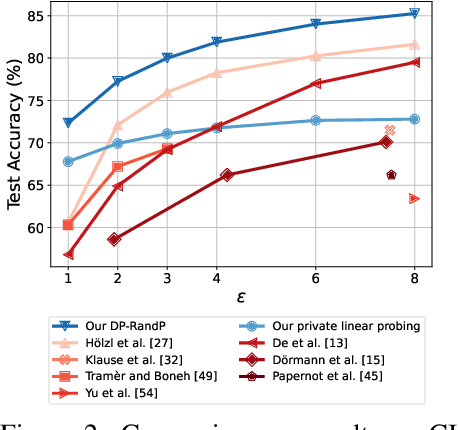

In privacy-preserving machine learning, differentially private stochastic gradient descent (DP-SGD) performs worse than SGD due to per-sample gradient clipping and noise addition. A recent focus in private learning research is improving the performance of DP-SGD on private data by incorporating priors that are learned on real-world public data. In this work, we explore how we can improve the privacy-utility tradeoff of DP-SGD by learning priors from images generated by random processes and transferring these priors to private data. We propose DP-RandP, a three-phase approach. We attain new state-of-the-art accuracy when training from scratch on CIFAR10, CIFAR100, and MedMNIST for a range of privacy budgets $\varepsilon \in [1, 8]$. In particular, we improve the previous best reported accuracy on CIFAR10 from $60.6 \%$ to $72.3 \%$ for $\varepsilon=1$. Our code is available at https://github.com/inspire-group/DP-RandP.
Picture that Sketch: Photorealistic Image Generation from Abstract Sketches
Mar 30, 2023
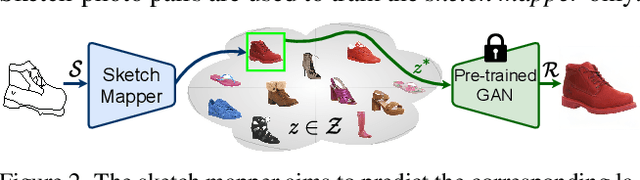
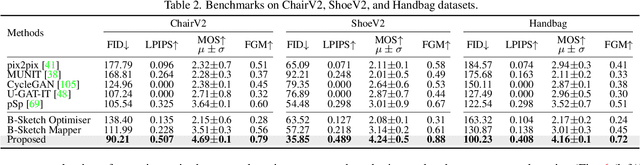
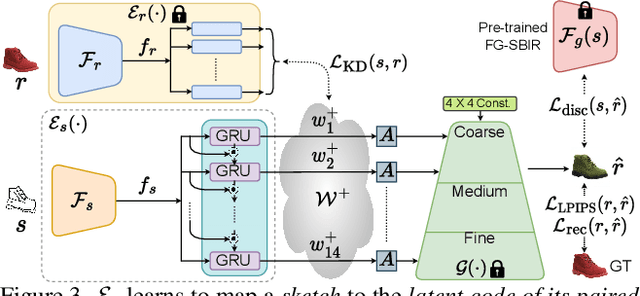
Given an abstract, deformed, ordinary sketch from untrained amateurs like you and me, this paper turns it into a photorealistic image - just like those shown in Fig. 1(a), all non-cherry-picked. We differ significantly from prior art in that we do not dictate an edgemap-like sketch to start with, but aim to work with abstract free-hand human sketches. In doing so, we essentially democratise the sketch-to-photo pipeline, "picturing" a sketch regardless of how good you sketch. Our contribution at the outset is a decoupled encoder-decoder training paradigm, where the decoder is a StyleGAN trained on photos only. This importantly ensures that generated results are always photorealistic. The rest is then all centred around how best to deal with the abstraction gap between sketch and photo. For that, we propose an autoregressive sketch mapper trained on sketch-photo pairs that maps a sketch to the StyleGAN latent space. We further introduce specific designs to tackle the abstract nature of human sketches, including a fine-grained discriminative loss on the back of a trained sketch-photo retrieval model, and a partial-aware sketch augmentation strategy. Finally, we showcase a few downstream tasks our generation model enables, amongst them is showing how fine-grained sketch-based image retrieval, a well-studied problem in the sketch community, can be reduced to an image (generated) to image retrieval task, surpassing state-of-the-arts. We put forward generated results in the supplementary for everyone to scrutinise.
A Comparison of Image Denoising Methods
Apr 18, 2023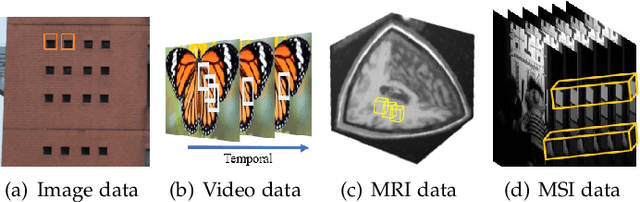
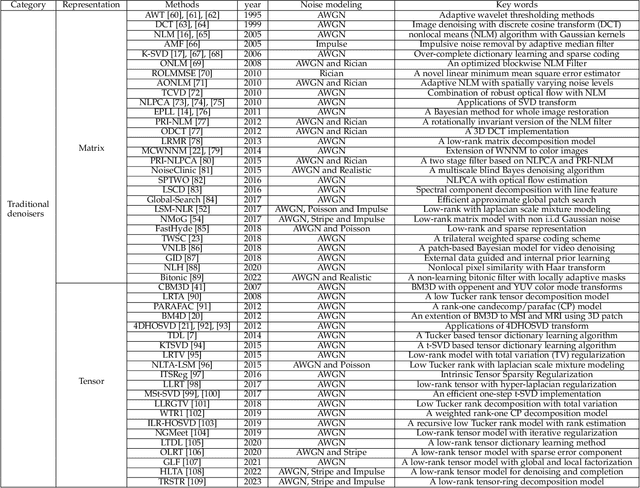
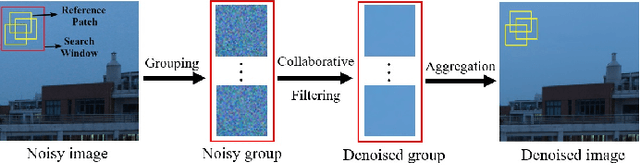
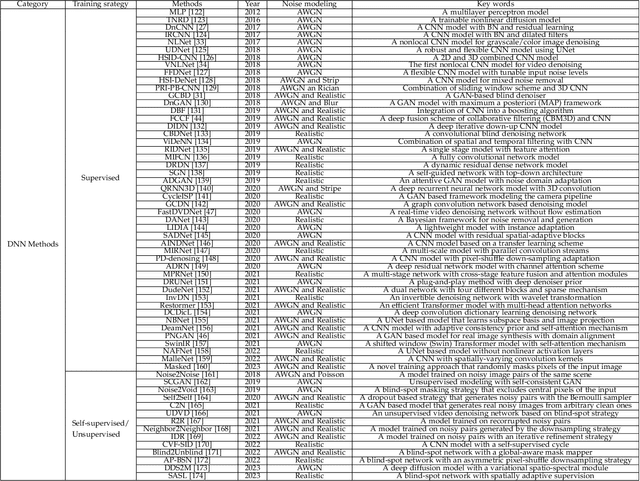
The advancement of imaging devices and countless images generated everyday pose an increasingly high demand on image denoising, which still remains a challenging task in terms of both effectiveness and efficiency. To improve denoising quality, numerous denoising techniques and approaches have been proposed in the past decades, including different transforms, regularization terms, algebraic representations and especially advanced deep neural network (DNN) architectures. Despite their sophistication, many methods may fail to achieve desirable results for simultaneous noise removal and fine detail preservation. In this paper, to investigate the applicability of existing denoising techniques, we compare a variety of denoising methods on both synthetic and real-world datasets for different applications. We also introduce a new dataset for benchmarking, and the evaluations are performed from four different perspectives including quantitative metrics, visual effects, human ratings and computational cost. Our experiments demonstrate: (i) the effectiveness and efficiency of representative traditional denoisers for various denoising tasks, (ii) a simple matrix-based algorithm may be able to produce similar results compared with its tensor counterparts, and (iii) the notable achievements of DNN models, which exhibit impressive generalization ability and show state-of-the-art performance on various datasets. In spite of the progress in recent years, we discuss shortcomings and possible extensions of existing techniques. Datasets, code and results are made publicly available and will be continuously updated at https://github.com/ZhaomingKong/Denoising-Comparison.