 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SVIT: Scaling up Visual Instruction Tuning
Jul 09, 2023


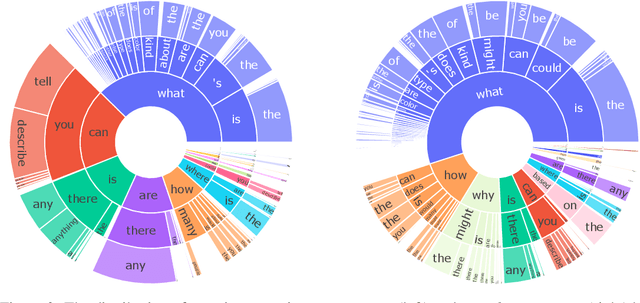

Thanks to the emerging of foundation models, the large language and vision models are integrated to acquire the multimodal ability of visual captioning, dialogue, question answering, etc. Although existing multimodal models present impressive performance of visual understanding and reasoning, their limits are still largely under-explored due to the scarcity of high-quality instruction tuning data. To push the limits of multimodal capability, we Sale up Visual Instruction Tuning (SVIT) by constructing a dataset of 3.2 million visual instruction tuning data including 1.6M conversation question-answer (QA) pairs and 1.6M complex reasoning QA pairs and 106K detailed image descriptions. Besides the volume, the proposed dataset is also featured by the high quality and rich diversity, which is generated by prompting GPT-4 with the abundant manual annotations of images. We empirically verify that training multimodal models on SVIT can significantly improve the multimodal performance in terms of visual perception, reasoning and planing.
ECL: Class-Enhancement Contrastive Learning for Long-tailed Skin Lesion Classification
Jul 09, 2023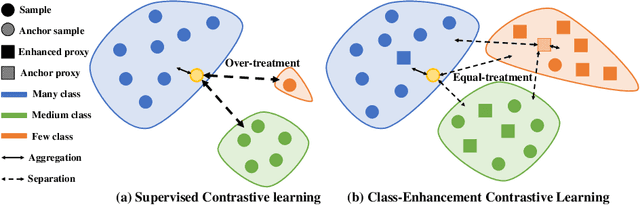
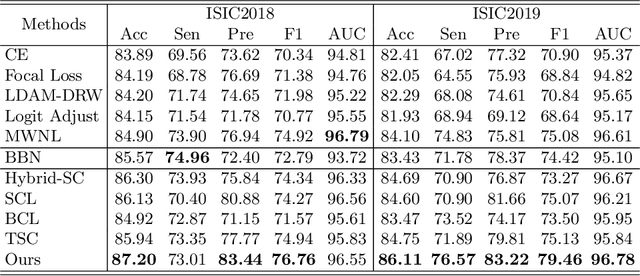
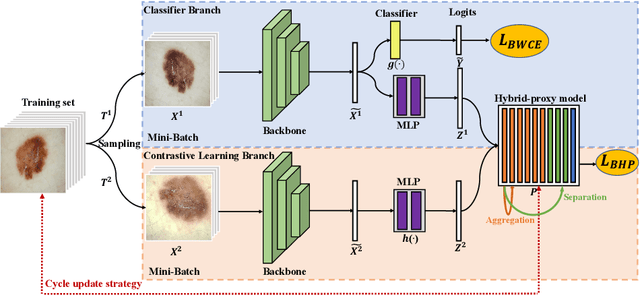
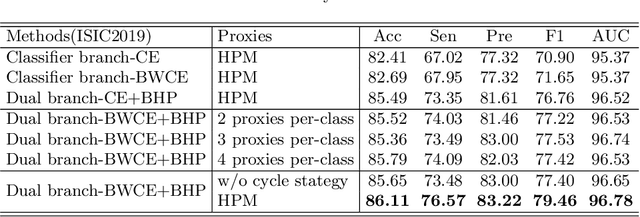
Skin image datasets often suffer from imbalanced data distribution, exacerbating the difficulty of computer-aided skin disease diagnosis. Some recent works exploit supervised contrastive learning (SCL) for this long-tailed challenge. Despite achieving significant performance, these SCL-based methods focus more on head classes, yet ignoring the utilization of information in tail classes. In this paper, we propose class-Enhancement Contrastive Learning (ECL), which enriches the information of minority classes and treats different classes equally. For information enhancement, we design a hybrid-proxy model to generate class-dependent proxies and propose a cycle update strategy for parameters optimization. A balanced-hybrid-proxy loss is designed to exploit relations between samples and proxies with different classes treated equally. Taking both "imbalanced data" and "imbalanced diagnosis difficulty" into account, we further present a balanced-weighted cross-entropy loss following curriculum learning schedule. Experimental results on the classification of imbalanced skin lesion data have demonstrated the superiority and effectiveness of our method.
Zero-shot Image-to-Image Translation
Feb 06, 2023
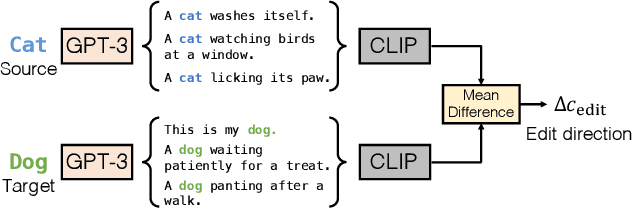

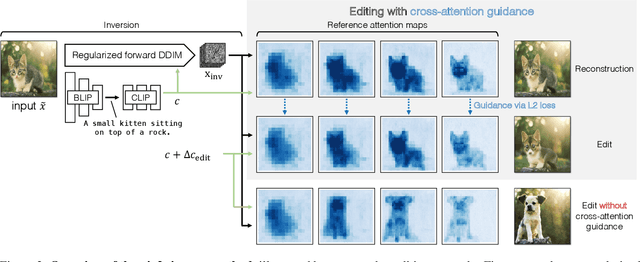
Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.
Efficient Annotation of Medieval Charters
Jun 24, 2023
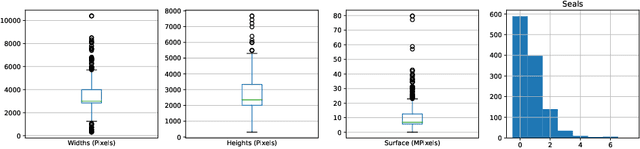
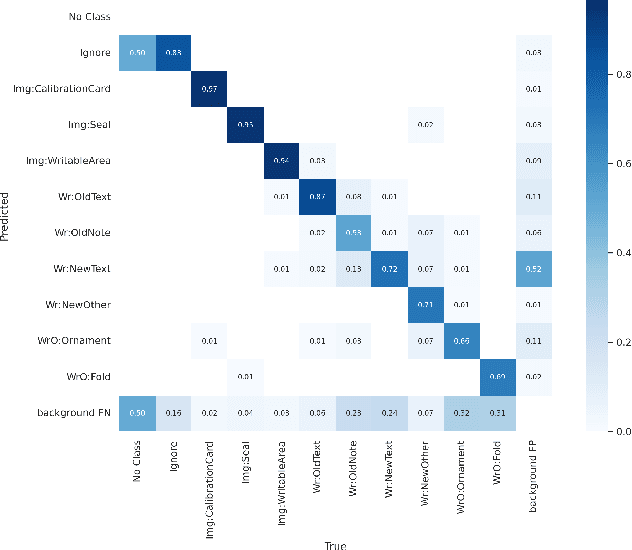
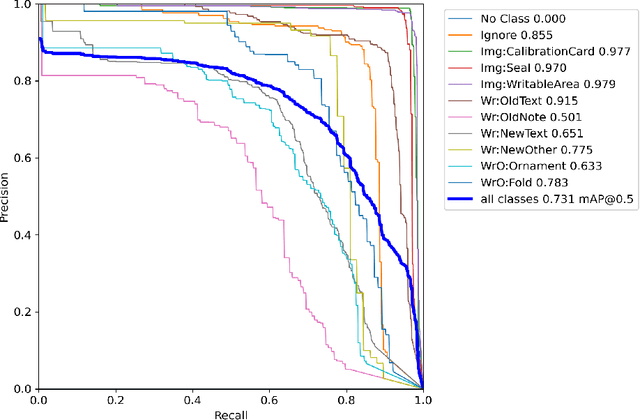
Diplomatics, the analysis of medieval charters, is a major field of research in which paleography is applied. Annotating data, if performed by laymen, needs validation and correction by experts. In this paper, we propose an effective and efficient annotation approach for charter segmentation, essentially reducing it to object detection. This approach allows for a much more efficient use of the paleographer's time and produces results that can compete and even outperform pixel-level segmentation in some use cases. Further experiments shed light on how to design a class ontology in order to make the best use of annotators' time and effort. Exploiting the presence of calibration cards in the image, we further annotate the data with the physical length in pixels and train regression neural networks to predict it from image patches.
Generalizable One-shot Neural Head Avatar
Jun 14, 2023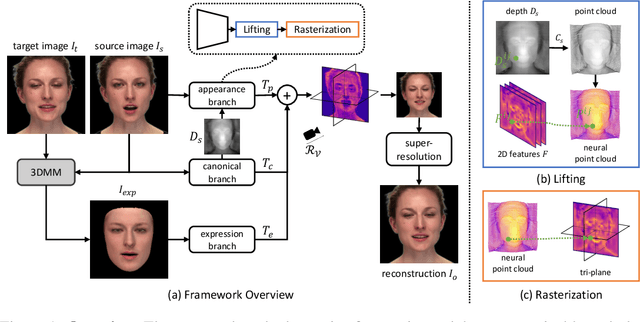
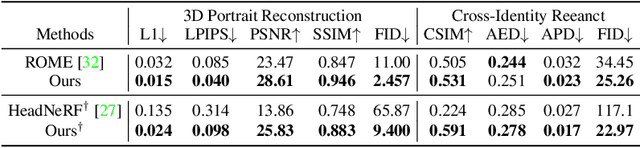

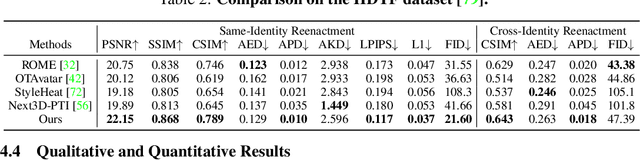
We present a method that reconstructs and animates a 3D head avatar from a single-view portrait image. Existing methods either involve time-consuming optimization for a specific person with multiple images, or they struggle to synthesize intricate appearance details beyond the facial region. To address these limitations, we propose a framework that not only generalizes to unseen identities based on a single-view image without requiring person-specific optimization, but also captures characteristic details within and beyond the face area (e.g. hairstyle, accessories, etc.). At the core of our method are three branches that produce three tri-planes representing the coarse 3D geometry, detailed appearance of a source image, as well as the expression of a target image. By applying volumetric rendering to the combination of the three tri-planes followed by a super-resolution module, our method yields a high fidelity image of the desired identity, expression and pose. Once trained, our model enables efficient 3D head avatar reconstruction and animation via a single forward pass through a network. Experiments show that the proposed approach generalizes well to unseen validation datasets, surpassing SOTA baseline methods by a large margin on head avatar reconstruction and animation.
Sulcal Pattern Matching with the Wasserstein Distance
Jul 01, 2023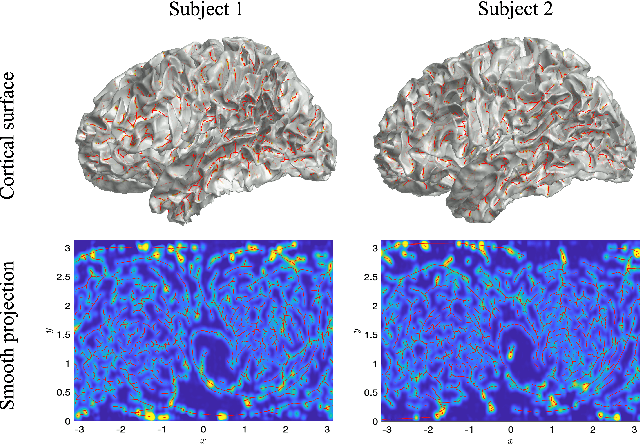
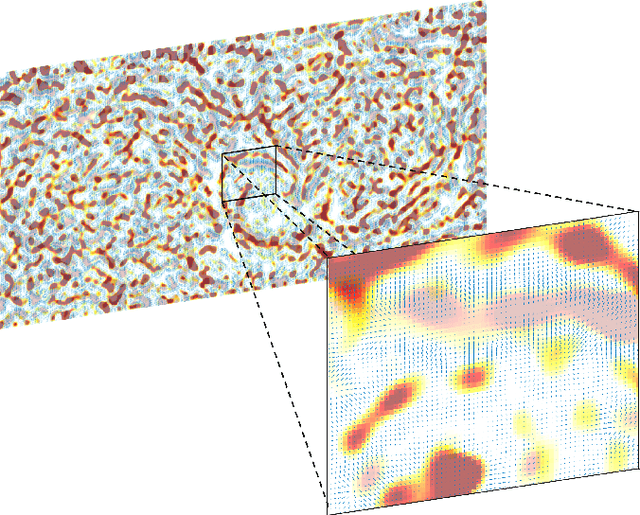
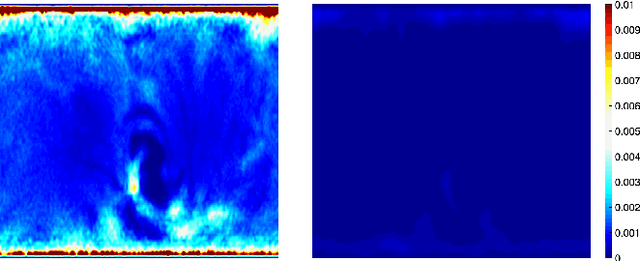
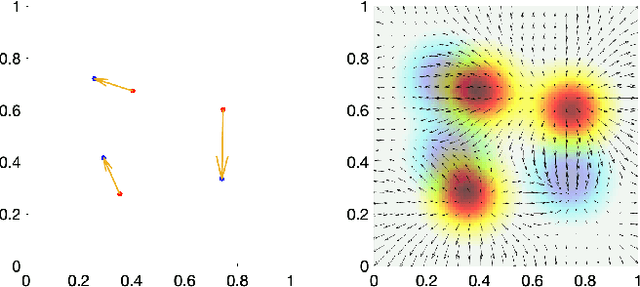
We present the unified computational framework for modeling the sulcal patterns of human brain obtained from the magnetic resonance images. The Wasserstein distance is used to align the sulcal patterns nonlinearly. These patterns are topologically different across subjects making the pattern matching a challenge. We work out the mathematical details and develop the gradient descent algorithms for estimating the deformation field. We further quantify the image registration performance. This method is applied in identifying the differences between male and female sulcal patterns.
Autoencoders with Intrinsic Dimension Constraints for Learning Low Dimensional Image Representations
Apr 16, 2023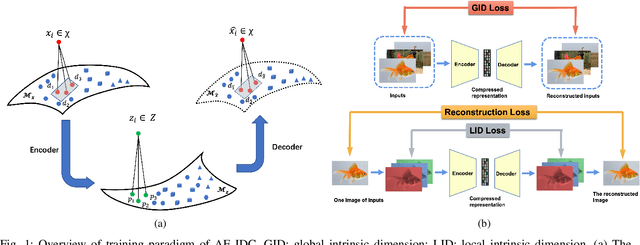
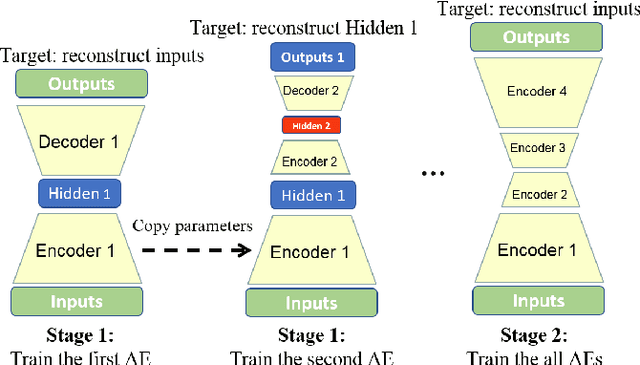
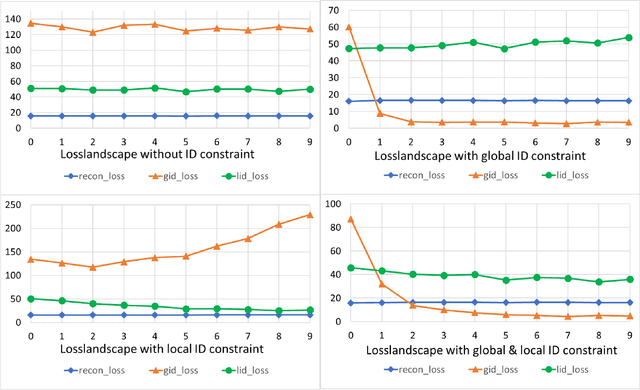

Autoencoders have achieved great success in various computer vision applications. The autoencoder learns appropriate low dimensional image representations through the self-supervised paradigm, i.e., reconstruction. Existing studies mainly focus on the minimizing the reconstruction error on pixel level of image, while ignoring the preservation of Intrinsic Dimension (ID), which is a fundamental geometric property of data representations in Deep Neural Networks (DNNs). Motivated by the important role of ID, in this paper, we propose a novel deep representation learning approach with autoencoder, which incorporates regularization of the global and local ID constraints into the reconstruction of data representations. This approach not only preserves the global manifold structure of the whole dataset, but also maintains the local manifold structure of the feature maps of each point, which makes the learned low-dimensional features more discriminant and improves the performance of the downstream algorithms. To our best knowledge, existing works are rare and limited on exploiting both global and local ID invariant properties on the regularization of autoencoders. Numerical experimental results on benchmark datasets (Extended Yale B, Caltech101 and ImageNet) show that the resulting regularized learning models achieve better discriminative representations for downstream tasks including image classification and clustering.
1st Solution Places for CVPR 2023 UG$^{\textbf{2}}$+ Challenge Track 2.1-Text Recognition through Atmospheric Turbulence
Jun 15, 2023In this technical report, we present the solution developed by our team VIELab-HUST for text recognition through atmospheric turbulence in Track 2.1 of the CVPR 2023 UG$^{2}$+ challenge. Our solution involves an efficient multi-stage framework that restores a high-quality image from distorted frames. Specifically, a frame selection algorithm based on sharpness is first utilized to select the sharpest set of distorted frames. Next, each frame in the selected frames is aligned to suppress geometric distortion through optical-flow-based image registration. Then, a region-based image fusion method with DT-CWT is utilized to mitigate the blur caused by the turbulence. Finally, a learning-based deartifacts method is applied to remove the artifacts in the fused image, generating a high-quality outuput. Our framework can handle both hot-air text dataset and turbulence text dataset provided in the final testing phase and achieved 1st place in text recognition accuracy. Our code will be available at https://github.com/xsqhust/Turbulence_Removal.
Matting Anything
Jun 08, 2023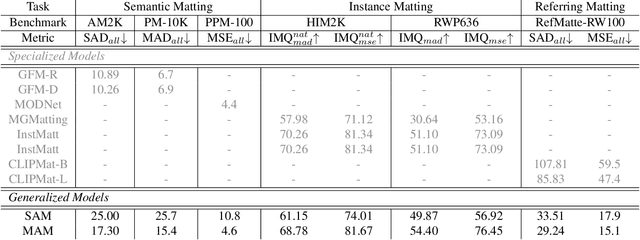
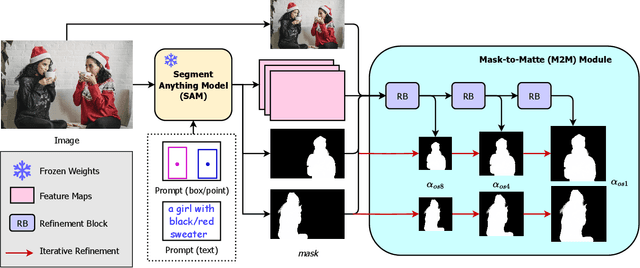
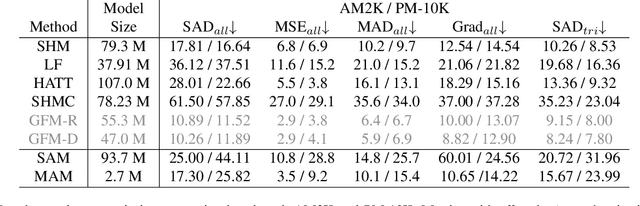
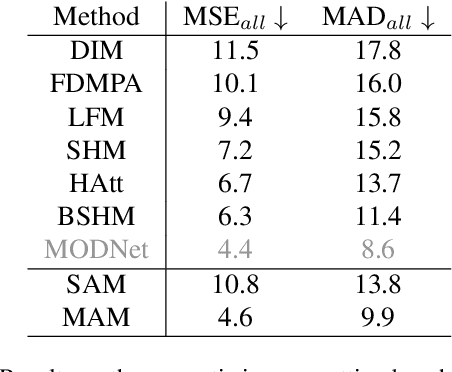
In this paper, we propose the Matting Anything Model (MAM), an efficient and versatile framework for estimating the alpha matte of any instance in an image with flexible and interactive visual or linguistic user prompt guidance. MAM offers several significant advantages over previous specialized image matting networks: (i) MAM is capable of dealing with various types of image matting, including semantic, instance, and referring image matting with only a single model; (ii) MAM leverages the feature maps from the Segment Anything Model (SAM) and adopts a lightweight Mask-to-Matte (M2M) module to predict the alpha matte through iterative refinement, which has only 2.7 million trainable parameters. (iii) By incorporating SAM, MAM simplifies the user intervention required for the interactive use of image matting from the trimap to the box, point, or text prompt. We evaluate the performance of MAM on various image matting benchmarks, and the experimental results demonstrate that MAM achieves comparable performance to the state-of-the-art specialized image matting models under different metrics on each benchmark. Overall, MAM shows superior generalization ability and can effectively handle various image matting tasks with fewer parameters, making it a practical solution for unified image matting. Our code and models are open-sourced at https://github.com/SHI-Labs/Matting-Anything.
Zero-Shot Video Editing Using Off-The-Shelf Image Diffusion Models
Apr 13, 2023
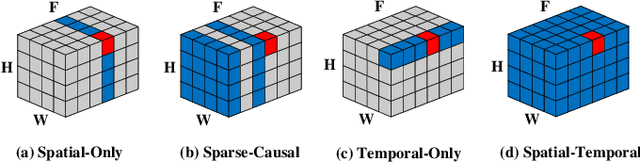

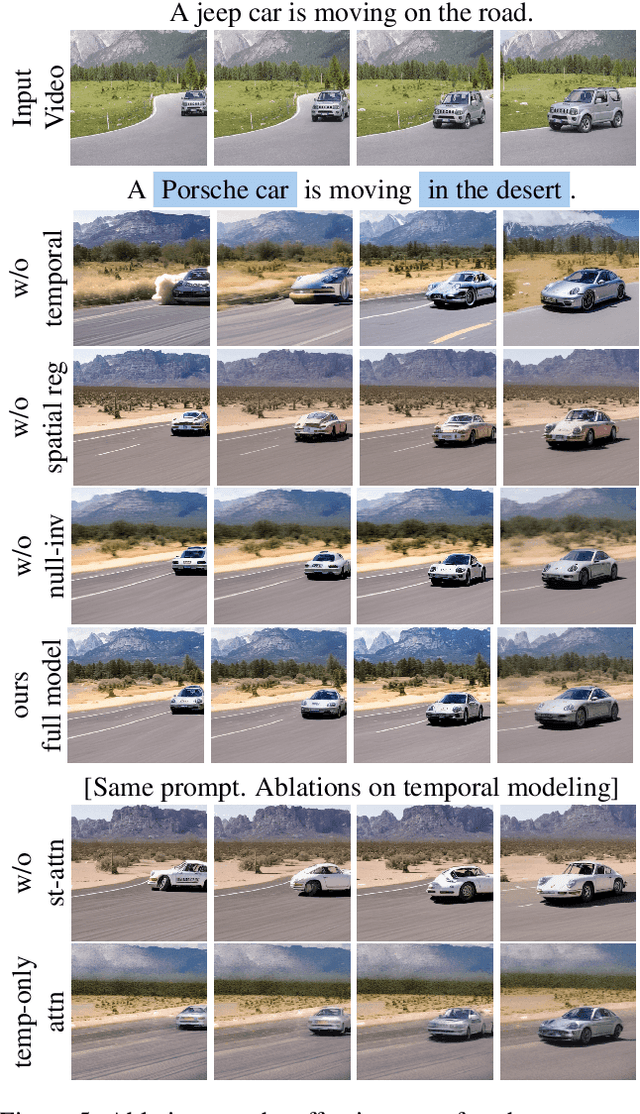
Large-scale text-to-image diffusion models achieve unprecedented success in image generation and editing. However, how to extend such success to video editing is unclear. Recent initial attempts at video editing require significant text-to-video data and computation resources for training, which is often not accessible. In this work, we propose vid2vid-zero, a simple yet effective method for zero-shot video editing. Our vid2vid-zero leverages off-the-shelf image diffusion models, and doesn't require training on any video. At the core of our method is a null-text inversion module for text-to-video alignment, a cross-frame modeling module for temporal consistency, and a spatial regularization module for fidelity to the original video. Without any training, we leverage the dynamic nature of the attention mechanism to enable bi-directional temporal modeling at test time. Experiments and analyses show promising results in editing attributes, subjects, places, etc., in real-world videos. Code is made available at \url{https://github.com/baaivision/vid2vid-zero}.