 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Retrieve Anyone: A General-purpose Person Re-identification Task with Instructions
Jul 04, 2023
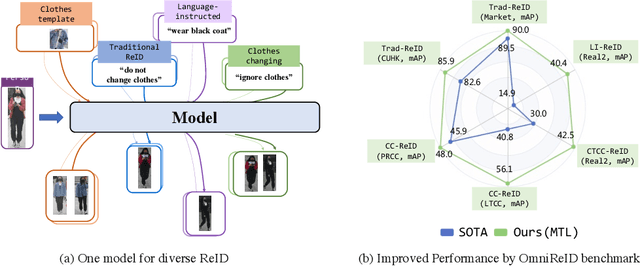
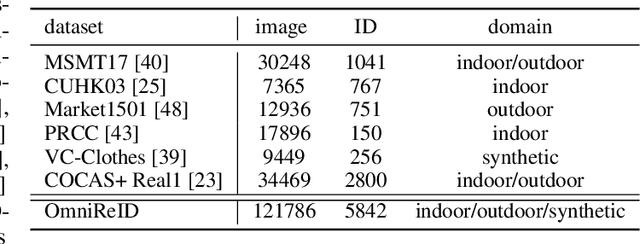
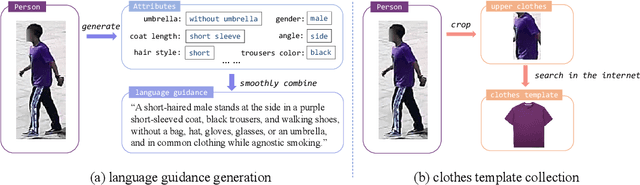
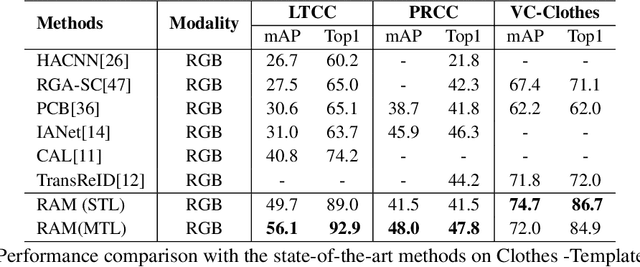
Human intelligence can retrieve any person according to both visual and language descriptions. However, the current computer vision community studies specific person re-identification (ReID) tasks in different scenarios separately, which limits the applications in the real world. This paper strives to resolve this problem by proposing a new instruct-ReID task that requires the model to retrieve images according to the given image or language instructions.Our instruct-ReID is a more general ReID setting, where existing ReID tasks can be viewed as special cases by designing different instructions. We propose a large-scale OmniReID benchmark and an adaptive triplet loss as a baseline method to facilitate research in this new setting. Experimental results show that the baseline model trained on our OmniReID benchmark can improve +0.6%, +1.4%, 0.2% mAP on Market1501, CUHK03, MSMT17 for traditional ReID, +0.8%, +2.0%, +13.4% mAP on PRCC, VC-Clothes, LTCC for clothes-changing ReID, +11.7% mAP on COCAS+ real2 for clothestemplate based clothes-changing ReID when using only RGB images, +25.4% mAP on COCAS+ real2 for our newly defined language-instructed ReID. The dataset, model, and code will be available at https://github.com/hwz-zju/Instruct-ReID.
EANet: Enhanced Attribute-based RGBT Tracker Network
Jul 04, 2023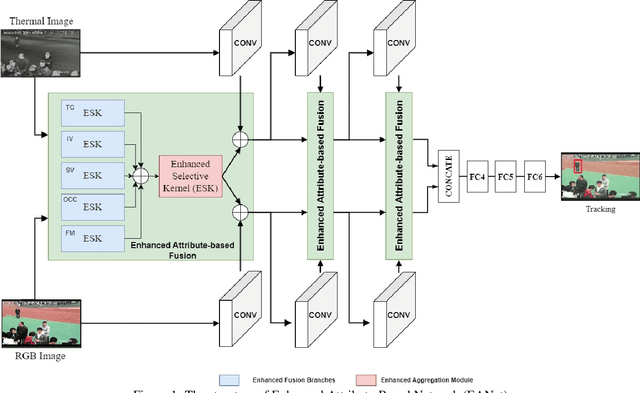
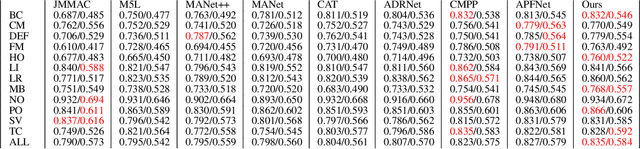
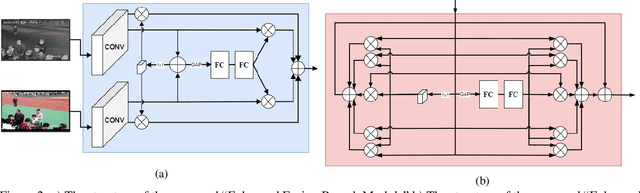
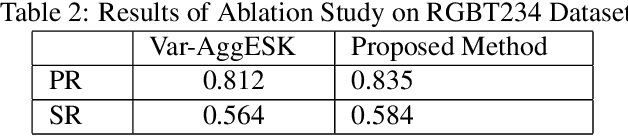
Tracking objects can be a difficult task in computer vision, especially when faced with challenges such as occlusion, changes in lighting, and motion blur. Recent advances in deep learning have shown promise in challenging these conditions. However, most deep learning-based object trackers only use visible band (RGB) images. Thermal infrared electromagnetic waves (TIR) can provide additional information about an object, including its temperature, when faced with challenging conditions. We propose a deep learning-based image tracking approach that fuses RGB and thermal images (RGBT). The proposed model consists of two main components: a feature extractor and a tracker. The feature extractor encodes deep features from both the RGB and the TIR images. The tracker then uses these features to track the object using an enhanced attribute-based architecture. We propose a fusion of attribute-specific feature selection with an aggregation module. The proposed methods are evaluated on the RGBT234 \cite{LiCLiang2018} and LasHeR \cite{LiLasher2021} datasets, which are the most widely used RGBT object-tracking datasets in the literature. The results show that the proposed system outperforms state-of-the-art RGBT object trackers on these datasets, with a relatively smaller number of parameters.
Hybrid Neural Diffeomorphic Flow for Shape Representation and Generation via Triplane
Jul 04, 2023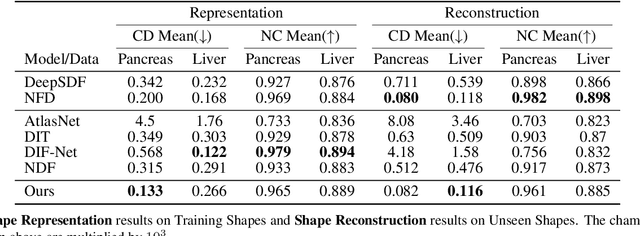
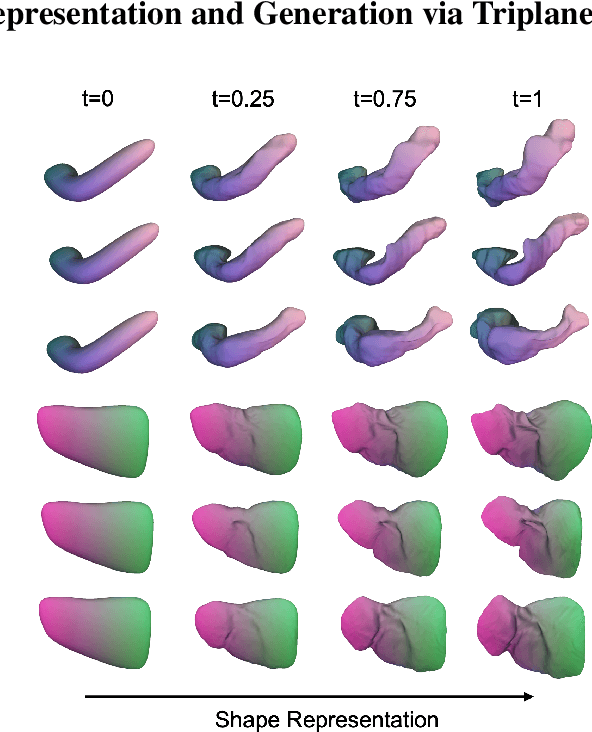
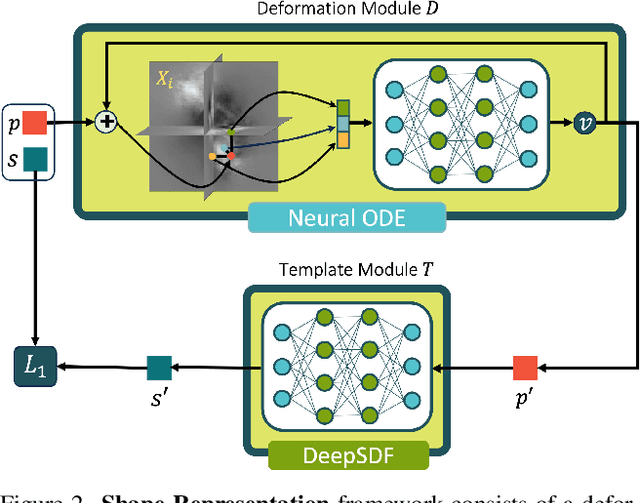
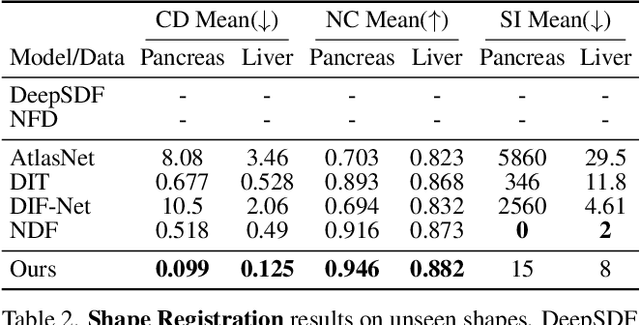
Deep Implicit Functions (DIFs) have gained popularity in 3D computer vision due to their compactness and continuous representation capabilities. However, addressing dense correspondences and semantic relationships across DIF-encoded shapes remains a critical challenge, limiting their applications in texture transfer and shape analysis. Moreover, recent endeavors in 3D shape generation using DIFs often neglect correspondence and topology preservation. This paper presents HNDF (Hybrid Neural Diffeomorphic Flow), a method that implicitly learns the underlying representation and decomposes intricate dense correspondences into explicitly axis-aligned triplane features. To avoid suboptimal representations trapped in local minima, we propose hybrid supervision that captures both local and global correspondences. Unlike conventional approaches that directly generate new 3D shapes, we further explore the idea of shape generation with deformed template shape via diffeomorphic flows, where the deformation is encoded by the generated triplane features. Leveraging a pre-existing 2D diffusion model, we produce high-quality and diverse 3D diffeomorphic flows through generated triplanes features, ensuring topological consistency with the template shape. Extensive experiments on medical image organ segmentation datasets evaluate the effectiveness of HNDF in 3D shape representation and generation.
Fast Optimal Transport through Sliced Wasserstein Generalized Geodesics
Jul 04, 2023
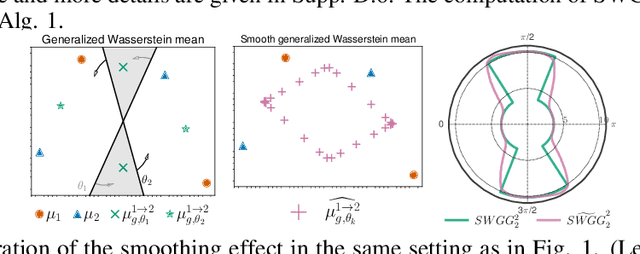
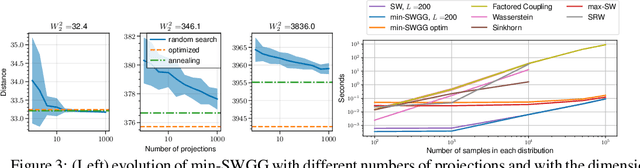
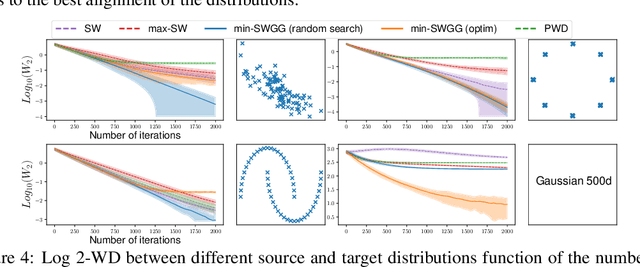
Wasserstein distance (WD) and the associated optimal transport plan have been proven useful in many applications where probability measures are at stake. In this paper, we propose a new proxy of the squared WD, coined min-SWGG, that is based on the transport map induced by an optimal one-dimensional projection of the two input distributions. We draw connections between min-SWGG and Wasserstein generalized geodesics in which the pivot measure is supported on a line. We notably provide a new closed form for the exact Wasserstein distance in the particular case of one of the distributions supported on a line allowing us to derive a fast computational scheme that is amenable to gradient descent optimization. We show that min-SWGG is an upper bound of WD and that it has a complexity similar to as Sliced-Wasserstein, with the additional feature of providing an associated transport plan. We also investigate some theoretical properties such as metricity, weak convergence, computational and topological properties. Empirical evidences support the benefits of min-SWGG in various contexts, from gradient flows, shape matching and image colorization, among others.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Mar 30, 2023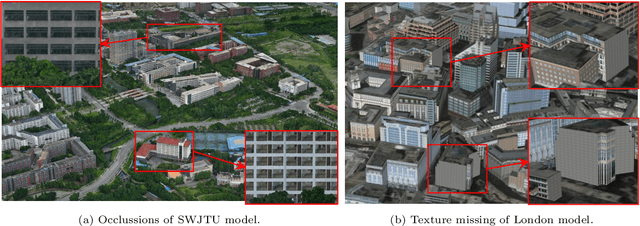
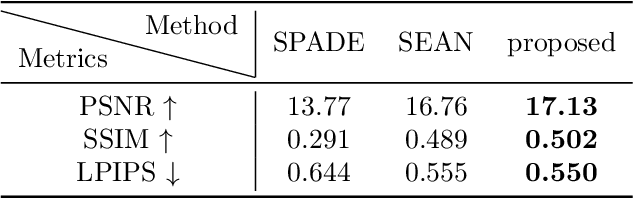
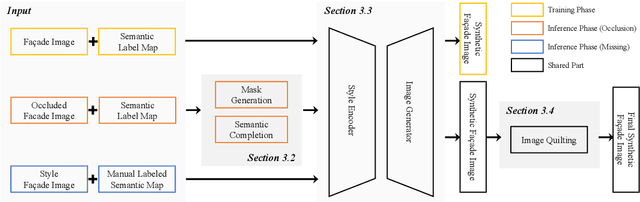

The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.
Degradation-Noise-Aware Deep Unfolding Transformer for Hyperspectral Image Denoising
May 06, 2023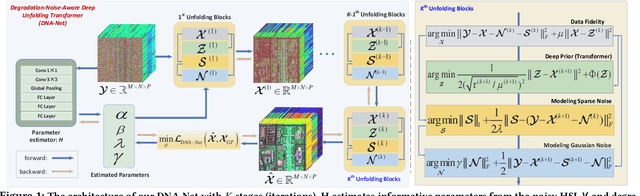
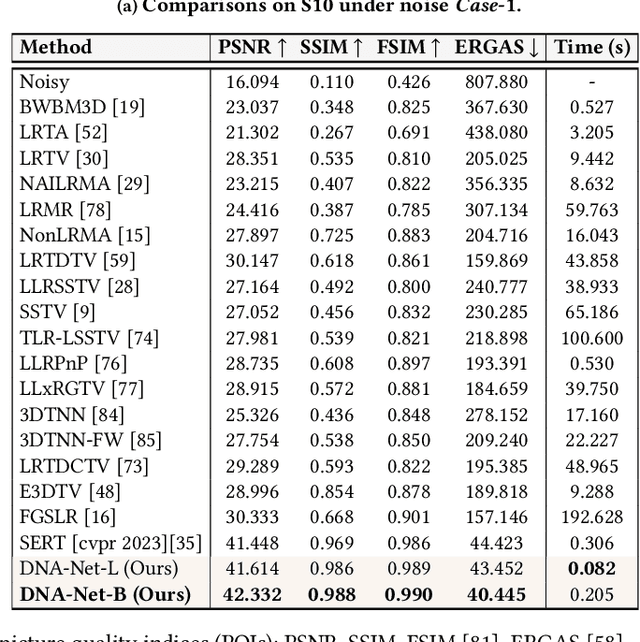
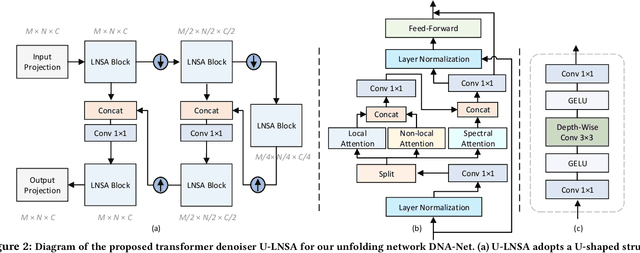
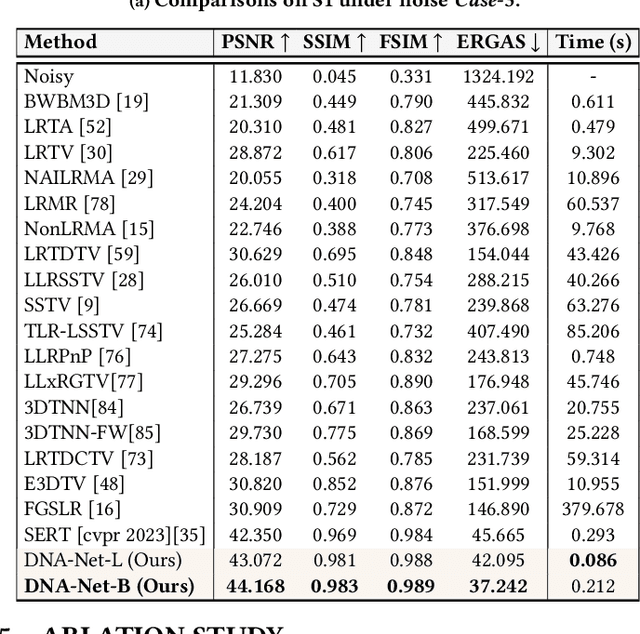
Hyperspectral imaging (HI) has emerged as a powerful tool in diverse fields such as medical diagnosis, industrial inspection, and agriculture, owing to its ability to detect subtle differences in physical properties through high spectral resolution. However, hyperspectral images (HSIs) are often quite noisy because of narrow band spectral filtering. To reduce the noise in HSI data cubes, both model-driven and learning-based denoising algorithms have been proposed. However, model-based approaches rely on hand-crafted priors and hyperparameters, while learning-based methods are incapable of estimating the inherent degradation patterns and noise distributions in the imaging procedure, which could inform supervised learning. Secondly, learning-based algorithms predominantly rely on CNN and fail to capture long-range dependencies, resulting in limited interpretability. This paper proposes a Degradation-Noise-Aware Unfolding Network (DNA-Net) that addresses these issues. Firstly, DNA-Net models sparse noise, Gaussian noise, and explicitly represent image prior using transformer. Then the model is unfolded into an end-to-end network, the hyperparameters within the model are estimated from the noisy HSI and degradation model and utilizes them to control each iteration. Additionally, we introduce a novel U-Shaped Local-Non-local-Spectral Transformer (U-LNSA) that captures spectral correlation, local contents, and non-local dependencies simultaneously. By integrating U-LNSA into DNA-Net, we present the first Transformer-based deep unfolding HSI denoising method. Experimental results show that DNA-Net outperforms state-of-the-art methods, and the modeling of noise distributions helps in cases with heavy noise.
Rethinking Context Aggregation in Natural Image Matting
Apr 03, 2023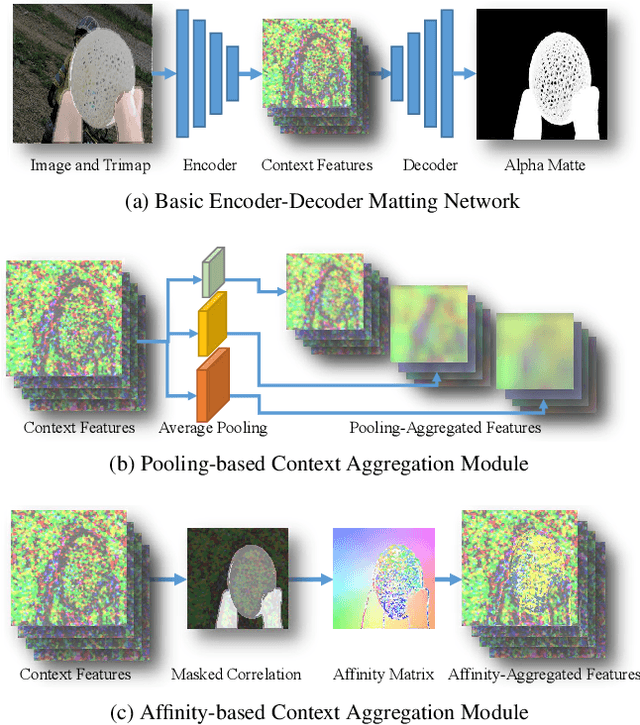
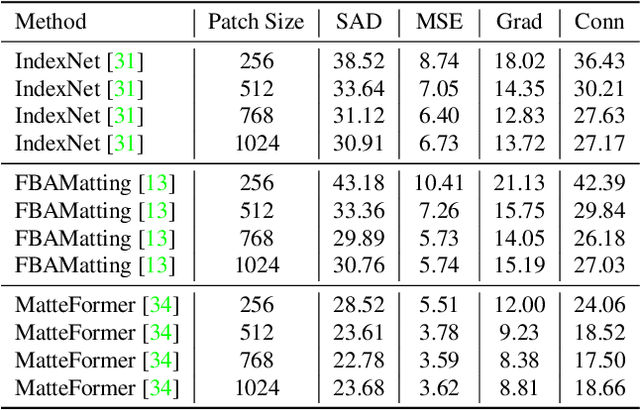
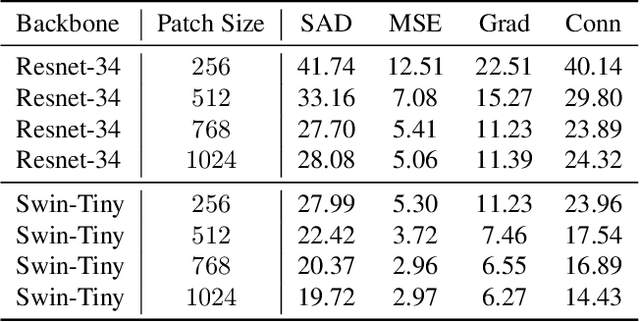

For natural image matting, context information plays a crucial role in estimating alpha mattes especially when it is challenging to distinguish foreground from its background. Exiting deep learning-based methods exploit specifically designed context aggregation modules to refine encoder features. However, the effectiveness of these modules has not been thoroughly explored. In this paper, we conduct extensive experiments to reveal that the context aggregation modules are actually not as effective as expected. We also demonstrate that when learned on large image patches, basic encoder-decoder networks with a larger receptive field can effectively aggregate context to achieve better performance.Upon the above findings, we propose a simple yet effective matting network, named AEMatter, which enlarges the receptive field by incorporating an appearance-enhanced axis-wise learning block into the encoder and adopting a hybrid-transformer decoder. Experimental results on four datasets demonstrate that our AEMatter significantly outperforms state-of-the-art matting methods (e.g., on the Adobe Composition-1K dataset, \textbf{25\%} and \textbf{40\%} reduction in terms of SAD and MSE, respectively, compared against MatteFormer). The code and model are available at \url{https://github.com/QLYoo/AEMatter}.
Learning Semantic-Aware Knowledge Guidance for Low-Light Image Enhancement
Apr 14, 2023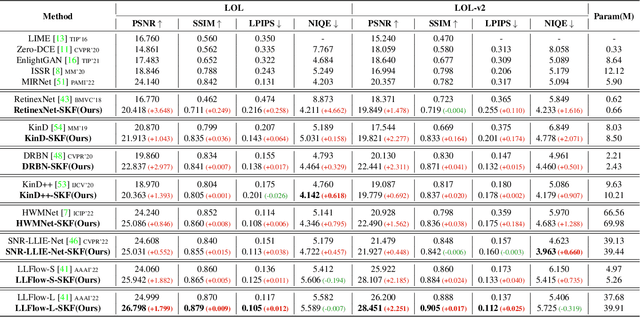
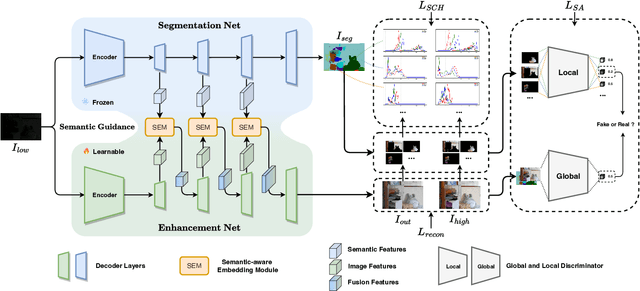
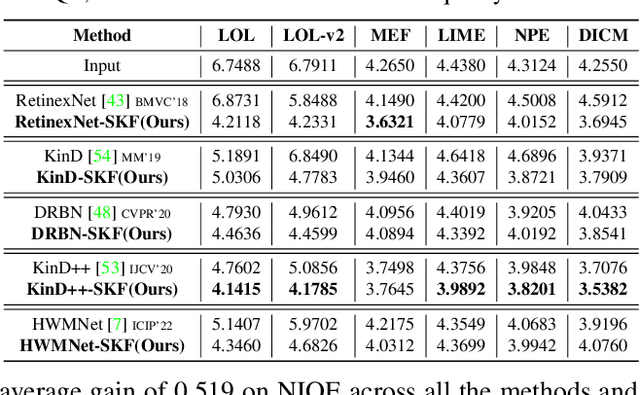
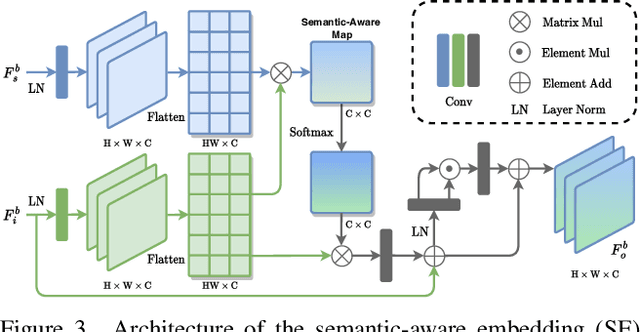
Low-light image enhancement (LLIE) investigates how to improve illumination and produce normal-light images. The majority of existing methods improve low-light images via a global and uniform manner, without taking into account the semantic information of different regions. Without semantic priors, a network may easily deviate from a region's original color. To address this issue, we propose a novel semantic-aware knowledge-guided framework (SKF) that can assist a low-light enhancement model in learning rich and diverse priors encapsulated in a semantic segmentation model. We concentrate on incorporating semantic knowledge from three key aspects: a semantic-aware embedding module that wisely integrates semantic priors in feature representation space, a semantic-guided color histogram loss that preserves color consistency of various instances, and a semantic-guided adversarial loss that produces more natural textures by semantic priors. Our SKF is appealing in acting as a general framework in LLIE task. Extensive experiments show that models equipped with the SKF significantly outperform the baselines on multiple datasets and our SKF generalizes to different models and scenes well. The code is available at Semantic-Aware-Low-Light-Image-Enhancement.
VVC Extension Scheme for Object Detection Using Contrast Reduction
May 30, 2023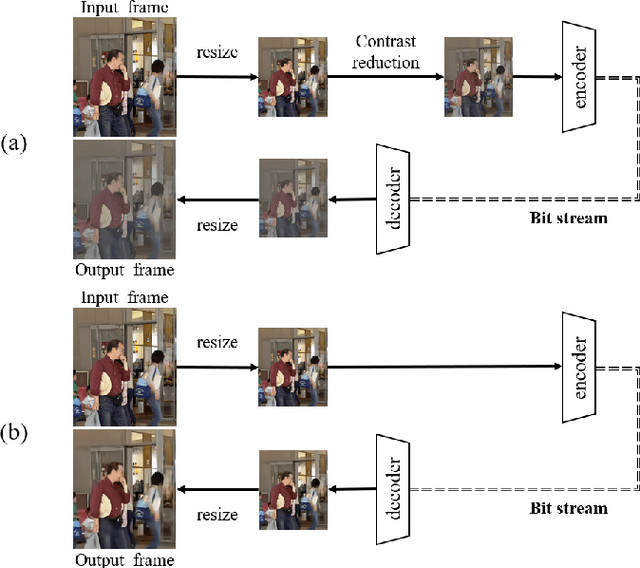
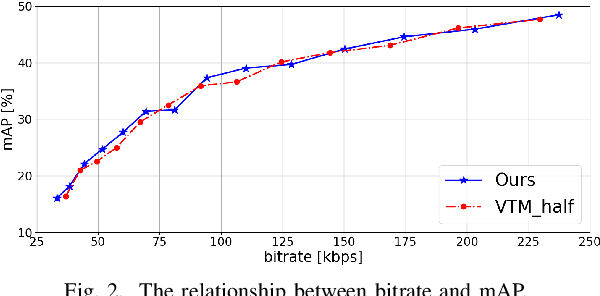
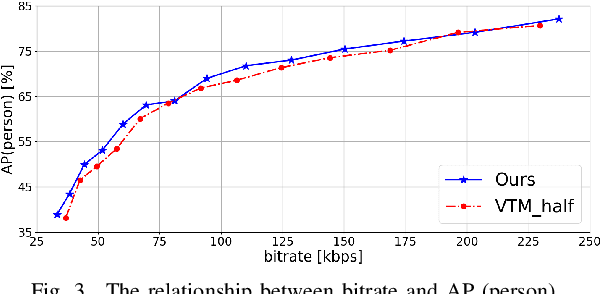
In recent years, video analysis using Artificial Intelligence (AI) has been widely used, due to the remarkable development of image recognition technology using deep learning. In 2019, the Moving Picture Experts Group (MPEG) has started standardization of Video Coding for Machines (VCM) as a video coding technology for image recognition. In the framework of VCM, both higher image recognition accuracy and video compression performance are required. In this paper, we propose an extention scheme of video coding for object detection using Versatile Video Coding (VVC). Unlike video for human vision, video used for object detection does not require a large image size or high contrast. Since downsampling of the image can reduce the amount of information to be transmitted. Due to the decrease in image contrast, entropy of the image becomes smaller. Therefore, in our proposed scheme, the original image is reduced in size and contrast, then coded with VVC encoder to achieve high compression performance. Then, the output image from the VVC decoder is restored to its original image size using the bicubic method. Experimental results show that the proposed video coding scheme achieves better coding performance than regular VVC in terms of object detection accuracy.
Non-aligned supervision for Real Image Dehazing
Mar 14, 2023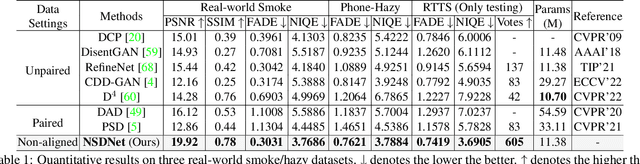
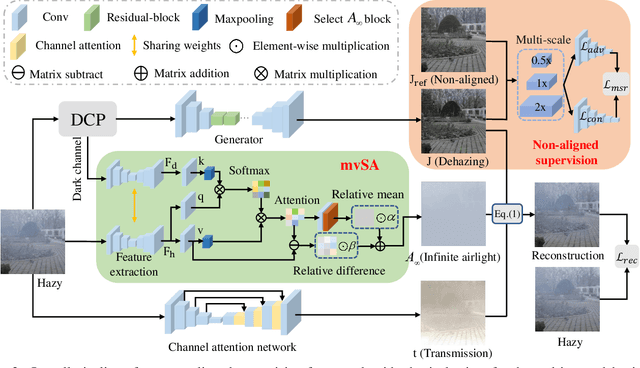
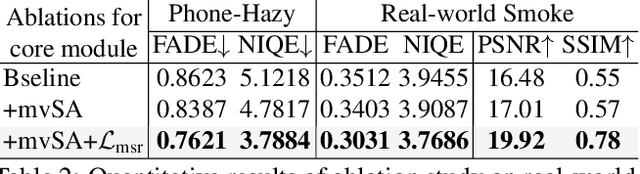

Removing haze from real-world images is challenging due to unpredictable weather conditions, resulting in misaligned hazy and clear image pairs. In this paper, we propose a non-aligned supervision framework that consists of three networks - dehazing, airlight, and transmission. In particular, we explore a non-alignment setting by utilizing a clear reference image that is not aligned with the hazy input image to supervise the dehazing network through a multi-scale reference loss that compares the features of the two images. Our setting makes it easier to collect hazy/clear image pairs in real-world environments, even under conditions of misalignment and shift views. To demonstrate this, we have created a new hazy dataset called "Phone-Hazy", which was captured using mobile phones in both rural and urban areas. Additionally, we present a mean and variance self-attention network to model the infinite airlight using dark channel prior as position guidance, and employ a channel attention network to estimate the three-channel transmission. Experimental results show that our framework outperforms current state-of-the-art methods in the real-world image dehazing. Phone-Hazy and code will be available at https://github.com/hello2377/NSDNet.