 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MedLSAM: Localize and Segment Anything Model for 3D Medical Images
Jun 26, 2023
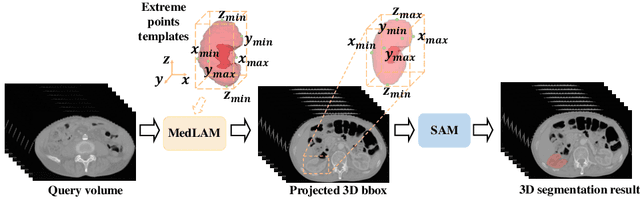
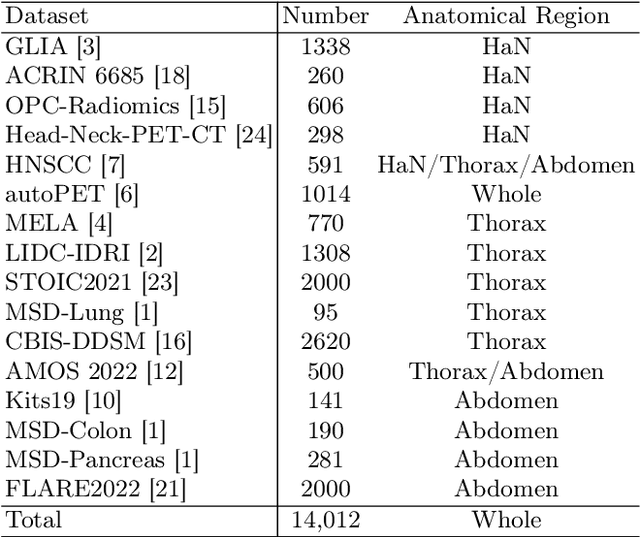
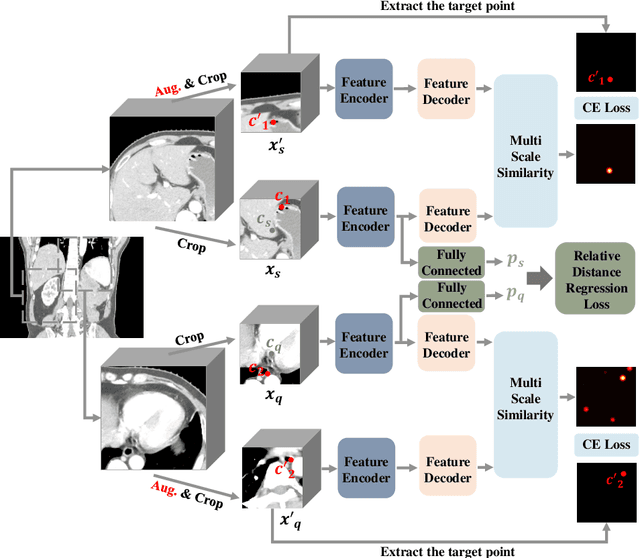
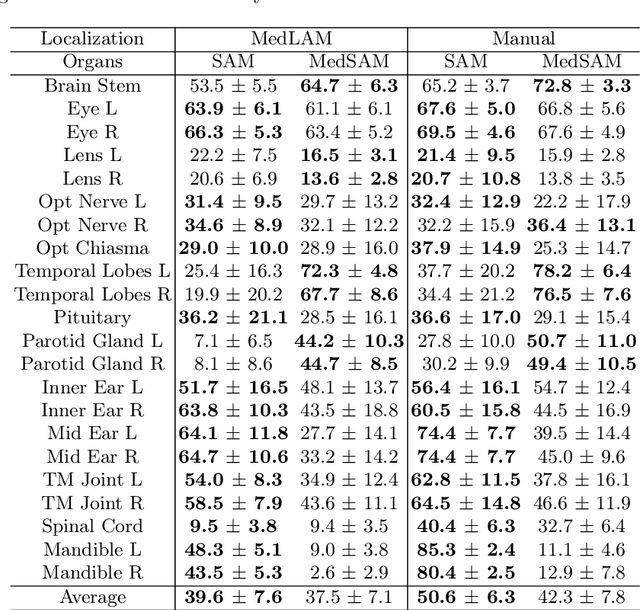
The Segment Anything Model (SAM) has recently emerged as a groundbreaking model in the field of image segmentation. Nevertheless, both the original SAM and its medical adaptations necessitate slice-by-slice annotations, which directly increase the annotation workload with the size of the dataset. We propose MedLSAM to address this issue, ensuring a constant annotation workload irrespective of dataset size and thereby simplifying the annotation process. Our model introduces a few-shot localization framework capable of localizing any target anatomical part within the body. To achieve this, we develop a Localize Anything Model for 3D Medical Images (MedLAM), utilizing two self-supervision tasks: relative distance regression (RDR) and multi-scale similarity (MSS) across a comprehensive dataset of 14,012 CT scans. We then establish a methodology for accurate segmentation by integrating MedLAM with SAM. By annotating only six extreme points across three directions on a few templates, our model can autonomously identify the target anatomical region on all data scheduled for annotation. This allows our framework to generate a 2D bounding box for every slice of the image, which are then leveraged by SAM to carry out segmentations. We conducted experiments on two 3D datasets covering 38 organs and found that MedLSAM matches the performance of SAM and its medical adaptations while requiring only minimal extreme point annotations for the entire dataset. Furthermore, MedLAM has the potential to be seamlessly integrated with future 3D SAM models, paving the way for enhanced performance. Our code is public at \href{https://github.com/openmedlab/MedLSAM}{https://github.com/openmedlab/MedLSAM}.
Data-Efficient Image Quality Assessment with Attention-Panel Decoder
Apr 11, 2023
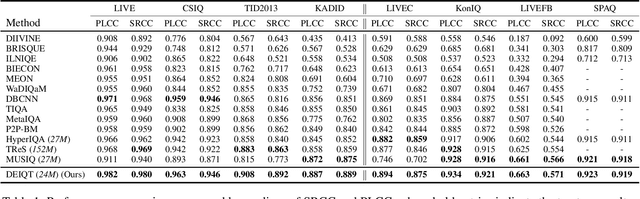
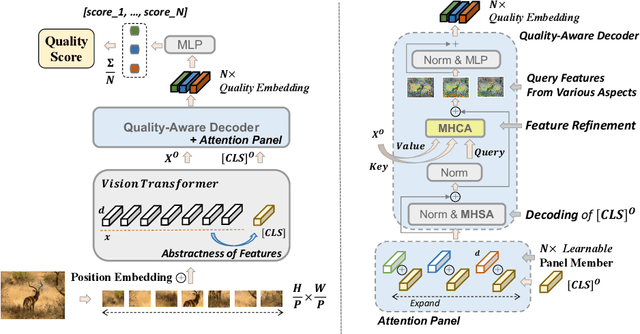
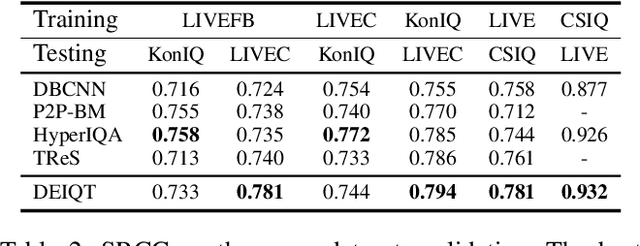
Blind Image Quality Assessment (BIQA) is a fundamental task in computer vision, which however remains unresolved due to the complex distortion conditions and diversified image contents. To confront this challenge, we in this paper propose a novel BIQA pipeline based on the Transformer architecture, which achieves an efficient quality-aware feature representation with much fewer data. More specifically, we consider the traditional fine-tuning in BIQA as an interpretation of the pre-trained model. In this way, we further introduce a Transformer decoder to refine the perceptual information of the CLS token from different perspectives. This enables our model to establish the quality-aware feature manifold efficiently while attaining a strong generalization capability. Meanwhile, inspired by the subjective evaluation behaviors of human, we introduce a novel attention panel mechanism, which improves the model performance and reduces the prediction uncertainty simultaneously. The proposed BIQA method maintains a lightweight design with only one layer of the decoder, yet extensive experiments on eight standard BIQA datasets (both synthetic and authentic) demonstrate its superior performance to the state-of-the-art BIQA methods, i.e., achieving the SRCC values of 0.875 (vs. 0.859 in LIVEC) and 0.980 (vs. 0.969 in LIVE).
Picking Up Quantization Steps for Compressed Image Classification
Apr 21, 2023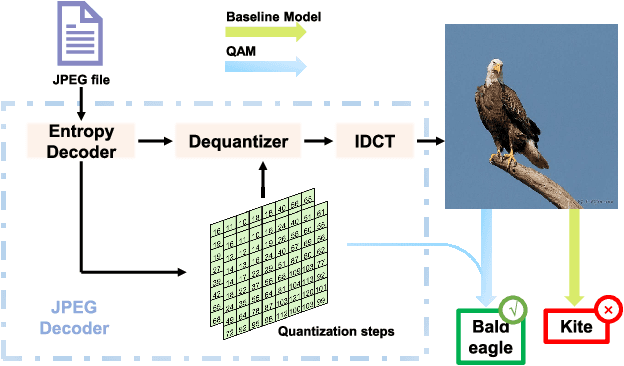
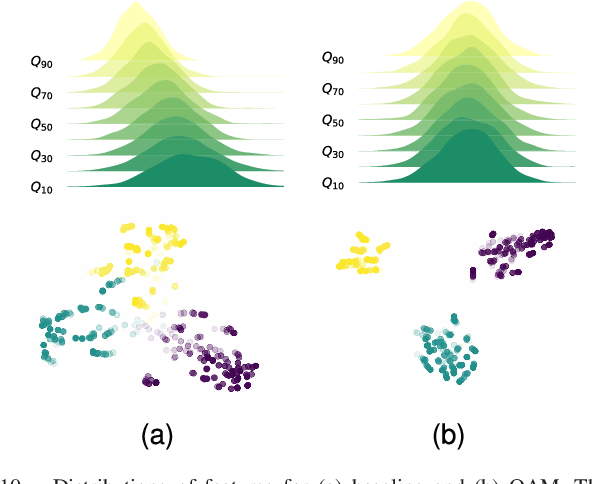
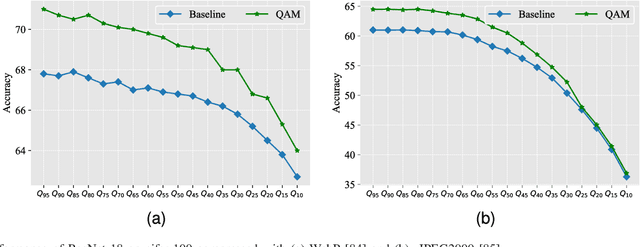
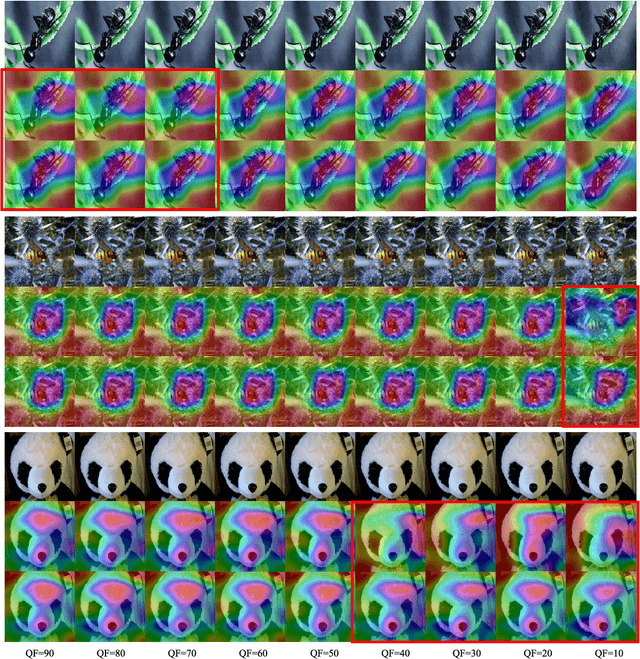
The sensitivity of deep neural networks to compressed images hinders their usage in many real applications, which means classification networks may fail just after taking a screenshot and saving it as a compressed file. In this paper, we argue that neglected disposable coding parameters stored in compressed files could be picked up to reduce the sensitivity of deep neural networks to compressed images. Specifically, we resort to using one of the representative parameters, quantization steps, to facilitate image classification. Firstly, based on quantization steps, we propose a novel quantization aware confidence (QAC), which is utilized as sample weights to reduce the influence of quantization on network training. Secondly, we utilize quantization steps to alleviate the variance of feature distributions, where a quantization aware batch normalization (QABN) is proposed to replace batch normalization of classification networks. Extensive experiments show that the proposed method significantly improves the performance of classification networks on CIFAR-10, CIFAR-100, and ImageNet. The code is released on https://github.com/LiMaPKU/QSAM.git
What's in a Name? Beyond Class Indices for Image Recognition
Apr 05, 2023

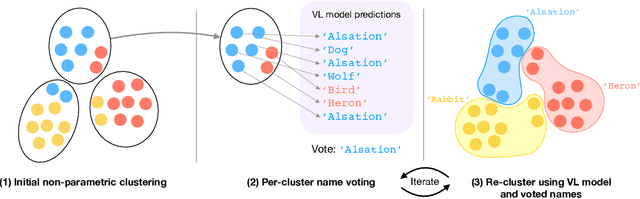

Existing machine learning models demonstrate excellent performance in image object recognition after training on a large-scale dataset under full supervision. However, these models only learn to map an image to a predefined class index, without revealing the actual semantic meaning of the object in the image. In contrast, vision-language models like CLIP are able to assign semantic class names to unseen objects in a `zero-shot' manner, although they still rely on a predefined set of candidate names at test time. In this paper, we reconsider the recognition problem and task a vision-language model to assign class names to images given only a large and essentially unconstrained vocabulary of categories as prior information. We use non-parametric methods to establish relationships between images which allow the model to automatically narrow down the set of possible candidate names. Specifically, we propose iteratively clustering the data and voting on class names within them, showing that this enables a roughly 50\% improvement over the baseline on ImageNet. Furthermore, we tackle this problem both in unsupervised and partially supervised settings, as well as with a coarse-grained and fine-grained search space as the unconstrained dictionary.
Lightweight High-Performance Blind Image Quality Assessment
Mar 23, 2023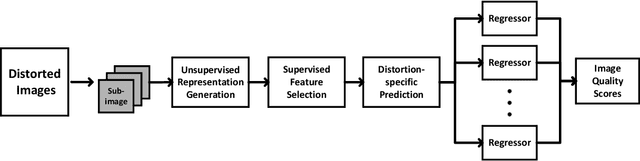

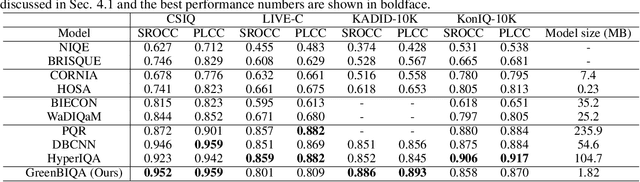

Blind image quality assessment (BIQA) is a task that predicts the perceptual quality of an image without its reference. Research on BIQA attracts growing attention due to the increasing amount of user-generated images and emerging mobile applications where reference images are unavailable. The problem is challenging due to the wide range of content and mixed distortion types. Many existing BIQA methods use deep neural networks (DNNs) to achieve high performance. However, their large model sizes hinder their applicability to edge or mobile devices. To meet the need, a novel BIQA method with a small model, low computational complexity, and high performance is proposed and named "GreenBIQA" in this work. GreenBIQA includes five steps: 1) image cropping, 2) unsupervised representation generation, 3) supervised feature selection, 4) distortion-specific prediction, and 5) regression and decision ensemble. Experimental results show that the performance of GreenBIQA is comparable with that of state-of-the-art deep-learning (DL) solutions while demanding a much smaller model size and significantly lower computational complexity.
Benchmark data to study the influence of pre-training on explanation performance in MR image classification
Jun 21, 2023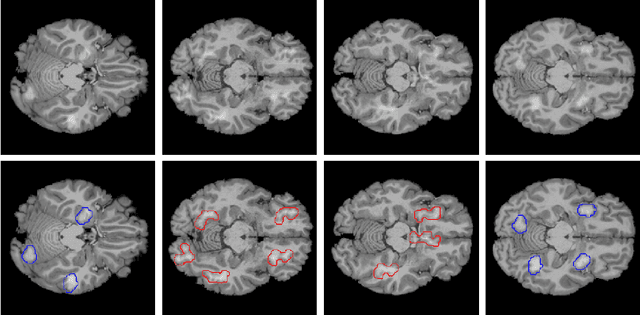
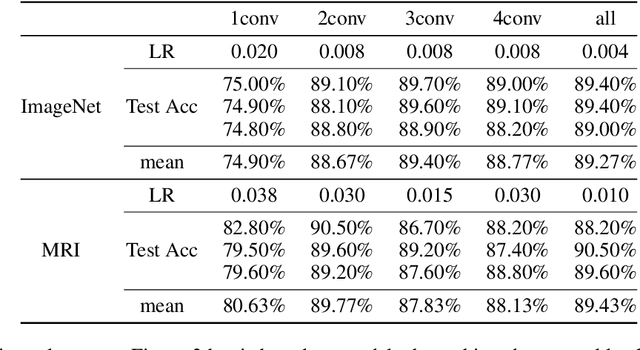

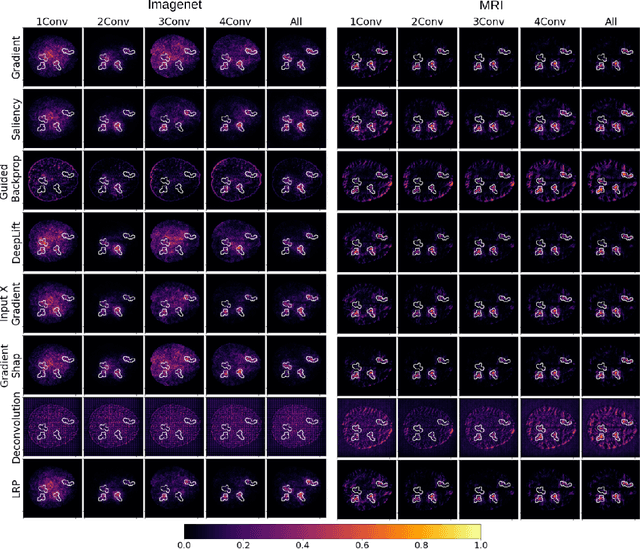
Convolutional Neural Networks (CNNs) are frequently and successfully used in medical prediction tasks. They are often used in combination with transfer learning, leading to improved performance when training data for the task are scarce. The resulting models are highly complex and typically do not provide any insight into their predictive mechanisms, motivating the field of 'explainable' artificial intelligence (XAI). However, previous studies have rarely quantitatively evaluated the 'explanation performance' of XAI methods against ground-truth data, and transfer learning and its influence on objective measures of explanation performance has not been investigated. Here, we propose a benchmark dataset that allows for quantifying explanation performance in a realistic magnetic resonance imaging (MRI) classification task. We employ this benchmark to understand the influence of transfer learning on the quality of explanations. Experimental results show that popular XAI methods applied to the same underlying model differ vastly in performance, even when considering only correctly classified examples. We further observe that explanation performance strongly depends on the task used for pre-training and the number of CNN layers pre-trained. These results hold after correcting for a substantial correlation between explanation and classification performance.
Self-Supervised Hyperspectral Inpainting with the Optimisation inspired Deep Neural Network Prior
Jun 12, 2023


Hyperspectral Image (HSI)s cover hundreds or thousands of narrow spectral bands, conveying a wealth of spatial and spectral information. However, due to the instrumental errors and the atmospheric changes, the HSI obtained in practice are often contaminated by noise and dead pixels(lines), resulting in missing information that may severely compromise the subsequent applications. We introduce here a novel HSI missing pixel prediction algorithm, called Low Rank and Sparsity Constraint Plug-and-Play (LRS-PnP). It is shown that LRS-PnP is able to predict missing pixels and bands even when all spectral bands of the image are missing. The proposed LRS-PnP algorithm is further extended to a self-supervised model by combining the LRS-PnP with the Deep Image Prior (DIP), called LRS-PnP-DIP. In a series of experiments with real data, It is shown that the LRS-PnP-DIP either achieves state-of-the-art inpainting performance compared to other learning-based methods, or outperforms them.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Mar 30, 2023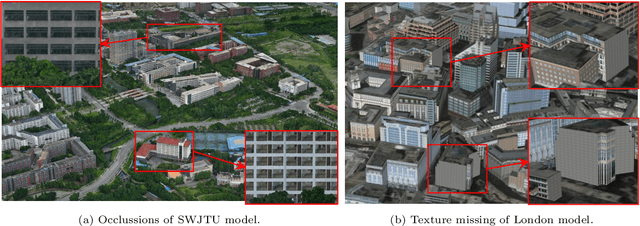
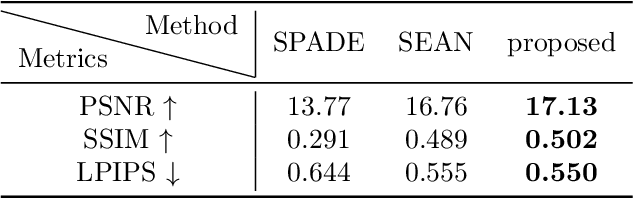
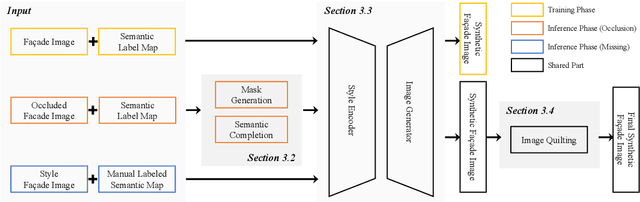

The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.
Non-aligned supervision for Real Image Dehazing
Mar 14, 2023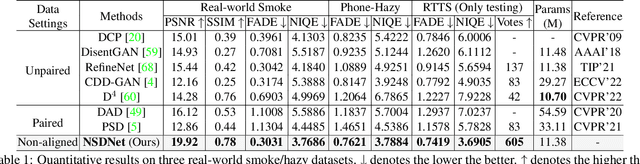
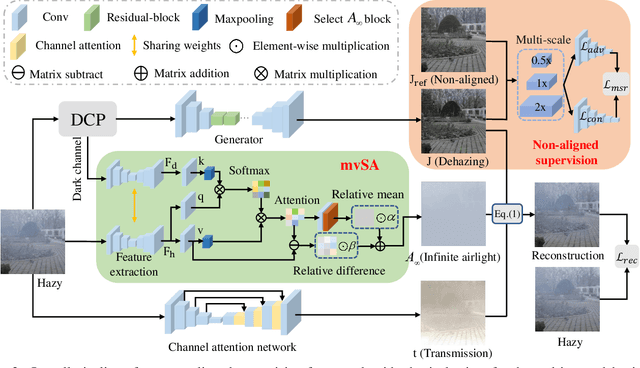
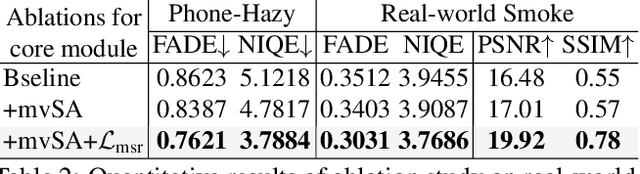

Removing haze from real-world images is challenging due to unpredictable weather conditions, resulting in misaligned hazy and clear image pairs. In this paper, we propose a non-aligned supervision framework that consists of three networks - dehazing, airlight, and transmission. In particular, we explore a non-alignment setting by utilizing a clear reference image that is not aligned with the hazy input image to supervise the dehazing network through a multi-scale reference loss that compares the features of the two images. Our setting makes it easier to collect hazy/clear image pairs in real-world environments, even under conditions of misalignment and shift views. To demonstrate this, we have created a new hazy dataset called "Phone-Hazy", which was captured using mobile phones in both rural and urban areas. Additionally, we present a mean and variance self-attention network to model the infinite airlight using dark channel prior as position guidance, and employ a channel attention network to estimate the three-channel transmission. Experimental results show that our framework outperforms current state-of-the-art methods in the real-world image dehazing. Phone-Hazy and code will be available at https://github.com/hello2377/NSDNet.
Rethinking Context Aggregation in Natural Image Matting
Apr 03, 2023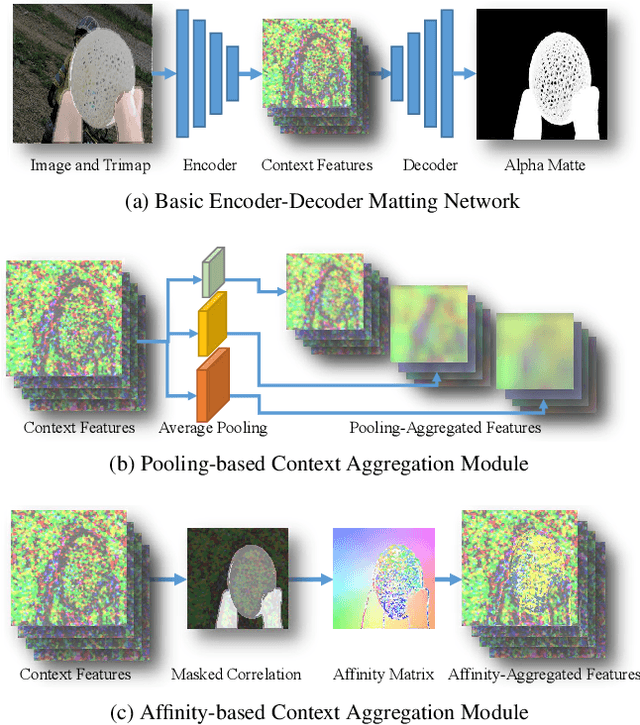
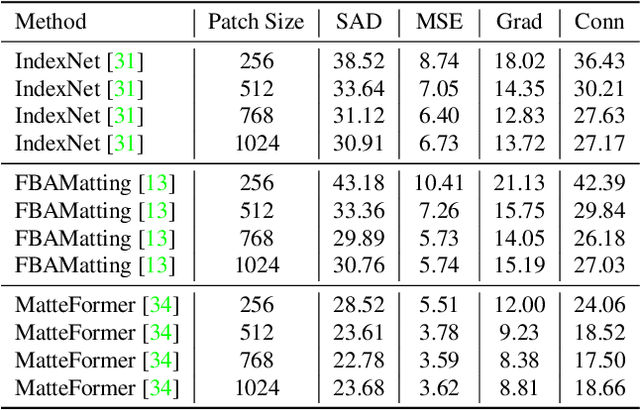
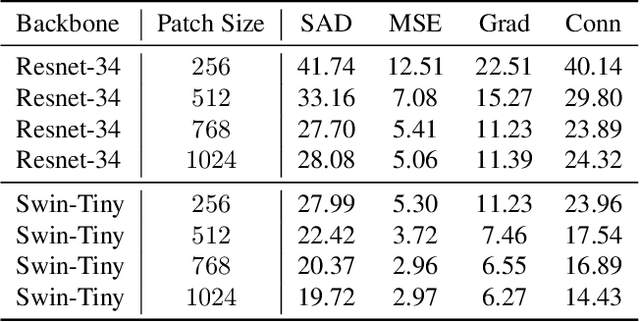

For natural image matting, context information plays a crucial role in estimating alpha mattes especially when it is challenging to distinguish foreground from its background. Exiting deep learning-based methods exploit specifically designed context aggregation modules to refine encoder features. However, the effectiveness of these modules has not been thoroughly explored. In this paper, we conduct extensive experiments to reveal that the context aggregation modules are actually not as effective as expected. We also demonstrate that when learned on large image patches, basic encoder-decoder networks with a larger receptive field can effectively aggregate context to achieve better performance.Upon the above findings, we propose a simple yet effective matting network, named AEMatter, which enlarges the receptive field by incorporating an appearance-enhanced axis-wise learning block into the encoder and adopting a hybrid-transformer decoder. Experimental results on four datasets demonstrate that our AEMatter significantly outperforms state-of-the-art matting methods (e.g., on the Adobe Composition-1K dataset, \textbf{25\%} and \textbf{40\%} reduction in terms of SAD and MSE, respectively, compared against MatteFormer). The code and model are available at \url{https://github.com/QLYoo/AEMatter}.