 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
KD-DLGAN: Data Limited Image Generation via Knowledge Distillation
Mar 30, 2023
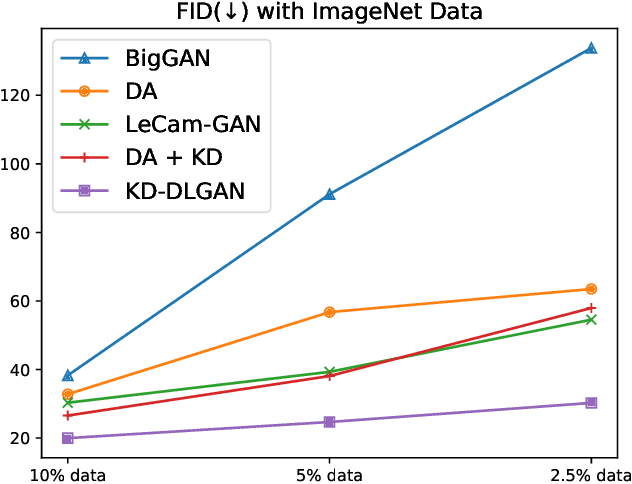
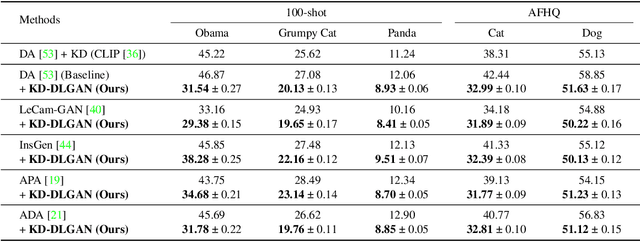
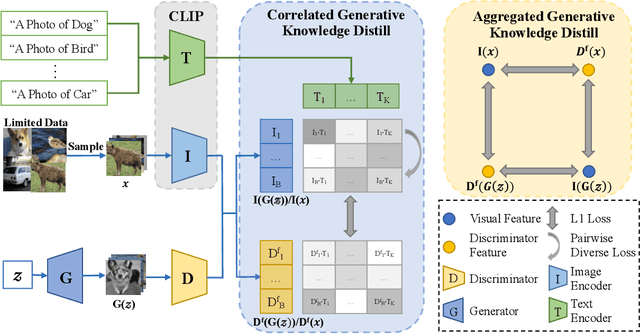
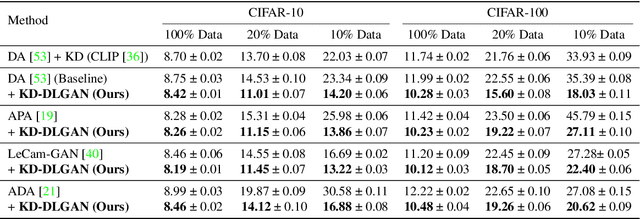
Generative Adversarial Networks (GANs) rely heavily on large-scale training data for training high-quality image generation models. With limited training data, the GAN discriminator often suffers from severe overfitting which directly leads to degraded generation especially in generation diversity. Inspired by the recent advances in knowledge distillation (KD), we propose KD-DLGAN, a knowledge-distillation based generation framework that introduces pre-trained vision-language models for training effective data-limited generation models. KD-DLGAN consists of two innovative designs. The first is aggregated generative KD that mitigates the discriminator overfitting by challenging the discriminator with harder learning tasks and distilling more generalizable knowledge from the pre-trained models. The second is correlated generative KD that improves the generation diversity by distilling and preserving the diverse image-text correlation within the pre-trained models. Extensive experiments over multiple benchmarks show that KD-DLGAN achieves superior image generation with limited training data. In addition, KD-DLGAN complements the state-of-the-art with consistent and substantial performance gains.
The Forward-Forward Algorithm as a feature extractor for skin lesion classification: A preliminary study
Jul 02, 2023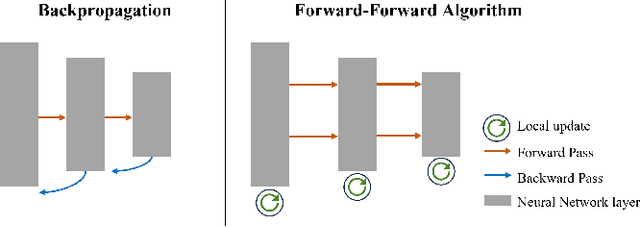
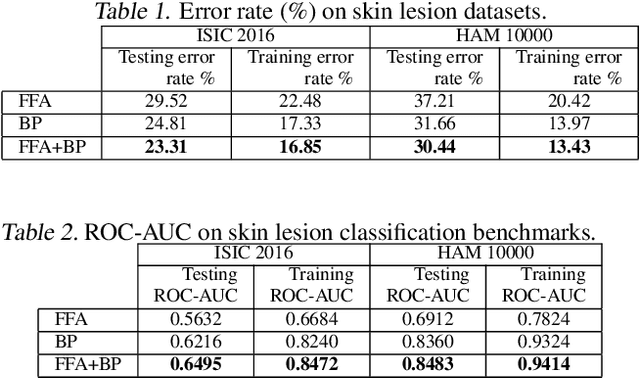
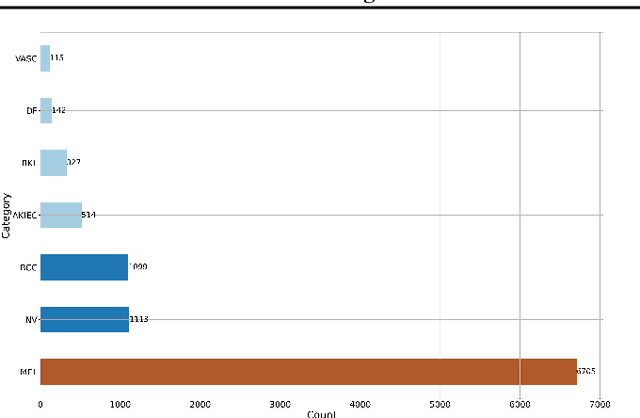
Skin cancer, a deadly form of cancer, exhibits a 23\% survival rate in the USA with late diagnosis. Early detection can significantly increase the survival rate, and facilitate timely treatment. Accurate biomedical image classification is vital in medical analysis, aiding clinicians in disease diagnosis and treatment. Deep learning (DL) techniques, such as convolutional neural networks and transformers, have revolutionized clinical decision-making automation. However, computational cost and hardware constraints limit the implementation of state-of-the-art DL architectures. In this work, we explore a new type of neural network that does not need backpropagation (BP), namely the Forward-Forward Algorithm (FFA), for skin lesion classification. While FFA is claimed to use very low-power analog hardware, BP still tends to be superior in terms of classification accuracy. In addition, our experimental results suggest that the combination of FFA and BP can be a better alternative to achieve a more accurate prediction.
ARHNet: Adaptive Region Harmonization for Lesion-aware Augmentation to Improve Segmentation Performance
Jul 02, 2023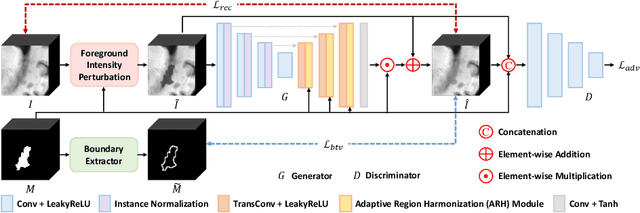
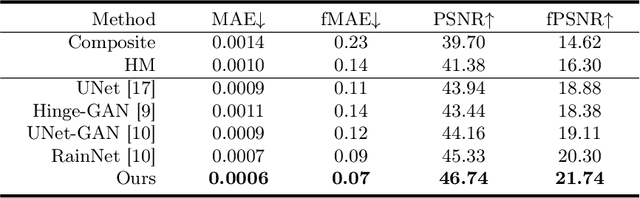
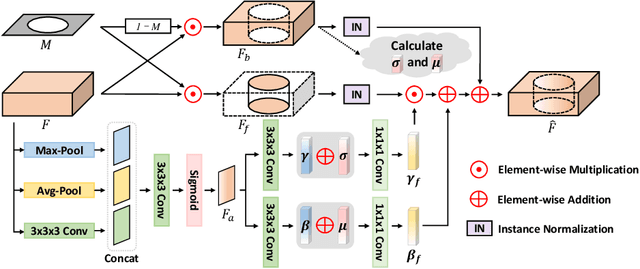
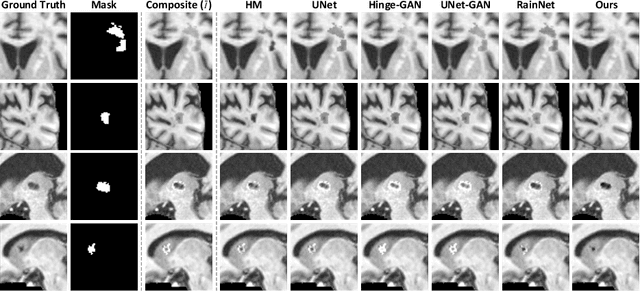
Accurately segmenting brain lesions in MRI scans is critical for providing patients with prognoses and neurological monitoring. However, the performance of CNN-based segmentation methods is constrained by the limited training set size. Advanced data augmentation is an effective strategy to improve the model's robustness. However, they often introduce intensity disparities between foreground and background areas and boundary artifacts, which weakens the effectiveness of such strategies. In this paper, we propose a foreground harmonization framework (ARHNet) to tackle intensity disparities and make synthetic images look more realistic. In particular, we propose an Adaptive Region Harmonization (ARH) module to dynamically align foreground feature maps to the background with an attention mechanism. We demonstrate the efficacy of our method in improving the segmentation performance using real and synthetic images. Experimental results on the ATLAS 2.0 dataset show that ARHNet outperforms other methods for image harmonization tasks, and boosts the down-stream segmentation performance. Our code is publicly available at https://github.com/King-HAW/ARHNet.
Fraunhofer SIT at CheckThat! 2023: Mixing Single-Modal Classifiers to Estimate the Check-Worthiness of Multi-Modal Tweets
Jul 02, 2023The option of sharing images, videos and audio files on social media opens up new possibilities for distinguishing between false information and fake news on the Internet. Due to the vast amount of data shared every second on social media, not all data can be verified by a computer or a human expert. Here, a check-worthiness analysis can be used as a first step in the fact-checking pipeline and as a filtering mechanism to improve efficiency. This paper proposes a novel way of detecting the check-worthiness in multi-modal tweets. It takes advantage of two classifiers, each trained on a single modality. For image data, extracting the embedded text with an OCR analysis has shown to perform best. By combining the two classifiers, the proposed solution was able to place first in the CheckThat! 2023 Task 1A with an F1 score of 0.7297 achieved on the private test set.
* 8 pages
Super-Resolving Face Image by Facial Parsing Information
Apr 06, 2023



Face super-resolution is a technology that transforms a low-resolution face image into the corresponding high-resolution one. In this paper, we build a novel parsing map guided face super-resolution network which extracts the face prior (i.e., parsing map) directly from low-resolution face image for the following utilization. To exploit the extracted prior fully, a parsing map attention fusion block is carefully designed, which can not only effectively explore the information of parsing map, but also combines powerful attention mechanism. Moreover, in light of that high-resolution features contain more precise spatial information while low-resolution features provide strong contextual information, we hope to maintain and utilize these complementary information. To achieve this goal, we develop a multi-scale refine block to maintain spatial and contextual information and take advantage of multi-scale features to refine the feature representations. Experimental results demonstrate that our method outperforms the state-of-the-arts in terms of quantitative metrics and visual quality. The source codes will be available at https://github.com/wcy-cs/FishFSRNet.
Text-to-Image Diffusion Models are Zero-Shot Classifiers
Mar 27, 2023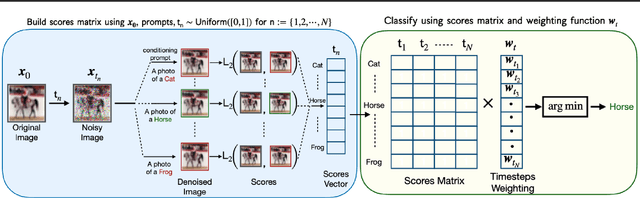
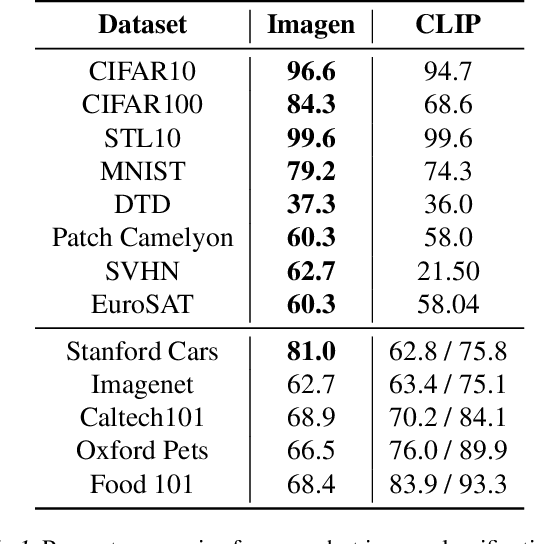
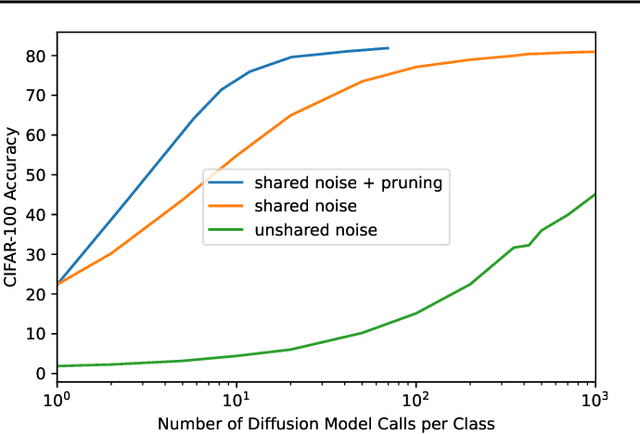

The excellent generative capabilities of text-to-image diffusion models suggest they learn informative representations of image-text data. However, what knowledge their representations capture is not fully understood, and they have not been thoroughly explored on downstream tasks. We investigate diffusion models by proposing a method for evaluating them as zero-shot classifiers. The key idea is using a diffusion model's ability to denoise a noised image given a text description of a label as a proxy for that label's likelihood. We apply our method to Imagen, using it to probe fine-grained aspects of Imagen's knowledge and comparing it with CLIP's zero-shot abilities. Imagen performs competitively with CLIP on a wide range of zero-shot image classification datasets. Additionally, it achieves state-of-the-art results on shape/texture bias tests and can successfully perform attribute binding while CLIP cannot. Although generative pre-training is prevalent in NLP, visual foundation models often use other methods such as contrastive learning. Based on our findings, we argue that generative pre-training should be explored as a compelling alternative for vision and vision-language problems.
Synthesizing Realistic Image Restoration Training Pairs: A Diffusion Approach
Mar 13, 2023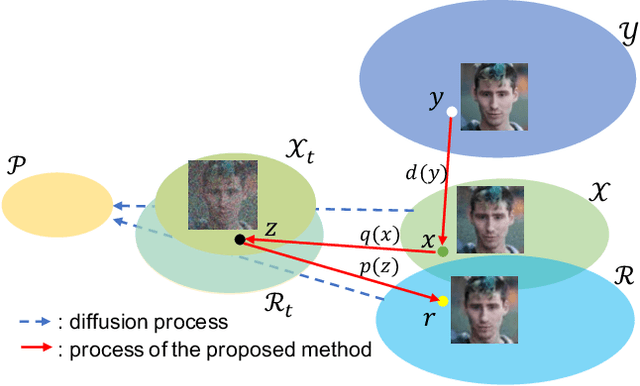


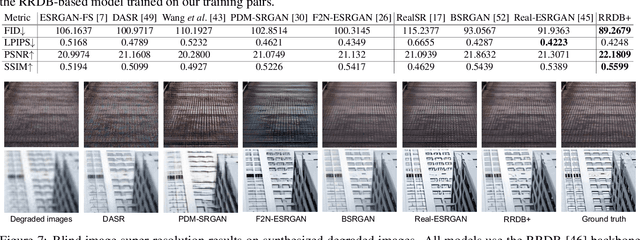
In supervised image restoration tasks, one key issue is how to obtain the aligned high-quality (HQ) and low-quality (LQ) training image pairs. Unfortunately, such HQ-LQ training pairs are hard to capture in practice, and hard to synthesize due to the complex unknown degradation in the wild. While several sophisticated degradation models have been manually designed to synthesize LQ images from their HQ counterparts, the distribution gap between the synthesized and real-world LQ images remains large. We propose a new approach to synthesizing realistic image restoration training pairs using the emerging denoising diffusion probabilistic model (DDPM). First, we train a DDPM, which could convert a noisy input into the desired LQ image, with a large amount of collected LQ images, which define the target data distribution. Then, for a given HQ image, we synthesize an initial LQ image by using an off-the-shelf degradation model, and iteratively add proper Gaussian noises to it. Finally, we denoise the noisy LQ image using the pre-trained DDPM to obtain the final LQ image, which falls into the target distribution of real-world LQ images. Thanks to the strong capability of DDPM in distribution approximation, the synthesized HQ-LQ image pairs can be used to train robust models for real-world image restoration tasks, such as blind face image restoration and blind image super-resolution. Experiments demonstrated the superiority of our proposed approach to existing degradation models. Code and data will be released.
On the Effectiveness of Image Manipulation Detection in the Age of Social Media
Apr 19, 2023
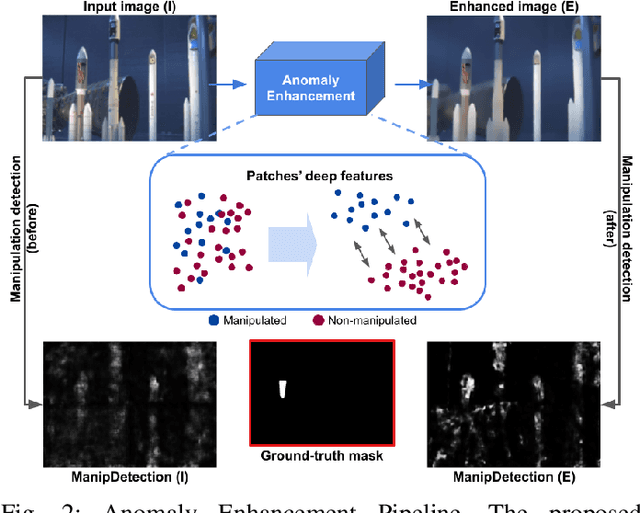
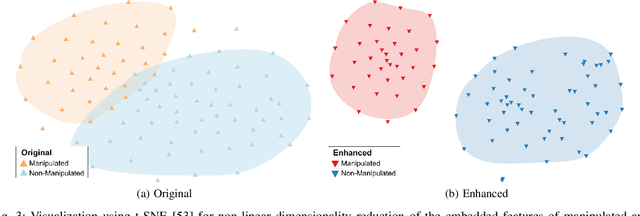

Image manipulation detection algorithms designed to identify local anomalies often rely on the manipulated regions being ``sufficiently'' different from the rest of the non-tampered regions in the image. However, such anomalies might not be easily identifiable in high-quality manipulations, and their use is often based on the assumption that certain image phenomena are associated with the use of specific editing tools. This makes the task of manipulation detection hard in and of itself, with state-of-the-art detectors only being able to detect a limited number of manipulation types. More importantly, in cases where the anomaly assumption does not hold, the detection of false positives in otherwise non-manipulated images becomes a serious problem. To understand the current state of manipulation detection, we present an in-depth analysis of deep learning-based and learning-free methods, assessing their performance on different benchmark datasets containing tampered and non-tampered samples. We provide a comprehensive study of their suitability for detecting different manipulations as well as their robustness when presented with non-tampered data. Furthermore, we propose a novel deep learning-based pre-processing technique that accentuates the anomalies present in manipulated regions to make them more identifiable by a variety of manipulation detection methods. To this end, we introduce an anomaly enhancement loss that, when used with a residual architecture, improves the performance of different detection algorithms with a minimal introduction of false positives on the non-manipulated data. Lastly, we introduce an open-source manipulation detection toolkit comprising a number of standard detection algorithms.
MedLSAM: Localize and Segment Anything Model for 3D Medical Images
Jun 26, 2023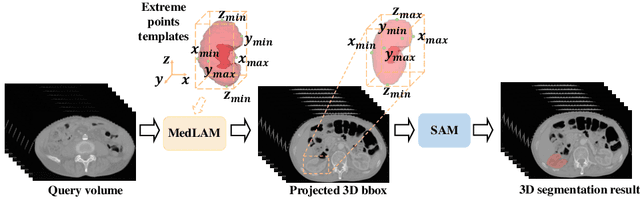
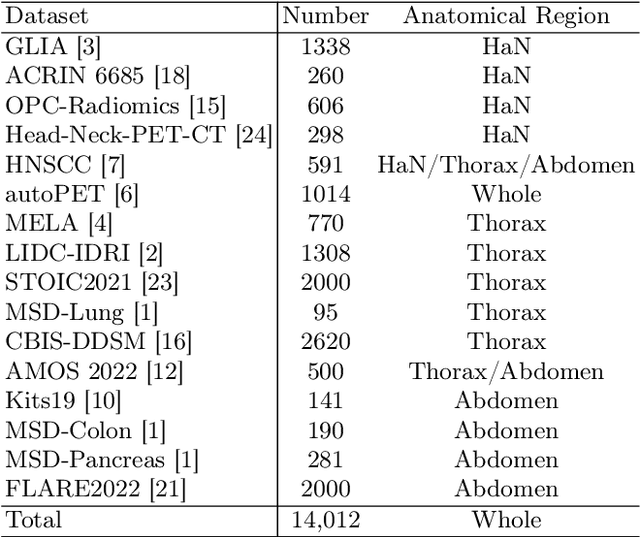
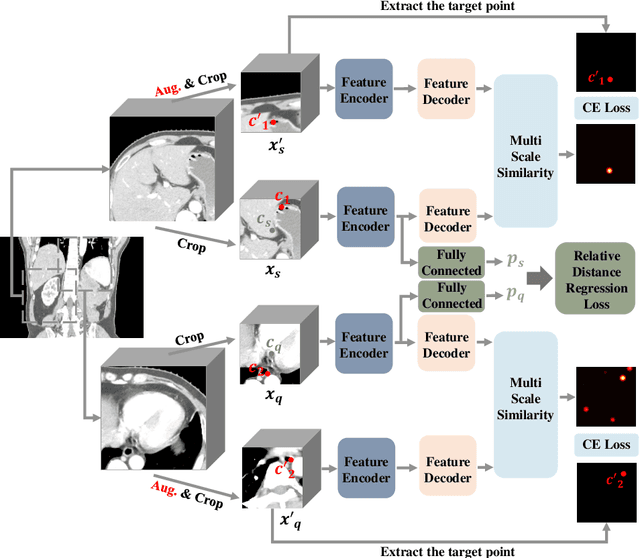
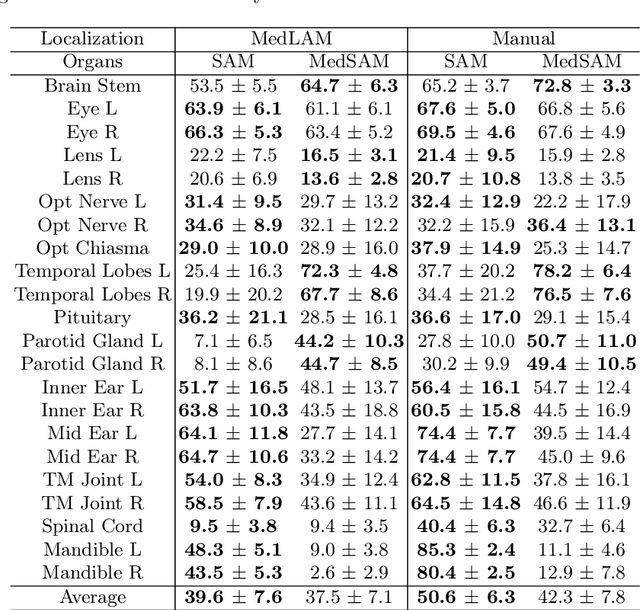
The Segment Anything Model (SAM) has recently emerged as a groundbreaking model in the field of image segmentation. Nevertheless, both the original SAM and its medical adaptations necessitate slice-by-slice annotations, which directly increase the annotation workload with the size of the dataset. We propose MedLSAM to address this issue, ensuring a constant annotation workload irrespective of dataset size and thereby simplifying the annotation process. Our model introduces a few-shot localization framework capable of localizing any target anatomical part within the body. To achieve this, we develop a Localize Anything Model for 3D Medical Images (MedLAM), utilizing two self-supervision tasks: relative distance regression (RDR) and multi-scale similarity (MSS) across a comprehensive dataset of 14,012 CT scans. We then establish a methodology for accurate segmentation by integrating MedLAM with SAM. By annotating only six extreme points across three directions on a few templates, our model can autonomously identify the target anatomical region on all data scheduled for annotation. This allows our framework to generate a 2D bounding box for every slice of the image, which are then leveraged by SAM to carry out segmentations. We conducted experiments on two 3D datasets covering 38 organs and found that MedLSAM matches the performance of SAM and its medical adaptations while requiring only minimal extreme point annotations for the entire dataset. Furthermore, MedLAM has the potential to be seamlessly integrated with future 3D SAM models, paving the way for enhanced performance. Our code is public at \href{https://github.com/openmedlab/MedLSAM}{https://github.com/openmedlab/MedLSAM}.
Zero-shot personalized lip-to-speech synthesis with face image based voice control
May 09, 2023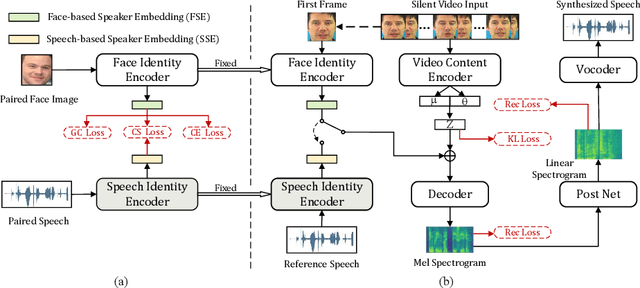

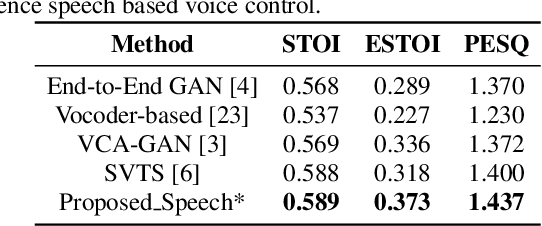
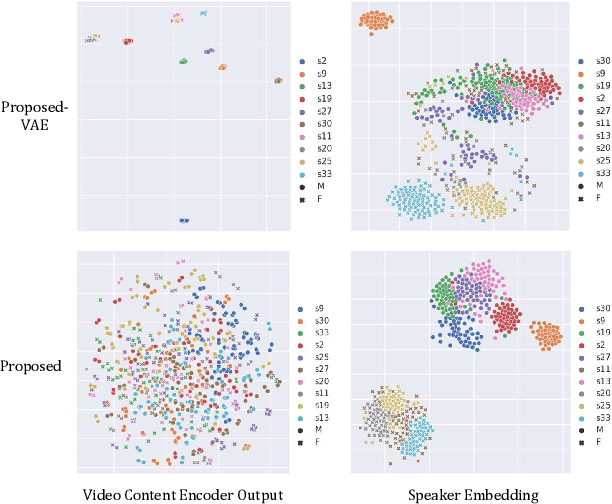
Lip-to-Speech (Lip2Speech) synthesis, which predicts corresponding speech from talking face images, has witnessed significant progress with various models and training strategies in a series of independent studies. However, existing studies can not achieve voice control under zero-shot condition, because extra speaker embeddings need to be extracted from natural reference speech and are unavailable when only the silent video of an unseen speaker is given. In this paper, we propose a zero-shot personalized Lip2Speech synthesis method, in which face images control speaker identities. A variational autoencoder is adopted to disentangle the speaker identity and linguistic content representations, which enables speaker embeddings to control the voice characteristics of synthetic speech for unseen speakers. Furthermore, we propose associated cross-modal representation learning to promote the ability of face-based speaker embeddings (FSE) on voice control. Extensive experiments verify the effectiveness of the proposed method whose synthetic utterances are more natural and matching with the personality of input video than the compared methods. To our best knowledge, this paper makes the first attempt on zero-shot personalized Lip2Speech synthesis with a face image rather than reference audio to control voice characteristics.