 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CosalPure: Learning Concept from Group Images for Robust Co-Saliency Detection
Mar 27, 2024
Co-salient object detection (CoSOD) aims to identify the common and salient (usually in the foreground) regions across a given group of images. Although achieving significant progress, state-of-the-art CoSODs could be easily affected by some adversarial perturbations, leading to substantial accuracy reduction. The adversarial perturbations can mislead CoSODs but do not change the high-level semantic information (e.g., concept) of the co-salient objects. In this paper, we propose a novel robustness enhancement framework by first learning the concept of the co-salient objects based on the input group images and then leveraging this concept to purify adversarial perturbations, which are subsequently fed to CoSODs for robustness enhancement. Specifically, we propose CosalPure containing two modules, i.e., group-image concept learning and concept-guided diffusion purification. For the first module, we adopt a pre-trained text-to-image diffusion model to learn the concept of co-salient objects within group images where the learned concept is robust to adversarial examples. For the second module, we map the adversarial image to the latent space and then perform diffusion generation by embedding the learned concept into the noise prediction function as an extra condition. Our method can effectively alleviate the influence of the SOTA adversarial attack containing different adversarial patterns, including exposure and noise. The extensive results demonstrate that our method could enhance the robustness of CoSODs significantly.
Addressing Source Scale Bias via Image Warping for Domain Adaptation
Mar 19, 2024
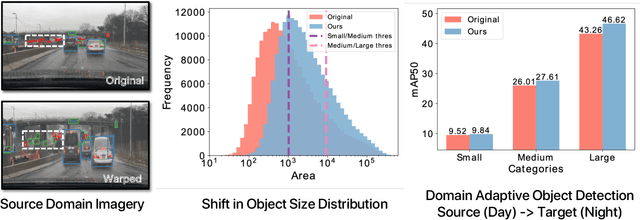

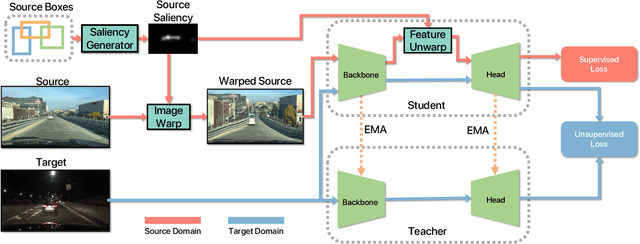
In visual recognition, scale bias is a key challenge due to the imbalance of object and image size distribution inherent in real scene datasets. Conventional solutions involve injecting scale invariance priors, oversampling the dataset at different scales during training, or adjusting scale at inference. While these strategies mitigate scale bias to some extent, their ability to adapt across diverse datasets is limited. Besides, they increase computational load during training and latency during inference. In this work, we use adaptive attentional processing -- oversampling salient object regions by warping images in-place during training. Discovering that shifting the source scale distribution improves backbone features, we developed a instance-level warping guidance aimed at object region sampling to mitigate source scale bias in domain adaptation. Our approach improves adaptation across geographies, lighting and weather conditions, is agnostic to the task, domain adaptation algorithm, saliency guidance, and underlying model architecture. Highlights include +6.1 mAP50 for BDD100K Clear $\rightarrow$ DENSE Foggy, +3.7 mAP50 for BDD100K Day $\rightarrow$ Night, +3.0 mAP50 for BDD100K Clear $\rightarrow$ Rainy, and +6.3 mIoU for Cityscapes $\rightarrow$ ACDC. Our approach adds minimal memory during training and has no additional latency at inference time. Please see Appendix for more results and analysis.
MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
Mar 17, 2024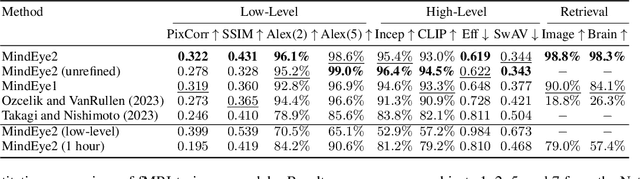
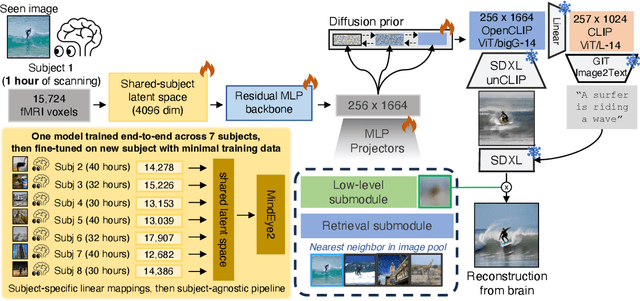
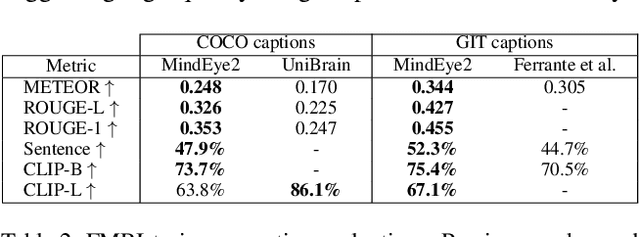

Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
Diverse Feature Learning by Self-distillation and Reset
Mar 29, 2024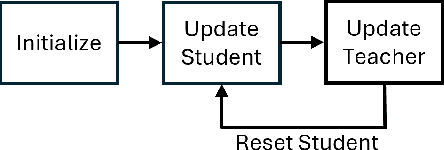
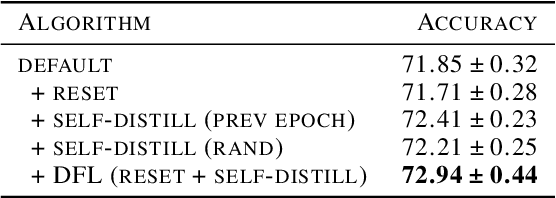
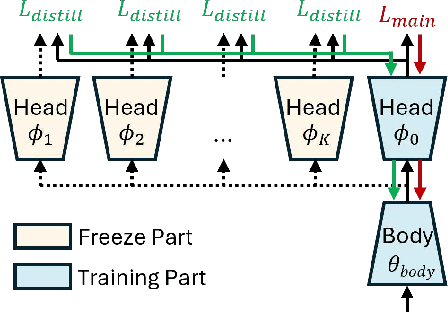
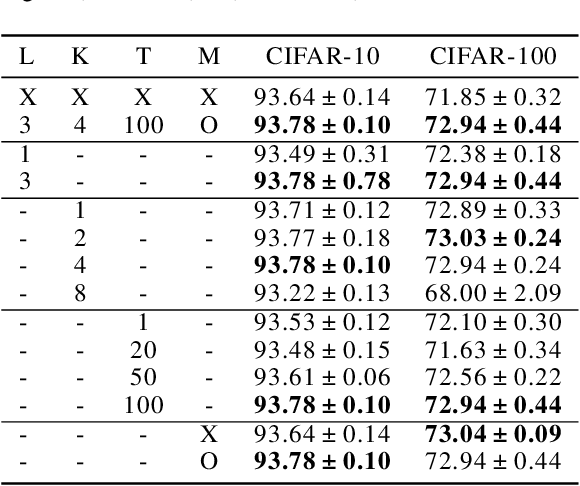
Our paper addresses the problem of models struggling to learn diverse features, due to either forgetting previously learned features or failing to learn new ones. To overcome this problem, we introduce Diverse Feature Learning (DFL), a method that combines an important feature preservation algorithm with a new feature learning algorithm. Specifically, for preserving important features, we utilize self-distillation in ensemble models by selecting the meaningful model weights observed during training. For learning new features, we employ reset that involves periodically re-initializing part of the model. As a result, through experiments with various models on the image classification, we have identified the potential for synergistic effects between self-distillation and reset.
Frame by Familiar Frame: Understanding Replication in Video Diffusion Models
Mar 28, 2024

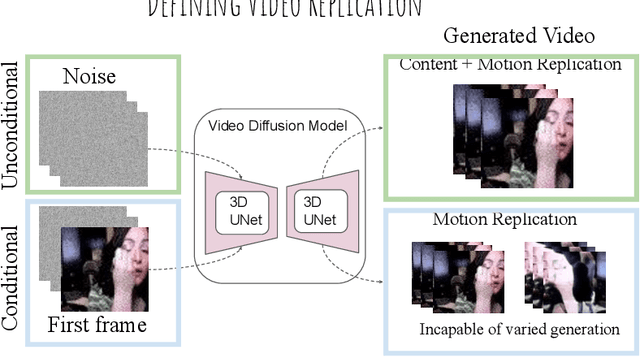

Building on the momentum of image generation diffusion models, there is an increasing interest in video-based diffusion models. However, video generation poses greater challenges due to its higher-dimensional nature, the scarcity of training data, and the complex spatiotemporal relationships involved. Image generation models, due to their extensive data requirements, have already strained computational resources to their limits. There have been instances of these models reproducing elements from the training samples, leading to concerns and even legal disputes over sample replication. Video diffusion models, which operate with even more constrained datasets and are tasked with generating both spatial and temporal content, may be more prone to replicating samples from their training sets. Compounding the issue, these models are often evaluated using metrics that inadvertently reward replication. In our paper, we present a systematic investigation into the phenomenon of sample replication in video diffusion models. We scrutinize various recent diffusion models for video synthesis, assessing their tendency to replicate spatial and temporal content in both unconditional and conditional generation scenarios. Our study identifies strategies that are less likely to lead to replication. Furthermore, we propose new evaluation strategies that take replication into account, offering a more accurate measure of a model's ability to generate the original content.
SeNM-VAE: Semi-Supervised Noise Modeling with Hierarchical Variational Autoencoder
Mar 26, 2024The data bottleneck has emerged as a fundamental challenge in learning based image restoration methods. Researchers have attempted to generate synthesized training data using paired or unpaired samples to address this challenge. This study proposes SeNM-VAE, a semi-supervised noise modeling method that leverages both paired and unpaired datasets to generate realistic degraded data. Our approach is based on modeling the conditional distribution of degraded and clean images with a specially designed graphical model. Under the variational inference framework, we develop an objective function for handling both paired and unpaired data. We employ our method to generate paired training samples for real-world image denoising and super-resolution tasks. Our approach excels in the quality of synthetic degraded images compared to other unpaired and paired noise modeling methods. Furthermore, our approach demonstrates remarkable performance in downstream image restoration tasks, even with limited paired data. With more paired data, our method achieves the best performance on the SIDD dataset.
Powerful Lossy Compression for Noisy Images
Mar 26, 2024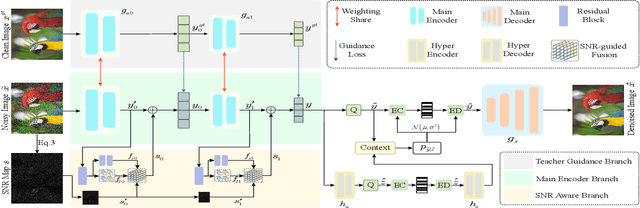
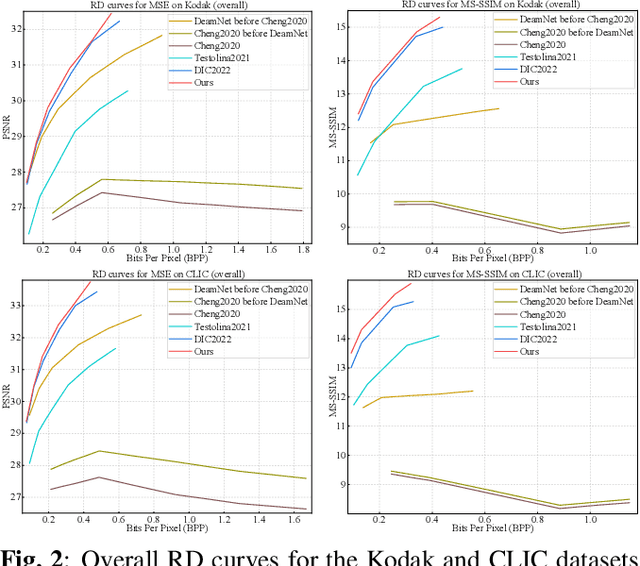
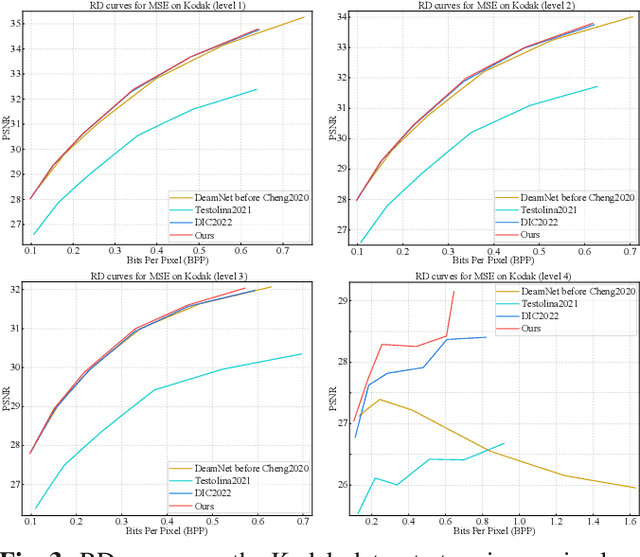
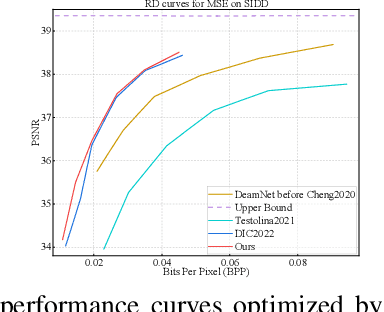
Image compression and denoising represent fundamental challenges in image processing with many real-world applications. To address practical demands, current solutions can be categorized into two main strategies: 1) sequential method; and 2) joint method. However, sequential methods have the disadvantage of error accumulation as there is information loss between multiple individual models. Recently, the academic community began to make some attempts to tackle this problem through end-to-end joint methods. Most of them ignore that different regions of noisy images have different characteristics. To solve these problems, in this paper, our proposed signal-to-noise ratio~(SNR) aware joint solution exploits local and non-local features for image compression and denoising simultaneously. We design an end-to-end trainable network, which includes the main encoder branch, the guidance branch, and the signal-to-noise ratio~(SNR) aware branch. We conducted extensive experiments on both synthetic and real-world datasets, demonstrating that our joint solution outperforms existing state-of-the-art methods.
Envision3D: One Image to 3D with Anchor Views Interpolation
Mar 13, 2024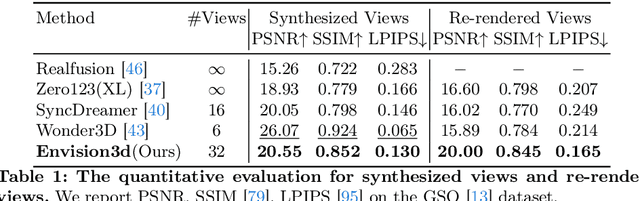
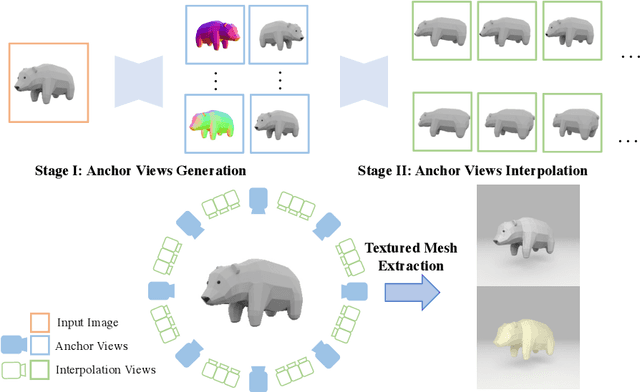

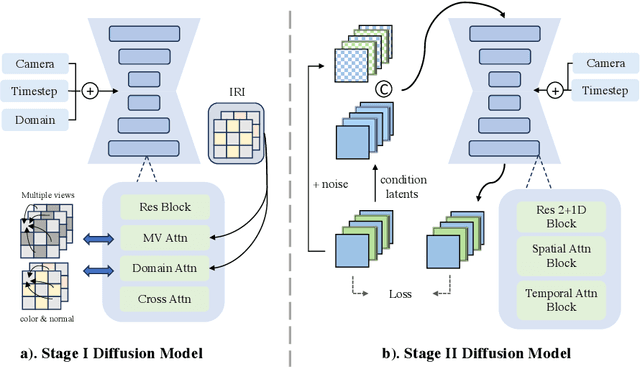
We present Envision3D, a novel method for efficiently generating high-quality 3D content from a single image. Recent methods that extract 3D content from multi-view images generated by diffusion models show great potential. However, it is still challenging for diffusion models to generate dense multi-view consistent images, which is crucial for the quality of 3D content extraction. To address this issue, we propose a novel cascade diffusion framework, which decomposes the challenging dense views generation task into two tractable stages, namely anchor views generation and anchor views interpolation. In the first stage, we train the image diffusion model to generate global consistent anchor views conditioning on image-normal pairs. Subsequently, leveraging our video diffusion model fine-tuned on consecutive multi-view images, we conduct interpolation on the previous anchor views to generate extra dense views. This framework yields dense, multi-view consistent images, providing comprehensive 3D information. To further enhance the overall generation quality, we introduce a coarse-to-fine sampling strategy for the reconstruction algorithm to robustly extract textured meshes from the generated dense images. Extensive experiments demonstrate that our method is capable of generating high-quality 3D content in terms of texture and geometry, surpassing previous image-to-3D baseline methods.
The Impact of Uniform Inputs on Activation Sparsity and Energy-Latency Attacks in Computer Vision
Mar 27, 2024Resource efficiency plays an important role for machine learning nowadays. The energy and decision latency are two critical aspects to ensure a sustainable and practical application. Unfortunately, the energy consumption and decision latency are not robust against adversaries. Researchers have recently demonstrated that attackers can compute and submit so-called sponge examples at inference time to increase the energy consumption and decision latency of neural networks. In computer vision, the proposed strategy crafts inputs with less activation sparsity which could otherwise be used to accelerate the computation. In this paper, we analyze the mechanism how these energy-latency attacks reduce activation sparsity. In particular, we find that input uniformity is a key enabler. A uniform image, that is, an image with mostly flat, uniformly colored surfaces, triggers more activations due to a specific interplay of convolution, batch normalization, and ReLU activation. Based on these insights, we propose two new simple, yet effective strategies for crafting sponge examples: sampling images from a probability distribution and identifying dense, yet inconspicuous inputs in natural datasets. We empirically examine our findings in a comprehensive evaluation with multiple image classification models and show that our attack achieves the same sparsity effect as prior sponge-example methods, but at a fraction of computation effort. We also show that our sponge examples transfer between different neural networks. Finally, we discuss applications of our findings for the good by improving efficiency by increasing sparsity.
Lift3D: Zero-Shot Lifting of Any 2D Vision Model to 3D
Mar 27, 2024In recent years, there has been an explosion of 2D vision models for numerous tasks such as semantic segmentation, style transfer or scene editing, enabled by large-scale 2D image datasets. At the same time, there has been renewed interest in 3D scene representations such as neural radiance fields from multi-view images. However, the availability of 3D or multiview data is still substantially limited compared to 2D image datasets, making extending 2D vision models to 3D data highly desirable but also very challenging. Indeed, extending a single 2D vision operator like scene editing to 3D typically requires a highly creative method specialized to that task and often requires per-scene optimization. In this paper, we ask the question of whether any 2D vision model can be lifted to make 3D consistent predictions. We answer this question in the affirmative; our new Lift3D method trains to predict unseen views on feature spaces generated by a few visual models (i.e. DINO and CLIP), but then generalizes to novel vision operators and tasks, such as style transfer, super-resolution, open vocabulary segmentation and image colorization; for some of these tasks, there is no comparable previous 3D method. In many cases, we even outperform state-of-the-art methods specialized for the task in question. Moreover, Lift3D is a zero-shot method, in the sense that it requires no task-specific training, nor scene-specific optimization.