 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PDS-MAR: a fine-grained Projection-Domain Segmentation-based Metal Artifact Reduction method for intraoperative CBCT images with guidewires
Jun 21, 2023
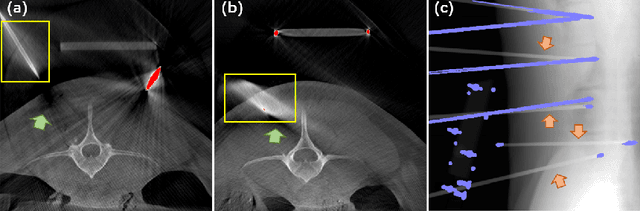

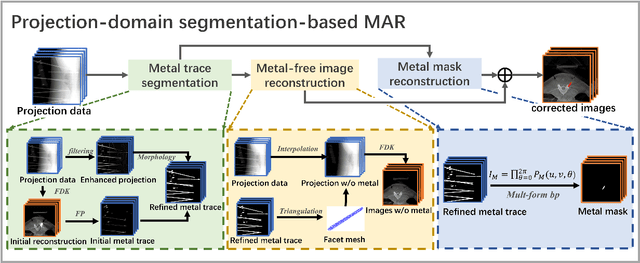
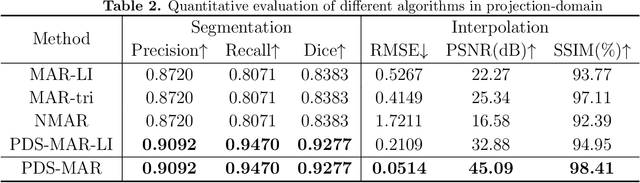
Since the invention of modern CT systems, metal artifacts have been a persistent problem. Due to increased scattering, amplified noise, and insufficient data collection, it is more difficult to suppress metal artifacts in cone-beam CT, limiting its use in human- and robot-assisted spine surgeries where metallic guidewires and screws are commonly used. In this paper, we demonstrate that conventional image-domain segmentation-based MAR methods are unable to eliminate metal artifacts for intraoperative CBCT images with guidewires. To solve this problem, we present a fine-grained projection-domain segmentation-based MAR method termed PDS-MAR, in which metal traces are augmented and segmented in the projection domain before being inpainted using triangular interpolation. In addition, a metal reconstruction phase is proposed to restore metal areas in the image domain. The digital phantom study and real CBCT data study demonstrate that the proposed algorithm achieves significantly better artifact suppression than other comparing methods and has the potential to advance the use of intraoperative CBCT imaging in clinical spine surgeries.
Toward Fairness Through Fair Multi-Exit Framework for Dermatological Disease Diagnosis
Jul 01, 2023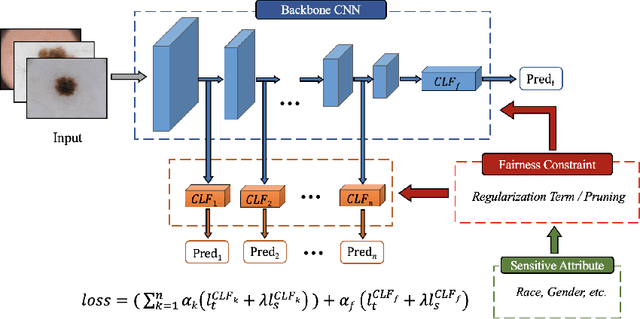
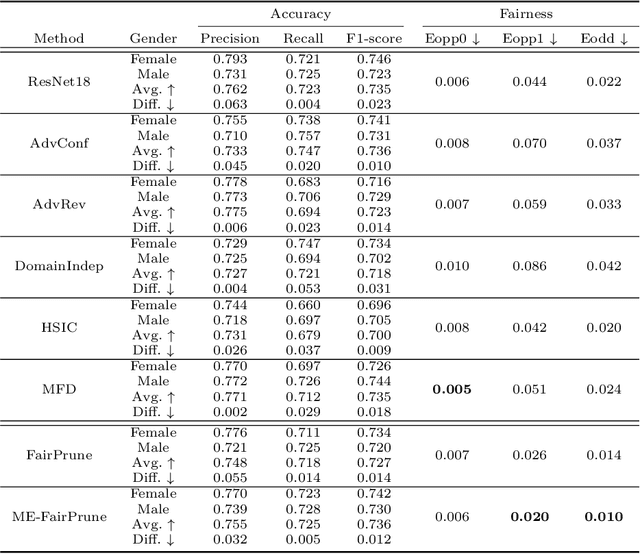
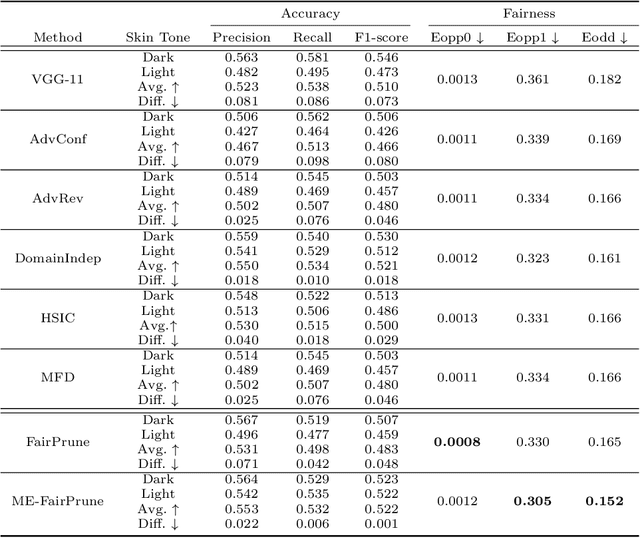
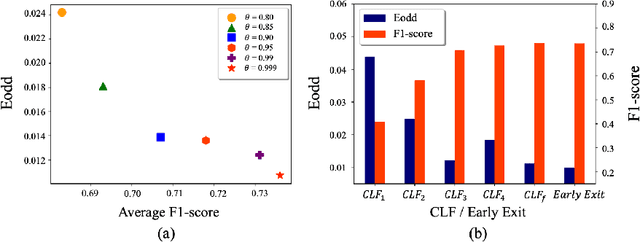
Fairness has become increasingly pivotal in medical image recognition. However, without mitigating bias, deploying unfair medical AI systems could harm the interests of underprivileged populations. In this paper, we observe that while features extracted from the deeper layers of neural networks generally offer higher accuracy, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit frameworks. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented; the internal classifiers are trained to be more accurate and fairer, with high extensibility to apply to most existing fairness-aware frameworks. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Experimental results show that the proposed framework can improve the fairness condition over the state-of-the-art in two dermatological disease datasets.
Implementation of Real-Time Automotive SAR Imaging
Jun 16, 2023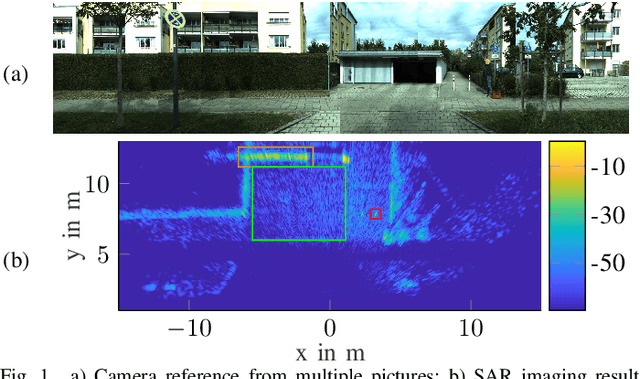

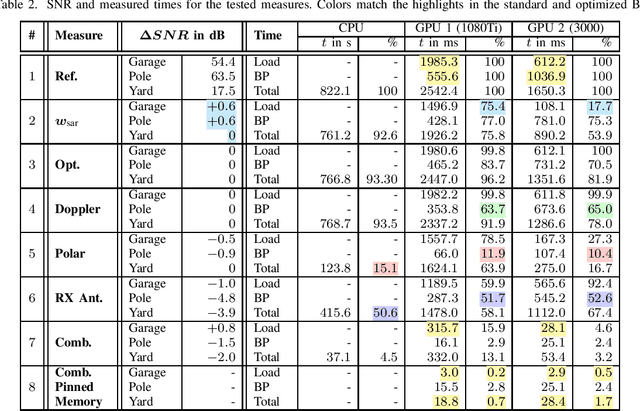

This paper presents measures to reduce the computation time of automotive synthetic aperture radar (SAR) imaging to achieve real-time capability. For this, the image formation, which is based on the Back-Projection algorithm, was thoroughly analyzed. Various optimizations were individually tested and analyzed on graphics processing units (GPU). Apart from the time reduction gained from these measures, the data size needed for processing was also drastically decreased. With a combination of all measures, a high-resolution SAR image of 30 m by 30 m that combines 8192 chirps can be reconstructed in less than 30 ms using a standard GPU. It is thus demonstrated that a real-time implementation of automotive SAR is possible.
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing
Jun 14, 2023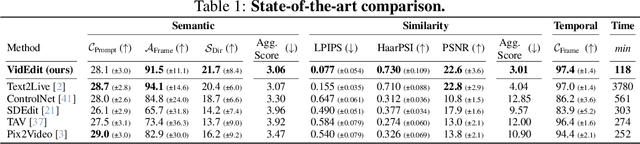
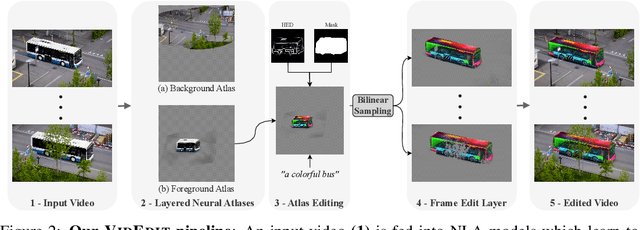
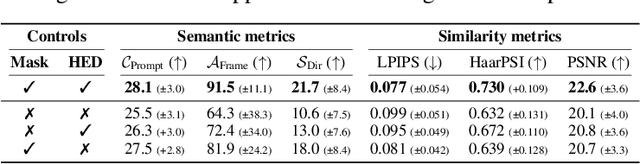
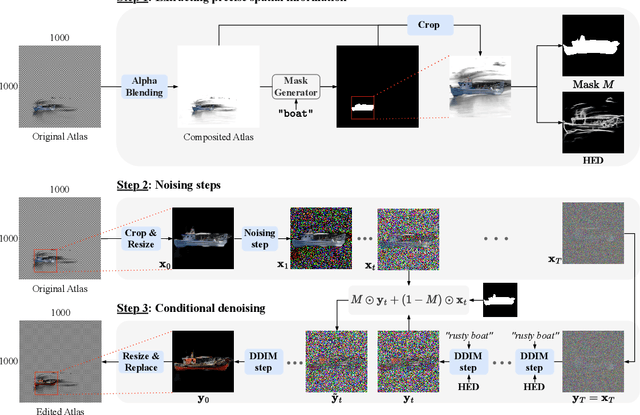
Recently, diffusion-based generative models have achieved remarkable success for image generation and edition. However, their use for video editing still faces important limitations. This paper introduces VidEdit, a novel method for zero-shot text-based video editing ensuring strong temporal and spatial consistency. Firstly, we propose to combine atlas-based and pre-trained text-to-image diffusion models to provide a training-free and efficient editing method, which by design fulfills temporal smoothness. Secondly, we leverage off-the-shelf panoptic segmenters along with edge detectors and adapt their use for conditioned diffusion-based atlas editing. This ensures a fine spatial control on targeted regions while strictly preserving the structure of the original video. Quantitative and qualitative experiments show that VidEdit outperforms state-of-the-art methods on DAVIS dataset, regarding semantic faithfulness, image preservation, and temporal consistency metrics. With this framework, processing a single video only takes approximately one minute, and it can generate multiple compatible edits based on a unique text prompt. Project web-page at https://videdit.github.io
DIRE for Diffusion-Generated Image Detection
Mar 16, 2023
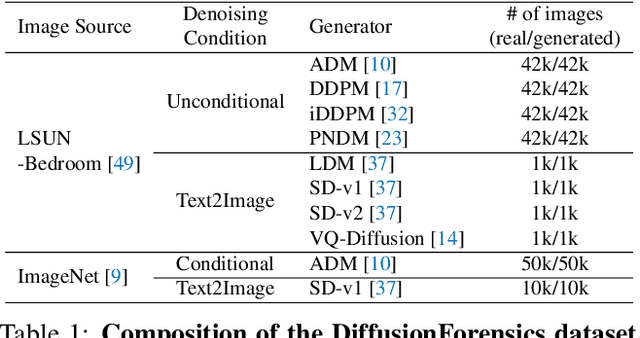

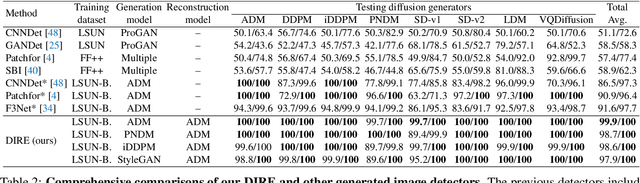
Diffusion models have shown remarkable success in visual synthesis, but have also raised concerns about potential abuse for malicious purposes. In this paper, we seek to build a detector for telling apart real images from diffusion-generated images. We find that existing detectors struggle to detect images generated by diffusion models, even if we include generated images from a specific diffusion model in their training data. To address this issue, we propose a novel image representation called DIffusion Reconstruction Error (DIRE), which measures the error between an input image and its reconstruction counterpart by a pre-trained diffusion model. We observe that diffusion-generated images can be approximately reconstructed by a diffusion model while real images cannot. It provides a hint that DIRE can serve as a bridge to distinguish generated and real images. DIRE provides an effective way to detect images generated by most diffusion models, and it is general for detecting generated images from unseen diffusion models and robust to various perturbations. Furthermore, we establish a comprehensive diffusion-generated benchmark including images generated by eight diffusion models to evaluate the performance of diffusion-generated image detectors. Extensive experiments on our collected benchmark demonstrate that DIRE exhibits superiority over previous generated-image detectors. The code and dataset are available at https://github.com/ZhendongWang6/DIRE.
Self-supervised Multi-task Learning Framework for Safety and Health-Oriented Connected Driving Environment Perception using Onboard Camera
Jun 20, 2023Cutting-edge connected vehicle (CV) technologies have drawn much attention in recent years. The real-time traffic data captured by a CV can be shared with other CVs and data centers so as to open new possibilities for solving diverse transportation problems. However, imagery captured by onboard cameras in a connected environment, are not sufficiently investigated, especially for safety and health-oriented visual perception. In this paper, a bidirectional process of image synthesis and decomposition (BPISD) approach is proposed, and thus a novel self-supervised multi-task learning framework, to simultaneously estimate depth map, atmospheric visibility, airlight, and PM2.5 mass concentration, in which depth map and visibility are considered highly associated with traffic safety, while airlight and PM2.5 mass concentration are directly correlated with human health. Both the training and testing phases of the proposed system solely require a single image as input. Due to the innovative training pipeline, the depth estimation network can manage various levels of visibility conditions and overcome inherent problems in current image-synthesis-based depth estimation, thereby generating high-quality depth maps even in low-visibility situations and further benefiting accurate estimations of visibility, airlight, and PM2.5 mass concentration. Extensive experiments on the synthesized data from the KITTI and real-world data collected in Beijing demonstrate that the proposed method can (1) achieve performance competitive in depth estimation as compared with state-of-the-art methods when taking clear images as input; (2) predict vivid depth map for images contaminated by various levels of haze; and (3) accurately estimate visibility, airlight, and PM2.5 mass concentrations. Beneficial applications can be developed based on the presented work to improve traffic safety, air quality, and public health.
The Rise of AI Language Pathologists: Exploring Two-level Prompt Learning for Few-shot Weakly-supervised Whole Slide Image Classification
May 29, 2023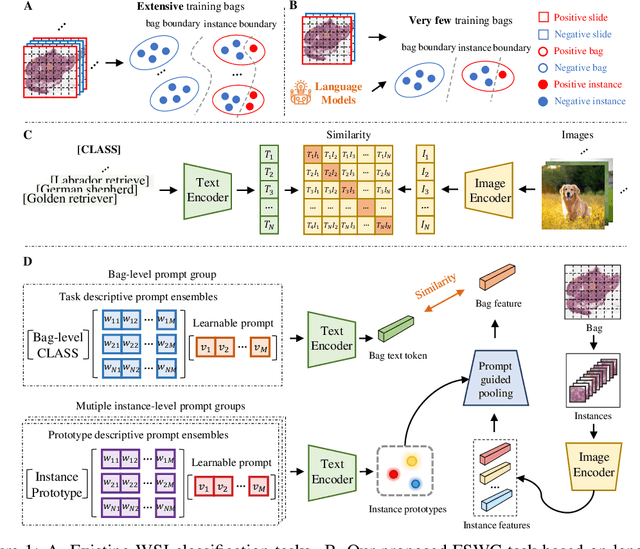
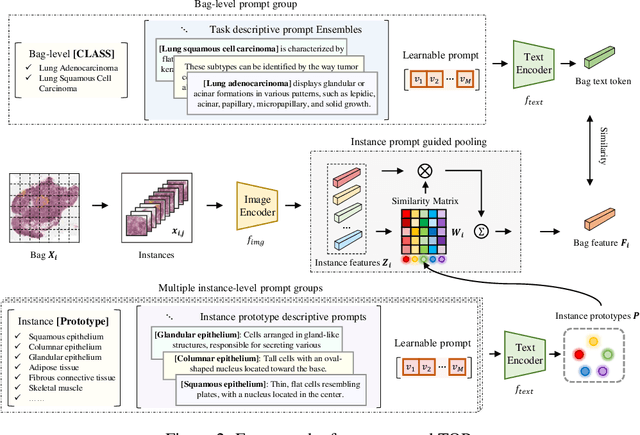
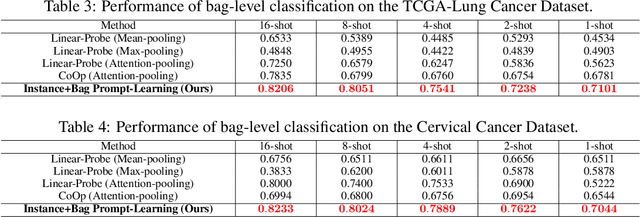
This paper introduces the novel concept of few-shot weakly supervised learning for pathology Whole Slide Image (WSI) classification, denoted as FSWC. A solution is proposed based on prompt learning and the utilization of a large language model, GPT-4. Since a WSI is too large and needs to be divided into patches for processing, WSI classification is commonly approached as a Multiple Instance Learning (MIL) problem. In this context, each WSI is considered a bag, and the obtained patches are treated as instances. The objective of FSWC is to classify both bags and instances with only a limited number of labeled bags. Unlike conventional few-shot learning problems, FSWC poses additional challenges due to its weak bag labels within the MIL framework. Drawing inspiration from the recent achievements of vision-language models (V-L models) in downstream few-shot classification tasks, we propose a two-level prompt learning MIL framework tailored for pathology, incorporating language prior knowledge. Specifically, we leverage CLIP to extract instance features for each patch, and introduce a prompt-guided pooling strategy to aggregate these instance features into a bag feature. Subsequently, we employ a small number of labeled bags to facilitate few-shot prompt learning based on the bag features. Our approach incorporates the utilization of GPT-4 in a question-and-answer mode to obtain language prior knowledge at both the instance and bag levels, which are then integrated into the instance and bag level language prompts. Additionally, a learnable component of the language prompts is trained using the available few-shot labeled data. We conduct extensive experiments on three real WSI datasets encompassing breast cancer, lung cancer, and cervical cancer, demonstrating the notable performance of the proposed method in bag and instance classification. All codes will be made publicly accessible.
AxonCallosumEM Dataset: Axon Semantic Segmentation of Whole Corpus Callosum cross section from EM Images
Jul 05, 2023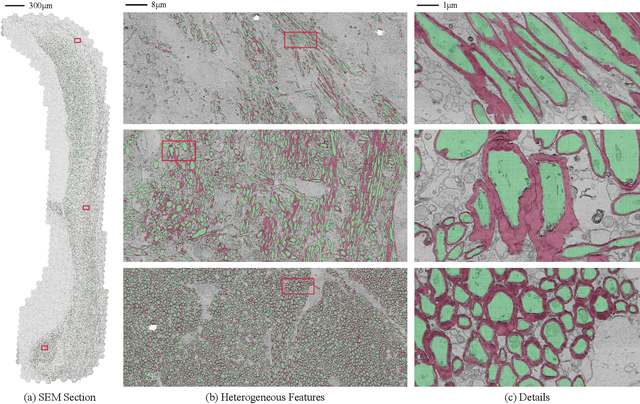
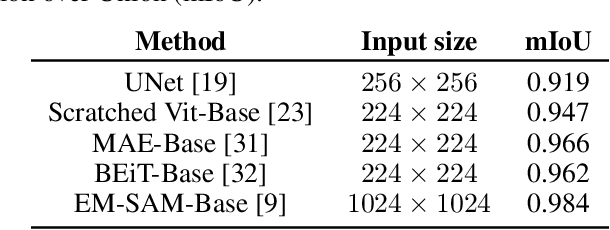
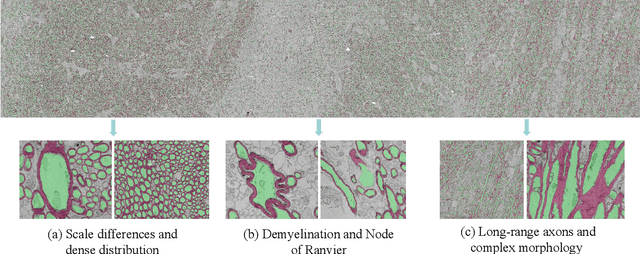
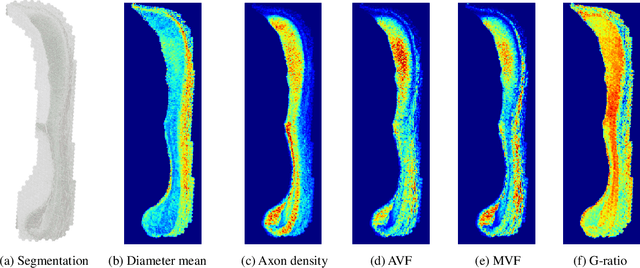
The electron microscope (EM) remains the predominant technique for elucidating intricate details of the animal nervous system at the nanometer scale. However, accurately reconstructing the complex morphology of axons and myelin sheaths poses a significant challenge. Furthermore, the absence of publicly available, large-scale EM datasets encompassing complete cross sections of the corpus callosum, with dense ground truth segmentation for axons and myelin sheaths, hinders the advancement and evaluation of holistic corpus callosum reconstructions. To surmount these obstacles, we introduce the AxonCallosumEM dataset, comprising a 1.83 times 5.76mm EM image captured from the corpus callosum of the Rett Syndrome (RTT) mouse model, which entail extensive axon bundles. We meticulously proofread over 600,000 patches at a resolution of 1024 times 1024, thus providing a comprehensive ground truth for myelinated axons and myelin sheaths. Additionally, we extensively annotated three distinct regions within the dataset for the purposes of training, testing, and validation. Utilizing this dataset, we develop a fine-tuning methodology that adapts Segment Anything Model (SAM) to EM images segmentation tasks, called EM-SAM, enabling outperforms other state-of-the-art methods. Furthermore, we present the evaluation results of EM-SAM as a baseline.
SVDM: Single-View Diffusion Model for Pseudo-Stereo 3D Object Detection
Jul 05, 2023

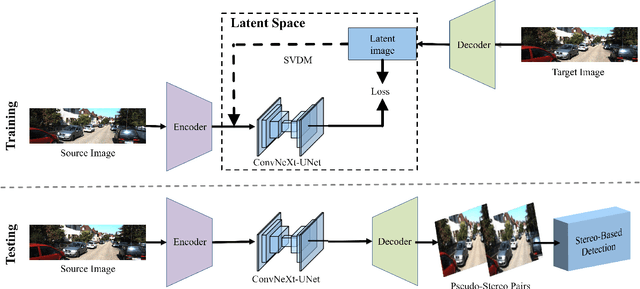

One of the key problems in 3D object detection is to reduce the accuracy gap between methods based on LiDAR sensors and those based on monocular cameras. A recently proposed framework for monocular 3D detection based on Pseudo-Stereo has received considerable attention in the community. However, so far these two problems are discovered in existing practices, including (1) monocular depth estimation and Pseudo-Stereo detector must be trained separately, (2) Difficult to be compatible with different stereo detectors and (3) the overall calculation is large, which affects the reasoning speed. In this work, we propose an end-to-end, efficient pseudo-stereo 3D detection framework by introducing a Single-View Diffusion Model (SVDM) that uses a few iterations to gradually deliver right informative pixels to the left image. SVDM allows the entire pseudo-stereo 3D detection pipeline to be trained end-to-end and can benefit from the training of stereo detectors. Afterwards, we further explore the application of SVDM in depth-free stereo 3D detection, and the final framework is compatible with most stereo detectors. Among multiple benchmarks on the KITTI dataset, we achieve new state-of-the-art performance.
What Matters in Training a GPT4-Style Language Model with Multimodal Inputs?
Jul 05, 2023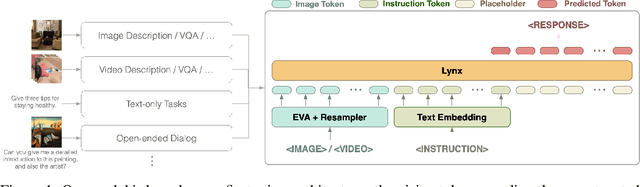
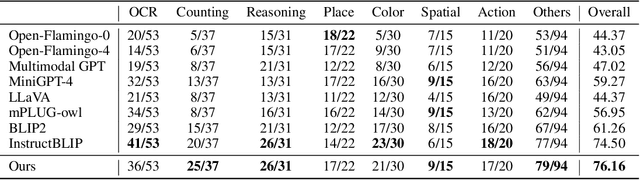
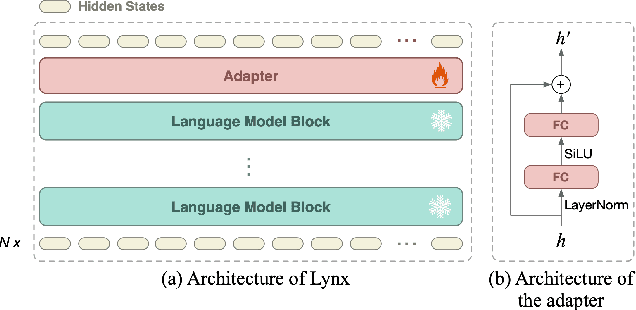
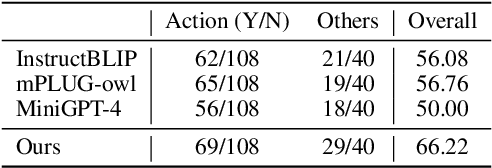
Recent advancements in Large Language Models (LLMs) such as GPT4 have displayed exceptional multi-modal capabilities in following open-ended instructions given images. However, the performance of these models heavily relies on design choices such as network structures, training data, and training strategies, and these choices have not been extensively discussed in the literature, making it difficult to quantify progress in this field. To address this issue, this paper presents a systematic and comprehensive study, quantitatively and qualitatively, on training such models. We implement over 20 variants with controlled settings. Concretely, for network structures, we compare different LLM backbones and model designs. For training data, we investigate the impact of data and sampling strategies. For instructions, we explore the influence of diversified prompts on the instruction-following ability of the trained models. For benchmarks, we contribute the first, to our best knowledge, comprehensive evaluation set including both image and video tasks through crowd-sourcing. Based on our findings, we present Lynx, which performs the most accurate multi-modal understanding while keeping the best multi-modal generation ability compared to existing open-sourced GPT4-style models.