 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comprehensive Multi-scale Approach for Speech and Dynamics Synchrony in Talking Head Generation
Jul 04, 2023

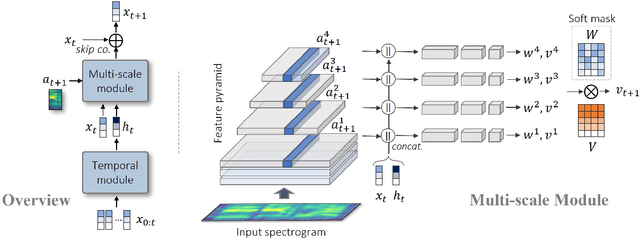
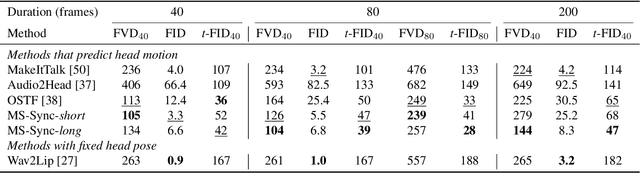
Animating still face images with deep generative models using a speech input signal is an active research topic and has seen important recent progress. However, much of the effort has been put into lip syncing and rendering quality while the generation of natural head motion, let alone the audio-visual correlation between head motion and speech, has often been neglected. In this work, we propose a multi-scale audio-visual synchrony loss and a multi-scale autoregressive GAN to better handle short and long-term correlation between speech and the dynamics of the head and lips. In particular, we train a stack of syncer models on multimodal input pyramids and use these models as guidance in a multi-scale generator network to produce audio-aligned motion unfolding over diverse time scales. Our generator operates in the facial landmark domain, which is a standard low-dimensional head representation. The experiments show significant improvements over the state of the art in head motion dynamics quality and in multi-scale audio-visual synchrony both in the landmark domain and in the image domain.
CT-based Subchondral Bone Microstructural Analysis in Knee Osteoarthritis via MR-Guided Distillation Learning
Jul 11, 2023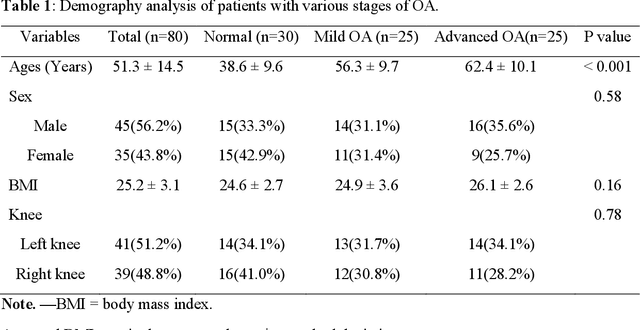

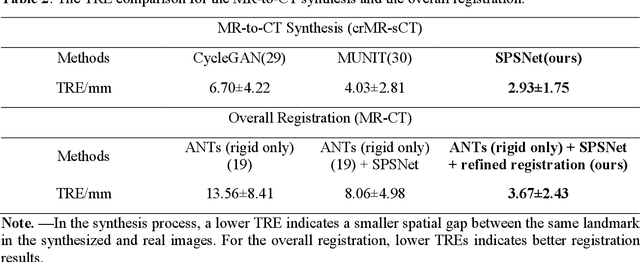
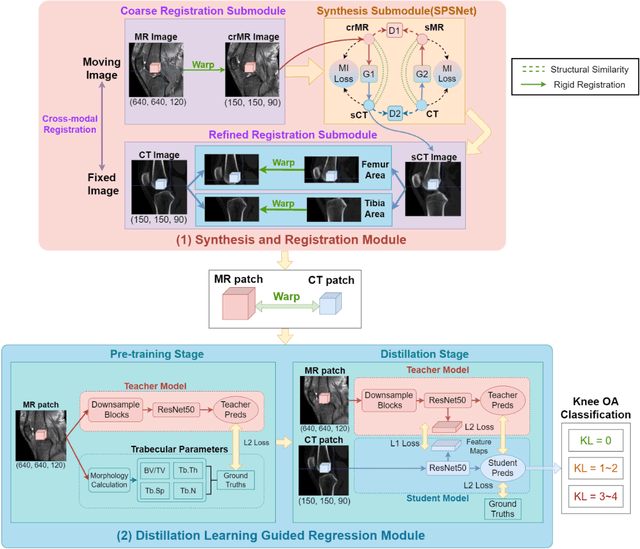
Background: MR-based subchondral bone effectively predicts knee osteoarthritis. However, its clinical application is limited by the cost and time of MR. Purpose: We aim to develop a novel distillation-learning-based method named SRRD for subchondral bone microstructural analysis using easily-acquired CT images, which leverages paired MR images to enhance the CT-based analysis model during training. Materials and Methods: Knee joint images of both CT and MR modalities were collected from October 2020 to May 2021. Firstly, we developed a GAN-based generative model to transform MR images into CT images, which was used to establish the anatomical correspondence between the two modalities. Next, we obtained numerous patches of subchondral bone regions of MR images, together with their trabecular parameters (BV / TV, Tb. Th, Tb. Sp, Tb. N) from the corresponding CT image patches via regression. The distillation-learning technique was used to train the regression model and transfer MR structural information to the CT-based model. The regressed trabecular parameters were further used for knee osteoarthritis classification. Results: A total of 80 participants were evaluated. CT-based regression results of trabecular parameters achieved intra-class correlation coefficients (ICCs) of 0.804, 0.773, 0.711, and 0.622 for BV / TV, Tb. Th, Tb. Sp, and Tb. N, respectively. The use of distillation learning significantly improved the performance of the CT-based knee osteoarthritis classification method using the CNN approach, yielding an AUC score of 0.767 (95% CI, 0.681-0.853) instead of 0.658 (95% CI, 0.574-0.742) (p<.001). Conclusions: The proposed SRRD method showed high reliability and validity in MR-CT registration, regression, and knee osteoarthritis classification, indicating the feasibility of subchondral bone microstructural analysis based on CT images.
Novel Pipeline for Diagnosing Acute Lymphoblastic Leukemia Sensitive to Related Biomarkers
Jul 11, 2023
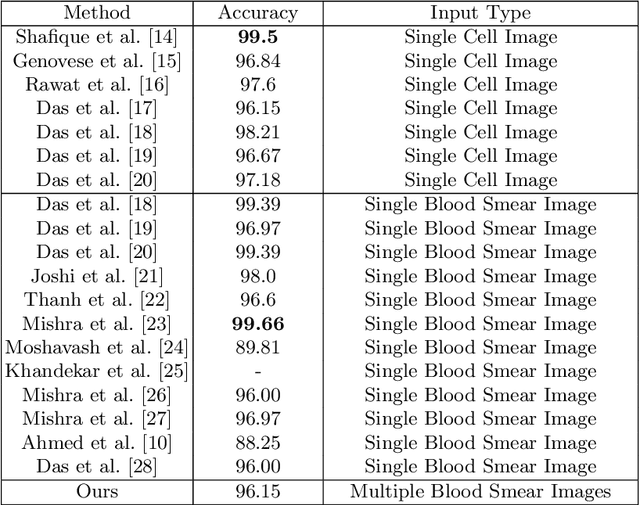
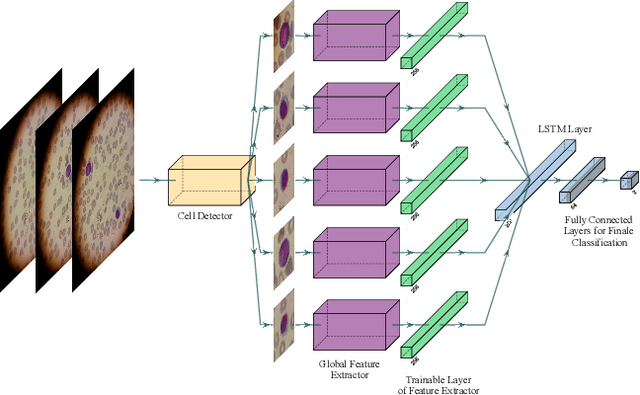
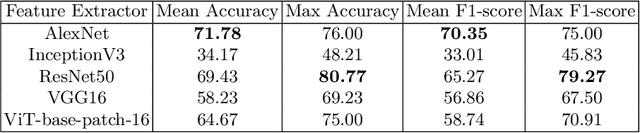
Acute Lymphoblastic Leukemia (ALL) is one of the most common types of childhood blood cancer. The quick start of the treatment process is critical to saving the patient's life, and for this reason, early diagnosis of this disease is essential. Examining the blood smear images of these patients is one of the methods used by expert doctors to diagnose this disease. Deep learning-based methods have numerous applications in medical fields, as they have significantly advanced in recent years. ALL diagnosis is not an exception in this field, and several machine learning-based methods for this problem have been proposed. In previous methods, high diagnostic accuracy was reported, but our work showed that this alone is not sufficient, as it can lead to models taking shortcuts and not making meaningful decisions. This issue arises due to the small size of medical training datasets. To address this, we constrained our model to follow a pipeline inspired by experts' work. We also demonstrated that, since a judgement based on only one image is insufficient, redefining the problem as a multiple-instance learning problem is necessary for achieving a practical result. Our model is the first to provide a solution to this problem in a multiple-instance learning setup. We introduced a novel pipeline for diagnosing ALL that approximates the process used by hematologists, is sensitive to disease biomarkers, and achieves an accuracy of 96.15%, an F1-score of 94.24%, a sensitivity of 97.56%, and a specificity of 90.91% on ALL IDB 1. Our method was further evaluated on an out-of-distribution dataset, which posed a challenging test and had acceptable performance. Notably, our model was trained on a relatively small dataset, highlighting the potential for our approach to be applied to other medical datasets with limited data availability.
Parameter-Free Channel Attention for Image Classification and Super-Resolution
Mar 20, 2023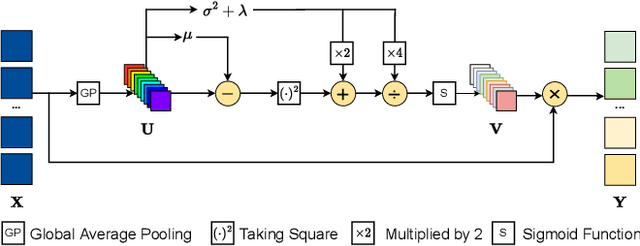
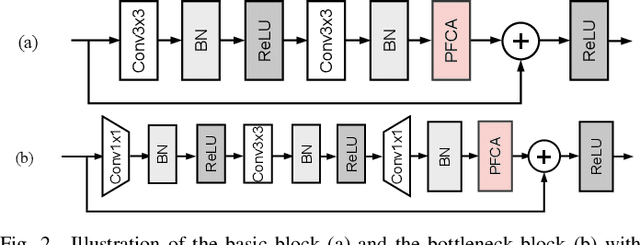
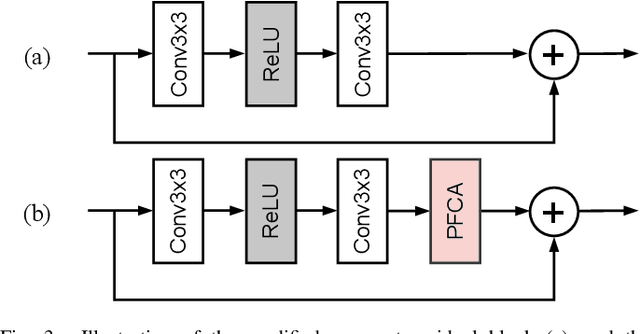
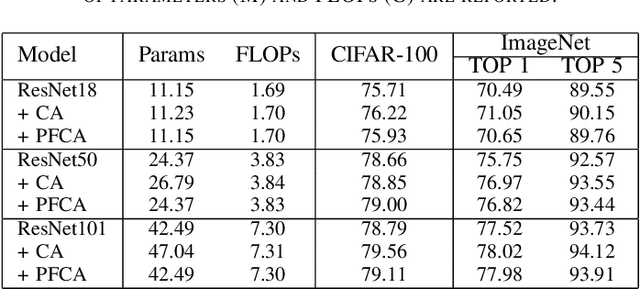
The channel attention mechanism is a useful technique widely employed in deep convolutional neural networks to boost the performance for image processing tasks, eg, image classification and image super-resolution. It is usually designed as a parameterized sub-network and embedded into the convolutional layers of the network to learn more powerful feature representations. However, current channel attention induces more parameters and therefore leads to higher computational costs. To deal with this issue, in this work, we propose a Parameter-Free Channel Attention (PFCA) module to boost the performance of popular image classification and image super-resolution networks, but completely sweep out the parameter growth of channel attention. Experiments on CIFAR-100, ImageNet, and DIV2K validate that our PFCA module improves the performance of ResNet on image classification and improves the performance of MSRResNet on image super-resolution tasks, respectively, while bringing little growth of parameters and FLOPs.
Omni Aggregation Networks for Lightweight Image Super-Resolution
Apr 24, 2023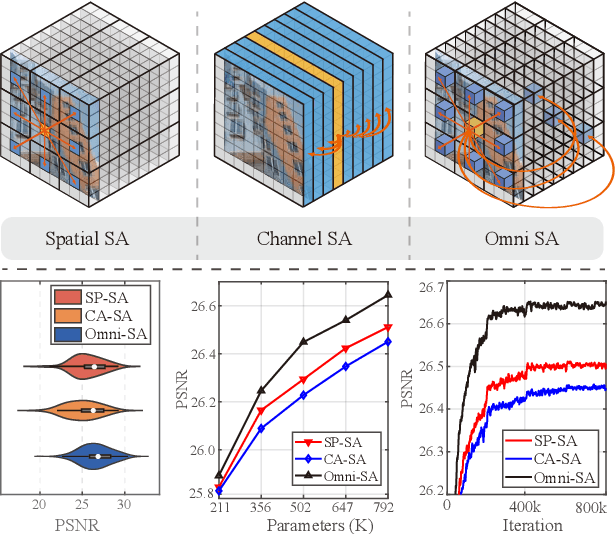
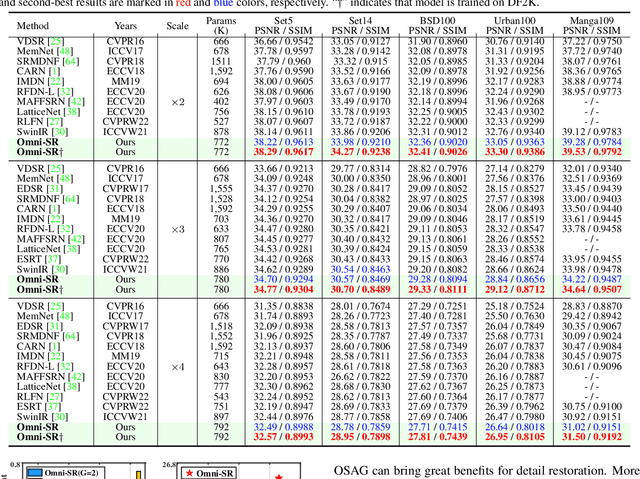
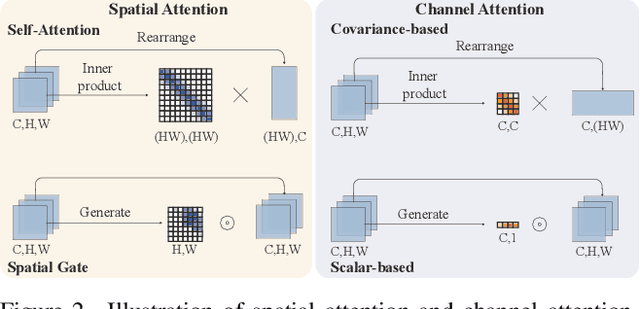

While lightweight ViT framework has made tremendous progress in image super-resolution, its uni-dimensional self-attention modeling, as well as homogeneous aggregation scheme, limit its effective receptive field (ERF) to include more comprehensive interactions from both spatial and channel dimensions. To tackle these drawbacks, this work proposes two enhanced components under a new Omni-SR architecture. First, an Omni Self-Attention (OSA) block is proposed based on dense interaction principle, which can simultaneously model pixel-interaction from both spatial and channel dimensions, mining the potential correlations across omni-axis (i.e., spatial and channel). Coupling with mainstream window partitioning strategies, OSA can achieve superior performance with compelling computational budgets. Second, a multi-scale interaction scheme is proposed to mitigate sub-optimal ERF (i.e., premature saturation) in shallow models, which facilitates local propagation and meso-/global-scale interactions, rendering an omni-scale aggregation building block. Extensive experiments demonstrate that Omni-SR achieves record-high performance on lightweight super-resolution benchmarks (e.g., 26.95 dB@Urban100 $\times 4$ with only 792K parameters). Our code is available at \url{https://github.com/Francis0625/Omni-SR}.
MeMaHand: Exploiting Mesh-Mano Interaction for Single Image Two-Hand Reconstruction
Apr 17, 2023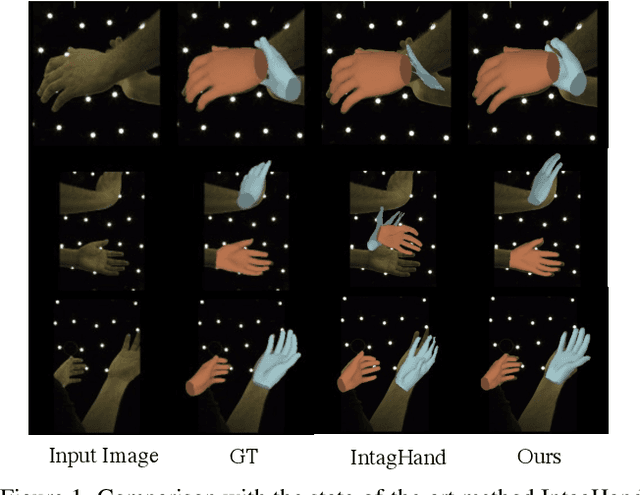
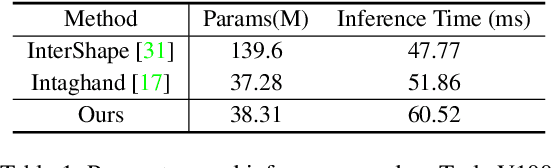
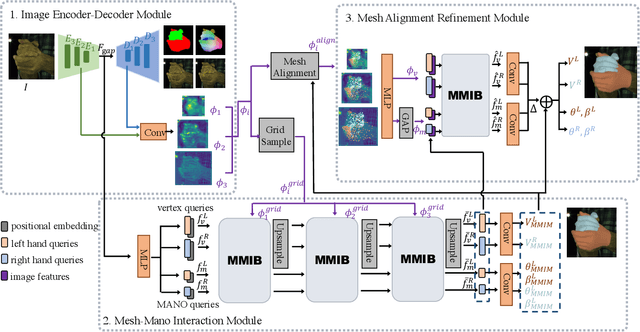
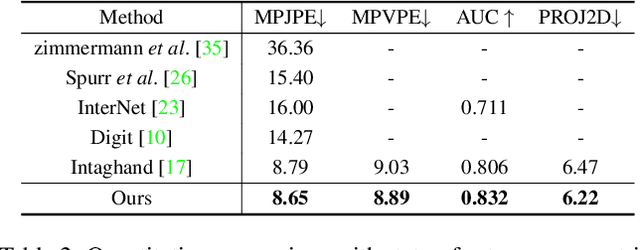
Existing methods proposed for hand reconstruction tasks usually parameterize a generic 3D hand model or predict hand mesh positions directly. The parametric representations consisting of hand shapes and rotational poses are more stable, while the non-parametric methods can predict more accurate mesh positions. In this paper, we propose to reconstruct meshes and estimate MANO parameters of two hands from a single RGB image simultaneously to utilize the merits of two kinds of hand representations. To fulfill this target, we propose novel Mesh-Mano interaction blocks (MMIBs), which take mesh vertices positions and MANO parameters as two kinds of query tokens. MMIB consists of one graph residual block to aggregate local information and two transformer encoders to model long-range dependencies. The transformer encoders are equipped with different asymmetric attention masks to model the intra-hand and inter-hand attention, respectively. Moreover, we introduce the mesh alignment refinement module to further enhance the mesh-image alignment. Extensive experiments on the InterHand2.6M benchmark demonstrate promising results over the state-of-the-art hand reconstruction methods.
AToMiC: An Image/Text Retrieval Test Collection to Support Multimedia Content Creation
Apr 04, 2023
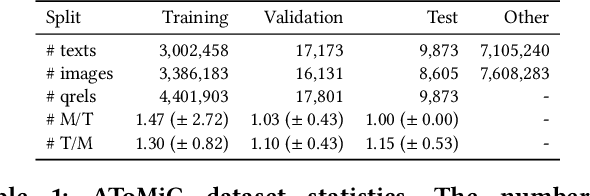
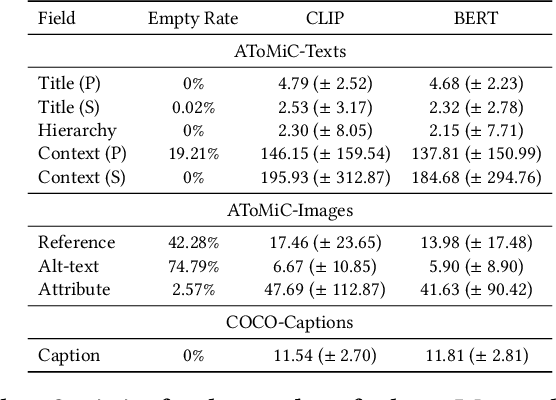
This paper presents the AToMiC (Authoring Tools for Multimedia Content) dataset, designed to advance research in image/text cross-modal retrieval. While vision-language pretrained transformers have led to significant improvements in retrieval effectiveness, existing research has relied on image-caption datasets that feature only simplistic image-text relationships and underspecified user models of retrieval tasks. To address the gap between these oversimplified settings and real-world applications for multimedia content creation, we introduce a new approach for building retrieval test collections. We leverage hierarchical structures and diverse domains of texts, styles, and types of images, as well as large-scale image-document associations embedded in Wikipedia. We formulate two tasks based on a realistic user model and validate our dataset through retrieval experiments using baseline models. AToMiC offers a testbed for scalable, diverse, and reproducible multimedia retrieval research. Finally, the dataset provides the basis for a dedicated track at the 2023 Text Retrieval Conference (TREC), and is publicly available at https://github.com/TREC-AToMiC/AToMiC.
Toward Fairness Through Fair Multi-Exit Framework for Dermatological Disease Diagnosis
Jul 01, 2023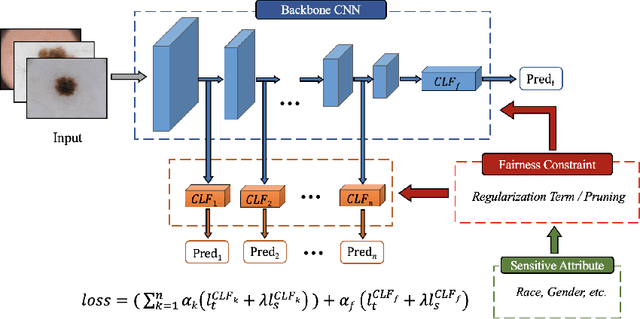
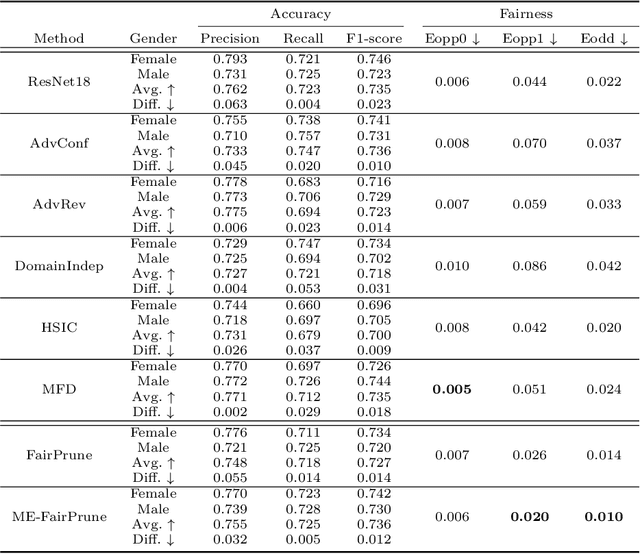
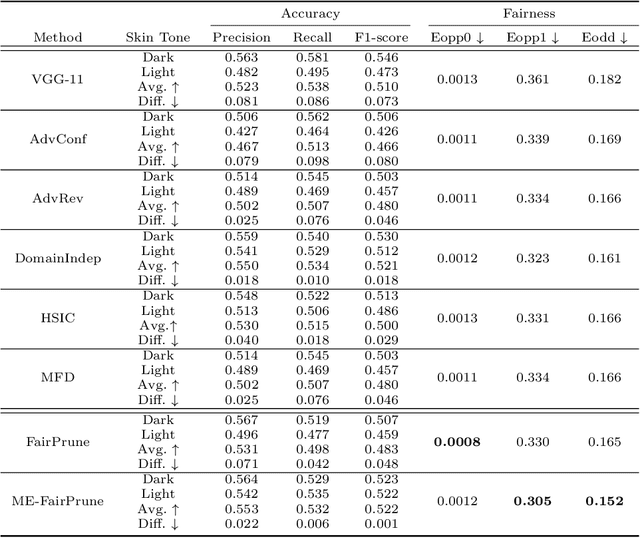
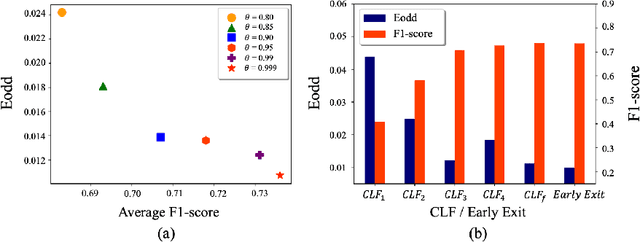
Fairness has become increasingly pivotal in medical image recognition. However, without mitigating bias, deploying unfair medical AI systems could harm the interests of underprivileged populations. In this paper, we observe that while features extracted from the deeper layers of neural networks generally offer higher accuracy, fairness conditions deteriorate as we extract features from deeper layers. This phenomenon motivates us to extend the concept of multi-exit frameworks. Unlike existing works mainly focusing on accuracy, our multi-exit framework is fairness-oriented; the internal classifiers are trained to be more accurate and fairer, with high extensibility to apply to most existing fairness-aware frameworks. During inference, any instance with high confidence from an internal classifier is allowed to exit early. Experimental results show that the proposed framework can improve the fairness condition over the state-of-the-art in two dermatological disease datasets.
PDS-MAR: a fine-grained Projection-Domain Segmentation-based Metal Artifact Reduction method for intraoperative CBCT images with guidewires
Jun 21, 2023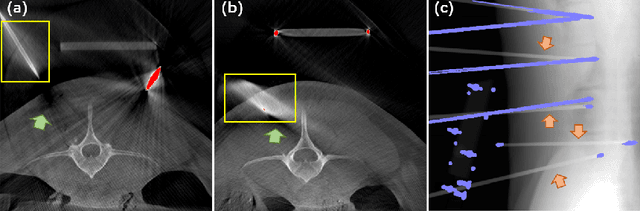

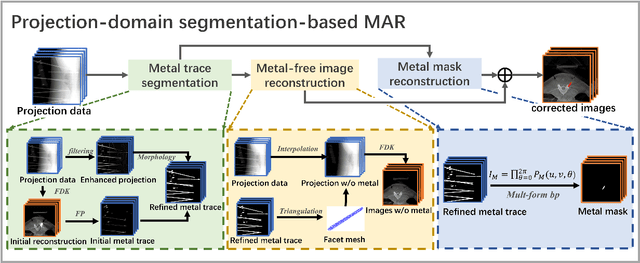
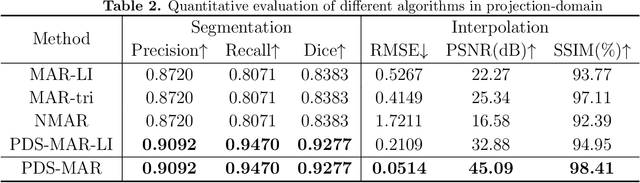
Since the invention of modern CT systems, metal artifacts have been a persistent problem. Due to increased scattering, amplified noise, and insufficient data collection, it is more difficult to suppress metal artifacts in cone-beam CT, limiting its use in human- and robot-assisted spine surgeries where metallic guidewires and screws are commonly used. In this paper, we demonstrate that conventional image-domain segmentation-based MAR methods are unable to eliminate metal artifacts for intraoperative CBCT images with guidewires. To solve this problem, we present a fine-grained projection-domain segmentation-based MAR method termed PDS-MAR, in which metal traces are augmented and segmented in the projection domain before being inpainted using triangular interpolation. In addition, a metal reconstruction phase is proposed to restore metal areas in the image domain. The digital phantom study and real CBCT data study demonstrate that the proposed algorithm achieves significantly better artifact suppression than other comparing methods and has the potential to advance the use of intraoperative CBCT imaging in clinical spine surgeries.
AxonCallosumEM Dataset: Axon Semantic Segmentation of Whole Corpus Callosum cross section from EM Images
Jul 05, 2023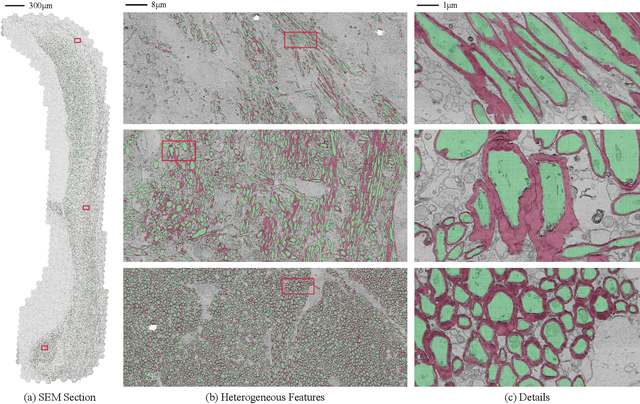
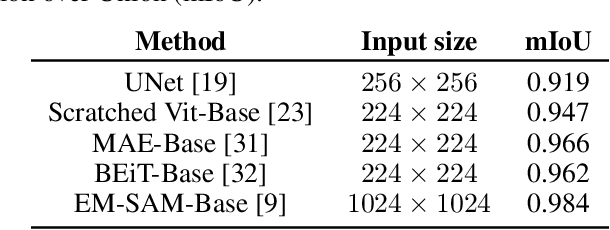
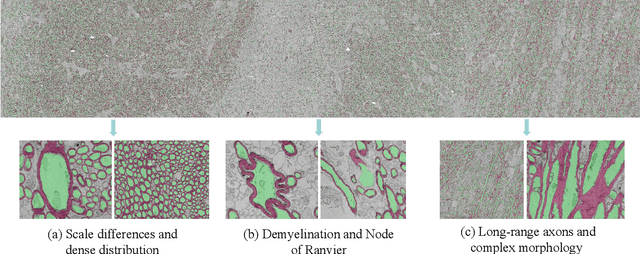
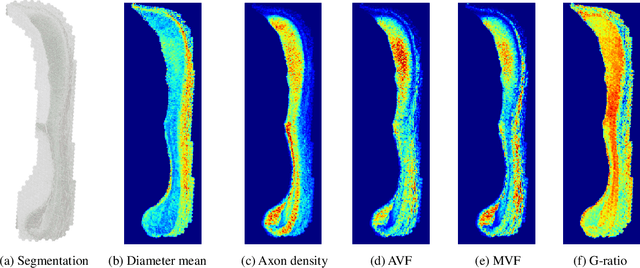
The electron microscope (EM) remains the predominant technique for elucidating intricate details of the animal nervous system at the nanometer scale. However, accurately reconstructing the complex morphology of axons and myelin sheaths poses a significant challenge. Furthermore, the absence of publicly available, large-scale EM datasets encompassing complete cross sections of the corpus callosum, with dense ground truth segmentation for axons and myelin sheaths, hinders the advancement and evaluation of holistic corpus callosum reconstructions. To surmount these obstacles, we introduce the AxonCallosumEM dataset, comprising a 1.83 times 5.76mm EM image captured from the corpus callosum of the Rett Syndrome (RTT) mouse model, which entail extensive axon bundles. We meticulously proofread over 600,000 patches at a resolution of 1024 times 1024, thus providing a comprehensive ground truth for myelinated axons and myelin sheaths. Additionally, we extensively annotated three distinct regions within the dataset for the purposes of training, testing, and validation. Utilizing this dataset, we develop a fine-tuning methodology that adapts Segment Anything Model (SAM) to EM images segmentation tasks, called EM-SAM, enabling outperforms other state-of-the-art methods. Furthermore, we present the evaluation results of EM-SAM as a baseline.