 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Masked Contrastive Graph Representation Learning for Age Estimation
Jun 16, 2023

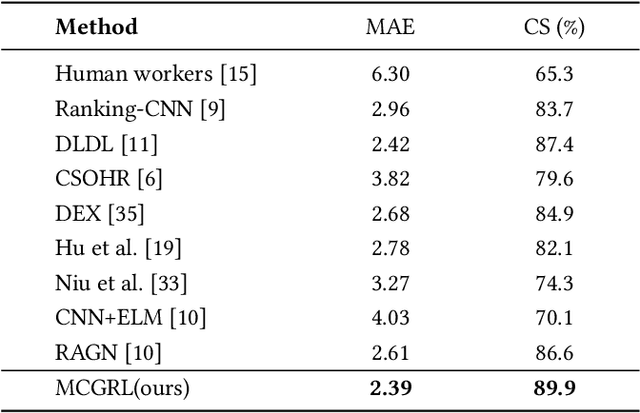

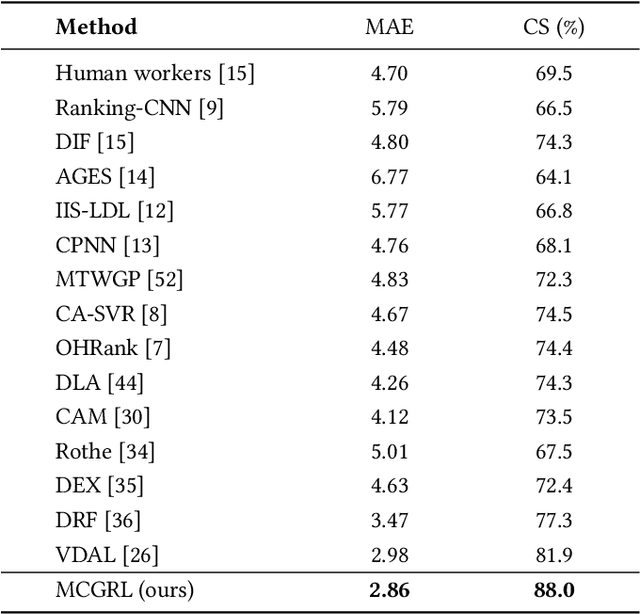
Age estimation of face images is a crucial task with various practical applications in areas such as video surveillance and Internet access control. While deep learning-based age estimation frameworks, e.g., convolutional neural network (CNN), multi-layer perceptrons (MLP), and transformers have shown remarkable performance, they have limitations when modelling complex or irregular objects in an image that contains a large amount of redundant information. To address this issue, this paper utilizes the robustness property of graph representation learning in dealing with image redundancy information and proposes a novel Masked Contrastive Graph Representation Learning (MCGRL) method for age estimation. Specifically, our approach first leverages CNN to extract semantic features of the image, which are then partitioned into patches that serve as nodes in the graph. Then, we use a masked graph convolutional network (GCN) to derive image-based node representations that capture rich structural information. Finally, we incorporate multiple losses to explore the complementary relationship between structural information and semantic features, which improves the feature representation capability of GCN. Experimental results on real-world face image datasets demonstrate the superiority of our proposed method over other state-of-the-art age estimation approaches.
Realistic Restorer: artifact-free flow restorer(AF2R) for MRI motion artifact removal
Jun 19, 2023Motion artifact is a major challenge in magnetic resonance imaging (MRI) that severely degrades image quality, reduces examination efficiency, and makes accurate diagnosis difficult. However, previous methods often relied on implicit models for artifact correction, resulting in biases in modeling the artifact formation mechanism and characterizing the relationship between artifact information and anatomical details. These limitations have hindered the ability to obtain high-quality MR images. In this work, we incorporate the artifact generation mechanism to reestablish the relationship between artifacts and anatomical content in the image domain, highlighting the superiority of explicit models over implicit models in medical problems. Based on this, we propose a novel end-to-end image domain model called AF2R, which addresses this problem using conditional normalization flow. Specifically, we first design a feature encoder to extract anatomical features from images with motion artifacts. Then, through a series of reversible transformations using the feature-to-image flow module, we progressively obtain MR images unaffected by motion artifacts. Experimental results on simulated and real datasets demonstrate that our method achieves better performance in both quantitative and qualitative results, preserving better anatomical details.
Stochastic Light Field Holography
Jul 12, 2023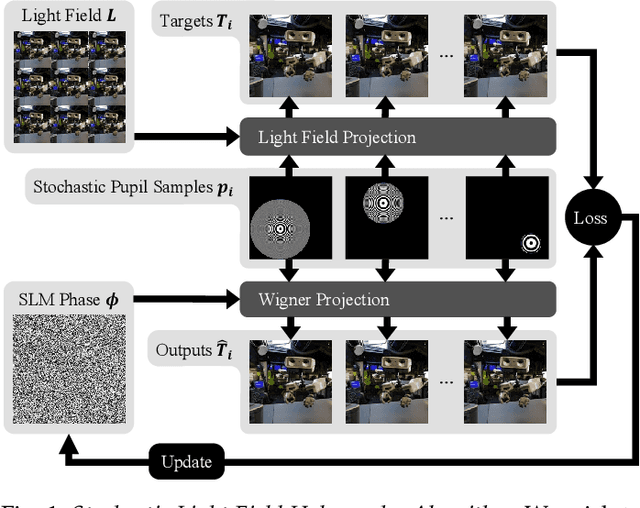


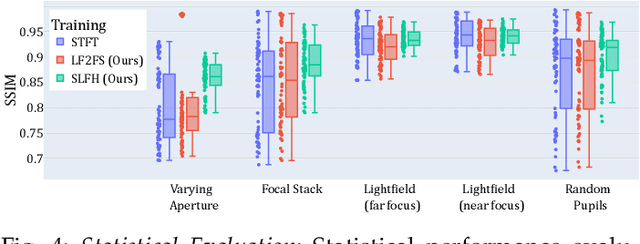
The Visual Turing Test is the ultimate goal to evaluate the realism of holographic displays. Previous studies have focused on addressing challenges such as limited \'etendue and image quality over a large focal volume, but they have not investigated the effect of pupil sampling on the viewing experience in full 3D holograms. In this work, we tackle this problem with a novel hologram generation algorithm motivated by matching the projection operators of incoherent Light Field and coherent Wigner Function light transport. To this end, we supervise hologram computation using synthesized photographs, which are rendered on-the-fly using Light Field refocusing from stochastically sampled pupil states during optimization. The proposed method produces holograms with correct parallax and focus cues, which are important for passing the Visual Turing Test. We validate that our approach compares favorably to state-of-the-art CGH algorithms that use Light Field and Focal Stack supervision. Our experiments demonstrate that our algorithm significantly improves the realism of the viewing experience for a variety of different pupil states.
Evaluating Adversarial Robustness on Document Image Classification
Apr 24, 2023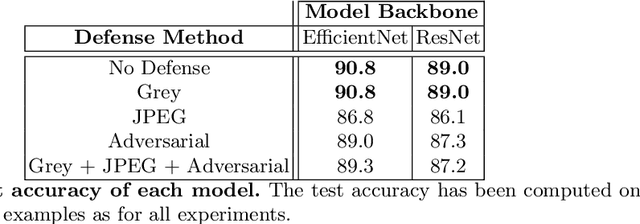

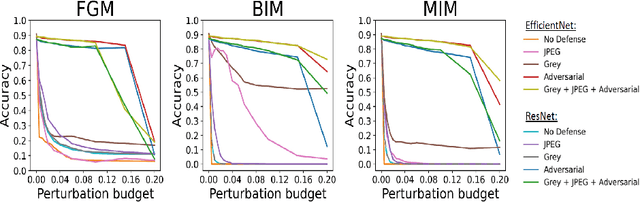
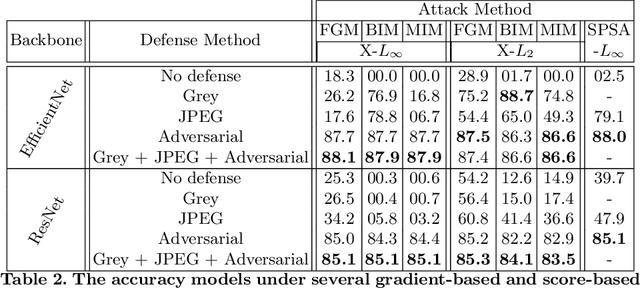
Adversarial attacks and defenses have gained increasing interest on computer vision systems in recent years, but as of today, most investigations are limited to images. However, many artificial intelligence models actually handle documentary data, which is very different from real world images. Hence, in this work, we try to apply the adversarial attack philosophy on documentary and natural data and to protect models against such attacks. We focus our work on untargeted gradient-based, transfer-based and score-based attacks and evaluate the impact of adversarial training, JPEG input compression and grey-scale input transformation on the robustness of ResNet50 and EfficientNetB0 model architectures. To the best of our knowledge, no such work has been conducted by the community in order to study the impact of these attacks on the document image classification task.
Restormer-Plus for Real World Image Deraining: One State-of-the-Art Solution to the GT-RAIN Challenge (CVPR 2023 UG$^2$+ Track 3)
May 11, 2023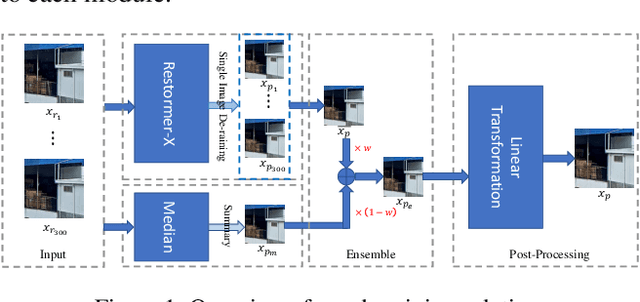

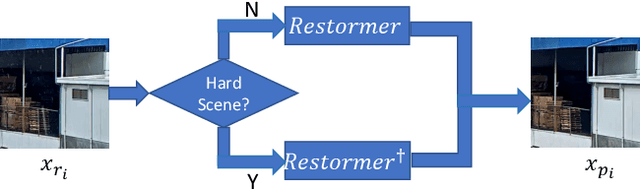

This technical report presents our Restormer-Plus approach, which was submitted to the GT-RAIN Challenge (CVPR 2023 UG$^2$+ Track 3). Details regarding the challenge are available at http://cvpr2023.ug2challenge.org/track3.html. Our Restormer-Plus outperformed all other submitted solutions in terms of peak signal-to-noise ratio (PSNR). It consists mainly of four modules: the single image de-raining module, the median filtering module, the weighted averaging module, and the post-processing module. We named the single-image de-raining module Restormer-X, which is built on Restormer and performed on each rainy image. The median filtering module is employed as a median operator for the 300 rainy images associated with each scene. The weighted averaging module combines the median filtering results with that of Restormer-X to alleviate overfitting if we only use Restormer-X. Finally, the post-processing module is used to improve the brightness restoration. Together, these modules render Restormer-Plus to be one state-of-the-art solution to the GT-RAIN Challenge. Our code is available at https://github.com/ZJLAB-AMMI/Restormer-Plus.
Introduction to Facial Micro Expressions Analysis Using Color and Depth Images: A Matlab Coding Approach (Second Edition, 2023)
Jun 19, 2023
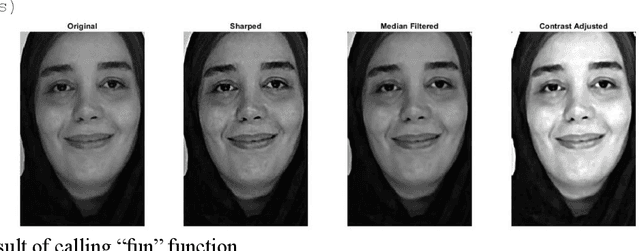
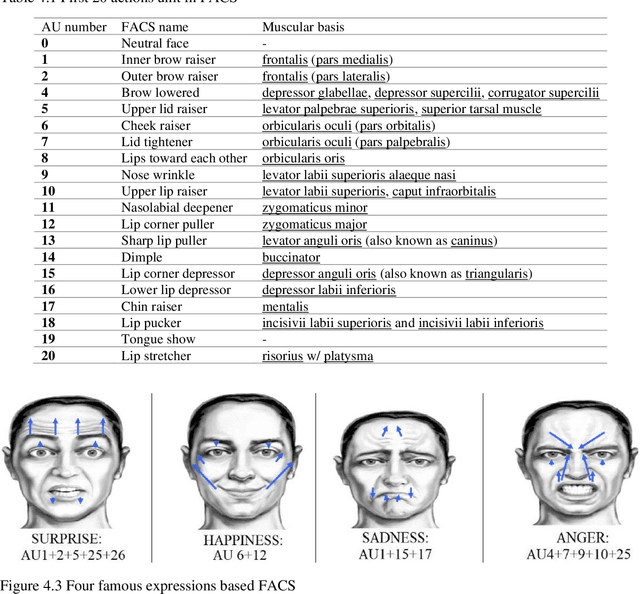
The book attempts to introduce a gentle introduction to the field of Facial Micro Expressions Recognition (FMER) using Color and Depth images, with the aid of MATLAB programming environment. FMER is a subset of image processing and it is a multidisciplinary topic to analysis. So, it requires familiarity with other topics of Artifactual Intelligence (AI) such as machine learning, digital image processing, psychology and more. So, it is a great opportunity to write a book which covers all of these topics for beginner to professional readers in the field of AI and even without having background of AI. Our goal is to provide a standalone introduction in the field of MFER analysis in the form of theorical descriptions for readers with no background in image processing with reproducible Matlab practical examples. Also, we describe any basic definitions for FMER analysis and MATLAB library which is used in the text, that helps final reader to apply the experiments in the real-world applications. We believe that this book is suitable for students, researchers, and professionals alike, who need to develop practical skills, along with a basic understanding of the field. We expect that, after reading this book, the reader feels comfortable with different key stages such as color and depth image processing, color and depth image representation, classification, machine learning, facial micro-expressions recognition, feature extraction and dimensionality reduction. The book attempts to introduce a gentle introduction to the field of Facial Micro Expressions Recognition (FMER) using Color and Depth images, with the aid of MATLAB programming environment.
Detection of Adversarial Physical Attacks in Time-Series Image Data
Apr 27, 2023

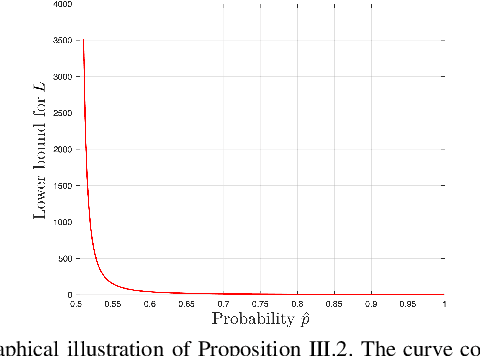
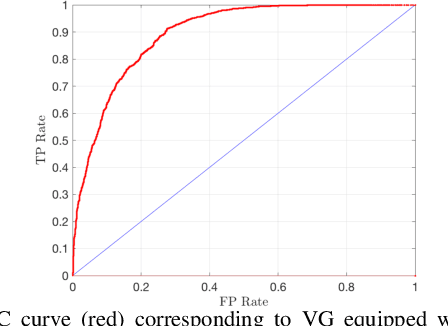
Deep neural networks (DNN) have become a common sensing modality in autonomous systems as they allow for semantically perceiving the ambient environment given input images. Nevertheless, DNN models have proven to be vulnerable to adversarial digital and physical attacks. To mitigate this issue, several detection frameworks have been proposed to detect whether a single input image has been manipulated by adversarial digital noise or not. In our prior work, we proposed a real-time detector, called VisionGuard (VG), for adversarial physical attacks against single input images to DNN models. Building upon that work, we propose VisionGuard* (VG), which couples VG with majority-vote methods, to detect adversarial physical attacks in time-series image data, e.g., videos. This is motivated by autonomous systems applications where images are collected over time using onboard sensors for decision-making purposes. We emphasize that majority-vote mechanisms are quite common in autonomous system applications (among many other applications), as e.g., in autonomous driving stacks for object detection. In this paper, we investigate, both theoretically and experimentally, how this widely used mechanism can be leveraged to enhance the performance of adversarial detectors. We have evaluated VG* on videos of both clean and physically attacked traffic signs generated by a state-of-the-art robust physical attack. We provide extensive comparative experiments against detectors that have been designed originally for out-of-distribution data and digitally attacked images.
Regularized Shallow Image Prior for Electrical Impedance Tomography
Mar 30, 2023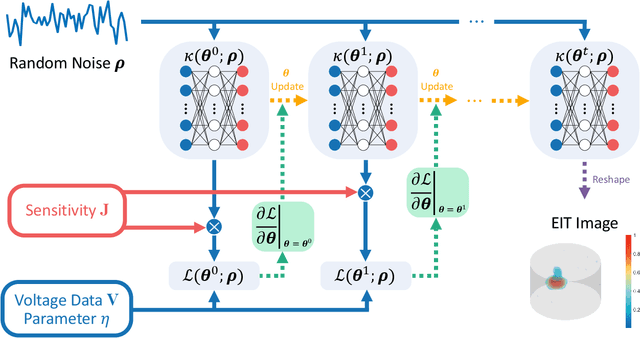
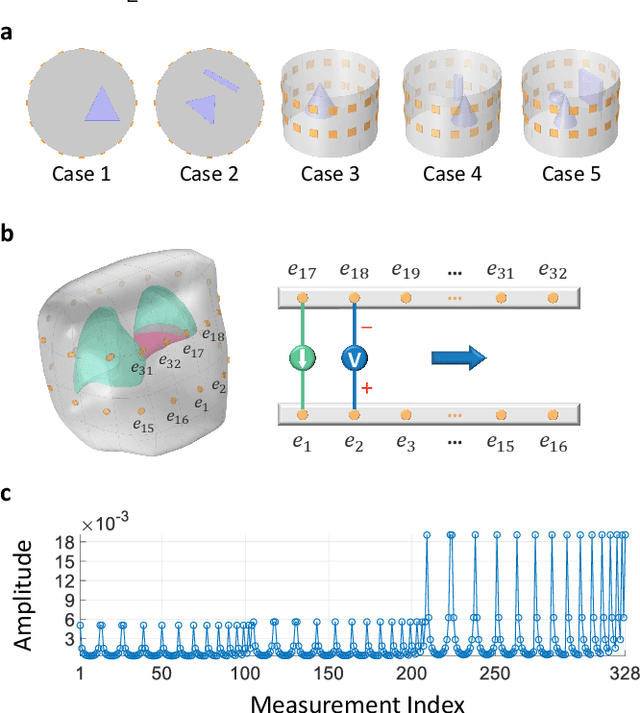
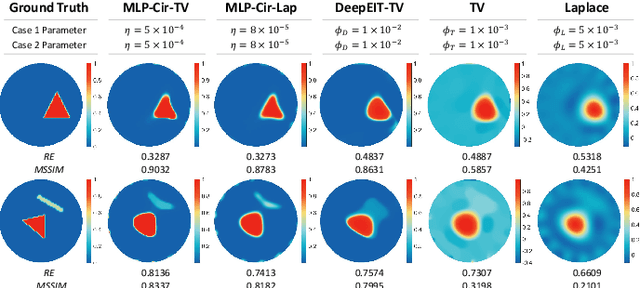
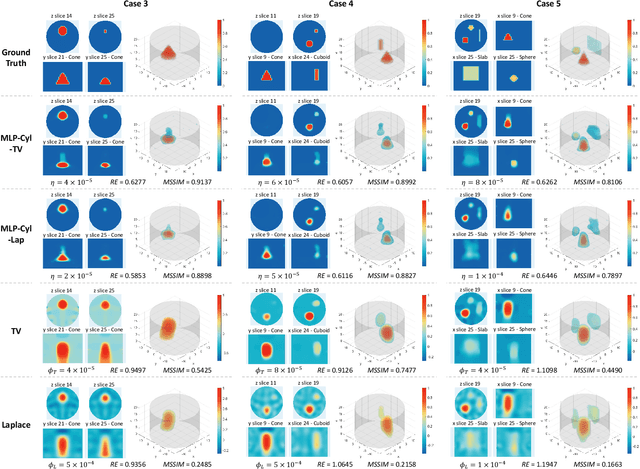
Untrained Neural Network Prior (UNNP) based algorithms have gained increasing popularity in tomographic imaging, as they offer superior performance compared to hand-crafted priors and do not require training. UNNP-based methods usually rely on deep architectures which are known for their excellent feature extraction ability compared to shallow ones. Contrary to common UNNP-based approaches, we propose a regularized shallow image prior method that combines UNNP with hand-crafted prior for Electrical Impedance Tomography (EIT). Our approach employs a 3-layer Multi-Layer Perceptron (MLP) as the UNNP in regularizing 2D and 3D EIT inversion. We demonstrate the influence of two typical hand-crafted regularizations when representing the conductivity distribution with shallow MLPs. We show considerably improved EIT image quality compared to conventional regularization algorithms, especially in structure preservation. The results suggest that combining the shallow image prior and the hand-crafted regularization can achieve similar performance to the Deep Image Prior (DIP) but with less architectural dependency and complexity of the neural network.
Deep learning-based deconvolution for interferometric radio transient reconstruction
Jun 24, 2023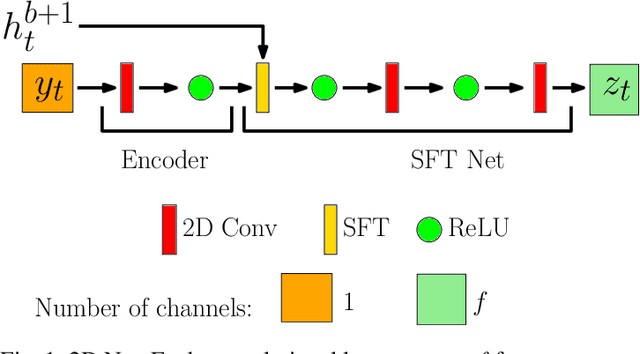
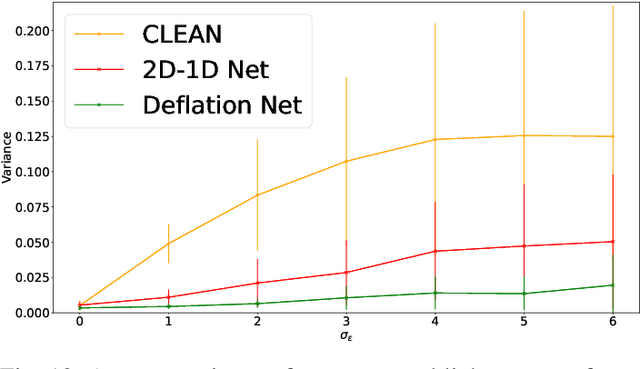
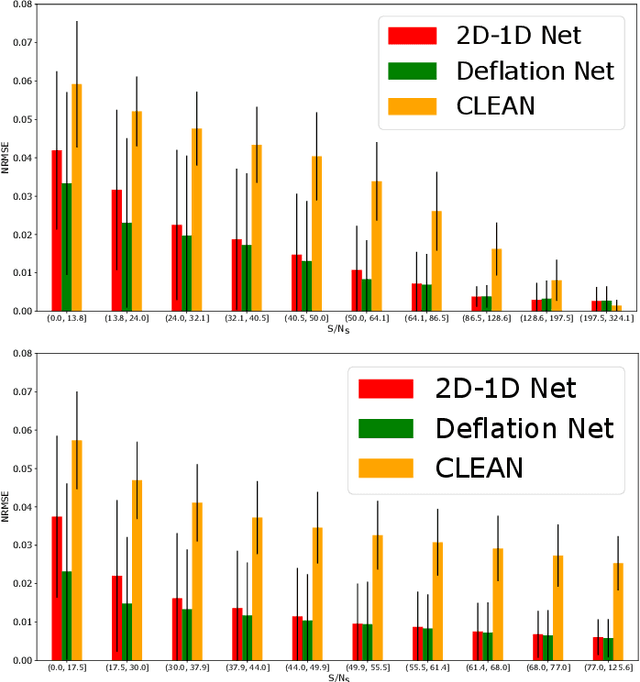
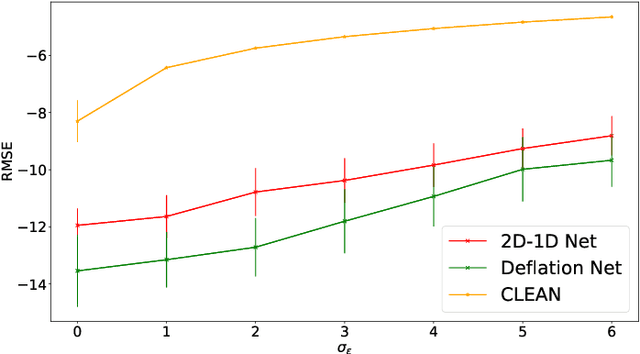
Radio astronomy is currently thriving with new large ground-based radio telescopes coming online in preparation for the upcoming Square Kilometre Array (SKA). Facilities like LOFAR, MeerKAT/SKA, ASKAP/SKA, and the future SKA-LOW bring tremendous sensitivity in time and frequency, improved angular resolution, and also high-rate data streams that need to be processed. They enable advanced studies of radio transients, volatile by nature, that can be detected or missed in the data. These transients are markers of high-energy accelerations of electrons and manifest in a wide range of temporal scales. Usually studied with dynamic spectroscopy of time series analysis, there is a motivation to search for such sources in large interferometric datasets. This requires efficient and robust signal reconstruction algorithms. To correctly account for the temporal dependency of the data, we improve the classical image deconvolution inverse problem by adding the temporal dependency in the reconstruction problem. Then, we introduce two novel neural network architectures that can do both spatial and temporal modeling of the data and the instrumental response. Then, we simulate representative time-dependent image cubes of point source distributions and realistic telescope pointings of MeerKAT to generate toy models to build the training, validation, and test datasets. Finally, based on the test data, we evaluate the source profile reconstruction performance of the proposed methods and classical image deconvolution algorithm CLEAN applied frame-by-frame. In the presence of increasing noise level in data frame, the proposed methods display a high level of robustness compared to frame-by-frame imaging with CLEAN. The deconvolved image cubes bring a factor of 3 improvement in fidelity of the recovered temporal profiles and a factor of 2 improvement in background denoising.
Correlational Image Modeling for Self-Supervised Visual Pre-Training
Mar 30, 2023
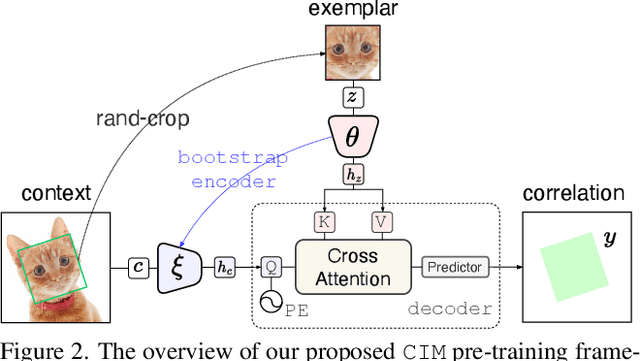
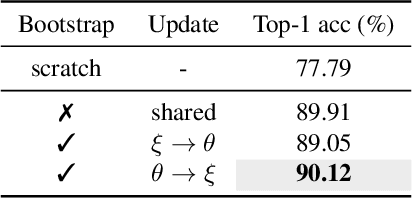

We introduce Correlational Image Modeling (CIM), a novel and surprisingly effective approach to self-supervised visual pre-training. Our CIM performs a simple pretext task: we randomly crop image regions (exemplars) from an input image (context) and predict correlation maps between the exemplars and the context. Three key designs enable correlational image modeling as a nontrivial and meaningful self-supervisory task. First, to generate useful exemplar-context pairs, we consider cropping image regions with various scales, shapes, rotations, and transformations. Second, we employ a bootstrap learning framework that involves online and target encoders. During pre-training, the former takes exemplars as inputs while the latter converts the context. Third, we model the output correlation maps via a simple cross-attention block, within which the context serves as queries and the exemplars offer values and keys. We show that CIM performs on par or better than the current state of the art on self-supervised and transfer benchmarks.