 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ViTEraser: Harnessing the Power of Vision Transformers for Scene Text Removal with SegMIM Pretraining
Jun 21, 2023
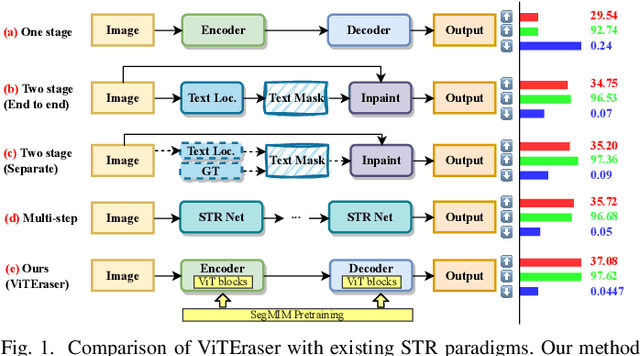

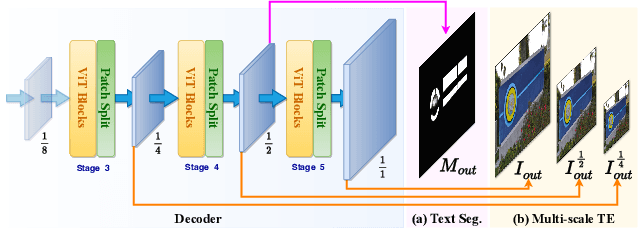

Scene text removal (STR) aims at replacing text strokes in natural scenes with visually coherent backgrounds. Recent STR approaches rely on iterative refinements or explicit text masks, resulting in higher complexity and sensitivity to the accuracy of text localization. Moreover, most existing STR methods utilize convolutional neural networks (CNNs) for feature representation while the potential of vision Transformers (ViTs) remains largely unexplored. In this paper, we propose a simple-yet-effective ViT-based text eraser, dubbed ViTEraser. Following a concise encoder-decoder framework, different types of ViTs can be easily integrated into ViTEraser to enhance the long-range dependencies and global reasoning. Specifically, the encoder hierarchically maps the input image into the hidden space through ViT blocks and patch embedding layers, while the decoder gradually upsamples the hidden features to the text-erased image with ViT blocks and patch splitting layers. As ViTEraser implicitly integrates text localization and inpainting, we propose a novel end-to-end pretraining method, termed SegMIM, which focuses the encoder and decoder on the text box segmentation and masked image modeling tasks, respectively. To verify the effectiveness of the proposed methods, we comprehensively explore the architecture, pretraining, and scalability of the ViT-based encoder-decoder for STR, which provides deep insights into the application of ViT to STR. Experimental results demonstrate that ViTEraser with SegMIM achieves state-of-the-art performance on STR by a substantial margin. Furthermore, the extended experiment on tampered scene text detection demonstrates the generality of ViTEraser to other tasks. We believe this paper can inspire more research on ViT-based STR approaches. Code will be available at https://github.com/shannanyinxiang/ViTEraser.
It is all about where you start: Text-to-image generation with seed selection
Apr 27, 2023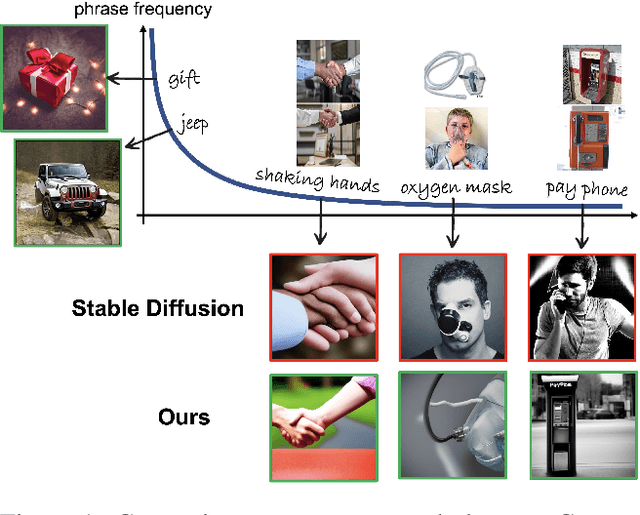
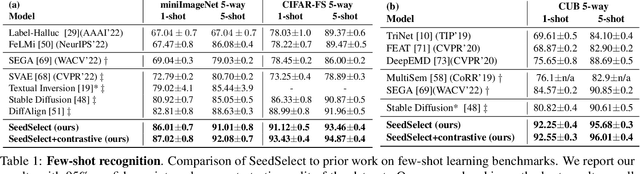
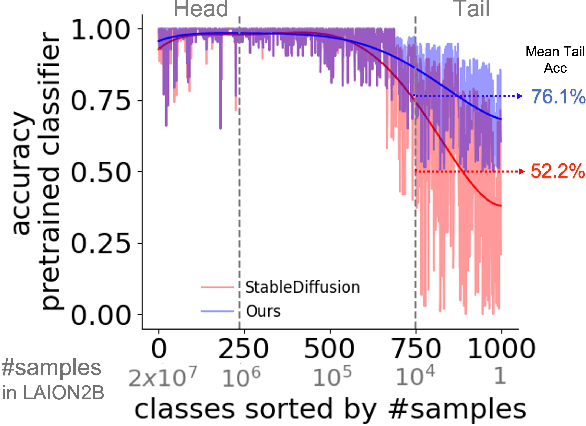
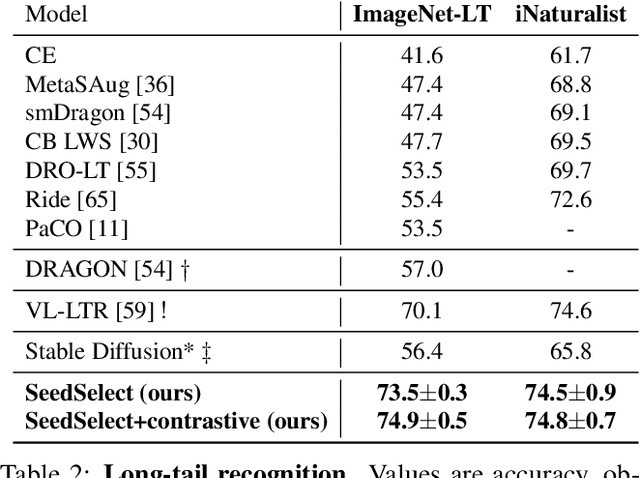
Text-to-image diffusion models can synthesize a large variety of concepts in new compositions and scenarios. However, they still struggle with generating uncommon concepts, rare unusual combinations, or structured concepts like hand palms. Their limitation is partly due to the long-tail nature of their training data: web-crawled data sets are strongly unbalanced, causing models to under-represent concepts from the tail of the distribution. Here we characterize the effect of unbalanced training data on text-to-image models and offer a remedy. We show that rare concepts can be correctly generated by carefully selecting suitable generation seeds in the noise space, a technique that we call SeedSelect. SeedSelect is efficient and does not require retraining the diffusion model. We evaluate the benefit of SeedSelect on a series of problems. First, in few-shot semantic data augmentation, where we generate semantically correct images for few-shot and long-tail benchmarks. We show classification improvement on all classes, both from the head and tail of the training data of diffusion models. We further evaluate SeedSelect on correcting images of hands, a well-known pitfall of current diffusion models, and show that it improves hand generation substantially.
Joint Salient Object Detection and Camouflaged Object Detection via Uncertainty-aware Learning
Jul 10, 2023
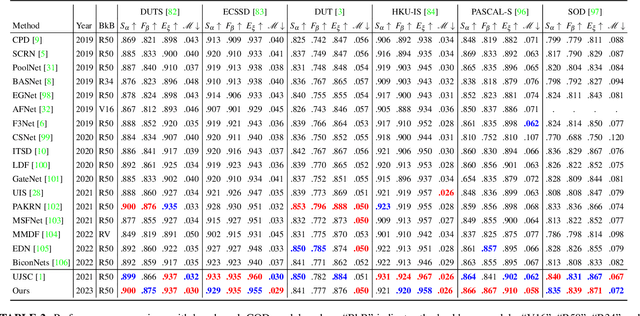

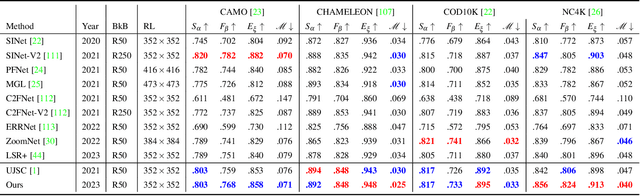
Salient objects attract human attention and usually stand out clearly from their surroundings. In contrast, camouflaged objects share similar colors or textures with the environment. In this case, salient objects are typically non-camouflaged, and camouflaged objects are usually not salient. Due to this inherent contradictory attribute, we introduce an uncertainty-aware learning pipeline to extensively explore the contradictory information of salient object detection (SOD) and camouflaged object detection (COD) via data-level and task-wise contradiction modeling. We first exploit the dataset correlation of these two tasks and claim that the easy samples in the COD dataset can serve as hard samples for SOD to improve the robustness of the SOD model. Based on the assumption that these two models should lead to activation maps highlighting different regions of the same input image, we further introduce a contrastive module with a joint-task contrastive learning framework to explicitly model the contradictory attributes of these two tasks. Different from conventional intra-task contrastive learning for unsupervised representation learning, our contrastive module is designed to model the task-wise correlation, leading to cross-task representation learning. To better understand the two tasks from the perspective of uncertainty, we extensively investigate the uncertainty estimation techniques for modeling the main uncertainties of the two tasks, namely task uncertainty (for SOD) and data uncertainty (for COD), and aiming to effectively estimate the challenging regions for each task to achieve difficulty-aware learning. Experimental results on benchmark datasets demonstrate that our solution leads to both state-of-the-art performance and informative uncertainty estimation.
Unsupervised augmentation optimization for few-shot medical image segmentation
Jun 08, 2023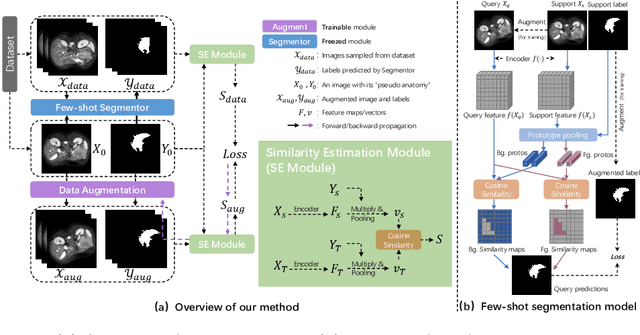
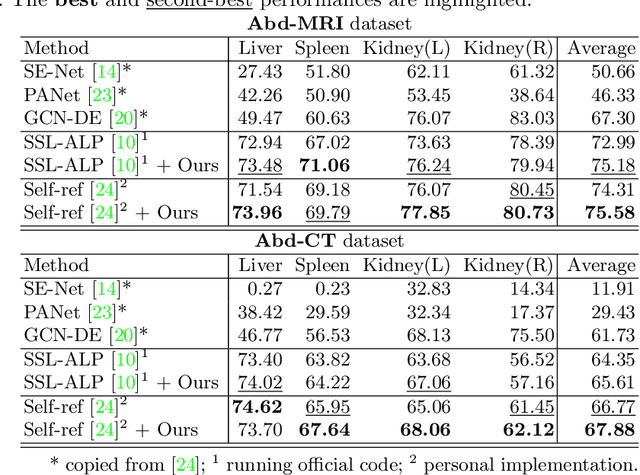
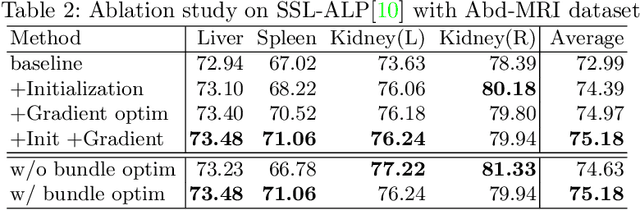
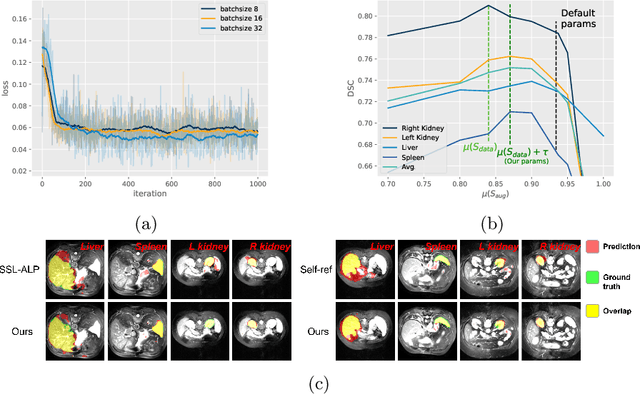
The augmentation parameters matter to few-shot semantic segmentation since they directly affect the training outcome by feeding the networks with varying perturbated samples. However, searching optimal augmentation parameters for few-shot segmentation models without annotations is a challenge that current methods fail to address. In this paper, we first propose a framework to determine the ``optimal'' parameters without human annotations by solving a distribution-matching problem between the intra-instance and intra-class similarity distribution, with the intra-instance similarity describing the similarity between the original sample of a particular anatomy and its augmented ones and the intra-class similarity representing the similarity between the selected sample and the others in the same class. Extensive experiments demonstrate the superiority of our optimized augmentation in boosting few-shot segmentation models. We greatly improve the top competing method by 1.27\% and 1.11\% on Abd-MRI and Abd-CT datasets, respectively, and even achieve a significant improvement for SSL-ALP on the left kidney by 3.39\% on the Abd-CT dataset.
Detecting the Sensing Area of A Laparoscopic Probe in Minimally Invasive Cancer Surgery
Jul 07, 2023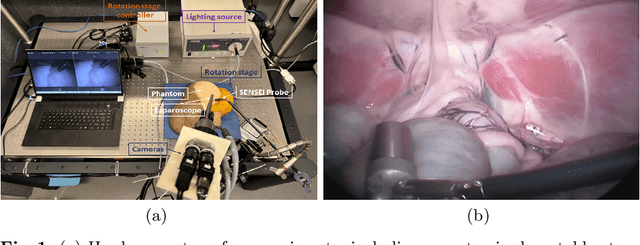
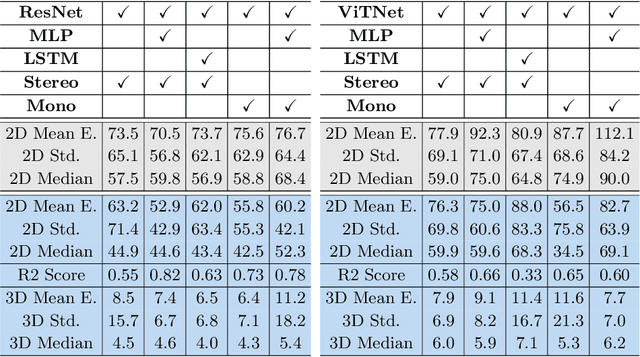


In surgical oncology, it is challenging for surgeons to identify lymph nodes and completely resect cancer even with pre-operative imaging systems like PET and CT, because of the lack of reliable intraoperative visualization tools. Endoscopic radio-guided cancer detection and resection has recently been evaluated whereby a novel tethered laparoscopic gamma detector is used to localize a preoperatively injected radiotracer. This can both enhance the endoscopic imaging and complement preoperative nuclear imaging data. However, gamma activity visualization is challenging to present to the operator because the probe is non-imaging and it does not visibly indicate the activity origination on the tissue surface. Initial failed attempts used segmentation or geometric methods, but led to the discovery that it could be resolved by leveraging high-dimensional image features and probe position information. To demonstrate the effectiveness of this solution, we designed and implemented a simple regression network that successfully addressed the problem. To further validate the proposed solution, we acquired and publicly released two datasets captured using a custom-designed, portable stereo laparoscope system. Through intensive experimentation, we demonstrated that our method can successfully and effectively detect the sensing area, establishing a new performance benchmark. Code and data are available at https://github.com/br0202/Sensing_area_detection.git
RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
Jun 19, 2023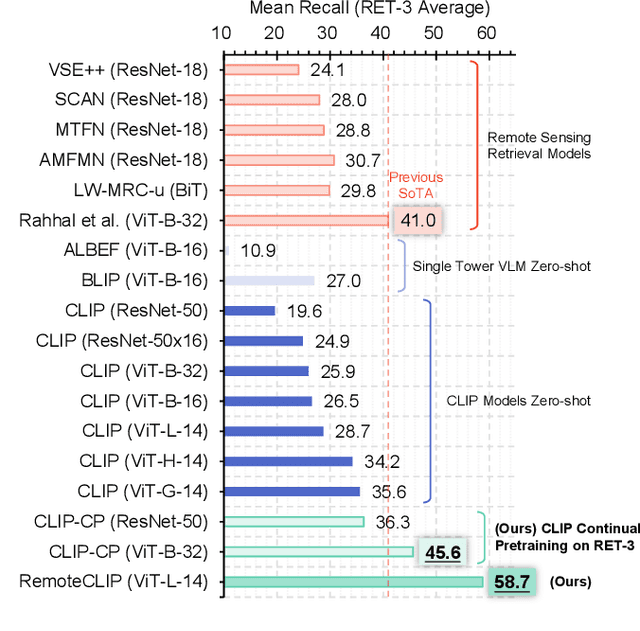

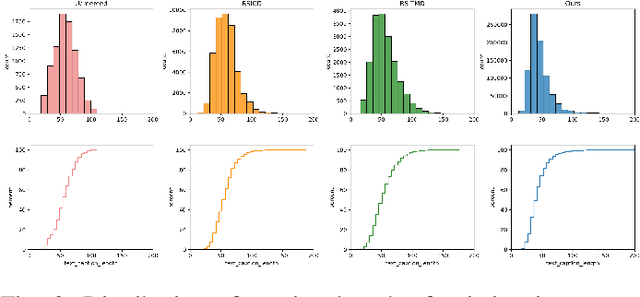

General-purpose foundation models have become increasingly important in the field of artificial intelligence. While self-supervised learning (SSL) and Masked Image Modeling (MIM) have led to promising results in building such foundation models for remote sensing, these models primarily learn low-level features, require annotated data for fine-tuning, and not applicable for retrieval and zero-shot applications due to the lack of language understanding. In response to these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics, as well as aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling, converting heterogeneous annotations based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion, and further incorporating UAV imagery, resulting a 12xlarger pretraining dataset. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, k-NN classification, few-shot classification, image-text retrieval, and object counting. Evaluations on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, show that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP outperform previous SoTA by 9.14% mean recall on RSICD dataset and by 8.92% on RSICD dataset. For zero-shot classification, our RemoteCLIP outperform CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets.
Prompting classes: Exploring the Power of Prompt Class Learning in Weakly Supervised Semantic Segmentation
Jul 08, 2023
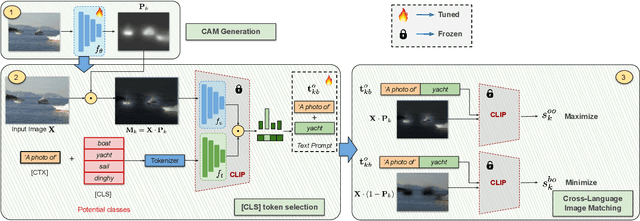
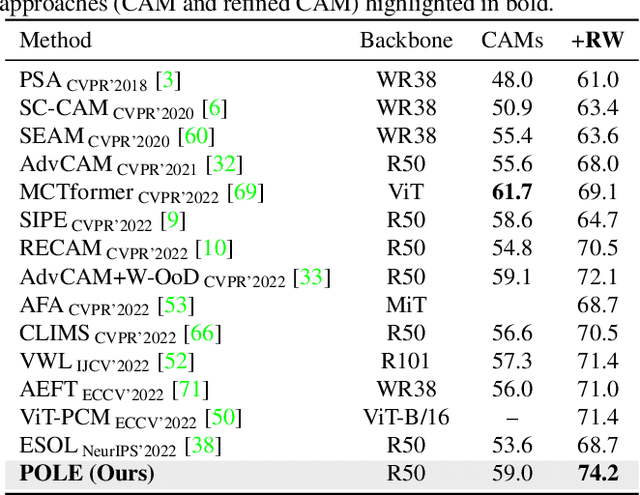
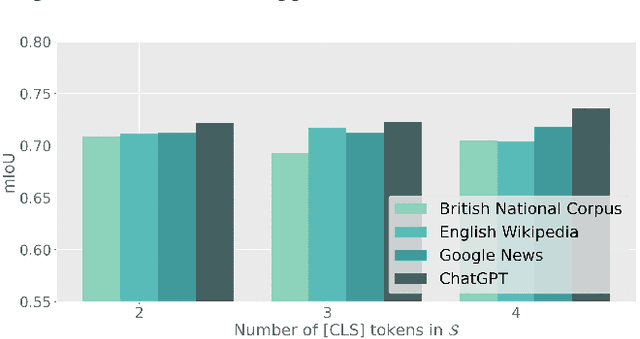
Recently, CLIP-based approaches have exhibited remarkable performance on generalization and few-shot learning tasks, fueled by the power of contrastive language-vision pre-training. In particular, prompt tuning has emerged as an effective strategy to adapt the pre-trained language-vision models to downstream tasks by employing task-related textual tokens. Motivated by this progress, in this work we question whether other fundamental problems, such as weakly supervised semantic segmentation (WSSS), can benefit from prompt tuning. Our findings reveal two interesting observations that shed light on the impact of prompt tuning on WSSS. First, modifying only the class token of the text prompt results in a greater impact on the Class Activation Map (CAM), compared to arguably more complex strategies that optimize the context. And second, the class token associated with the image ground truth does not necessarily correspond to the category that yields the best CAM. Motivated by these observations, we introduce a novel approach based on a PrOmpt cLass lEarning (POLE) strategy. Through extensive experiments we demonstrate that our simple, yet efficient approach achieves SOTA performance in a well-known WSSS benchmark. These results highlight not only the benefits of language-vision models in WSSS but also the potential of prompt learning for this problem. The code is available at https://github.com/rB080/WSS_POLE.
Neural Image-based Avatars: Generalizable Radiance Fields for Human Avatar Modeling
Apr 10, 2023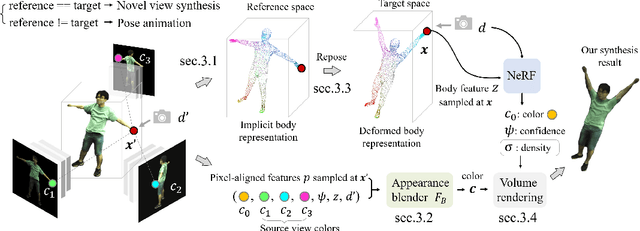
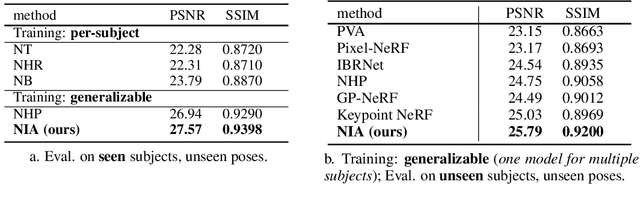


We present a method that enables synthesizing novel views and novel poses of arbitrary human performers from sparse multi-view images. A key ingredient of our method is a hybrid appearance blending module that combines the advantages of the implicit body NeRF representation and image-based rendering. Existing generalizable human NeRF methods that are conditioned on the body model have shown robustness against the geometric variation of arbitrary human performers. Yet they often exhibit blurry results when generalized onto unseen identities. Meanwhile, image-based rendering shows high-quality results when sufficient observations are available, whereas it suffers artifacts in sparse-view settings. We propose Neural Image-based Avatars (NIA) that exploits the best of those two methods: to maintain robustness under new articulations and self-occlusions while directly leveraging the available (sparse) source view colors to preserve appearance details of new subject identities. Our hybrid design outperforms recent methods on both in-domain identity generalization as well as challenging cross-dataset generalization settings. Also, in terms of the pose generalization, our method outperforms even the per-subject optimized animatable NeRF methods. The video results are available at https://youngjoongunc.github.io/nia
Increasing Textual Context Size Boosts Medical Image-Text Matching
Mar 23, 2023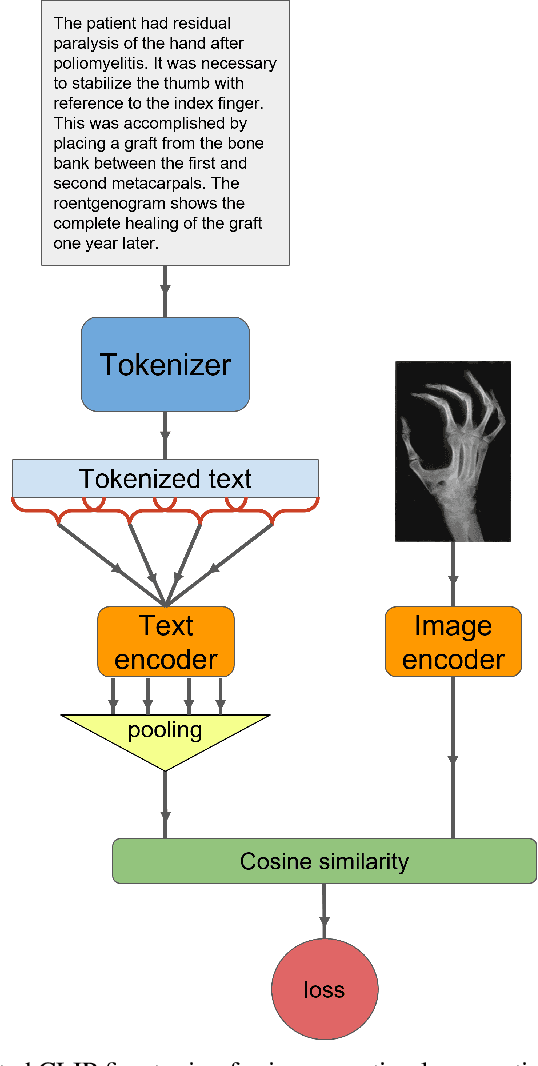
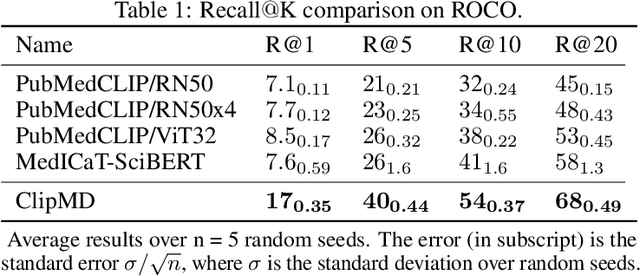
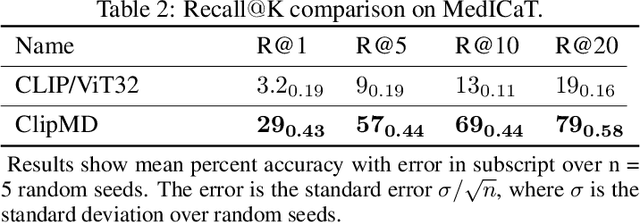
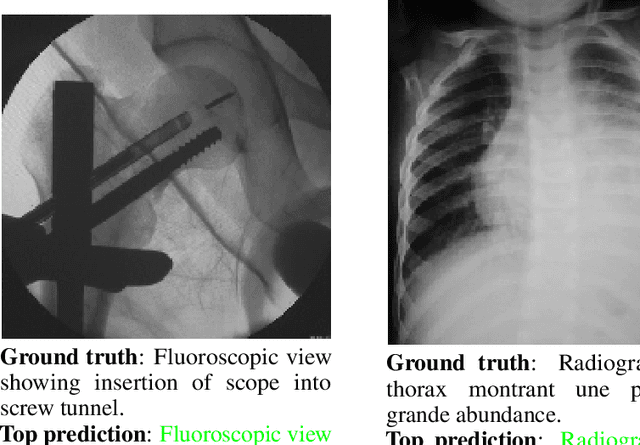
This short technical report demonstrates a simple technique that yields state of the art results in medical image-text matching tasks. We analyze the use of OpenAI's CLIP, a general image-text matching model, and observe that CLIP's limited textual input size has negative impact on downstream performance in the medical domain where encoding longer textual contexts is often required. We thus train and release ClipMD, which is trained with a simple sliding window technique to encode textual captions. ClipMD was tested on two medical image-text datasets and compared with other image-text matching models. The results show that ClipMD outperforms other models on both datasets by a large margin. We make our code and pretrained model publicly available.
ArtWhisperer: A Dataset for Characterizing Human-AI Interactions in Artistic Creations
Jun 13, 2023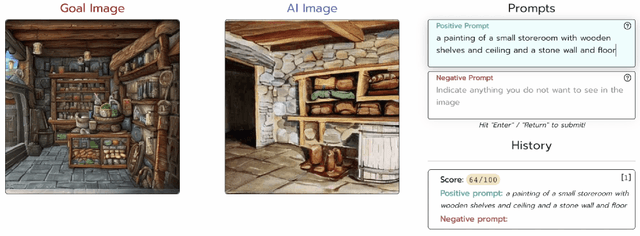
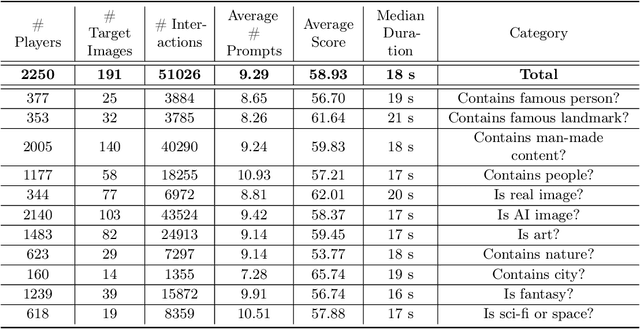
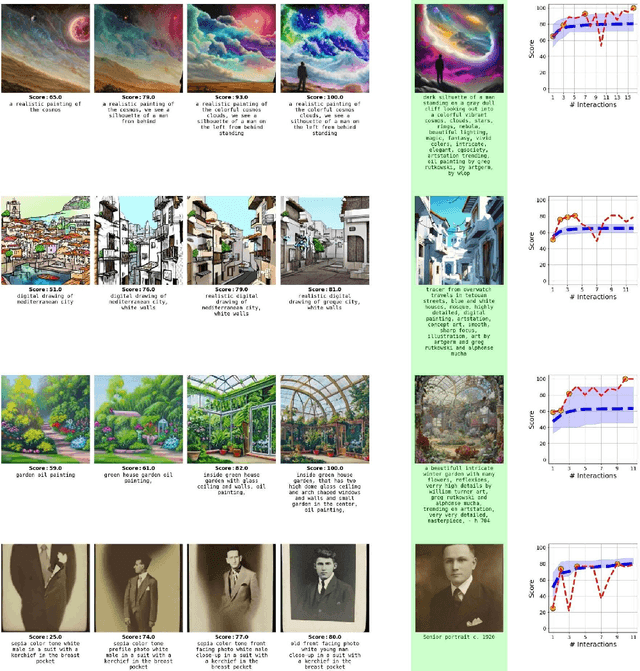
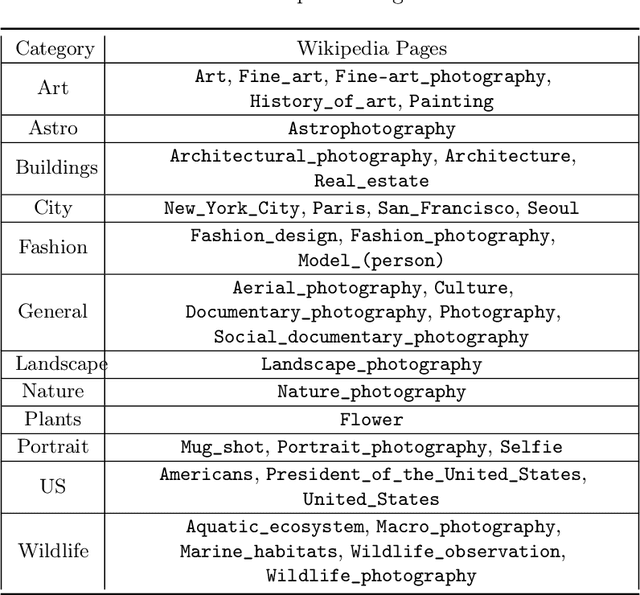
As generative AI becomes more prevalent, it is important to study how human users interact with such models. In this work, we investigate how people use text-to-image models to generate desired target images. To study this interaction, we created ArtWhisperer, an online game where users are given a target image and are tasked with iteratively finding a prompt that creates a similar-looking image as the target. Through this game, we recorded over 50,000 human-AI interactions; each interaction corresponds to one text prompt created by a user and the corresponding generated image. The majority of these are repeated interactions where a user iterates to find the best prompt for their target image, making this a unique sequential dataset for studying human-AI collaborations. In an initial analysis of this dataset, we identify several characteristics of prompt interactions and user strategies. People submit diverse prompts and are able to discover a variety of text descriptions that generate similar images. Interestingly, prompt diversity does not decrease as users find better prompts. We further propose to a new metric the study the steerability of AI using our dataset. We define steerability as the expected number of interactions required to adequately complete a task. We estimate this value by fitting a Markov chain for each target task and calculating the expected time to reach an adequate score in the Markov chain. We quantify and compare AI steerability across different types of target images and two different models, finding that images of cities and natural world images are more steerable than artistic and fantasy images. These findings provide insights into human-AI interaction behavior, present a concrete method of assessing AI steerability, and demonstrate the general utility of the ArtWhisperer dataset.