 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-training with dual uncertainty for semi-supervised medical image segmentation
Apr 10, 2023
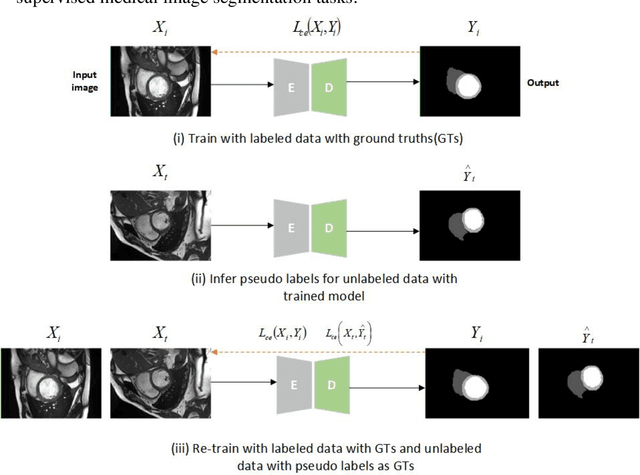
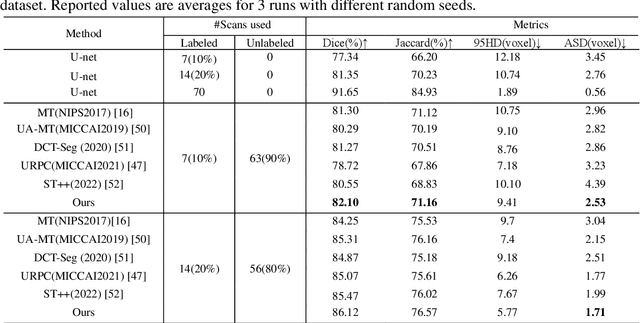
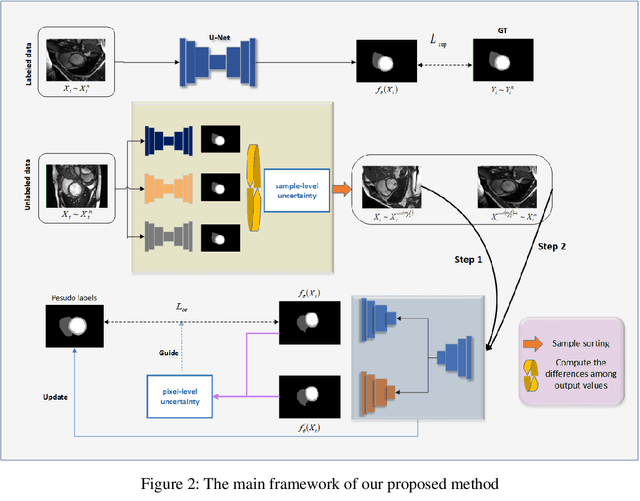
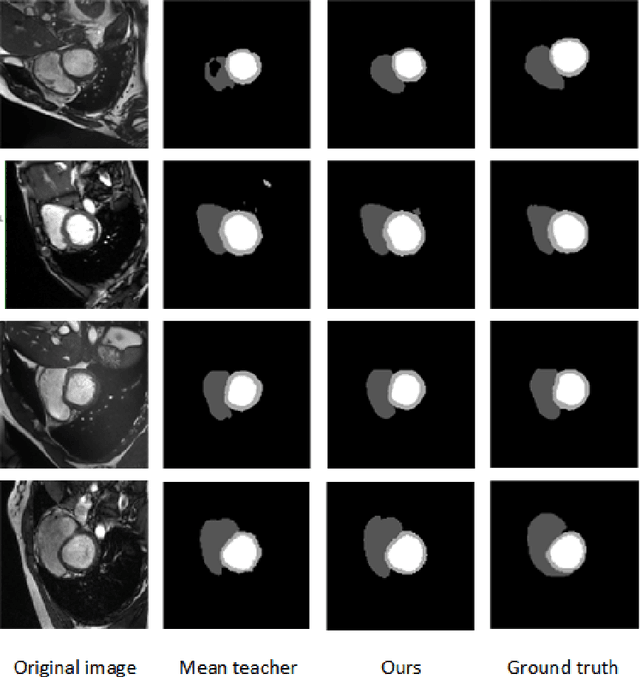
In the field of semi-supervised medical image segmentation, the shortage of labeled data is the fundamental problem. How to effectively learn image features from unlabeled images to improve segmentation accuracy is the main research direction in this field. Traditional self-training methods can partially solve the problem of insufficient labeled data by generating pseudo labels for iterative training. However, noise generated due to the model's uncertainty during training directly affects the segmentation results. Therefore, we added sample-level and pixel-level uncertainty to stabilize the training process based on the self-training framework. Specifically, we saved several moments of the model during pre-training, and used the difference between their predictions on unlabeled samples as the sample-level uncertainty estimate for that sample. Then, we gradually add unlabeled samples from easy to hard during training. At the same time, we added a decoder with different upsampling methods to the segmentation network and used the difference between the outputs of the two decoders as pixel-level uncertainty. In short, we selectively retrained unlabeled samples and assigned pixel-level uncertainty to pseudo labels to optimize the self-training process. We compared the segmentation results of our model with five semi-supervised approaches on the public 2017 ACDC dataset and 2018 Prostate dataset. Our proposed method achieves better segmentation performance on both datasets under the same settings, demonstrating its effectiveness, robustness, and potential transferability to other medical image segmentation tasks. Keywords: Medical image segmentation, semi-supervised learning, self-training, uncertainty estimation
Multi-modal reward for visual relationships-based image captioning
Mar 21, 2023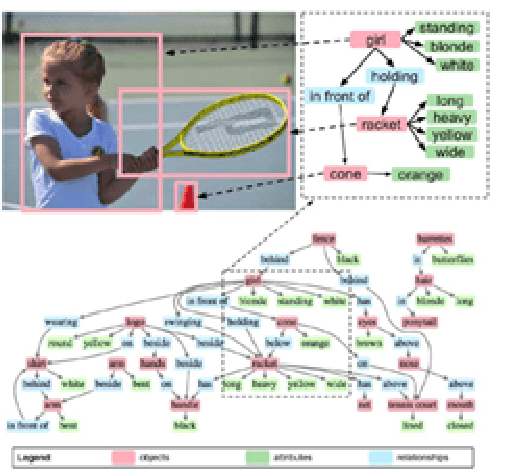
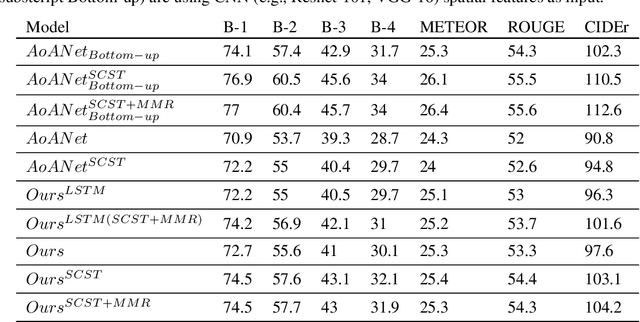
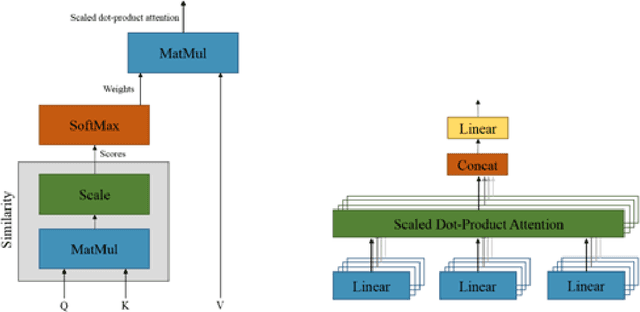
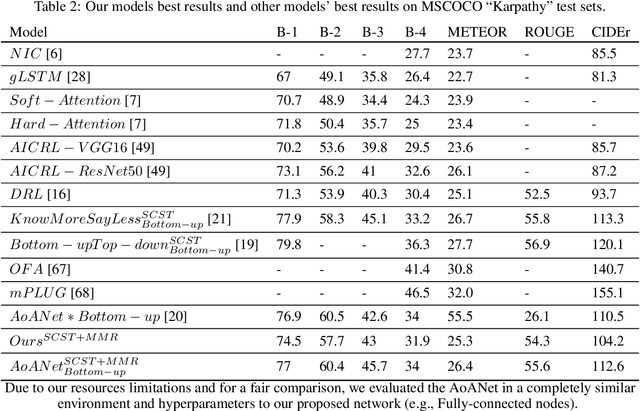
Deep neural networks have achieved promising results in automatic image captioning due to their effective representation learning and context-based content generation capabilities. As a prominent type of deep features used in many of the recent image captioning methods, the well-known bottomup features provide a detailed representation of different objects of the image in comparison with the feature maps directly extracted from the raw image. However, the lack of high-level semantic information about the relationships between these objects is an important drawback of bottom-up features, despite their expensive and resource-demanding extraction procedure. To take advantage of visual relationships in caption generation, this paper proposes a deep neural network architecture for image captioning based on fusing the visual relationships information extracted from an image's scene graph with the spatial feature maps of the image. A multi-modal reward function is then introduced for deep reinforcement learning of the proposed network using a combination of language and vision similarities in a common embedding space. The results of extensive experimentation on the MSCOCO dataset show the effectiveness of using visual relationships in the proposed captioning method. Moreover, the results clearly indicate that the proposed multi-modal reward in deep reinforcement learning leads to better model optimization, outperforming several state-of-the-art image captioning algorithms, while using light and easy to extract image features. A detailed experimental study of the components constituting the proposed method is also presented.
Boosting Adversarial Transferability with Learnable Patch-wise Masks
Jun 28, 2023Adversarial examples have raised widespread attention in security-critical applications because of their transferability across different models. Although many methods have been proposed to boost adversarial transferability, a gap still exists in the practical demand. In this paper, we argue that the model-specific discriminative regions are a key factor to cause the over-fitting to the source model, and thus reduce the transferability to the target model. For that, a patch-wise mask is utilized to prune the model-specific regions when calculating adversarial perturbations. To accurately localize these regions, we present a learnable approach to optimize the mask automatically. Specifically, we simulate the target models in our framework, and adjust the patch-wise mask according to the feedback of simulated models. To improve the efficiency, Differential Evolutionary (DE) algorithm is utilized to search for patch-wise masks for a specific image. During iterative attacks, the learned masks are applied to the image to drop out the patches related to model-specific regions, thus making the gradients more generic and improving the adversarial transferability. The proposed approach is a pre-processing method and can be integrated with existing gradient-based methods to further boost the transfer attack success rate. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our method. We incorporate the proposed approach with existing methods in the ensemble attacks and achieve an average success rate of 93.01% against seven advanced defense methods, which can effectively enhance the state-of-the-art transfer-based attack performance.
Semi-supervised Multimodal Representation Learning through a Global Workspace
Jun 27, 2023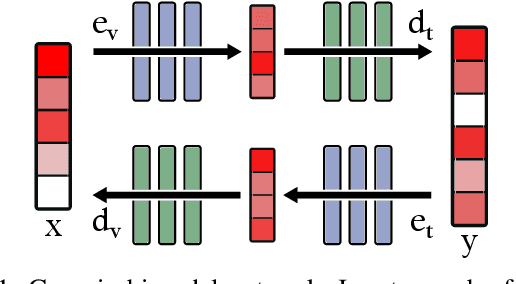

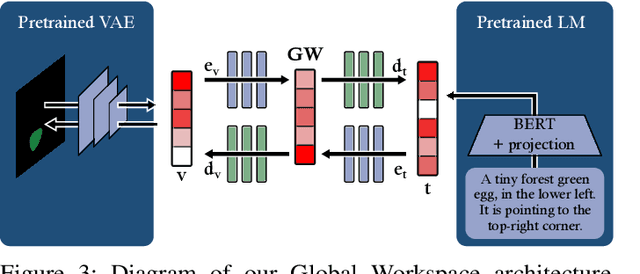
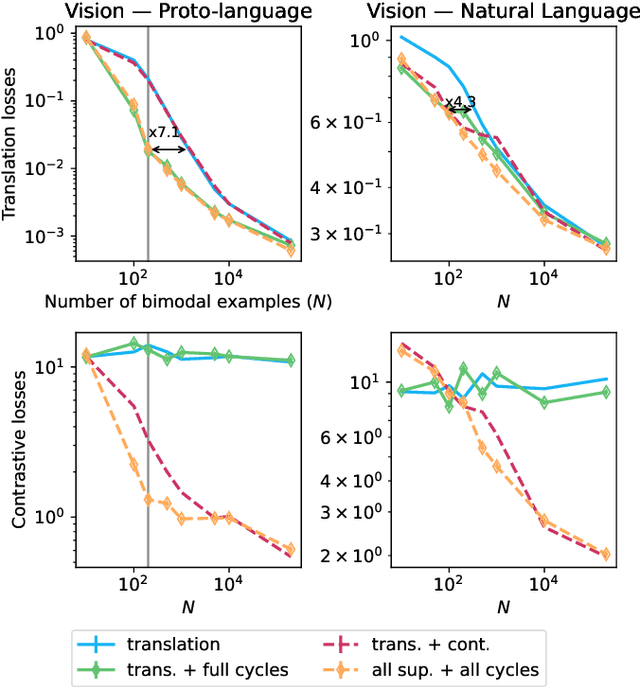
Recent deep learning models can efficiently combine inputs from different modalities (e.g., images and text) and learn to align their latent representations, or to translate signals from one domain to another (as in image captioning, or text-to-image generation). However, current approaches mainly rely on brute-force supervised training over large multimodal datasets. In contrast, humans (and other animals) can learn useful multimodal representations from only sparse experience with matched cross-modal data. Here we evaluate the capabilities of a neural network architecture inspired by the cognitive notion of a "Global Workspace": a shared representation for two (or more) input modalities. Each modality is processed by a specialized system (pretrained on unimodal data, and subsequently frozen). The corresponding latent representations are then encoded to and decoded from a single shared workspace. Importantly, this architecture is amenable to self-supervised training via cycle-consistency: encoding-decoding sequences should approximate the identity function. For various pairings of vision-language modalities and across two datasets of varying complexity, we show that such an architecture can be trained to align and translate between two modalities with very little need for matched data (from 4 to 7 times less than a fully supervised approach). The global workspace representation can be used advantageously for downstream classification tasks and for robust transfer learning. Ablation studies reveal that both the shared workspace and the self-supervised cycle-consistency training are critical to the system's performance.
Correlational Image Modeling for Self-Supervised Visual Pre-Training
Mar 23, 2023
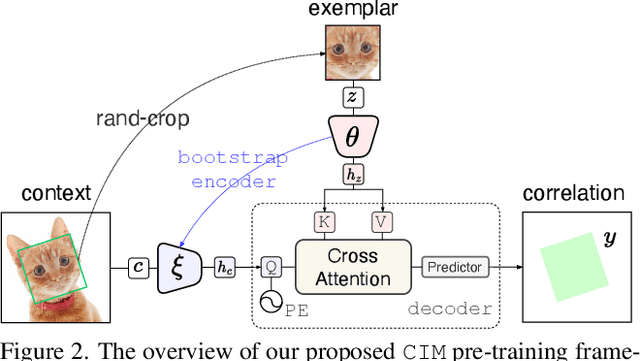
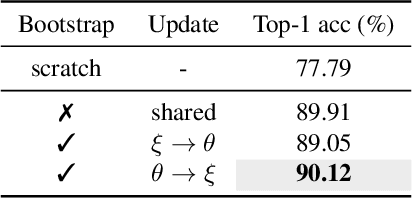

We introduce Correlational Image Modeling (CIM), a novel and surprisingly effective approach to self-supervised visual pre-training. Our CIM performs a simple pretext task: we randomly crop image regions (exemplars) from an input image (context) and predict correlation maps between the exemplars and the context. Three key designs enable correlational image modeling as a nontrivial and meaningful self-supervisory task. First, to generate useful exemplar-context pairs, we consider cropping image regions with various scales, shapes, rotations, and transformations. Second, we employ a bootstrap learning framework that involves online and target encoders. During pre-training, the former takes exemplars as inputs while the latter converts the context. Third, we model the output correlation maps via a simple cross-attention block, within which the context serves as queries and the exemplars offer values and keys. We show that CIM performs on par or better than the current state of the art on self-supervised and transfer benchmarks.
Multimodal Image-Text Matching Improves Retrieval-based Chest X-Ray Report Generation
Mar 29, 2023
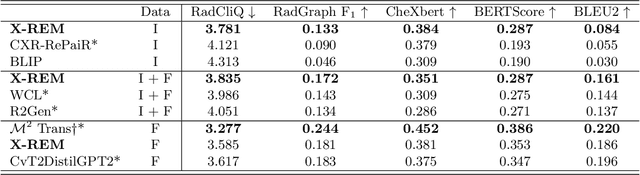
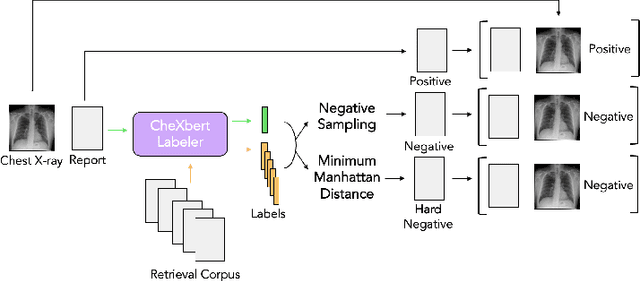

Automated generation of clinically accurate radiology reports can improve patient care. Previous report generation methods that rely on image captioning models often generate incoherent and incorrect text due to their lack of relevant domain knowledge, while retrieval-based attempts frequently retrieve reports that are irrelevant to the input image. In this work, we propose Contrastive X-Ray REport Match (X-REM), a novel retrieval-based radiology report generation module that uses an image-text matching score to measure the similarity of a chest X-ray image and radiology report for report retrieval. We observe that computing the image-text matching score with a language-image model can effectively capture the fine-grained interaction between image and text that is often lost when using cosine similarity. X-REM outperforms multiple prior radiology report generation modules in terms of both natural language and clinical metrics. Human evaluation of the generated reports suggests that X-REM increased the number of zero-error reports and decreased the average error severity compared to the baseline retrieval approach. Our code is available at: https://github.com/rajpurkarlab/X-REM
Efficient ResNets: Residual Network Design
Jun 21, 2023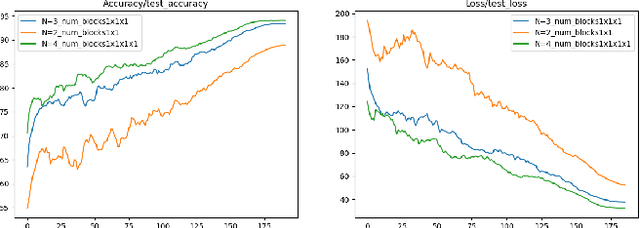
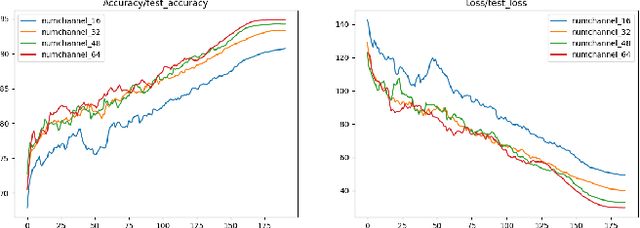
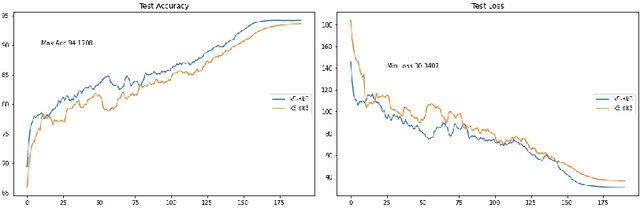
ResNets (or Residual Networks) are one of the most commonly used models for image classification tasks. In this project, we design and train a modified ResNet model for CIFAR-10 image classification. In particular, we aimed at maximizing the test accuracy on the CIFAR-10 benchmark while keeping the size of our ResNet model under the specified fixed budget of 5 million trainable parameters. Model size, typically measured as the number of trainable parameters, is important when models need to be stored on devices with limited storage capacity (e.g. IoT/edge devices). In this article, we present our residual network design which has less than 5 million parameters. We show that our ResNet achieves a test accuracy of 96.04% on CIFAR-10 which is much higher than ResNet18 (which has greater than 11 million trainable parameters) when equipped with a number of training strategies and suitable ResNet hyperparameters. Models and code are available at https://github.com/Nikunj-Gupta/Efficient_ResNets.
LF-PGVIO: A Visual-Inertial-Odometry Framework for Large Field-of-View Cameras using Points and Geodesic Segments
Jun 11, 2023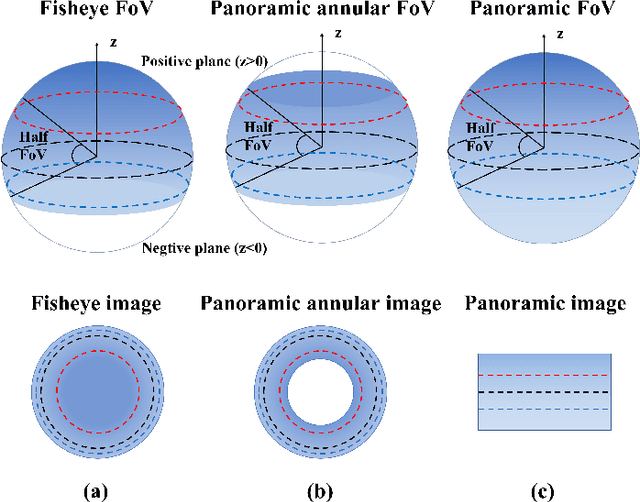
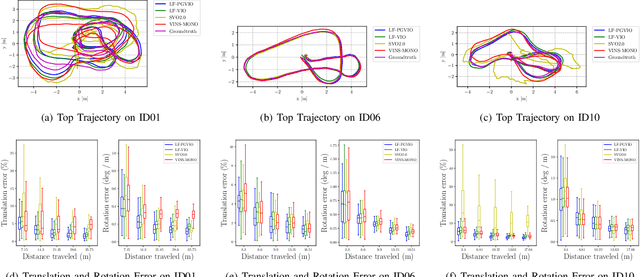
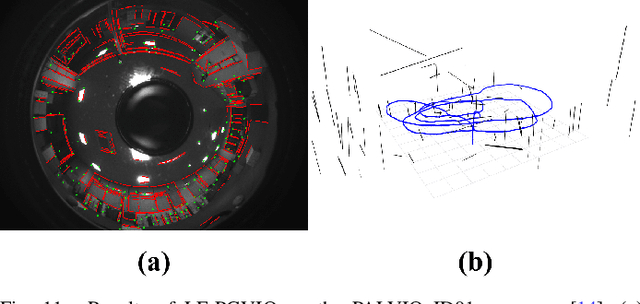
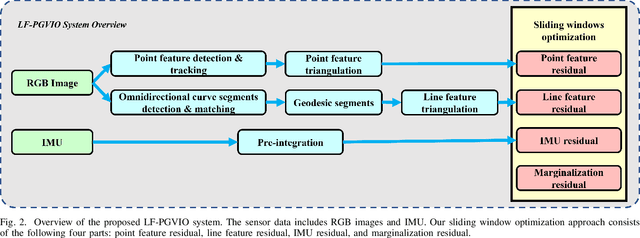
In this paper, we propose LF-PGVIO, a Visual-Inertial-Odometry (VIO) framework for large Field-of-View (FoV) cameras with a negative plane using points and geodesic segments. Notoriously, when the FoV of a panoramic camera reaches the negative half-plane, the image cannot be unfolded into a single pinhole image. Moreover, if a traditional straight-line detection method is directly applied to the original panoramic image, it cannot be normally used due to the large distortions in the panoramas and remains under-explored in the literature. To address these challenges, we put forward LF-PGVIO, which can provide line constraints for cameras with large FoV, even for cameras with negative-plane FoV, and directly extract omnidirectional curve segments from the raw omnidirectional image. We propose an Omnidirectional Curve Segment Detection (OCSD) method combined with a camera model which is applicable to images with large distortions, such as panoramic annular images, fisheye images, and various panoramic images. Each point on the image is projected onto the sphere, and the detected omnidirectional curve segments in the image named geodesic segments must satisfy the criterion of being a geodesic segment on the unit sphere. The detected geodesic segment is sliced into multiple straight-line segments according to the radian of the geodesic, and descriptors are extracted separately and recombined to obtain new descriptors. Based on descriptor matching, we obtain the constraint relationship of the 3D line segments between multiple frames. In our VIO system, we use sliding window optimization using point feature residuals, line feature residuals, and IMU residuals. Our evaluation of the proposed system on public datasets demonstrates that LF-PGVIO outperforms state-of-the-art methods in terms of accuracy and robustness. Code will be open-sourced at https://github.com/flysoaryun/LF-PGVIO.
IRGen: Generative Modeling for Image Retrieval
Mar 17, 2023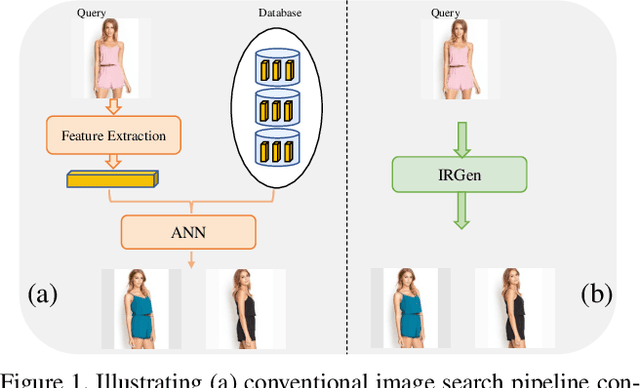
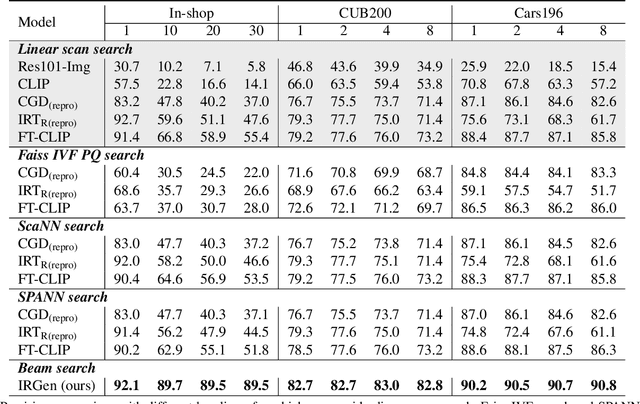
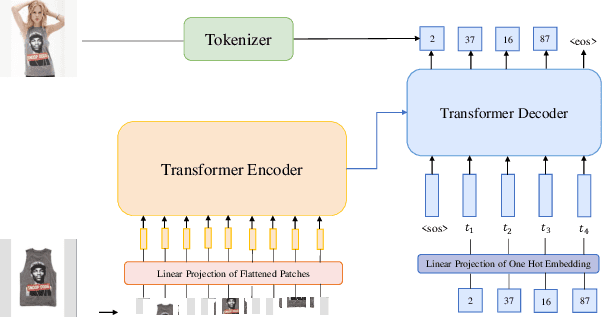
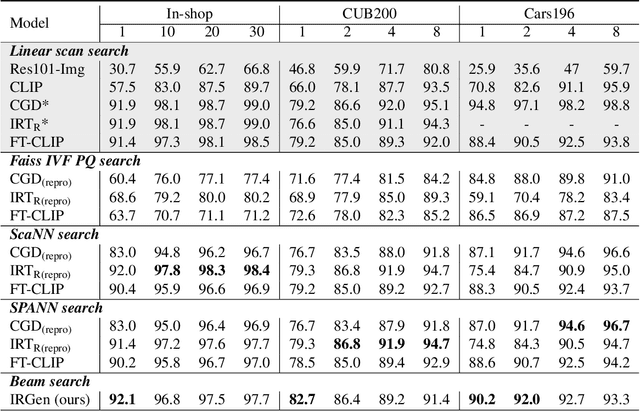
While generative modeling has been ubiquitous in natural language processing and computer vision, its application to image retrieval remains unexplored. In this paper, we recast image retrieval as a form of generative modeling by employing a sequence-to-sequence model, contributing to the current unified theme. Our framework, IRGen, is a unified model that enables end-to-end differentiable search, thus achieving superior performance thanks to direct optimization. While developing IRGen we tackle the key technical challenge of converting an image into quite a short sequence of semantic units in order to enable efficient and effective retrieval. Empirical experiments demonstrate that our model yields significant improvement over three commonly used benchmarks, for example, 22.9\% higher than the best baseline method in precision@10 on In-shop dataset with comparable recall@10 score.
Physics-assisted Deep Learning for FMCW Radar Quantitative Imaging of Two-dimension Target
Jul 05, 2023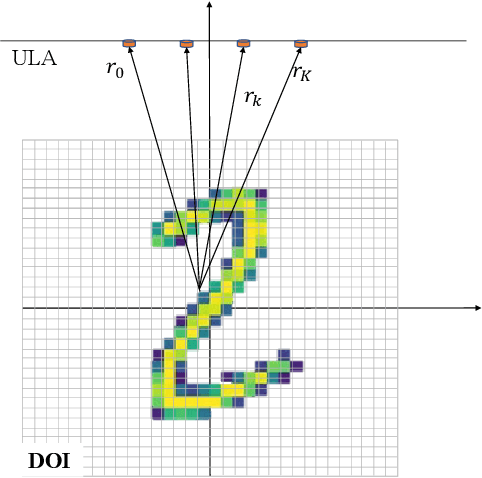
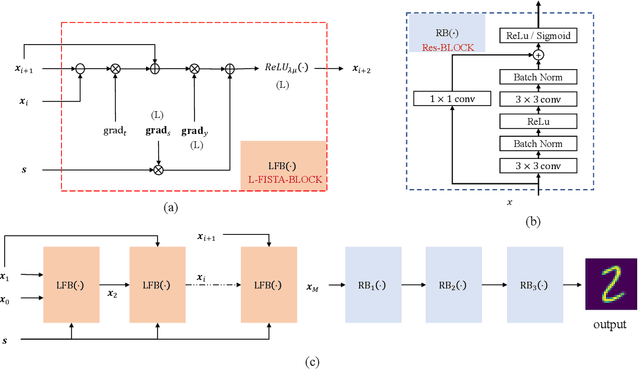


Radar imaging is crucial in remote sensing and has many applications in detection and autonomous driving. However, the received radar signal for imaging is enormous and redundant, which degrades the speed of real-time radar quantitative imaging and leads to obstacles in the downlink applications. In this paper, we propose a physics-assisted deep learning method for radar quantitative imaging with the advantage of compressed sensing (CS). Specifically, the signal model for frequency-modulated continuous-wave (FMCW) radar imaging which only uses four antennas and parts of frequency components is formulated in terms of matrices multiplication. The learned fast iterative shrinkage-thresholding algorithm with residual neural network (L-FISTA-ResNet) is proposed for solving the quantitative imaging problem. The L-FISTA is developed to ensure the basic solution and ResNet is attached to enhance the image quality. Simulation results show that our proposed method has higher reconstruction accuracy than the traditional optimization method and pure neural networks. The effectiveness and generalization performance of the proposed strategy is verified in unseen target imaging, denoising, and frequency migration tasks.