 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatial Reasoning via Deep Vision Models for Robotic Sequential Manipulation
Jul 06, 2023
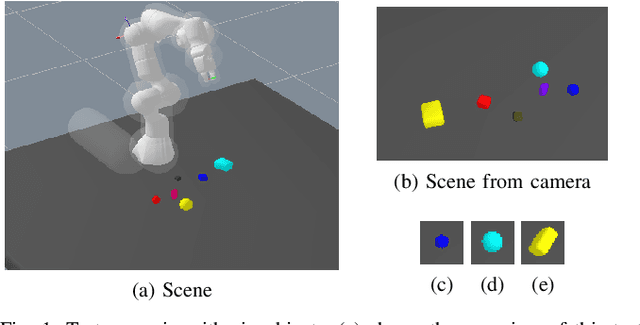

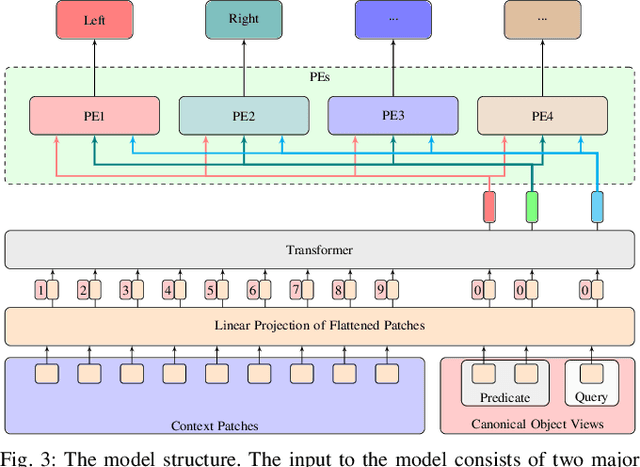
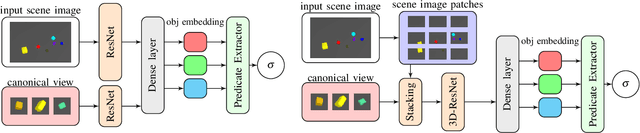
In this paper, we propose using deep neural architectures (i.e., vision transformers and ResNet) as heuristics for sequential decision-making in robotic manipulation problems. This formulation enables predicting the subset of objects that are relevant for completing a task. Such problems are often addressed by task and motion planning (TAMP) formulations combining symbolic reasoning and continuous motion planning. In essence, the action-object relationships are resolved for discrete, symbolic decisions that are used to solve manipulation motions (e.g., via nonlinear trajectory optimization). However, solving long-horizon tasks requires consideration of all possible action-object combinations which limits the scalability of TAMP approaches. To overcome this combinatorial complexity, we introduce a visual perception module integrated with a TAMP-solver. Given a task and an initial image of the scene, the learned model outputs the relevancy of objects to accomplish the task. By incorporating the predictions of the model into a TAMP formulation as a heuristic, the size of the search space is significantly reduced. Results show that our framework finds feasible solutions more efficiently when compared to a state-of-the-art TAMP solver.
That's BAD: Blind Anomaly Detection by Implicit Local Feature Clustering
Jul 06, 2023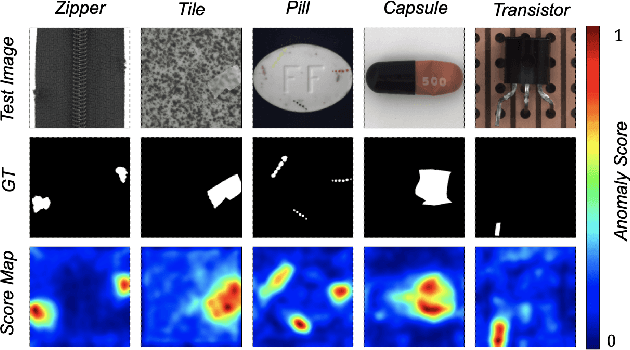

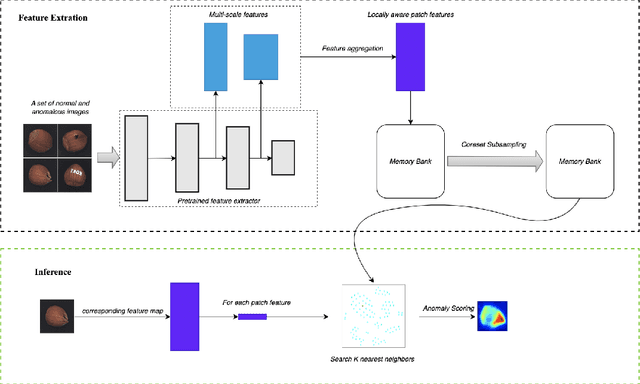

Recent studies on visual anomaly detection (AD) of industrial objects/textures have achieved quite good performance. They consider an unsupervised setting, specifically the one-class setting, in which we assume the availability of a set of normal (\textit{i.e.}, anomaly-free) images for training. In this paper, we consider a more challenging scenario of unsupervised AD, in which we detect anomalies in a given set of images that might contain both normal and anomalous samples. The setting does not assume the availability of known normal data and thus is completely free from human annotation, which differs from the standard AD considered in recent studies. For clarity, we call the setting blind anomaly detection (BAD). We show that BAD can be converted into a local outlier detection problem and propose a novel method named PatchCluster that can accurately detect image- and pixel-level anomalies. Experimental results show that PatchCluster shows a promising performance without the knowledge of normal data, even comparable to the SOTA methods applied in the one-class setting needing it.
Increasing Textual Context Size Boosts Medical Image-Text Matching
Mar 23, 2023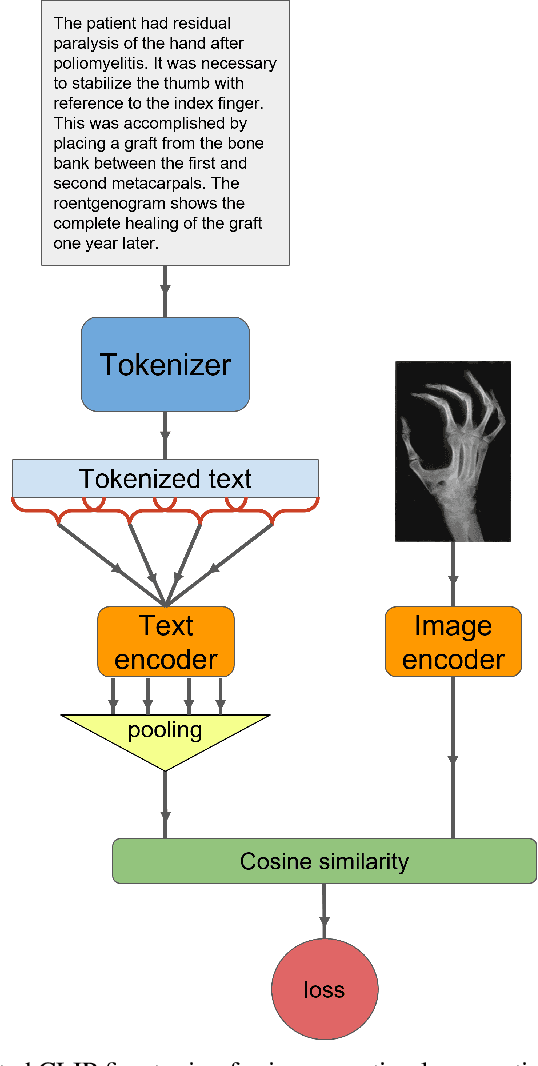
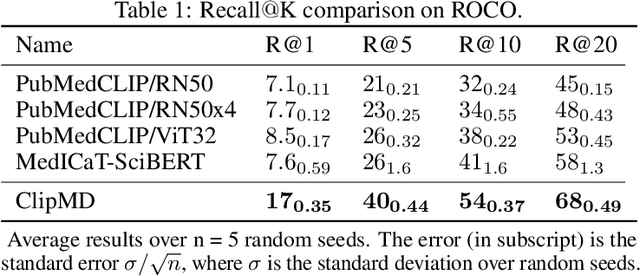
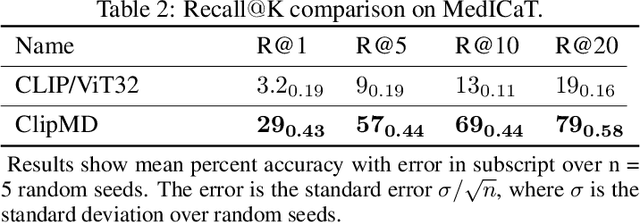
This short technical report demonstrates a simple technique that yields state of the art results in medical image-text matching tasks. We analyze the use of OpenAI's CLIP, a general image-text matching model, and observe that CLIP's limited textual input size has negative impact on downstream performance in the medical domain where encoding longer textual contexts is often required. We thus train and release ClipMD, which is trained with a simple sliding window technique to encode textual captions. ClipMD was tested on two medical image-text datasets and compared with other image-text matching models. The results show that ClipMD outperforms other models on both datasets by a large margin. We make our code and pretrained model publicly available.
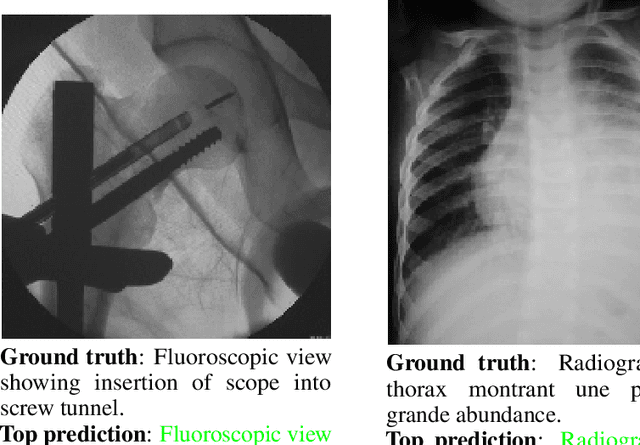
Generation of Radiology Findings in Chest X-Ray by Leveraging Collaborative Knowledge
Jun 18, 2023

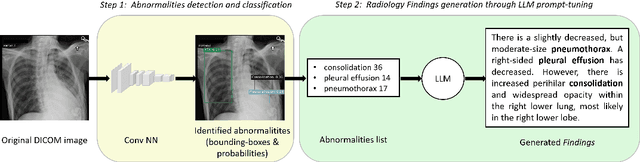
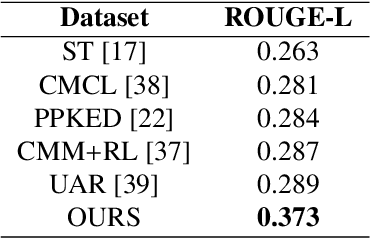
Among all the sub-sections in a typical radiology report, the Clinical Indications, Findings, and Impression often reflect important details about the health status of a patient. The information included in Impression is also often covered in Findings. While Findings and Impression can be deduced by inspecting the image, Clinical Indications often require additional context. The cognitive task of interpreting medical images remains the most critical and often time-consuming step in the radiology workflow. Instead of generating an end-to-end radiology report, in this paper, we focus on generating the Findings from automated interpretation of medical images, specifically chest X-rays (CXRs). Thus, this work focuses on reducing the workload of radiologists who spend most of their time either writing or narrating the Findings. Unlike past research, which addresses radiology report generation as a single-step image captioning task, we have further taken into consideration the complexity of interpreting CXR images and propose a two-step approach: (a) detecting the regions with abnormalities in the image, and (b) generating relevant text for regions with abnormalities by employing a generative large language model (LLM). This two-step approach introduces a layer of interpretability and aligns the framework with the systematic reasoning that radiologists use when reviewing a CXR.
* Information Technology and Quantitative Management (ITQM 2023)
LegoNet: Alternating Model Blocks for Medical Image Segmentation
Jun 06, 2023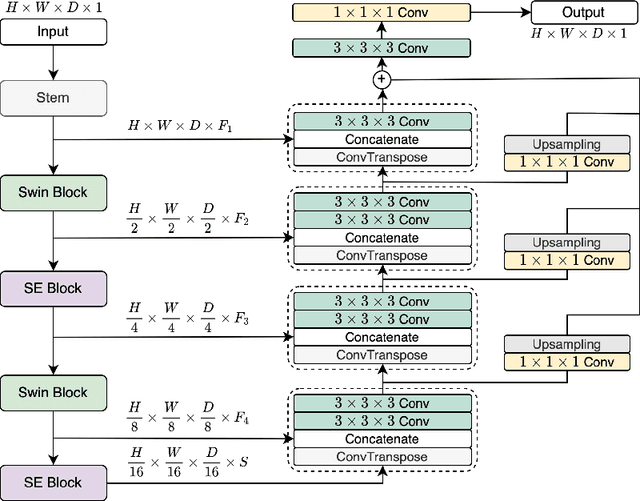
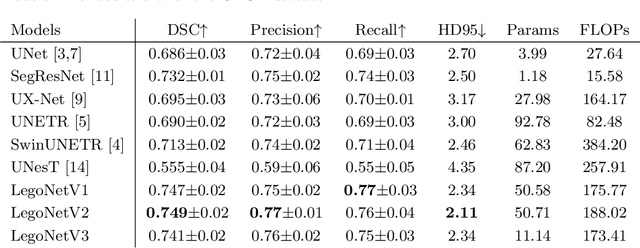

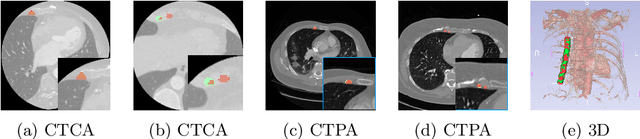
Since the emergence of convolutional neural networks (CNNs), and later vision transformers (ViTs), the common paradigm for model development has always been using a set of identical block types with varying parameters/hyper-parameters. To leverage the benefits of different architectural designs (e.g. CNNs and ViTs), we propose to alternate structurally different types of blocks to generate a new architecture, mimicking how Lego blocks can be assembled together. Using two CNN-based and one SwinViT-based blocks, we investigate three variations to the so-called LegoNet that applies the new concept of block alternation for the segmentation task in medical imaging. We also study a new clinical problem which has not been investigated before, namely the right internal mammary artery (RIMA) and perivascular space segmentation from computed tomography angiography (CTA) which has demonstrated a prognostic value to major cardiovascular outcomes. We compare the model performance against popular CNN and ViT architectures using two large datasets (e.g. achieving 0.749 dice similarity coefficient (DSC) on the larger dataset). We evaluate the performance of the model on three external testing cohorts as well, where an expert clinician made corrections to the model segmented results (DSC>0.90 for the three cohorts). To assess our proposed model for suitability in clinical use, we perform intra- and inter-observer variability analysis. Finally, we investigate a joint self-supervised learning approach to assess its impact on model performance. The code and the pretrained model weights will be available upon acceptance.
Review of Large Vision Models and Visual Prompt Engineering
Jul 03, 2023
Visual prompt engineering is a fundamental technology in the field of visual and image Artificial General Intelligence, serving as a key component for achieving zero-shot capabilities. As the development of large vision models progresses, the importance of prompt engineering becomes increasingly evident. Designing suitable prompts for specific visual tasks has emerged as a meaningful research direction. This review aims to summarize the methods employed in the computer vision domain for large vision models and visual prompt engineering, exploring the latest advancements in visual prompt engineering. We present influential large models in the visual domain and a range of prompt engineering methods employed on these models. It is our hope that this review provides a comprehensive and systematic description of prompt engineering methods based on large visual models, offering valuable insights for future researchers in their exploration of this field.
SAMAug: Point Prompt Augmentation for Segment Anything Model
Jul 03, 2023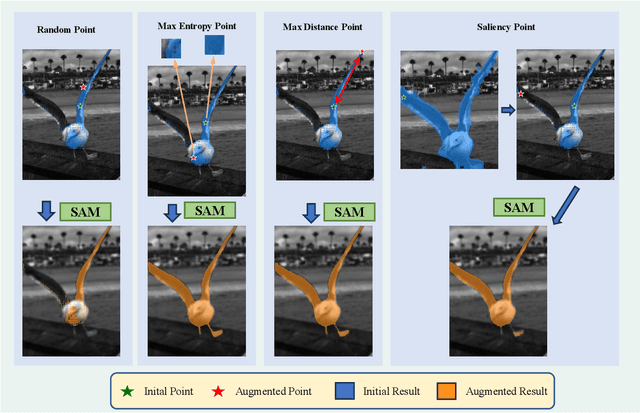
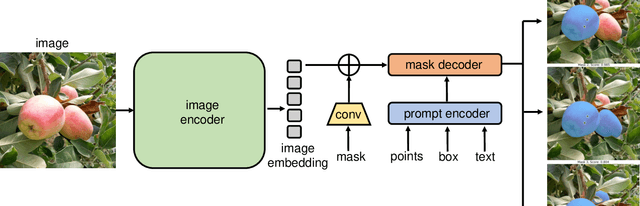

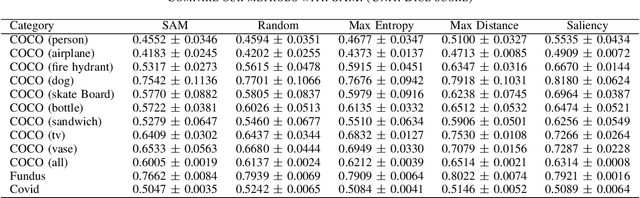
This paper introduces SAMAug, a novel visual point augmentation method for the Segment Anything Model (SAM) that enhances interactive image segmentation performance. SAMAug generates augmented point prompts to provide more information to SAM. From the initial point prompt, SAM produces the initial mask, which is then fed into our proposed SAMAug to generate augmented point prompts. By incorporating these extra points, SAM can generate augmented segmentation masks based on the augmented point prompts and the initial prompt, resulting in improved segmentation performance. We evaluate four point augmentation techniques: random selection, maximum difference entropy, maximum distance, and a saliency model. Experiments on the COCO, Fundus, and Chest X-ray datasets demonstrate that SAMAug can boost SAM's segmentation results, especially using the maximum distance and saliency model methods. SAMAug underscores the potential of visual prompt engineering to advance interactive computer vision models.
Cross-Modal Attribute Insertions for Assessing the Robustness of Vision-and-Language Learning
Jun 19, 2023
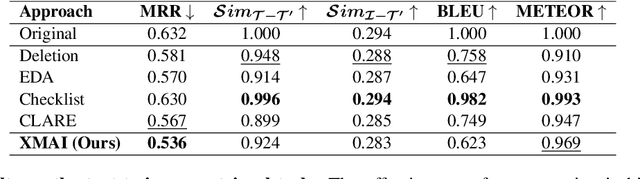
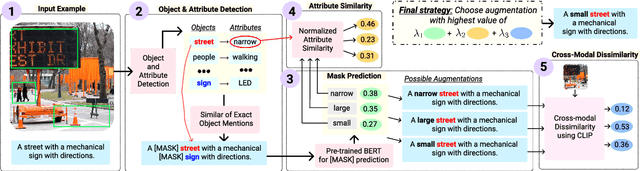
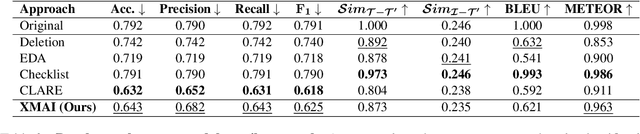
The robustness of multimodal deep learning models to realistic changes in the input text is critical for their applicability to important tasks such as text-to-image retrieval and cross-modal entailment. To measure robustness, several existing approaches edit the text data, but do so without leveraging the cross-modal information present in multimodal data. Information from the visual modality, such as color, size, and shape, provide additional attributes that users can include in their inputs. Thus, we propose cross-modal attribute insertions as a realistic perturbation strategy for vision-and-language data that inserts visual attributes of the objects in the image into the corresponding text (e.g., "girl on a chair" to "little girl on a wooden chair"). Our proposed approach for cross-modal attribute insertions is modular, controllable, and task-agnostic. We find that augmenting input text using cross-modal insertions causes state-of-the-art approaches for text-to-image retrieval and cross-modal entailment to perform poorly, resulting in relative drops of 15% in MRR and 20% in $F_1$ score, respectively. Crowd-sourced annotations demonstrate that cross-modal insertions lead to higher quality augmentations for multimodal data than augmentations using text-only data, and are equivalent in quality to original examples. We release the code to encourage robustness evaluations of deep vision-and-language models: https://github.com/claws-lab/multimodal-robustness-xmai.
Broken Rail Detection With Texture Image Processing Using Two-Dimensional Gray Level Co-occurrence Matrix
Apr 23, 2023Application of electronic railway systems as well as the implication of Automatic Train Control (ATC) System has increased the safety of rail transportation. However, one of the most important causes of accidents on the railway is rail damage and breakage. In this paper, we have proposed a method that the rail region is first recognized from the observation area, then by investigating the image texture processing data, the types of rail defects including cracks, wear, peeling, disintegration, and breakage are detected. In order to reduce the computational cost, the image is changed from the RGB color spectrum to the gray spectrum. Image texture processing data is obtained by the two-dimensional Gray Levels Co-occurrence Matrix (GLCM) at different angles; this data demonstrates second-order features of the images. Large data of features has a negative effect on the overall accuracy of the classifiers. To tackle this issue and acquire faster response, Principal Component Analysis (PCA) algorithm is used, before entering the band into the classifier. Then the features extracted from the images are compared by three different classifiers including Support Vector Machine (SVM), Random Forest (RF), and K-Nearest Neighbor (KNN) classification. The results obtained from this method indicate that the Random Forest classifier has better performance (accuracy 97%, precision 96%, and recall 96%) than other classifiers.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Apr 01, 2023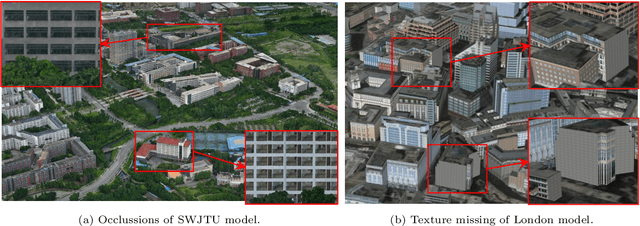
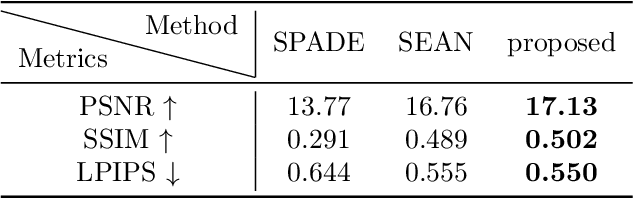
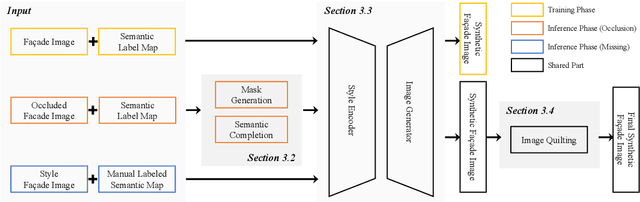

The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.