 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DreamCatcher: Revealing the Language of the Brain with fMRI using GPT Embedding
Jun 16, 2023
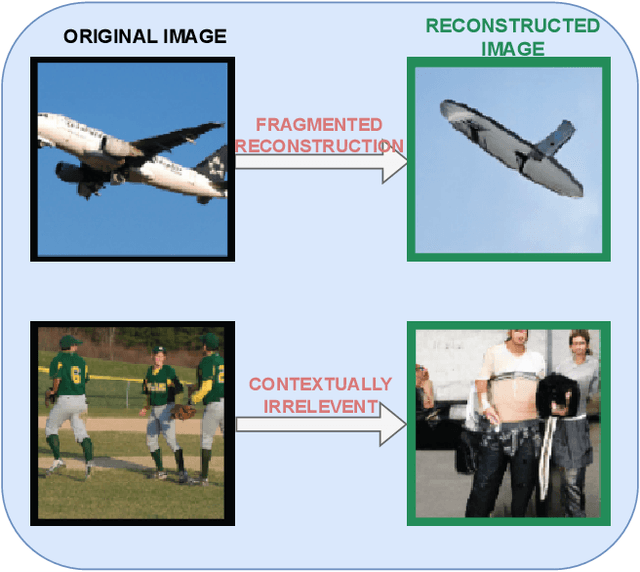

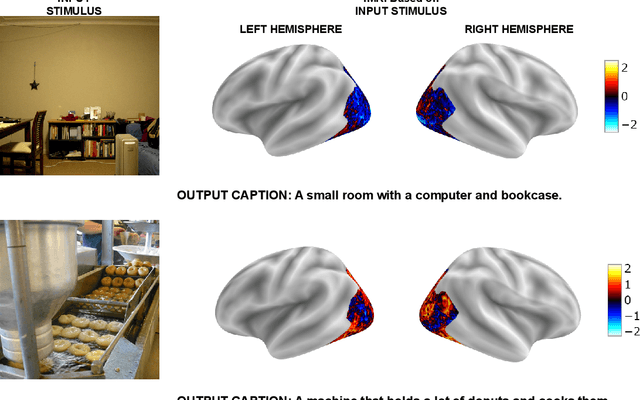
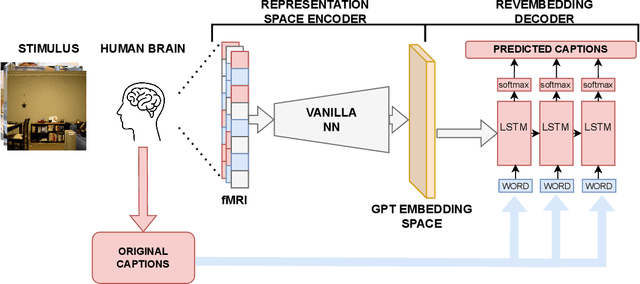
The human brain possesses remarkable abilities in visual processing, including image recognition and scene summarization. Efforts have been made to understand the cognitive capacities of the visual brain, but a comprehensive understanding of the underlying mechanisms still needs to be discovered. Advancements in brain decoding techniques have led to sophisticated approaches like fMRI-to-Image reconstruction, which has implications for cognitive neuroscience and medical imaging. However, challenges persist in fMRI-to-image reconstruction, such as incorporating global context and contextual information. In this article, we propose fMRI captioning, where captions are generated based on fMRI data to gain insight into the neural correlates of visual perception. This research presents DreamCatcher, a novel framework for fMRI captioning. DreamCatcher consists of the Representation Space Encoder (RSE) and the RevEmbedding Decoder, which transform fMRI vectors into a latent space and generate captions, respectively. We evaluated the framework through visualization, dataset training, and testing on subjects, demonstrating strong performance. fMRI-based captioning has diverse applications, including understanding neural mechanisms, Human-Computer Interaction, and enhancing learning and training processes.
Recovering Continuous Scene Dynamics from A Single Blurry Image with Events
Apr 05, 2023
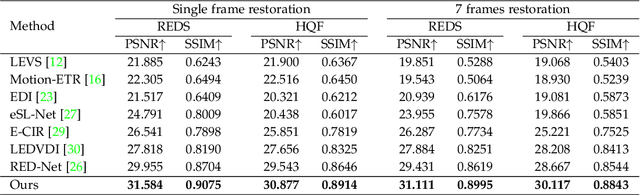

This paper aims at demystifying a single motion-blurred image with events and revealing temporally continuous scene dynamics encrypted behind motion blurs. To achieve this end, an Implicit Video Function (IVF) is learned to represent a single motion blurred image with concurrent events, enabling the latent sharp image restoration of arbitrary timestamps in the range of imaging exposures. Specifically, a dual attention transformer is proposed to efficiently leverage merits from both modalities, i.e., the high temporal resolution of event features and the smoothness of image features, alleviating temporal ambiguities while suppressing the event noise. The proposed network is trained only with the supervision of ground-truth images of limited referenced timestamps. Motion- and texture-guided supervisions are employed simultaneously to enhance restorations of the non-referenced timestamps and improve the overall sharpness. Experiments on synthetic, semi-synthetic, and real-world datasets demonstrate that our proposed method outperforms state-of-the-art methods by a large margin in terms of both objective PSNR and SSIM measurements and subjective evaluations.
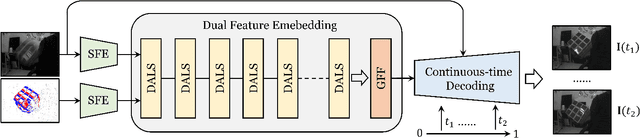
Burstormer: Burst Image Restoration and Enhancement Transformer
Apr 03, 2023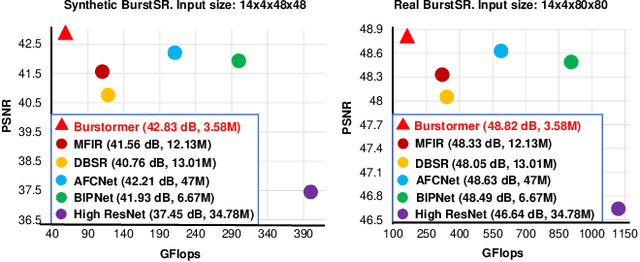
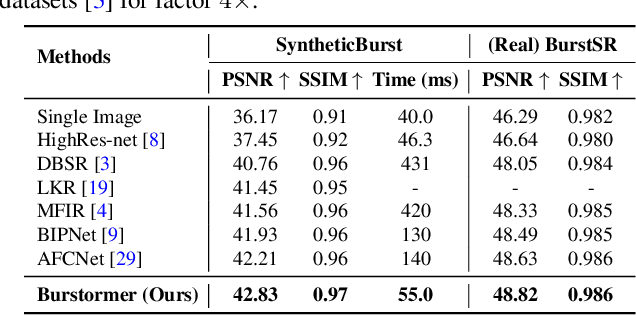
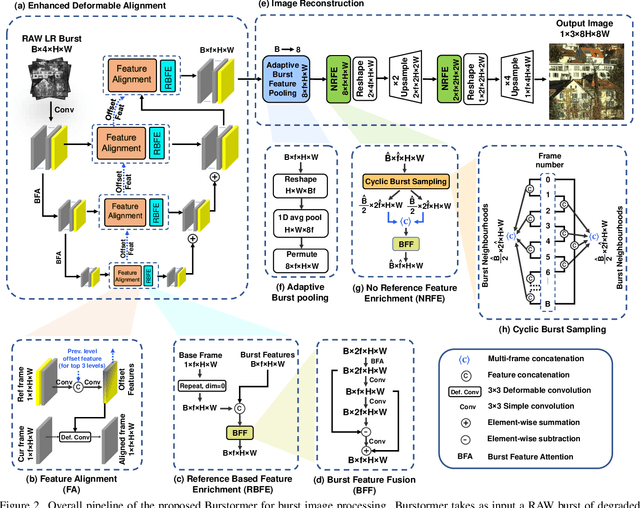
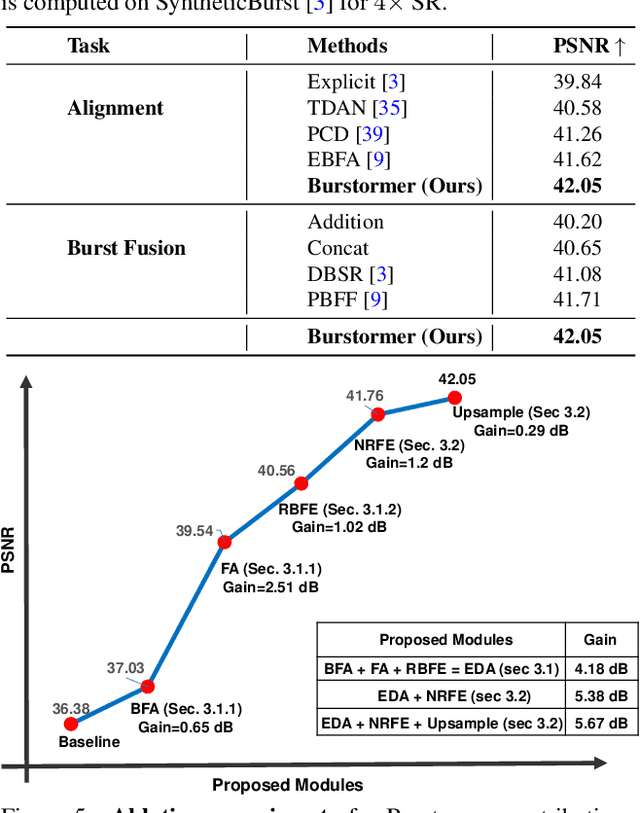
On a shutter press, modern handheld cameras capture multiple images in rapid succession and merge them to generate a single image. However, individual frames in a burst are misaligned due to inevitable motions and contain multiple degradations. The challenge is to properly align the successive image shots and merge their complimentary information to achieve high-quality outputs. Towards this direction, we propose Burstormer: a novel transformer-based architecture for burst image restoration and enhancement. In comparison to existing works, our approach exploits multi-scale local and non-local features to achieve improved alignment and feature fusion. Our key idea is to enable inter-frame communication in the burst neighborhoods for information aggregation and progressive fusion while modeling the burst-wide context. However, the input burst frames need to be properly aligned before fusing their information. Therefore, we propose an enhanced deformable alignment module for aligning burst features with regards to the reference frame. Unlike existing methods, the proposed alignment module not only aligns burst features but also exchanges feature information and maintains focused communication with the reference frame through the proposed reference-based feature enrichment mechanism, which facilitates handling complex motions. After multi-level alignment and enrichment, we re-emphasize on inter-frame communication within burst using a cyclic burst sampling module. Finally, the inter-frame information is aggregated using the proposed burst feature fusion module followed by progressive upsampling. Our Burstormer outperforms state-of-the-art methods on burst super-resolution, burst denoising and burst low-light enhancement. Our codes and pretrained models are available at https:// github.com/akshaydudhane16/Burstormer
Creating Realistic Anterior Segment Optical Coherence Tomography Images using Generative Adversarial Networks
Jun 24, 2023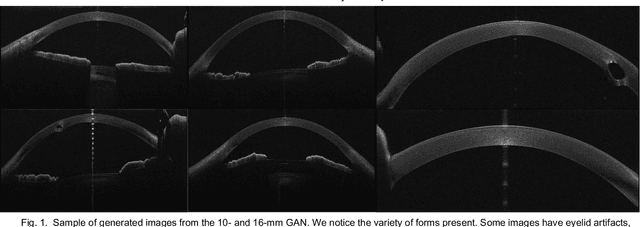

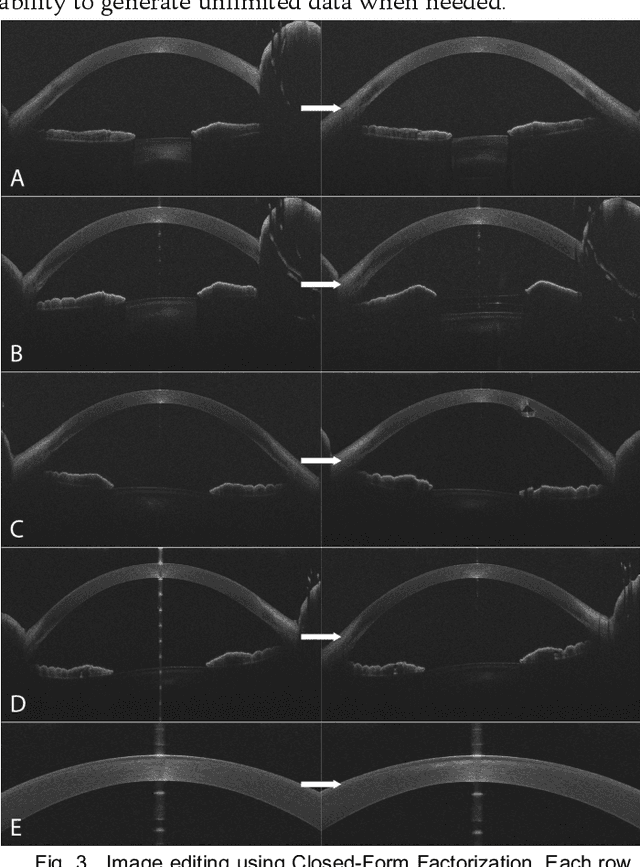
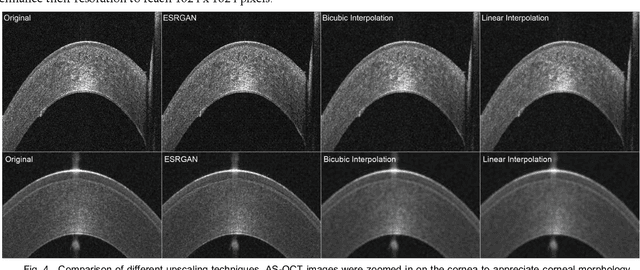
This paper presents the development and validation of a Generative Adversarial Network (GAN) purposed to create high-resolution, realistic Anterior Segment Optical Coherence Tomography (AS-OCT) images. We trained the Style and WAvelet based GAN (SWAGAN) on 142,628 AS-OCT B-scans. Three experienced refractive surgeons performed a blinded assessment to evaluate the realism of the generated images; their results were not significantly better than chance in distinguishing between real and synthetic images, thus demonstrating a high degree of image realism. To gauge their suitability for machine learning tasks, a convolutional neural network (CNN) classifier was trained with a dataset containing both real and GAN-generated images. The CNN demonstrated an accuracy rate of 78% trained on real images alone, but this accuracy rose to 100% when training included the generated images. This underscores the utility of synthetic images for machine learning applications. We further improved the resolution of the generated images by up-sampling them twice (2x) using an Enhanced Super Resolution GAN (ESRGAN), which outperformed traditional up-sampling techniques. In conclusion, GANs can effectively generate high-definition, realistic AS-OCT images, proving highly beneficial for machine learning and image analysis tasks.
Zero-shot Referring Image Segmentation with Global-Local Context Features
Apr 03, 2023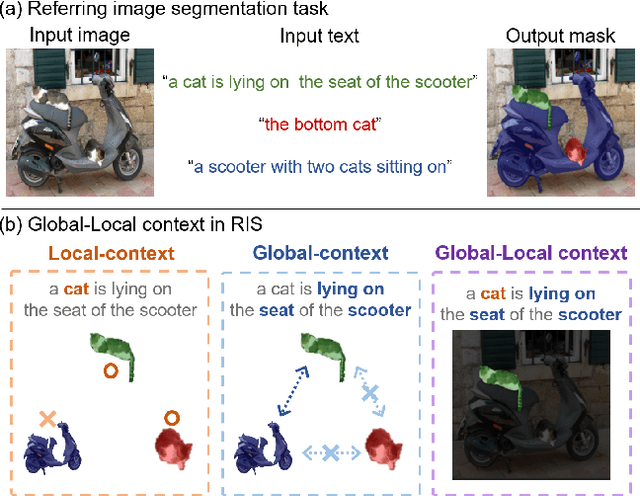
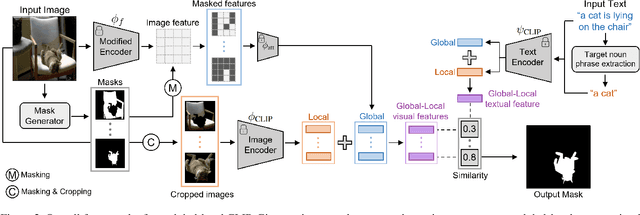
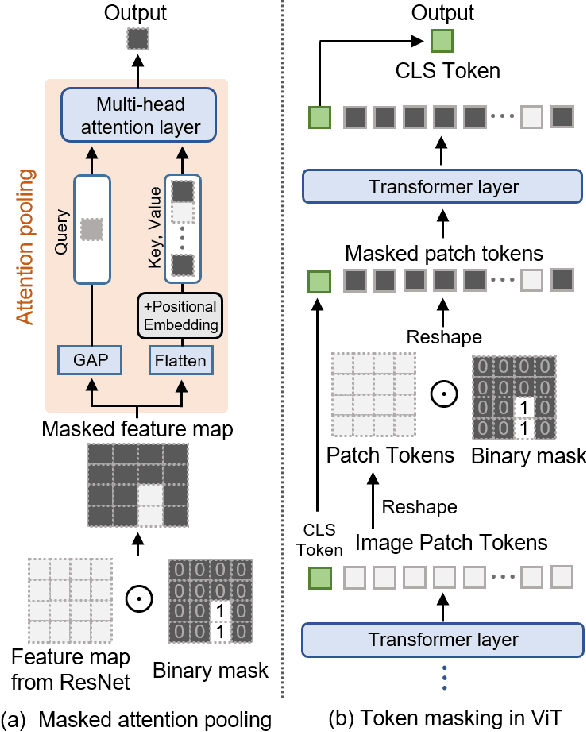
Referring image segmentation (RIS) aims to find a segmentation mask given a referring expression grounded to a region of the input image. Collecting labelled datasets for this task, however, is notoriously costly and labor-intensive. To overcome this issue, we propose a simple yet effective zero-shot referring image segmentation method by leveraging the pre-trained cross-modal knowledge from CLIP. In order to obtain segmentation masks grounded to the input text, we propose a mask-guided visual encoder that captures global and local contextual information of an input image. By utilizing instance masks obtained from off-the-shelf mask proposal techniques, our method is able to segment fine-detailed Istance-level groundings. We also introduce a global-local text encoder where the global feature captures complex sentence-level semantics of the entire input expression while the local feature focuses on the target noun phrase extracted by a dependency parser. In our experiments, the proposed method outperforms several zero-shot baselines of the task and even the weakly supervised referring expression segmentation method with substantial margins. Our code is available at https://github.com/Seonghoon-Yu/Zero-shot-RIS.
Texturize a GAN Using a Single Image
Mar 11, 2023
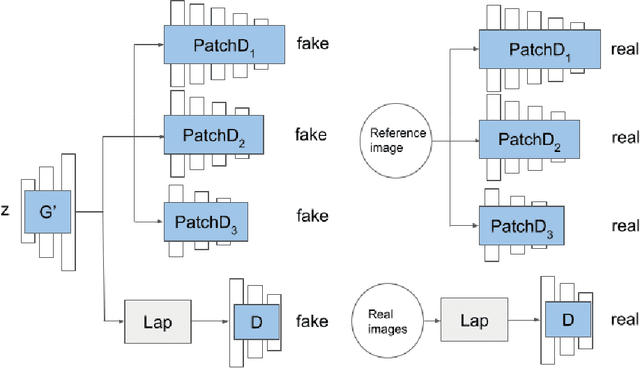


Can we customize a deep generative model which can generate images that can match the texture of some given image? When you see an image of a church, you may wonder if you can get similar pictures for that church. Here we present a method, for adapting GANs with one reference image, and then we can generate images that have similar textures to the given image. Specifically, we modify the weights of the pre-trained GAN model, guided by the reference image given by the user. We use a patch discriminator adversarial loss to encourage the output of the model to match the texture on the given image, also we use a laplacian adversarial loss to ensure diversity and realism, and alleviate the contradiction between the two losses. Experiments show that the proposed method can make the outputs of GANs match the texture of the given image as well as keep diversity and realism.
Generation of Radiology Findings in Chest X-Ray by Leveraging Collaborative Knowledge
Jun 18, 2023

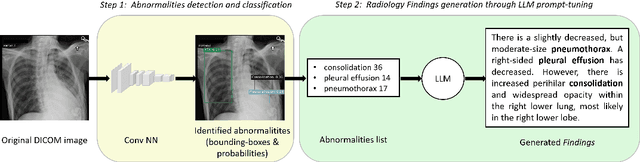
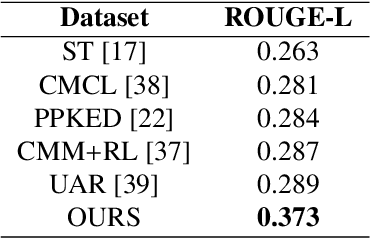
Among all the sub-sections in a typical radiology report, the Clinical Indications, Findings, and Impression often reflect important details about the health status of a patient. The information included in Impression is also often covered in Findings. While Findings and Impression can be deduced by inspecting the image, Clinical Indications often require additional context. The cognitive task of interpreting medical images remains the most critical and often time-consuming step in the radiology workflow. Instead of generating an end-to-end radiology report, in this paper, we focus on generating the Findings from automated interpretation of medical images, specifically chest X-rays (CXRs). Thus, this work focuses on reducing the workload of radiologists who spend most of their time either writing or narrating the Findings. Unlike past research, which addresses radiology report generation as a single-step image captioning task, we have further taken into consideration the complexity of interpreting CXR images and propose a two-step approach: (a) detecting the regions with abnormalities in the image, and (b) generating relevant text for regions with abnormalities by employing a generative large language model (LLM). This two-step approach introduces a layer of interpretability and aligns the framework with the systematic reasoning that radiologists use when reviewing a CXR.
* Information Technology and Quantitative Management (ITQM 2023)
Cross-Modal Attribute Insertions for Assessing the Robustness of Vision-and-Language Learning
Jun 19, 2023
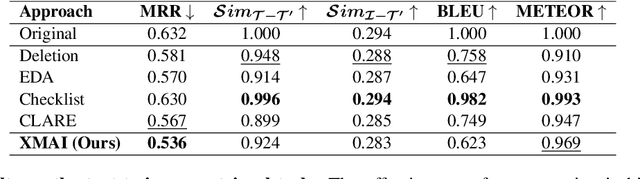
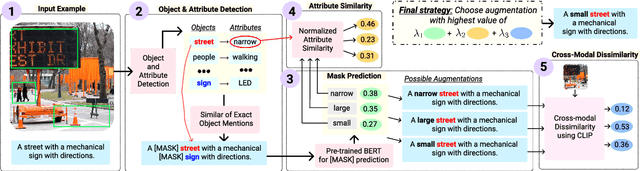
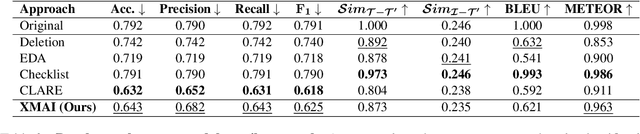
The robustness of multimodal deep learning models to realistic changes in the input text is critical for their applicability to important tasks such as text-to-image retrieval and cross-modal entailment. To measure robustness, several existing approaches edit the text data, but do so without leveraging the cross-modal information present in multimodal data. Information from the visual modality, such as color, size, and shape, provide additional attributes that users can include in their inputs. Thus, we propose cross-modal attribute insertions as a realistic perturbation strategy for vision-and-language data that inserts visual attributes of the objects in the image into the corresponding text (e.g., "girl on a chair" to "little girl on a wooden chair"). Our proposed approach for cross-modal attribute insertions is modular, controllable, and task-agnostic. We find that augmenting input text using cross-modal insertions causes state-of-the-art approaches for text-to-image retrieval and cross-modal entailment to perform poorly, resulting in relative drops of 15% in MRR and 20% in $F_1$ score, respectively. Crowd-sourced annotations demonstrate that cross-modal insertions lead to higher quality augmentations for multimodal data than augmentations using text-only data, and are equivalent in quality to original examples. We release the code to encourage robustness evaluations of deep vision-and-language models: https://github.com/claws-lab/multimodal-robustness-xmai.
Sigmoid Loss for Language Image Pre-Training
Mar 27, 2023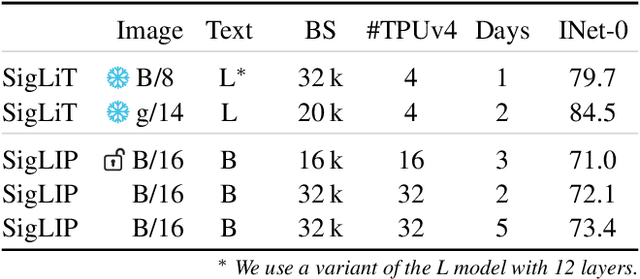
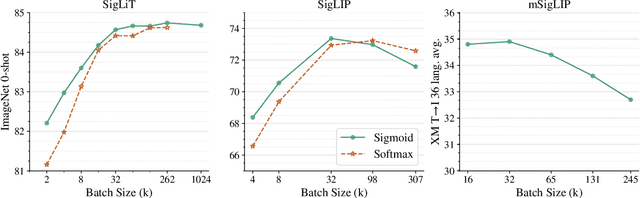
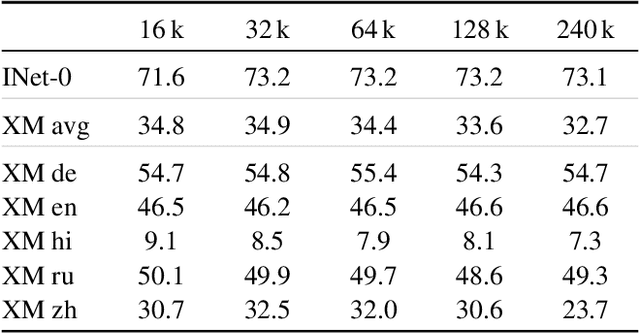
We propose a simple pairwise sigmoid loss for image-text pre-training. Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. The sigmoid loss simultaneously allows further scaling up the batch size, while also performing better at smaller batch sizes. With only four TPUv4 chips, we can train a Base CLIP model at 4k batch size and a Large LiT model at 20k batch size, the latter achieves 84.5% ImageNet zero-shot accuracy in two days. This disentanglement of the batch size from the loss further allows us to study the impact of examples vs pairs and negative to positive ratio. Finally, we push the batch size to the extreme, up to one million, and find that the benefits of growing batch size quickly diminish, with a more reasonable batch size of 32k being sufficient. We hope our research motivates further explorations in improving the quality and efficiency of language-image pre-training.
Crossway Diffusion: Improving Diffusion-based Visuomotor Policy via Self-supervised Learning
Jul 04, 2023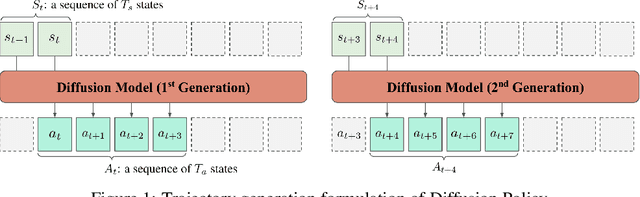

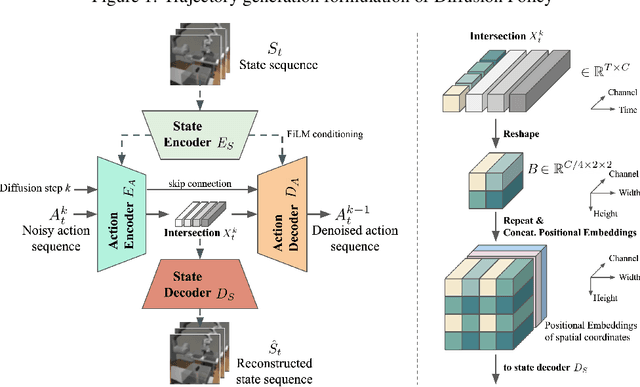

Sequence modeling approaches have shown promising results in robot imitation learning. Recently, diffusion models have been adopted for behavioral cloning, benefiting from their exceptional capabilities in modeling complex data distribution. In this work, we propose Crossway Diffusion, a method to enhance diffusion-based visuomotor policy learning by using an extra self-supervised learning (SSL) objective. The standard diffusion-based policy generates action sequences from random noise conditioned on visual observations and other low-dimensional states. We further extend this by introducing a new decoder that reconstructs raw image pixels (and other state information) from the intermediate representations of the reverse diffusion process, and train the model jointly using the SSL loss. Our experiments demonstrate the effectiveness of Crossway Diffusion in various simulated and real-world robot tasks, confirming its advantages over the standard diffusion-based policy. We demonstrate that such self-supervised reconstruction enables better representation for policy learning, especially when the demonstrations have different proficiencies.