 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Who is bragging more online? A large scale analysis of bragging in social media
Mar 25, 2024
Bragging is the act of uttering statements that are likely to be positively viewed by others and it is extensively employed in human communication with the aim to build a positive self-image of oneself. Social media is a natural platform for users to employ bragging in order to gain admiration, respect, attention and followers from their audiences. Yet, little is known about the scale of bragging online and its characteristics. This paper employs computational sociolinguistics methods to conduct the first large scale study of bragging behavior on Twitter (U.S.) by focusing on its overall prevalence, temporal dynamics and impact of demographic factors. Our study shows that the prevalence of bragging decreases over time within the same population of users. In addition, younger, more educated and popular users in the U.S. are more likely to brag. Finally, we conduct an extensive linguistics analysis to unveil specific bragging themes associated with different user traits.
MeaCap: Memory-Augmented Zero-shot Image Captioning
Mar 06, 2024
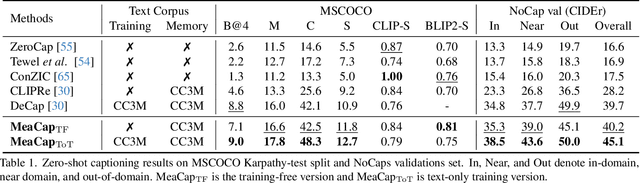
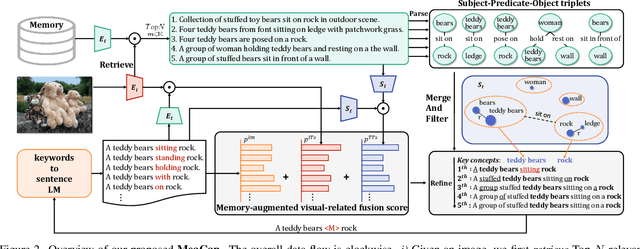
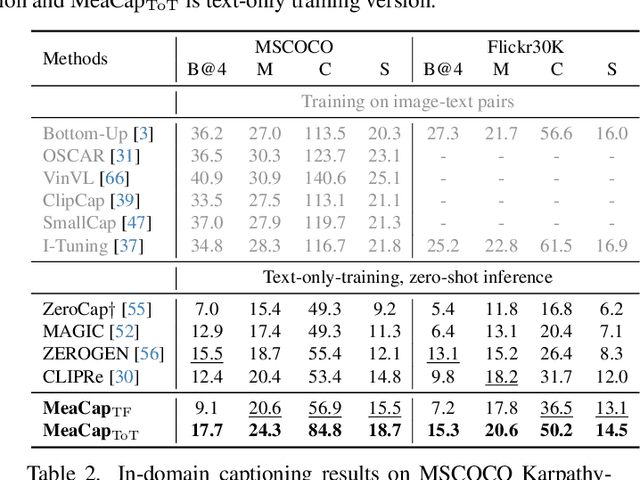
Zero-shot image captioning (IC) without well-paired image-text data can be divided into two categories, training-free and text-only-training. Generally, these two types of methods realize zero-shot IC by integrating pretrained vision-language models like CLIP for image-text similarity evaluation and a pre-trained language model (LM) for caption generation. The main difference between them is whether using a textual corpus to train the LM. Though achieving attractive performance w.r.t. some metrics, existing methods often exhibit some common drawbacks. Training-free methods tend to produce hallucinations, while text-only-training often lose generalization capability. To move forward, in this paper, we propose a novel Memory-Augmented zero-shot image Captioning framework (MeaCap). Specifically, equipped with a textual memory, we introduce a retrieve-then-filter module to get key concepts that are highly related to the image. By deploying our proposed memory-augmented visual-related fusion score in a keywords-to-sentence LM, MeaCap can generate concept-centered captions that keep high consistency with the image with fewer hallucinations and more world-knowledge. The framework of MeaCap achieves the state-of-the-art performance on a series of zero-shot IC settings. Our code is available at https://github.com/joeyz0z/MeaCap.
FedFMS: Exploring Federated Foundation Models for Medical Image Segmentation
Mar 08, 2024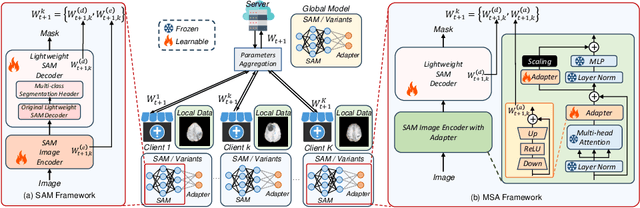
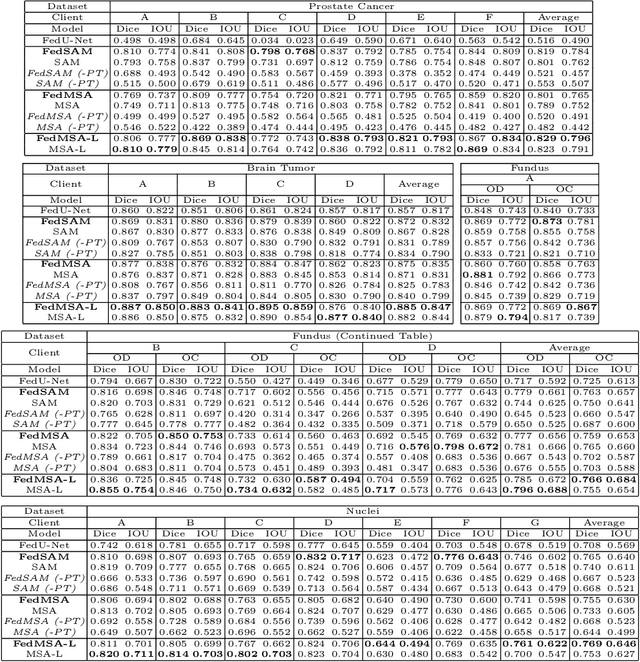
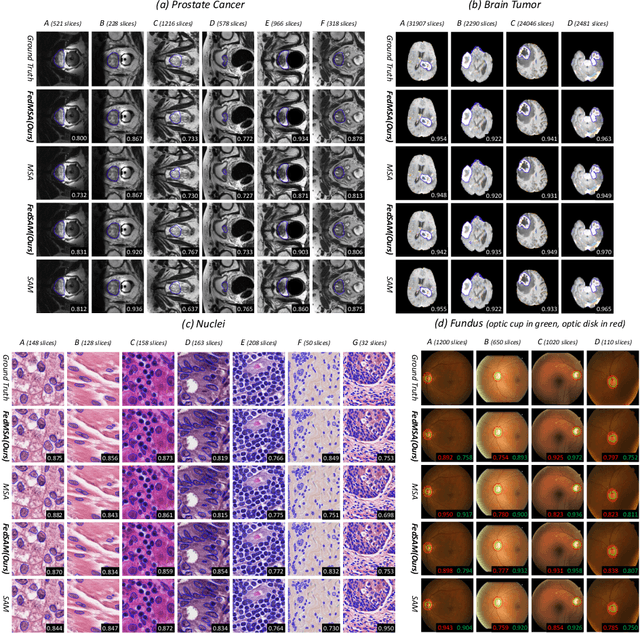

Medical image segmentation is crucial for clinical diagnosis. The Segmentation Anything Model (SAM) serves as a powerful foundation model for visual segmentation and can be adapted for medical image segmentation. However, medical imaging data typically contain privacy-sensitive information, making it challenging to train foundation models with centralized storage and sharing. To date, there are few foundation models tailored for medical image deployment within the federated learning framework, and the segmentation performance, as well as the efficiency of communication and training, remain unexplored. In response to these issues, we developed Federated Foundation models for Medical image Segmentation (FedFMS), which includes the Federated SAM (FedSAM) and a communication and training-efficient Federated SAM with Medical SAM Adapter (FedMSA). Comprehensive experiments on diverse datasets are conducted to investigate the performance disparities between centralized training and federated learning across various configurations of FedFMS. The experiments revealed that FedFMS could achieve performance comparable to models trained via centralized training methods while maintaining privacy. Furthermore, FedMSA demonstrated the potential to enhance communication and training efficiency. Our model implementation codes are available at https://github.com/LIU-YUXI/FedFMS.
Deployment of Deep Learning Model in Real World Clinical Setting: A Case Study in Obstetric Ultrasound
Mar 22, 2024Despite the rapid development of AI models in medical image analysis, their validation in real-world clinical settings remains limited. To address this, we introduce a generic framework designed for deploying image-based AI models in such settings. Using this framework, we deployed a trained model for fetal ultrasound standard plane detection, and evaluated it in real-time sessions with both novice and expert users. Feedback from these sessions revealed that while the model offers potential benefits to medical practitioners, the need for navigational guidance was identified as a key area for improvement. These findings underscore the importance of early deployment of AI models in real-world settings, leading to insights that can guide the refinement of the model and system based on actual user feedback.
Videoshop: Localized Semantic Video Editing with Noise-Extrapolated Diffusion Inversion
Mar 22, 2024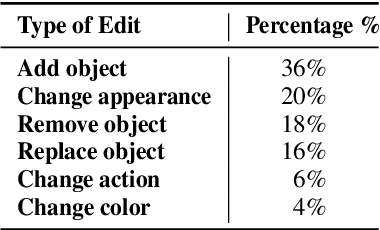
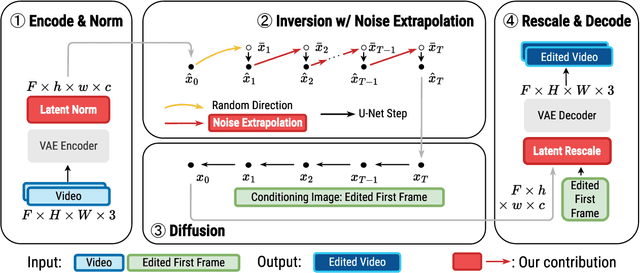
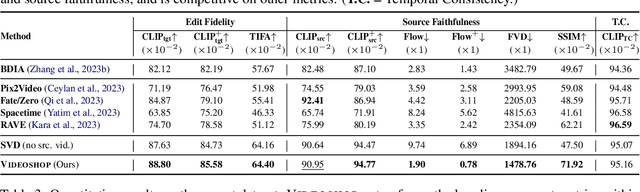
We introduce Videoshop, a training-free video editing algorithm for localized semantic edits. Videoshop allows users to use any editing software, including Photoshop and generative inpainting, to modify the first frame; it automatically propagates those changes, with semantic, spatial, and temporally consistent motion, to the remaining frames. Unlike existing methods that enable edits only through imprecise textual instructions, Videoshop allows users to add or remove objects, semantically change objects, insert stock photos into videos, etc. with fine-grained control over locations and appearance. We achieve this through image-based video editing by inverting latents with noise extrapolation, from which we generate videos conditioned on the edited image. Videoshop produces higher quality edits against 6 baselines on 2 editing benchmarks using 10 evaluation metrics.
AnyV2V: A Plug-and-Play Framework For Any Video-to-Video Editing Tasks
Mar 21, 2024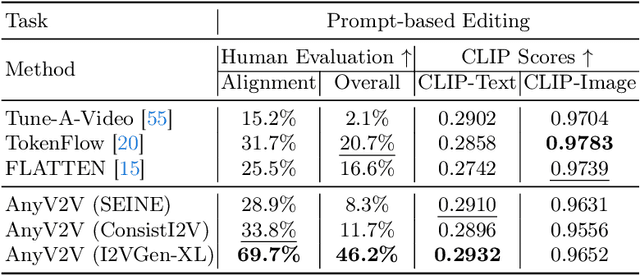
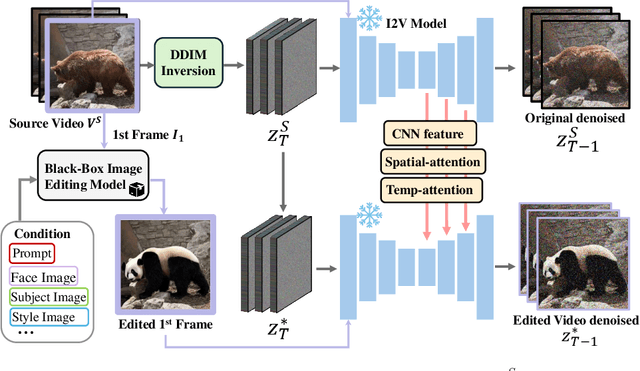
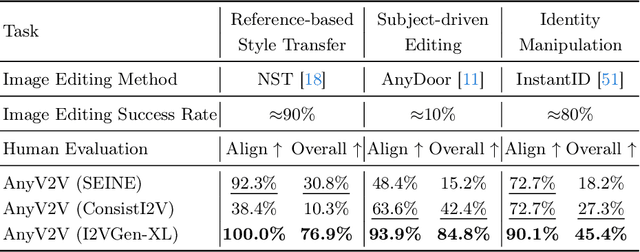

Video-to-video editing involves editing a source video along with additional control (such as text prompts, subjects, or styles) to generate a new video that aligns with the source video and the provided control. Traditional methods have been constrained to certain editing types, limiting their ability to meet the wide range of user demands. In this paper, we introduce AnyV2V, a novel training-free framework designed to simplify video editing into two primary steps: (1) employing an off-the-shelf image editing model (e.g. InstructPix2Pix, InstantID, etc) to modify the first frame, (2) utilizing an existing image-to-video generation model (e.g. I2VGen-XL) for DDIM inversion and feature injection. In the first stage, AnyV2V can plug in any existing image editing tools to support an extensive array of video editing tasks. Beyond the traditional prompt-based editing methods, AnyV2V also can support novel video editing tasks, including reference-based style transfer, subject-driven editing, and identity manipulation, which were unattainable by previous methods. In the second stage, AnyV2V can plug in any existing image-to-video models to perform DDIM inversion and intermediate feature injection to maintain the appearance and motion consistency with the source video. On the prompt-based editing, we show that AnyV2V can outperform the previous best approach by 35\% on prompt alignment, and 25\% on human preference. On the three novel tasks, we show that AnyV2V also achieves a high success rate. We believe AnyV2V will continue to thrive due to its ability to seamlessly integrate the fast-evolving image editing methods. Such compatibility can help AnyV2V to increase its versatility to cater to diverse user demands.
Chain-of-Spot: Interactive Reasoning Improves Large Vision-Language Models
Mar 21, 2024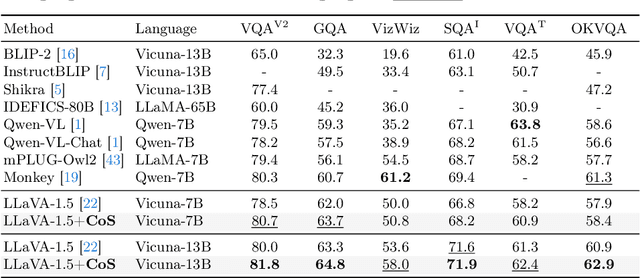
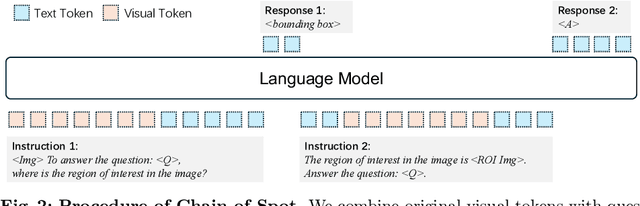
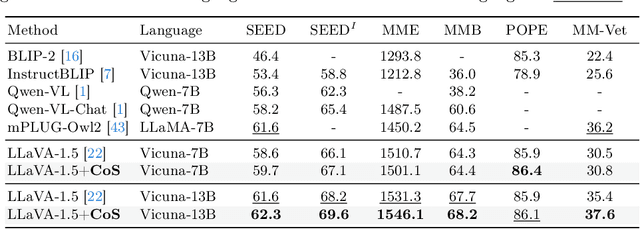

In the realm of vision-language understanding, the proficiency of models in interpreting and reasoning over visual content has become a cornerstone for numerous applications. However, it is challenging for the visual encoder in Large Vision-Language Models (LVLMs) to extract useful features tailored to questions that aid the language model's response. Furthermore, a common practice among existing LVLMs is to utilize lower-resolution images, which restricts the ability for visual recognition. Our work introduces the Chain-of-Spot (CoS) method, which we describe as Interactive Reasoning, a novel approach that enhances feature extraction by focusing on key regions of interest (ROI) within the image, corresponding to the posed questions or instructions. This technique allows LVLMs to access more detailed visual information without altering the original image resolution, thereby offering multi-granularity image features. By integrating Chain-of-Spot with instruct-following LLaVA-1.5 models, the process of image reasoning consistently improves performance across a wide range of multimodal datasets and benchmarks without bells and whistles and achieves new state-of-the-art results. Our empirical findings demonstrate a significant improvement in LVLMs' ability to understand and reason about visual content, paving the way for more sophisticated visual instruction-following applications. Code and models are available at https://github.com/dongyh20/Chain-of-Spot
Holo-Relighting: Controllable Volumetric Portrait Relighting from a Single Image
Mar 14, 2024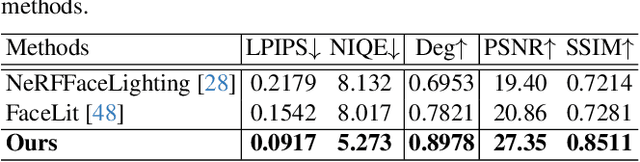
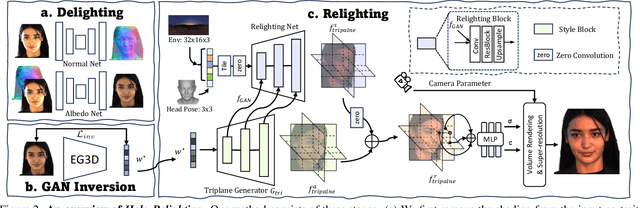
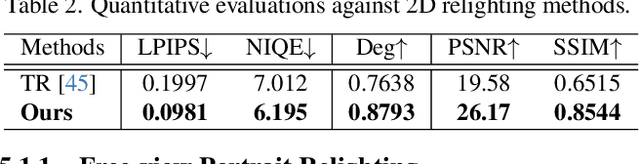
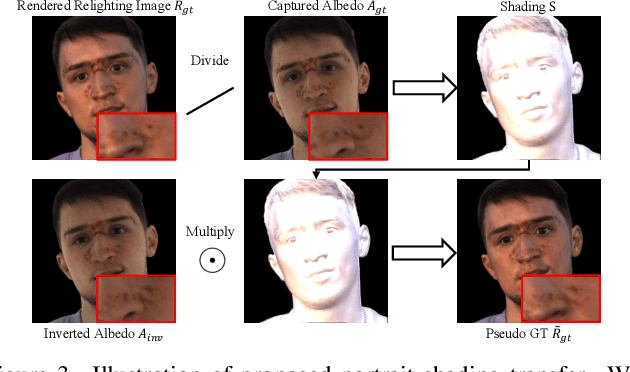
At the core of portrait photography is the search for ideal lighting and viewpoint. The process often requires advanced knowledge in photography and an elaborate studio setup. In this work, we propose Holo-Relighting, a volumetric relighting method that is capable of synthesizing novel viewpoints, and novel lighting from a single image. Holo-Relighting leverages the pretrained 3D GAN (EG3D) to reconstruct geometry and appearance from an input portrait as a set of 3D-aware features. We design a relighting module conditioned on a given lighting to process these features, and predict a relit 3D representation in the form of a tri-plane, which can render to an arbitrary viewpoint through volume rendering. Besides viewpoint and lighting control, Holo-Relighting also takes the head pose as a condition to enable head-pose-dependent lighting effects. With these novel designs, Holo-Relighting can generate complex non-Lambertian lighting effects (e.g., specular highlights and cast shadows) without using any explicit physical lighting priors. We train Holo-Relighting with data captured with a light stage, and propose two data-rendering techniques to improve the data quality for training the volumetric relighting system. Through quantitative and qualitative experiments, we demonstrate Holo-Relighting can achieve state-of-the-arts relighting quality with better photorealism, 3D consistency and controllability.
Self-supervised Photographic Image Layout Representation Learning
Mar 06, 2024
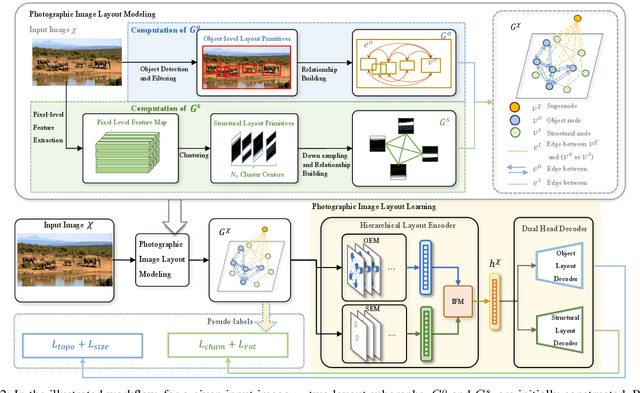
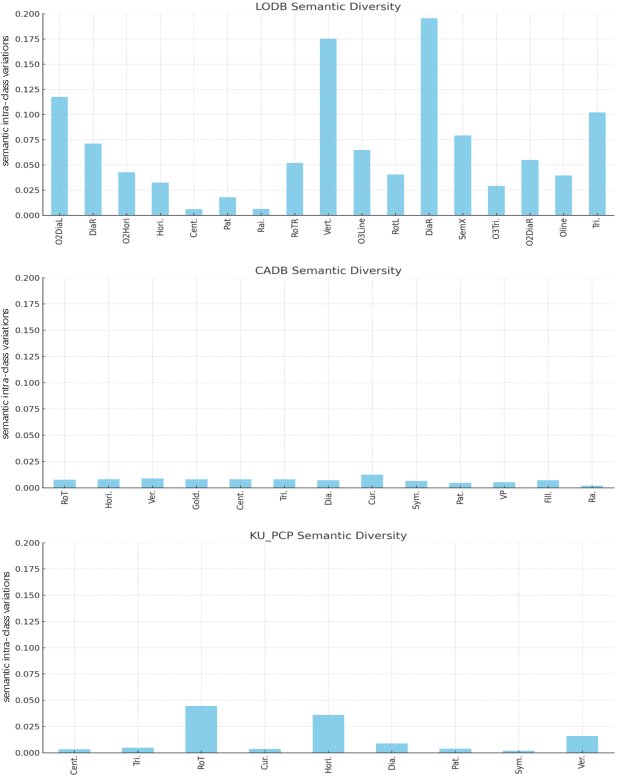

In the domain of image layout representation learning, the critical process of translating image layouts into succinct vector forms is increasingly significant across diverse applications, such as image retrieval, manipulation, and generation. Most approaches in this area heavily rely on costly labeled datasets and notably lack in adapting their modeling and learning methods to the specific nuances of photographic image layouts. This shortfall makes the learning process for photographic image layouts suboptimal. In our research, we directly address these challenges. We innovate by defining basic layout primitives that encapsulate various levels of layout information and by mapping these, along with their interconnections, onto a heterogeneous graph structure. This graph is meticulously engineered to capture the intricate layout information within the pixel domain explicitly. Advancing further, we introduce novel pretext tasks coupled with customized loss functions, strategically designed for effective self-supervised learning of these layout graphs. Building on this foundation, we develop an autoencoder-based network architecture skilled in compressing these heterogeneous layout graphs into precise, dimensionally-reduced layout representations. Additionally, we introduce the LODB dataset, which features a broader range of layout categories and richer semantics, serving as a comprehensive benchmark for evaluating the effectiveness of layout representation learning methods. Our extensive experimentation on this dataset demonstrates the superior performance of our approach in the realm of photographic image layout representation learning.
Neural Network-Based Processing and Reconstruction of Compromised Biophotonic Image Data
Mar 21, 2024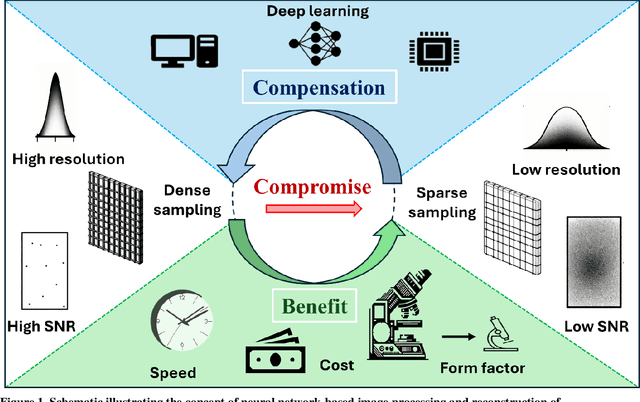
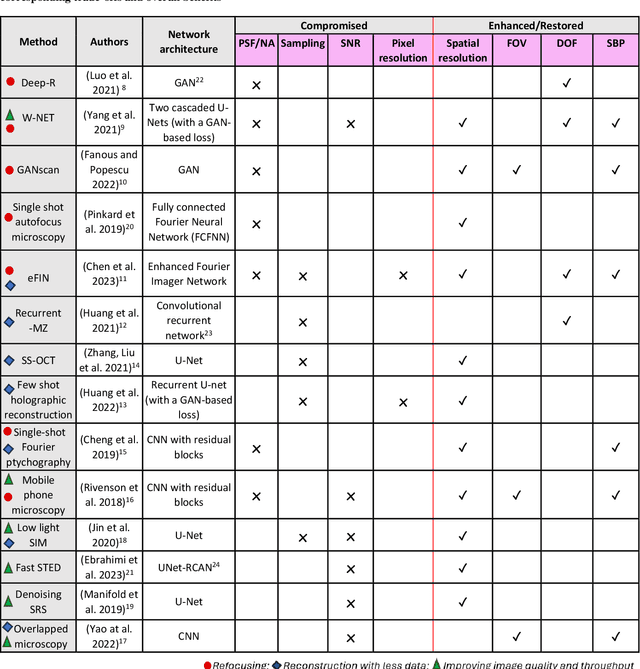
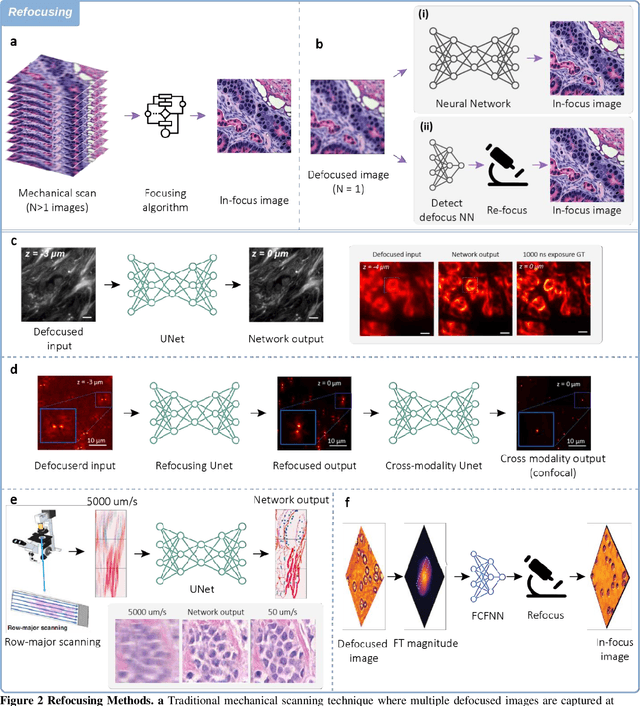
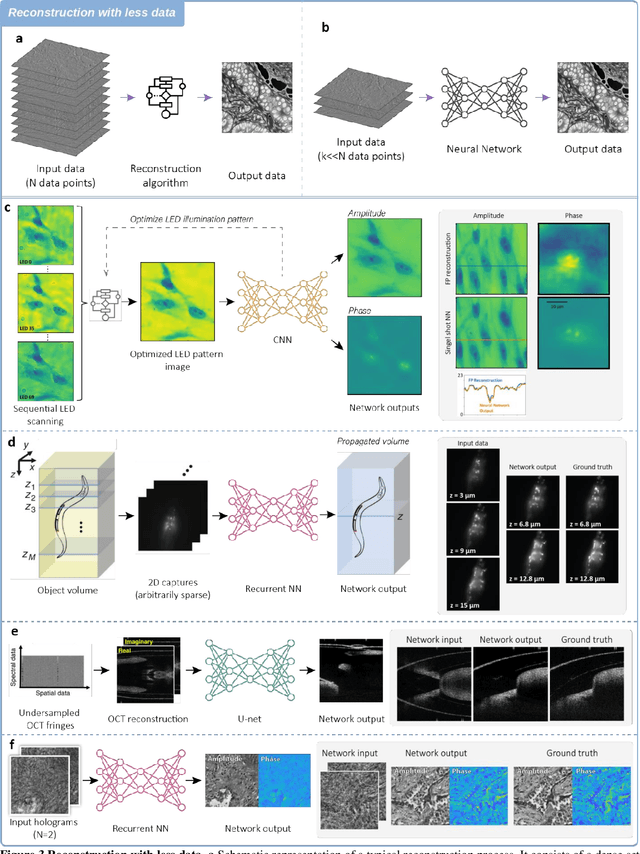
The integration of deep learning techniques with biophotonic setups has opened new horizons in bioimaging. A compelling trend in this field involves deliberately compromising certain measurement metrics to engineer better bioimaging tools in terms of cost, speed, and form-factor, followed by compensating for the resulting defects through the utilization of deep learning models trained on a large amount of ideal, superior or alternative data. This strategic approach has found increasing popularity due to its potential to enhance various aspects of biophotonic imaging. One of the primary motivations for employing this strategy is the pursuit of higher temporal resolution or increased imaging speed, critical for capturing fine dynamic biological processes. This approach also offers the prospect of simplifying hardware requirements/complexities, thereby making advanced imaging standards more accessible in terms of cost and/or size. This article provides an in-depth review of the diverse measurement aspects that researchers intentionally impair in their biophotonic setups, including the point spread function, signal-to-noise ratio, sampling density, and pixel resolution. By deliberately compromising these metrics, researchers aim to not only recuperate them through the application of deep learning networks, but also bolster in return other crucial parameters, such as the field-of-view, depth-of-field, and space-bandwidth product. Here, we discuss various biophotonic methods that have successfully employed this strategic approach. These techniques span broad applications and showcase the versatility and effectiveness of deep learning in the context of compromised biophotonic data. Finally, by offering our perspectives on the future possibilities of this rapidly evolving concept, we hope to motivate our readers to explore novel ways of balancing hardware compromises with compensation via AI.