 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spatio-Temporal Perception-Distortion Trade-off in Learned Video SR
Jul 04, 2023

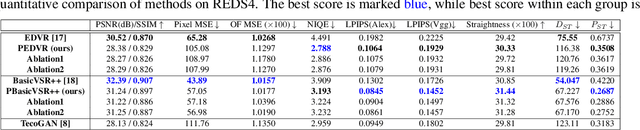
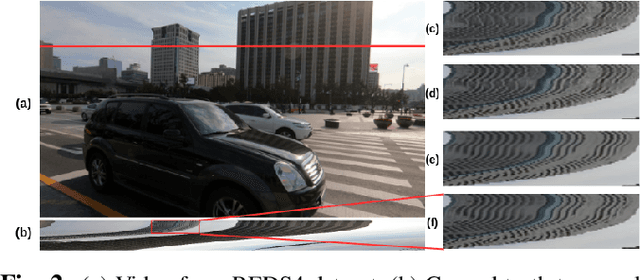
Perception-distortion trade-off is well-understood for single-image super-resolution. However, its extension to video super-resolution (VSR) is not straightforward, since popular perceptual measures only evaluate naturalness of spatial textures and do not take naturalness of flow (temporal coherence) into account. To this effect, we propose a new measure of spatio-temporal perceptual video quality emphasizing naturalness of optical flow via the perceptual straightness hypothesis (PSH) for meaningful spatio-temporal perception-distortion trade-off. We also propose a new architecture for perceptual VSR (PSVR) to explicitly enforce naturalness of flow to achieve realistic spatio-temporal perception-distortion trade-off according to the proposed measures. Experimental results with PVSR support the hypothesis that a meaningful perception-distortion tradeoff for video should account for the naturalness of motion in addition to naturalness of texture.
Plausibility-Based Heuristics for Latent Space Classical Planning
Jun 20, 2023

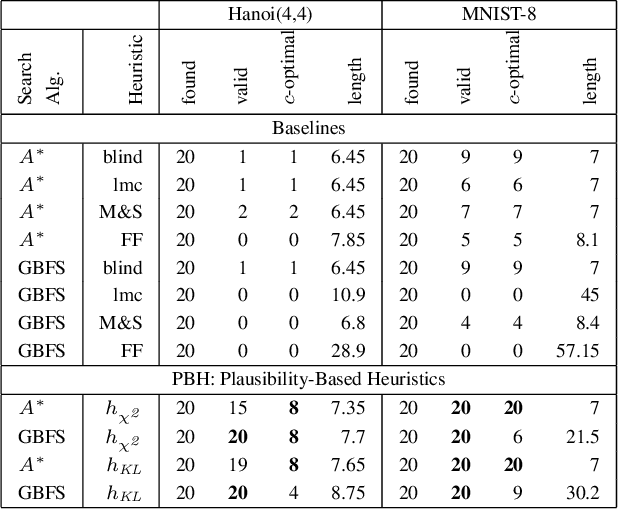
Recent work on LatPlan has shown that it is possible to learn models for domain-independent classical planners from unlabeled image data. Although PDDL models acquired by LatPlan can be solved using standard PDDL planners, the resulting latent-space plan may be invalid with respect to the underlying, ground-truth domain (e.g., the latent-space plan may include hallucinatory/invalid states). We propose Plausibility-Based Heuristics, which are domain-independent plausibility metrics which can be computed for each state evaluated during search and uses as a heuristic function for best-first search. We show that PBH significantly increases the number of valid found plans on image-based tile puzzle and Towers of Hanoi domains.
Defect Detection Approaches Based on Simulated Reference Image
Mar 21, 2023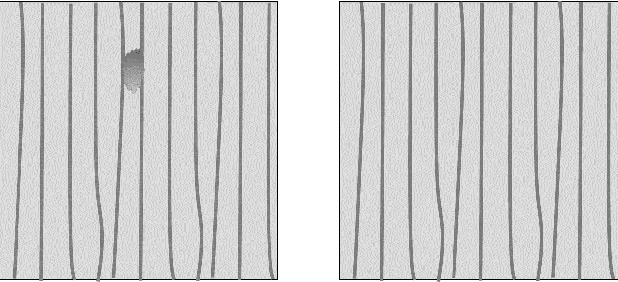

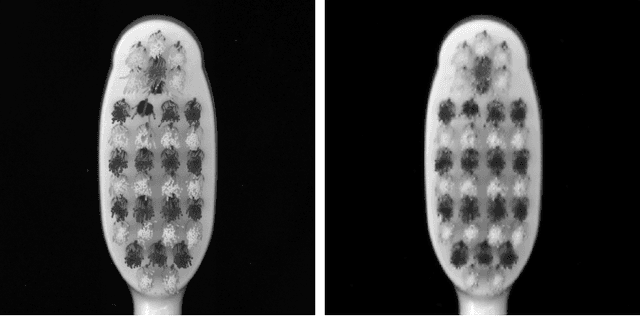

This work is addressing the problem of defect anomaly detection based on a clean reference image. Specifically, we focus on SEM semiconductor defects in addition to several natural image anomalies. There are well-known methods to create a simulation of an artificial reference image by its defect specimen. In this work, we introduce several applications for this capability, that the simulated reference is beneficial for improving their results. Among these defect detection methods are classic computer vision applied on difference-image, supervised deep-learning (DL) based on human labels, and unsupervised DL which is trained on feature-level patterns of normal reference images. We show in this study how to incorporate correctly the simulated reference image for these defect and anomaly detection applications. As our experiment demonstrates, simulated reference achieves higher performance than the real reference of an image of a defect and anomaly. This advantage of simulated reference occurs mainly due to the less noise and geometric variations together with better alignment and registration to the original defect background.
Balanced Energy Regularization Loss for Out-of-distribution Detection
Jun 18, 2023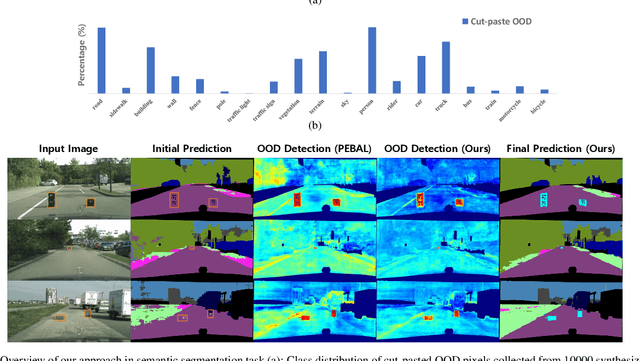
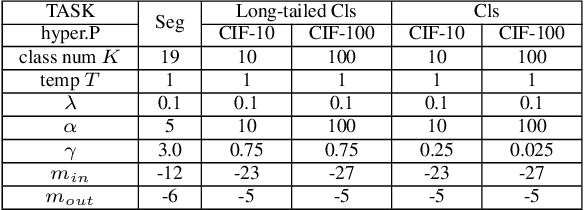
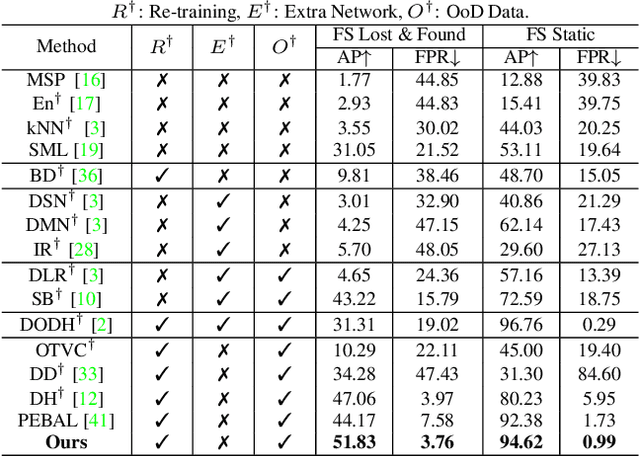
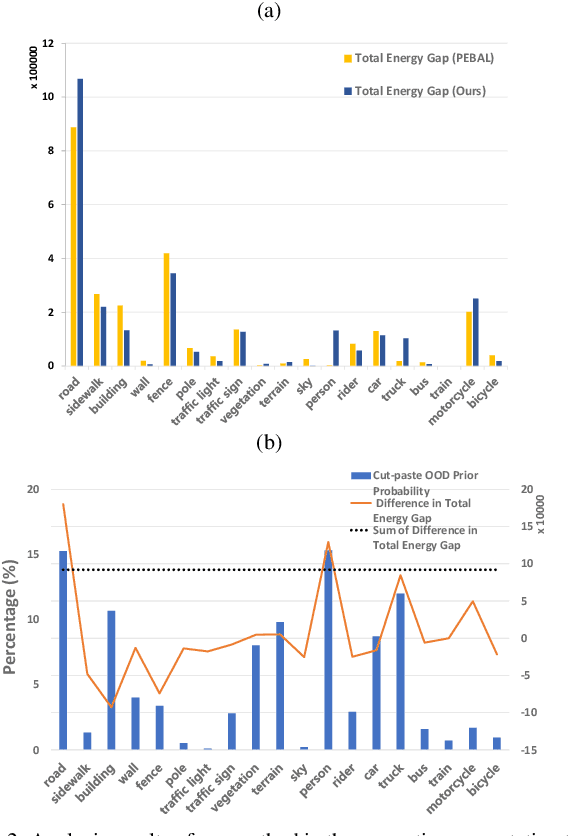
In the field of out-of-distribution (OOD) detection, a previous method that use auxiliary data as OOD data has shown promising performance. However, the method provides an equal loss to all auxiliary data to differentiate them from inliers. However, based on our observation, in various tasks, there is a general imbalance in the distribution of the auxiliary OOD data across classes. We propose a balanced energy regularization loss that is simple but generally effective for a variety of tasks. Our balanced energy regularization loss utilizes class-wise different prior probabilities for auxiliary data to address the class imbalance in OOD data. The main concept is to regularize auxiliary samples from majority classes, more heavily than those from minority classes. Our approach performs better for OOD detection in semantic segmentation, long-tailed image classification, and image classification than the prior energy regularization loss. Furthermore, our approach achieves state-of-the-art performance in two tasks: OOD detection in semantic segmentation and long-tailed image classification. Code is available at https://github.com/hyunjunChhoi/Balanced_Energy.
Understanding Depth Map Progressively: Adaptive Distance Interval Separation for Monocular 3d Object Detection
Jun 19, 2023
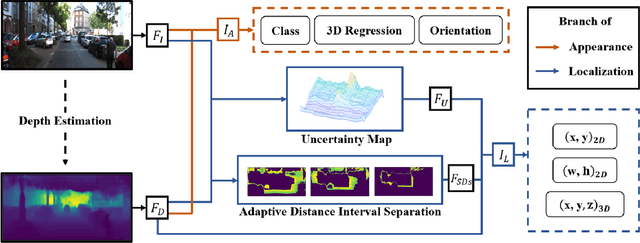
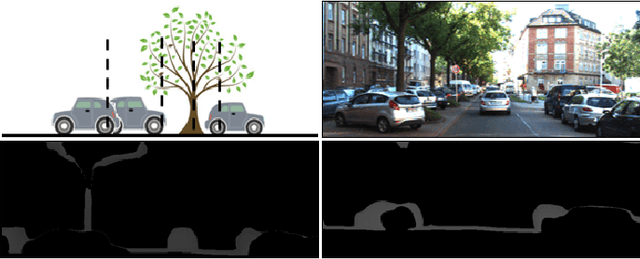
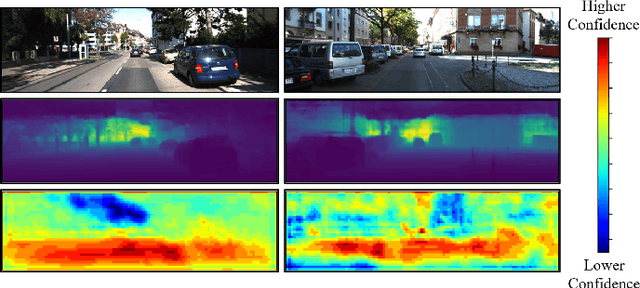
Monocular 3D object detection aims to locate objects in different scenes with just a single image. Due to the absence of depth information, several monocular 3D detection techniques have emerged that rely on auxiliary depth maps from the depth estimation task. There are multiple approaches to understanding the representation of depth maps, including treating them as pseudo-LiDAR point clouds, leveraging implicit end-to-end learning of depth information, or considering them as an image input. However, these methods have certain drawbacks, such as their reliance on the accuracy of estimated depth maps and suboptimal utilization of depth maps due to their image-based nature. While LiDAR-based methods and convolutional neural networks (CNNs) can be utilized for pseudo point clouds and depth maps, respectively, it is always an alternative. In this paper, we propose a framework named the Adaptive Distance Interval Separation Network (ADISN) that adopts a novel perspective on understanding depth maps, as a form that lies between LiDAR and images. We utilize an adaptive separation approach that partitions the depth map into various subgraphs based on distance and treats each of these subgraphs as an individual image for feature extraction. After adaptive separations, each subgraph solely contains pixels within a learned interval range. If there is a truncated object within this range, an evident curved edge will appear, which we can leverage for texture extraction using CNNs to obtain rich depth information in pixels. Meanwhile, to mitigate the inaccuracy of depth estimation, we designed an uncertainty module. To take advantage of both images and depth maps, we use different branches to learn localization detection tasks and appearance tasks separately.
fRegGAN with K-space Loss Regularization for Medical Image Translation
Mar 28, 2023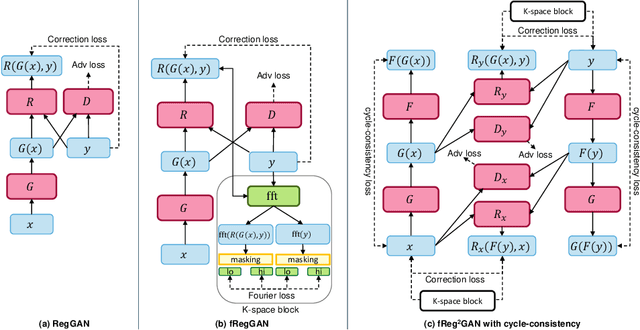
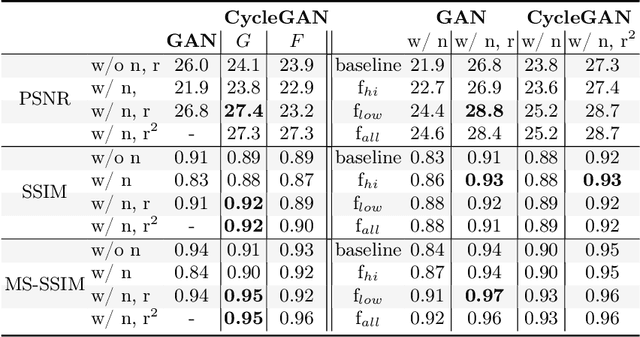
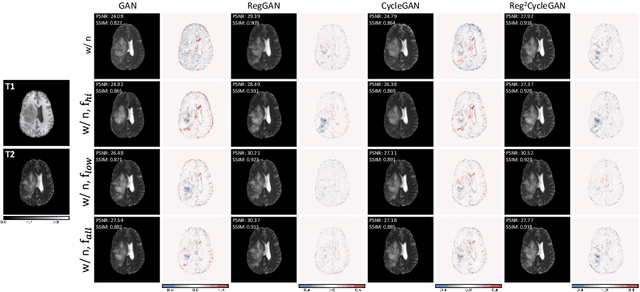
Generative adversarial networks (GANs) have shown remarkable success in generating realistic images and are increasingly used in medical imaging for image-to-image translation tasks. However, GANs tend to suffer from a frequency bias towards low frequencies, which can lead to the removal of important structures in the generated images. To address this issue, we propose a novel frequency-aware image-to-image translation framework based on the supervised RegGAN approach, which we call fRegGAN. The framework employs a K-space loss to regularize the frequency content of the generated images and incorporates well-known properties of MRI K-space geometry to guide the network training process. By combine our method with the RegGAN approach, we can mitigate the effect of training with misaligned data and frequency bias at the same time. We evaluate our method on the public BraTS dataset and outperform the baseline methods in terms of both quantitative and qualitative metrics when synthesizing T2-weighted from T1-weighted MR images. Detailed ablation studies are provided to understand the effect of each modification on the final performance. The proposed method is a step towards improving the performance of image-to-image translation and synthesis in the medical domain and shows promise for other applications in the field of image processing and generation.
Restart Sampling for Improving Generative Processes
Jun 26, 2023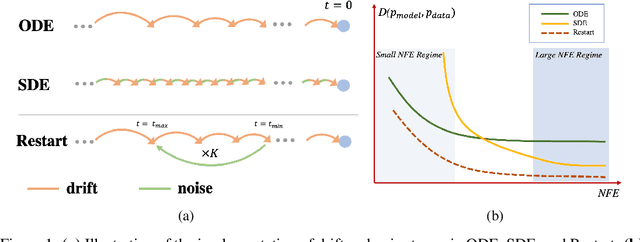
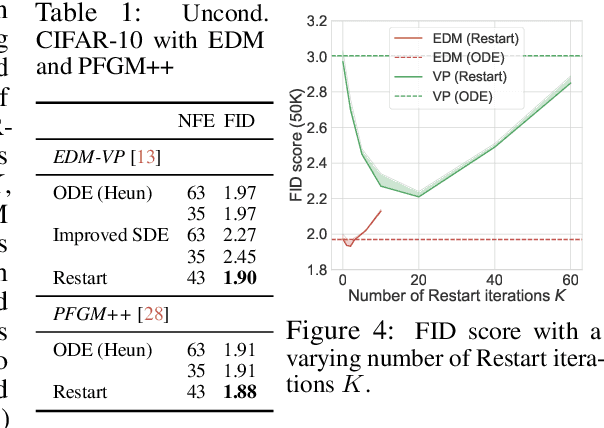
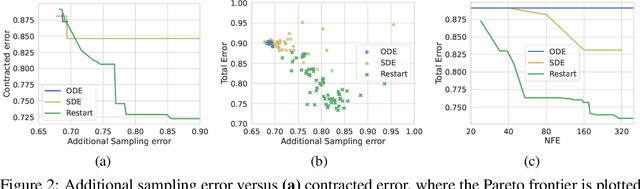

Generative processes that involve solving differential equations, such as diffusion models, frequently necessitate balancing speed and quality. ODE-based samplers are fast but plateau in performance while SDE-based samplers deliver higher sample quality at the cost of increased sampling time. We attribute this difference to sampling errors: ODE-samplers involve smaller discretization errors while stochasticity in SDE contracts accumulated errors. Based on these findings, we propose a novel sampling algorithm called Restart in order to better balance discretization errors and contraction. The sampling method alternates between adding substantial noise in additional forward steps and strictly following a backward ODE. Empirically, Restart sampler surpasses previous SDE and ODE samplers in both speed and accuracy. Restart not only outperforms the previous best SDE results, but also accelerates the sampling speed by 10-fold / 2-fold on CIFAR-10 / ImageNet $64 \times 64$. In addition, it attains significantly better sample quality than ODE samplers within comparable sampling times. Moreover, Restart better balances text-image alignment/visual quality versus diversity than previous samplers in the large-scale text-to-image Stable Diffusion model pre-trained on LAION $512 \times 512$. Code is available at https://github.com/Newbeeer/diffusion_restart_sampling
If at First You Don't Succeed, Try, Try Again: Faithful Diffusion-based Text-to-Image Generation by Selection
May 22, 2023

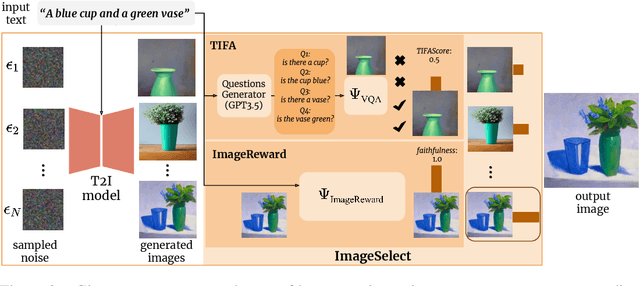
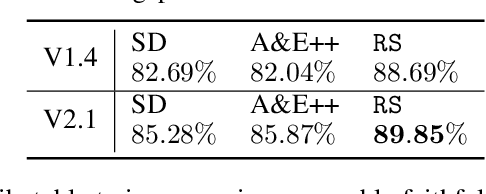
Despite their impressive capabilities, diffusion-based text-to-image (T2I) models can lack faithfulness to the text prompt, where generated images may not contain all the mentioned objects, attributes or relations. To alleviate these issues, recent works proposed post-hoc methods to improve model faithfulness without costly retraining, by modifying how the model utilizes the input prompt. In this work, we take a step back and show that large T2I diffusion models are more faithful than usually assumed, and can generate images faithful to even complex prompts without the need to manipulate the generative process. Based on that, we show how faithfulness can be simply treated as a candidate selection problem instead, and introduce a straightforward pipeline that generates candidate images for a text prompt and picks the best one according to an automatic scoring system that can leverage already existing T2I evaluation metrics. Quantitative comparisons alongside user studies on diverse benchmarks show consistently improved faithfulness over post-hoc enhancement methods, with comparable or lower computational cost. Code is available at \url{https://github.com/ExplainableML/ImageSelect}.
Generative Diffusion Prior for Unified Image Restoration and Enhancement
Apr 03, 2023
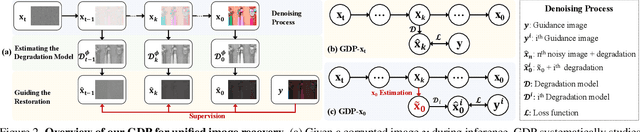
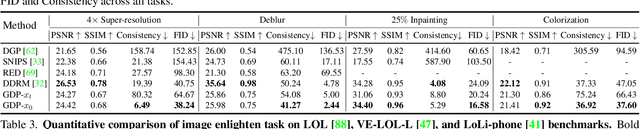

Existing image restoration methods mostly leverage the posterior distribution of natural images. However, they often assume known degradation and also require supervised training, which restricts their adaptation to complex real applications. In this work, we propose the Generative Diffusion Prior (GDP) to effectively model the posterior distributions in an unsupervised sampling manner. GDP utilizes a pre-train denoising diffusion generative model (DDPM) for solving linear inverse, non-linear, or blind problems. Specifically, GDP systematically explores a protocol of conditional guidance, which is verified more practical than the commonly used guidance way. Furthermore, GDP is strength at optimizing the parameters of degradation model during the denoising process, achieving blind image restoration. Besides, we devise hierarchical guidance and patch-based methods, enabling the GDP to generate images of arbitrary resolutions. Experimentally, we demonstrate GDP's versatility on several image datasets for linear problems, such as super-resolution, deblurring, inpainting, and colorization, as well as non-linear and blind issues, such as low-light enhancement and HDR image recovery. GDP outperforms the current leading unsupervised methods on the diverse benchmarks in reconstruction quality and perceptual quality. Moreover, GDP also generalizes well for natural images or synthesized images with arbitrary sizes from various tasks out of the distribution of the ImageNet training set.
Blended-NeRF: Zero-Shot Object Generation and Blending in Existing Neural Radiance Fields
Jun 22, 2023Editing a local region or a specific object in a 3D scene represented by a NeRF is challenging, mainly due to the implicit nature of the scene representation. Consistently blending a new realistic object into the scene adds an additional level of difficulty. We present Blended-NeRF, a robust and flexible framework for editing a specific region of interest in an existing NeRF scene, based on text prompts or image patches, along with a 3D ROI box. Our method leverages a pretrained language-image model to steer the synthesis towards a user-provided text prompt or image patch, along with a 3D MLP model initialized on an existing NeRF scene to generate the object and blend it into a specified region in the original scene. We allow local editing by localizing a 3D ROI box in the input scene, and seamlessly blend the content synthesized inside the ROI with the existing scene using a novel volumetric blending technique. To obtain natural looking and view-consistent results, we leverage existing and new geometric priors and 3D augmentations for improving the visual fidelity of the final result. We test our framework both qualitatively and quantitatively on a variety of real 3D scenes and text prompts, demonstrating realistic multi-view consistent results with much flexibility and diversity compared to the baselines. Finally, we show the applicability of our framework for several 3D editing applications, including adding new objects to a scene, removing/replacing/altering existing objects, and texture conversion.