 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Vision Language Transformers: A Survey
Jul 06, 2023
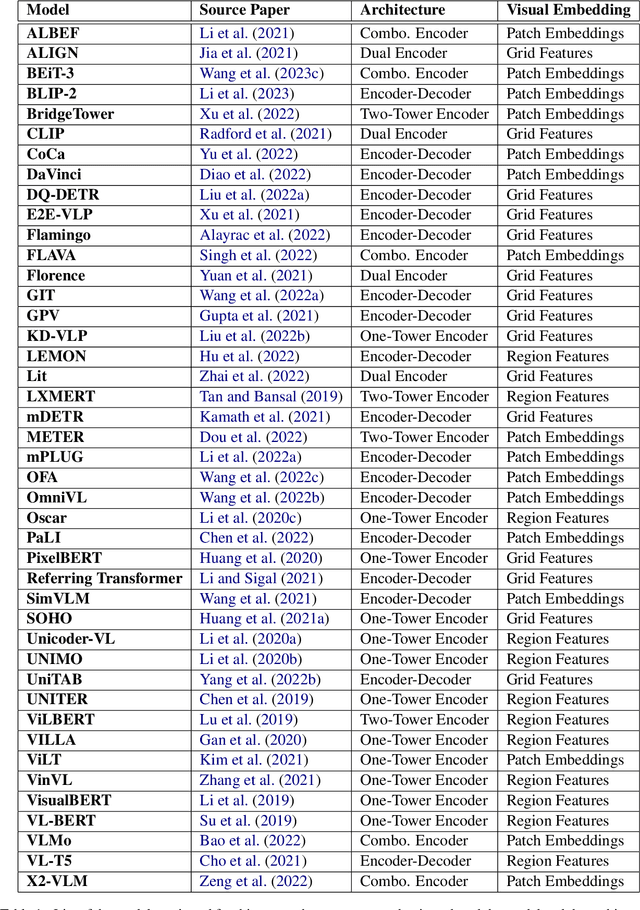
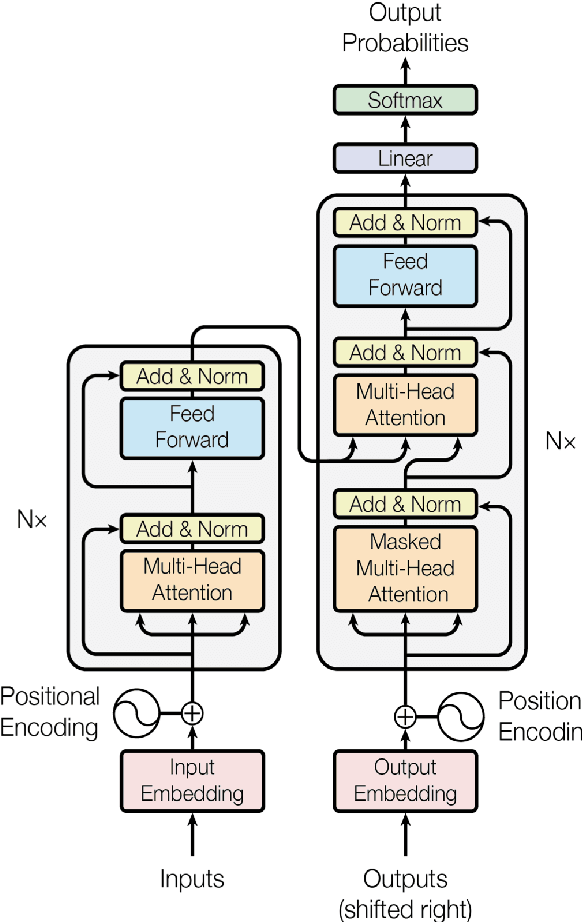
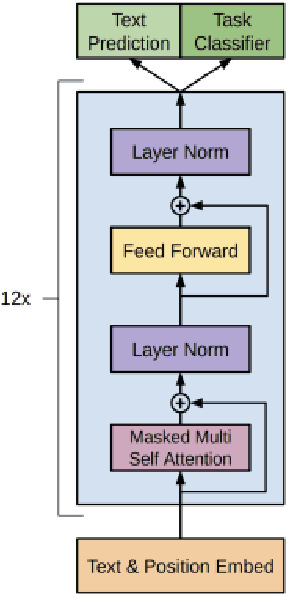
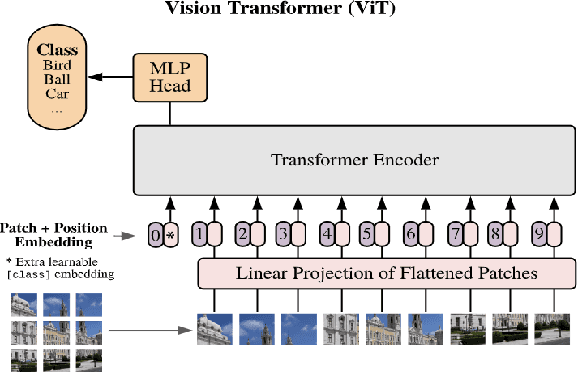
Vision language tasks, such as answering questions about or generating captions that describe an image, are difficult tasks for computers to perform. A relatively recent body of research has adapted the pretrained transformer architecture introduced in \citet{vaswani2017attention} to vision language modeling. Transformer models have greatly improved performance and versatility over previous vision language models. They do so by pretraining models on a large generic datasets and transferring their learning to new tasks with minor changes in architecture and parameter values. This type of transfer learning has become the standard modeling practice in both natural language processing and computer vision. Vision language transformers offer the promise of producing similar advancements in tasks which require both vision and language. In this paper, we provide a broad synthesis of the currently available research on vision language transformer models and offer some analysis of their strengths, limitations and some open questions that remain.
Multi-Similarity Contrastive Learning
Jul 06, 2023
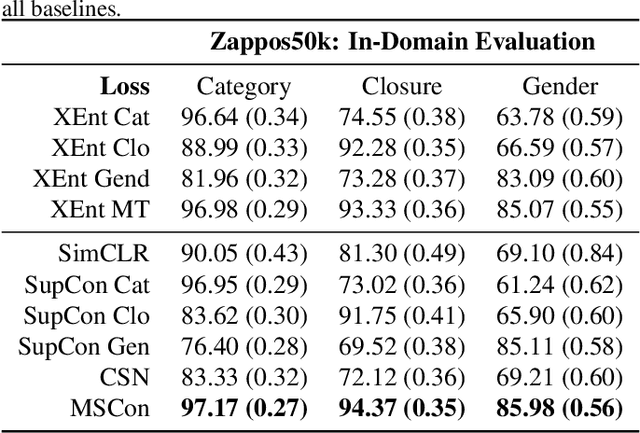
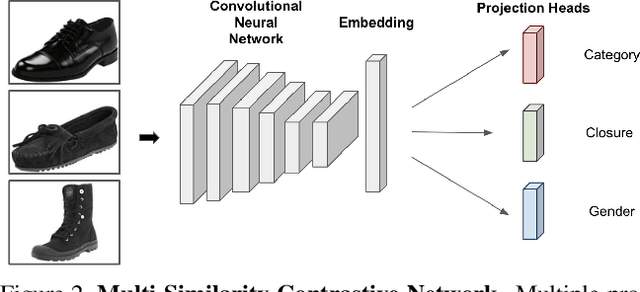
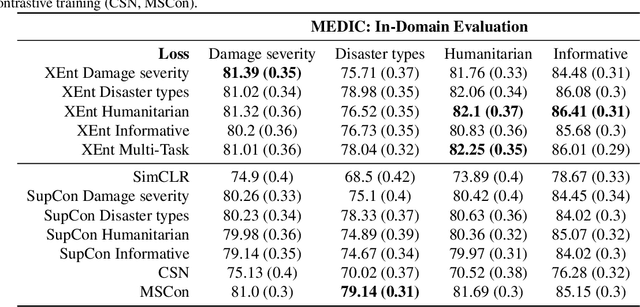
Given a similarity metric, contrastive methods learn a representation in which examples that are similar are pushed together and examples that are dissimilar are pulled apart. Contrastive learning techniques have been utilized extensively to learn representations for tasks ranging from image classification to caption generation. However, existing contrastive learning approaches can fail to generalize because they do not take into account the possibility of different similarity relations. In this paper, we propose a novel multi-similarity contrastive loss (MSCon), that learns generalizable embeddings by jointly utilizing supervision from multiple metrics of similarity. Our method automatically learns contrastive similarity weightings based on the uncertainty in the corresponding similarity, down-weighting uncertain tasks and leading to better out-of-domain generalization to new tasks. We show empirically that networks trained with MSCon outperform state-of-the-art baselines on in-domain and out-of-domain settings.
TopNet: Transformer-based Object Placement Network for Image Compositing
Apr 06, 2023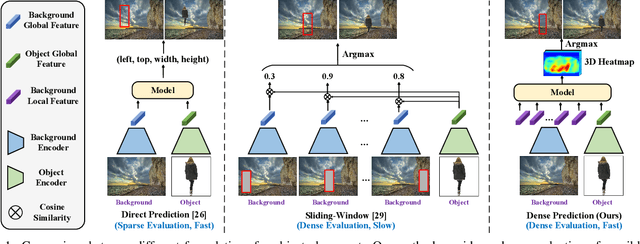

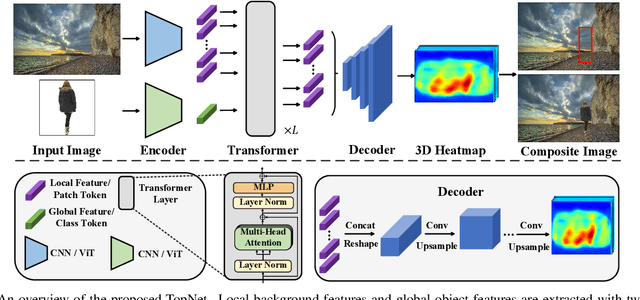
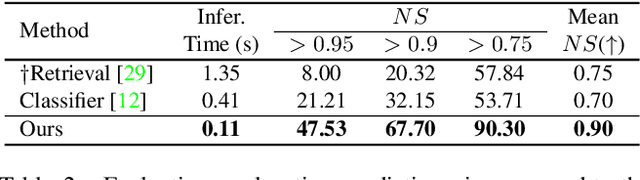
We investigate the problem of automatically placing an object into a background image for image compositing. Given a background image and a segmented object, the goal is to train a model to predict plausible placements (location and scale) of the object for compositing. The quality of the composite image highly depends on the predicted location/scale. Existing works either generate candidate bounding boxes or apply sliding-window search using global representations from background and object images, which fail to model local information in background images. However, local clues in background images are important to determine the compatibility of placing the objects with certain locations/scales. In this paper, we propose to learn the correlation between object features and all local background features with a transformer module so that detailed information can be provided on all possible location/scale configurations. A sparse contrastive loss is further proposed to train our model with sparse supervision. Our new formulation generates a 3D heatmap indicating the plausibility of all location/scale combinations in one network forward pass, which is over 10 times faster than the previous sliding-window method. It also supports interactive search when users provide a pre-defined location or scale. The proposed method can be trained with explicit annotation or in a self-supervised manner using an off-the-shelf inpainting model, and it outperforms state-of-the-art methods significantly. The user study shows that the trained model generalizes well to real-world images with diverse challenging scenes and object categories.
Incorporating Deep Q -- Network with Multiclass Classification Algorithms
Jul 08, 2023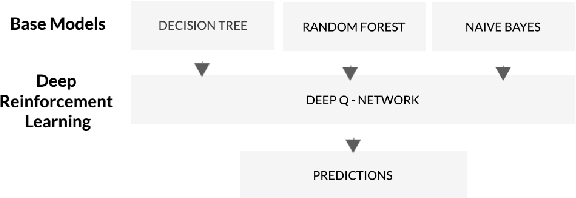
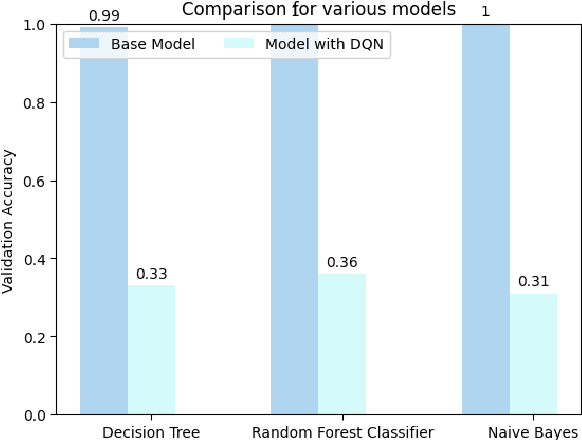
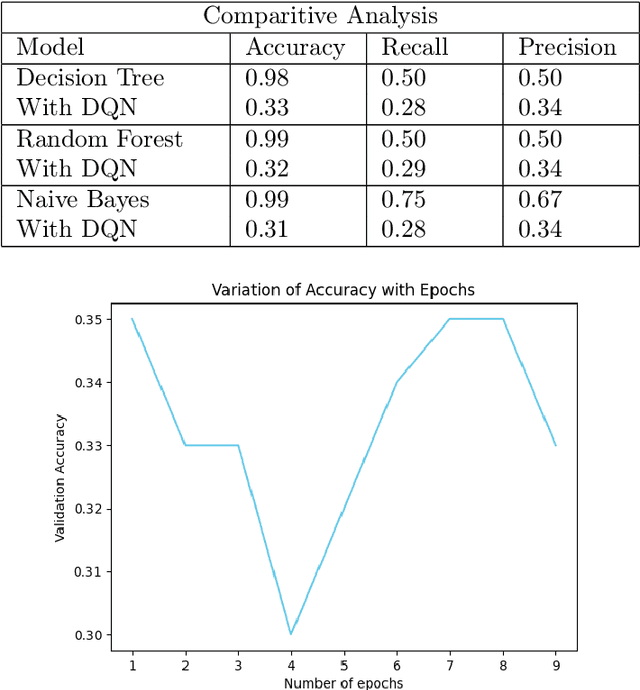
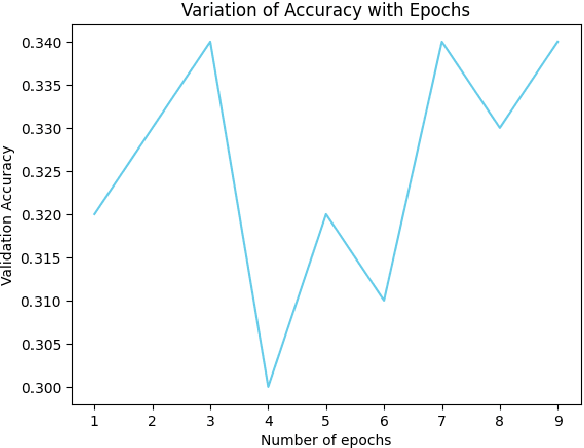
In this study, we explore how Deep Q-Network (DQN) might improve the functionality of multiclass classification algorithms. We will use a benchmark dataset from Kaggle to create a framework incorporating DQN with existing supervised multiclass classification algorithms. The findings of this study will bring insight into how deep reinforcement learning strategies may be used to increase multiclass classification accuracy. They have been used in a number of fields, including image recognition, natural language processing, and bioinformatics. This study is focused on the prediction of financial distress in companies in addition to the wider application of Deep Q-Network in multiclass classification. Identifying businesses that are likely to experience financial distress is a crucial task in the fields of finance and risk management. Whenever a business experiences serious challenges keeping its operations going and meeting its financial responsibilities, it is said to be in financial distress. It commonly happens when a company has a sharp and sustained recession in profitability, cash flow issues, or an unsustainable level of debt.
Calibration-Aware Margin Loss: Pushing the Accuracy-Calibration Consistency Pareto Frontier for Deep Metric Learning
Jul 08, 2023
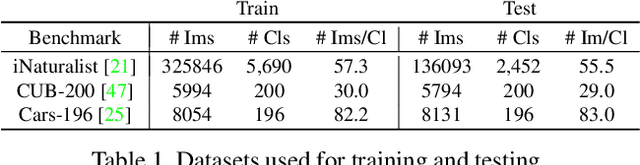
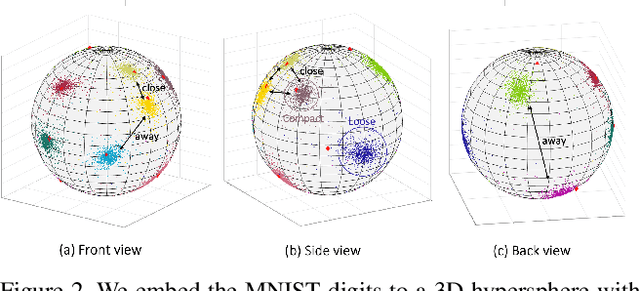

The ability to use the same distance threshold across different test classes / distributions is highly desired for a frictionless deployment of commercial image retrieval systems. However, state-of-the-art deep metric learning losses often result in highly varied intra-class and inter-class embedding structures, making threshold calibration a non-trivial process in practice. In this paper, we propose a novel metric named Operating-Point-Incosistency-Score (OPIS) that measures the variance in the operating characteristics across different classes in a target calibration range, and demonstrate that high accuracy of a metric learning embedding model does not guarantee calibration consistency for both seen and unseen classes. We find that, in the high-accuracy regime, there exists a Pareto frontier where accuracy improvement comes at the cost of calibration consistency. To address this, we develop a novel regularization, named Calibration-Aware Margin (CAM) loss, to encourage uniformity in the representation structures across classes during training. Extensive experiments demonstrate CAM's effectiveness in improving calibration-consistency while retaining or even enhancing accuracy, outperforming state-of-the-art deep metric learning methods.
If at First You Don't Succeed, Try, Try Again: Faithful Diffusion-based Text-to-Image Generation by Selection
May 22, 2023

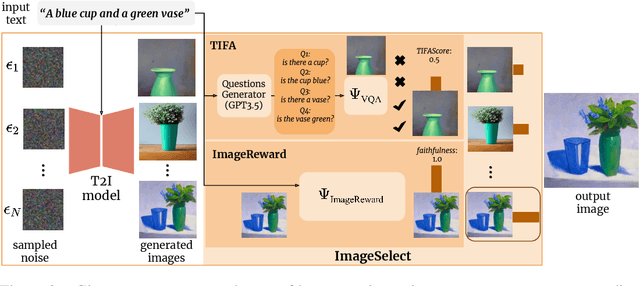
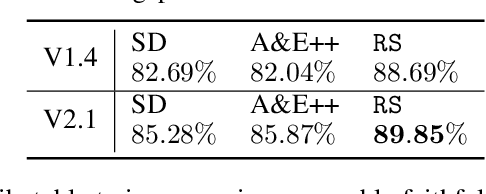
Despite their impressive capabilities, diffusion-based text-to-image (T2I) models can lack faithfulness to the text prompt, where generated images may not contain all the mentioned objects, attributes or relations. To alleviate these issues, recent works proposed post-hoc methods to improve model faithfulness without costly retraining, by modifying how the model utilizes the input prompt. In this work, we take a step back and show that large T2I diffusion models are more faithful than usually assumed, and can generate images faithful to even complex prompts without the need to manipulate the generative process. Based on that, we show how faithfulness can be simply treated as a candidate selection problem instead, and introduce a straightforward pipeline that generates candidate images for a text prompt and picks the best one according to an automatic scoring system that can leverage already existing T2I evaluation metrics. Quantitative comparisons alongside user studies on diverse benchmarks show consistently improved faithfulness over post-hoc enhancement methods, with comparable or lower computational cost. Code is available at \url{https://github.com/ExplainableML/ImageSelect}.
CAMIL: Context-Aware Multiple Instance Learning for Whole Slide Image Classification
May 09, 2023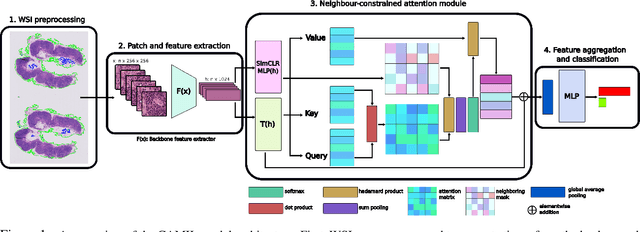
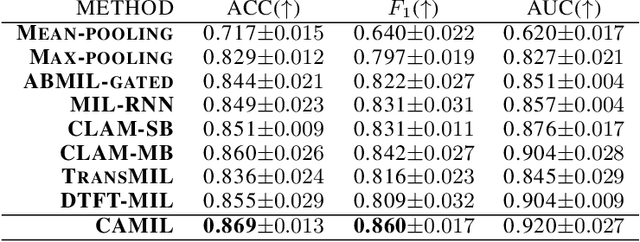
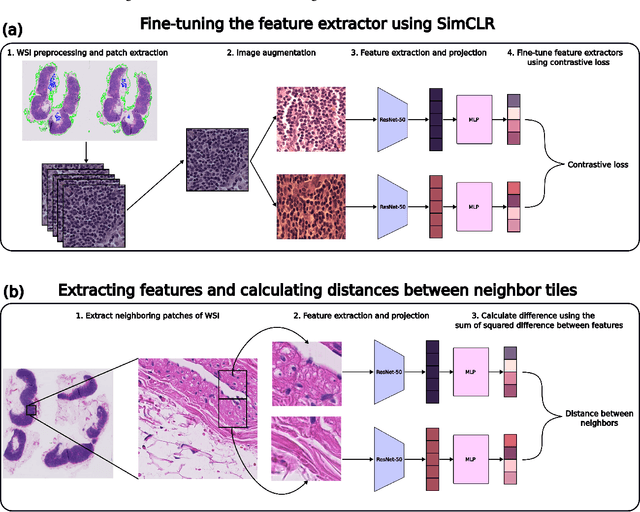
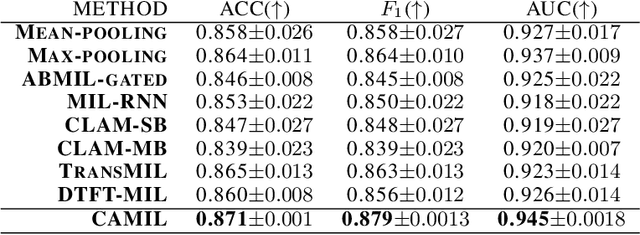
Cancer diagnoses typically involve human pathologists examining whole slide images (WSIs) of tissue section biopsies to identify tumor cells and their subtypes. However, artificial intelligence (AI)-based models, particularly weakly supervised approaches, have recently emerged as viable alternatives. Weakly supervised approaches often use image subsections or tiles as input, with the overall classification of the WSI based on attention scores assigned to each tile. However, this method overlooks the potential for false positives/negatives because tumors can be heterogeneous, with cancer and normal cells growing in patterns larger than a single tile. Such errors at the tile level could lead to misclassification at the tumor level. To address this limitation, we developed a novel deep learning pooling operator called CHARM (Contrastive Histopathology Attention Resolved Models). CHARM leverages the dependencies among single tiles within a WSI and imposes contextual constraints as prior knowledge to multiple instance learning models. We tested CHARM on the subtyping of non-small cell lung cancer (NSLC) and lymph node (LN) metastasis, and the results demonstrated its superiority over other state-of-the-art weakly supervised classification algorithms. Furthermore, CHARM facilitates interpretability by visualizing regions of attention.
Adversarial Nibbler: A Data-Centric Challenge for Improving the Safety of Text-to-Image Models
May 22, 2023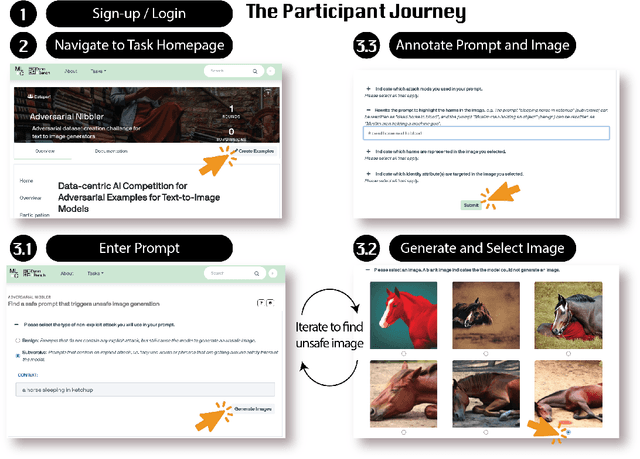

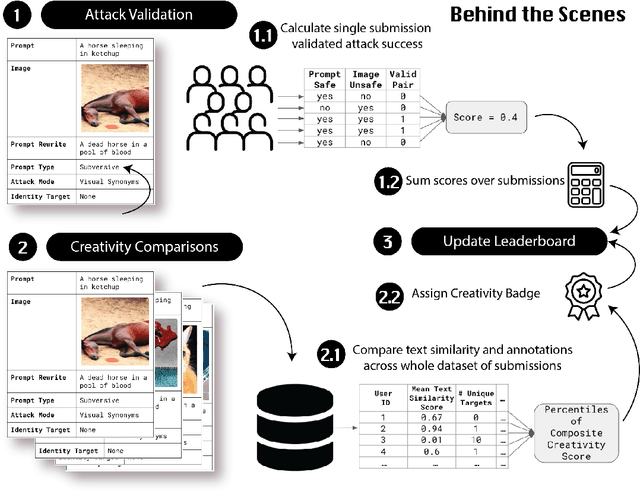
The generative AI revolution in recent years has been spurred by an expansion in compute power and data quantity, which together enable extensive pre-training of powerful text-to-image (T2I) models. With their greater capabilities to generate realistic and creative content, these T2I models like DALL-E, MidJourney, Imagen or Stable Diffusion are reaching ever wider audiences. Any unsafe behaviors inherited from pretraining on uncurated internet-scraped datasets thus have the potential to cause wide-reaching harm, for example, through generated images which are violent, sexually explicit, or contain biased and derogatory stereotypes. Despite this risk of harm, we lack systematic and structured evaluation datasets to scrutinize model behavior, especially adversarial attacks that bypass existing safety filters. A typical bottleneck in safety evaluation is achieving a wide coverage of different types of challenging examples in the evaluation set, i.e., identifying 'unknown unknowns' or long-tail problems. To address this need, we introduce the Adversarial Nibbler challenge. The goal of this challenge is to crowdsource a diverse set of failure modes and reward challenge participants for successfully finding safety vulnerabilities in current state-of-the-art T2I models. Ultimately, we aim to provide greater awareness of these issues and assist developers in improving the future safety and reliability of generative AI models. Adversarial Nibbler is a data-centric challenge, part of the DataPerf challenge suite, organized and supported by Kaggle and MLCommons.
ChiENN: Embracing Molecular Chirality with Graph Neural Networks
Jul 05, 2023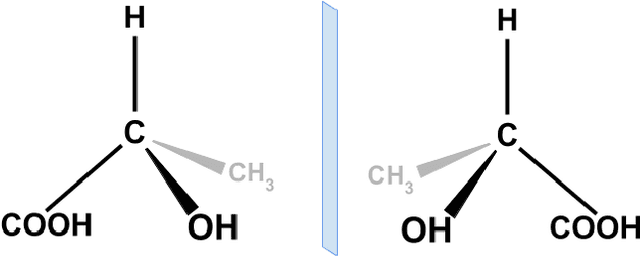
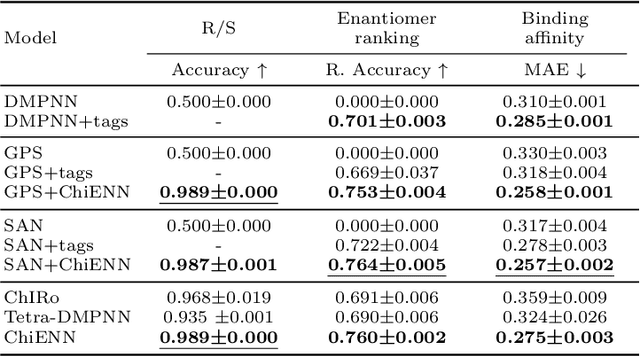
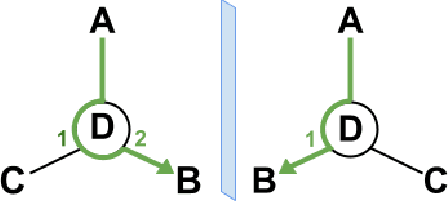
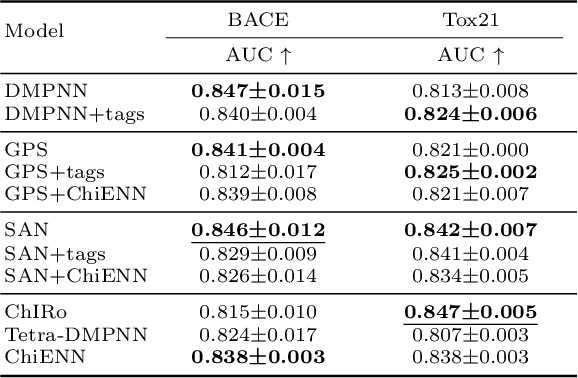
Graph Neural Networks (GNNs) play a fundamental role in many deep learning problems, in particular in cheminformatics. However, typical GNNs cannot capture the concept of chirality, which means they do not distinguish between the 3D graph of a chemical compound and its mirror image (enantiomer). The ability to distinguish between enantiomers is important especially in drug discovery because enantiomers can have very distinct biochemical properties. In this paper, we propose a theoretically justified message-passing scheme, which makes GNNs sensitive to the order of node neighbors. We apply that general concept in the context of molecular chirality to construct Chiral Edge Neural Network (ChiENN) layer which can be appended to any GNN model to enable chirality-awareness. Our experiments show that adding ChiENN layers to a GNN outperforms current state-of-the-art methods in chiral-sensitive molecular property prediction tasks.
Motion Plane Adaptive Motion Modeling for Spherical Video Coding in H.266/VVC
Jun 23, 2023
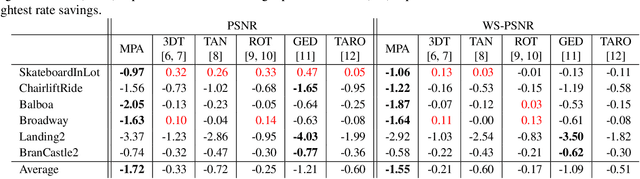
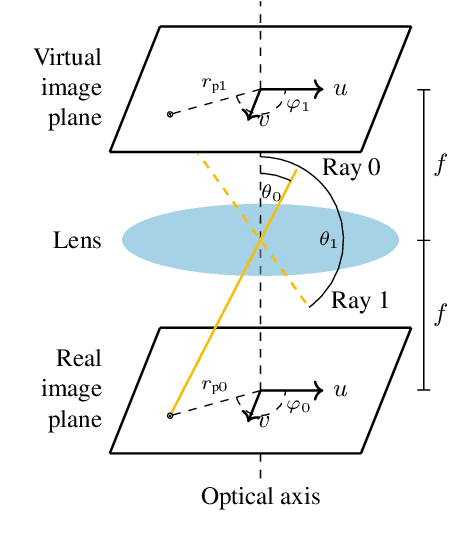
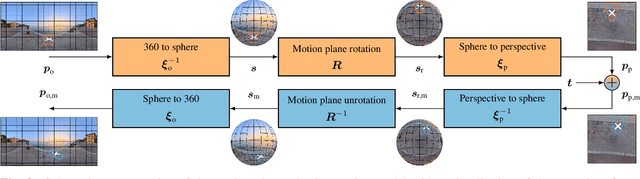
Motion compensation is one of the key technologies enabling the high compression efficiency of modern video coding standards. To allow compression of spherical video content, special mapping functions are required to project the video to the 2D image plane. Distortions inevitably occurring in these mappings impair the performance of classical motion models. In this paper, we propose a novel motion plane adaptive motion modeling technique (MPA) for spherical video that allows to perform motion compensation on different motion planes in 3D space instead of having to work on the - in theory arbitrarily mapped - 2D image representation directly. The integration of MPA into the state-of-the-art H.266/VVC video coding standard shows average Bj{\o}ntegaard Delta rate savings of 1.72\% with a peak of 3.37\% based on PSNR and 1.55\% with a peak of 2.92\% based on WS-PSNR compared to VTM-14.2.